
Obsah
1. Podpora SIMD instrukcí na mikroprocesorech řady HP PA-RISC
2. Rodina 32bitových mikroprocesorů řady HP PA-RISC
3. Mikroprocesory HP PA-7100, PA-7100LC a PA-7300LC
4. Multimedia Acceleration eXtensions 1 (MAX-1)
5. Seznam instrukcí obsažených v rozšiřující instrukční sadě MAX-1
6. Jak velká byla „oběť“ za podporu SIMD v případě procesorů PA-7100LC?
7. Multimedia Acceleration eXtensions 2 (MAX-2)
8. Seznam instrukcí obsažených v rozšiřující instrukční sadě MAX-2
1. Podpora SIMD instrukcí na mikroprocesorech řady HP PA-RISC
V předchozí části seriálu o architekturách počítačů jsme si řekli základní informace o rozšíření instrukční sady MDMX (MaDMaX, MIPS Digital Media eXtension), která byla používána u mikroprocesorů MIPS s architekturou RISC. Víme již, že technologie MDMX byla navržena a implementována s ohledem na to, aby bylo možné urychlit provádění rastrových operací, popř. operací se zvukovými daty. Pro tyto účely byly do instrukční sady mikroprocesorů MIPS přidány nové instrukce umožňující provádění aritmetických operací nad vektory obsahujícími osmibitové, popř. šestnáctibitové celočíselné hodnoty. Ve skutečnosti se však v případě technologie MDMX nejednalo o první využití instrukcí typu SIMD na RISCových mikroprocesorech. Prvenství si v tomto případě připsalo rozšíření instrukční sady MAX-1, která byla již v roce 1994 implementována v mikroprocesoru PA-7100LC, tj. mikroprocesoru patřícího do slavné rodiny 32bitových a posléze i 64bitových mikroprocesorů PA-RISC firmy Hewlett-Packard. Tato instrukční sada představuje první komerčně použitou implementaci SIMD instrukcí na mikroprocesorech vůbec, protože o dva roky předběhla i první Pentia s MMX.

Obrázek 1: Struktura moderní varianty multiprocesoru postaveného na čipech PA-RISC.
Připomeňme si, že první varianta RISCového mikroprocesoru řady PA-RISC, která nesla modelové označení TS-1, byla založena na integrovaných obvodech s technologií TTL majících nízkou a střední integraci, jenž byly umístěny na šesti deskách, takže se – podle striktního pojetí – vlastně ani o plnohodnotný mikroprocesor nejednalo. Po této spíše testovací verzi se již pro další mikroprocesory PA-RISC začaly používat podobné technologie integrovaných obvodů VLSI, jaké používali i konkurenční výrobci čipů. Mikroprocesory s označením NS-1 a NS-2 byly založeny na technologii NMOS, zatímco mikroprocesory s označením CS-1 (testovací série) a PCX (komerčně nabízený čip) používaly technologii CMOS. Celá 32bitová rodina těchto mikroprocesorů pokračovala řadou PCX-L a zakončena byla čipem pojmenovaným PCX-L2, po němž již následovaly 64bitové varianty mikroprocesorů PA-RISC (které byly mimochodem vybaveny SIMD instrukcemi MAX-2).

Obrázek 2: Mikroprocesor PA-RISC 7100LC. (Autor: Konstantin Lanzet)
2. Rodina 32bitových mikroprocesorů řady HP PA-RISC
V tabulce zobrazené pod tímto odstavcem jsou vypsány základní parametry 32bitových čipů řady PA-RISC. Z hlediska instrukční sady MAX-1 s instrukcemi typu SIMD nás bude zajímat především mikroprocesor PA-7100 a z něho v pozdějších letech odvozené čipy PA-7100LC i PA-7300LC. Růst počtu tranzistorů v celém více než desetiletém období, kdy byly tyto mikroprocesory vyráběny, byl způsoben především postupnou integrací dalších funkčních modulů na plochu jednoho čipu. Jednalo se například o druhou (paralelně pracující) aritmeticko-logickou jednotku, matematický koprocesor, jednotku pro řízení přístupu do operační paměti, řadič vyrovnávací paměti první úrovně atd.
| # | Model procesoru | Označení | Rok výroby | Frekvence (MHz) | Výrobní proces [µm] | Počet tranzistorů na čipu nebo multičipu |
|---|---|---|---|---|---|---|
| 1 | TS-1 | × | 1986 | 8 | ? | 115 000 |
| 2 | CS-1 | × | 1987 | 8 | 1.6 | 164 000 |
| 3 | NS-1 | × | 1987 | 25/30 | 1.5 | 144 000 |
| 4 | NS-2 | × | 1989 | 27.5/30 | 1.5 | 183 000 |
| 5 | PCX | × | 1990 | 50 | 1.0 | 196 000 |
| 6 | PCX-S | PA-7000 | 1991 | 66 | 1.0 | 580 000 |
| 7 | PCX-T | PA-7100 | 1992 | 33–100 | 0.8 | 850 000 |
| 8 | PCX-T | PA-7150 | 1994 | 125 | 0.8 | 850 000 |
| 9 | PCX-T' | PA-7200 | 1994 | 120 | 0.55 | 1 260 000 |
| 10 | PCX-L | PA-7100LC | 1994 | 60–100 | 0.75 | 900 000 |
| 11 | PCX-L2 | PA-7300LC | 1996 | 132–180 | 0.5 | 9 200 000 |

Obrázek 3: Mikroprocesor PA-RISC 7300LC. (Autor: Konstantin Lanzet)
3. Mikroprocesory HP PA-7100, PA-7100LC a PA-7300LC
Instrukční sada MAX-1, kterou se dnes budeme zabývat, byla poprvé představena jako součást 32bitového mikroprocesoru PA-7100LC, známého taktéž pod označením model PCX-L nebo též Hummingbird (kódové jméno). Tento mikroprocesor byl vyráběn s využitím 0,75mikronové technologie, měl zhruba 900 000 FET, plocha čipu byla 14,2×14,2mm a umístěn byl (většinou) v PGA pouzdru s 432 piny, popř. v MQUAD pouzdru s 240 a 304 piny. Jednalo se o mikroprocesor založený na úspěšném čipu PA-7100 (PCX-T) z roku 1992, který ovšem prošel celou řadou více či méně viditelných vylepšení. Na rozdíl od svého předchůdce měl totiž mikroprocesor PA-7100LC superskalární architekturu (s klasickou pětifázovou RISCovou instrukční pipeline) a zdvojenou aritmeticko-logickou jednotku určenou pro provádění operací s celými 32bitovými čísly – viz též následující obrázek. Díky zdvojené ALU bylo možné současně provádět až dvě instrukce, i když možnosti párování instrukcí byly v některých případech omezeny.

Obrázek 4: Mikroprocesor PA-7100LC byl vybaven třemi funkčními jednotkami: dvojicí ALU a matematickým koprocesorem.
Zatímco společně s aritmetickou instrukcí bylo možné spustit i instrukci typu „load/store“, popř. druhou aritmetickou instrukci, párování dvou operací „load/store“ bylo omezeno jen na speciální instrukce „double word load“ a „double word store“, které sloužily pro čtení či zápis ze dvou 32bitových slov umístěných v operační paměti na sousedních adresách (důvod je zřejmý – v případě přístupu do dvou slov se zcela rozdílnou adresou je nutné obětovat několik taktů pro vyslání nové adresy). Na čip PA-7100LC navázal mikroprocesor PA-7300LC z roku 1996. Pokud se podíváte do tabulky z předchozí kapitoly, můžete zjistit, že mezi oběma zmíněnými procesory jsou velké rozdíly jak v hodinové frekvenci (100MHz vs. 180MHz) a ve výrobním procesu (0,75 mikronu vs. 0,5 mikronu), tak i v celkovém počtu tranzistorů umístěných na jednom čipu. To je způsobeno tím, že firma Hewlett-Packard zaintegrovala do čipu PA-7300LC jak vlastní mikroprocesor a matematický koprocesor, tak i další moduly, zejména řadič vyrovnávací paměti první úrovně a jednotku pro řízení přístupu do paměti (MMU). Jednalo se o poměrně úspěšný mikroprocesor používaný v pracovních stanicích.

Obrázek 5: Tři způsoby zapouzdření mikroprocesoru PA-7100LC: pouzdro PGA s 432 piny, pouzdro MQUAD s 240 piny a pouzdro MQUAD s 304 piny.
4. Multimedia Acceleration eXtensions 1 (MAX-1)
Konstruktéři mikroprocesoru PA-7100LC se velmi pečlivě věnovali návrhu nové instrukční sady se SIMD instrukcemi. Dokonce pro tento účel vytvořili i jeden z prvních multimediálních benchmarků, díky němuž mohli provést analýzu a následnou optimalizaci instrukční sady. Výsledkem této snahy byla velmi malá a přitom elegantně navržená sada pouze devíti nových instrukcí, jejichž sémantika plně odpovídá základům, na nichž jsou postaveny prakticky všechny RISCové mikroprocesory (týká se to jak kódování instrukcí, tak i způsobu zaintegrování nových instrukcí do stávající instrukční sady). Nové instrukce byly určeny pro zpracování šestnáctibitových slov nazývaných „subword data“, popř. „halfword data“ (označením „word“ jsou v případě 32bitových mikroprocesorů PA-RISC samozřejmě myšlena 32bitová slova, menší informační jednotky se neadresovaly). Vždy dvojice šestnáctibitových slov mohla být uložena do libovolného pracovního registru GR1 až GR31, protože registr GR0 obsahoval konstantu 0, jak je tomu ostatně u RISCových procesorů zvykem.

Obrázek 6: Mikroprocesor PA-7100LC s chladičem. (Autor: Marcin ‚Rambo‘ Roguski)
Vzhledem k tomu, že každý pracovní registr mohl v případě nových instrukcí MAX obsahovat dva prvky, znamenalo to dvojnásobné urychlení některých základních aritmetických operací. Ve skutečnosti však bylo možné díky již zmíněnému párování ALU instrukcí pro dvě paralelně pracující aritmeticko-logické jednotky dosáhnout až čtyřnásobného urychlení. Jinými slovy: pokud nenastaly kolize při přístupu k pracovním registrům, bylo možné v každém taktu dokončit čtyři ALU operace prováděné nad šestnáctibitovými půlslovy (halfword). V době vzniku technologie MAX-1, kdy se výpočetní výkon mikroprocesorů pohyboval na hraně použitelnosti pro multimediální aplikace (například pro přehrávání videa ve formátu MPEG-1) se tedy jednalo o dosti výraznou pomoc. Navíc byly nové aritmetické operace přizpůsobeny pro zpracování multimediálních dat – bylo u nich možné zvolit, zda se bude provádět součet či rozdíl se saturací nebo s přetečením. To znamenalo další urychlení pro mnoho algoritmů z oblasti zpracování video a audio signálu.
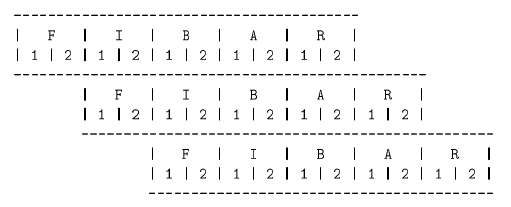
Obrázek 7: Superskalární pipeline mikroprocesorů PA-7100LC a PA-7300LC.
5. Seznam instrukcí obsažených v rozšiřující instrukční sadě MAX-1
Pojďme se nyní konečně podívat, jaké nové instrukce byly v rámci rozšiřující instrukční sady MAX-1 přidány ke stávající instrukční sadě PA-RISC (1). Jak jsme si již řekli v předchozím textu, jde o devět nových instrukcí určených pro provádění pouhých pěti operací. První trojici instrukcí tvoří instrukce pro provedení operace součtu dvou dvojic šestnáctibitových hodnot (HADD – half word add) s možností výběru, zda se má součet provést s přetečením (modulo) nebo se saturací. V případě provádění součtu se saturací se navíc určovalo, zda je minimální a maximální hodnota rovna 0×0000 a 0×ffff (čísla bez znaménka – unsigned) či 0×8000 a 0×7fff (čísla se znaménkem – signed). Další trojice instrukcí je obdobná, jsou ovšem určeny pro výpočet rozdílu dvojice dvouprvkových vektorů (HSUB – half word subtract). Třetím typem operace je výpočet průměru. Zde k saturaci ani k přetečení dojít nemůže, proto je tato operace reprezentována jedinou instrukcí HAVG (half word average).

Obrázek 8: Jeden ze serverů vybavených mikroprocesory PA-RISC: stroj HP9000-RP2400.
Poslední dvě instrukce jsou určeny pro posun hodnot doleva či doprava, který je následovaný součtem. Tyto instrukce lze použít například pro implementaci algoritmu násobení či dělení, což jsou operace, které z pochopitelných důvodů nejsou přímo součástí instrukční sady (tyto dvě aritmetické operace, pokud nejsou rozloženy do jednotlivých iterací, totiž nemohou být provedeny v RISCové pětifázové pipeline):
| # | Jméno instrukce | Prováděná operace | Aritmetika | Počet cyklů pro fázi execute |
|---|---|---|---|---|
| 1 | HADD | součet | s přetečením (modulo) | 1 cyklus |
| 2 | HADD,ss | součet | hodnoty se znaménkem, saturace | 1 cyklus |
| 3 | HADD,us | součet | hodnoty bez znaménka, saturace | 1 cyklus |
| 4 | HSUB | rozdíl | s přetečením (modulo) | 1 cyklus |
| 5 | HSUB,ss | rozdíl | hodnoty se znaménkem, saturace | 1 cyklus |
| 6 | HSUB,us | rozdíl | hodnoty bez znaménka, saturace | 1 cyklus |
| 7 | HAVG | průměr | hodnoty se znaménkem (k přetečení ani saturaci nemůže dojít) | 1 cyklus |
| 8 | HSHLADD | posun doleva+součet | hodnoty se znaménkem, saturace | 1 cyklus |
| 9 | HSHRADD | posun doprava+součet | hodnoty se znaménkem, saturace | 1 cyklus |

Obrázek 9: Sada serverů HP9000-RP2400 (viz též předchozí obrázek) umístěných v racku.
6. Jak velká byla „oběť“ za podporu SIMD v případě procesorů PA-7100LC?
Ze současného hlediska, kdy počet tranzistorů umisťovaných na jeden čip neustále roste, a to mnohdy bez znatelného nárůstu reálného výkonu, je zajímavé zjistit, jak složitá vlastně byla implementace SIMD instrukcí obsažených v instrukční sadě MAX-1 a jak se zvýšil výkon některých algoritmů využívajících tyto nové instrukce. Začněme nejdříve cenou, kterou bylo nutné „zaplatit“ za nové instrukce. Ta byla v podstatě nepatrná, protože implementace SIMD instrukcí MAX-1 zabrala pouze 0,2% plochy čipu! Tento zanedbatelný nárůst složitosti mikroprocesoru byl dosažen zejména pečlivým výběrem SIMD instrukcí a taktéž tím, že se díky použití obecných pracovních registrů pro provádění SIMD operací mohly využít již existující subsystémy umístěné na mikroprocesoru – dvojice aritmeticko-logických jednotek (ty se musely upravit jen minimálně), interní sběrnice atd. Naproti tomu se v případě instrukční sady MMX firmy Intel na toto hledisko z mnoha důvodů příliš nehledělo, takže se MMX instrukce provádí ve vlastních funkčních blocích, nezávisle na tom, že v mikroprocesoru již existuje dvojice ALU i dalších potenciálně využitelných bloků.

Obrázek 10: Mikroprocesor PA-7300LC. (Autor: Marcin ‚Rambo‘ Roguski)
Nyní se podívejme na to, zda se existence oněch devíti nových instrukcí nějak výrazně (či zda vůbec) projevila na výpočetním výkonu. V roce 1993, tedy zhruba rok před uvedením čipu PA-7100LC na trh, byla dokončena norma MPEG-1 popisující způsob kódování video a audio signálu (ostatně právě zde byl mj. popsán i MPEG Audio Layer III, neboli MP3). Tato technologie se začala používat v mnoha oblastech, například na Video CD a později i na Super Video CD a původně taktéž pro přenos digitální kabelové a satelitní televize (později došlo k náhradě za MPEG-2). Návrháři mikroprocesoru PA-7100LC chtěli, aby se nové SIMD instrukce mohly použít pro přehrávání videa MPEG-1 v reálném čase a to bez použití specializovaných čipů či DSP procesorů. To se jim skutečně podařilo, protože například na hi-end pracovní stanici 735/99 s procesorem bez podpory MAX-1 taktovaném na 99 MHz a 512 kB vyrovnávací paměti bylo možné přehrávat video se snímkovou frekvencí 18,7 fps, zatímco průměrná pracovní stanice 712 s procesorem taktovaným na 60 MHz s podporou MAX-1 a pouhými 64 kB vyrovnávací paměti se dosáhla při přehrávání snímkové frekvence 26 fps.
7. Multimedia Acceleration eXtensions 2 (MAX-2)
V roce 1995 byly firmou HP představeny 64bitové RISCové procesory nové generace, které začaly být používány již o rok později – v roce 1996. Skutečně se jednalo o zcela novou architekturu procesorů, která sice částečně převzala instrukční formát a další maličkosti z 32bitové platformy, ovšem interně šlo o zcela nové čipy. Tyto 64bitové mikroprocesory byly založeny na čtyřcestné instrukční pipeline (zatímco původní 32bitová řada měla buď jednu pipeline, popř. dvoucestnou pipeline) a umožňovaly provádět instrukce mimo pořadí (out of order), navíc byly vybaveny i prediktorem skoků. O provádění instrukcí se staralo celkem deset funkčních bloků – dvě aritmeticko-logické jednotky, dvě jednotky pro bitové posuny, dvě jednotky FMAC (fuse multiply-accumulate, matematické koprocesory pro základní aritmetické operace kromě dělení), dvě jednotky pro provádění dělení a výpočtu druhé odmocniny a konečně dvě jednotky určené pro načítání a ukládání dat do operační paměti.

Obrázek 11: Mikroprocesor HP-PA 8000.
Zdroj: Wikipedia
Kromě vylepšené interní struktury mikroprocesorů se zvětšila i bitová šířka pracovních registrů, které se rozšířily z původních 32 bitů na 64 bitů. To mělo samozřejmě velký dopad i na SIMD instrukce v rozšiřující instrukční sadě MAX, protože každý pracovní registr bylo možné použít pro uložení vektoru obsahujícího čtveřici 16bitových prvků. Již jen tento fakt znamenal dvojnásobné zvětšení výpočetního výkonu (například v případě již zmiňovaného dekódování videa uloženého podle standardu MPEG-1), ve skutečnosti se však reálný výpočetní výkon mohl při vhodné optimalizaci programů zvýšit ještě více, protože v ideálních případech bylo možné spustit dvě SIMD instrukce prováděné v aritmeticko-logických jednotkách a dvě SIMD instrukce prováděné jednotce (modulu) pro bitové posuny – viz též informace uvedené v navazující kapitole.

Obrázek 12: Mikroprocesor HP-PA 8500.
Zdroj: Wikipedia
8. Seznam instrukcí obsažených v rozšiřující instrukční sadě MAX-2
Vylepšená instrukční sada se SIMD operacemi dostala jméno MAX-2. Do stávajícího repertoáru „vektorových instrukcí“ byly přidány čtyři nové operace. Jedná se o bitové posuny doleva a doprava (jak posun logický, tak i aritmetický s kopií znaménka), operaci typu MIX pro kombinaci 16bitových prvků uložených ve dvou zdrojových registrech do prvků umístěných do registru cílového a konečně o operaci typu PERMUTE sloužící pro permutaci – změnu pořadí – 16bitových prvků umístěných v jediném zdrojovém registru. Všechny SIMD instrukce, včetně instrukcí převzatých z předchozí instrukční sady, jsou vypsány v následující tabulce:
| # | Jméno instrukce | Prováděná operace | Aritmetika |
|---|---|---|---|
| 1 | HADD | součet | s přetečením (modulo) |
| 2 | HADD,ss | součet | hodnoty se znaménkem, saturace |
| 3 | HADD,us | součet | hodnoty bez znaménka, saturace |
| 4 | HSUB | rozdíl | s přetečením (modulo) |
| 5 | HSUB,ss | rozdíl | hodnoty se znaménkem, saturace |
| 6 | HSUB,us | rozdíl | hodnoty bez znaménka, saturace |
| 7 | HAVG | průměr | hodnoty se znaménkem (k přetečení ani saturaci nemůže dojít) |
| 8 | HSHLADD | posun doleva+součet | hodnoty se znaménkem, saturace |
| 9 | HSHRADD | posun doprava+součet | hodnoty se znaménkem, saturace |
| 10 | HSHR | aritmetický posun doprava | hodnoty se znaménkem |
| 11 | HSHR,u | logický posun doprava | hodnoty bez znaménka |
| 12 | HSHL | logický posun doleva | hodnoty bez znaménka |
| 13 | MIXH | kombinace prvků umístěných v dvojici registrů | × |
| 14 | MIXW | kombinace prvků umístěných v dvojici registrů | × |
| 15 | PERMH | prohození pořadí prvků umístěných v jednom registru | × |
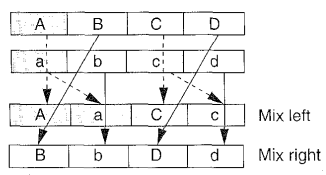
Obrázek 13: Schéma provedení instrukce MIX.

V předchozí kapitole jsme si řekli, že 64bitové mikroprocesory PA-RISC obsahovaly dvojici aritmeticko-logických jednotek (ALU) a dvojici jednotek pro bitové posuny (SMU). SIMD operace obsažené v instrukční sadě MAX-2 byly rozděleny podle toho, ve kterých jednotkách se spouštěly. To mělo velký význam pro paralelizaci operací. Pro zajímavost jsou v následující tabulce vypsány SIMD operace podle toho, ve které jednotce mohly být spuštěny. Díky jednoduchosti a eleganci instrukční sady MAX-2 a navíc díky velkému množství pracovních registrů byly optimalizace SIMD operací součástí překladačů a bylo je možné relativně snadno provádět i ručně:
| # | ALU operace | SMU operace |
|---|---|---|
| 1 | HADD | HSHR |
| 2 | HADD,ss | HSHR,u |
| 3 | HADD,us | HSHL |
| 4 | HSUB | MIXH |
| 5 | HSUB,ss | MIXW |
| 6 | HSUB,us | PERMH |
| 7 | HAVG | |
| 3 | HSHLADD | |
| 4 | HSHRADD |
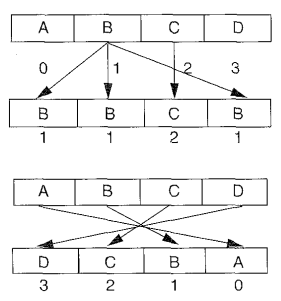
Obrázek 14: Schéma provedení instrukce PERMUTE.
9. Odkazy na Internetu
- OpenPA.net – PA-7100LC (PCX-L)
http://www.openpa.net/pa-risc_processor_pa-7100lc.html - OpenPA.net – PA-7300LC (PCX-L2)
http://www.openpa.net/pa-risc_processor_pa-7300lc.html - Multimedia Acceleration eXtensions (MAX-1 and MAX-2)
http://www.openpa.net/pa-risc_architecture.html#max - Architectures Hewlett-Packard PA-RISC Hewlett-Packard PA7300LC
http://rambo.id.uw.edu.pl/cpuengine.htm?show=Hewlett-Packard%20PA-RISC/PA7300 - PA-7100LC
http://en.wikipedia.org/wiki/PA-7100LC - PA7100LC ERS (External Reference Specification)
Hewlett-Packard Company (1999)
http://ftp.parisc-linux.org/docs/chips/PCXL_ers.pdf - The PA 7100LC Microprocessor: A Case Study of IC Design Decisions in a Competitive Environment
http://www.hpl.hp.com/hpjournal/95apr/apr95a2.pdf - NEON
http://www.arm.com/products/processors/technologies/neon.php - Architecture and Implementation of the ARM Cortex-A8 Microprocessor
http://www.design-reuse.com/articles/11580/architecture-and-implementation-of-the-arm-cortex-a8-microprocessor.html - Multimedia Acceleration eXtensions (Wikipedia)
http://en.wikipedia.org/wiki/Multimedia_Acceleration_eXtensions - AltiVec (Wikipedia)
http://en.wikipedia.org/wiki/AltiVec - Visual Instruction Set (Wikipedia)
http://en.wikipedia.org/wiki/Visual_Instruction_Set - MAJC (Wikipedia)
http://en.wikipedia.org/wiki/MAJC - MDMX (Wikipedia)
http://en.wikipedia.org/wiki/MDMX - MIPS Multiply Unit
http://programmedlessons.org/AssemblyTutorial/Chapter-14/ass14_3.html - Silicon Graphics Introduces Enhanced MIPS Architecture
http://bwrc.eecs.berkeley.edu/CIC/otherpr/enhanced_mips.html - MIPS-3D (Wikipedia)
http://en.wikipedia.org/wiki/MIPS-3D - MIPS Technologies, Inc. announces new MIPS-3D technology to provide silicon-efficient 3D graphics acceleration
http://www.design-reuse.com/news/2057/mips-mips-3d-technology-silicon-efficient-3d-graphics-acceleration.html - MIPS-3D Built-in Function (gcc.gnu.org)
http://gcc.gnu.org/onlinedocs/gcc/MIPS_002d3D-Built_002din-Functions.html - Baha Guclu Dundar:
Intel MMX, SSE, SSE2, SSE3/SSSE3/SSE4 Architectures - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - Cray History
http://www.cray.com/About/History.aspx?404;http://www.cray.com:80/about_cray/history.html - Cray Historical Timeline
http://www.cray.com/Assets/PDF/about/CrayTimeline.pdf - Computer Speed Claims 1980 to 1996
http://homepage.virgin.net/roy.longbottom/mips.htm - Superpočítače Cray
http://www.root.cz/clanky/superpocitace-cray/ - Superpočítače Cray (druhá část)
http://www.root.cz/clanky/superpocitace-cray-druha-cast/ - Superpočítače Cray (třetí část)
http://www.root.cz/clanky/superpocitace-cray-treti-cast/ - Superpočítače Cray (čtvrtá část)
http://www.root.cz/clanky/superpocitace-cray-ctvrta-cast/ - Superpočítače Cray (pátá část): architektura Cray X-MP
http://www.root.cz/clanky/superpocitace-cray-pata-cast-architektura-pocitace-cray-x-mp-a-jeho-pouziti-ve-filmovem-prumyslu/






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU