
Obsah
1. Architektura VLIW a rodina DSP čipů TI TMS320C6×
2. Zvyšování výpočetního výkonu mikroprocesorů
3. VLIW – řešení některých problémů architektur CISC a RISC
4. Klasický dispatcher versus VLIW
5. Způsob rozdělení instrukčního slova do polí
6. VLIW=složitá instrukční slova?
7. Některá rizika spojená s mikroprocesory s architekturou VLIW
8. Porovnání architektur RISC, CISC a VLIW
9. Rodina DSP čipů TI TMS320C6×
10. Čipy TMS320C62× – DSP pro operace s hodnotami s pevnou řádovou čárkou
11. Interní struktura TMS320C62×
12. Přenosy dat mezi částmi A a B
1. Architektura VLIW a rodina DSP čipů TI TMS320C6×
Na předchozí článek o digitálních signálových procesorech řady TSM320 vyráběných společností Texas Instruments dnes navážeme, protože si popíšeme jednu velmi zajímavou a současně i pro mnoho programátorů neobvyklou řadu signálových procesorů TMS320C6×. Tyto signálové procesory jsou založeny na architektuře VLIW, která byla použita především z toho důvodu, že umožňovala zvýšit výpočetní výkon s použitím paralelně běžících jednotek (ALU, MAC atd.) a současně zachovat jednoduchost vlastního čipu (naproti tomu bylo nutné investovat do lepšího překladače). Použití VLIW vlastně nemusí být příliš překvapivé, když si uvědomíme, že už první čipy TMS32010 byly navrženy na podobném principu – s trochou nadsázky je možné říct, že se jednalo o výkonnou násobičku doplněnou o nezbytnou ALU, řadič a registry. U čipů VLIW firmy TI je to podobné – úkolem celého čipu je zabezpečit co nejlepší vytížení násobiček (MAC), ALU i shifterů, a to i za cenu delšího programu.
Tato na dobu vzniku velmi výkonná architektura (ostatně DSP řady TMS320C67× byly první DSP, které pokořily hranici 1 GFLOPS) umožnila nasazení DSP v mnoha oblastech, od modemů a DSL až po zařízení pro GPS, některá (dnes již překonaná) zařízení pro 3D grafiku a virtuální realitu, zpracování audio signálů v reálném čase, zpracování obrazů (MRI, ultrazvukové snímky, rozpoznávání otisků prstů) atd.
2. Zvyšování výpočetního výkonu mikroprocesorů
Snaha o zvýšení výpočetního výkonu mikroprocesorů není nijak nová, protože se tímto problémem zabývali i konstruktéři prvních mikroprocesorů (a předtím konstruktéři procesorů, které ještě nebyly integrovány na jediném čipu). Řešení tohoto problému je několik – od klasické RISCové pipeline s překrývajícími se instrukcemi přes několik samostatně pracujících instrukčních pipeline (superskalární procesory), SIMD až po paralelizaci výpočtů na větším množství procesorových jader. Objevila se i některá částečná řešení – použití branch delay slotů u RISCových pipeline, provádění instrukcí mimo pořadí (out of order execution), použití prediktorů skoků apod. Většina vylepšení byla ovšem implementována na úkor neustále se zvyšující interní složitosti čipů, což platí zejména pro technologii provádění instrukcí mimo pořadí, která vyžaduje zcela přepracovanou strukturu mikroprocesoru.

Obrázek 1: Mikroprocesor Intel Pentium s hodinovou frekvencí 66 MHz, který je postavený na mikroarchitektuře P5. Jedná se sice o procesor CISC, je ovšem vybaven dvojicí paralelně pracujících pipeline a tudíž se jedná o superskalární procesor. O tom, že vytvořit superskalární CISCový procesor nebyla jednoduchá záležitost (ve své době se dokonce hodně příznivců RISCových procesorů vyjadřovalo v tom smyslu, že je to kvůli špatně navržené instrukční sadě x86 dokonce nemožné), svědčí i to, že ve vývojovém týmu Pentia bylo zaměstnáno přibližně 200 inženýrů (zatímco například RISC I je výsledek práce dvou až tří lidí).
Proto není divu, že se někteří konstruktéři mikroprocesorů a především digitálních signálových procesorů (včetně firmy Texas Instruments) při návrhu některých čipů vrátili k relativně staré myšlence takzvaného instrukčního paralelismu, jenž by však byl zabudován přímo v instrukční sadě a nikoli v samotném mikroprocesoru. Jinými slovy by se starost o paralelizaci instrukcí (což je jedna z nejúčinnějších metod zvýšení výpočetního výkonu) v aplikacích přenesla na překladač, popř. na programátora vytvářejícího své programy přímo v assembleru (to v oblasti DSP není tak velký problém, jak by se mohlo zdát, protože mnoho aplikací pro zpracování signálů jsou relativně jednoduché „mlátičky“ dat). Jednu z alternativ představuje i architektura VLIW neboli Very Long Instruction Word.
3. VLIW – řešení některých problémů architektur CISC a RISC
Název architektury VLIW již částečně vysvětluje, čím se tato architektura odlišuje od mikroprocesorů CISC a RISC. Připomeňme si, že mikroprocesory s architekturou CISC mívají ve velkém množství případů instrukční sadu s proměnnou délkou instrukčních slov (jedná se například o známou řadu Intel 8008 pokračující až k rodině i386, ale i o mnohé další mikroprocesory a taktéž mikrořadiče, s nimiž jsme se již v tomto seriálu seznámili). Instrukce, které se v instrukční sadě nachází, mohou být i poměrně složité a mohou obsahovat různé adresní režimy, ovšem v každém instrukčním slovu je většinou uložena pouze jedna operace, v mezním případě operace prováděná nad vektorem (rozšíření instrukčních sad o instrukce MMX a SSE). Na druhou stranu procesory RISC mají naopak instrukční sadu s instrukcemi pevné délky (většinou se jedná o 32bitové instrukce, i když i zde jsme mohli narazit na výjimky s instrukcemi o šířce šestnácti bitů), a opět platí, že v každé instrukci je uložena pouze jedna operace, například načtení slova z operační paměti, součet dvou pracovních registrů, uložení konstanty do pracovního registru či provedení podmíněného, popř. nepodmíněného skoku.

Obrázek 2: Instrukční sada mikrořadiče M68HC05 s architekturou CISC. Instrukce mají podle svého typu a adresního režimu různou délku.
(Zdroj: Freescale Semiconductor, Ltd. MC68HC05B6/D Rev. 4.1 08/2005)
Při přechodu původně čistě skalárních čipů s architekturami CISC a RISC na superskalární procesory to ovšem znamená, že superskalární čipy musí načíst větší množství instrukcí a potom tyto instrukce vhodným způsobem rozeslat do jednotlivých instrukčních front. Superskalární procesory musí současně řešit i vzniklé konflikty při přístupu k pracovním registrům atd. (u některých jednodušších procesorů však konflikty nejsou řešeny, popř. se při konfliktu pouze vygeneruje výjimka). To vše je daň zaplacená za flexibilitu instrukční sady (což se vyplácí v oblasti desktopů a serverů, méně již ve specializovaných oblastech, mezi něž patří MCU a DSP).
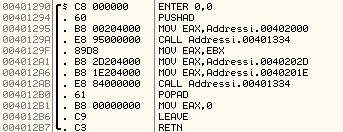
Obrázek 3: Ukázka kódování instrukcí různé délky. Tyto instrukce jsou použity u mikroprocesorů patřících do rodiny x86 v 32bitovém režimu.
Naproti tomu se u mikroprocesorů VLIW používá zcela odlišný instrukční formát, který má ovšem zcela zásadní vliv na interní strukturu těchto mikroprocesorů. U VLIW se používají instrukce pevné délky, podobně jako je tomu u mikroprocesorů s architekturou RISC, ovšem délka těchto instrukcí je většinou (mnohem) delší, než 32 bitů, dosahuje řádově šířky několik desítek i stovek bitů. Je tomu tak z toho důvodu, že každé instrukční slovo je rozděleno do většího množství bitových polí (bit fields), přičemž v každém bitovém poli je umístěn kód jedné operace.
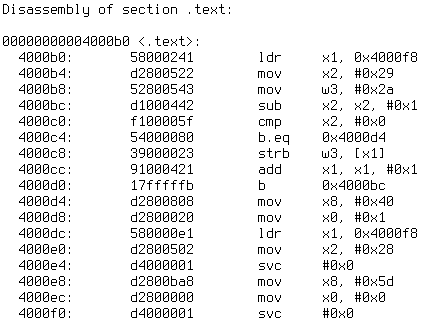
Obrázek 4: Ukázka kódování instrukcí pevné délky. Zde se konkrétně jedná o disassemblovaný strojový kód určený pro 64bitovou architekturu AArch64, s níž jsme se seznámili v tomto a tomto článku.
4. Klasický dispatcher versus VLIW
Jak se od sebe odlišuje dispatcher používaný v klasických skalárních i superskalárních procesorech od jednoduchého VLIW procesoru, je naznačeno na následující dvojici obrázků. Na levé straně můžeme vidět paměť programu (pro jednoduchost bez I-cache, fronty atd.). Jednotlivé instrukce jsou načítány a buď postupně rozdělovány mezi jednotlivé výkonné moduly procesoru (dispatcher), nebo se jednoduše z celého širokého instrukčního slova pošlou vybrané bity do jednotlivých modulů. Na obrázcích je pro jednoduchost nakreslen procesor s pouhými čtyřmi moduly – aritmeticko-logickými jednotkami a násobičkou spojenou se sčítačkou (v DSP oblasti se operace MAC – Multiply and Accumulate používá velmi často). V praxi však bude modulů víc (shiftery, podmíněné a nepodmíněné skoky, přenosy dat…) a navíc od sebe nebudou striktně odděleny, protože například ALU většinou sdílí nějaké pracovní registry.
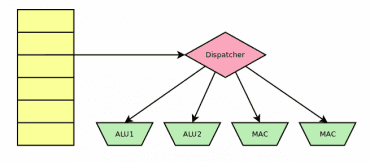
Obrázek 5: Dispatcher použitý v klasických skalárních i superskalárních procesorech.
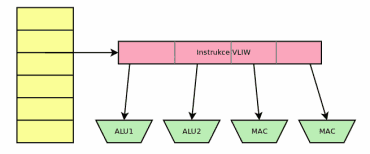
Obrázek 6: VLIW s instrukcemi rozdělenými do bitových polí.
Poznámka: nikde není naznačena existence či neexistence pipeline, protože tu lze použít i u VLIW.
5. Způsob rozdělení instrukčního slova do polí
Ve třetí kapitole jsme si řekli, že u mikroprocesorů s architekturou VLIW je instrukční slovo rozděleno do několika polí, které mohou být buď pevné délky („klasický“ VLIW), nebo délky proměnné (v tomto případě se můžeme setkat s označením EPIC, popř. s dalšími obchodními názvy). Pokud se tedy například v jednom instrukčním slovu nachází pět bitových polí, je možné do instrukčního slova zakódovat až pět různých operací, které se mohou začít spouštět paralelně, protože mikroprocesor s architekturou VLIW nemusí provádět žádnou kontrolu, zda se skutečně jedná o operace, jenž se mohou paralelně spustit – slučování operací do instrukčních slov je zcela záležitostí překladače (ten samozřejmě musí při překladu brát v potaz interní strukturu mikroprocesoru, a to v mnohem větší míře, než je tomu u procesorů RISC a CISC). Navíc se mikroprocesor s architekturou VLIW vůbec nemusí složitě snažit o rozdělování jednotlivých operací do instrukčních pipeline, protože i to je předem určeno překladačem – pozicí operace v instrukčním slovu.
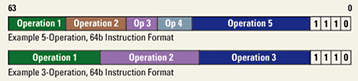
Obrázek 7: Některé možnosti rozdělení dlouhého instrukčního slova do bitových polí odlišné délky a taktéž rozdílné funkce.
V praxi to například může znamenat, že v jednom „dlouhém“ instrukčním slovu se mohou nacházet kódy dvou operací pro celočíselnou aritmeticko-logickou jednotku, jeden kód pro operaci skoku, jeden kód operace určené pro provedení matematickým koprocesorem (samozřejmě jen pokud je matematický procesor na čipu implementován) a navíc poslední kód operace pro načtení či uložení operandů z operační paměti (některé procesory VLIW navíc obsahují i jednotky pro provádění grafických operací, u DSP bývá z ALU separována i násobička či větší množství násobiček).
6. VLIW=složitá instrukční slova?
Instrukční slovo rozdělené do polí sice může na první pohled vypadat složitě, skutečnost je ovšem taková, že mikroprocesor či dnes častěji DSP s architekturou VLIW je interně mnohem jednodušší (a tím pádem i levnější a současně i méně energeticky náročný), než superskalární mikroprocesor s architekturou RISC, vůbec již nemluvě o složitosti stejně výkonného superskalárního mikroprocesoru s architekturou CISC, což je taktéž jeden z důvodů, proč se dnešní mikroprocesory řady x86 sice navenek chovají jako procesory CISC, mají ovšem mnohdy RISCové jádro.
Musíme si navíc uvědomit, že rozdělení instrukčního slova do několika samostatně prováděných bitových polí je zásadně odlišné od pouhého spojení většího množství operací do jediné instrukce. Jeden z praktických rozdílů je ten, že se v každém poli (a tím pádem i v každé jednotce, která dané pole spouští) většinou omezuje počet a typ pracovních registrů, takže pro uložení indexů registrů do instrukce je (většinou) zapotřebí použít menší množství bitů, než je tomu například u klasických RISCových procesorů, v nichž se mnohdy jen pro uložení indexů registrů musí „obětovat“ patnáct bitů instrukčního slova.

Obrázek 8: Některé digitální signálové procesory TMS řady 320C6× jsou založené na architektuře VLIW. Právě těmito procesory se budeme zabývat v navazujících kapitolách.
7. Některá rizika spojená s mikroprocesory s architekturou VLIW
Ovšem právě ve zvoleném formátu instrukcí s pevně zadanými poli se skrývá největší potenciální problém celé architektury VLIW – skutečná výkonnost mikroprocesorů VLIW v praxi je totiž prakticky zcela závislá na překladači a jeho schopnostech při generování strojového kódu. Pokud se překladači nebude z různých důvodů dařit ukládat do instrukčního slova více paralelně spouštěných operací (tj. pole budou obsahovat většinou pouze instrukce NOP), popř. pokud bude nutné vkládat tytéž instrukce při čekání na dokončení operací, sníží se mnohdy velmi razantně reálný výpočetní výkon, což není pouze teoretická hrozba, neboť právě nedostatky překladačů způsobily u několika procesorů VLIW obchodní neúspěch (což ovšem není případ firmy TI). Názorným příkladem, jak „úspěšně“ zabít dobrý čip, může být mikroprocesor Intel 860, který sice nebyl po technologické stránce úplně špatný, ale překladače dostupné v době jeho uvedení na trh nedokázaly jeho předností využít, takže výpočetní výkon dosahovaný v reálných aplikacích zaostával za tvrzením výrobce (který samozřejmě měl prostředky na ruční optimalizaci syntetických výkonnostních benchmarků).

Obrázek 9: Mikroprocesor Intel i860.
Další nevýhodou mikroprocesorů s architekturou VLIW je to, že při každé změně interní struktury mikroprocesoru, například po přidání další pomocné aritmeticko-logické jednotky, je nutné provést nový překlad programů, což není u procesorů CISC a RISC (samozřejmě v případě, že náleží do stejné rodiny) nutné. Příkladem – a to současně dobrým i špatným – může být právě rodina x86 zaručující již po tři desetiletí zpětnou binární kompatibilitu. Dalším příkladem jsou některé rodiny RISCových procesorů, u nichž se postupně zvyšoval počet registrových oken, zaváděly se nové prediktory skoků a další technologie, ovšem původní programy mohly zůstat beze změny. Možná právě binární nekompatibilita mezi procesory VLIW (kterou už z principu nejde jednoduše obejít) způsobila, že tyto mikroprocesory najdeme spíše ve specializovaných zařízeních a nikoli například u desktopových počítačů.

Obrázek 10: Mikroprocesor Itanium je taktéž založen na architektuře VLIW (i když do značné míry modifikované). Z různých důvodů se tyto mikroprocesory nakonec neprosadily do takové míry, jak bylo plánováno nebo odhadováno – https://en.wikipedia.org/wiki/Itanium#/media/File:Itanium_Sales_Forecasts_edit.png
8. Porovnání architektur RISC, CISC a VLIW
V následující tabulce je pro ilustraci provedeno vzájemné porovnání některých vlastností mikroprocesorů s architekturami RISC, CISC a VLIW. Povšimněte si především poměrně velkého množství shodných vlastností mezi architekturami RISC a VLIW (to samozřejmě není náhoda, navrhnout funkční architekturu VLIW s CISC instrukcemi se neukázalo být tou správnou cestou):
| Charakteristika | Procesory CISC | Procesory RISC | Procesory VLIW |
|---|---|---|---|
| Interní struktura | mikrořadič | bez mikrořadiče | bez mikrořadiče |
| Počet pipeline | jedna (pro skalární CPU) | jedna (pro skalární CPU) | větší množství pipeline |
| Přístup do paměti | různé adresovací režimy | architektura Load&Store | architektura Load&Store |
| Délka instrukcí | proměnná (většinou od jednoho bajtu) | fixní, většinou 32bitů | fixní, desítky až stovky bitů |
| Formát instrukcí | proměnný | pouze několik formátů (ALU operace, skoky, Load&Store, načtení konstanty) | fixní |
| Složitost instrukcí | proměnná | jedna instrukce=jedna základní operace | více jednodušších, na sobě nezávislých operací |
| Počet registrů | relativně malé množství | větší množství (většinou alespoň 32) | větší množství |
| Funkce registrů | rozdělení pro: aritmetické operace, adresování, indexové registry… | obecné pracovní registry | obecné pracovní registry (někdy dělené do skupin) |
| Příklady CPU | Intel 8080 MOS 6502 Zilog Z80 Motorola 68k Intel 80386 Intel Pentium |
RISC I RISC II MIPS SPARC UltraSPARC PA-RISC |
TMS320C6× (DSP) SHARC (DSP) Itanium Transmeta Crusoe (interně) jádra ST200 (HP a STM) |
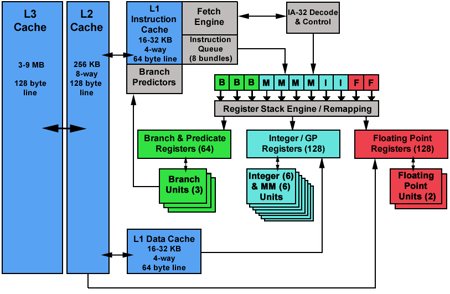
Obrázek 11: Interní struktura mikroprocesorů Itanium.
9. Rodina DSP čipů TI TMS320C6×
Rodina digitálních signálových procesorů TI TMS320C6× je poměrně rozsáhlá, protože v ní nalezneme čipy určené pro různé aplikační oblasti. Základní dělení je na čipy, které dokážou primárně zpracovávat celočíselná data popř. data s pevnou řádovou čárkou (fixed point), a na čipy, které naopak zpracovávají hodnoty s plovoucí řádovou čárkou (floating point). O jaké typy DSP se jedná, se dá poměrně jednoduše zjistit pohledem na číslo, které se nachází na devátém místě označení čipu. Prozatím se přidržíme původní rodiny TMS320 a nikoli složitějších integrovaných obvodů OMAP a DaVinci:
| Označení | Fixed point | Floating point | Poznámka |
|---|---|---|---|
| TMS320C62× | ✓ | × | základní model stručně popsaný níže |
| TMS320C67× | × | ✓ | na úrovni zdrojového kódu kompatibilní s prvním čipem |
| TMS320C64× | ✓ | × | na úrovni zdrojového kódu kompatibilní s prvním čipem |
| TMS320C67×+ | × | ✓ | vylepšení čipu TMS320C67× |
| TMS320C64×+ | ✓ | × | vylepšení čipu TMS320C64× |
| TMS320C674× | ✓ | ✓ | vznikl sloučením vlastností TMS320C64×+ a TMS320C67×+ |
| TMS320C66× | ✓ | ✓ | nová řada založená na TMS320C674× |
10. Čipy TMS320C62× – DSP pro operace s hodnotami s pevnou řádovou čárkou
Základními modely digitálních signálových procesorů TMS320 jsou čipy TMS320C62×. Tyto čipy byly navrženy a prodávány již na sklonku devadesátých let minulého století a postupně se ukázalo, že jejich VLIW architektura je z obchodního hlediska velmi úspěšná. I z tohoto důvodu se na DSP TMS320C62× navázalo dalšími modely, což bylo ostatně patrné i z tabulky uvedené v předchozí kapitole. Typickým znakem těchto DSP je jejich schopnost spustit v jednom cyklu až osm instrukcí, což je na hardwarové úrovni podpořeno existencí šesti aritmeticko-logických jednotek (s 32bitovými či 40bitovými výsledky) a dvou násobiček (se šestnáctibitovými operandy a 32bitovými výsledky). Právě na základě těchto vlastností se uvádí teoretická výpočetní výkonnost těchto DSP: 2400 MIPS pro čip s hodinovým signálem 300 MHz (2400=300×8), resp. 2000 MIPS pro čip s hodinovým signálem 250 MHz (později pochopitelně došlo ke zvýšení hodinové frekvence společně s přechodem na novou výrobní technologii). Kromě ALU a násobiček procesorové jádro obsahuje i 32 pracovních registrů, přičemž do každého registru je možné uložit slovo o šířce třiceti dvou bitů.
Jména čipů jsou složena z několika částí, například:
| TMS | 320 | C | 6201 | GLS | A | 300 |
|---|---|---|---|---|---|---|
| TMX=experimentální | rodina | technologie | zařízení | pouzdro | teplota | frekvence |
| TMP=prototyp | (nic=NMOS) | 6201 | GFN=BGA s 256 piny | A=-40..105 | 100 MHz min | |
| TMS=komerční | C=CMOS | 6202 | GLS=BGA s 384 piny | nic=0..90 | 600 MHz | |
| SMJ=military | M=interní ROM | atd. | GLZ=BGA s 532 piny | atd. |

Obrázek 12: Interní struktura digitálních signálových procesorů TMS řady 320C64× (tyto čipy mají větší množství pracovních registrů v porovnání s 320C62×).
11. Interní struktura TMS320C62×
Celý procesor je rozdělený na dvě části pojmenované datapath A a datapath B. Každá z těchto částí obsahuje sadu pracovních registrů (konkrétně je v každé sadě umístěno šestnáct 32bitových registrů, celkem tedy již zmíněných 32 registrů) a čtyři výkonné jednotky (.L1, .S1, .M1, .D1 pro část A a .L2, .S2, .M2, .D2 pro část B):
+-----------------+-----------------+ | Registry Ax | Registry Bx | +-----------------+-----------------+ ⇅ ⇅ ⇅ ⇅ ⇅ ⇅ ⇅ ⇅ +---+---+---+---+ +---+---+---+---+ |.L1|.S1|.M1|.D1| |.D2|.M2|.S2|.L2| +---+---+---+---+ +---+---+---+---+
Funkci různých typů jednotek shrnuje následující tabulka:
| Jednotka | Funkce |
|---|---|
| .Lx | ALU pro operandy šířky 32 bitů či 40 bitů |
| .Sx | 32bitová ALU + shiftery pro operandy šířky 32 bitů či 40 bitů, skoky |
| .Mx | násobička 16×16bitů nebo 8×8 bitů, též MAC operace atd. |
| .Dx | jednodušší ALU (součet, rozdíl), datové přenosy, výpočty adres (offsety) apod. |
Pokud se používají operandy o šířce 40 bitů, je nutné použít registrový pár (dvojici sousedních pracovních registrů), přičemž u druhého registru má význam jen spodních osm bitů.
Všechny jednotky provádějící výpočty, tj. jednotky .L, .S a .M, jako své vstupní operandy vždy používají pracovní registry. O načítání dat do registrů popř. pro ukládání dat zpět do operační paměti se starají jednotky .D; z tohoto pohledu se jedná o myšlenku rozpracovanou v RISCových procesorech.
Poznámka: z funkcí jednotek vyplývají i jejich názvy: L – long integers, S – short integers či shifter, M – multiply, D – data.

12. Přenosy dat mezi částmi A a B
Každá z jednotek v části A může pro svůj vstupní operand (či operandy) použít libovolný registr A0 až A15; to samé samozřejmě platí pro část B a registry B0 až B15. Mohlo by se tedy zdát, že každá část je zcela samostatná a oddělená od části druhé; ve skutečnosti je však v reálných aplikacích nutné, aby bylo možné data mezi oběma částmi přenášet. To pro adresy zabezpečují jednotky .D1 a .D2, které pomocí volitelného přepínače dokážou uložit výsledná data do vybraného registru z druhé jednotky (za to ovšem zaplatíme pozdržením přenosu o jeden hodinový cyklus). Navíc je možné vždy u vybrané jednotky .Lx, .Sx či .Mx zvolit, že druhý operand bude vybrán z opačné části. To zajišťují dva jednosměrné komunikační kanály nazvané crosspath(s) a označované 1X a 2X (ovšem je nutné si uvědomit, že takto lze zvolit „cizí“ operand jen u jediné jednotky, navíc se vždy může přenést obsah jednoho registru, nikoli registrového páru). Zjednodušeně lze tok dat od vstupních operandů k operandům výstupním naznačit takto (už je asi zřejmé, proč mám u části B jednotky uvedeny v opačném pořadí):
+------------------+------------------+ | Registry Ax | Registry Bx | | 2x|1x | +------------------+------------------+ (1x)(1x)(1x) (2x)(2x)(2x) ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ +---+---+---+---+ +---+---+---+---+ |.L1|.S1|.M1|.D1| |.D2|.M2|.S2|.L2| +---+---+---+---+ +---+---+---+---+ ↓ ↓ ↓ ↓ ↘ ↙ ↓ ↓ ↓ ↓ +------------------+------------------+ | Registry Ax | Registry Bx | +------------------+------------------+
13. VLIW instrukce
Všechna instrukční slova mají šířku 256 bitů (ano, skutečně VLIW) a jsou načítány z adresy dělitelné 32. Celý 256bitový vektor instrukčního slova je rozdělen na osm částí, z nichž každá má šířku 32 bitů. Každá z těchto částí může tvořit instrukci pro vybranou výkonnou jednotku (L1, S1, M1, D1, L2, S2, M2, D2), přičemž samozřejmě je možné každé jednotce předat jedinou instrukci. Pokud se překladači nepodaří rozdělit úkoly všem jednotkám (což je velmi pravděpodobné, tedy kromě syntetických testů), může se použít instrukce NOP, což ale samozřejmě vede ke snížení čistého výpočetního výkonu. V některých případech je navíc nutné určit, že se instrukce nemají spustit paralelně, ale má se naopak čekat na dokončení předchozí instrukce. K tomu slouží p-bity (nejnižší bity každé instrukce), které určují, zda se mají instrukce paralelizovat či naopak vykonat sériově (popř. některé instrukce paralelizovat a jiné nikoli). Povšimněte si, že i toto chování plně řídí překladač, protože samotný čip neobsahuje logiku pro detekci kolizí při čtení či zápisu do pracovních registrů. Podrobnější informace o instrukčním souboru si řekneme příště.
14. Odkazy na Internetu
- VLIW: Very Long Instruction Word: Texas Instruments TMS320C6×
http://www.ecs.umass.edu/ece/koren/architecture/VLIW/2/ti1.html - An Introduction To Very-Long Instruction Word (VLIW) Computer Architecture
Philips Semiconductors - VLIW Architectures for DSP: A Two-Part Lecture (PDF, slajdy)
http://www.bdti.com/MyBDTI/pubs/vliw_icspat99.pdf - Very long instruction word (Wikipedia)
https://en.wikipedia.org/wiki/Very_long_instruction_word - A VLIW Approach to Architecture, Compilers and Tools
http://www.vliw.org/book/ - VEX Toolchain (VEX = VLIW Example)
http://www.hpl.hp.com/downloads/vex/ - Použití assembleru v Linuxu: RISCová architektura AArch64
https://mojefedora.cz/pouziti-assembleru-v-linuxu-riscova-architektura-aarch64/ - Použití assembleru v Linuxu: RISCová architektura AArch64 (programové smyčky)
https://mojefedora.cz/pouziti-assembleru-v-linuxu-riscova-architektura-aarch64-programove-smycky/ - Elbrus (computer)
https://en.wikipedia.org/wiki/Elbrus_%28computer%29 - Super Harvard Architecture Single-Chip Computer
https://en.wikipedia.org/wiki/Super_Harvard_Architecture_Single-Chip_Computer - Digital Signal Processors (stránky TI)
http://www.ti.com/lsds/ti/processors/dsp/overview.page - Introduction to DSP
http://www.ti.com/lit/wp/spry281/spry281.pdf - The Evolution of TMS (Family of DSPs)
http://www.slideshare.net/moto_modx/theevo1 - Datasheet k TMS32010
http://www.datasheetarchive.com/dlmain/49326c32a52050140abffe6f0ac4894aa09889/M/TMS32010 - 1979: Single Chip Digital Signal Processor Introduced
http://www.computerhistory.org/siliconengine/single-chip-digital-signal-processor-introduced/ - The TMS32010. The DSP chip that changed the destiny of a semiconductor giant
http://www.tihaa.org/historian/TMS32010–12.pdf - Texas Instruments TMS320 (Wikipedia)
https://en.wikipedia.org/wiki/Texas_Instruments_TMS320 - Great Microprocessors of the Past and Present: Part IX: Signetics 8×300, Early cambrian DSP ancestor (1978):
http://www.cpushack.com/CPU/cpu2.html#Sec2Part9 - Great Microprocessors of the Past and Present (V 13.4.0)
http://jbayko.sasktelwebsite.net/cpu.html - Introduction to DSP – DSP processors:
http://www.bores.com/courses/intro/chips/index.htm - The Scientist and Engineer's Guide to Digital Signal Processing:
http://www.dspguide.com/ - Digital signal processor (Wikipedia EN)
http://en.wikipedia.org/wiki/Digital_signal_processor - Digitální signálový procesor (Wikipedia CZ)
http://cs.wikipedia.org/wiki/Digitální_signálový_procesor - Digital Signal Processing FAQs
http://dspguru.com/dsp/faqs - Reprezentace numerických hodnot ve formátech FX a FP
http://www.root.cz/clanky/fixed-point-arithmetic/ - IEEE 754 a její příbuzenstvo: FP formáty
http://www.root.cz/clanky/norma-ieee-754-a-pribuzni-formaty-plovouci-radove-tecky/ - Čtyři základní způsoby uložení čísel pomocí FX formátů
http://www.root.cz/clanky/binarni-reprezentace-numerickych-hodnot-v-fx-formatu/ - Základní aritmetické operace prováděné v FX formátu
http://www.root.cz/clanky/zakladni-aritmeticke-operace-provadene-ve-formatu-fx/ - Aritmetické operace s hodnotami uloženými ve formátu FP
http://www.root.cz/clanky/aritmeticke-operace-s-hodnotami-ve-formatu-plovouci-radove-carky/ - FIR Filter FAQ
http://dspguru.com/dsp/faqs/fir - Finite impulse response (Wikipedia)
http://en.wikipedia.org/wiki/Finite_impulse_response - DSPRelated
http://www.dsprelated.com/ - Addressing mode (Wikipedia)
https://en.wikipedia.org/wiki/Addressing_mode - Orthogonal instruction set
https://en.wikipedia.org/wiki/Orthogonal_instruction_set - TI 16-bit and 32-bit microcontrollers
http://www.ti.com/lsds/ti/microcontrollers16-bit32-bit/overview.page - TMS 32010 Assembly Language Programmer's Guide (kniha na Amazonu)
https://www.amazon.com/32010-Assembly-Language-Programmers-Guide/dp/0904047423 - COSC2425: PC Architecture and Machine Language, PC Assembly Language
http://www.austincc.edu/rblack/courses/COSC2425/index.html




































{kind=link}