Další funkce
GNode* g_node_get_root(GNode *node); …nalezne kořen stromu, jehož příslušníkem je uzel node.
#define G_NODE_IS_LEAF(node) …makro, jehož výsledkem je TRUE, pokud uzel node je listem (nemá žádné následovníky).
#define G_NODE_IS_ROOT(node) …makro vracející TRUE, pokud uzel node je kořenem stromu (nemá žádné předky).
guint g_node_depth(GNode *node); …vrací hloubku daného uzlu node. Je-li node rovno NULL, návratovou hodnotou bude 0, je-li node kořenem, vrátí se 1. Pro přímé potomky (syny) kořenového uzlu je hloubka rovna 2 a tak dále.
Jinými slovy, hloubkou uzlu rozumějte pořadí generace (předek – potomek), ke které uzel náleží.
guint g_node_n_nodes(GNode *root, GTraverseFlags flags);
…vrátí počet uzlů ve stromu s kořenem root. Jestliže uzel root není kořenem stromu, vrátí se počet prvků v podstromu s kořenem root. Parametrem flags můžete specifikovat, mají-li se počítat všechny uzly ( G_TRAVERSE_ALL) nebo jen listy ( G_TRAVERSE_LEAFS) či jen ne-listové uzly ( G_TRAVERSE_NON_LEAFS). Více viz GLib část 21.
gboolean g_node_is_ancestor(GNode *node, GNode *descendant); Funkce g_node_is_ancestor() vrátí TRUE, pokud uzel node je předchůdce (v širším slova smyslu) potomka descendant. Vrácená hodnota je TRUE, pokud node je rodič, prarodič atd. uzlu descendant.
guint g_node_max_height(GNode *root); …vrátí maximální výšku větví od uzlu root. Jinými slovy, vrácenou hodnotou je maximální vzdálenost od uzlu root k listům. Je-li root rovno NULL, vrátí se 0. Jestliže root nemá potomky, vrátí se 1. Jestliže root má nějaké potomky, vrátí se 2. Jestliže i potomci uzlu root mají potomky, vrátí se 3 atd.
Příklad 1
#include <glib.h>
/* funkce pro vytisknuti jednoho uzlu
* (neni urcena pro samostatne pouziti!) */
gboolean __print_node(GNode *node, gpointer data)
{
gint x; /* pomocna promenna */
if (!(G_NODE_IS_ROOT(node))) {
/* node neni korenem - posun od zacatku radku */
x = (g_node_depth(node) - 1);
while (x > 0) {
printf(" ");
x--;
}
}
printf("%s\n", node->data);
return (FALSE);
}
/* funkce pro tisk stromu */
void my_node_print_tree(GNode *root)
{
/* skonci, neni-li root korenem! */
g_return_if_fail(G_NODE_IS_ROOT(root));
g_node_traverse(root, G_PRE_ORDER, G_TRAVERSE_ALL,
-1, __print_node, NULL);
}
/* hlavni telo programu */
gint main(void)
{
GNode *otec, *syn, *vnuk;
/* inicializace stromu */
otec = g_node_new("otec");
/* potomci otce */
syn = g_node_append_data(otec, "syn1");
/* potomci syna1 */
g_node_append_data(syn, "vnuk1.1");
vnuk = g_node_append_data(syn, "vnuk1.2");
g_node_append_data(syn, "vnuk1.3");
/* potomci vnuka1.2 */
g_node_append_data(vnuk, "pravnuk1.2.1");
/* potomci otce */
g_node_append_data(otec, "syn2");
syn = g_node_append_data(otec, "syn3");
/* potomci syna3 */
vnuk = g_node_append_data(syn, "vnuk3.1");
/* potomci vnuka3.1 */
g_node_append_data(vnuk, "pravnuk3.1.1");
g_node_append_data(vnuk, "pravnuk3.1.2");
/* tisk stromu */
puts("Puvodni strom:");
my_node_print_tree(otec);
/* nyni z puvodniho stromu "vykousneme" podstrom
* s korenem v uzlu syn3 */
g_node_unlink(syn);
/* tisk stromu */
puts("\nPuvodni strom po uprave:");
my_node_print_tree(otec);
puts("\nNovy strom:");
my_node_print_tree(syn);
/* stromy opet spojime, ale trochu jinak
* (jako potomky uzlu vnuk1.2) */
g_node_prepend(otec->children->children->next, syn);
/* tisk stromu */
puts("\nPuvodni strom po druhe uprave:");
my_node_print_tree(otec);
/* dealokace stromu */
g_node_destroy(otec);
}
Tento příklad definuje jednu funkci, kterou možná ve svých programech použijete pro ladicí účely. Je to funkce my_node_print_tree(). Jak už její název napovídá, funkce tiskne vzhled stromu. Pojďme se podívat, jak to všechno funguje:
Funkce my_node_print_tree() začíná makrem g_return_if_fail(), které zkontroluje, jestli její jediný parametr root je kořenem. (O makru g_return_if_fail() se dočtete více, až se budeme bavit o podpůrných ladicích funkcích knihovny GLib.)
Následuje volání funkce g_node_traverse() s uživatelskou funkcí __print_node(), která má za úkol tisknout jeden uzel. Funkcí g_node_traverse() se projdou všechny uzly ( G_TRAVERSE_ALL) v pořadí G_PRE_ORDER (= nejprve uzel, pak jeho potomci) do neomezené hloubky (max_depth = –1).
Funkce __print_node() tedy bude zavolána na každý uzel stromu. Pokud uzel node není kořenem, dojde k odsazení textu od začátku řádku. O kolik znaků, to určí hloubka daného uzlu ( g_node_depth()). Pak se už jen vytisknou data daného uzlu a funkce s návratovou hodnotou FALSE končí. ( FALSE proto, aby nikdy nedošlo k předčasnému ukončení procházení (traverse) stromem.)
Hlavní tělo programu se stará o toto:
Nejprve se inicializuje strom s kořenem otec tak, jako na obrázku 1. Zbylé dvě proměnné ( syn a vnuk) z inicializace vyjdou tak, že syn bude ukazovat na uzel syn3 a vnuk na uzel vnuk3.1.
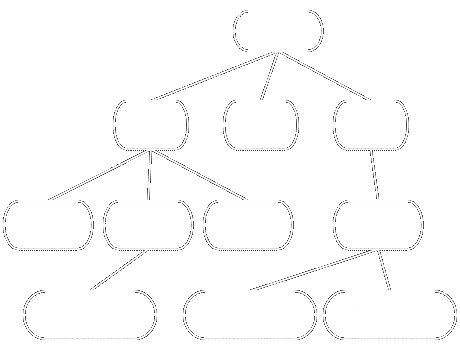
Obrázek 1 – Programem vytvořený strom
Strom se ukázkově funkcí my_node_print_tree() vytiskne a aby nebyla nuda, ještě se s ním trochu zacvičí. Nejprve se od něj funkcí g_node_unlink() oddělí podstrom s kořenem syn3 (proměnná syn), který se následně funkcí g_node_prepend() znovu ke stromu připojí, tentokrát ale jako potomek uzlu vnuk1.2.
Všimněte si, jak byl ve volání g_node_prepend() uadresován uzel vnuk1.2: otec->children->children->next.
Mezi každou operací se přitom provádějí kontrolní tisky, abychom měli možnost názorně vidět, co se se stromy děje.
Nakonec se celý strom dealokuje. Podstrom syn není třeba dealokovat zvlášť, protože jsme jej nakonec zase spojili s hlavním stromem.
Výstup programu by měl být takovýto:
Puvodni strom:
otec
syn1
vnuk1.1
vnuk1.2
pravnuk1.2.1
vnuk1.3
syn2
syn3
vnuk3.1
pravnuk3.1.1
pravnuk3.1.2
Puvodni strom po uprave:
otec
syn1
vnuk1.1
vnuk1.2
pravnuk1.2.1
vnuk1.3
syn2
Novy strom:
syn3
vnuk3.1
pravnuk3.1.1
pravnuk3.1.2
Puvodni strom po druhe uprave:
otec
syn1
vnuk1.1
vnuk1.2
syn3
vnuk3.1
pravnuk3.1.1
pravnuk3.1.2
pravnuk1.2.1
vnuk1.3
syn2
Příklad 2
Ukažme si ale ještě jeden příklad. V této ukázce se pracuje se stejným stromem, jako v příkladu 1, proto i inicializační část programu je stejná.
Kód vytváří novou vyhledávací funkci my_node_hledej(), která hledá uzly podle řetězce uloženého v datech. K úspěšnému nalezení uzlu tedy nemusíte znát přímo pointer, ale jen správný text.
#include <glib.h> /* funkce pro porovnani retezce v datech s hledanym
* retezcem (fce neni urcena pro samostatne pouziti!) */
gboolean __porovnej_retezce(GNode *node, gpointer data)
{
gpointer *p;
p = data;
if (strcmp((gchar *) node->data, (gchar *) p[0]) == 0) {
/* nasel - koncime */
p[1] = node;
return (TRUE);
} else {
/* nenasel */
return (FALSE);
}
}
/* hledani uzlu podle retezce */
GNode* my_node_hledej(GNode *root, gchar *what)
{
gpointer p[2];
/* kontrola parametru */
g_return_if_fail(G_NODE_IS_ROOT(root));
g_return_if_fail(what != NULL);
/* nastaveni pole */
p[0] = what;
p[1] = NULL;
g_node_traverse(root, G_PRE_ORDER, G_TRAVERSE_ALL,
-1, __porovnej_retezce, p);
return (p[1]);
}
/* hlavni telo programu */
gint main(void)
{
GNode *otec, *syn, *vnuk, *nalezeny;
/* inicializace stromu */
otec = g_node_new("otec");
syn = g_node_append_data(otec, "syn1");
g_node_append_data(syn, "vnuk1.1");
vnuk = g_node_append_data(syn, "vnuk1.2");
g_node_append_data(syn, "vnuk1.3");
g_node_append_data(vnuk, "pravnuk1.2.1");
g_node_append_data(otec, "syn2");
syn = g_node_append_data(otec, "syn3");
vnuk = g_node_append_data(syn, "vnuk3.1");
g_node_append_data(vnuk, "pravnuk3.1.1");
g_node_append_data(vnuk, "pravnuk3.1.2");
/* vyhledani uzlu */
nalezeny = my_node_hledej(otec, "vnuk3.1");
/* kontrolni tisk */
if (nalezeny != NULL)
printf("%s\n", nalezeny->data);
/* dealokace stromu */
g_node_destroy(otec);
}
Hlavní tělo programu po inicializaci stromu zavolá funkci my_node_hledej() a její výsledek uloží do pointeru nalezeny. Hledá se uzel s textem „vnuk3.1“. Následuje kontrolní tisk, který vypíše data nalezeného uzlu, a uvolnění stromu z paměti.
Funkce my_node_hledej() očekává dva parametry: kořen root stromu a hledaný řetězec what. K prohledání stromu využijeme standardní funkci knihovny GLib, g_node_traverse() a předáme jí takovou uživatelskou funkci, která v případě nalezení uzlu vrátí TRUE (čímž se procházení stromu zastaví). Jak ale zjistit, na kterém uzlu prohledávání stromu skončilo? Funkce g_node_traverse() nic nevrací a tak nám zbývají jen malinká vrátka v podobě uživatelských dat (poslední parametr funkce g_node_traverse()).
Funkce my_node_hledej() definuje dvouprvkové pole pointerů ( p). p[0] bude sloužit pro uložení hledaného řetězce a p[1] pro nalezený uzel. (Prozatím se inicializuje na NULL.) Takto nastavené pole p se spolu s uživatelskou funkcí __porovnej_retezce() předá funkci g_node_traverse().
__porovnej_retezce() Vraťme se nyní zpět do funkce my_node_hledej(). Po dokončení volání g_node_traverse() i tato funkce končí a jako návratová hodnota se použije pointer uložený v p[1] (pointer na nalezený uzel nebo NULL).
Použití parametru data je asi jediným rozumným způsobem jak zjistit uzel, na kterém procházení stromu skončilo. Škoda, že tvůrci knihovny GLib na toto nemysleli a nevymysleli funkci g_node_traverse() tak, aby pointer vracela automaticky sama.