
INGRES
Akademické období 1973 – 1979
Tato databáze je neodmyslitelně spojena s vývojem relačních databází – časově se shoduje s vývojem Systému R – relační databáze vyvíjené v IBM. Na obou těchto projektech se podílel Dr. Codd [INGRES07]. Na rozdíl od vývoje v IBM vývoj v Berkeley probíhal v skromnějších podmínkách – a na tehdejší „low-end“ o.s. Unix a počítači PDP 111. Prvním úkolem v projektu bylo získání prostředků na zakoupení počítače, což bylo tehdy 90 tis. dolarů. Prostředky byly získány z celé řady zdrojů2. Cílem projektu INGRES bylo navrhnout databázi pro správu demografických dat a jejich grafickou prezentaci – zadavatelem byla Urban Economics Group vedená Pravinem Varaiyou a Rolandem Artlem. Hlavním požadavkem na hw byly velkokapacitní disky (o kapacitě 50 až 100 megabytů) a kvalitní sw. Od podzimu 1973 do léta 1974 probíhaly souběžně semináře věnované návrhu dotazovacího jazyka a vlastnímu obslužnému systému. Semináře věnované návrhu systému vedl Stonebraker. Návrh dotazovacího jazyka vedl Eugene Wong. Výsledkem byl jazyk QUEL, který konvergoval k návrhu jazyka DSL/Alpha3 (který navrhl Dr. E.F. Codd). V září 1974, po dodání počítače (PDP-11), mohl být zahájen vlastní vývoj software.
Dalších 5 let probíhal vývoj většinou řízený programátorem na plný úvazek a skupinou studentů na částečný úvazek. V březnu 1975 byl demonstrován prototyp, který zvládal parsování dotazu (na základě doporučení Kena Thompsona byl postaven na YACCu), byly k dispozici rutiny pro správu relací a základní rutiny pro přístup k datům – halda (heap), hash, komprimovaný hash, index a komprimovaný index4). INGRES také získal prvního uživatele – Dana Gielana z New York Telephone co.
Koncem roku 1975 byl systém více-méně provozu schopný. Kód však obsahoval množství chyb, při psaní kódu nebyly dodržovány žádné konvence – styl, pojmenování proměnných a bylo zřejmé, že je neudržovatelný. Kod byl přepsán s přihlédnutím ke konvencím obvyklých ve velkých softwarových firmách. Konečně došlo k řízení souběžného přístupu a k řešení zotavení po výpadku. Databáze INGRES měla v roce 1979 cca stovku uživatelů, kteří již požadovali kvalitnější dokumentaci, další funkce a vyšší výkon. Databáze se tehdy distribuovala, jak bylo tehdy obvyklé, ve formě zdrojových kódů za cenu média. Ovšem našli se uživatelé, kteří ji začali prodávat jako svůj vlastní produkt – čemuž se díky nedostatečnému právnímu zajištění nedalo zabránit.
Z akademického pohledu projekt byl projekt velice úspěšný – návrh byl kladně hodnocen nezpochybnitelnými autoritami jako byl Dr. Codd nebo Dr. Date. Na druhou stranu vzhledem k nezkušenosti vývojářů i a nevyzrálosti tehdejšího UNIXu se vývojáři nevyhnuli chybám, v čehož důsledku byla INGRES pomalá databáze. Z chyb, které Stonebaker zmiňuje, to je zejména závislost na souborovém systému Unixu, který byl pomalý a neměl k dispozici nástroje pro obnovu dat v případě výpadku [STONE80]. Unix nepodporoval velké soubory (limit 16MB) a používal příliš malou velikost stránky (512 bytů). Interface INGRESu bylo založené na interpretu QUELu, na tehdejších počítačích pomalého a náročného na paměť. Řešením byl překladač – EQUEL (Embedded QUEL), který se ovšem obtížně používal.
main()
{
## int VALUE;
## char RELNAME[13],DOMNAME[13],DOMVAL[80];
## char DOMNAME2[13];
READ(RELNAME);
READ(DOMNAME);
READ(DOMNAME2);
## RANGE OF X IS RELNAME
While (READ(DOMVAL))
{
## RETRIEVE (VALUE=X.DOMNAME)
## WHERE X.DOMNAME2=DOMVAL
##{
PROCESS(VALUE)
##}
}
}
EQUEL obsahoval mix C kódu a QUEL kódu (zapsaného za zdvojeným hashem).
Projekt INGRES byl řízen Prof. Eugenem Wongem, Larry Rowe a Dr. Stonebrakerem. Na pozici hlavního programátora se vystřídali Gerald Held (Tandem NonStop SQL), Peter Kreps, Eric Allman (autor sendmailu), a Robert Epstein (spoluzakladatel Sybase). Na projektu se podílela řada dalších lidí – např. Paula Hawthorn (spoluzakladatelka Illustry).
Akademické období po roce 1979 až 1989
Po založení Relation Technologii a vytvoření komerční odnože INGRESu stále pokračoval vývoj na univerzitě v Berkeley (i když nikoliv s předchozí intenzitou5) – univerzitní kód je nyní označován jako university INGRES (případně Berkeley INGRES) nebo Ingres89. INGRES se používal i při vývoji Postgresu jako etalon výkonu a ještě v roce 1987 byl v některých testech rychlejší než Postgres [LAI87ma]. Kód INGRESu byl ještě použit k několika vědeckým projektům. V projektu „Distributed INGRES“ šlo o návrh konceptu distribuovaných databází [STONE83]. Po roce 1980 bylo uvolněno ještě několik verzí – až na výjimky obsahovaly pouze opravy existujícího kódu.
INGRES a QUEL se ještě uplatnil v práci Richarda Snograsse v první polovině 80 let [SNOGRAS84]. Ten navrhl rozšíření relační algebry o časovou dimenzi, čímž položil základy k dnešnímu návrhu tzv. temporálních databází6. Zde má každý záznam atributy valid_time (from/to), a transaction_time (from/to). Přidáním prostředků pro manipulaci s těmito atributy do jazyku QUEL vznikl jazyk TQuel7.
RANGE OF a IS Associates RETRIEVE (Name = a.Name) WHEN a OVERLAP "September"Projekt byl ukončen v roce 1989 (verze 8.9). Univerzitní verze nikdy neobsahovala podporu SQL
Komerční období 1980 – 2012
Koncem sedmdesátých let přišly první nabídky na komerční využití Ingresu, které ovšem nebyly zužitkovány. Jedním z důvodů, proč se „nespěchalo“ s komerčním využitím INGRESu, byla neexistence COBOLu na platformě Unix. Teprve v říjnu 1980 Wong, Row a Stonebraker spoluzakládají společnost Relational Technology8, Inc. za účelem komerčního vývoje INGRESu9. O rok později byla databáze INGRES přeportována z Unixu na DEC/VMS a Relation Technology pokračovala růstem – o dva roky později měla 52 zaměstnanců (z toho 32 vývojářů), o další rok později 130 zaměstnanců (71 vývojářů). V roce 1986 byla db INGRES nejrozšířenější databází na platformě DEC/VAX. Když v roce 1999 ASK Computer Systems kupoval Ingres Company (za 110 mil dolarů), byla Ingres Company osmnáctá největší softwarová společnost na světě). O pět let později (1994) bylo Ingres Company koupeno společností Computer Associates.
V první polovině osmdesátých let INGRES úspěšně soupeřil s rdbms Oracle – přičemž databáze INGRES byla hodnocena lépe pro bohatší nabídku funkcí, pro lepší návrh (teoretiky byl jazyk QUEL vyzdvihován nad SQL) a pro větší stabilitu. V druhé polovině osmdesátých let už INGRES ztrácel svou pozici na trhu ve prospěch Oracle10 a dalších nových relačních databází. Důvodů proč INGRES, byť starší a vyspělejší systém než Oracle, nedokázal držet krok, bylo několik – Oracle využíval agresivní marketing a spolupracoval s širokou skupinu partnerů, Oracle rychleji dokázal nabídnout funkce, které uživatelé požadovali. Na vývoji INGRESu se podepsalo i střídání majitelů, kteří měnili koncepty, měnili strategii – a s každým novým majitelem došlo ke zhoršení pozice i vztahů mezi vývojáři a managementem (zejména po koupi CA došlo k masivnímu odchodu vývojářů). Vývojáři INGRESu vyzkoušeli řadu nových konceptů, přičemž zákonitě občas předběhli možnosti, které nabízel tehdy dostupný hw. Dalším možným důvodem, proč INGRES neuspěl, byl proprietární dotazovací jazyk – Oracle těžil z jazyka SQL (a z jeho propagace IBM). QUEL byl pro uživatele bez matematického zázemí obtížný. A i když INGRES posléze obsahoval podporu i SQL11, tak tato podpora nebyla úplná, přišla pozdě a nebyla příliš efektivní. Optimalizace dotazů implementovaná Bobem Coyem byla navržena pro QUEL a nevyhovovala SQL (díky rozdílům v sémantice mezi SQL a QUEL). Bohužel pro INGRES, Bob Coye odešel do Oracle, pro který napsal optimalizátor dotazů, a nenašel se nikdo, kdo by jej dokázal nahradit [INGRES07].
Pro dokreslení technologických rozdílů mezi Oraclem a INGRESem lze uvést skutečnost, že INGRES nabízel optimalizátor dotazů, kdežto Oracle pouze planner na bázi pravidel [INGRES85], INGRES nabízel konzistentní podporu pravidel pro zajištění referenční a doménové integrity, Oracle umožňoval pouze zajištění referenční integrity, které ovšem v některých případech nefungovalo dokonale. Oracle měl na některých platformách vážné problémy s bezpečností. Při vývoji INGRESu byl kladen důraz na teoretické koncepty – takže v INGRESu poměrně dlouho chyběla podpora NULL, a kterou si museli vynutit uživatelé. INGRES dříve než Oracle implementoval vnořené transakce (Savepoints) [INGRES85]. INGRES podporoval distribuované databáze v roce 1987 – INGRES/Star. Oracle anoncoval podporu distribuovaných databází v témže roce, reálně ale byla tato funkcionalita podporována až v roce 1993 – v Oracle 7. Na druhou stranu databáze Oracle byla rychlejší, podporovala NULL, poddotazy a zámky na úrovni řádků12, dříve podporovala architekturu klient-server, podporovala neblokující konzistentní čtení a podporovala rekurzivní dotazy.
V druhé polovině 80 let se objevil další vážný soupeř INGRESu, databáze SYBASE. Databáze INGRES poskytovala podstatně více funkcí, byla odladěnější a stabilnější, ale také o 30 až 50 % pomalejší. SYBASE byla lépe připravena13 pro nasazení ve finančním segmentu, kde zásadním ukazatelem byl výkon v transakcích za sekundu, a pro tento typ nasazení nebyla databáze INGRES navržena. Toho si byli v RTI dobře vědomi a snažili se řešit problém s výkonem. Tou dobou si již uvědomovali, že QUEL nepředstavuje výhodu a v podpoře SQL musí dohánět konkurenci [INGRES87].
V průběhu devadesátých let INGRES svou pozici dále ztrácel (v důsledku minimálního vývoje pod hlavičkou CA) a v květnu 2004 došlo k uvolnění zdrojových kódů komerční verze. Ingres Corporation byla obnovena v roce 2005 s cílem dalšího vývoje a propagace INGRESu. V roce 2006 došlo k přelicencování zdrojových kódů na licenci GPL. V roce 2010 Ingres Corporation ohlásila nový produkt Ingres VectorWise, což je výsledek sloučení dvou databázových produktů a to databáze INGRES a databáze VectorWise. K dalším změnám došlo v roce 2011, kdy v září 2011 došlo k přejmenování Ingres Corporation na Action Corporation a ohlášení záměru vytvoření „cloudu“ umožňujícího zpracování velkých dat.
POSTGRES
Prakticky všechny specifické funkce, díky kterým má PostgreSQL své nezastupitelné místo, byly implementovány v POSTGRESu a vycházejí z představ a vizí M. Stonebrakera a jeho spolupracovníků.
Univerzitní projekt 1985–1996 (Berkeley)
V listopadu 1985 (publikováno v létě 1986) v dokumentu „The Design of POSTGRES“ M. Stonebraker spolu s L. Rowem představují návrh relační databáze nové generace, která by řešila problémy stávajících databází. Od této databáze se požaduje [STONE86]:
-
podpora rozšiřitelnosti – vlastní datové typy, vlastní operátory, možnost vlastních metod přístupu k datům,
-
podpora kompozitních typů: POLYGON, CIRCLE, LINE,…
-
podpora aktivních databází – alerty a triggery,
-
podpora optických disků,
-
podpora výše uvedeného bez nutnosti modifikace relačního modelu.
Kód INGRESu byl již v takovém stavu, že by implementace dalších zásadních funkcí byla obtížná. Navíc se ukázalo, že některá dřívější rozhodnutí ohledně architektury byla chybná, ovšem oprava by byla velice náročná. Z těchto důvodů bylo praktičtější začít „na zelené louce“ a vytvořit úplně nový systém.
Jedním ze testovaných konceptů bylo tzv. FastPath14 API. Toto jednoduché rozhraní zprostředkovávalo přístup k nízkoúrovňovým funkcím POSTGRESu – vývojář externích modulů mohl volat funkce parseru, optimalizátoru nebo executoru. Toto API bylo možné použít na straně backendu, kdy sloužilo jako základní rozhraní pro externí moduly, nebo na straně klienta – kdy pomocí RPC klient mohl volat téměř libovolnou funkci serveru – např. obejít parser a vykonat příkaz zadaný jako abstraktní syntaktický strom. S tímto API se počítalo pro vytvoření 4GL databázové architektury nad POSTGRESem (PICASSO) nebo efektivní implementace CLOS (Common Lisp Object System) [ROWE91].
Během následujících pěti let se postupně upřesňovala specifikace databáze – např. v [ROWE87] je popsán datový model POSTGRESu – návrh abstraktních datových typů15, návrh procedurálního datového typu16, návrh rozšíření relačního modelu o vícenásobnou dědičnost17:
create PERSON ( Name = char[25], Birthdate = date, Height = int4, Weight = int4, StreetAddress = char[25], City = char[25], State = char[2]) create EMPLOYEE (Depth = char[25], Status = int2, Mgr = char[25], JobTitle = char[25], Salary = money) inherits (PERSON) create STUDENT(Sno = char[12], Status = int2, Level = char[20]) inherits (PERSON) create STUDENTP(IsWorkStudy = bool) inherits (STUDENT, EMPLOYEE)
Kromě návrhu specifikací pokračovala i vlastní implementace. První demoverze byla k dispozici v roce 1987, první verze pak v červnu 1989 (i zde se spíše jednalo o testovací verzi, chyběly např. agregační funkce, podpora „time travel“ nebyla úplná, v porovnání s komerční verzí INGRESu 5.0 byl POSTGRES cca 5–10× pomalejší18).
V říjnu 1989 Stonebraker shrnuje zkušenosti z předchozího tříletého vývoje projektu [STONE90]. Vývoj realizovala pětice studentů na částečný úvazek s jedním vedoucím programátorem na plný úvazek (obdobně jako na projektu INGRES). POSTGRES tvořilo (cca po třech letech vývoje) zhruba 90 tisíc řádků kódu (některé moduly museli přepsat19). Dokument [STONE90] obsahuje i kritiku prvotní implementace „rules“ včetně návrhu nové implementace, která byla implementována v následující verzi20.
V roce 1989 v dokumentu „The Object-Oriented Database System Manifesto“ je definován koncept objektových databází. Tento koncept nevychází z relačního modelu, neřeší otázku dotazovacího jazyka, neřeší univerzální přístup k datům v databázi. V [STONE90–1] Stonebraker a spol. obhajuje relační model a navrhuje jeho rozšíření o podporu komplexních datových typů, navrhuje objektové typy a podporu OOP. Zejména však navrhuje SQL coby univerzální jazyk pro manipulaci s daty21. Z celého manifestu je patrně nejznámější věta „For better or worse, SQL is intergalactic dataspeak“22. Oficiálním autorem tohoto dokumentu není M. Stonebraker ale „The Committee for Advanced DBMS Functions“23 ve složení Stonebraker, Rowe (Berkeley), Lindsay (IBM), Gray (Tandem Coputers), Carey (Wisconsin), Brodie (GTE), Bernstein (DEC) a Beech (Oracle Corporation). Některé z návrhů v dokumentu se promítly do návrhu SQL 3 a posléze byly více či méně implementovány v několika RDBMS (Oracle, DB2, POSTGRES).
Třetí verze z roku 1991 přichází s přepsaným nepřepisujícím úložištěm (no-overwrite storage24). Při úpravě původní data nejsou přepsána novými – díky tomu lze zajistit obnovu po havárii bez transakčního logu25 a proces obnovy po havárii je znatelně jednodušší a rychlejší. Navíc předchozí data jsou stále dostupná, a je možné se k nim vracet.
V letech 1991 a 1992 Pamela Marcera a Silvia de Hoop implementovaly datové typy nezbytné pro podporu geografických informačních systémů.
append26 EMPLOY (Name = "Claire", Salary = 2000, ...) retrieve27 (EMPLOY.Name) where EMP.Salary > 2000 retrieve28 (how_many = count{EMPLOY.Name}) define function29 high_pay (language = "postquel", returntype = setof EMPLOY) as "retrieve (EMPLOY.all) where EMPLOY.salary > 1500" retrieve (overpaid = name(high_pay())) retrieve (E.Name) from E in EMPLOY*30 where E.Salary > 2000 retrieve (E.Salary) from E in EMPLOY["epoch","now"]31 where E.Name = "Sam" retrieve*32 into answer (parent.older) using a in answer where parent.younger = "John" or parent.younger = a.older
V létě 1991 byl zahájen projekt Sequoia 200033 – cílem tohoto projektu bylo vytvoření informačního systému pro podporu studia globálních změn. Projektu se účastnili vědci z oboru počítačových věd, vědci z environmentálních věd a zástupci vlády a průmyslu. Projekt zahrnoval vytvoření vysokokapacitních úložišť, vysokorychlostních sítí, distribuovaných souborových systémů, nástrojů pro vizualizaci dat, a distribuovaných databází s podporou prostorových dat a multidimenzionálních polí (např. satelitní snímky). Prakticky se také zkoušely první videokonference. Fakticky se jednalo o první masivní nasazení POSTGRESu. Díky tomuto projektu se během jednoho roku zdvojnásobil počat uživatelů. Úspěch projektu ale uspíšil konec projektu – úpravy a opravy vyžadované uživateli odčerpávali zdroje na vlastní výzkum, a tak POSTGRES jako vědecký projekt skončil34. Byla vydána poslední, čtvrtá verze, jejíž cílem bylo pročištění kódu.
V první polovině devadesátých let se na krátký čas setkává PostgreSQL a MySQL. Postgraduální student z univerzity v Bondu v Austrálii – David Hughes pro svůj projekt implementoval překladač z SQL do PostQUELu, který nazval miniSQL (nebo také mSQL). Při testování se ukázalo, že POSTGRES výkonnostně nevyhovuje jeho potřebám – a že je zbytečně komplexní. Proto začal hledat jiný databázový engine. Ve stejnou dobu ve švédské firmě TcX řešili opačný problém – pro svůj databázový engine UNIREG B+ ISAM handler hledali vhodný interface. Michael Widenius kontaktoval Davida Hughese a společně připravili první verzi MySQL 1.0 (1995). Díky internetu a velice tolerantní licenci se MySQL masově rozšířila. MiniSQL se dodnes vyvíjí pod hlavičkou HughesTechnologies, i když nikterak bouřlivě.
POSTGRES si na implementaci SQL musel ještě počkat – je s podivem, že implementace SQL pro POSTGRES nebyla zastřešena vědeckým projektem (a financována z grantů)35. Postgraduální studenti Andrew Yu36 (hlavní programátor Mariposy) and Jolly Chen zmodernizovali POSTGRES 4.1 pro použití ve svých projektech Mariposa a Tioga. PostQUEL nahradili jazykem SQL a provedli další pročištění a optimalizaci kódu. Výsledek své práce nazvali PostgreSQL9537. Po ukončení studií neměli dostatek volného času se věnovat PostgreSQL, a proto zveřejnili následující výzvu (1996):
„We appreciated [their] enthusiasm over the project. Since the code was already licensed in an open BSD-style, there wasn't much we needed to do as far as the turnover was concerned. They just set up some new mailing lists, ftp sites, and that was it. Neither Andrew nor I felt like we "owned“ the project. After all, postgres was the result of many graduate students work over the years, not ours alone."
Tato výzva byla počátkem komunitní verze PostgreSQL.
Již bylo zmíněno – PostgreSQL95 se ještě použil v projektech Mariposa (realizace masivně distribuované databáze) a Tioga (vizualizace dat, vizuální dolování dat). Další univerzitní projekty v Berkeley (např. TelegraphCQ38) vycházely z komunitní verzí PostgreSQL.
Komerční projekt Miro', Montage, Illusta 1992–2001
V roce 1992 M. Stonebraker spolu s G. Morthenthalerm39 zakládají startup Miro'. Cílem je vytvořit komerční databázi na základě POSTGRESu40, která by umožňovala prostřednictvím SQL manipulaci s multimediálními daty. V srpnu 1993 zahajují prodej pod názvem Montage Database a pod hlavičkou Montage Software, Inc. Jedním z investorů je zakladatel Informixu Roger Sippl. V Montage Database se poprvé objevují rozšiřující moduly pro podporu operací s textem – Text DataBlade, s grafikou – Image DataBlade a geografickými daty – Spatial DataBlade. Tato databáze také obsahuje modul Montage Viewer, který vychází z projektu Tioga. Ještě jednou se firma i produkt přejmenovává – tentokrát na Illustra information technologies a Illustra Server. Illustra byla první databází na trhu poskytující rozšiřitelnost (vlastní datové typy) ve shodě se standardem SQL3 [MORG05] a byla první databází, která byla určena pro nově vznikající trh SQL databází pro inženýrské a vědecké aplikace41.
V únoru 1996 Illustru kupuje Informix ($350M). M. Stonebraker se stává CEO Informixu. Vydává se poslední verze Illustry – Informix Illustra Server42 a pracuje se na integraci objektových vlastností do Informixu. To se povedlo částečně ve verzi 7 a plně ve verzi 9 – Informix IUS. Po roce 1997 se Informix opakovaně dostává do ztrát, které vrcholový management kamufluje manipulací s účetnictvím. V roce 1999 je již situace neudržitelná, akcie společnosti v několika dnech padají o 40 % a databázovou divizi Informixu (včetně produktů) přebírá do svého portfolia IBM.
V roce 2001 M. Stonebraker odchází na MIT, kde se věnuje novým databázových architekturám – Aurora (proudové databáze), C-store (sloupcové úložiště), H-store (paměťové databáze). Tyto nové architektury dokáží lépe pokrýt nové požadavky a lépe využít možnosti moderního hardware. Klasická databázová architektura vychází z možností a potřeb sedmdesátých let – omezená operační paměť, pomalé CPU, pomalá síť. Nynější možnosti jsou naprosto odlišné – dostatek operační paměti, rychlé SSD média, rychlé LAN, WAN, procesory s desítkami jader, možnost využití desítek, stovek počítačů v gridu. Univerzální architektura podporující OLAP i OLTP nedokáže efektivně využít výkon a možnosti moderního hw, protože specifické požadavky jdou proti sobě, a proto je praktické navrhovat a používat specializované databáze [STONE07].
Tento nový koncept reflektuje i zatím poslední projekt, na kterém se podílí prof. Stonebraker – databáze SciDB. Tato databáze je navržena pro předem jasně stanovený způsob využití – a podporuje dva dotazovací jazyky – první jednoduchý funkcionální jazyk AFL, druhý vycházející z zjednodušeného SQL – AQL.
Komunitní vývoj po roce 1996 do současnosti (2011)
Po převzetí kódu bylo nutné v prvé řadě opravit množství kritických chyb a „přeformátovat“ kód. Převzetí kódu a vydání první komunitní verze má na svědomí Marc Fournier (infrastruktura, koordinátor), Thomas Lockhart (dokumentace), Bruce Momjian (opravy, popularizace) a Vadim Mikheev (MVCC, WAL, subselects). Teprve poté začíná nový vývoj. Díky dostupnému zdrojovému kódu a licenci došlo velice brzo k lokalizaci PostgreSQL pro ruštinu a japonštinu43. Neustálé problémy s úniky paměti vyřešila až zásadní revize správy paměti (Tom Lane 7.1). Projekt na sebe nabaloval další vývojáře – k projektu se přidal Tom Lane (optimalizátor dotazu), Jan Wieck (PL/pgSQL44 (1998)) a další. Postupně došlo k opravě kritických chyb (řada 6 (1997)) a k úplné implementaci ANSI SQL 92 (řada 7 (2000)), vytvoření dokumentace a návodů, markantnímu zvýšení výkonu a portaci pro MS Windows (řada 8 (2005)) a konečně k implementaci k pokročilých funkcí – vestavěné replikace, vestavěného online fyzického zálohování, správy doplňků (řada 9 (2010)).
Vývoj PostgreSQL je živelný a poměrně dynamický, ale naštěstí bez dramatických momentů. Po letech pokusů a diskuzí vykrystalizoval vývojový model, který vyhovuje vývojářům i uživatelům. PostgreSQL vydává každý rok novou verzi a čtyřikrát do roka opravy. Roční vývojový cyklus je rozdělen na tři tříměsíční bloky věnované implementaci nových funkcí a tříměsíční blok věnovaný stabilizaci kódu. Patch do PostgreSQL může přihlásit kdokoliv, v rámci tříměsíčního bloku by měl být posouzen a přijat, nebo vrácen k dopracování nebo zamítnut.
PostgreSQL je jedním z mála komplexnějších Open Source projektů, jehož vývoj realizuje skutečně komunita vývojářů a nikoliv komerční subjekt. Vývoj je poměrně rovnoměrně rozdělen mezi několik firem45, které zaměstnávají a platí vývojáře a mezi dobrovolníky.
Komerční projekty po roce 2000 do současnosti (2012)
Poměrně dlouho se nedařilo nalézt obchodní model, který by umožnil komerčně distribuovat kód PostgreSQL (případně služby na PostgreSQL navázané). Firmy, které měly obchodní model postavený na PostgreSQL vznikaly a, bohužel, poměrně rychle zanikaly – např. Great Bridge LLC46. Dalším neúspěšným projektem byla společnost PostgreSQL, Inc. Marca Fourniera. Mezi roky 2002 a 2003 se PostgreSQL snažil propagovat RedHat (Red Hat Database)47. K popularitě PostgreSQL nepochybně přispěla veřejná podpora fy. Pervasive v roce 2005 – bohužel o rok později nabídku podpory ukončila. Počínaje rokem 2005 PostgreSQL masivně podporoval a propagoval Sun – jeho podpora se omezila v roce 2008 po převzetí MySQL AB (a úplně skončila po převzetí Oraclem).
Pravděpodobně nejznámější aktivní firmou, která komerčně distribuuje PostgreSQL je EnterpriseDB. Tato firma byla založena v roce 2004 Denisem Lussierem a Andy Astorem. Jejím hlavním produktem je PostgreSQL upravený tak, že je kompatibilní (více-méně) s RDBMS Oracle. Dalším produktem je software zjednodušující migraci databáze z Oracle do PostgreSQL. Jejich strategií je dodání databáze, která dokáže zastoupit Oracle za cca pětinové pořizovací a provozní náklady. S databází zákazník získává další přibalený software – z části se jedná o jejicch vývoj např. SQL/Protect48 – zbytek je volně dostupný O.S. software. EnterpriseDB zaměstnává několik vývojářů PostgreSQL, také investovala do vývoje několika zásadních funkcí (HOT UPDATE, PL/pgSQL debugger) a pravidelně sponzoruje konference věnované PostgreSQL. Interpret PL/SQL49 licencovala IBM (prostřednictvím investice do EnterpriseDB) a implementovala do DB2 9.7 – Oracle compatibility.
Dalším projektem postaveným nad PostgreSQL je Greenplum Database společnosti Greenplum založené v roce 2003 Scotem Yarou a Lukem Lonerganem. Jedná se o PostgreSQL rozšířený o podporu massively parallel processing (MPP). Úpravou optimalizátoru a exekutoru může tato databáze distribuovat zpracování dotazu mezi počítače umístěné v clusteru50.V roce 2005 Greenplum inicializoval vývoji Bizgresu – O.S. forku PostgreSQL upraveného pro potřeby datawarehousingu51. Po dvou letech vývoje došlo k ukončení projektu – přičemž Greenplum ale dále pokračoval v interním vývoji. V roce 2010 Greenplun vydal tzv Community Edition verzi, kterou lze volně používat.
Nejmladším projektem založeným nad kódem PostgreSQL je tPostgreSQL – což je verze PostgreSQL poskytující kompatibilitu s MS SQL Serverem. Zakladatelem projektu je Denis Lussier52 a Affan Salman. Databáze by měla být k dispozici začátkem roku 2013, a to pod licencí AGPL v3.
Akademické projekty po roce 2000
PostgreSQL byl použit v mnoha projektech věnovaných úpravám optimalizátoru případně testování nových funkcí jako základ prototypu – Xplus nebo RankSQL53, nebo implementace operátoru SKYLINE OF54 (výběr na základě multikriteriální optimalizace). Žádný z těchto projektů zatím neopustil akademické prostředí. PostgreSQL se uplatnil jako prototyp při testování návrhu a implementace operací FlashScan a FlashJoin (optimalizace fundamentálních operací pro SSD disky [TSIRO09].
Rozšířením PostgreSQL 7.1 o podporu datových proudů vznikla databáze TelegraphCQ.
Posledním trendem je masivní paralelní zpracování dat ve virtualizovaném prostředí. V duchu tohoto trendu je navržena databáze HadoopDB – závislost na PostgreSQL není příliš silná – autoři si zvolili PostgreSQL jako databázový backend, ale zrovna tak by si mohli vybrat jakoukoliv databázi, pro kterou existuje JDBC driver.
V posledních deseti letech se PostgreSQL používá mnohem intenzivněji nikoliv jako subjekt výzkumu, ale jako nástroj pro zpracování a organizaci dat – ať už se jedná o astronomii (pgSphere) nebo výzkum genomu. Nepřehlédnutelné je množství projektů využívajících PostGIS – podporu GIS pro PostgreSQL55.
Poměrně novou kategorií databází jsou vědecké databáze pro správu polí (arrays (raster) databases). Tyto databáze umožňují pracovat s poli jako s „first class“ objekty. Databáze tohoto typu umožňují uložit pole do množství fragmentů, čímž je možné obejít limity operačního systému a souborového systému. Nechybí ani podpora distribuovaných a paralelních výpočtů56. V druhé polovině devadesátých let byl zahájen projekt RasDaMan57 – pilotní projekt implementující podporu zpracování multidimenzionálních diskrétních dat s využitím SQL [RASDAMAN97]. RasDaMan může být provozován nad libovolnou relační databází – (fragmenty polí ukládá do BLOBu), nicméně ve výchozí instalaci se počítá s PostgreSQL, a také PostgreSQL je nejčastěji zmiňovaná RDBMS v souvislosti s tímto projektem58. Návrh Web Coverage Processing Service OGC vychází z konceptů a zkušeností z vývojem a nasazením rasdamanu – RasDaMan by měl být základem referenční implementace – aktuálně je RasDaMan je jedním z projektů v inkubátoru OSGeo.
PostGIS a OpenStreetMap od roku 2001 do současnosti (2011)
V roce 1998 Paul Ramsay zakládá konzultační firmu Refraction Research, která realizuje projekty pro úřad vlády Britské Kolumbie. Jedním z projektů byla správa geografických dat, kdy jedno z možných řešení bylo uložení dat do databáze. Zaměstnanec Refraction Research Dave Blasby navrhl implementaci typu GEOMETRY jako nativního PostgreSQL typu59 (v druhém kvartále roku 2001). Nativní implementace překvapila svým výkonem (byla o dva řády rychlejší než implementace s uložením dat v normalizované formě60 a o řád rychlejší než při použití BLOBů). S implementací prostorového indexu (využívajícího GiST – inspirací byla implementace R-Tree z contribu) byl základ PostGISu kompletní a byla vydána verze 0.1 (31. května 2001) [REFR08]. O dva měsíce později byla vydána verze 0.5, kde názvy funkcí odpovídaly specifikaci OpenGIS. Pro tuto verzi byla také přidána podpora do Mapserveru. Koncem roku 2003 byla uvolněna verze 0.8 obsahující plnou funkcionalitu vyžadující v „Simple Features for SQL“, a to díky integraci knihovny GEOS. Tato verze PostGISu se používala v RR i pro rozsáhlé projekty, kdy se začaly objevovat problémy s výkonem. Příčinnou těchto problémů byla neefektivnost typu GEOMETRY, který vyžadoval mnohem více prostoru na disku, než bylo nutné. Přepracovaný typ GEOMETRY se spolu s podporou MS Windows objevil ve verzi 0.9.
Verze 1.0 byla uvolněna v dubnu 2005. Další zásadní změny v PostGISu přišly o rok a půl později. Ve verzi 1.2 se „opouští“ specifikace OpenGIS a primární normou se stává specifikace SQL/MM. Ještě v roce 2007 vychází PostGIS 1.3, který pokračuje v postupné implementaci SQL/MM. Od roku 2008 se hlavním vývojářem PostGISu stává Paul Ramsey, který se původně věnoval dokumentaci a komponentám napsaných v Javě.
Začátkem roku 2009 Paul Ramsey opouští Refraction a přechází do OpenGeo (aby měl více prostoru pro vývoj a propagaci PostGISu), což je divize neziskové organizace OpenPlans61 zaměřená na podporu a vývoj Open Source GIS (PostGIS, GeoServer, GeoWebCache, OpenLayers, GeoExt – dohromady OpenGeo Suit). Od roku 2009 PostGIS je součástí iniciativy OSGeo62. V únoru 2010 vychází verze 1.5, která obsahuje typ GEOGRAPHY podporující geografické souřadnice. Připravovaná verze 2.0 (únor 2012) by měla být v mnohém přelomová – přináší podporu 3D (4D) a podporu rastrů.
Některé nové funkce v PostgreSQL byly implementovány (a financovány neziskovou organizací OpenGeo, která také financuje vývoj PostGISu) s přihlédnutím k potřebám PostGISu – implementace GiST KNN vyhledávání (výběr nejbližších bodů ve verzi PostgreSQL 9.1 a PostGIS 2.0) nebo implementace SP-GiST63(Space Partitioning Trees ve verzi 9.2).
Další populární projekt, který využívá PostgreSQL a věnuje se správě geografických dat, je OpenStreetMap. Projekt založil v červenci 2004 Steave Coast. Jeho inspirací byla Wikipedie. O dva roky později vzniká nadace OpenStreetMap Foundation, která projekt zaštiťuje. Cílem projektu je vytvořit a poskytovat volně dostupná geografická data. V listopadu 2011 bylo v OpenStreetMap zaregistrováno půl miliónu uživatelů a každý měsíc přibude cca 3 % dat [WIKIPEDIA]. Původně byla pořízená geografická data ukládána do MySQL. V dubnu 2008 OpenStreetMap přechází na PostgreSQL64 [RAMSEY0904]. Nyní má tato databáze cca 20GB zkomprimovaných dat (dekomprimovaná data včetně indexů více než 500GB). Na tento projekt jsou navázány další komerční i nekomerční projekty – namádkou MTB map Czech Republic, http://www.freemap.sk/.
Third-generation Database System Manifesto
Nelze doložit autorství návrhu objektově relačních databází M. Stonebrakerovi. Je ovšem nezpochybnitelné úsilí, které M. Stonebraker a jeho tým věnoval návrhu a propagaci tohoto konceptu. V dokumentu [STONE90–1] Stonebraker formuluje principy pro návrh na třetí generace65 databázových systémů a předkládá podrobnější teze, jak tyto principy realizovat – a tím de facto definuje novou generaci databázových systémů – objektově relační databáze. Jedná se o tyto principy:
-
Databáze třetí generace musí podporovat komplexní datové typy, případně kolekce hodnot těchto typů (např. text, složený typ, typy pro prostorová data),
-
Třetí generace DBMS zachovává (a rozšiřuje) funkcionalitu DBMS druhé generace – musí být zachován neprocedurální přístup a datová nezávislost (pod pojmem „datová nezávislost“ Stonebraker míní fyzickou datovou nezávislost – tj způsob přístupu k datům (index, halda) zvolí optimalizátor),
-
Třetí generace DBMS musí být otevřena ostatním subsystémům – databáze musí podporovat přístup z různých prostředí z různých aplikací.
Dokument [STONE90–1] obsahuje třináct tezí:
-
Databáze třetí generace musí podporovat komplexní datové typy – vlastní datové typy, typ pole, kompozitní datový typ, možnost rekurzivních (vnořených datových typů),
-
Databáze třetí generace by měly podporovat dědičnost,
-
Databáze třetí generace by měly podporovat procedury a metody (zapouzdření),
-
V případě, že uživatel nedeklaruje primární klíč, by databáze třetí generace měla být schopna přiřadit každému záznamu neměnný unikátní identifikátor,
-
Podpora rules (triggers, constraints) budou zásadní funkce databází třetí generace,
-
Veškerý přístup do databáze má být realizován prostřednictvím neprocedurálního vysokoúrovňového jazyka
-
Kolekce by měly být definovány jak staticky – výčtem, tak i dynamicky – dotazem,
-
Podpora aktualizovatelných pohledů je nutností,
-
Databáze by měla poskytovat nezávislé (na datovém modelu) metriky výkonu,
-
Databáze třetí generace by být dostupná z různých prostředí a z různých programovacích jazyků,
-
Neměla by chybět podpora persistentních objektů pro vysokoúrovňové jazyky v návaznosti na podporu komplexních datových typů,
-
SQL je základ, který umožňuje komunikaci – „SQL is intergalactic dataspeak“ – dotazy do DBMS třetí generace by měly být vyjádřeny v SQL, tím se zvýší nezávislost klienta na serveru.
-
Dotaz a výsledek dotazu může představovat nejnižší úroveň v komunikaci mezi klientem a serverem – podpora dalších prostředků, jako je např. záznam nebo datová stránka, zbytečně komplikuje datový protokol.
Stonebrakerovy projekty po roce 2000
Po převzetí Informixu IBM se Michael Stonebraker vrací zpět na akademickou půdu. Nikoliv ovšem do Berkeley, ale na MIT, kde se věnuje novým konceptům databázových systémů. Opouští svou ideu univerzálních databází ve prospěch jednodušších specializovaných databázových systémů66 (proudové databáze, sloupcové databáze a paměťové databáze), které svou architekturou odpovídají soudobým požadavkům a možnostem, které nabízí současný hw. Tyto projekty už nijak nesouvisí s PostgreSQL, nicméně je zmiňuji, protože poměrně dobře mapují vývoj v oblasti zpracování dat v posledních deseti letech.
Aurora, Medusa, Borealis
Cílem projektu Aurora67 bylo vytvoření prototypu správy dat68 vycházejícího z modelu datových proudů (data streams), přičemž návrh procesu zpracování dat vychází z konceptu „data-flow“69, který lze snadno vizualizovat a vizuálně navrhovat a udržovat.
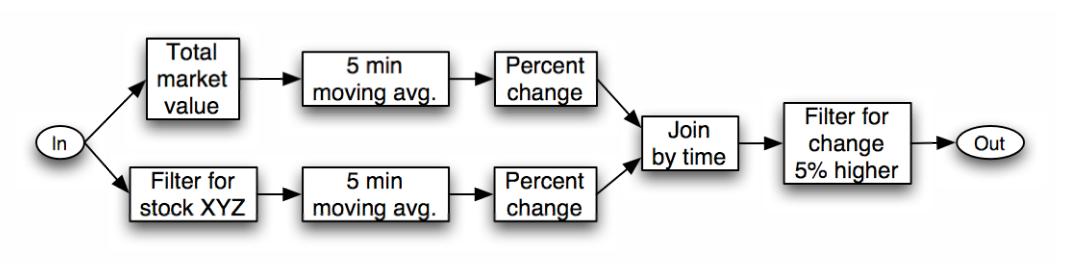
Vizuální dotaz v Auroře
V projektu Medusa šlo o distribuované zpracování datových proudů – zpracování bylo postaveno nad sítí úzlů systémů Aurora. Redesignem systému Aurora (a rozšířením o funkcionalitu distribuovaného zpracování z projektu Medusa) vznikl systém Borealis70.
C-Store
Pozornosti Michaela Stonebrakera neušly ani sloupcové databáze. Tento relativně nový (nebo znovu objevený) koncept uložení dat po sloupcích je vhodný pro analytické zpracování dat (OLAP). V této oblasti se typicky používají široké (denormalizované) tabulky. Velice často se pracuje s daty, které se zapisují hromadně a minimálně dochází k jejich aktualizacím (read optimized store). V testech zaměřených na analytické zpracování (TPC-H) dosahují sloupcové databáze několikanásobně lepších výsledků.
Databáze C-Store je výsledkem výzkumu Daniela J. Abadiho v letech 2005 a 2006 [ABADI08]. Paralelně s vývojem databáze C-Store probíhal vývoj databáze Vertica – což je komerčně vyvíjená databáze ve společnosti Vertica Systems71 (spoluzakladatelem je M. Stonebraker). Při jejím vývoji se uplatnily zkušenosti získané při vývoji a experimentování s C-Store.
H-Store
Databáze H-Store je pokusem o moderní extrémně výkonnou transakční SQL ACID databázi72 (OLTP), kde veškerá data jsou uložena v operační paměti a persistence dat a dostupnosti se dosahuje replikací dat na ostatní uzly v clusteru. Transakce jsou definovány uloženými procedurami napsanými v Javě (samotná databáze je napsaná v C++). V rámci jednoho uzlu a partition jsou tyto procedury prováděny sériově – odpadá tak režie spojená se zámky a izolací transakcí. Uvnitř procedur lze používat jednoduché SQL příkazy73. Na vývoji se podílel M. Stonebraker, Sam Madden a Daniel Abadi. Vývoj H-Store začal v roce 2007 a v roce 2009 byl projekt komercializován pod názvem VoltDB74.
SciDB
I když je SciDB jednou z nejmladších databází, má velké ambice prosadit se v oblasti správy extrémně velkých multidimenzionálních vědeckých dat. Tomuto účelu je podřízen návrh – opouští se relační model, zjednodušuje se a upravuje se SQL75. Databáze podporuje distribuci dat a distribuované zpracování dat. Předpokládá se, že do databáze se bude masivně paralelně zapisovat, že se nad daty poběží paralelně distribuované agregační úlohy a že data budou více-méně statická – oprav (UPDATE) bude minimálně. Zatímco v klasických SQL databázích je primárním objektem tabulka, ve SciDB je základním objektem multidimenzionální nezarovnané pole (ragged array) – které je přirozenou strukturou jak pro uložení časových řad tak i rastrů. Tato databáze by měla podporovat mraky (clouds) v rozsahu desítek tisíc uzlů. Neměla by chybět podpora Rka, Matlabu, C++, Pythonu.
CREATE ARRAY A <x: double NOT NULL, err: double> [i=0:99,10,0, j=0:99,10,0];
SciDB podporuje verzování dat a tudíž lze dohledat hodnotu platnou pro určitý okamžik:
SELECT * FROM A @ datetime('11-11-2010 09:00:00')76;
K vývoji SciDB se od začátku přistupovalo s cílem vyvinout databázi pro produkční nasazení, čímž se liší od výše uvedených projektů a je proto pravděpodobné, že se s SciDB budeme setkávat více.
Literatura
[ABADI08] Query Execution in Column-Oriented Database Systems , Daniel J. Abadi
MASSACHUSETTS INSTITUTE OF TECHNOLOGY, February 2008
[INGRES85] INGRES-Oracle Compararision – How to compete, Sandra Duerr
Ingres internal material, Computer History Museum, 2007
[INGRES87] A Comparision of RTI-INGRES and SYBASE,
Relation Technology, 1987, Computer History Museum, 2007
[INGRES07] RDBMS Workshop: Ingres and Sybase, moderator Dough Jerger
Computer History Museum, 2007
[LAI87] Analyzing and Improving the Performance of POSTGRES,
Computer Science Division, Electrical Engineering and Computer Sciences, University of California
[MORG05] Oral History of Gary Morgenthaler, Interviewed by Luanne Johnson,
Computer History Museum, 2005
[POSTGRES94] The POSTGRES User Manual, Edited by POSTGRES Group,
Computer Science Div, Depth. of EECS, University of California at Berkeley
[POSTGRESQL95] The POSTGRESQL95 User Manual, version 1.0, september 1995,
Andrew Yu and Jolly Chen (with POSTGRES Group)
[RASDAMAN97] The RasDaMan Approach to Multidimensional Database Management,
Peter Bauman, Paula Furtado, Roland Ritsch, Norbert Widmann,
Bavarian Research Centre for Knowledge-Based Systems, 1997 ACM Inc.
[ROWE87] The POSTGRES Data Model, L.A.Rowe, M.R.Stonebraker,
13th VLDB Conference, Brighton 1987
[ROWE91] The Picasso application framework, L.A.Rowe, J.A.Konstan, B.C.Smith,S.Seitz,C.Liu
ACM Sympossium on User Interface and Technology, 95–105
[SNOGRAS84] Temporal Query Language, Snograss Richard,
Department of Computer Science, University of North Carolina
[STONE80] Retrospection on a Database System, Michael Stonebraker
ACM Transaction on Database Systems, Vol 5, No. 2, June 1980
[STONE83] Performance Analysis of Distributed Data Base Systems, Michael Stonebraker, John Woodfill, Jeff Ranstrom, Joseph Kalash, Kenneth Arnold and Erika Andersen
Computer Science Division, Electrical Engineering and Computer Sciences
University of California
[STONE86] The Design of POSTGRES,
Michael Stonebraker and Lawrence A. Rowe,
Computer Science Division, Electrical Engineering and Computer Sciences,University of California,
ACMSIGMOD Conference, Washington, D.C., June 1986.
[STONE90] The Implementation of POSTGRES, M. Stonebraker, L. A. Rowe, M. Hirohama,
IEEE TRANSACTION ON KNOWLEDGE AND DATA ENGINEERING, VOL 2. NO. 1. 1990
[STONE90–1] Third-generation Database System Manifesto,
The committee for advanced DBMS Function,
SIGMOD RECORD, Vol. 19, No. 3, September 1990
[STONE07] The End of an Architectural Era (It's Time for Complete Rewrite)
Stonebraker, Madden, Abadi, Harizopoulos, Hachem, Helland
VLDB '07, September 23–28, 2007, Vienna, Austria
[TSIRO09] Query Processing Techniques for Solid State Drives , Tsirogiannis, Harizopoulos, Shah,
Wiener , Graefe
SIGMOD'09, June 29-July 2, 2009 ACM 978–1–60558–551–2/09/06
[RAMSEY0904] http://blog.cleverelephant.ca/2009/04/openstreetmap-moves-to-postgresql.html

[REFR08] http://www.refractions.net/products/postgis/history/
[WIKIPEDIA] http://en.wikipedia.org/wiki/OpenStreetMap
1Vývojový tým INGRESu byl prvním uživatelem Unixu mimo prostředí MIT [INGRES07].
2U.S. Air Force Office of Scientific Research, U.S. Army Research Office, National Science Foundation [STONE80]
3Tento jazyk je postaven na relačním kalkulu. SQL je založeno na relační algebře. Základní entitou QUELu je relační proměnná. Základní entitou v SQL je relace.
4V INGRESu bylo možné zvolit metodu pro přístup k datům („access method“, přičemž bylo možné implementovat vlastní metody – stačilo implementovat rozhraní Access Method Interface (AMI).
5Stejná historie se bude ještě několikrát opakovat u dalších Stonebrakerových projektů.
6Pozdější POSTGRES obsahoval podobné funkce jako temporální databáze – time travel. Při návrhu se ovšem nenavazovalo na Snograssův koncept. Možnosti POSTGRESu v této oblasti vycházely z konceptu nepřepisujících se dat, který byl navržen pro tehdejší velkokapacitní magneticko-optické média. Možnost přístupu k historickým verzím byla v rámci raných oprav PostgreSQL odstraněna (se záměrem reimplementace, ke které, nedošlo).
7V devadesátých letech se pracovalo na rozšíření ANSI SQL o funkce temporálních databází – tyto práce vedl Richard Snograss. Částečná podpora temporálních databází je v ANSI SQL:2011.
8Relation Technology se v roce 1989 přejmenovala na Ingres Corporation.
9Univerzitní kód bylo nutné optimalizovat (byl zrychlen o řád až dva řády) aby jej bylo možné prodávat.
10Oracle vykazoval 100% roční nárůst oproti 50% růstu INGRESu.
11Příkazy SQL se překládaly do QUEL.
12Oracle zamykal s granularitou řádků pouze pro příkaz SELECT FOR UPDATE. V ostatních případech byly zamykány celé tabulky. Oproti tomu INGRES ve většině případů zamykalo pouze datové stránky (které byly 2KB – podstatně menší než u Oracle). Nicméně z pohledu uživatelů byl byl návrh zámků v INGRESu hrubší a Oracle toho dokázal marketingově využít.
13SYBASE byla navržena na základě zkušeností z vývoje INGRESu (zakladatelem SYBASE byl jeden z vedoucích programátorů INGRESu Robert Epstein) – kód SYBASE obsahoval minimální závislosti na systémových voláních, SYBASE přišla s konceptem RAW IO atd.
14Toto API je součástí PostgreSQL, i když z bezpečnostních důvodů značně limitované (v porovnání s implementací v POSTGRESu).
15Každý ADT (Abstract Date Type) má definován název, velikost interní reprezentace v bajtech, funkce pro konverzi z externí reprezentace do interní a z externí do interní reprezentace a výchozí hodnotu.
16Procedurální datový typ byl konceptuální návrh předcházející návrhu funkcí. Uživatel mohl definovat typ jako dotaz – hodnota daného typu byla určena výsledkem dotazu [ROWE87].
17Pokud při vícenásobné dědičnosti nastane konflikt názvů atributů a dotčené atributy mají stejné datové typy, pak se předpokládá, že se jedná o jednu a tutéž hodnotu. Situace, že by dotčené atributy měly různé datové typy, není povolena. Díky podpoře dědičnosti se POSTGRES řadí mezi tzv objektově relační databáze.
18Pro uživatele univerzitního INGRESu byl POSTGRES zajímavý v té době i výkonnostně – v testech byl cca 1,5× rychlejší než university INGRES.
19Jedním z „omylů“ byl optimalizátor dotazů v LISPu. Původně měl být POSTGRES napsán kompletně v LISPu, ukázalo se ale, že pro některé moduly (správa cache datovch stránek) je C výrazně vhodnější a tudíž byly pro POSTGRES použity oba jazyky (cca 17000 řádků v LISPu, a cca 63000 řádků v C). Zásadní překážkou se ukázaly paměťové nároky LISPu, správa paměti využívající garbage collector (který bylo nutné obejít, aby bylo možné použít LISP v DBMS), a skutečnost, že kód v LISPu byl cca 2× pomalejší než kód v C. Z těchto a dalších důvodů se rozhodlo přepsat optimalizátor do C.
20S rules se můžeme setkat i v PostgreSQL. Transparentně se používají pro implementaci pohledů. Explicitně je lze použít pro implementaci materializovaných nebo aktualizovatelných pohledů. Lze je použít i místo triggerů – což je ve shodě s původním Stonebrakerovým návrhem – nicméně pro možné nechtěné vedlejší efekty to není doporučováno.
21Kromě jiného je to i obhajoba konceptů, podle kterých byl navržen a implementován POSTGRES.
22Proposition 3.3 [MANIFESTO90] – Tuto větu nemohl ponechat bez komentáře Chris Date – popularizátor SQL, a později nejhlasitější kritik SQL – spolu s Hughem Darwenem připravili jedenáctistránkový dokument „Third manifest“ (1995) obsahující kritiku Stonebrakerova konceptu a seznam požadavků na ideální dotazovací jazyk D. Své téze pak rozvedli v knize „Foundation for Object / Relational Databases: The Third Manifesto“ (1998).
23Dokument však nese zřejmé a neskrývané stopy Stonebrakerova rukopisu a také obsahuje některé odstavce ze specifikace POSTGRESu. V dalších projektech se M. Stonebraker nasazuje SQL a relační model i databázích, které s „klasickou architekturou“ nemají nic společného – Aurora (StreamBase), C-Store (Vertica), H-Store (VoltDB). Teprve v [STONE07] se objevuje kritika SQL – „SQL is Not the Answer“ – pro některé účely mohou být vhodnější specializované jednodušší (snazší na implementaci, snazší na naučení) dotazovací jazyky
24V roce 1992 bylo možné provozovat POSTGRES vůči vysokokapacitním datovým uložištím s optickými disky Sony Jukebox (360GB)- M.A.Olson – Extending the POSTGRES Database System to Manage Tertiary Storage
25O několik let později (v řadě 7) se transakční log (tentokrát již) v PostgreSQL objevuje znovu. Ukázalo se, že operace fsync na datových souborech představuje výkonnostní problém. Nepřepisující úložiště v PostgreSQL zůstalo – po úpravě je základem implementace multigenerační architektury MVCA (MGA), díky které UPDATE neblokuje SELECT (řada 6). Na možné výkonnostní problémy upozorňoval Stonebraker již v roce 1989 [STONE90] – zmýlil se v očekávání nástupu zařízení se stabilní (stable) operační pamětí, kde by se výkonnostní problém nemusel řešit.
26vložení záznamu – ukázka dotazovacího jazyka POSTQUEL [POSTGRES94]
27dotaz
28dotaz s agregací vracející počet zaměstnanců
29definice funkce – funkce hrály v POSTQUELu výraznou roli – používaly se místo pohledů a vnořených dotazů.
30Vratí seznam zaměstnanců a pracujících studentů (třída STUDENTP, která dědí třídu zaměstnanec) s mzdou vyšší 2000.
31Ukázka dotazu typu „time travel“ – vrací všechny historické hodnoty atributu mzda zaměstnance „Sam“.
32Rekurzivní dotaz – vrací všechny potomky Johna.
33Tento projekt pokračoval až do léta 1994
34M. Stonebraker se tou dobou plně angažoval v Illustře – kde bylo zaměstnáno také mnoho programátorů POSTGRESu. Systém pro uložení satelitních snímků pro další etapu projektu SEQUIOA byl již navržen pro Illustru, nikoliv pro POSTGRES. Zkušenosti z projektu byly nepochybně zúročeny v databázi Illustra.
35K PostgreSQ95 existuje minimum dokumentů – jediný zdroj informací je manuál [POSTGRESQL95]
36Andrey Yu je aktuálně (2012) zaměstnancem Greenplumu, kde vede skupinu zaměřenou na vývoj Hadoopu.
37Z této verze vychází komunitní PostgreSQL
38prototyp streamové databáze
39též spoluzakladatel Ingres corp.
40Jedná se o upravený (opravený) POSTGRES s podporou SQL
41díky tomu měla poměrně dobré šance uspět oproti zavedeným a dominantním RDBMS [MORG05]
42 Po ukončení vývoje Illustry se někteří zaměstnanci neúspěšně snažili o otevření kódu.
43Díky podpoře japonštiny byla velice brzo v PostgreSQL podpora vícebajtových kódování.
44Cílem bylo vytvoření integrovaného programovacího jazyka pro realizaci uložených procedur bez externích závislostí.
452nd Quadrant, EnterpriseDB, RedHat, Skype a další
46Great Bridge neuspěla – představovala ale zlom, kdy několik důležitých vývojářů se začalo věnovat PostgreSQL profesionálně.
47V RedHatu vzniklo několik nepříliš kvalitních a neintegrovaných nástrojů pro správu PostgreSQL, přesto ale díky RedHatu se PostgreSQL 7.3 a 7.4 stala nasazovanou databází v Enterprise sféře – a díky dlouhodobé podpoře (garantované RedHatem) má zaměstnání hlavní vývojář PostgreSQL Tom Lane. RedHat financuje opravy chyb v PostgreSQL.
48Modul do PostgreSQL zajišťující detekci a ochranu proti SQL Injection
49EnterpriseDB používá název SPL
50Ne tak úzce navázaná na PostgreSQL (mohla využívat i další O.S. databáze) s podobným zaměřením byla databáze ExtenDB Parallel Server ohlášená v prosinci 2005 (autorem je Mason Sharp). V roce 2008 tuto databázi převzala EnterpriseDB (2007) a jako součást balíku PostgreSQL Plus ji distribuovala pod názvem GridSQL včetně kódu. Začátkem roku 2011 byl vývoj GridSQL ukončen a EnterpriseDB se od tohoto produktu distancovala. Vývoj pokračuje pod názvem Stado (Jim Mlodgenski, Mason Sharp).
51Vývoj Bizgresu ustrnul v roce 2007 ve verzi 0.9 (vycházel z PostgreSQL 8.1) – určitý kód z Bizgresu se později portoval do PostgreSQL, kde přispěl k značnému zvýšení rychlosti dotazů ve verzích 8.3 a 8.4 (inmemory bitmap indexes, constraint exclussion, ..).
52Denis Lussier založil EnterpriseDB, Affan Salman byl vývojářem v EDB.
53Supporting Ranking Queries in Relational Database – optimalizace top-k dotazů
54Např. seznam viditelných budov by mohl být získán dotazem
SELECT * FROM building SKYLINE OF x DIFF, z MAX
55Díky PostGISu se PostgreSQL skutečně využívá k účelům, pro které byl před třiceti roky navrhován INGRES.
56např. databáze SciDB nebo MonetDB/SciQL
57Raster Data Management in Databases – vývoj byl financován Evropskou komisí v rámci programu ESPRIT (European Strategic Program on Research in Information Technology). RasDaMan je šířen pod GPL licencí.
58Ve French National Geographic Institute (IGN-F) zpracovávají dvanácti terabajtové letecké snímky v RasDaManu nad PostgreSQL.
59Ve své prezentaci – Keynote PGCon 2011 – shrnuje Paul Remsay důvody, proč PostGIS není součástí PostgreSQL (byť v roce 2011 připravil patch pro pg integrující PostGIS): licence (GPL x BSD), velikost (PostGIS 0.5 ~ 400KB zkomprimovaného kódu), kvalita (i kdyby v roce 2011 nebyl patch zamítnut z licenčních důvodů, tak by byl patrně zamítnut, jelikož nesplňoval požadavky na kód pg – vlastními slovy "it was fugly then. It’s fugly now ", a zejména nikdy nebyl zvláštní důvod pro integraci – navíc vlastní nezávislý vývoj přináší výhodu ve vlastní organizaci projektu.
60realizovaný podle „Simple Features for SQL“
61Na vývoji PostGISu se podílí také společnosti Keybit, Oslandia, Refraction, Paragon Corporation a Sirius
62Infrastrukturu nezbytnou pro vývoj (např. správu zdrojových kódů) zajišťuje OSGeo.
63SP-GiST je framework, který umožňuje implementaci K-D-Tree, Quadtree, Suffixtree indexů. V testestech nad reálnými daty se ukazuje, že výběr s těmito indexy je několikanásobně rychlejší než se stávajícím GiST indexem.
64Databáze OpenStreetMap nepoužívá PostGIS – slouží primárně pro pořízení a správu geodat. Obsah této databáze je periodicky exportován – do souboru formátu XML, který je veřejně k dispozici. Kromě primární databáze provozuje OpenStreetMap databázi osm_simple, která je již postavená nad PostGISem, a která obsahuje data načtena z primární databáze.
65První generací jsou databáze postavené nad hierarchickým a síťovým modelem, generací druhou pak klasické relační databáze bez možnosti používat komplexní datové typy a bez možnosti definování vlastních datových typů. Širšímu použití těchto databází bránilo jejich úzké zaměření na oblast ekonomických aplikací. Tyto databáze se nedaly použít pro uložení dat vytvořených systémy CAD nebe CASE.
66A jak je jeho zvykem – koncepty, vytvořené na akademické půdě přeměnil v komerční produkty (StreamBase, Vertica, VoltDB).
67Komercializací projektu vznikla DBMS StreamBase.
68Také se používá označení Data Stream engine, Stream database nebo Real-time database.
69Jiným přístupem je rozšíření SQL o koncept proudů dat – TelegraphCQ (fork PostgreSQL – Berkeley po roce 2000 – komerčně vyvíjený pod názvem Truviso (od 2006))
70Na vývoji se podílely Brandeis University, Brown University a MIT – aktivní vývoj cca do roku 2008.
71V dubnu 2010 byla Vertica Systems koupena HP za 350M $.
72H-Store je určená pouze pro OLTP – nemá smysl ji používat pro OLAP.
73Jelikož jsou transakce omezeny na uložené procedury, tak musí být veškerá byznys logika implementována v uložených procedurách – tím se minimalizuje režie ODBC/JDBC volání – a hlavně – je mnohem vyšší pravděpodobnost, že transakce budou krátké.
74Komunitní verze VoltDB je k dispozici pod licencí GPLV3.
75K dispozici je AQL – Array Query Language – což je SQL přizpůsobené jinému datovému modelu v SciDB a AFL – Array Functional Language – funkcionální jazyk se stejnou funkcionalitou jakou má AQL. Tato oblast databází se dynamicky vyvíjí – zatím se spíše jedná o akademický výzkum a tak chybí unifikace – obdobou AQL je SciQL, který je extenzí MonetDB.
76Vrátí obsah pole A v okamžiku 11–11–2010 09:00:00




















