Obsah
1. Celery: systém implementující asynchronní fronty úloh pro Python
2. Brokeři podporovaní nástrojem Celery
3. Instalace Celery při použití Redisu v roli brokera
4. Příprava na spuštění nástroje Celery
5. Vlastní spuštění nástroje Celery
6. Nastavení počtu paralelně spuštěných workerů
7. Vložení úlohy do fronty a vykonání úlohy
8. Uložení výsledků úloh do Redisu
9. Objekt AsyncResult vrácený po zavolání app.delay()
10. Naplánování úlohy a přečtení výsledků
12. Chování systému při spuštění většího množství úloh
13. Řetězec několika úloh, které na sobě závisí
14. Výsledky zřetězeného spouštění úloh
15. Zjištění aktuálních informací o stavu systému front
17. Obsah další části a poznámka na závěr
18. Repositář s demonstračními příklady
1. Celery: systém implementující asynchronní fronty úloh pro Python
V předchozím článku jsme se věnovali popisu užitečného nástroje Redis Queue (RQ), který slouží pro vytváření a konfiguraci takzvaných úloh (zde se ovšem používá termín job, nikoli task), které jsou ukládány do zvolené (pojmenované) fronty. Následně si úlohy z fronty vyzvedává takzvaný worker, který zadanou úlohu zpracuje a uloží případný výsledek do Redisu, odkud si tento výsledek může kdokoli, kdo zná identifikátor úlohy, přečíst. Samotná úloha (job) přitom v kontextu nástroje Redis Queue není vůbec nic složitého – jedná se totiž o pouhé určení funkce (a jejích parametrů) implementované v Pythonu a přímo volané z workeru (ono přímé volání ovšem pochopitelně vyžaduje inicializaci interpretru programovacího jazyka Python atd.).
Dnes si popíšeme sice podobně koncipovaný, ovšem v mnoha ohledech odlišný nástroj, který se jmenuje Celery. Tento nástroj je opět určený pro vývojáře používající programovací jazyk Python a znovu se jedná o systém určený pro konfiguraci a použití front úloh. Ovšem zatímco Redis Queue byl určen spíše pro přímočaré použití front, kde se nevyžadovala větší flexibilita, je tomu v případě Celery poněkud jinak, neboť tento nástroj umožňuje konfiguraci a modifikaci všech svých částí, u vybraných brokerů podporuje sledování systému (monitoring) popř. takzvané vzdálené ovládání workerů (remote control). Podporuje taktéž systém událostí (events). Navíc není Celery vázán pouze na jedinou implementaci front (přesněji na takzvaného brokera), ale je možné si podle potřeb vybrat z několika brokerů, a to včetně Amazonu SQS apod.
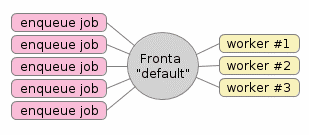
Obrázek 1: Typická konfigurace systému s frontami úloh. Zde se konkrétně používá jediná fronta nazvaná „default“, do které se mohou úlohy přidávat několika programy (těch může být libovolné množství). Samotné zpracování úloh je reprezentováno ve workerech, kterých taktéž může být libovolné množství podle požadavků aplikace, dostupných zdrojů atd. atd. Navíc je možné, aby v systému existovalo větší množství pojmenovaných front. Fronty je tak možné rozdělit podle priority, typu zpracovávaných úloh apod. Existuje dokonce jedna fronta, do níž se ukládají ty úlohy, na nichž worker zhavaroval. V systému Celery se výchozí fronta jmenuje „celery“, princip je však zachován.
2. Brokeři podporovaní nástrojem Celery
Již v úvodní kapitole jsem se zmínil o tom, že nástroj Celery je možné provozovat s různými brokery. Pod tímto názvem si můžeme představit především vlastní implementaci fronty (či front), která může být doplněna o další pomocné a administrační nástroje (konfigurace front, sledování aktuálního stavu front, load balancing, clustering atd.). V současnosti jsou plně podporování tři brokeři a jeden broker je ve stavu experimentálního použití. Pravděpodobně nejpoužívanější je RabbitMQ, ovšem setkat se můžeme i s použitím nám již známého Redisu či dokonce Amazonu SQS, který je součástí Amazon Web Services (AWS je ovšem téma na samostatný článek). V následující tabulce je vypsáno, které vlastnosti Celery jsou jednotlivými brokery podporovány a které nikoli:
| Broker | Současný stav | Monitoring | Vzdálené ovládání workerů |
|---|---|---|---|
| RabbitMQ | stabilní | ✓ | ✓ |
| Redis | stabilní | ✓ | ✓ |
| Amazon SQS | stabilní | × | × |
| Apache Zookeeper | experimentální | × | × |
Kromě vlastních brokerů je možné nastavit i systém, do kterého se ukládají výsledky práce workerů. Opět se může jednat o Redis, ovšem nakonfigurovat je možné například i Cassandru, CouchDB, Elastic Search apod. V případě potřeby se dá využít i přímo souborový systém (sdílený všemi servery s workery).
3. Instalace Celery při použití Redisu v roli brokera
V dalším textu si ukážeme způsob použití nástroje Celery společně s Redisem, který bude použit jak v roli brokera, tak i v roli backendu sloužícího pro uložení výsledků workerů (obecně je ovšem role brokera a backendu oddělena a používají se pro ni odlišné nástroje). Všechny dále uvedené příklady ovšem budou funkční i s jinými brokery, bude se odlišovat pouze volání konstruktoru třídy Celery (viz další kapitoly).
Samotná instalace nástroje Celery bude probíhat prakticky stejným způsobem, jako instalace nástroje Redis Queue. Lišit se bude pouze specifikace balíčku, protože budeme potřebovat nainstalovat variantu Celery s podporou Redisu (viz též popis konfigurace balíčku). Vzhledem k tomu, že jsou použity hranaté závorky, je bezpečnější celý název balíčku umístit do uvozovek, aby nedošlo k nechtěné expanzi zadaného názvu shellem:
$ pip3 install --user "celery[redis]"
Samotný průběh instalace je již plně v rukou nástroje pip:
Collecting celery[redis]
Downloading https://files.pythonhosted.org/packages/e8/58/2a0b1067ab2c12131b5c089dfc579467c76402475c5231095e36a43b749c/celery-4.2.1-py2.py3-none-any.whl (401kB)
100% |████████████████████████████████| 409kB 1.6MB/s
Collecting kombu<5.0,>=4.2.0 (from celery[redis])
Downloading https://files.pythonhosted.org/packages/97/61/65838c7da048e56d549e358ac19c0979c892e17dc6186610c49531d35b70/kombu-4.2.1-py2.py3-none-any.whl (177kB)
100% |████████████████████████████████| 184kB 2.4MB/s
Collecting billiard<3.6.0,>=3.5.0.2 (from celery[redis])
Downloading https://files.pythonhosted.org/packages/87/ac/9b3cc065557ad5769d0626fd5dba0ad1cb40e3a72fe6acd3d081b4ad864e/billiard-3.5.0.4.tar.gz (150kB)
100% |████████████████████████████████| 153kB 2.7MB/s
Requirement already satisfied: pytz>dev in /usr/lib/python3.6/site-packages (from celery[redis])
Requirement already satisfied: redis>=2.10.5; extra == "redis" in /home/tester/.local/lib/python3.6/site-packages (from celery[redis])
Collecting amqp<3.0,>=2.1.4 (from kombu<5.0,>=4.2.0->celery[redis])
Downloading https://files.pythonhosted.org/packages/7f/cf/12d4611fc67babd4ae250c9e8249c5650ae1933395488e9e7e3562b4ff24/amqp-2.3.2-py2.py3-none-any.whl (48kB)
100% |████████████████████████████████| 51kB 4.2MB/s
Collecting vine>=1.1.3 (from amqp<3.0,>=2.1.4->kombu<5.0,>=4.2.0->celery[redis])
Downloading https://files.pythonhosted.org/packages/10/50/5b1ebe42843c19f35edb15022ecae339fbec6db5b241a7a13c924dabf2a3/vine-1.1.4-py2.py3-none-any.whl
Installing collected packages: vine, amqp, kombu, billiard, celery
Running setup.py install for billiard ... done
Successfully installed amqp-2.3.2 billiard-3.5.0.4 celery-4.2.1 kombu-4.2.1 vine-1.1.4
100% |████████████████████████████████| 153kB 2.7MB/s
Requirement already satisfied: pytz>dev in /usr/lib/python3.6/site-packages (from celery[redis])
Requirement already satisfied: redis>=2.10.5; extra == "redis" in /home/tester/.local/lib/python3.6/site-packages (from celery[redis])
Collecting amqp<3.0,>=2.1.4 (from kombu<5.0,>=4.2.0->celery[redis])
Downloading https://files.pythonhosted.org/packages/7f/cf/12d4611fc67babd4ae250c9e8249c5650ae1933395488e9e7e3562b4ff24/amqp-2.3.2-py2.py3-none-any.whl (48kB)
100% |████████████████████████████████| 51kB 4.2MB/s
Collecting vine>=1.1.3 (from amqp<3.0,>=2.1.4->kombu<5.0,>=4.2.0->celery[redis])
Downloading https://files.pythonhosted.org/packages/10/50/5b1ebe42843c19f35edb15022ecae339fbec6db5b241a7a13c924dabf2a3/vine-1.1.4-py2.py3-none-any.whl
Installing collected packages: vine, amqp, kombu, billiard, celery
Running setup.py install for billiard ... done
Dále je vhodné pro jistotu zkontrolovat, jestli je dostupný příkaz celery, který by měl být umístěn na PATH (typicky v ~/.local/bin). V mém případě mám k dispozici dvě instalace – jednu systémovou a jednu nainstalovanou pro lokálního uživatele:
$ whereis -b celery celery: /usr/bin/celery /home/tester/.local/bin/celery
Samotný příkaz celery má k dispozici poměrně rozsáhlý systém nápovědy, která je rozdělena podle jednotlivých podpříkazů (worker, events, beat, shell, multi a amqp):
$ celery help usage: celery [options] Show help screen and exit. positional arguments: args optional arguments: -h, --help show this help message and exit --version show program's version number and exit Global Options: -A APP, --app APP -b BROKER, --broker BROKER --result-backend RESULT_BACKEND --loader LOADER --config CONFIG --workdir WORKDIR --no-color, -C --quiet, -q ---- -- - - ---- Commands- -------------- --- ------------ + Main: | celery worker | celery events | celery beat | celery shell | celery multi | celery amqp ... ... ...
4. Příprava na spuštění nástroje Celery
Po (doufejme, že úspěšné) instalaci se můžeme pokusit nástroj Celery spustit. Vzhledem k tomu, že ve funkci brokera používáme systém Redis, budeme muset ve skutečnosti nejdříve inicializovat server Redisu, a to nám již známým způsobem s využitím tohoto konfiguračního souboru připraveného tak, aby byl server viditelný pouze pro lokální nástroje:
$ cd ~/redis $ redis-server redis.conf
Dále musíme v pracovním adresáři vytvořit první implementaci workera, tj. programového kódu, který bude provádět jednotlivé úlohy (task, job). Prozatím bez dalšího podrobnějšího popisu uvedu zdrojový kód workera, ovšem v navazujících kapitolách si samozřejmě konfiguraci workerů popíšeme podrobněji:
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y
Konstruktoru Celery se předává minimálně jméno hlavního modulu, které později použijeme při spuštění nástroje celery z příkazového řádku. Toto jméno je použito mj. i pro vytvoření prefixu všech úloh vkládaných do fronty. Dále konstruktoru předáme takzvaný connection string brokera, kterého budeme využívat. Povšimněte si, že se budeme připojovat k lokálně běžícímu Redisu, jehož API je dostupné na portu 6379 (což je výchozí port pro tento nástroj):
app = Celery('tasks', broker='redis://localhost:6379/0')
Dále si povšimněte tohoto řádku:
@app.task
Jedná se o dekorátor, který jednoduchou funkci implementující vlastní práci workera promění ve skutečnou úlohu. V praxi je totiž nutné workera volat nepřímo, což je logické, protože se do fronty pouze ukládá žádost o spuštění úlohy (+ parametry úlohy), ovšem samotné volání bude provedeno nástrojem Celery asynchronně. Dekorátor tedy funkci workera obalí potřebným kódem, což je ovšem pro běžné uživatele zcela transparentní (pokud nedojde k nějaké závažnější chybě).
Zdrojový kód workera by měl být uložen v souboru nazvaném tasks.py a naleznete ho na adrese https://github.com/tisnik/message-queues-examples/blob/master/celery/example01/tasks.py.
5. Vlastní spuštění nástroje Celery
Zbývá nám vlastně již jen vlastní spuštění nástroje Celery. K tomu použijeme příkaz celery, kterému přes přepínač -A předáme jméno aplikace s implementací workerů (viz název souboru tasks.py a taktéž první parametr konstruktoru Celery), parametrem worker specifikujeme, že se má spustit instance workera a konečně parametrem –loglevel nastavíme úroveň podrobností logovacích informací (bude nás zajímat vše):
$ celery -A tasks worker --loglevel=info
-------------- celery@localhost.localdomain v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc27.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-11-30 15:53:44
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7f939094cc88
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: disabled://
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
Ihned po inicializaci systému se automaticky přidají úlohy, provede se připojení k brokeru a následně se zpřístupní API dalším utilitám:
[tasks] . tasks.add [2018-11-30 15:53:44,436: INFO/MainProcess] Connected to redis://localhost:6379/0 [2018-11-30 15:53:44,443: INFO/MainProcess] mingle: searching for neighbors [2018-11-30 15:53:45,461: INFO/MainProcess] mingle: all alone [2018-11-30 15:53:45,472: INFO/MainProcess] celery@localhost.localdomain ready.
Nyní by měl být Celery připraven přijímat úlohy a distribuovat je mezi workery.
$ celery worker --help
usage: celery worker [options]
Start worker instance.
Examples:
$ celery worker --app=proj -l info
$ celery worker -A proj -l info -Q hipri,lopri
$ celery worker -A proj --concurrency=4
$ celery worker -A proj --concurrency=1000 -P eventlet
$ celery worker --autoscale=10,0
...
...
...
6. Nastavení počtu paralelně spuštěných workerů
Počet spuštěných workerů je odvozen od počtu jader, resp. přesněji řečeno počtu jader rozeznaných jádrem operačního systému. V mém případě jsem nástroj Celery testoval na stroji s osmi jádry (přesněji se jednalo o čtyři fyzická s hyper-threadingem: vendor_id: GenuineIntel, bugs: cpu_insecure :-), takže se nejdříve podívejme, jak takový mikroprocesor vlastně vidí operační systém:
$ nproc 8
Dále spustíme Celery na pozadí a získáme ID hlavního procesu:
$ celery -A tasks worker & [1] 12477
Nakonec zjistíme, kolik podprocesů bylo vytvořeno:
$ pstree -a $! celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker ├─celery /usr/bin/celery -A tasks worker └─celery /usr/bin/celery -A tasks worker
Nikoli náhodou bylo vytvořeno (klasicky: forkem) přesně tolik podprocesů s workery, aby se při paralelním spuštění všech workerů vytížila všechna jádra (předpokládá se, že samotný worker běží v jednom vláknu, což je v klasickém CPythonu s GILem ostatně nejjednodušší řešení).
Ovšem počet podprocesů s workery je možné velmi snadno ovlivnit, a to konkrétně parametrem –concurrency. Zkusme si spuštění dvaceti podprocesů s workery:
$ celery -A tasks worker --loglevel=info --concurrency=20 & [2] 12658
Zjištění, jak nyní vypadá struktura spuštěného procesu a jeho podprocesů:
$ pstree -a $! celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 ├─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2 └─celery /usr/bin/celery -A tasks worker --loglevel=info--concurrency=2
7. Vložení úlohy do fronty a vykonání úlohy
Ve chvíli, kdy je systém Celery připravený na akceptaci úloh, si můžeme vytvořit jednoduchý skript, kterým úlohu přidáme do fronty. Podobně, jako tomu bylo v Redis Queue, i v případě Celery je tento skript psaný přímo v Pythonu a musí importovat modul s workerem (přesněji řečeno modul, v němž je implementována funkce s dekorátorem @app.task). Díky tomuto přístupu je do jisté míry zaručeno, že worker i skript pro vytváření úloh budou mít odpovídající verze, i když je nutné říci, že díky dynamičnosti Pythonu jsou snahy o přísnější kontrolu těžko implementovatelné.
Podívejme se, jak může vypadat ta nejjednodušší forma skriptu, který do fronty přidá novou úlohu. Zdrojový kód naleznete na adrese https://github.com/tisnik/message-queues-examples/blob/master/celery/example01/enqueue_work.py a vypadá následovně:
from tasks import add result = add.delay(1, 2) print(result) print(result.backend)
Za povšimnutí stojí především zvýrazněný příkaz, kterým se přidává nová úloha do fronty. Tento příkaz se podobá přímému volání funkce add (odpovídají parametry atd. atd.), ovšem namísto přímého volání se použije nepřímé zavolání add.delay(), protože dekorátor z naší prosté funkce dynamicky vytvořil objekt.
Po spuštění tohoto skriptu se vytvoří úloha, vloží se do fronty a následně se vypíše informace o objektu, který add.delay vrací. Proměnná s tímto objektem je sice pojmenována result, ale samozřejmě se nejedná o výsledek práce workera, neboť ten je spuštěn asynchronně:
$ python3 enqueue_work.py 23cca8ee-49d8-487f-b1d9-26789bf52e5b <celery.backends.base.DisabledBackend object at 0x7f38b2d7f5c0>
Současně by se na terminálu se spuštěným procesem celery měly objevit informace o tom, že úloha byla přijata a posléze i informace o jejím dokončení:
[2018-11-30 15:55:47,253: INFO/MainProcess] Received task: tasks.add[ec190c42-1568-4be2-8db2-01cce0036543] [2018-11-30 15:55:47,255: INFO/ForkPoolWorker-7] Task tasks.add[ec190c42-1568-4be2-8db2-01cce0036543] succeeded in 0.0002822577953338623s: 3
8. Uložení výsledků úloh do Redisu
Worker, který byl ukázán v předchozích kapitolách, sice počítal výsledek (zde konkrétně součet hodnot), ale tento výsledek byl po dokončení práce zahozen, protože jsme nenakonfigurovali žádný backend pro (dočasné) uložení výsledků. To lze snadno napravit; samozřejmě za předpokladu, že je důležité výsledky workerů přímo využívat. Backend se nakonfiguruje přímo v souboru tasks.py, v němž je implementován vlastní kód workera:
from celery import Celery
app = Celery('tasks',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/0')
@app.task
def add(x, y):
return x + y
Pokud se nyní proces s celery restartuje, měla by se objevit i informace o nastaveném backendu – viz zvýrazněná část:
$ celery -A tasks worker --loglevel=info
-------------- celery@localhost.localdomain v4.2.1 (windowlicker)
---- **** -----
--- * *** * -- Linux-4.14.11-200.fc26.x86_64-x86_64-with-fedora-26-Twenty_Six 2018-12-05 13:40:10
-- * - **** ---
- ** ---------- [config]
- ** ---------- .> app: tasks:0x7fe0848c8cc0
- ** ---------- .> transport: redis://localhost:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 8 (prefork)
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** -----
-------------- [queues]
.> celery exchange=celery(direct) key=celery
Možnost ukládání výsledků workerů využijeme v dalších příkladech.
9. Objekt AsyncResult vrácený po zavolání app.delay()
Výsledkem vložení úlohy do fronty je objekt typu AsyncResult. Tento objekt má několik užitečných atributů a metod. Mezi atributy patří například:
| Atribut | Význam |
|---|---|
| id | jednoznačné ID úlohy |
| backend | backend použitý pro uložení výsledků |
| result | výsledek, pokud byla úloha dokončena |
| state | aktuální stav úlohy (PENDING, STARTED, RETRY, FAILURE nebo SUCCESS) |
Dále tento objekt nabízí metody, které je možné použít pro získání dalších informací o úloze:
| Metoda | Význam |
|---|---|
| ready() | dotaz na stav úlohy (vrací pravdivostní hodnotu) |
| failed() | dotaz na stav úlohy (vrací pravdivostní hodnotu) |
| forget() | odstranění výsledků úlohy z backendu |
| get() | získání výsledků popř. čekání na dokončení |
Důležité jsou především metody get() pro přečtení výsledků a forget() pro jejich odstranění z backendu (ovšem nic nám nebrání výsledky na backendu ponechat a zpracovat je někdy v budoucnosti).
10. Naplánování úlohy a přečtení výsledků
Další varianta skriptu pro naplánování úlohy je nepatrně složitější, než varianta první. Je tomu tak z toho důvodu, že úlohu nejenom naplánujeme, ale počkáme si na její dokončení. K tomuto účelu je zavolána metoda AsyncResult.get() s parametrem timeout=5, kterým omezujeme čas čekání na maximálně pět sekund. Dále by bylo možné specifikovat i parametr interval pro nastavení intervalu mezi testy, zda je úloha dokončena. Pro déletrvající úlohy tak můžeme nastavit čas čekání klidně na jednu hodinu (3600) a interval na jednu minutu (60):
from tasks import add result = add.delay(1, 2) print(result) print(result.backend) print(result.ready()) print(result.get()) print(result.ready()) print(result.get(timeout=5)) result.forget()
Po spuštění tohoto skriptu se vypíšou přibližně tyto zprávy:
$ python3 enqueue_work.py f6c9e2a9-7e7a-4b94-9343-726bbd4f3161 <celery.backends.redis.RedisBackend object at 0x7f901a45e6a0> False 3 True 3
11. Konfigurace workerů
Konfigurace brokeru a backendu stylem, který jsme si ukázali v předchozích kapitolách, je vhodná pouze pro malé aplikace (resp. pro malé workery). V praxi se však používá poněkud odlišný přístup: veškerá konfigurace, která souvisí s workerem, se uloží do souboru nazvaného celeryconfig.py (jméno sice nemusí být dodrženo, ale je dobré být konzistentní se zbytkem světa). Jedná se o běžný Pythonovský soubor, který ovšem typicky obsahuje pouze nastavení parametrů workeru a žádný jiný kód. Takový soubor může vypadat následovně:
broker_url = 'redis://localhost:6379/0' result_backend = 'redis://localhost:6379/0' task_serializer = 'json' result_serializer = 'json' accept_content = ['json'] timezone = 'Europe/Prague' enable_utc = True task_default_queue = 'celery' worker_log_color = True
Načtení konfigurace ve workerovi zařídí řádek:
app.config_from_object('celeryconfig')
Celý kód workera (soubor tasks.py) se tedy změní následujícím způsobem:
from celery import Celery
app = Celery('tasks')
app.config_from_object('celeryconfig')
@app.task
def add(x, y):
return x + y
Zatímco skript pro naplánování úlohy zůstává naprosto stejný:
from tasks import add result = add.delay(1, 2) print(result) print(result.backend) print(result.ready()) print(result.get()) print(result.ready()) print(result.get(timeout=5)) result.forget()
12. Chování systému při spuštění většího množství úloh
Pro zajímavost si ukažme, jak se změní chování Celery ve chvíli, kdy zadáme větší množství úloh. Připomínám, že test bude proveden na stroji s osmi jádry, tudíž bylo spuštěno osm procesů s workery.
Implementace workera se změní jen nepatrně – přidáme pouze tisk informací na standardní výstup a dvousekundové zpoždění, které simuluje těžkou a déletrvající práci:
from time import sleep
from celery import Celery
app = Celery('tasks')
app.config_from_object('celeryconfig')
@app.task
def add(x, y):
print("Working, received parameters {} and {}".format(x, y))
sleep(2)
print("Done")
return x + y
Odlišná ovšem bude implementace skriptu pro naplánování úloh. Nejdříve v první programové smyčce co nejrychleji naplánujeme deset úloh a posléze se ve druhé smyčce pokusíme o přečtení jejich výsledků a popř. čekání na výsledky:
from tasks import add
async_tasks = []
for i in range(10):
async_tasks.append(add.delay(i, i))
for task in async_tasks:
print(task)
print(task.backend)
print(task.ready())
print(task.get())
print(task.get(timeout=5))
task.forget()
Podívejme se, jaké informace se vypíšou na terminálu s běžícím systémem Celery. Vidíme, že print() ve workerech je zobrazen v logu jako varování, ovšem zajímavější je proložení informací o první části úlohy (před sleep) s informací o jejím dokončení. Navíc si povšimněte řetězců ForkPoolWorker-X. Tyto řetězce explicitně označují jeden z osmi procesů. Je vidět, že se workeři skutečně o práci dělí:
[2018-12-04 16:08:16,142: INFO/MainProcess] Received task: tasks.add[abfc4c46-1fbd-4041-bbea-7ac53a66249a] [2018-12-04 16:08:16,144: INFO/MainProcess] Received task: tasks.add[8059b2bc-2f05-43f9-ae99-a8973d21e387] [2018-12-04 16:08:16,144: WARNING/ForkPoolWorker-3] Working, received parameters 1 and 1 [2018-12-04 16:08:16,144: WARNING/ForkPoolWorker-2] Working, received parameters 0 and 0 [2018-12-04 16:08:16,145: INFO/MainProcess] Received task: tasks.add[2d7694fb-27b3-4cff-a005-b4702dd0445b] [2018-12-04 16:08:16,147: INFO/MainProcess] Received task: tasks.add[a8cac06e-1a27-4d18-9132-69d62e7d31d1] [2018-12-04 16:08:16,148: WARNING/ForkPoolWorker-5] Working, received parameters 2 and 2 [2018-12-04 16:08:16,148: WARNING/ForkPoolWorker-6] Working, received parameters 3 and 3 [2018-12-04 16:08:16,149: INFO/MainProcess] Received task: tasks.add[f017b5d9-9e1c-4515-81d3-36f30b28cd84] [2018-12-04 16:08:16,154: INFO/MainProcess] Received task: tasks.add[afdbdb0c-e5b8-4dbd-9978-1b430d736854] [2018-12-04 16:08:16,156: WARNING/ForkPoolWorker-8] Working, received parameters 4 and 4 [2018-12-04 16:08:16,156: WARNING/ForkPoolWorker-1] Working, received parameters 5 and 5 [2018-12-04 16:08:16,158: INFO/MainProcess] Received task: tasks.add[d65daef0-9c96-4766-a9af-8309b763af65] [2018-12-04 16:08:16,162: INFO/MainProcess] Received task: tasks.add[2f37a8fb-5529-4e89-a1a0-3af736d276aa] [2018-12-04 16:08:16,163: WARNING/ForkPoolWorker-7] Working, received parameters 6 and 6 [2018-12-04 16:08:16,163: WARNING/ForkPoolWorker-4] Working, received parameters 7 and 7 [2018-12-04 16:08:16,165: INFO/MainProcess] Received task: tasks.add[0ee1a155-9f9b-40ae-8e24-c84088ff741b] [2018-12-04 16:08:16,169: INFO/MainProcess] Received task: tasks.add[fb639532-cdba-4d8e-b0f2-9485b76a24d6] [2018-12-04 16:08:18,147: WARNING/ForkPoolWorker-3] Done [2018-12-04 16:08:18,147: WARNING/ForkPoolWorker-2] Done [2018-12-04 16:08:18,149: INFO/ForkPoolWorker-2] Task tasks.add[abfc4c46-1fbd-4041-bbea-7ac53a66249a] succeeded in 2.0046470165252686s: 0 [2018-12-04 16:08:18,149: INFO/ForkPoolWorker-3] Task tasks.add[8059b2bc-2f05-43f9-ae99-a8973d21e387] succeeded in 2.0048255398869514s: 2 [2018-12-04 16:08:18,150: WARNING/ForkPoolWorker-6] Done [2018-12-04 16:08:18,151: WARNING/ForkPoolWorker-5] Done [2018-12-04 16:08:18,152: INFO/ForkPoolWorker-6] Task tasks.add[a8cac06e-1a27-4d18-9132-69d62e7d31d1] succeeded in 2.0038469433784485s: 6 [2018-12-04 16:08:18,153: WARNING/ForkPoolWorker-3] Working, received parameters 9 and 9 [2018-12-04 16:08:18,153: INFO/ForkPoolWorker-5] Task tasks.add[2d7694fb-27b3-4cff-a005-b4702dd0445b] succeeded in 2.0052460320293903s: 4 [2018-12-04 16:08:18,153: WARNING/ForkPoolWorker-2] Working, received parameters 8 and 8 [2018-12-04 16:08:18,157: WARNING/ForkPoolWorker-8] Done [2018-12-04 16:08:18,158: WARNING/ForkPoolWorker-1] Done [2018-12-04 16:08:18,158: INFO/ForkPoolWorker-8] Task tasks.add[f017b5d9-9e1c-4515-81d3-36f30b28cd84] succeeded in 2.0022214762866497s: 8 [2018-12-04 16:08:18,158: INFO/ForkPoolWorker-1] Task tasks.add[afdbdb0c-e5b8-4dbd-9978-1b430d736854] succeeded in 2.002465270459652s: 10 [2018-12-04 16:08:18,166: WARNING/ForkPoolWorker-7] Done [2018-12-04 16:08:18,166: WARNING/ForkPoolWorker-4] Done [2018-12-04 16:08:18,167: INFO/ForkPoolWorker-4] Task tasks.add[2f37a8fb-5529-4e89-a1a0-3af736d276aa] succeeded in 2.004064477980137s: 14 [2018-12-04 16:08:18,167: INFO/ForkPoolWorker-7] Task tasks.add[d65daef0-9c96-4766-a9af-8309b763af65] succeeded in 2.0041318498551846s: 12 [2018-12-04 16:08:20,156: WARNING/ForkPoolWorker-3] Done [2018-12-04 16:08:20,156: WARNING/ForkPoolWorker-2] Done [2018-12-04 16:08:20,157: INFO/ForkPoolWorker-3] Task tasks.add[fb639532-cdba-4d8e-b0f2-9485b76a24d6] succeeded in 2.0045981109142303s: 18 [2018-12-04 16:08:20,157: INFO/ForkPoolWorker-2] Task tasks.add[0ee1a155-9f9b-40ae-8e24-c84088ff741b] succeeded in 2.0046060904860497s: 16
13. Řetězec několika úloh, které na sobě závisí
Poměrně často se můžeme setkat s požadavkem, aby se po zpracování jedné úlohy spustila úloha další, přičemž tato další úloha přebere již vypočtené mezivýsledky. Systém Celery sice není pro tyto účely zcela nejvhodnějším nástrojem, ovšem v případě, že graf závislostí úloh není příliš rozsáhlý, ho můžeme využít i v této oblasti. Nejprve upravíme workera takovým způsobem, aby obsahoval dvě funkce implementující dvě různé úlohy. Pro jednoduchost se bude jednat o úlohy součtu a součinu. Obě funkce musí používat dekorátor @app.task:
from time import sleep
from celery import Celery
app = Celery('tasks')
app.config_from_object('celeryconfig')
@app.task
def add(x, y):
print("Working, received parameters {} and {} to add".format(x, y))
sleep(2)
result = x + y
print("Done with result {}".format(result))
return result
@app.task
def multiply(x, y):
print("Working, received parameters {} and {} to multiply".format(x, y))
sleep(2)
result = x * y
print("Done with result {}".format(result))
return result
Lišit se ovšem bude spuštění úloh. Budeme chtít, aby se výsledek součtu (první úloha) předal do úlohy druhé, v níž se výsledek vynásobí třemi. V Celery se takovéto zřetězení zapíše nepovinným parametrem link. Navíc namísto volání app.delay použijeme volání app.apply_async, které provádí stejnou činnost (naplánování úlohy), ovšem je zde možné rozlišit parametry úlohy od parametrů samotné funkce app.apply_async. Parametry úlohy se nyní předávají v n-tici:
from tasks import add, multiply add.apply_async((1, 2), link=multiply.s(3))
Samozřejmě můžeme naprosto stejným způsobem spustit větší množství úloh:
from tasks import add, multiply
for i in range(10):
add.apply_async((i, i + 1), link=multiply.s(i))
14. Výsledky zřetězeného spouštění úloh
Pokud spustíme pouze první skript s dvěma zřetězenými úlohami, můžeme v terminálu se spuštěným celery sledovat, jak se nejprve zavolá add a posléze multiply (zvýrazněný text):
[2018-12-04 20:53:48,759: INFO/MainProcess] Received task: tasks.add[19aa842f-a5a9-41ad-ac6d-0bd72b7ee6f5] [2018-12-04 20:53:48,760: WARNING/ForkPoolWorker-2] Working, received parameters 1 and 2 to add [2018-12-04 20:53:50,762: WARNING/ForkPoolWorker-2] Done with result 3 [2018-12-04 20:53:50,767: INFO/ForkPoolWorker-2] Task tasks.add[19aa842f-a5a9-41ad-ac6d-0bd72b7ee6f5] succeeded in 2.0068626664578915s: 3 [2018-12-04 20:53:50,767: INFO/MainProcess] Received task: tasks.multiply[ad5ec5c6-21df-46a6-a69f-0622e41a905b] [2018-12-04 20:53:50,769: WARNING/ForkPoolWorker-2] Working, received parameters 3 and 3 to multiply [2018-12-04 20:53:52,772: WARNING/ForkPoolWorker-2] Done with result 9 [2018-12-04 20:53:52,773: INFO/ForkPoolWorker-2] Task tasks.multiply[ad5ec5c6-21df-46a6-a69f-0622e41a905b] succeeded in 2.004228986799717s: 9
Pokud je naplánovaných více úloh pro součet a následné násobení (celkem dvacet úloh), budou se o jednotlivé úlohy starat různí workeři:
[2018-12-04 20:55:01,396: INFO/MainProcess] Received task: tasks.add[2a603183-42cf-4526-9d16-c6211d00f758] [2018-12-04 20:55:01,397: INFO/MainProcess] Received task: tasks.add[90332b97-5508-4d1d-9e3c-3e661fa75771] [2018-12-04 20:55:01,397: WARNING/ForkPoolWorker-1] Working, received parameters 1 and 2 to add [2018-12-04 20:55:01,397: WARNING/ForkPoolWorker-2] Working, received parameters 0 and 1 to add [2018-12-04 20:55:01,397: INFO/MainProcess] Received task: tasks.add[96ff6943-8cbe-4ab2-83d5-aa761aa53259] [2018-12-04 20:55:01,399: INFO/MainProcess] Received task: tasks.add[e0cbbb1f-2ad6-4a76-a0ed-3621b3b40ab9] [2018-12-04 20:55:01,399: INFO/MainProcess] Received task: tasks.add[8eca11fd-6b46-40ff-aa08-2bb0eb77bdec] [2018-12-04 20:55:01,400: INFO/MainProcess] Received task: tasks.add[eabdb75b-6e58-411b-971c-4b2a7293ddc2] [2018-12-04 20:55:01,400: INFO/MainProcess] Received task: tasks.add[31c5bac7-6b23-4d85-aed8-9a006efc4327] [2018-12-04 20:55:01,401: INFO/MainProcess] Received task: tasks.add[f3ec7d5a-49a4-40fc-8b7d-63c5882ceb21] [2018-12-04 20:55:01,401: INFO/MainProcess] Received task: tasks.add[5b3bb032-d6ba-4ac6-8bdd-f05023355c1d] [2018-12-04 20:55:01,402: INFO/MainProcess] Received task: tasks.add[fee99828-f183-4805-a7cb-53950e99c1ba] [2018-12-04 20:55:03,399: WARNING/ForkPoolWorker-2] Done with result 1 [2018-12-04 20:55:03,399: WARNING/ForkPoolWorker-1] Done with result 3 [2018-12-04 20:55:03,403: INFO/ForkPoolWorker-2] Task tasks.add[2a603183-42cf-4526-9d16-c6211d00f758] succeeded in 2.0061469674110413s: 1 [2018-12-04 20:55:03,403: INFO/ForkPoolWorker-1] Task tasks.add[90332b97-5508-4d1d-9e3c-3e661fa75771] succeeded in 2.006296880543232s: 3 [2018-12-04 20:55:03,406: WARNING/ForkPoolWorker-2] Working, received parameters 2 and 3 to add [2018-12-04 20:55:03,406: WARNING/ForkPoolWorker-1] Working, received parameters 3 and 4 to add [2018-12-04 20:55:04,332: INFO/MainProcess] Received task: tasks.multiply[1674a9b3-a7f1-4173-9dfd-ea615cb34b70] [2018-12-04 20:55:04,335: INFO/MainProcess] Received task: tasks.multiply[84928082-373d-4b34-bb13-f3b25561b7fa] [2018-12-04 20:55:05,409: WARNING/ForkPoolWorker-1] Done with result 7 [2018-12-04 20:55:05,409: WARNING/ForkPoolWorker-2] Done with result 5 ... ... ... [2018-12-04 20:55:19,469: WARNING/ForkPoolWorker-2] Working, received parameters 17 and 8 to multiply [2018-12-04 20:55:19,469: WARNING/ForkPoolWorker-1] Working, received parameters 19 and 9 to multiply [2018-12-04 20:55:21,472: WARNING/ForkPoolWorker-2] Done with result 136 [2018-12-04 20:55:21,472: WARNING/ForkPoolWorker-1] Done with result 171 [2018-12-04 20:55:21,473: INFO/ForkPoolWorker-2] Task tasks.multiply[0f2801bb-4b0c-42e7-86f3-63abf4bce32e] succeeded in 2.0041882805526257s: 136 [2018-12-04 20:55:21,473: INFO/ForkPoolWorker-1] Task tasks.multiply[041480fa-f0d3-46c8-916a-d42590ec9f0e] succeeded in 2.004200141876936s: 171
15. Zjištění aktuálních informací o stavu systému front
Pro zjištění, zda systém Celery běží a jak je naškálovaný, použijeme tento příkaz:
$ celery -A tasks status celery@localhost.localdomain: OK 1 node online.
V případě, že budeme chtít zjistit výsledek nějaké úlohy (který je uložen v backendu), použijeme příkaz:
$ celery -A tasks result -t tasks.multiply 0f2801bb-4b0c-42e7-86f3-63abf4bce32e 136
16. Příkaz celery inspect
Dále můžeme zjistit, zda a jaké úlohy jsou právě aktivní. Vrátí se tolik řádků, kolik běží úloh:
$ celery -A tasks inspect active
-> celery@localhost.localdomain: OK
* {'id': '44b3813e-08ab-4b6f-9518-9fdeee1af0d1', 'name': 'tasks.add', 'args': '(5, 6)', 'kwargs': '{}', 'type': 'tasks.add', 'hostname': 'celery@localhost.localdomain', 'time_start': 1543953820.9402742, 'acknowledged': True, 'delivery_info': {'exchange': '', 'routing_key': 'celery', 'priority': 0, 'redelivered': None}, 'worker_pid': 15706}
Tento příkaz ovšem může vrátit pouze zprávu „empty“, pokud žádná úloha neběží:
$ celery -A tasks inspect active
-> celery@localhost.localdomain: OK
- empty -
Zajímavé je taktéž zjištění statistických informací o běžícím Celery. Povšimněte si především nastavení „pool“ se sadou workerů a „writes“ s informacemi o zápisu do backendu:
$ celery -A tasks inspect stats
-> celery@localhost.localdomain: OK
{
"broker": {
"alternates": [],
"connect_timeout": 4,
"failover_strategy": "round-robin",
"heartbeat": 120.0,
"hostname": "localhost",
"insist": false,
"login_method": null,
"port": 6379,
"ssl": false,
"transport": "redis",
"transport_options": {},
"uri_prefix": null,
"userid": null,
"virtual_host": "0"
},
"clock": "4",
"pid": 15699,
"pool": {
"max-concurrency": 8,
"max-tasks-per-child": "N/A",
"processes": [
15703,
15704,
15705,
15706,
15707,
15708,
15709,
15710
],
"put-guarded-by-semaphore": false,
"timeouts": [
0,
0
],
"writes": {
"all": "12.50%, 10.00%, 12.50%, 15.00%, 12.50%, 10.00%, 12.50%, 15.00%",
"avg": "12.50%",
"inqueues": {
"active": 0,
"total": 8
},
"raw": "5, 4, 5, 6, 5, 4, 5, 6",
"strategy": "fair",
"total": 40
}
},
...
...
e ...
17. Obsah další části a poznámka na závěr
S dalšími možnostmi nástroje Celery se seznámíme ve druhé a současně i poslední části tohoto článku. Ukážeme si například práci s takzvaným canvasem a taktéž užitečný nástroj Flower pro sledování a vizualizaci úloh (flower zde neznamená květ, ale jde o odvozeninu ze slova „flow“).

Obrázek 1: Pomocný nástroj pro zobrazení událostí a výsledků práce workerů.

Na závěr si dovolím krátké odbočení, které ovšem souvisí jak s dnešním článkem, tak i s paralelně běžícím seriálem o programovacím jazyku Go. Již v úvodním článku jsme si řekli, že na Go přechází (většinou) nikoli programátoři používající jazyky C nebo C++, ale programátoři, kteří paralelně pracují s Pythonem nebo Node.js. Pochopitelně je vhodné, aby oba ekosystémy (Go+Python) používaly podobné nástroje a právě z tohoto důvodu vznikl zajímavý projekt gocelery, s nímž se pravděpodobně seznámíme v samostatném článku (ovšem později).
18. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů naprogramovaných v Pythonu byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/message-queues-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce. Každý příklad se skládá minimálně ze dvou skriptů – implementace workera a skriptu pro uložení nové úlohy do fronty:
19. Odkazy na Internetu
- celery na PyPi
https://pypi.org/project/celery/ - Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Použití nástroje RQ (Redis Queue) pro správu úloh zpracovávaných na pozadí
https://www.root.cz/clanky/pouziti-nastroje-rq-redis-queue-pro-spravu-uloh-zpracovavanych-na-pozadi/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Python Celery & RabbitMQ Tutorial
https://tests4geeks.com/python-celery-rabbitmq-tutorial/ - Flower: Real-time Celery web-monitor
http://docs.celeryproject.org/en/latest/userguide/monitoring.html#flower-real-time-celery-web-monitor - Asynchronous Tasks With Django and Celery
https://realpython.com/asynchronous-tasks-with-django-and-celery/ - First Steps with Celery
http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html - node-celery
https://github.com/mher/node-celery - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq - Running multiple workers using Celery
https://serverfault.com/questions/655387/running-multiple-workers-using-celery - celery — Distributed processing
http://docs.celeryproject.org/en/latest/reference/celery.html - Chains
https://celery.readthedocs.io/en/latest/userguide/canvas.html#chains - Routing
http://docs.celeryproject.org/en/latest/userguide/routing.html#automatic-routing - Celery Distributed Task Queue in Go
https://github.com/gocelery/gocelery/ - Python Decorators
https://wiki.python.org/moin/PythonDecorators





































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU