
Úvod
Neocognitron se často používá (mimo jiného) pro rozpoznávání ručně psaných znaků či číslic, kde dosahuje velice kvalitních výsledků. Existuje samozřejmé i mnoho jiných metod, ale protože každý člověk píše trochu jinak, většina z nich vyžaduje k učení mnoho vzorků a tyto metody jsou málo odolné vůči šumu. Naproti tomu neocognitron se může dobře naučit i z pouhého jednoho vzorku a navíc chybovost i v případě velkého šumu je nízká. Další výhodou je, že rozpoznávaný tvar nemusí mít stejnou velikost ani pozici v obrázku a může být i částečné zdeformován a stále neocognitronová síť bude schopna správně rozpoznávat.


Připomeňme si pár věcí z gestalt psychologie a vnímání tvarů. Podívejte se na obrázek níže. Bez velké náročnosti a dlouhého přemýšlení je člověk schopen okamžitě vidět dva překřížené trojúhelníky, čtverce a kružnice i přesto že tyto tvary tam defakto nejsou. Lidské oko má úžasnou schopnost vnímat a doplňovat tvary a hranice.

Mezi gestalt zákony patří:
- Zákon blízkosti – tendence vnímat podobné objekty jako skupiny nebo série
- Zákon podobnosti – smíšené skupiny podobných a odlišných objektů vidíme po skupinách
- Zákon pokračování/směru – v obrazcích hledáme čáry s nepřerušeným pokračováním
- Zákon výstižnosti (Prägnanz) – tendence vidět nejjednodušší tvar
- Zákon dobrého tvaru – tendence doplňovat obrazce
- Vnímání figury a pozadí – schopnost mysli zaměřit pozornost na smysluplný tvar a ignorovat zbytek
- Konstantnost velikosti – schopnost vnímání perspektivy
Neocognitronové sítě se dokážou z části s uvedenými věcmi vypořádat a v tom je jejich obrovská výhoda v porovnání s jinými metodami.

Bilogogické procesy

Na obrázku výše je znázorněna sítnice oka a buněk v ní. Světlo se pohybuje zleva doprava k fotoreceptorům (zajímavé je, že sítnice je napojena „opačně“, tedy světlo musí nejprve projít namačkanými „dráty“ než dosáhne citlivých fotobuněk).
Od fotoreceptorů se signál šíří k horizontálním a bipolárním buňkám a poté k buňkám amacrine a ganglionům. Již na sítnici tak dochází k předzpracování signálu a výsledkem tohoto předzpracování je právě analogie k detekci hran. Detekcí hran dojde k extrakci relevantních informací ale zároveň i k určité kompresi – přenáší se pouze relevantní informace o hranách nikoliv informace o jednobarevné ploše, kde se nic neděje – což je potřeba neboť přenášet lze pouze omezené množství informace. To ovšem není překvapivé, vnímat velkou prázdnou plochu, kde je málo hran, jako celek je jednoduché, ale vnímat něco pestrého (např. mapu) jako celek nelze, můžeme se soustředit pouze na určitou část v určitém měřítku.
Z fotoreceptorů se signál šíří do gangliových buněk přes bipolární a horizontální buňky – ty slouží k přenosu informace a částečnému předzpracování např. zlepšení kontrastu.
Gangliové buňky potom detekují hrany v obraze. Gangliové buňky se dají rozdělit na dva typy – tzv. „on center“ a „off center“, liší se rozdílným způsobem reakce.
Buňky „On center“ vysílají signál v případě, že se detekuje světlé místo obklopené tmavým okrajem. Buňky „Off center“ detekují opačnou situaci, když tmavé místo je obklopene světlým okrajem. Jednotlivé možnosti ukazuje obrázek níže.

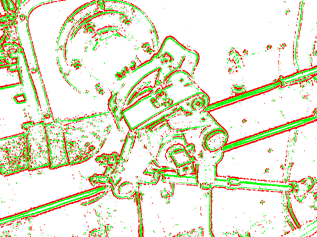
Na dalším obrázku můžeme vidět simulaci, kde jsou znázorněny signály od obojích typů buněk („on center“ červené a „off center“ zelené).
Další významnou úlohu hrají tzv. jednoduché, komplexní buňky a komplexní buňky s inhibicí v zrakovém centru mozku, které umožňují detekovat jednoduché i složitější tvary. Jednoduché buňky detekují rovné hrany v konkrétním místě a s konkrétní orientací. Komplexní buňky spojují tyto jednoduché buňky a reagují v případě, že je některá z těchto jednoduchých buněk aktivní. Představme si situaci, že několik jednoduchých buňek detekuje určitý tvar v různých místech v obraze. Komplexní buňka, která je spojuje tak bude detekovat tento tvar v libovolném z těchto míst v obraze (to by se dalo přirovnat k jakémusi rozmazání obrazu).

Klikněte si pro animaci
Na dalším obrázku můžeme vidět, jakým způsobem se obraz zpracovává v různých částech mozku.

Matematický model

Síť neocognitron se skládá z několika za sebou zapojených vrstev. Každá vrstva obsahuje plochy, každá plocha se skládá z buněk. Vrstvy jsou trojího typu: S-vrtvy, C-vrstvy a V-vrstvy. S-vrstvy (na obrázku označené jako US) napodobují funkci jednoduchých neuronů, C-vrstvy (na obrázku označené jako UC) komplexních neuronů. V-vrstvy (na obrázku označené jako UV) byly přidány do modelu později a působí inhibičně, pro lepší rozlišení kontrastu.
Každá za sebou následující Si-vrstva a Ci-vrstva se skládájí ze stejného počtu ploch. Každá za sebou následující Ci-vrstva a S(i+1)-vrstva mají stejné počty neuronů v plochách (mají plochy o stejných velikostech). V-vrstva má plochu pouze jednu. Vrstva UG obsahuje dvě plochy a provádí detekci hran (podobně jako gangliové neurony) podle výše popsaného způsobu „on center“ a „off center“.
Po detekci hran ve vrstvě UG se signál šíří do vrstvy US1. Každá plocha vrstvy US1 umí detekovat hranu určitého rozměru a určité orientace. Ty neurony, které přítomnost této určité hrany na svém místě detekují vyšlou signál. Výstupem každé plochy vrstvy US1 je tak mapa výskytu určitého tvaru v obrázku.
Tento signál se šíří do vrstvy UC1, která má stejný počet ploch jako vrstva US1 a vzájemně jsou propojeny pouze si odpovídající dvojice ploch. Vrstva UC1 provede v podstatě rozmazání signálu na plochách ve vrstvě US1. Tím je zajištěno, že pro správné rozpoznání výskyt daného tvaru nemusí být pouze na konkrétním místě, ale v určitém okolí.
Zpracování pokračuje podobným způsobem dále. Vrstva US2 detekuje na předchozí vrstvě UC1 tvary a vrstva UC2 provádí rozmazání, aby klasifikace nebyla vázána pouze s konkrétním výskytem detekovaného tvaru.
Poslední vrstva UC4 se skládá z tolika ploch, kolik je různých tvarů, které chceme klasifikovat a každá plocha se skládá z jediné buňky. Vyšle-li tato buňka signál, znamená to, že odpovídající tvar byl detekován.
V každé následující úrovni se detekuje složitější útvar až v poslední vrstvě se detekuje celý obrazec.

Různé plochy na obrázku výše odpovídají plochám v S-vrstvách. Každá plocha S-vrstvy detekuje určitý tvar. Na obrázku níže je zase znázorněna funkce C-vrstev, kde pozice detekovaných tvarů jsou rozmazávany do určitého okolí. Tím je docíleno toho, že se správně rozpozná tvar, i když jsou detekované hrany posunuty či mírně deformovány.

Na dalším obrázku vidíme, jakým způsobem jsou jednotlivé plochy mezi vrstvami vzájemně propojeny. Buňka vyšší vrstvy je napojena na buňky nižší vrstvy ve stejném místě v obraze. Každé propojení má nastavenou určitou váhu. Síť se učí tím, že nastavuje tyto váhy. V neocognitronové síti je několik typů váh: a, b, c, d. Kde se tyto váhy uplatňují je vidět na dalším obrázku.



Nakonec si uvedeme vztahy, které vyjadřují výstupy neuronů ve vrstvách S, C a V označené jako us, uc, uv. Symbolem us-1 je označen výstup předchozí S-vrstvy. Parametr θ vyjadřuje práh a symboly a, b, c, d vyjadřují váhy. Ve všech vztazích se sčítá přes parametr i, který iteruje přes všechny napojené buňky v daném okolí. Někdy se lze setkat i s jinými vztahy.

Neocognitron v akci
Příště
V dalším díle se seznámíme s algoritmy inspirované mravenčími koloniemi.






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU