
Obsah
1. Komunikační strategie Publish-Subscribe
2. Zpracování většího množství zpráv při použití strategie Publish-Subscribe
3. Nastavení tématu (topic) pro strategii Publish-Subscribe
4. Implementace producenta zpráv
5. Implementace různých konzumentů zpráv připojených k nastaveným tématům
6. Komunikační strategie Request-Response
7. Implementace klienta používajícího strategii Request-Response
8. Implementace serveru zpracovávajícího požadavky
9. Server zpracovávající dotazy v jediném vláknu
10. Chování serveru při zpracování velkého množství dotazů
11. Komunikační strategie Survey
14. Ukázka poslání otázky a zpracování odpovědí
18. Repositář s demonstračními příklady
19. Odkazy na předchozí části seriálu o message brokerech
1. Komunikační strategie Publish-Subscribe
V předchozí části seriálu o message brokerech jsme se seznámili s některými možnostmi poskytovanými nativní knihovnou (naprogramovanou v céčku) nazvanou nanomsg. Jedná se o ideového nástupce knihovny ØMQ, kterou jsme si již v tomto seriálu popsali [1] [2] [3] [4]. Oproti ØMQ došlo z pohledu vývojáře k několika podstatným změnám a současně i ke zjednodušením, takže se například nemusíme starat o takzvaný kontext. S využitím knihovny nanomsg je možné vytvářet aplikace (resp. části aplikace), které mezi sebou komunikují pomocí šesti typů strategií, které jsou vypsány v následující tabulce:
| # | Strategie/vzor | Stručný popis významu strategie |
|---|---|---|
| 1 | PAIR | jedna z nejjednodušších komunikačních strategií s dvojicí uzlů a vazbou 1:1; komunikace je obecně obousměrná (samozřejmě lze použít i komunikaci jednosměrnou) |
| 2 | BUS | složitější strategie, v níž se používá obecnější vazba M:N; tuto strategii si popíšeme v závěrečné části článku |
| 3 | PUBSUB | klasická komunikační strategie PUB-SUB neboli PUBLISH-SUBSCRIBE |
| 4 | REQREP | klasická komunikační strategie REQ-REP neboli REQUEST-RESPONSE, bude popsána v navazujících kapitolách |
| 5 | PIPELINE | jednosměrná komunikace buď s vazbami 1:1 (jeden vysílač a jeden přijímač), popř. mezi více vysílači a několika přijímači |
| 6 | SURVEY | speciální strategie umožňující získat stav více uzlů (procesů) jediným dotazem a mnoha odpovědmi; tato zcela nová strategie bude popsána v navazujících kapitolách |
Strategii pojmenovanou PIPELINE a zajišťující jednosměrný přenos zpráv od vysílající aplikace (vlákna, procesu) k aplikaci přijímající jsme si již popsali minule, konkrétně v osmé kapitole. Jedná se čistě o jednosměrnou komunikaci naznačenou na prvním obrázku:

Obrázek 1: Jednosměrná komunikace využívající strategii PIPELINE.
Složitější komunikační schéma je zajištěno strategií PAIR popsané minule ve dvanácté kapitole, která umožňuje buď jednosměrné posílání zpráv z prvního uzlu do uzlu druhého:

Obrázek 2: Jednosměrná komunikace využívající strategii PAIR-PAIR.
nebo (a to častěji) obousměrné posílání zpráv:

Obrázek 3: Obousměrná komunikace využívající strategii PAIR-PAIR.
A konečně jsme si minule v sedmnácté kapitole ukázali (i když prozatím ve stručnosti) strategii typu PUB-SUB či zkráceně pouze PUBSUB. Tato velmi často používaná strategie umožňuje rozesílat zprávy libovolnému množství příjemců (či v mezním případě žádnému příjemci):
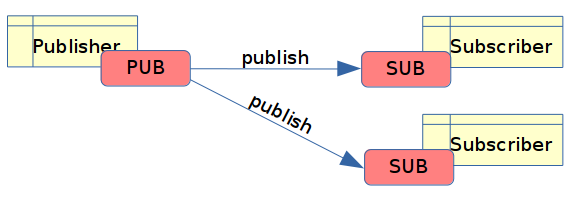
Obrázek 4: Jednosměrná komunikace využívající strategii PUB-SUB.
V dnešním článku nejdříve dokončíme popis strategie PUB-SUB a posléze se zaměříme na tři zbývající strategie REQREP, SURVEY a BUS, které jsou již nepatrně složitější, ovšem v některých případech i užitečnější.
Všechny dále popsané demonstrační příklady budou vyvinuty v programovacím jazyku C (většina jich je kompatibilních s ANSI C, pouze u některých požadujeme funkce, které v tomto standardu neexistují), protože rozhraními pro další programovací jazyky se budeme zabývat v navazující části tohoto seriálu. Příklady jsou navíc napsány s ohledem na co největší stručnost zápisu, takže u některých z nich nejsou provedeny všechny kontroly chyb, jež by se ovšem v produkčním kódu pochopitelně měly použít (na případné možnosti vylepšení se ovšem taktéž zaměříme).
Pro překlad, slinkování a spuštění je u každého příkladu použit Makefile, takže využijete příkaz/nástroj make, který by měl být nainstalován.
2. Zpracování většího množství zpráv při použití strategie Publish-Subscribe
V úvodním článku o knihovně nanomsg jsme si mj. popsali i velmi často používanou komunikační strategii nazvanou PUB-SUB, v níž spolu komunikují dva typy uzlů: zdroje zpráv (publishers) a konzumenti zpráv (subscribers). Konzumenti se mohou k odebírání zpráv kdykoli přihlásit a kdykoli se také odpojit, což zdroj zpráv nijak neovlivní – ten bude posílat zprávy nezávisle na tom, kdo je přijímá (v knihovně nanomsg se i filtrace zpráv na základě témat/topiců provádí až na straně konzumenta, nikoli na straně zdroje!).
Toto chování, v němž zcela cíleně chybí většina kontrolních a řídicích Lmechanismů, má ovšem jeden důsledek, který je poměrně problematický a který vyplývá z toho, že nanomsg ve skutečnosti není klasickým message brokerem, ale jen „pouhou“ knihovnou: pokud konzument zpráv nebude mít k dispozici dostatečné množství prostředků ke zpracování zpráv, může se stát, že nějakou zprávu nepřijme. Popsané chování si můžeme velmi snadno odsimulovat, a to tak, že vytvoříme producenta, který odešle předem nastavený počet zpráv, ovšem mezi posláním zpráv nebudou žádné pauzy – producent tedy bude zprávy posílat maximální možnou rychlostí.
Úplný zdrojový kód producenta vypadá následovně:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/pubsub.h>
const int MAX_MESSAGES = 1000;
const char *URL = "ipc:///tmp/example7";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void send_message(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
sleep(1);
}
void publisher(const char *url)
{
int socket;
int endpoint;
int i;
if ((socket = nn_socket(AF_SP, NN_PUB)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Remote endpoint bound to the socket");
for (i=0; i < MAX_MESSAGES; i++) {
char buffer[45];
int number = rand() % 10000;
sprintf(buffer, "Hello, this is my top secret PIN: %04d", number);
send_message(socket, buffer);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
publisher(URL);
return 0;
}
Samotný konzument, jehož úplný zdrojový kód je zobrazen pod tímto odstavcem, zůstal prakticky ve stejné podobě, s jakou jsme se seznámili v předchozím článku:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/pubsub.h>
const char *URL = "ipc:///tmp/example7";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_message(const int socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void subscriber(const char *url)
{
int socket;
int endpoint;
int messages;
if ((socket = nn_socket(AF_SP, NN_SUB)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if (nn_setsockopt(socket, NN_SUB, NN_SUB_SUBSCRIBE, "", 0) < 0) {
report_error("nn_setsockopt");
}
if ((endpoint = nn_connect(socket, url)) < 0) {
report_error("nn_connect");
}
puts("Endpoint connected to socket");
puts("Waiting for messages...");
while (1) {
receive_message(socket);
messages++;
printf("Processed %d messages so far\n", messages);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(int argc, char **argv)
{
subscriber(URL);
return 0;
}
Podívejme se ještě na soubor Makefile využitý jak pro překlad, tak i spuštění producenta i konzumenta:
CC=gcc
LINKER=gcc
LIBS=nanomsg
CFLAGS=-O0 -Wall -ansi -pedantic
LFLAGS=-l$(LIBS)
LIBRARY_PATH=/usr/local/lib64/
.PHONY: clean run_publisher run_subscriber
all: publisher subscriber
%.o: %.c
$(CC) -c -o $@ $(CFLAGS) $<
publisher: publisher.o
$(CC) -o $@ $(LFLAGS) $<
subscriber: subscriber.o
$(CC) -o $@ $(LFLAGS) $<
clean:
rm -f publisher.o \
rm -f subscriber.o \
rm -f publisher \
rm -f subscriber
run_publisher:
LD_LIBRARY_PATH=$(LIBRARY_PATH) ./publisher
run_subscriber:
LD_LIBRARY_PATH=$(LIBRARY_PATH) ./subscriber
Podívejme se nyní na chování takto vytvořené architektury sestávající ze dvou komunikujících uzlů – jednoho producenta a jednoho konzumenta zpráv. Nejprve, například z nového terminálu, přeložíme a spustíme konzumenta zpráv:
$ make consumer $ make run_consumer
Dále pochopitelně budeme muset přeložit a spustit producenta:
$ make producer $ make run_producer
Chování producenta je jednoduché a snadno pochopitelné – bude postupně vytvářet a posílat (publikovat) zadaný počet zpráv.
Konzument se bude snažit tyto zprávy přijímat, ovšem (v závislosti na mnoha faktorech) se mu to nemusí vždy podařit a může nějakou zprávu vynechat:
... ... ... Processed 564 messages so far Received message 'Hello, this is my top secret PIN: 8382' with length 39 bytes Processed 565 messages so far Received message 'Hello, this is my top secret PIN: 5421' with length 39 bytes Processed 566 messages so far
Na toto chování můžeme v praxi narazit v mnoha případech. Zde se konkrétně jedná o fakt, že je jak producent, tak i konzument spuštěn na jednom počítači, takže záleží na tom, kdy dojde k přepnutí kontextu. U aplikací, jejichž uzly jsou umístěny na různých počítačích a pro komunikaci se používá síť, se může situace dále zkomplikovat. Jedno z možných řešení spočívá v použití takzvaného zařízení (device) a v lepší správě bufferů na straně producenta, ovšem my si vyzkoušíme, jak se chování změní ve chvíli, kdy se mezi posláním jednotlivých zpráv vloží krátká pauza. Úprava bude provedena následujícím způsobem:
void send_message(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
usleep(100*1000);
}
S výsledkem, který je již mnohem lepší:
... ... ... Processed 96 messages so far Received message '8586 is my top secret PIN' with length 26 bytes Processed 97 messages so far Received message '8094 is my top secret PIN' with length 26 bytes Processed 98 messages so far Received message '7539 is my top secret PIN' with length 26 bytes Processed 99 messages so far
Zbývá nám vyřešit ještě jeden problém, který spočívá v tom, že konzument nepřijme první poslanou zprávu. Je to ostatně patrné i při pohledu na jeho výstup zobrazený před tímto odstavcem.
Toto chování je ve skutečnosti možné napravit, a to zcela jednoduše. Postačuje totiž, aby se vložila krátká pauza mezi voláním funkcí nn_bind() a vlastním posíláním zpráv:
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Remote endpoint bound to the socket");
sleep(1);
for (i=0; i < MAX_MESSAGES; i++) {
char buffer[45];
int number = rand() % 10000;
sprintf(buffer, "%04d is my top secret PIN", number);
send_message(socket, buffer);
}
Výsledek je již mnohem lepší a bude odpovídat očekávanému chování:
... ... ... Processed 97 messages so far Received message '8586 is my top secret PIN' with length 26 bytes Processed 98 messages so far Received message '8094 is my top secret PIN' with length 26 bytes Processed 99 messages so far Received message '7539 is my top secret PIN' with length 26 bytes Processed 100 messages so far
3. Nastavení tématu (topic) pro strategii Publish-Subscribe
Při použití komunikační strategie PUB-SUB se velmi často setkáme s požadavkem na to, aby se zprávy filtrovaly podle nastaveného tématu (topic). V klasických implementacích message brokerů bývají zprávy rozšířeny o hlavičku a téma bývá součástí této hlavičky. Ovšem knihovna nanomsg je nízkoúrovňová, takže samotnou zprávu považuje za dále nijak neinterpretovaná binární data. Tématem je poté libovolný prefix, tj. několik prvních znaků zprávy, přičemž filtrace probíhá až u konzumenta, nikoli u zdroje zpráv. Samotné nastavení filtrace zpráv lze provést funkcí nn_setsockopt(), které se předá prefix a jeho délka:
if (nn_setsockopt(socket, NN_SUB, NN_SUB_SUBSCRIBE, topic, strlen(topic)) < 0) {
report_error("nn_setsockopt");
}
else {
printf("Topic set to '%s'\n", topic);
}
4. Implementace producenta zpráv
Zdroj (producent) zpráv, které budou filtrovány na základě nastaveného tématu na straně konzumentů, se nebude nijak zásadně lišit od již popsaných producentů, pouze si vystačíme jen se sto zprávami. Jeho zdrojový kód je následující:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/pubsub.h>
const int MAX_MESSAGES = 100;
const char *URL = "ipc:///tmp/example10";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void send_message(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
usleep(100*1000);
}
void publisher(const char *url)
{
int socket;
int endpoint;
int i;
if ((socket = nn_socket(AF_SP, NN_PUB)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Remote endpoint bound to the socket");
for (i=0; i < MAX_MESSAGES; i++) {
char buffer[45];
int number = rand() % 10000;
sprintf(buffer, "%04d is my top secret PIN", number);
send_message(socket, buffer);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
publisher(URL);
return 0;
}
5. Implementace různých konzumentů zpráv připojených k nastaveným tématům
Zatímco u producenta došlo jen k nepatrné změně, konkrétně k přesunu čísla s PINem na začátek zprávy, budou konzumenti odlišní. První z nich bude zpracovávat jen ty zprávy, které začínají znakem „0“, které je zde považováno za téma:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/pubsub.h>
const char *URL = "ipc:///tmp/example10";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_message(const int socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void subscriber(const char *url)
{
const char *topic = "0";
int socket;
int endpoint;
int messages;
if ((socket = nn_socket(AF_SP, NN_SUB)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if (nn_setsockopt(socket, NN_SUB, NN_SUB_SUBSCRIBE, topic, strlen(topic)) < 0) {
report_error("nn_setsockopt");
}
else {
printf("Topic set to '%s'\n", topic);
}
if ((endpoint = nn_connect(socket, url)) < 0) {
report_error("nn_connect");
}
puts("Endpoint connected to socket");
puts("Waiting for messages...");
while (1) {
receive_message(socket);
messages++;
printf("Processed %d messages so far\n", messages);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(int argc, char **argv)
{
subscriber(URL);
return 0;
}
Druhý konzument se odlišuje pouze v jinak nastaveném tématu:
const char *topic = "1";
A konečně třetí konzument akceptuje všechny zprávy.
Chování jednotlivých konzumentů:
$ make run_subscriber_0 LD_LIBRARY_PATH=/usr/local/lib64/ ./subscriber_0 Socket created Topic set to '0' Endpoint connected to socket Waiting for messages... Received message '0886 is my top secret PIN' with length 26 bytes Processed 1 messages so far Received message '0492 is my top secret PIN' with length 26 bytes Processed 2 messages so far Received message '0027 is my top secret PIN' with length 26 bytes Processed 3 messages so far Received message '0059 is my top secret PIN' with length 26 bytes Processed 4 messages so far Received message '0540 is my top secret PIN' with length 26 bytes Processed 5 messages so far Received message '0925 is my top secret PIN' with length 26 bytes Processed 6 messages so far Received message '0336 is my top secret PIN' with length 26 bytes Processed 7 messages so far Received message '0846 is my top secret PIN' with length 26 bytes Processed 8 messages so far Received message '0545 is my top secret PIN' with length 26 bytes Processed 9 messages so far Received message '0364 is my top secret PIN' with length 26 bytes Processed 10 messages so far Received message '0012 is my top secret PIN' with length 26 bytes Processed 11 messages so far
$ make run_subscriber_1 LD_LIBRARY_PATH=/usr/local/lib64/ ./subscriber_1 Socket created Topic set to '1' Endpoint connected to socket Waiting for messages... Received message '1421 is my top secret PIN' with length 26 bytes Processed 1 messages so far Received message '1530 is my top secret PIN' with length 26 bytes Processed 2 messages so far Received message '1393 is my top secret PIN' with length 26 bytes Processed 3 messages so far Received message '1873 is my top secret PIN' with length 26 bytes Processed 4 messages so far Received message '1729 is my top secret PIN' with length 26 bytes Processed 5 messages so far Received message '1313 is my top secret PIN' with length 26 bytes Processed 6 messages so far Received message '1087 is my top secret PIN' with length 26 bytes Processed 7 messages so far
$ make run_subscriber_all LD_LIBRARY_PATH=/usr/local/lib64/ ./subscriber_all Socket created Endpoint connected to socket Waiting for messages... Received message '0886 is my top secret PIN' with length 26 bytes Processed 1 messages so far Received message '2777 is my top secret PIN' with length 26 bytes Processed 2 messages so far Received message '6915 is my top secret PIN' with length 26 bytes Processed 3 messages so far Received message '7793 is my top secret PIN' with length 26 bytes Processed 4 messages so far Received message '8335 is my top secret PIN' with length 26 bytes Processed 5 messages so far Received message '5386 is my top secret PIN' with length 26 bytes Processed 6 messages so far Received message '0492 is my top secret PIN' with length 26 bytes Processed 7 messages so far Received message '6649 is my top secret PIN' with length 26 bytes Processed 8 messages so far Received message '1421 is my top secret PIN' with length 26 bytes Processed 9 messages so far Received message '2362 is my top secret PIN' with length 26 bytes Processed 10 messages so far
6. Komunikační strategie Request-Response
Další velmi často používaná komunikační strategie se nazývá Request-Response nebo zkráceně REQ-REP popř. pouze REQREP. Při použití této strategie spolu komunikují dva typy uzlů – server a teoreticky neomezené množství klientů. Server přijímá požadavky (request) a odpovídá na ně (response), přičemž je možné, aby požadavky posílalo několik klientů (a jeden klient naopak může v případě potřeby posílat požadavky více serverům). Tato velmi asymetrická komunikace se strategií REQ-REP je v praxi poměrně častá, ostatně je na ní založen i známý protokol HTTP a jeho pozdější varianty (dokonce se někdy nad HTTP staví jiné komunikační strategie, což je ovšem neoptimální řešení).
Nejjednodušší forma komunikace probíhá mezi pouhými dvěma uzly, jak je to naznačeno na dalším obrázku:

Obrázek 5: Obousměrná komunikace využívající strategii REQ-REP mezi jedním klientem a jedním serverem.
Samozřejmě nám však nic nebrání v použití většího množství klientů, které se připojí k jednomu serveru:

Obrázek 6: Obousměrná komunikace využívající strategii REQ-REP mezi dvěma klienty a jedním serverem.
Tato komunikační strategie vyžaduje, aby server používal sockety typu NN_REP a klienti sockety typu NN_REQ. Server typicky využívá funkci nn_bind(), klienti funkci nn_connect(), protože port (či koncový bod) serveru je z pohledu administrace systému „stabilní“, na rozdíl od klientů. Komunikaci vždy iniciuje klient posláním požadavku (request); server na tento požadavek odpovídá (response). Jedná se o strategii umožňující load balancing a taktéž znovuodeslání požadavku, pokud v nastaveném čase nepřišla žádná odpověď.
7. Implementace klienta používajícího strategii Request-Response
Nejprve si ukažme, jak vypadá implementace klienta používajícího strategii REQ-REP. Ta je ve skutečnosti velmi jednoduchá, protože postačuje otevřít socket se specifikací strategie NN_REQ, poslat požadavek s využitím funkce nn_send() a následně počkat a přijmout výsledek (odpověď serveru) funkcí nn_recv(). Pro lepší přehlednost příkladu je poslání požadavku implementováno v uživatelské funkci nazvané send_request() a přijetí odpovědi serveru ve funkci nazvané receive_response().
Vytvoření socketu a připojení k serveru:
if ((socket = nn_socket(AF_SP, NN_REQ)) < 0) {
report_error("nn_socket");
}
if ((endpoint = nn_connect(socket, url)) < 0) {
report_error("nn_connect");
}
Poslání zprávy (přesněji řečeno požadavku):
void send_request(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
sleep(1);
}
Příjem zprávy (přesněji řečeno odpovědi serveru):
void receive_response(const int socket)
{
char *response = NULL;
int bytes;
if ((bytes = nn_recv(socket, &response, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received response '%s' with length %d bytes\n", response, bytes);
if (nn_freemsg(response) < 0) {
report_error("nn_freemsg");
}
}
Úplný zdrojový kód klienta vypadá následovně:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/reqrep.h>
const char *URL = "ipc:///tmp/example11";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void send_request(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
sleep(1);
}
void receive_response(const int socket)
{
char *response = NULL;
int bytes;
if ((bytes = nn_recv(socket, &response, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received response '%s' with length %d bytes\n", response, bytes);
if (nn_freemsg(response) < 0) {
report_error("nn_freemsg");
}
}
void client(const char *url)
{
int socket;
int endpoint;
if ((socket = nn_socket(AF_SP, NN_REQ)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_connect(socket, url)) < 0) {
report_error("nn_connect");
}
puts("Remote endpoint added to the socket");
send_request(socket, "Hello from 'first'!");
puts("Waiting for response...");
receive_response(socket);
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
client(URL);
return 0;
}
8. Implementace serveru zpracovávajícího požadavky
Server založený na strategii REQ-REP bude používat socket typu NN_REP a pro vytvoření koncového bodu pochopitelně použijeme funkci nn_bind() a nikoli nn_connect():
if ((socket = nn_socket(AF_SP, NN_REP)) < 0) {
report_error("nn_socket");
}
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
Zcela nejjednodušší varianta serveru přijme pouze jediný požadavek a pošle na něj odpověď zpět klientovi. Žádné další požadavky již nebudou akceptovány, protože se server odpojí:
receive_request(socket);
send_response(socket, "ACK!");
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
Samozřejmě si opět ukážeme úplný zdrojový kód serveru, který vypadá následovně:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/reqrep.h>
const char *URL = "ipc:///tmp/example11";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_request(const int socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void send_response(const int socket, const char *response)
{
int bytes;
printf("Sending response '%s'\n", response);
if ((bytes = nn_send(socket, response, strlen(response)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Response with length %d bytes sent, flushing\n", bytes);
sleep(1);
}
void server(const char *url)
{
int socket;
int endpoint;
if ((socket = nn_socket(AF_SP, NN_REP)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Endpoint bound to socket");
puts("Waiting for message...");
receive_request(socket);
send_response(socket, "ACK!");
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(int argc, char **argv)
{
server(URL);
return 0;
}
9. Server zpracovávající dotazy v jediném vláknu
Pochopitelně nám nic nebrání ve vytvoření serveru, který bude jednotlivé dotazy zpracovávat postupně a v takovém pořadí, v jakém je bude přijímat. Prozatím nepoužijeme žádnou formu multitaskingu ani multithreadingu, protože toto řešení není ideální – výhodnější je použít takzvaná zařízení (device).
Zdrojový kód takto upraveného serveru naleznete na adrese https://github.com/tisnik/message-queues-examples/blob/master/nanomsg/13_req_res_single_thread/server.c:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/reqrep.h>
const char *URL = "ipc:///tmp/example12";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_request(socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void send_response(const int socket, const char *response)
{
int bytes;
printf("Sending response '%s'\n", response);
if ((bytes = nn_send(socket, response, strlen(response)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Response with length %d bytes sent, flushing\n", bytes);
sleep(1);
}
void server(const char *url)
{
int socket;
int endpoint;
if ((socket = nn_socket(AF_SP, NN_REP)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Endpoint bound to socket");
puts("Waiting for messages...");
while (1) {
receive_request(socket);
send_response(socket, "ACK!");
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(int argc, char **argv)
{
server(URL);
return 0;
}
10. Chování serveru při zpracování velkého množství dotazů
Na rozdíl od strategie PUB-SUB by se při použití strategie REQ-REP neměly žádné zprávy ztrácet. Můžeme se o tom snadno přesvědčit úpravou klienta i serveru.
Klient, jehož zdrojový kód je možné nalézt na adrese https://github.com/tisnik/message-queues-examples/blob/master/nanomsg/13_req_res_single_thread/client.c, je nakonfigurován tak, aby poslal celkem 100 zpráv:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/reqrep.h>
const int MESSAGES = 100;
const char *URL = "ipc:///tmp/example13";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void send_request(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
}
void receive_response(socket)
{
char *response = NULL;
int bytes;
if ((bytes = nn_recv(socket, &response, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received response '%s' with length %d bytes\n", response, bytes);
if (nn_freemsg(response) < 0) {
report_error("nn_freemsg");
}
}
void client(const char *url)
{
int socket;
int endpoint;
int i;
if ((socket = nn_socket(AF_SP, NN_REQ)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_connect(socket, url)) < 0) {
report_error("nn_connect");
}
puts("Remote endpoint added to the socket");
for (i=0; i < MESSAGES; i++) {
send_request(socket, "Hello from 'first'!");
puts("Waiting for response...");
receive_response(socket);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
client(URL);
return 0;
}
Server tyto zprávy bude přijímat a současně vypíše, kolik zpráv již dokázal zpracovat:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/reqrep.h>
const char *URL = "ipc:///tmp/example13";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_request(socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void send_response(const int socket, const char *response)
{
int bytes;
printf("Sending response '%s'\n", response);
if ((bytes = nn_send(socket, response, strlen(response)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Response with length %d bytes sent, flushing\n", bytes);
}
void server(const char *url)
{
int socket;
int endpoint;
int messages;
if ((socket = nn_socket(AF_SP, NN_REP)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Endpoint bound to socket");
puts("Waiting for messages...");
while (1) {
receive_request(socket);
send_response(socket, "ACK!");
messages++;
printf("Processed %d messages so far\n", messages);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(int argc, char **argv)
{
server(URL);
return 0;
}
Chování klienta:
Chování serveru:
$ make run_server LD_LIBRARY_PATH=/usr/local/lib64/ ./server Socket created Endpoint bound to socket Waiting for messages... Received message 'Hello from 'first'!' with length 20 bytes Sending response 'ACK!' Response with length 5 bytes sent, flushing Processed 1 messages so far Received message 'Hello from 'first'!' with length 20 bytes Sending response 'ACK!' ... ... ... Processed 97 messages so far Received message 'Hello from 'first'!' with length 20 bytes Sending response 'ACK!' Response with length 5 bytes sent, flushing Processed 98 messages so far Received message 'Hello from 'first'!' with length 20 bytes Sending response 'ACK!' Response with length 5 bytes sent, flushing Processed 99 messages so far Received message 'Hello from 'first'!' with length 20 bytes Sending response 'ACK!' Response with length 5 bytes sent, flushing Processed 100 messages so far
Chování klienta:
$ make run_client LD_LIBRARY_PATH=/usr/local/lib64/ ./client Socket created Remote endpoint added to the socket Sending message 'Hello from 'first'!' Message with length 20 bytes sent, flushing Waiting for response... Received response 'ACK!' with length 5 bytes Sending message 'Hello from 'first'!' Message with length 20 bytes sent, flushing Waiting for response... ... ... ...
11. Komunikační strategie Survey
V pořadí již pátou komunikační strategií, se kterou se dnes seznámíme, je strategie nazvaná Survey. Jedná se o dosti příhodný název, protože v této strategii vystupuje jeden uzel, který se dotáže ostatních uzlů například na jejich stav a uzly následně mohou odpovídat. Dotazující se uzel má nastavenu dobu čekání, takže může jednotlivé odpovědi zaznamenat a po uplynutí zadaného časového okamžiku zjistit, které uzly vůbec neodpověděly (nebo to nestihly, což je ovšem z pohledu dotazujícího to samé):

Obrázek 7: Komunikační strategie Survey.
Tato strategie je v praxi velmi užitečná, protože umožňuje například sledování velkého množství čidel, počítačů v clusteru atd., aniž by tato zařízení musela aktivně někam posílat svůj stav, typicky s využitím strategie PUB-SUB. Nevýhodou může být nárazový způsob využívání sítě, to ovšem již do určité míry záleží na její topologii.
12. Implementace klienta
Implementace klienta odpovídajícího na otázky serveru je relativně jednoduchá a nalezneme ji na adrese https://github.com/tisnik/message-queues-examples/blob/master/nanomsg/15_survey/client.c. Povšimněte si, že klient v odpovědi pošle pseudonáhodné číslo:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/survey.h>
const char *URL = "ipc:///tmp/example14";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_question(const int socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void send_answer(const int socket, const char *answer)
{
int bytes;
printf("Sending answer '%s'\n", answer);
if ((bytes = nn_send(socket, answer, strlen(answer)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Answer with length %d bytes sent, flushing\n", bytes);
}
#define ANSWER_LENGTH 100
void client(const char *url)
{
int socket;
int endpoint;
char answer[ANSWER_LENGTH];
int number;
if ((socket = nn_socket(AF_SP, NN_RESPONDENT)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_connect(socket, url)) < 0) {
report_error("nn_connect");
}
puts("Remote endpoint added to the socket");
while (1) {
receive_question(socket);
puts("Question received");
/* nemame vypocetni vykon Hlubiny mysleni... */
srand((unsigned) getpid());
number = rand() % 100;
snprintf(answer, ANSWER_LENGTH, "It must be %d", number);
send_answer(socket, answer);
puts("Answer sent");
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
client(URL);
return 0;
}
13. Implementace serveru
Server, který implementuje strategii Survey, nalezneme na adrese https://github.com/tisnik/message-queues-examples/blob/master/nanomsg/15_survey/server.c. Jeho základem je tento kód posílající dotaz a očekávající libovolné množství odpovědí:
send_survey(socket, "What do you get when you multiply six by nine?");
puts("Survey send, waiting for answers...");
while (1) {
receive_answer(socket);
answers++;
printf("Processed %d answers so far\n", answers);
}
Následuje výpis úplného zdrojového kódu tohoto příkladu:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/survey.h>
const char *URL = "ipc:///tmp/example14";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void send_survey(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
}
void receive_answer(const int socket)
{
char *response = NULL;
int bytes;
if ((bytes = nn_recv(socket, &response, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received answer '%s' with length %d bytes\n", response, bytes);
if (nn_freemsg(response) < 0) {
report_error("nn_freemsg");
}
}
void wait_for_clients(int seconds)
{
int i;
puts("Waiting for clients to connect...");
for (i=10; i>0; i--) {
printf("%d ", i);
fflush(stdout);
sleep(1);
}
puts("\nDone");
}
void server(const char *url)
{
int socket;
int endpoint;
int answers;
if ((socket = nn_socket(AF_SP, NN_SURVEYOR)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
puts("Endpoint bound to socket");
wait_for_clients(10);
send_survey(socket, "What do you get when you multiply six by nine?");
puts("Survey send, waiting for answers...");
while (1) {
receive_answer(socket);
answers++;
printf("Processed %d answers so far\n", answers);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(int argc, char **argv)
{
server(URL);
return 0;
}
14. Ukázka poslání otázky a zpracování odpovědí
Podívejme se nyní na to, jakým způsobem bude pracovat server. Nejprve se spustí a počká deset sekund na připojení klientů (ty spustíme například v paralelně běžících terminálech):
Socket created Endpoint bound to socket Waiting for clients to connect... 10 9 8 7 6 5 4 3 2 1 Done
Následně server pošle dotaz, a to všem aktuálně připojeným klientům. Ihned po poslání dotazu začne očekávat jednotlivé odpovědi:
Sending message 'What do you get when you multiply six by nine?' Message with length 47 bytes sent, flushing Survey send, waiting for answers...
Odpovědi skutečně dostane, a to v našem konkrétním případě tři (od třech klientů):
Received answer 'It must be 99' with length 14 bytes Processed 1 answers so far Received answer 'It must be 88' with length 14 bytes Processed 2 answers so far Received answer 'It must be 73' with length 14 bytes Processed 3 answers so far
Následně ovšem již další odpovědi nepřijdou a dojde k detekovatelné chybě (timeout):
nn_recv: Connection timed out make: *** [Makefile:34: run_server] Error 1
15. Komunikační strategie Bus
Poslední komunikační strategie, s níž se seznámíme a která je knihovnou nanomsg podporována, se jmenuje Bus neboli sběrnice. Tato strategie obecně podporuje komunikaci libovolného uzlu s ostatními uzly, ovšem musíme si uvědomit, že zde není k dispozici jediný centrální message broker ani skutečný message bus. Efektu sběrnice se dosahuje takovým způsobem, že se jednotlivé uzly propojí mezi sebou, což je sice nejobecnější schéma, ovšem taktéž nejvíce náchylné na různé neočekávané výpadky a rozpady připojení. Taktéž samotná konfigurace aplikace může být problematická, protože jednotlivé uzly o sobě musí navzájem vědět, přesněji řečeno musí být k dispozici konfigurační mechanismus popř. mechanismus nalézání uzlů. V demonstračním příkladu z tohoto důvodu pro jednoduchost použijeme pouze dva uzly, přičemž jeden bude zprávy pouze přijímat a druhý vysílat.
16. Implementace prvního uzlu
První uzel, jehož úplný zdrojový kód je uložen na adrese https://github.com/tisnik/message-queues-examples/blob/master/nanomsg/16_bus/node1.c, pouze na svém portu očekává zprávy. Je tedy pasivní a sám o sobě žádné zprávy dalším uzlům neposílá:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/bus.h>
const char *URL = "ipc:///tmp/example14";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void receive_message(const int socket)
{
char *message = NULL;
int bytes;
if ((bytes = nn_recv(socket, &message, NN_MSG, 0)) < 0) {
report_error("nn_recv");
}
printf("Received message '%s' with length %d bytes\n", message, bytes);
if (nn_freemsg(message) < 0) {
report_error("nn_freemsg");
}
}
void node1(const char *url)
{
int socket;
int endpoint;
int messages = 0;
if ((socket = nn_socket(AF_SP, NN_BUS)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
if ((endpoint = nn_bind(socket, url)) < 0) {
report_error("nn_bind");
}
printf("Remote endpoint %s bound to the socket\n", url);
puts("Waiting for messages...");
while (1) {
receive_message(socket);
messages++;
printf("Processed %d messages so far\n", messages);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
node1(URL);
return 0;
}
17. Implementace druhého uzlu
Druhý uzel naopak zprávy posílá, a to uzlu prvnímu. Zdrojový kód implementace tohoto uzlu naleznete zde:

#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <nanomsg/nn.h>
#include <nanomsg/bus.h>
const char *URL = "ipc:///tmp/example14";
void report_error(const char *func)
{
fprintf(stderr, "%s: %s\n", func, nn_strerror(nn_errno()));
exit(1);
}
void send_message(const int socket, const char *message)
{
int bytes;
printf("Sending message '%s'\n", message);
if ((bytes = nn_send(socket, message, strlen(message)+1, 0)) < 0) {
report_error("nn_send");
}
printf("Message with length %d bytes sent, flushing\n", bytes);
sleep(1);
}
#define BUF_LEN 100
void node2(const char *url)
{
int socket;
int endpoint;
char buffer[BUF_LEN];
int i;
if ((socket = nn_socket(AF_SP, NN_BUS)) < 0) {
report_error("nn_socket");
}
puts("Socket created");
endpoint = nn_connect(socket, url);
if (endpoint < 0) {
report_error("nn_connect");
}
printf("Connected to the remote %s endpoint\n", url);
sleep(1);
for (i=0; i<10; i++) {
sprintf(buffer, "Message #%d from node2", i);
send_message(socket, buffer);
}
if (nn_shutdown(socket, endpoint) < 0) {
report_error("nn_shutdown");
}
puts("Shutdown completed");
}
int main(const int argc, const char **argv)
{
node2(URL);
return 0;
}
18. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů vyvinutých v programovacím jazyku Go byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/message-queues-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce. Každý příklad se skládá ze dvou samostatně překládaných a spouštěných souborů – producenta zpráv a konzumenta zpráv:
19. Odkazy na předchozí části seriálu o message brokerech
V této kapitole jsou uvedeny odkazy na všech šestnáct předchozích částí seriálu, v němž se zabýváme různými způsoby implementace front zpráv a k nim přidružených technologií message brokerů:
- Použití nástroje RQ (Redis Queue) pro správu úloh zpracovávaných na pozadí
https://www.root.cz/clanky/pouziti-nastroje-rq-redis-queue-pro-spravu-uloh-zpracovavanych-na-pozadi/ - Celery: systém implementující asynchronní fronty úloh pro Python
https://www.root.cz/clanky/celery-system-implementujici-asynchronni-fronty-uloh-pro-python/ - Celery: systém implementující asynchronní fronty úloh pro Python (dokončení)
https://www.root.cz/clanky/celery-system-implementujici-asynchronni-fronty-uloh-pro-python-dokonceni/ - RabbitMQ: jedna z nejúspěšnějších implementací brokera
https://www.root.cz/clanky/rabbitmq-jedna-z-nejuspesnejsich-implementaci-brokera/ - Pokročilejší operace nabízené systémem RabbitMQ
https://www.root.cz/clanky/pokrocilejsi-operace-nabizene-systemem-rabbitmq/ - ØMQ: knihovna pro asynchronní předávání zpráv
https://www.root.cz/clanky/0mq-knihovna-pro-asynchronni-predavani-zprav/ - Další možnosti poskytované knihovnou ØMQ
https://www.root.cz/clanky/dalsi-moznosti-poskytovane-knihovnou-mq/ - Využití zařízení v knihovně ØMQ při tvorbě systému se složitější architekturou
https://www.root.cz/clanky/vyuziti-zarizeni-v-knihovne-mq-pri-tvorbe-systemu-se-slozitejsi-architekturou/ - Další možnosti nabízené knihovnou ØMQ, implementace protokolů ØMQ v čisté Javě
https://www.root.cz/clanky/dalsi-moznosti-nabizene-knihovnou-mq-implementace-protokolu-mq-v-ciste-jave/ - Apache ActiveMQ – další systém implementující message brokera
https://www.root.cz/clanky/apache-activemq-dalsi-system-implementujici-message-brokera/ - Použití Apache ActiveMQ s protokolem STOMP
https://www.root.cz/clanky/pouziti-apache-activemq-s-protokolem-stomp/ - Použití Apache ActiveMQ s protokolem AMQP, jazyk Go a message brokeři
https://www.root.cz/clanky/pouziti-apache-activemq-s-protokolem-amqp-jazyk-go-a-message-brokeri/ - Komunikace s message brokery z programovacího jazyka Go
https://www.root.cz/clanky/komunikace-s-message-brokery-z-programovaciho-jazyka-go/ - Použití message brokeru NATS
https://www.root.cz/clanky/pouziti-message-brokeru-nats/ - NATS Streaming Server
https://www.root.cz/clanky/nats-streaming-server/ - Implementace různých komunikačních strategií s využitím knihovny nanomsg
https://www.root.cz/clanky/implementace-ruznych-komunikacnich-strategii-s-vyuzitim-knihovny-nanomsg/
20. Odkazy na Internetu
- nanomsg na GitHubu
https://github.com/nanomsg/nanomsg - Referenční příručka knihovny nanomsg
https://nanomsg.org/v1.1.5/nanomsg.html - nng (nanomsg-next-generation)
https://github.com/nanomsg/nng - Differences between nanomsg and ZeroMQ
https://nanomsg.org/documentation-zeromq.html - NATS
https://nats.io/about/ - NATS Streaming Concepts
https://nats.io/documentation/streaming/nats-streaming-intro/ - NATS Streaming Server
https://nats.io/download/nats-io/nats-streaming-server/ - NATS Introduction
https://nats.io/documentation/ - NATS Client Protocol
https://nats.io/documentation/internals/nats-protocol/ - NATS Messaging (Wikipedia)
https://en.wikipedia.org/wiki/NATS_Messaging - Stránka Apache Software Foundation
http://www.apache.org/ - Informace o portu 5672
http://www.tcp-udp-ports.com/port-5672.htm - Třída MessagingHandler knihovny Qpid Proton
https://qpid.apache.org/releases/qpid-proton-0.27.0/proton/python/api/proton._handlers.MessagingHandler-class.html - Třída Event knihovny Qpid Proton
https://qpid.apache.org/releases/qpid-proton-0.27.0/proton/python/api/proton._events.Event-class.html - package stomp (Go)
https://godoc.org/github.com/go-stomp/stomp - Go language library for STOMP protocol
https://github.com/go-stomp/stomp - python-qpid-proton 0.26.0 na PyPi
https://pypi.org/project/python-qpid-proton/ - Qpid Proton
http://qpid.apache.org/proton/ - Using the AMQ Python Client
https://access.redhat.com/documentation/en-us/red_hat_amq/7.1/html-single/using_the_amq_python_client/ - Apache ActiveMQ
http://activemq.apache.org/ - Apache ActiveMQ Artemis
https://activemq.apache.org/artemis/ - Apache ActiveMQ Artemis User Manual
https://activemq.apache.org/artemis/docs/latest/index.html - KahaDB
http://activemq.apache.org/kahadb.html - Understanding the KahaDB Message Store
https://access.redhat.com/documentation/en-US/Fuse_MQ_Enterprise/7.1/html/Configuring_Broker_Persistence/files/KahaDBOverview.html - Command Line Tools (Apache ActiveMQ)
https://activemq.apache.org/activemq-command-line-tools-reference.html - stomp.py 4.1.21 na PyPi
https://pypi.org/project/stomp.py/ - Stomp Tutorial
https://access.redhat.com/documentation/en-US/Fuse_Message_Broker/5.5/html/Connectivity_Guide/files/FMBConnectivityStompTelnet.html - Heartbeat (computing)
https://en.wikipedia.org/wiki/Heartbeat_(computing) - Apache Camel
https://camel.apache.org/ - Red Hat Fuse
https://developers.redhat.com/products/fuse/overview/ - Confusion between ActiveMQ and ActiveMQ-Artemis?
https://serverfault.com/questions/873533/confusion-between-activemq-and-activemq-artemis - Staré stránky projektu HornetQ
http://hornetq.jboss.org/ - Snapshot JeroMQ verze 0.4.4
https://oss.sonatype.org/content/repositories/snapshots/org/zeromq/jeromq/0.4.4-SNAPSHOT/ - Difference between ActiveMQ vs Apache ActiveMQ Artemis
http://activemq.2283324.n4.nabble.com/Difference-between-ActiveMQ-vs-Apache-ActiveMQ-Artemis-td4703828.html - Microservices communications. Why you should switch to message queues
https://dev.to/matteojoliveau/microservices-communications-why-you-should-switch-to-message-queues–48ia - Stomp.py 4.1.19 documentation
https://stomppy.readthedocs.io/en/stable/ - Repositář knihovny JeroMQ
https://github.com/zeromq/jeromq/ - ØMQ – Distributed Messaging
http://zeromq.org/ - ØMQ Community
http://zeromq.org/community - Get The Software
http://zeromq.org/intro:get-the-software - PyZMQ Documentation
https://pyzmq.readthedocs.io/en/latest/ - Module: zmq.decorators
https://pyzmq.readthedocs.io/en/latest/api/zmq.decorators.html - ZeroMQ is the answer, by Ian Barber
https://vimeo.com/20605470 - ZeroMQ RFC
https://rfc.zeromq.org/ - ZeroMQ and Clojure, a brief introduction
https://antoniogarrote.wordpress.com/2010/09/08/zeromq-and-clojure-a-brief-introduction/ - zeromq/czmq
https://github.com/zeromq/czmq - golang wrapper for CZMQ
https://github.com/zeromq/goczmq - ZeroMQ version reporting in Python
http://zguide.zeromq.org/py:version - A Go interface to ZeroMQ version 4
https://github.com/pebbe/zmq4 - Broker vs. Brokerless
http://zeromq.org/whitepapers:brokerless - Learning ØMQ with pyzmq
https://learning-0mq-with-pyzmq.readthedocs.io/en/latest/ - Céčková funkce zmq_ctx_new
http://api.zeromq.org/4–2:zmq-ctx-new - Céčková funkce zmq_ctx_destroy
http://api.zeromq.org/4–2:zmq-ctx-destroy - Céčková funkce zmq_bind
http://api.zeromq.org/4–2:zmq-bind - Céčková funkce zmq_unbind
http://api.zeromq.org/4–2:zmq-unbind - Céčková C funkce zmq_connect
http://api.zeromq.org/4–2:zmq-connect - Céčková C funkce zmq_disconnect
http://api.zeromq.org/4–2:zmq-disconnect - Céčková C funkce zmq_send
http://api.zeromq.org/4–2:zmq-send - Céčková C funkce zmq_recv
http://api.zeromq.org/4–2:zmq-recv - Třída Context (Python)
https://pyzmq.readthedocs.io/en/latest/api/zmq.html#context - Třída Socket (Python)
https://pyzmq.readthedocs.io/en/latest/api/zmq.html#socket - Python binding
http://zeromq.org/bindings:python - Why should I have written ZeroMQ in C, not C++ (part I)
http://250bpm.com/blog:4 - Why should I have written ZeroMQ in C, not C++ (part II)
http://250bpm.com/blog:8 - About Nanomsg
https://nanomsg.org/ - Advanced Message Queuing Protocol
https://www.amqp.org/ - Advanced Message Queuing Protocol na Wikipedii
https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol - Dokumentace k příkazu rabbitmqctl
https://www.rabbitmq.com/rabbitmqctl.8.html - RabbitMQ
https://www.rabbitmq.com/ - RabbitMQ Tutorials
https://www.rabbitmq.com/getstarted.html - RabbitMQ: Clients and Developer Tools
https://www.rabbitmq.com/devtools.html - RabbitMQ na Wikipedii
https://en.wikipedia.org/wiki/RabbitMQ - Streaming Text Oriented Messaging Protocol
https://en.wikipedia.org/wiki/Streaming_Text_Oriented_Messaging_Protocol - Message Queuing Telemetry Transport
https://en.wikipedia.org/wiki/MQTT - Erlang
http://www.erlang.org/ - pika 0.12.0 na PyPi
https://pypi.org/project/pika/ - Introduction to Pika
https://pika.readthedocs.io/en/stable/ - Langohr: An idiomatic Clojure client for RabbitMQ that embraces the AMQP 0.9.1 model
http://clojurerabbitmq.info/ - AMQP 0–9–1 Model Explained
http://www.rabbitmq.com/tutorials/amqp-concepts.html - Part 1: RabbitMQ for beginners – What is RabbitMQ?
https://www.cloudamqp.com/blog/2015–05–18-part1-rabbitmq-for-beginners-what-is-rabbitmq.html - Downloading and Installing RabbitMQ
https://www.rabbitmq.com/download.html - celery na PyPi
https://pypi.org/project/celery/ - Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Python Celery & RabbitMQ Tutorial
https://tests4geeks.com/python-celery-rabbitmq-tutorial/ - Flower: Real-time Celery web-monitor
http://docs.celeryproject.org/en/latest/userguide/monitoring.html#flower-real-time-celery-web-monitor - Asynchronous Tasks With Django and Celery
https://realpython.com/asynchronous-tasks-with-django-and-celery/ - First Steps with Celery
http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html - node-celery
https://github.com/mher/node-celery - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queue – A thread-safe FIFO implementation
https://pymotw.com/2/Queue/ - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq - Running multiple workers using Celery
https://serverfault.com/questions/655387/running-multiple-workers-using-celery - celery — Distributed processing
http://docs.celeryproject.org/en/latest/reference/celery.html - Chains
https://celery.readthedocs.io/en/latest/userguide/canvas.html#chains - Routing
http://docs.celeryproject.org/en/latest/userguide/routing.html#automatic-routing - Celery Distributed Task Queue in Go
https://github.com/gocelery/gocelery/ - Python Decorators
https://wiki.python.org/moin/PythonDecorators - Periodic Tasks
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html - celery.schedules
http://docs.celeryproject.org/en/latest/reference/celery.schedules.html#celery.schedules.crontab - Pros and cons to use Celery vs. RQ
https://stackoverflow.com/questions/13440875/pros-and-cons-to-use-celery-vs-rq - Priority queue
https://en.wikipedia.org/wiki/Priority_queue - Jupyter
https://jupyter.org/ - How IPython and Jupyter Notebook work
https://jupyter.readthedocs.io/en/latest/architecture/how_jupyter_ipython_work.html - Context Managers
http://book.pythontips.com/en/latest/context_managers.html






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU