
Obsah
1. Calysto Hy: integrace programovacího jazyka Hy s Jupyter Notebookem
3. Instalace Jupyter Notebooku
4. Instalace projektu Calysto Hy
5. Registrace nového kernelu do Jupyter Notebooku a spuštění Jupyter Notebooku
6. Základní datové typy jazyka Hy
7. Zpracování kolekcí – vektorů a slovníků – v jazyku Hy
8. Funkce a makra určená pro práci se slovníky
9. Volání funkcí a metod definovaných v Pythonu
11. Volání funkcí definovaných v jazyku Hy z Pythonu
12. Makrosystém programovacího jazyka Hy
13. Využití eval, homoikonicita jazyků
14. Makra „quote“ a „syntax-quote“
15. Praktické použití – jednoduchá makra vytvořená v jazyku Hy
16. Spuštění samotného interpretru jazyka Hy a práce s interaktivní smyčkou REPL
17. Dodatek: Dostupné kernely pro Jupyter Notebook
18. Předchozí články o Jupyter Notebooku
19. Repositář s demonstračními příklady
1. Calysto Hy: integrace programovacího jazyka Hy s Jupyter Notebookem
V dnešním článku si ukážeme, jakým způsobem je možné zajistit integraci programovacího jazyka Hy (což je homoikonický jazyk odvozený od Lispu a běžící ve virtuálním stroji Pythonu) s Jupyter Notebookem. Jedná se tedy o pokračování článků, v nichž jsme si představili propojení Jupyter Notebooku s programovacím jazykem R, Go a v neposlední řadě taktéž s jazykem Clojure.

Obrázek 1: Logo programovacího jazyka Hy.
Čtenář si zajisté může položit otázku, proč by vlastně měl jazyk Hy vyzkoušet a jaké nové či lepší vlastnosti mu přinese. Pravděpodobně největším přínosem je – podobně jako v dalších lispovských jazycích – homoikonocita umožňující metaprogramování. Dalším přínosem je snadnější manipulace se symboly. Nesmíme ale zapomenout ani na další vlastnosti jazyka Hy, například na možnost práce se zlomky (fraction) namísto výpočtů s numerickými hodnotami reprezentovanými podle IEEE 754 (v Pythonu konkrétně s double, v knihovně NumPy pak i s dalšími typy, a to včetně typu half). Výpočty se zlomky jsou sice pomalejší, neboť pro normalizaci výsledků se používá softwarové řešení a nikoli možnosti poskytované matematickým koprocesorem, ovšem mnoho nepříjemných vlastností typů s plovoucí řádovou čárkou se zde neobjevuje (například je možné přesně pracovat s desetinnými hodnotami atd.). Určitou nevýhodu představuje fakt, že nelze reprezentovat například 1/0 (tedy nekonečno) nebo 0/0.

Obrázek 2: Logo projektu Jupyter Notebook.

Obrázek 3: Logo známé knihovny NumPy.
2. Programovací jazyk Hy
Programovací jazyk Hy je ve velké míře inspirován (poměrně populárním) jazykem Clojure, s nímž jsme se na stránkách Roota již mnohokrát setkali v samostatném seriálu. Ovšem zatímco interpret programovacího jazyka Clojure překládá všechny zapsané výrazy (resp. přesněji řečeno formy) do bajtkódu JVM a teprve poté je spouští, pracuje jazyk Hy odlišně, protože kód generuje s využitím AST a dokonce dokáže zdrojový LISPovský kód transformovat do Pythonu a teprve poté ho spustit (takže se vlastně jedná o transpiler). To je výhodná vlastnost, protože umožňuje Hy poměrně snadno integrovat například s debuggery atd. Překlad přes AST nebo Python podporuje jak Python 2.x, tak i Python 3.x. Další důležitou vlastností Hy je možnost plné kooperace mezi kódem zapsaným přímo v tomto jazyku a Pythoním kódem, což znamená, že je možné použít všechny pythonovské knihovny a frameworky (včetně Numpy, PyTorch, Flask atd.) a naopak – například mít napsanou aplikaci v Pythonu a pro manipulaci se symboly použít Hy (v tomto ohledu jsou homoikonické programovací jazyky s podporou maker a ideálně i neměnitelných datových struktur podle mého názoru mnohem lepší, než samotný Python).
A právě možnost použít jazyk Hy společně s naprostou většinou balíčků programovacího jazyka Python umožnila integraci jazyka Hy do projektu Jupyter Notebook.
Fakt, že různé dialekty jazyků LISP a Scheme vznikají pro prakticky všechny moderní virtuální stroje (typicky pro JVM, VM JavaScriptu nebo VM Pythonu) vlastně není nic překvapivého. Musíme si totiž uvědomit, že praktická použitelnost programovacího jazyka je do značné míry určena i celým ekosystémem, který je programátorům k dispozici. A ekosystém Pythonu je dnes již velmi rozsáhlý a obsahuje kvalitní a v celém světě používané knihovny i celé frameworky, takže se může jednat o vhodný základ, na němž je možné postavit moderní varianty LISPu či Scheme. Podobným způsobem ostatně vznikl i programovací jazyk Clojure (což je taktéž dialekt LISPu, i když v mnoha ohledech vylepšený a navíc od běžných Lispů odlišný), který vlastně vůbec nemá svůj vlastní virtuální stroj – původně Clojure vzniklo pro virtuální stroj Javy (JVM), další varianty posléze byly implementovány pro CLR (ClojureCLR) a ClojureScript, který je kompilovaný do JavaScriptu, takže může běžet buď v prohlížeči, v Node.js atd.
Pro virtuální stroj Pythonu je v současnosti k dispozici hned několik dialektů LISPu, Scheme či Clojure. Jedná se například o méně známé projekty Lizpop, Lispy či Lython, dále o SchemePy (ten mimochodem tvoří základ pro integraci Scheme s Jupyter Notebookem – o tom však až jindy), Clojure-py o němž se zmíníme v dalším textu a především velmi zajímavým způsobem implementovaný programovací jazyk Hy, kterému je věnována větší část dnešního článku. Do této kategorie částečně spadá i jazyk Pixie, s nímž jsme se již na stránkách Roota ve stručnosti seznámili.
3. Instalace Jupyter Notebooku
S programovacím jazykem Hy se pochopitelně seznámíme prakticky a využijeme přitom interaktivní prostředí Jupyter Notebooku. To je možné nainstalovat hned několika způsoby, podle toho, zda se využijí balíčky dostupné přímo v repositáři dané linuxové distribuce nebo se použijí jiní správci balíčků (typicky conda nebo pip). Prakticky všechny oficiálně podporované postupy instalace jsou zmíněny v diagramu umístěném na stránce https://jupyter.readthedocs.io/en/latest/projects/content-projects.html.
Ve Fedoře (27 a výše) lze instalaci provést příkazem:
$ sudo dnf install python3-notebook
Instalace na Linux Mintu a dalších distribucích odvozených od Ubuntu nebo Debianu:
$ sudo apt-get install python3-notebook
Samozřejmě se nainstaluje i velká řada podpůrných balíčků:
Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: fonts-font-awesome fonts-glyphicons-halflings javascript-common jupyter-core jupyter-nbextension-jupyter-js-widgets jupyter-notebook libjs-backbone libjs-bootstrap libjs-bootstrap-tour libjs-codemirror libjs-es6-promise libjs-jed libjs-jquery libjs-jquery-typeahead libjs-jquery-ui libjs-marked libjs-moment libjs-requirejs libjs-requirejs-text libjs-text-encoding libjs-underscore libjs-xterm pandoc pandoc-data python3-attr python3-bleach python3-dateutil python3-defusedxml python3-html5lib python3-importlib-metadata python3-ipykernel python3-ipywidgets python3-jinja2 python3-jsonschema python3-jupyter-client python3-jupyter-core python3-mistune python3-more-itertools python3-nbconvert python3-nbformat python3-pandocfilters python3-prometheus-client python3-pyrsistent python3-send2trash python3-terminado python3-testpath python3-tornado python3-webencodings python3-widgetsnbextension python3-zipp python3-zmq Suggested packages: apache2 | lighttpd | httpd libjs-jquery-lazyload libjs-json libjs-jquery-ui-docs texlive-latex-recommended texlive-xetex texlive-luatex pandoc-citeproc texlive-latex-extra context wkhtmltopdf librsvg2-bin groff ghc nodejs php python ruby r-base-core node-katex python-attr-doc python-bleach-doc python3-genshi python3-lxml python-ipywidgets-doc python-jinja2-doc python-jsonschema-doc python-nbconvert-doc python-notebook-doc python-tornado-doc python3-twisted The following NEW packages will be installed: fonts-font-awesome fonts-glyphicons-halflings javascript-common jupyter-core jupyter-nbextension-jupyter-js-widgets jupyter-notebook libjs-backbone libjs-bootstrap libjs-bootstrap-tour libjs-codemirror libjs-es6-promise libjs-jed libjs-jquery libjs-jquery-typeahead libjs-jquery-ui libjs-marked libjs-moment libjs-requirejs libjs-requirejs-text libjs-text-encoding libjs-underscore libjs-xterm pandoc pandoc-data python3-attr python3-bleach python3-dateutil python3-defusedxml python3-html5lib python3-importlib-metadata python3-ipykernel python3-ipywidgets python3-jinja2 python3-jsonschema python3-jupyter-client python3-jupyter-core python3-mistune python3-more-itertools python3-nbconvert python3-nbformat python3-notebook python3-pandocfilters python3-prometheus-client python3-pyrsistent python3-send2trash python3-terminado python3-testpath python3-tornado python3-webencodings python3-widgetsnbextension python3-zipp python3-zmq 0 upgraded, 52 newly installed, 0 to remove and 424 not upgraded. Need to get 21,1 MB of archives. After this operation, 165 MB of additional disk space will be used. Do you want to continue? [Y/n]
Využít je možné i výše zmíněného správce balíčků Conda. V případě, že tento nástroj používáte, bude instalace vypadat následovně:
$ conda install -c conda-forge notebook
A konečně lze použít i klasický pip nebo pip3 (v závislosti na tom, jaký je stav Pythonu 3 na daném operačním systému):
$ pip install notebook
V případě, že pip instaluje balíčky pro Python 2 a nikoli pro Python 3, použijeme:
$ pip3 install notebook
Použít je možné i spuštění v kontejneru. Konkrétně pro Docker je k dispozici hned několik obrazů Jupyter Notebooku, každý s rozdílnými kernely a dalšími moduly. Viz https://hub.docker.com/u/jupyter/#!.
4. Instalace projektu Calysto Hy
Po instalaci Jupyter Notebooku provedeného v rámci předchozí kapitoly nainstalujeme projekt Calysto Hy, který zajišťuje integraci jazyka Hy právě s Jupyter Notebookem. Pro zajímavost provedeme instalaci v rámci virtuálního prostředí Pythonu zajištěného známým nástrojem Virtualenv. Pochopitelně lze provést i instalaci pro celý operační systém, popř. pro aktuálně přihlášeného uživatele, ale pro testování a rozšiřování Jupyter Notebooku může být použití virtuálního prostředí bezpečnější (jednoduchým přepínáním mezi virtuálními prostředími lze omezit či změnit počet dostupných kernelů atd.).
Nejprve vytvoříme adresář, který bude obsahovat nástroje a balíčky nainstalované v rámci virtuálního prostředí:
$ python3 -m venv calysto_hy
Dále virtuální prostředí aktivujeme:
$ source calysto_hy/bin/activate
To by se mělo projevit úpravou výzvy (prompt):
(calysto_hy) bash-4.4$
Dalším krokem je instalace balíčku Jedhy, jenž zajišťuje automatické doplňování kódu, prohlížení dokumentace atd. pro jazyk Hy:
(calysto_hy) bash-4.4$ pip3 install git+https://github.com/ekaschalk/jedhy.git
Collecting git+https://github.com/ekaschalk/jedhy.git
Cloning https://github.com/ekaschalk/jedhy.git to /tmp/ramdisk/pip-27q_yyiv-build
Collecting toolz (from jedhy==1)
Downloading https://files.pythonhosted.org/packages/12/f5/537e55f8ba664ff2a26f26913010fb0fcb98b6bbadc6158af888184fd0b7/toolz-0.11.1-py3-none-any.whl (55kB)
Installing collected packages: toolz, jedhy
Running setup.py install for jedhy: started
Running setup.py install for jedhy: finished with status 'done'
Successfully installed jedhy-1 toolz-0.11.1
You are using pip version 9.0.3, however version 21.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
Podobně nainstalujeme samotný balíček Calysto Hy:
(calysto_hy) bash-4.4$ pip3 install git+https://github.com/Calysto/calysto_hy.git
Collecting git+https://github.com/Calysto/calysto_hy.git
Cloning https://github.com/Calysto/calysto_hy.git to /tmp/ramdisk/pip-rvdrr46p-build
Collecting metakernel (from calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/a4/3f/b4db994950bb1443228f097be3c0827f106641a18f0243f37bc1bd747a0a/metakernel-0.27.5-py2.py3-none-any.whl (208kB)
Collecting hy (from calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/42/5b/2a6930c12112b1e773e1c97d9c6cad9bf4b448d31daab53654b7ff2481cc/hy-0.20.0-py2.py3-none-any.whl (83kB)
Requirement already satisfied: toolz in ./calysto_hy/lib/python3.6/site-packages (from calysto-hy==0.1.1)
Collecting ipykernel (from metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/56/95/3a670c8b2c2370bd8631c313f42e60983b3113ffec4035940592252bd6d5/ipykernel-5.5.0-py3-none-any.whl (120kB)
Collecting pexpect>=4.2 (from metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/39/7b/88dbb785881c28a102619d46423cb853b46dbccc70d3ac362d99773a78ce/pexpect-4.8.0-py2.py3-none-any.whl (59kB)
Collecting astor>=0.8 (from hy->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/c3/88/97eef84f48fa04fbd6750e62dcceafba6c63c81b7ac1420856c8dcc0a3f9/astor-0.8.1-py2.py3-none-any.whl
Collecting rply>=0.7.7 (from hy->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/c0/7c/f66be9e75485ae6901ae77d8bdbc3c0e99ca748ab927b3e18205759bde09/rply-0.7.8-py2.py3-none-any.whl
Collecting funcparserlib>=0.3.6 (from hy->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/cb/f7/b4a59c3ccf67c0082546eaeb454da1a6610e924d2e7a2a21f337ecae7b40/funcparserlib-0.3.6.tar.gz
Collecting colorama (from hy->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/44/98/5b86278fbbf250d239ae0ecb724f8572af1c91f4a11edf4d36a206189440/colorama-0.4.4-py2.py3-none-any.whl
Collecting ipython>=5.0.0 (from ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/23/6a/210816c943c9aeeb29e4e18a298f14bf0e118fe222a23e13bfcc2d41b0a4/ipython-7.16.1-py3-none-any.whl (785kB)
Collecting traitlets>=4.1.0 (from ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/ca/ab/872a23e29cec3cf2594af7e857f18b687ad21039c1f9b922fac5b9b142d5/traitlets-4.3.3-py2.py3-none-any.whl (75kB)
Collecting jupyter-client (from ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/77/e8/c3cf72a32a697256608d5fa96360c431adec6e1c6709ba7f13f99ff5ee04/jupyter_client-6.1.12-py3-none-any.whl (112kB)
Collecting tornado>=4.2 (from ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/01/d1/8750ad20cbcefb499bb8b405e243f83c2c89f78d139e6f8c8d800640f554/tornado-6.1-cp36-cp36m-manylinux1_x86_64.whl (427kB)
Collecting ptyprocess>=0.5 (from pexpect>=4.2->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/22/a6/858897256d0deac81a172289110f31629fc4cee19b6f01283303e18c8db3/ptyprocess-0.7.0-py2.py3-none-any.whl
Collecting appdirs (from rply>=0.7.7->hy->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/3b/00/2344469e2084fb287c2e0b57b72910309874c3245463acd6cf5e3db69324/appdirs-1.4.4-py2.py3-none-any.whl
Collecting backcall (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/4c/1c/ff6546b6c12603d8dd1070aa3c3d273ad4c07f5771689a7b69a550e8c951/backcall-0.2.0-py2.py3-none-any.whl
Collecting prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0 (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/ce/ee/08ceeb759c570bf96b4c636582ebf18c14c3c844a601b2e77b17f462aa6b/prompt_toolkit-3.0.17-py3-none-any.whl (367kB)
Requirement already satisfied: setuptools>=18.5 in ./calysto_hy/lib/python3.6/site-packages (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Collecting decorator (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/ed/1b/72a1821152d07cf1d8b6fce298aeb06a7eb90f4d6d41acec9861e7cc6df0/decorator-4.4.2-py2.py3-none-any.whl
Collecting pygments (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/3a/80/a52c0a7c5939737c6dca75a831e89658ecb6f590fb7752ac777d221937b9/Pygments-2.8.1-py3-none-any.whl (983kB)
Collecting pickleshare (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/9a/41/220f49aaea88bc6fa6cba8d05ecf24676326156c23b991e80b3f2fc24c77/pickleshare-0.7.5-py2.py3-none-any.whl
Collecting jedi>=0.10 (from ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/f9/36/7aa67ae2663025b49e8426ead0bad983fee1b73f472536e9790655da0277/jedi-0.18.0-py2.py3-none-any.whl (1.4MB)
Collecting six (from traitlets>=4.1.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/ee/ff/48bde5c0f013094d729fe4b0316ba2a24774b3ff1c52d924a8a4cb04078a/six-1.15.0-py2.py3-none-any.whl
Collecting ipython-genutils (from traitlets>=4.1.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/fa/bc/9bd3b5c2b4774d5f33b2d544f1460be9df7df2fe42f352135381c347c69a/ipython_genutils-0.2.0-py2.py3-none-any.whl
Collecting jupyter-core>=4.6.0 (from jupyter-client->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/53/40/5af36bffa0af3ac71d3a6fc6709de10e4f6ff7c01745b8bc4715372189c9/jupyter_core-4.7.1-py3-none-any.whl (82kB)
Collecting pyzmq>=13 (from jupyter-client->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/7c/8f/e83fc0060a7626d3555b971a70a37a0d57f727ec7ec860e9aadf96fdd724/pyzmq-22.0.3-cp36-cp36m-manylinux1_x86_64.whl (1.1MB)
Collecting python-dateutil>=2.1 (from jupyter-client->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/d4/70/d60450c3dd48ef87586924207ae8907090de0b306af2bce5d134d78615cb/python_dateutil-2.8.1-py2.py3-none-any.whl (227kB)
Collecting wcwidth (from prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0->ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/59/7c/e39aca596badaf1b78e8f547c807b04dae603a433d3e7a7e04d67f2ef3e5/wcwidth-0.2.5-py2.py3-none-any.whl
Collecting parso<0.9.0,>=0.8.0 (from jedi>=0.10->ipython>=5.0.0->ipykernel->metakernel->calysto-hy==0.1.1)
Downloading https://files.pythonhosted.org/packages/ad/f0/ef6bdb1eba2dbfda60c985cd8d7b47b6ed8c6a1f5d212f39ff50b64f172c/parso-0.8.1-py2.py3-none-any.whl (93kB)
Installing collected packages: backcall, six, decorator, ipython-genutils, traitlets, wcwidth, prompt-toolkit, ptyprocess, pexpect, pygments, pickleshare, parso, jedi, ipython, jupyter-core, pyzmq, python-dateutil, tornado, jupyter-client, ipykernel, metakernel, astor, appdirs, rply, funcparserlib, colorama, hy, calysto-hy
Running setup.py install for funcparserlib: started
Running setup.py install for funcparserlib: finished with status 'done'
Running setup.py install for calysto-hy: started
Running setup.py install for calysto-hy: finished with status 'done'
Successfully installed appdirs-1.4.4 astor-0.8.1 backcall-0.2.0 calysto-hy-0.1.1 colorama-0.4.4 decorator-4.4.2 funcparserlib-0.3.6 hy-0.20.0 ipykernel-5.5.0 ipython-7.16.1 ipython-genutils-0.2.0 jedi-0.18.0 jupyter-client-6.1.12 jupyter-core-4.7.1 metakernel-0.27.5 parso-0.8.1 pexpect-4.8.0 pickleshare-0.7.5 prompt-toolkit-3.0.17 ptyprocess-0.7.0 pygments-2.8.1 python-dateutil-2.8.1 pyzmq-22.0.3 rply-0.7.8 six-1.15.0 tornado-6.1 traitlets-4.3.3 wcwidth-0.2.5
You are using pip version 9.0.3, however version 21.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
A konečně v posledním kroku instalace spustíme příkaz pro instalaci Calysto Hy do Notebooku:
python3 -m calysto_hy install --sys-prefix [InstallKernelSpec] Installed kernelspec calysto_hy in /home/ptisnovs/calysto_hy/share/jupyter/kernels/calysto_hy
5. Registrace nového kernelu do Jupyter Notebooku a spuštění Jupyter Notebooku
Pro jistotu se ještě přesvědčíme, že se nový kernel Calysto Hy skutečně zaregistroval do Jupyter Notebooku. Soubor s konfigurací kernelu je uložen v podadresáři calysto_hy/share/jupyter/kernels/calysto_hy a měl by vypadat následovně:
{"argv": ["/home/ptisnovs/calysto_hy/bin/python3", "-m", "calysto_hy", "-f", "{connection_file}"], "codemirror_mode": "hy", "display_name": "Calysto Hy", "language": "hy", "name": "calysto_hy"}
Po přeformátování:
{
"argv": [
"/home/ptisnovs/calysto_hy/bin/python3",
"-m",
"calysto_hy",
"-f",
"{connection_file}"
],
"codemirror_mode": "hy",
"display_name": "Calysto Hy",
"language": "hy",
"name": "calysto_hy"
}
Ještě před prvním spuštěním Jupyter Notebooku je vhodné si nastavit heslo, které se bude zadávat pro přístup do jeho grafického uživatelského rozhraní:
$ jupyter notebook password Enter password: Verify password: [NotebookPasswordApp] Wrote hashed password to /home/ptisnovs/.jupyter/jupyter_notebook_config.json
Nyní konečně nastal čas spustit Jupyter Notebook:
$ jupyter notebook [I 11:26:39.019 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret [W 11:26:39.615 NotebookApp] WARNING: The notebook server is listening on all IP addresses and not using encryption. This is not recommended. [I 11:26:39.629 NotebookApp] Serving notebooks from local directory: /home/ptisnovs [I 11:26:39.629 NotebookApp] 0 active kernels [I 11:26:39.629 NotebookApp] The Jupyter Notebook is running at: [I 11:26:39.629 NotebookApp] http://[all ip addresses on your system]:8888/ [I 11:26:39.629 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). [I 11:26:39.983 NotebookApp] 302 GET /tree (::1) 1.91ms
Pokud se zobrazí i řádky zvýrazněné kurzivou, znamená to, že server Jupyter Notebooku bude přístupný z ostatních počítačů v síti. Toto chování (někdy ho vyžadujeme) lze zakázat editací souboru ~/.jupyter/jupyter_notebook_config.json, konkrétně úpravou řádku s klíčem „ip“:
{
"NotebookApp": {
"password": "sha1:neco-tay-je",
"ip": "localhost"
}
}
Nové spuštění Jupyter Notebooku by již mělo být bezproblémové:
$ jupyter notebook [I 12:28:08.540 NotebookApp] Serving notebooks from local directory: /home/ptisnovs [I 12:28:08.540 NotebookApp] 0 active kernels [I 12:28:08.540 NotebookApp] The Jupyter Notebook is running at: [I 12:28:08.540 NotebookApp] http://localhost:8888/ [I 12:28:08.540 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).

Obrázek 4: První spuštění Jupyter Notebooku.
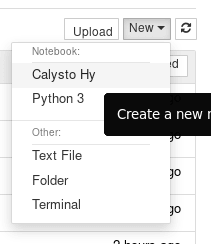
Obrázek 5: Nabídka vytvoření nového diáře používajícího kernel Calysto Hy.

Obrázek 6: Nový diář založený na kernelu Calysto Hy.
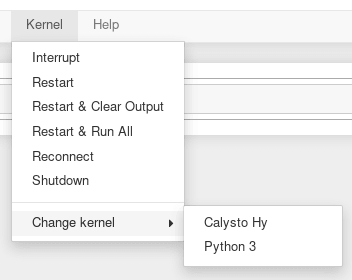
Obrázek 7: Kernel je možné prakticky kdykoli přepnout (i když to zde nedává význam).
6. Základní datové typy jazyka Hy
V této kapitole si popíšeme základní jednoduché datové typy programovacího jazyka Hy. Především se jedná o pravdivostní hodnoty. A právě v tomto ohledu se Hy odlišuje od většiny dalších dialektů LISPu, protože pro pravdivostní hodnoty používá True a False převzaté přímo z Pythonu. I prázdná hodnota se zapisuje jinak, než v mnoha dalších interpretrech LISPu, protože se používá Pythonovské None. Rozdíly mezi různými dialekty LISPu shrnuje následující tabulka:
| Dialekt | Pravda | Nepravda | Prázdná hodnota |
|---|---|---|---|
| Common Lisp | t | nil | nil |
| Scheme | #t | #f | '() |
| Clojure | true | false | nil |
| Hy | True | False | None |
Můžeme si to vyzkoušet:

Obrázek 8: Základní datové typy programovacího jazyka Hy.
Programovací jazyk Hy rozlišuje mezi celými čísly, čísly s plovoucí řádovou čárkou, komplexními čísly a konečně zlomky. První tři numerické typy jsou převzaty z Pythonu a jsou s ním plně kompatibilní; zlomky jsou typické pro prakticky všechny LISPovské jazyky a jsou interně implementovány objektem. U numerických hodnot je možné používat prefixy 0×, 0o a 0b:

Obrázek 9: Práce s numerickými hodnotami.
Řetězce se zapisují prakticky stejně jako v Pythonu, ovšem musí se použít uvozovky a nikoli apostrofy (ty mají odlišný význam). Podporovány jsou i prefixy pro Unicode řetězce (výchozí) a tzv. „raw“ řetězce (typicky používané při zápisu regulárních výrazů):
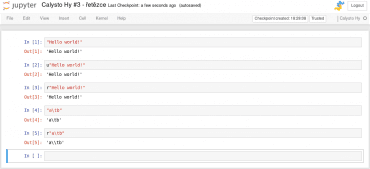
Obrázek 10: Práce s řetězci.
Specialitou jsou tzv.„here dokumenty“, tj. víceřádkové řetězce s prakticky libovolným obsahem, jejichž zápis byl inspirován programovacím jazykem Lua. Tyto řetězce začínají znaky #[XXX[ a končí znaky ]XXX], přičemž za XXX je možné doplnit libovolně dlouhou (i prázdnou) sekvenci znaků, která se v řetězci v ideálním případě nebude vyskytovat:

Obrázek 11: „Here dokumenty“ v jazyku Hy.
7. Zpracování kolekcí – vektorů a slovníků – v jazyku Hy
Ve druhé části dnešního článku se zaměříme na problematiku práce s kolekcemi (tj. zejména s vektory a se slovníky), protože to je jedna z oblastí, v níž se programovací jazyk Hy odlišuje od Clojure (s nímž má jinak velmi mnoho společných vlastností). Důvody pro všechny dále zmíněné rozdíly jsou ve skutečnosti velmi pragmatické – vzhledem k tomu, že v Hy jsou vektory představované Pythonovskými seznamy, není například možné zachovat neměnnost (immutability), což je jeden z hlavních konceptů, na nichž je postaven programovací jazyk Clojure. Většina základních funkcí navíc vrací přímo vektor a nikoli tzv. línou sekvenci (lazy sequence) tak, jak je tomu v Clojure.
Na začátek si uveďme důležitý fakt, že Hy rozlišuje mezi seznamem (list), což je datová struktura podobná klasickému LISPovskému seznamu tvořenému tečka-dvojicemi a mezi vektorem (vector), který odpovídá Pythonovskému seznamu, jehož obsah i tvar (shape) je měnitelný. Vektor se vytvoří následovně:
=> ; vektory nejsou neměnné (immutable) tak jako v Clojure! => (setv vektor [1 2 3 4])
Takto vytvořený vektor je možné modifikovat – měnit hodnotu jeho prvků, měnit jeho tvar (shape), tj. počet prvků atd.
V dalších demonstračním příkladech si ukážeme základní funkce určené pro práci s vektory. Jedná se v první řadě o funkci get určenou pro přečtení jednoho prvku ze seznamu na zadaném indexu (indexuje se od nuly) a taktéž o funkce nazvané příznačně first a last pro přístup k prvnímu, resp. k poslednímu prvku. Povšimněte si, že funkce get akceptuje i záporné indexy pro přístup k prvkům od konce vektoru, což vlastně není překvapivé, protože se tato funkce překládá na Pythonovské vektor[index]:
=> ; výraz pro přečtení prvku vektoru => (get vektor 1) 2 => (get vektor -1) 4 => (get vektor -2) 3 => ; speciální funkce pro významné prvky vektoru => (first vektor) 1 => (last vektor) 4
Další funkce určená pro práci s vektory se jmenuje rest a její chování již více odpovídá chování jazyka Clojure, protože tato funkce nevrací seznam ani vektor, ale iterátor, což je možné považovat za obdobu líné sekvence. Pro převod iterátoru na vektor se používá funkce list, což je sice matoucí, ale musíme si uvědomit, že snahou je zachování co největší úrovně kompatibility s Pythonem:
=> ; převod na sekvenci bez prvního prvku => (rest vektor) <itertools.islice object at 0x7f1237a16f98> => ; zpětný převod sekvence na vektor => (list (rest vektor)) [2, 3, 4] => ; vylepšený způsob zápisu předchozího výrazu => (-> vektor rest list) [2, 3, 4]
Následuje ukázka použití vektoru vektorů neboli matic, ať již pravidelných nebo nepravidelných:
=> ; dvourozměrný vektor (matice) => (setv matice [[1 2 3] [4 5 6] [7 8 9]]) => matice [[1, 2, 3], [4, 5, 6], [7, 8, 9]] => ; nepravidelná matice => (setv matice2 [[1] [2 3] [4 5 6] [7 8 9 10]]) => matice2 [[1], [2, 3], [4, 5, 6], [7, 8, 9, 10]]
Při snaze o vytvoření „plochého“ vektoru použijeme funkci pojmenovanou flatten:
=> (flatten matice) [1, 2, 3, 4, 5, 6, 7, 8, 9]
Další užitečná funkce cut slouží pro vytvoření dalšího vektoru z vybraných prvků vektoru prvního. Překlad této funkce odpovídá Pythonovskému vektor[od:do], a to včetně možnosti použití záporných indexů:
=> ; získání subvektoru => (cut vektor 1 5) [2, 3, 4] => (cut vektor 1) [2, 3, 4] => (cut vektor -5 -2) [1, 2] => (cut vektor -3 -2) [2]
Třetím nepovinným parametrem je možné určit krok, ať již kladný či záporný:
=> (setv vektor2 (list (range 20))) => ; sudé prvky => (cut vektor2 2 -1 2) [2, 4, 6, 8, 10, 12, 14, 16, 18] = => ; otočení vektoru => (cut vektor2 -1 0 -1) [19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1] = => ; otočení se získáním jen lichých prvků => (cut vektor2 -1 0 -2) [19, 17, 15, 13, 11, 9, 7, 5, 3, 1]
Pro změnu hodnoty prvku ve vektoru se používá makro assoc, ovšem musíme si dát pozor na to, aby prvek s daným indexem již ve vektoru existoval:
=> ; změna prvku ve vektoru je možná
=> (assoc vektor 2 42)
=
=> ; POZOR: vyhodí výjimku!
=> (assoc vektor 10 -1)
Traceback (most recent call last):
File "/home/tester/.local/lib/python3.6/site-packages/hy/importer.py", line 198, in hy_eval
eval(ast_compile(_ast, <eval_body>", "exec"), namespace)
File "<eval_body>", line 1, in <module>
IndexError: list assignment index out of range
Při mazání prvků z vektoru použijeme funkci del, typicky společně s funkcí cut:
=> (setv vektor2 ["A" "B" "C" "D" "E" "F"]) => vektor2 ['A', 'B', 'C', 'D', 'E', 'F'] => (cut vektor2 2 4) ['C', 'D'] => (del (cut vektor2 2 4)) => vektor2 ['A', 'B', 'E', 'F'] => (-> (cut vektor2 2 4) del) => vektor2 ['A', 'B']
A konečně pro přidání nového prvku do vektoru můžete použít metodu .append, která se zapisuje dvěma způsoby – funkcionálně nebo objektově:
=> ; přidání prvku do vektoru (na jeho konec) => (.append vektor 5) => ; přidání prvku do vektoru (na jeho konec) => (vektor.append 5)

Obrázek 12: Práce s vektory.
8. Funkce a makra určená pro práci se slovníky
Další funkce a makra, která si v dnešním článku popíšeme, se týkají práce se slovníky (dictionary). I v této oblasti vidíme inspiraci programovacím jazykem Clojure (konstruktory slovníků), ovšem současně je patrná poměrně úzká návaznost i na samotný programovací jazyk Python. Nejprve si zopakujme, jak vypadá konstruktor slovníku. Ten je jednoduchý – všechny dvojice klíč+hodnota se uvedou do složených závorek:
=> {"prvni" "first" "druhy" "second" "treti" "third"}
{'prvni': 'first', 'druhy': 'second', 'treti': 'third'}
Pro získání hodnoty uložené pod nějakým klíčem se opět používá funkce get, které se ovšem pochopitelně namísto indexu prvku předává klíč (obecně neceločíselný). V případě, že prvek s daným klíčem není nalezen, dojde k běhové výjimce:
=> (setv d1 {:id 1 :name "Eda" :surname "Wasserfall"})
=> (get d1 :name)
'Eda'
=> (get d1 :xyname)
Traceback (most recent call last):
File "/home/tester/.local/lib/python3.6/site-packages/hy/importer.py", line 201, in hy_eval
return eval(ast_compile(expr, "<eval>", "eval"), namespace)
File "<eval>", line 1, in <module>
KeyError: '\ufdd0:xyname'
V případě, že se ve funkci get použije větší množství selektorů (indexů, popř. klíčů), je možné vybírat hodnoty z vnořených datových struktur. Opět si to ukažme na velmi jednoduchém demonstračním příkladu, konkrétně na slovníku, který v jednom prvku obsahuje seznam:
=> (setv d2 {:id 1 :name "Eda" :surname "Wasserfall" :actors ["Genadij Rumlena" "Pavel Vondruška"]})
=> (get d2 :actors 1)
'Pavel Vondruška'
=> (get d2 :actors 0)
'Genadij Rumlena'
I u slovníků lze použít funkci assoc pro přidání další dvojice klíč+hodnota. Slovník je tedy možné vytvořit postupně:
=> (setv d3 {})
=> (assoc d3 :id 10)
=> (assoc d3 :name "Eda")
=> (assoc d3 :surname "Wasserfall")
Funkce assoc dokáže přepsat hodnotu prvku, a to ve chvíli, kdy použijeme stejný klíč, který je již ve slovníku obsažen:
=> (assoc d3 :id 10)
Vymazání dvojice klíč+hodnota zajišťuje funkce del:
=> (del (get d3 :surname))
Další možností, jak vytvořit slovník, je použití funkce pojmenované zip (ta zazipuje dvě sekvence), ovšem výsledek je nutné na slovník převést:
=> (dict (zip [:id :name :surname] [1 "Eda" "Wasserfall"]))
Nepatrně složitější příklady založené na funkci zip:
=> (repeat "A" 10)
repeat('A', 10)
=> (dict (zip (range 10) (repeat "A" 10)))
{0: 'A', 1: 'A', 2: 'A', 3: 'A', 4: 'A', 5: 'A', 6: 'A', 7: 'A', 8: 'A', 9: 'A'}
=> (-> (zip (range 10) (range 10 1 -1)) dict)
{0: 10, 1: 9, 2: 8, 3: 7, 4: 6, 5: 5, 6: 4, 7: 3, 8: 2}
Počet hodnot může přesahovat počet klíčů, ovšem hodnoty, které nelze na klíče namapovat, se budou jednoduše ignorovat:
=> (-> (zip (range 10) (range 50 1 -1)) dict)
{0: 50, 1: 49, 2: 48, 3: 47, 4: 46, 5: 45, 6: 44, 7: 43, 8: 42, 9: 41}

Obrázek 13: Práce se slovníky v Hy spuštěném v Jupyter Notebooku.
9. Volání funkcí a metod definovaných v Pythonu
V této kapitole si ukážeme, jakým způsobem můžeme v jazyku Hy použít funkce a metody definované v Pythonu. Pro tento účel si připravíme malý testovací modul nazvaný test_module.py, který obsahuje jak několik funkcí, tak i třídu s konstruktorem a jednou metodou. Navíc je deklarována jedna konstanta:
THE_ANSWER = 42
def multiply_two_numbers(x, y):
return x * y
class uber_class:
def __init__(self, x):
self._x = x
def compute_square(self):
return self._x * self._x
Použití tříd a metod z modulu datetime je snadné. Povšimněte si, že metody lze volat jak stylem (.metoda objekt parametry), tak i stylem (objekt.metoda parametry):
(import [datetime [date :as d]]) (setv date (d 2018 02 28)) (print date) (print date.year) (print date.month) (print date.day) (setv now1 (.today d)) (print now1) (setv now2 (d.today)) (print now2)
Příklad použití konstanty a funkce z našeho testovacího modulu ukazuje, že lze použít jak původní jména (vytvořená podle konvencí Pythonu), tak i jména odpovídající konvencím programovacího jazyka Hy:
(import [test_module [*]]) (print THE_ANSWER) (print *the-answer*) (print (multiply_two_numbers 6 7)) (print (multiply-two-numbers 6 7))
Alternativní způsob importu do vlastního jmenného prostoru t:
(import [test_module :as t]) (print t.THE_ANSWER) (print t.*the-answer*) (print (t.multiply_two_numbers 6 7)) (print (t.multiply-two-numbers 6 7))
Konstrukce objektu a volání jeho metody (opět oběma podporovanými způsoby):
(setv u (uber_class 42)) (print u) (print (u.compute_square)) (print (.compute_square u))
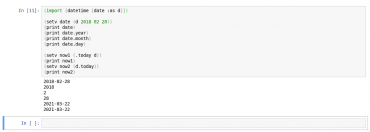
Obrázek 14: Volání funkcí Pythonu v Hy spuštěném v Jupyter Notebooku.
10. Jazyk Hy a knihovna Numpy
Jupyter Notebook se velmi často používá společně s knihovnou Numpy a Matplotlib, popř. s knihovnou Pandas. Všechny tři zmíněné knihovny jsou určeny pro programovací jazyk Python, takže je zřejmé (viz předchozí kapitolu), že tyto knihovny budou bez problémů volatelné i z programovacího jazyka Hy. Samozřejmě je nejprve nutné provést import těchto knihoven:
=> (import numpy)
popř.:
=> (import [numpy :as np])
Ihned poté je možné si zobrazit nápovědu k naimportované knihovně nebo jen jediné funkci:
=> (help np)
Help on package numpy:
NAME
numpy
DESCRIPTION
NumPy
=====
Provides
1. An array object of arbitrary homogeneous items
2. Fast mathematical operations over arrays
3. Linear Algebra, Fourier Transforms, Random Number Generation
Naimportovanou knihovnu můžeme ihned začít používat:
=> (np.arange 1 10)
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
=> (np.linspace 1 10)
array([ 1. , 1.18367347, 1.36734694, 1.55102041, 1.73469388,
1.91836735, 2.10204082, 2.28571429, 2.46938776, 2.65306122,
2.83673469, 3.02040816, 3.20408163, 3.3877551 , 3.57142857,
3.75510204, 3.93877551, 4.12244898, 4.30612245, 4.48979592,
4.67346939, 4.85714286, 5.04081633, 5.2244898 , 5.40816327,
5.59183673, 5.7755102 , 5.95918367, 6.14285714, 6.32653061,
6.51020408, 6.69387755, 6.87755102, 7.06122449, 7.24489796,
7.42857143, 7.6122449 , 7.79591837, 7.97959184, 8.16326531,
8.34693878, 8.53061224, 8.71428571, 8.89795918, 9.08163265,
9.26530612, 9.44897959, 9.63265306, 9.81632653, 10. ])
atd.
=> (np.array [1 2 3]) array([1, 2, 3]) => (type (np.arange 1 10)) <class 'numpy.ndarray'>
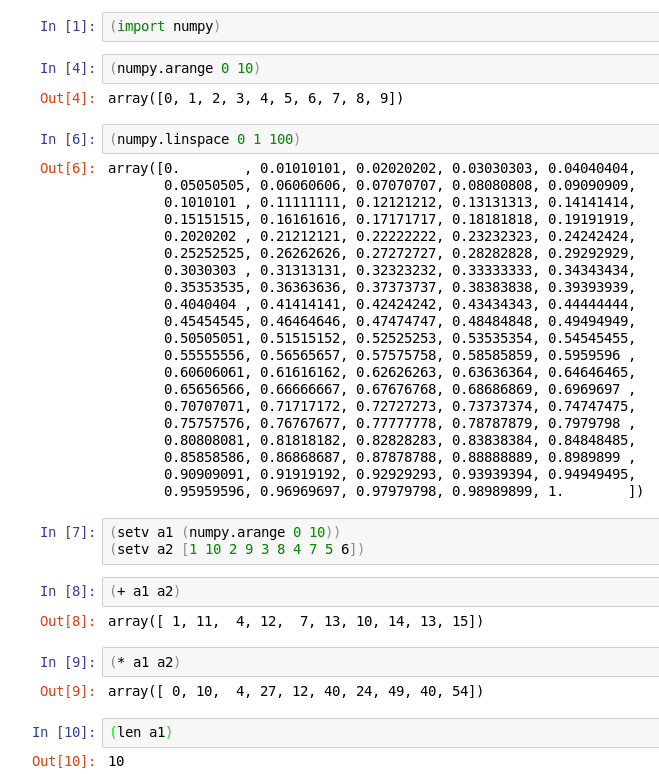
Obrázek 15: Volání funkcí z knihovny Numpy v Hy spuštěném v Jupyter Notebooku.
11. Volání funkcí definovaných v jazyku Hy z Pythonu
Nyní si ukážeme opačný směr spolupráce mezi programovacím jazykem Hy a Pythonem, než tomu bylo v deváté a desáté kapitole. Nejdříve nadefinujeme několik funkcí v jazyku Hy a posléze tyto funkce (resp. jen ty funkce, které mají korektní jméno) zavoláme z Pythonu. Nutné přitom je, aby se použilo následující pojmenování souboru s modulem naprogramovaným v Hy:
jméno_modulu.hy
Vytvoříme tedy soubor nazvaný interop2.hy, který bude mít následující obsah:
; Běžná funkce zapisovaná ve stylu LISPu
(defn calculate-multiplication
[x y]
(* x y))
; Predikáty
(defn zero?
[x]
(= x 0))
(defn even?
[x]
(zero? (% x 2)))
(defn odd?
[x]
(not (even? x)))
; Konverzní funkce
(defn string->bool
[s]
(= s "true"))
(defn deg->rad
[angle]
(* angle (/ 3.1415 180)))
; Privátní funkce
(defn -hidden
[x]
(+ x 1))
; Funkce psaná velkými písmeny
(defn *major*
[x]
(+ x 1))
Všechny funkce, u nichž se podařilo vytvoření korektního pythonovského jména, lze zavolat přímo z Pythonu, a to stejným způsobem, jako jakékoli jiné funkce. Nesmíme zapomenout na import modulu hy a samozřejmě i testovaného modulu (ten se nijak nepřekládá!):
import hy from interop2 import * print(calculate_multiplication(6, 7)) print(is_zero(0)) print(is_zero(1)) print(is_zero(2)) print(is_even(0)) print(is_even(1)) print(is_even(2)) print(is_odd(0)) print(is_odd(1)) print(is_odd(2)) print(MAJOR(1)) import interop2 print(interop2._hidden(1))
12. Makrosystém programovacího jazyka Hy
V navazujících kapitolách se ve stručnosti seznámíme s možnostmi makrosystému nabízeného programovacím jazykem Hy. Před zápisem uživatelských maker si však ukažme takzvaná reader makra, která jsou aplikována již ve chvíli načítání jednotlivých výrazů do interpretru. Samotná reader makra jsou velmi jednoduchá, protože nemají přístup k AST (jsou aplikována příliš brzy):
| # | Makro | Název | Význam |
|---|---|---|---|
| 1 | ; | comment | umožňuje obejít zápis (comment nějaký text) u komentářů |
| 2 | ' | quote | nahrazuje zápis (quote …) |
| 3 | ` | syntax-quote | provádí plnou kvalifikaci symbolů + zde lze použít makra ~ a ~@ |
| 4 | ~ | unquote | zajistí, že se vyhodnotí pouze označená část formy (= provede substituci této části výsledkem) |
| 5 | ~@ | unquote-splicing | podobné předchozími makru, ovšem výsledná sekvence se vloží ve formě samostatných prvků do „obalující“ sekvence |
| 6 | # | dispatch | má různé funkce: donutí reader, aby použil makro z jiné tabulky maker |
Makro dispatch (poslední v předchozí tabulce) má ve skutečnosti několik významů v závislosti na tom, jaký znak je uveden ihned po křížku (#):
| # | Dvojice znaků | Způsob použití | Význam |
|---|---|---|---|
| 1 | #{ | #{prvky} | zápis množiny |
| 2 | #_ | #_text | text je ignorován – alternativní způsob komentáře |
V uživatelských makrech (těch plnohodnotných) se velmi často používají reader makra syntax-quote a unquote, s nimiž se blíže seznámíme v dalším textu.
13. Využití funkce eval, homoikonicita jazyků
Jednoduchý interpret LISPu mohl být teoreticky implementován pouze s využitím trojice funkcí read (načtení výrazu/formy ze standardního vstupu), print (tisk výsledku vyhodnocení výrazu/formy na standardní výstup), eval (většinou rekurzivně implementovaná funkce určená pro vyhodnocení načtené formy), které byly doplněny speciální formou či makrem loop (nekonečná smyčka – při striktním pohledu se v tomto případě nemůže jednat o funkci). Ve skutečnosti je však samozřejmě nutné, aby byl prakticky použitelný programovací jazyk doplněn o alespoň minimální množství základních funkcí a speciálních forem. V případě původního LISPu se jednalo o sedm funkcí a dvě speciální formy: atom, car, cdr, cond, cons, eq, quote, lambda a konečně label.

Obrázek 16: Implementace interpretru LISPu
Autor: Paul Graham.
Původně relativně velmi jednoduše a přitom elegantně implementovaný interpret programovacího jazyka LISP se postupně začal vyvíjet a jednou z nových a přitom mocných technik, které do něj byly přidány, jsou takzvaná makra, která se však v mnoha ohledech liší od maker používaných například v programovacích jazycích C a C++. Zatímco v céčku a C++ jsou makra zpracovávána poměrně „hloupým“ preprocesorem, který dokáže provádět textové substituce, načítat vkládané soubory a vyhodnocovat jednoduché podmínky, mohou makra implementovaná v programovacím jazyce LISP pracovat přímo se zadávanými formami, které makra mohou různým způsobem modifikovat – přitom se zde využívá faktu, že v LISPu a tudíž i v programovacím jazyku Hy jsou programy reprezentovány ve formě (obvykle rekurzivně vnořených) seznamů, a změnou obsahu těchto seznamů lze vlastně přímo manipulovat s takzvaným abstraktním syntaktickým stromem (AST – Abstract Syntax Tree).
Není bez zajímavosti, že s AST se v LISPu nebo Hy může manipulovat za použití stejných mechanismů (funkcí/forem/maker), které se používají i při běžném programování – jinými slovy to znamená, že jazyk maker je stále jazykem, v němž se zapisují programy (na rozdíl od zmíněného céčka a C++, kde je jazyk maker zcela odlišný). Jinými slovy to znamená, že se při tvorbě maker musíme seznámit pouze se způsobem zápisu maker, ale v samotných makrech se mohou používat funkce, které jsme si již v tomto článku popsali – většinou se bude jednat o funkce pro práci se seznamy, což je vzhledem ke způsobu reprezentace programů (jako do sebe vnořených seznamů) pochopitelné.
Do funkce eval je tedy možné předat pouze korektně zapsanou formu. V některých případech je však určitý výraz nebo i větší část programů dostupná pouze ve formě řetězce – ten může být přečten například ze souboru, zadán uživatelem v nějakém GUI dialogu atd. Problém nastane v případě, kdy se pokusíme tento řetězec předat funkci eval v domnění, že se předávaný řetězec „automagicky“ bude transformovat na korektní formu a ta se následně vyhodnotí.
Předpoklad, že eval bude jako svůj parametr akceptovat řetězec, může vycházet ze zkušeností vývojáře s jinými programovacími jazyky (nemusíme ostatně chodit daleko – takto se totiž chová přímo Python), kde tomu tak skutečně může být, ovšem v Hy a ani v dalších dialektech LISPu to neplatí a pro toto chování jsou i dobré důvody – mimo jiné i bezpečnost (a taktéž to, že parsování řetězce skutečně není prací pro eval). Podívejme se nyní, co se stane, pokud se pokusíme nechat vyhodnotit řetězec obsahující zápis korektní formy, ovšem pouze v textové podobě:
; vytvoření nové globální proměnné
; a přiřazení SEZNAMU do této proměnné
=> (setv hello-code '(print "Hello world!"))
; hodnotu proměnné (tedy obsah seznamu)
; lze samozřejmě kdykoli získat
=> hello-code
HyExpression([
HySymbol('print'),
HyString('Hello world!')])
; i když proměnná obsahuje seznam s korektním
; voláním funkce, není možné použít následující
; formu pro zavolání této funkce
=> (hello-code)
Traceback (most recent call last):
File "/home/tester/.local/lib/python3.4/site-packages/hy/importer.py", line 201, in hy_eval
return eval(ast_compile(expr, "<eval>", "eval"), namespace)
File "<eval>", line 1, in <module>
TypeError: 'HyExpression' object is not callable
; namísto toho se musí použít funkce eval
=> (eval hello-code)
Hello world!
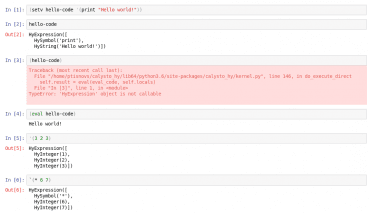
Obrázek 17: Použití eval v jazyku Hy.
14. Makra „quote“ a „syntax-quote“
Konečně se dostáváme k zajímavým a užitečným reader makrům. Jedno z nejdůležitějších a nejčastěji používaných maker se jmenuje quote a zapisuje se pomocí apostrofu. Toto makro zakazuje vyhodnocování seznamů, protože pokud by objekt reader načetl formu ve tvaru (a b c), předal by ji do funkce eval, kde by se tato forma vyhodnotila jako volání funkce a s parametry b a c. Pokud však reader načte formu '(a b c), ztransformuje ji do tvaru (quote (a b c)), přičemž quote je speciální forma zakazující vyhodnocení. Na většinu ostatních objektů kromě seznamů nemá makro quote většinou žádný vliv:
=> '42
HyInteger(42)
=> '(1 2 3)
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3)])
=> '[1 2 3]
HyList([
HyInteger(1),
HyInteger(2),
HyInteger(3)])
=> [1 2 3]
[1, 2, 3]
=> '(* 6 7)
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)])
=> (* 6 7)
42
Kromě makra quote ještě objekt reader rozeznává poněkud komplikovanější makro nazývané syntax-quote, které se zapisuje pomocí zpětného apostrofu: `. Chování tohoto makra se liší podle toho, s jakým typem objektu je použito, ovšem ve všech případech se makro chová tak, aby nedocházelo k vyhodnocení jeho argumentů, popř. ani k vyhodnocení vnořených forem. V následujících příkladech dochází k jednoduchému zákazu vyhodnocení předané formy:
=> `42 HyInteger(42) => `(1 2 3) HyExpression([ HyInteger(1), HyInteger(2), HyInteger(3)]) => `[1 2 3] HyList([ HyInteger(1), HyInteger(2), HyInteger(3)])
Další možnosti využití tohoto makra:
=> `(* 6 7)
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)])
=> `(str "Hello" "world")
HyExpression([
HySymbol('str'),
HyString('Hello'),
HyString('world')])
=> `[* seq str xyzzy neznamy]
HyList([
HySymbol('*'),
HySymbol('seq'),
HySymbol('str'),
HySymbol('xyzzy'),
HySymbol('neznamy')])
Makro nazvané unquote, které se zapisuje pomocí znaku ~ (tilda) dokáže vynutit vyhodnocení určité části výrazu, a to tehdy, pokud je tento výraz umístěn v makru ` (syntax-quote), nikoli však ' (quote). Nejprve si ukažme způsob zápisu tohoto makra i to, jaký má toto makro vliv na zapisované výrazy:
; makro quote zakáže vyhodnocení celého seznamu
=> '(1 2 (* 6 7) (/ 4 2))
HyExpression([
HyInteger(1),
HyInteger(2),
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)]),
HyExpression([
HySymbol('/'),
HyInteger(4),
HyInteger(2)])])
; makro syntax-quote zakáže vyhodnocení celého seznamu
=> `(1 2 (* 6 7) (/ 4 2))
HyExpression([
HyInteger(1),
HyInteger(2),
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)]),
HyExpression([
HySymbol('/'),
HyInteger(4),
HyInteger(2)])])
Použití ~ uvnitř makra ` je taktéž možné a dokonce velmi často používané:
; pomocí ~ vynutíme vyhodnocení podvýrazu (* 6 7)
=> `(1 2 ~(* 6 7) (/ 4 2))
HyExpression([
HyInteger(1),
HyInteger(2),
42,
HyExpression([
HySymbol('/'),
HyInteger(4),
HyInteger(2)])])
; pomocí ~ vynutíme vyhodnocení podvýrazu (/ 4 2)
=> `(1 2 (* 6 7) ~(/ 4 2))
HyExpression([
HyInteger(1),
HyInteger(2),
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)]),
2.0])
; pomocí dvou ~ vynutíme vyhodnocení obou podvýrazů
=> `(1 2 ~(* 6 7) ~(/ 4 2))
HyExpression([
HyInteger(1),
HyInteger(2),
42,
2.0])
Podobným způsobem pracuje i makro ~@, ovšem to navíc ještě provádí „zplošťování seznamů“. Prozatím si chování tohoto makra ukážeme na velmi jednoduchém umělém příkladu:
; uživatelsky definovaný seznam
=> (setv s '(1 2 3))
=> '(1 2 3 (cons s s))
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3),
HyExpression([
HySymbol('cons'),
HySymbol('s'),
HySymbol('s')])])
=> `(1 2 3 (cons s s))
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3),
HyExpression([
HySymbol('cons'),
HySymbol('s'),
HySymbol('s')])])
=> `(1 2 3 ~(cons s s))
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3),
HyExpression([
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3)]),
HyInteger(1),
HyInteger(2),
HyInteger(3)])])
=> `(1 2 3 ~@(cons s s))
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3),
HyExpression([
HyInteger(1),
HyInteger(2),
HyInteger(3)]),
HyInteger(1),
HyInteger(2),
HyInteger(3)])

Obrázek 18: Makra „quote“ a „syntax-quote“.
15. Praktické použití – jednoduchá makra vytvořená v jazyku Hy
Uživatelská makra se vytváří s využitím defmacro. Podívejme se nyní na velmi jednoduché makro, které po svém zavolání (v době zpracování vstupního textu!) provede expanzi na (print 'výraz), tj. vypíše se původní (nevyhodnocený!) výraz, což se může hodit například při ladění programů:
(defmacro print-expression-1
[expression]
`(print '~expression))
Makro můžeme upravit i takovým způsobem, aby se nejprve vypsal nevyhodnocený výraz a posléze i jeho výsledek. Použijeme zde speciální formu do pro spojení většího množství funkcí do jediného bloku. Povšimněte si, že celý blok je uvozen zpětným apostrofem a uvnitř bloku tedy můžeme využít ~:
(defmacro print-expression-2
[expression]
`(do (print '~expression)
(print ~expression)))
Příklady použití právě nadefinovaného makra print-expression-2:
(print-expression-1 (* 6 7))
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)])
(print-expression-2 (* 6 7))
HyExpression([
HySymbol('*'),
HyInteger(6),
HyInteger(7)])
42
Další makro nalezneme v doplňkové knihovně jazyka Hy. Umožňuje pro každý prvek seznamu zavolat nějakou funkci, která může mít vedlejší efekt. Uvnitř této funkce je příslušný prvek seznamu představován symbolem it. Makro nazvané ap-each vypadá následovně a jeho chování při expanzi je zřejmý, protože známe význam ` ~ i ~@:
(defmacro ap-each [lst &rest body] `(for [it ~lst] ~@body))
Příklad použití:
=> (ap-each [1 2 3] (print it)) 1 2 3 => (ap-each [1 2 3] (print (* it it))) 1 4 9

Obrázek 19: Dvě užitečná makra spuštěná přímo v prostředí Jupyter Notebooku.
16. Spuštění samotného interpretru jazyka Hy a práce s interaktivní smyčkou REPL
Interpret programovacího jazyka Hy není dostupný pouze z Jupyter Notebooku. Můžeme ho spustit i samostatně, a to velmi jednoduše: příkazem hy. Tento příkaz podporuje několik přepínačů, z nichž nejzajímavější je –spy, o němž se zmíníme v dalším textu:
$ hy --help
usage: hy [-h | -v | -i CMD | -c CMD | -m MODULE | FILE | -] [ARG]...
optional arguments:
-h, --help
show this help message and exit
-c=COMMAND
program passed in as a string (terminates option list)
-m=MOD
module to run, passed in as a string (terminates option list)
-E
ignore PYTHON* environment variables
-B
don't write .py[co] files on import; also PYTHONDONTWRITEBYTECODE=x
-i=ICOMMAND
program passed in as a string, then stay in REPL (terminates option list)
--spy
print equivalent Python code before executing
--repl-output-fn=REPL_OUTPUT_FN
function for printing REPL output (e.g., hy.contrib.hy-repr.hy-repr)
-v, --version
show program's version number and exit
FILE
program read from script
-
program read from stdin
[ARG]...
arguments passed to program in sys.argv[1:]
Zkusme si nyní interpret spustit a získat tak přístup k interaktivní smyčce REPL. Interpret se spustí prakticky okamžitě (na rozdíl od klasického Clojure založeného na JVM, kde je prodleva již patrnější – sekundy a v některých případech i desítky sekund). Výzva interpretru (prompt) se skládá ze znaků ⇒ (opět na rozdíl od Clojure bez uvedení výchozího jmenného prostoru):
$ hy hy 0.20.0 using CPython(default) 3.6.6 on Linux =>
V interaktivní smyčce je každý výraz po svém načtení (Read) ze standardního vstupu ihned vyhodnocen (Eval) a výsledná hodnota je následně vypsána do terminálu (Print) a interpret bude očekávat načtení dalšího výrazu (Loop). Některé výrazy jsou jednoduché, protože se vyhodnotí samy na sebe. Příkladem mohou být numerické hodnoty, pravdivostní hodnoty, řetězce atd:
=> 42 42 => 3.1415 3.1415 => 1+2j (1+2j) => 6j 6j => 4/7 Fraction(4, 7) => True True => False False => None
Volba –spy umožňuje zjisit, jakým způsobem je kód z Hy transformován do Pythonu před vypsáním výsledku výrazu:
=> (+ 10 20) 10 + 20 30 => (setv x 10) x = 10 None => (setv y 20) y = 20 None => (+ x y) x + y 30 => (setv z [1 2 3]) z = [1, 2, 3] None => (assoc z 4 4) z[4] = 4 None
Dále je možné s využitím nástrojů nazvaných hy2py a hy2py3 lze provést překlad zdrojových kódů naprogramovaných v jazyce Hy do Pythonu 2 či do Pythonu 3. Možnosti těchto nástrojů si ukážeme na třech variantách výpočtu faktoriálu. Povšimněte si, že výsledkem jsou většinou velmi pěkně čitelné zdrojové kódy, což při transpřekladu není vždy zvykem:
; nerekurzivní výpočet faktoriálu
(defn factorial
[n]
(if (neg? n)
(raise (ValueError "natural number expected"))
(reduce * (range 1 (inc n)))))
(print (factorial 10))
(for [n (range 1 11)]
(print n (factorial n)))
(print (factorial -10))
Výsledek přeložený nástrojem hy2py3 – příkaz od příkazu obdoba předchozího skriptu:
from hy.core.language import inc, is_neg, reduce
from hy.core.shadow import *
def factorial(n):
if is_neg(n):
raise ValueError('natural number expected')
_hy_anon_var_1 = None
else:
_hy_anon_var_1 = reduce(*, range(1, inc(n)))
return _hy_anon_var_1
print(factorial(10))
for n in range(1, 11):
print(n, factorial(n))
print(factorial(-10))
17. Dodatek: dostupné kernely pro Jupyter Notebook
V tomto dodatku jsou vypsány kernely, které jsou dostupné pro projekt Jupyter Notebook a které uživatelům nabízí vazbu na různé programovací jazyky. V kontextu dnešního článku zajímavé kernely jsou zvýrazněny:

| Kernel | Jazyk |
|---|---|
| Dyalog Jupyter Kernel | APL (Dyalog) |
| Coarray-Fortran | Fortran 2008/2015 |
| IJulia | Julia |
| IHaskell | ghc >= 7.6 |
| IRuby | ruby >= 2.3 |
| tslab | Typescript 3.7.2, JavaScript ESNext |
| IJavascript | nodejs >= 0.10 |
| ITypeScript | Typescript >= 2.0 |
| jpCoffeescript | coffeescript >= 1.7 |
| jp-LiveScript | livescript >= 1.5 |
| ICSharp | C# 4.0+ |
| IFSharp | F# |
| lgo | Go >= 1.8 |
| iGalileo | Galileo >= 0.1.3 |
| gopherlab | Go >= 1.6 |
| Gophernotes | Go >= 1.9 |
| IScala | Scala |
| IErlang | Erlang |
| ITorch | Torch 7 (LuaJIT) |
| IElixir | Elixir >= 1.5 |
| ierl | Erlang >= 19, Elixir >= 1.4, LFE 1.2 |
| OCaml-Jupyter | OCaml >= 4.02 |
| IForth | Forth |
| peforth | Forth |
| IPerl | Perl 5 |
| Perl6 | Perl 6.c |
| IPerl6 | Perl 6 |
| Jupyter-Perl6 | Perl 6.C |
| IPHP | PHP >= 5.4 |
| Jupyter-PHP | PHP >= 7.0.0 |
| IOctave | Octave |
| IScilab | Scilab |
| MATLAB Kernel | Matlab |
| Bash | bash |
| Z shell | zsh >= 5.3 |
| PowerShell | PowerShell |
| CloJupyter | Clojure >= 1.7 |
| jupyter-kernel-jsr223 | Clojure 1.8 |
| Hy Kernel | Hy |
| Calysto Hy | Hy |
| jp-babel | Babel |
| Lua Kernel | Lua |
| IPurescript | Purescript |
| IPyLua | Lua |
| ILua | Lua |
| Calysto Scheme | Scheme |
| Calysto Processing | Processing.js >= 2 |
| idl_kernel | IDL |
| Mochi Kernel | Mochi |
| Lua (used in Splash) | Lua |
| Calysto Bash | bash |
| IBrainfuck | Brainfuck |
| cling | C++ |
| xeus-cling | C++ |
| Prolog | Prolog |
| SWI-Prolog | SWI-Prolog |
| cl-jupyter | Common Lisp |
| common-lisp-jupyter | Common Lisp |
| IJython | Jython 2.7 |
| ROOT | C++/python |
| Tcl | Tcl 8.5 |
| J | J 805–807 (J901beta) |
| Jython | Jython>=2.7.0 |
| C | C |
| Coconut | Coconut |
| Pike | Pike >= 7.8 |
| jupyter-kotlin | Kotlin 1.1-M04 EAP |
| mit-scheme-kernel | MIT Scheme 9.2 |
| elm-kernel | elm |
| SciJava Jupyter Kernel | Java + 9 scripting languages |
| BeakerX | Groovy, Java, Scala, Clojure, Kotlin, SQL |
| IJava | Java 9 |
| Guile | Guile 2.0.12 |
| IRacket | Racket >= 6.10 |
| EvCxR Jupyter Kernel | Rust >= 1.29.2 |
| SSH Kernel | Bash |
| Emu86 Kernel | Intel Assembly Language |
18. Předchozí články o Jupyter Notebooku
Se samotným nástrojem Jupyter Notebook jsme se již na stránkách Rootu několikrát setkali (až již přímo či nepřímo), a to konkrétně v následujících článcích:
- Gophernotes: kombinace interaktivního prostředí Jupyteru s jazykem Go
https://www.root.cz/clanky/gophernotes-kombinace-interaktivniho-prostredi-jupyteru-s-jazykem-go/ - Jupyter Notebook – nástroj pro programátory, výzkumníky i lektory
https://www.root.cz/clanky/jupyter-notebook-nastroj-pro-programatory-vyzkumniky-i-lektory/ - Tvorba grafů v Jupyter Notebooku s využitím knihovny Matplotlib
https://www.root.cz/clanky/tvorba-grafu-v-jupyter-notebooku-s-vyuzitim-knihovny-matplotlib/ - Tvorba grafů v Jupyter Notebooku s využitím knihovny Matplotlib (dokončení)
https://www.root.cz/clanky/tvorba-grafu-v-jupyter-notebooku-s-vyuzitim-knihovny-matplotlib-dokonceni/ - Jupyter Notebook – operace s rastrovými obrázky a UML diagramy, literate programming
https://www.root.cz/clanky/jupyter-notebook-operace-s-rastrovymi-obrazky-a-uml-diagramy-literate-programming/ - Interpret programovacího jazyka Clojure integrovaný do Jupyter Notebooku
https://www.root.cz/clanky/interpret-programovaciho-jazyka-clojure-integrovany-do-jupyter-notebooku/ - Programovací jazyk R, Jupyter notebook a Jupytext
https://www.root.cz/clanky/programovaci-jazyk-r-jupyter-notebook-a-jupytext/
19. Repositář s demonstračními příklady
Všechny demonstrační příklady, resp. přesněji řečeno diáře pro Jupyter Notebook a kernel jazyka Hy, byly uloženy do repositáře, který naleznete na adrese https://github.com/tisnik/jupyter-notebook-examples:
20. Odkazy na Internetu
- Calysto Hy
https://github.com/Calysto/calysto_hy - Calysto Scheme
https://github.com/Calysto/calysto_scheme - Calysto Metakernel
https://github.com/Calysto/metakernel - Calysto Hy Notebooks: Tutorial.ipynb
https://github.com/Calysto/calysto_hy/blob/master/notebooks/Tutorial.ipynb - Python becomes a platform
https://khinsen.wordpress.com/2012/03/15/python-becomes-a-platform/ - Python becomes a platform. Thoughts on the release of clojure-py
https://news.ycombinator.com/item?id=3708974 - SchemePy
https://pypi.org/project/SchemePy/ - lispy
https://pypi.org/project/lispy/ - Lython
https://pypi.org/project/Lython/ - Lizpop
https://pypi.org/project/lizpop/ - Budoucnost programovacích jazyků
http://www.knesl.com/budoucnost-programovacich-jazyku - LISP Prolog and Evolution
http://blog.samibadawi.com/2013/05/lisp-prolog-and-evolution.html - List of Lisp-family programming languages
https://en.wikipedia.org/wiki/List_of_Lisp-family_programming_languages - clojure_py na indexu PyPi
https://pypi.python.org/pypi/clojure_py - PyClojure
https://github.com/eigenhombre/PyClojure - Hy na GitHubu
https://github.com/hylang/hy - Hy: The survival guide
https://notes.pault.ag/hy-survival-guide/ - Hy běžící na monitoru terminálu společnosti Symbolics
http://try-hy.appspot.com/ - Welcome to Hy’s documentation!
http://docs.hylang.org/en/stable/ - Hy na PyPi
https://pypi.org/project/hy/#description - Getting Hy on Python
https://lwn.net/Articles/596626/ - Programming Can Be Fun with Hy
https://opensourceforu.com/2014/02/programming-can-fun-hy/ - Přednáška o projektu Hy (pětiminutový lighttalk)
http://blog.pault.ag/day/2013/04/02 - Hy (Wikipedia)
https://en.wikipedia.org/wiki/Hy - Clojure home page
http://clojure.org/ - Clojure Sequences
http://clojure.org/sequences - Clojure Data Structures
http://clojure.org/data_structures - Clojure
https://en.wikipedia.org/wiki/Clojure - How to create Clojure notebooks in Jupyter
https://s01blog.wordpress.com/2017/12/10/how-to-create-clojure-notebooks-in-jupyter/ - Dokumentace k nástroji Conda
https://docs.conda.io/en/latest/ - Notebook interface
https://en.wikipedia.org/wiki/Notebook_interface - Matplotlib Home Page
http://matplotlib.org/ - Matplotlib (Wikipedia)
https://en.wikipedia.org/wiki/Matplotlib - Popis barvových map modulu matplotlib.cm
https://gist.github.com/endolith/2719900#id7 - Ukázky (palety) barvových map modulu matplotlib.cm
http://matplotlib.org/examples/color/colormaps_reference.html - Galerie grafů vytvořených v Matplotlibu
https://matplotlib.org/3.2.1/gallery/ - showcase example code: xkcd.py
https://matplotlib.org/xkcd/examples/showcase/xkcd.html - Customising contour plots in matplotlib
https://philbull.wordpress.com/2012/12/27/customising-contour-plots-in-matplotlib/ - Graphics with Matplotlib
http://kestrel.nmt.edu/~raymond/software/python_notes/paper004.html - The IPython Notebook
http://ipython.org/notebook.html - nbviewer: a simple way to share Jupyter Notebooks
https://nbviewer.jupyter.org/ - Back to the Future: Lisp as a Base for a Statistical Computing System
https://www.stat.auckland.ac.nz/~ihaka/downloads/Compstat-2008.pdf - gg4clj: a simple wrapper for using R's ggplot2 in Clojure and Gorilla REPL
https://github.com/JonyEpsilon/gg4clj - Analemma: a Clojure-based SVG DSL and charting library
http://liebke.github.io/analemma/
































