
Obsah
1. Interní reprezentace řetězců v různých jazycích: od počítačového pravěku po současnost
3. Řetězec bez ukončujícího znaku se známou délkou
4. Řetězec s předem známým ukončujícím znakem
6. Řetězce v programovacím jazyku C
7. Vylepšení práce s řetězci v UCSD Pascalu a Turbo Pascalu
8. Interpretry a překladače BASICu
9. Řetězce a pole řetězců v Sinclair BASICu
12. Řetězce podporující Unicode
14. Způsob ukládání řetězců na haldě v JVM
15. Nové trendy při práci s řetězci
16. Python 3.3 s flexibilní reprezentací řetězců
17. Otestování velikosti objektů typu řetězec v Pythonu 3.4.3
18. Interní reprezentace řetězce v Pythonu 3.4.3
1. Interní reprezentace řetězců v různých jazycích: od počítačového pravěku po současnost
Problematika ukládání řetězců nám sice může na první pohled připadat triviální, ovšem ve skutečnosti se jedná o dosti rozsáhlé téma, které je poměrně aktuální, protože mnoho aplikací zpracovává enormní množství řetězců (webové služby, postrelační databáze, ostatně i všechny moderní balíky „office“ interně pracují s relativně velkými dokumenty v XML), s řetězci (konkrétně s céčkovými řetězci) se pojí některé bezpečnostní problémy atd. Způsob interního ukládání řetězců ovlivňuje i operace, které je s nimi možné provádět, takže si při studiu jednotlivých technologií můžeme položit třeba následující otázky:
- Jsou řetězce neměnitelné (immutable) či měnitelné (mutable)? Obojí přístup má svoje výhody a samozřejmě i nevýhody. Mimochodem – většina dalších otázek se týká především měnitelných řetězců.
- Pokud jsou řetězce měnitelné, lze modifikovat i jejich délku či nikoli? V případě, že je délka měnitelná, znamená to, že runtime jazyka musí umožňovat realokaci paměti.
- Má jazyk rozpoznávat konstantní (statické) řetězce od měnitelných řetězců a zpracovávat je odlišným způsobem? Asi nejdále byla tato idea rozvinuta v jazyku Rust.
- Pokud je délka řetězce specifikována při jeho deklaraci a nelze ji dále změnit, co se stane ve chvíli, kdy se do řetězce přidají další znaky či se naopak znaky odeberou? Možností je opět více, například uživatelé Sinclair BASICu asi znají termín Prokrústéúv řetězec používaný u polí řetězců (více viz další kapitoly).
- Jakým způsobem a kde se uloží délka řetězce? K dispozici je několik možností – délku může znát jen překladač (původní Pascal, Fortran a kupodivu i některé moderní jazyky se statickými řetězci), délka může být uložena ve struktuře obalující řetězec, nebo se může použít vybraný znak reprezentující konec řetězce.
- Má řetězec obsahovat i další metainformace, například o použité kódové stránce? To je příklad typu AnsiString v Delphi 2009.
- Jak budou kódovány znaky v řetězci? Historicky se používal zejména EBCDIC a ASCII, později se rozšířily i takzvané „široké znaky“ a dnes je k výběru hned několik možností, jak reprezentovat všechny znaky z Unicode či jejich podmnožinu.
- V případě blokového přenosu (resp. častěji kopie) řetězců je taktéž nutné odpovědět na otázku, jak přesně se bude pracovat s koncem řetězce ve chvíli, kdy jeho délka nebude rovna celočíselnému násobku velikosti přenášené informace (typicky 2, 4 či osm bajtů). Jinými slovy – může se rutina pro práci s řetězci dovolit přistupovat ZA konec řetězce či nikoli?
2. Assemblery
Na stránkách Rootu jsme se již několikrát mohli setkat s takzvaným assemblerem neboli jazykem symbolických instrukcí (JSI), alternativně též nazývaným jazykem symbolických adres (JSA). Připomeňme si, že se jedná o nižší programovací jazyk, v němž je možné psát programy na úrovni jednotlivých strojových instrukcí konkrétního (vybraného) mikroprocesoru. To mimochodem znamená, že vzniklo prakticky nepřeberné množství assemblerů, mnohdy dokonce více assemblerů pro jediný typ mikroprocesoru (a naopak, některé assemblery podporují více architektur CPU). Assemblery vznikly proto, že programování na úrovni strojového kódu je velmi pracné, zejména ve chvíli, kdy je nutné existující program modifikovat a tím pádem měnit cílové adresy skoků, adresy globálních proměnných atd.
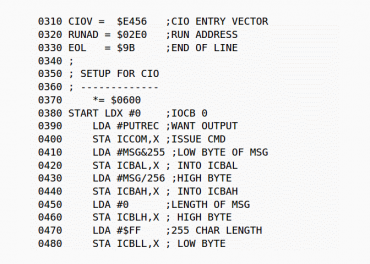
Obrázek 1: Úryvek programu napsaný v assembleru mikroprocesoru MOS 6502.
Assemblery tedy představovaly (a stále představují) mnohem civilizovanější způsob programování, než přímý zápis strojového kódu. Některé assemblery šly ještě dále, protože byly vybaveny více či méně dokonalým systémem maker (s parametry i bez parametrů, popř.s volitelným typem jejich expanze). Ostatně i z této vlastnosti vychází jejich běžné označení – macroassembler.
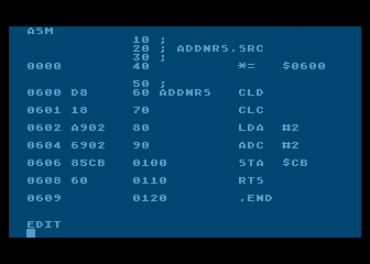
Obrázek 2: Vývojové prostředí Atari Macro Assembleru.
Na tomto místě si můžeme položit obvyklou otázku – jak se vlastně s řetězci pracuje v assemblerech a jak jsou řetězce reprezentovány? Vzhledem k tomu, že assembler je v hierarchii programovacích jazyků umístěn těsně nad strojovým kódem, je asi zřejmé, že reprezentace řetězců bude odpovídat zvyklostem architektury konkrétního mikroprocesoru a taktéž požadavkům operačního systému či knihoven, které se z assembleru volají.
Obrázek 3: Vývojové prostředí Zeus Assembleru.
3. Řetězec bez ukončujícího znaku se známou délkou
V tomto článku si ukážeme tři různé příklady, které se vždy týkají řetězců používajících kódování ASCII. První příklad je naprogramován pro mikroprocesory s architekturou x86 a je určen pro operační systém Linux. Po překladu a spuštění by se měla na standardní výstup vypsat klasická zpráva „Hello world!“, a to s využitím služby jádra operačního systému sys_write, které se předá file deskriptor standardního výstupu, adresa řetězce a jeho délka:
# asmsyntax=as
# Linux kernel system call table
sys_exit=1
sys_write=4
#-----------------------------------------------------------------------------
.section .data
hello_lbl:
.string "Hello World!\n"
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
mov $sys_write, %eax # cislo syscallu pro funkci "write"
mov $1,%ebx # standardni vystup
mov $hello_lbl,%ecx # adresa retezce, ktery se ma vytisknout
mov $13,%edx # pocet znaku, ktere se maji vytisknout
int $0x80 # volani Linuxoveho kernelu
movl $sys_exit,%eax # cislo sycallu pro funkci "exit"
movl $0,%ebx # exit code = 0
int $0x80 # volani Linuxoveho kernelu
Povšimněte si, že řetězec je v tomto případě reprezentován jako sled znaků, ovšem to samozřejmě nestačí – funkci jádra musíme dodat i informaci o adrese začátku řetězce a navíc i jeho délku (počet znaků). Díky tomu, že se délka řetězce předává v samostatném parametru, nemusí být řetězec ukončen speciálním znakem (tak, jak je tomu v dalších příkladech):
Pro architekturu AArch64 bude kód nepatrně odlišný (už jen proto, že se změnila čísla syscallů), ovšem s řetězci se bude pracovat shodně:
# Linux kernel system call table
sys_exit=93
sys_write=64
# List of syscalls for AArch64:
# https://github.com/torvalds/linux/blob/master/include/uapi/asm-generic/unistd.h
#-----------------------------------------------------------------------------
.section .data
hello_lbl:
.string "Hello World!\n"
#-----------------------------------------------------------------------------
.section .text
.global _start // tento symbol ma byt dostupny i linkeru
_start:
mov x8, #sys_write // cislo sycallu pro funkci "write"
mov x0, #1 // standardni vystup
ldr x1, =hello_lbl // adresa retezce, ktery se ma vytisknout
mov x2, #13 // pocet znaku, ktere se maji vytisknout
svc 0 // volani Linuxoveho kernelu
mov x8, #sys_exit // cislo sycallu pro funkci "exit"
mov x0, #0 // exit code = 0
svc 0 // volani Linuxoveho kernelu
4. Řetězec s předem známým ukončujícím znakem
Zatímco první příklad byl určen pro moderní operační systém (Linux) i pro moderní mikroprocesory (x86–64 a AArch64), pochází druhý assemblerovský příklad z poměrně dávné počítačové historie, konkrétně z dob kralování různých variant DOSu. Tento příklad, který poběží na všech mikroprocesorech řady Intel 8086, po svém překladu a spuštění taktéž vypíše zprávu na standardní výstup službou číslo 9, dále počká na stisk klávesy a následně se program ukončí (v případě COM programů stačí pro ukončení instrukce RET).
Opět se zaměřme na to, jak jsou reprezentovány řetězce. Nyní není reprezentace určena instrukční sadou ani snahou o kompatibilitu s vyššími programovacími jazyky, ale konvencemi použitého operačního systému, které v některých případech byly mimochodem „vypůjčeny“ ze staršího systému CP/M. Tyto konvence říkají, že při volání některých služeb jádra jsou řetězce ukončeny znakem $, takže jsme v assembleru museli tento znak explicitně zapsat (assembler to za nás v tomto případě neudělá automaticky). Vzhledem k tomu, že systém přesně ví, kde je řetězec ukončen, nemusí se službě jádra předávat jeho délka:
ideal
model tiny ;pametovy model CS=DS=SS mensi nez 64kB
p286 ;povoleny instrukce procesoru 286+
;-----------------------------------------------------------------------------
dataseg ;zacatek data-segmentu
message db "Hello world!$"
;-----------------------------------------------------------------------------
codeseg ;zacatek code-segmentu
org 0100h ;zacatek kodu pro programy typu COM
start:
;------ Tisk retezce na obrazovku
mov dx, offset message
mov ah, 9
int 21h
;------ Vyprazdnit buffer klavesnice a cekat na klavesu
xor ax, ax
int 16h
;------ Ukonceni procesu
retn
end start
Vzhledem ke značné flexibilitě assembleru v něm můžeme řetězce reprezentovat takovými způsoby, které budou vyhovovat vyšším programovacím jazykům a jejich knihovnám. V dalším příkladu se snažíme z assembleru volat známou funkci putc() ze standardní knihovny jazyka C. V céčku jsou řetězce uloženy jako sekvence znaků s ukončujícím znakem s kódem 0 (dnes jde většinou o znak NUL z ASCII), takže před voláním céčkovské funkce budeme muset připravit řetězce v tomto vyžadovaném formátu. To není prakticky žádný problém, protože pouze za vlastní sekvenci znaků přidáme nulu popř. můžeme v některých assemblerech použít makro či direktivu pojmenovanou například .asciz (GNU Assembler) či ASCIIZ (původní assembler pro PDP-10), která nulu doplní automaticky a samozřejmě pro ni zarezervuje bajt v operační paměti:
# asmsyntax=as
# Program pro otestovani volani funkci ze standardni knihovny jazyka C
# - volani funkce 'puts'
.intel_syntax noprefix
#-----------------------------------------------------------------------------
.section .data
hello_world_message:
.asciz "Hello world!\n" # zprava, ktera se ma vytisknout na standardni vystup
#-----------------------------------------------------------------------------
.section .text
.global main # tento symbol ma byt dostupny i linkeru
main:
sub rsp, 8 # zajistit zarovnani RSP na adresu delitelnou 16
# jedinym parametrem je adresa zpravy
mov rdi, offset hello_world_message
call puts # volani funkce 'puts' ze standardni knihovny
add rsp, 8 # obnoveni puvodni hodnoty RSP
xor eax, eax # navratova hodnota (exit status)
ret # ukonceni aplikace
5. Řetězce v původním Pascalu
Původní Pascal práci s řetězci prakticky žádným způsobem nepodporoval, pokud tedy nepočítáme možnost výpisu řetězcového literálu na terminál. Jediná datová struktura, která se řetězci podobala, bylo pole znaků, u něhož překladač znal jeho délku (délka je totiž součástí informace o typu, protože „open arrays“ začal Pascal podporovat až mnohem později). Takové pole se však inicializovalo poněkud těžkopádně; znak po znaku. Navíc nebylo přesně specifikováno chování v případě, že některé prvky pole nebyly inicializovány a řetězec se měl vypsat:
type
THistoricalString = array[0..10] of char;
var
aString: THistoricalString;
begin
aString[0] := 'H';
aString[1] := 'e';
aString[2] := 'l';
aString[3] := 'l';
aString[4] := 'o';
...
...
...
end;
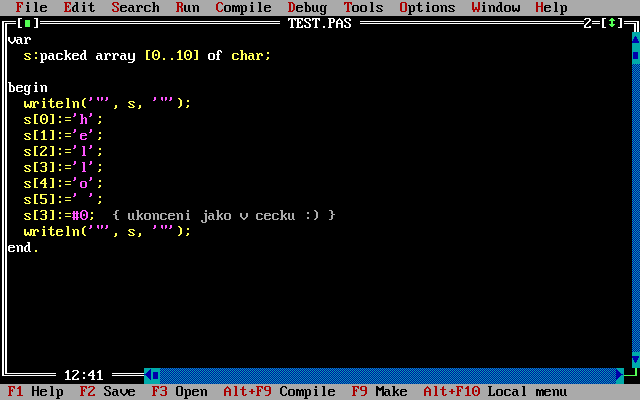
Obrázek 4: Takto přibližně vypadá „řetězec“ v původním Pascalu.
6. Řetězce v programovacím jazyku C
„To a lot of people, C is a dead language, and ${lang} is the language of the future, for ever-changing transient values of ${lang}. The reality of the situation is that all other languages today directly or indirectly sit on top of the Posix API and the NUL-terminated string of C.“
V tomto článku se samozřejmě nemůžeme nezmínit o jazyku C, protože způsob interní reprezentace řetězců v céčku ovlivnil celý další vývoj IT, což se týká například i instrukčních sad mikroprocesorů. Ostatně i například UTF-8 je navržen s ohledem na to, aby byl tento formát kompatibilní s céčkovými řetězci (význam nulového znaku). Zkráceně – v céčku jsou řetězce reprezentovány sekvencí znaků, přičemž tato sekvence je ukončena znakem s kódem nula (NUL v ASCII, ovšem céčko nemusí používat jen ASCII). To mimochodem znamená, že pro zjištění délky řetězce je nutné ho celý projít a najít, na kterém místě se ona nula nachází.
Proč byl vlastně zvolen tento formát uložení, když už před vznikem céčka existovaly odlišné formáty (například s délkou řetězce v prvním bajtu či slovu, adresou začátku i konce řetězce apod.)? Céčko je částečně odvozeno od programovacího jazyka B a když B vznikal, byly používány dosti rozmanité počítačové architektury, v nichž se bitová šířka znaků pohybovala od pouhých pěti bitů, přes běžnějších 7 a 8 bitů až po znaky o šířce 22 bitů. Stanovit tedy, že první znak bude obsahovat délku řetězce bylo poněkud ošemetné, zejména na strojích s pětibitovými znaky. Navíc by byla maximální délka řetězců závislá na použité platformě, což by nepřispělo k přenositelnosti programů.
Volba, kterou autoři céčka udělali, je proto pochopitelná; ostatně céčko bylo bez problémů portováno snad na všechny procesorové architektury, včetně DSP, které zpracovávají jen slova o šířce 32 bitů, počítačů používajících EBCDIC namísto ASCII atd.
7. Vylepšení práce s řetězci v UCSD Pascalu a Turbo Pascalu
Pro vývoj Pascalu se stal přelomovým projektem UCSD Pascal, který přinesl novinku – překlad do takzvaného P-kódu, jenž byl zpracováván virtuálním strojem, což je stejná technologie, jaká se používá doposud (Java, Python, Lua atd.). Navíc ještě UCSD Pascal přinesl podporu pro práci s řetězci, které již byly reprezentovány „klasickým Pascalovským“ stylem, tedy polem bajtů, jehož první prvek nesl informaci o délce řetězce. Tuto novinku později převzal i slavný Turbo Pascal, takže i v tomto jazyku lze poměrně flexibilně pracovat s řetězci o maximální délce 255 znaků.
Navíc zůstala zachována podpora i polí znaků (většinou se používá zápis packed array, i když packed Turbo Pascal ignoruje), přičemž konstantní pole znaků bylo možné inicializovat tak, jak je to patrné z dalšího obrázku (dost se to podobá céčkovému způsobu inicializace). Aby toho nebylo málo, podporuje Turbo Pascal typ PChar, jenž odpovídá céčkovskému char * se stejným významem. Tento typ se používá mj. i pro nulou ukončené řetězce.
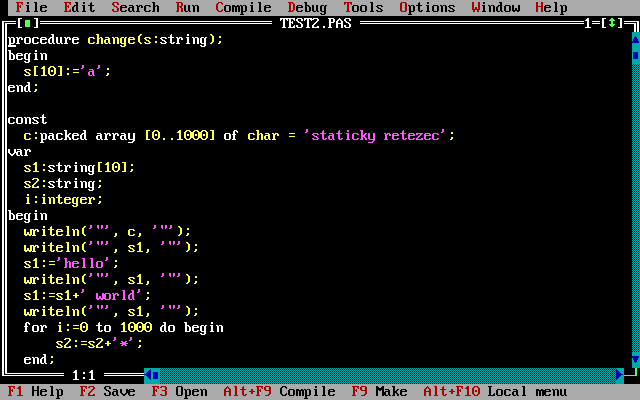
Obrázek 5: Některé operace, které lze s řetězci provádět v Turbo Pascalu.
8. Interpretry a překladače BASICu
Při popisu vývoje různých způsobů reprezentace řetězců samozřejmě nesmíme zapomenout ani programovací jazyk, jehož více či méně kvalitní dialekty existovaly prakticky pro všechny typy domácích (ale i profesionálních) osmibitových počítačů. Jedná se samozřejmě o jazyk BASIC (Beginner's All-purpose Symbolic Instruction Code), jehož syntaxe a především sémantika pozitivně, ale i negativně ovlivnily celou jednu generaci programátorů (včetně autora tohoto článku :-). Ovšem tento programovací jazyk je z historického hlediska zajímavý i proto, že se v souvislosti s jeho vývojem poprvé objevují jména Bill Gates a Paul Allen spolu s jejich společností původně nazývanou Micro-Soft.

Obrázek 6: Manuál k původnímu BASICu.
Programovací jazyk BASIC byl vyvinut v roce 1964 J. G. Kemenym a T. E. Kurtzem na universitě v Dartmouthu. Kemeny a Kurtz tento jazyk navrhli s ohledem na to, aby umožnili rychlé osvojení ovládání počítačů i jejich programování pracovníkům a studentům, kteří nejsou (a ani nechtějí být) specialisty na programování, ale potřebují problémy řešené v jejich praxi vhodným způsobem algoritmizovat a následně vhodným způsobem zapsat tak, aby počítač mohl zapsané algoritmy skutečně provést. Důraz na co největší jednoduchost jazyka se projevil například omezením počtu proměnných na 26, automatickou deklarací a inicializací proměnných (což je u větších programů velmi záludná vlastnost), existencí (původně) pouze jednoho datového typu atd.

Obrázek 7: BASIC pro mikropočítače Apple-II.
9. Řetězce a pole řetězců v Sinclair BASICu
Zajímavé je, že první verze BASICu práci s řetězci vlastně vůbec nepodporovala; tato velmi důležitá funkcionalita byla do jazyka přidána až o rok později, tedy v roce 1965. Od té doby se však jednalo o nezbytnou součást BASICu, i když funkce a operace pro práci s řetězci byly v různých dialektech dosti odlišné. Pro představení dvou způsobů uložení řetězců se podívejme na Sinclair Basic a Atari Basic, což jsou dva interpretry, které se od sebe v mnoha ohledech velmi liší.

Obrázek 8: BASIC na slavném mikropočítači ZX-81.
Sinclair Basic podporuje práci s běžnými řetězci, které mohou mít flexibilní délku, není nutné dopředu udávat jejich velikost a lze s nimi provádět řadu zajímavých operací díky podpoře takzvaného „slicingu“ (specifikaci podřetězce zadáním indexu prvního a posledního znaku):
10 LET a$="abcdef" 20 FOR n=1 TO 6 30 PRINT a$(n TO 6) 40 NEXT n 50 STOP

Obrázek 9: Znaková sada mikropočítače ZX80 a taktéž i mikropočítače ZX81, která byla uložena v paměti ROM, jejíž celková kapacita dosahovala 4kB resp. 8kB (nejvíce místa zabral interpret jazyka Basic). S využitím znaků z této sady bylo možné vykreslit i poměrně věrohodné obrázky a složité herní scény. Povšimněte si, že tato znaková sada neodpovídá ASCII a navíc obsahuje pouze 64 znaků; dalších 64 znaků jsou jen inverzní varianty.
Kromě běžných řetězců lze v Sinclair Basicu pracovat i s poli řetězců, ovšem v tomto případě mají řetězce uložené v poli konstantní velikost specifikovanou při vytváření pole příkazem DIM. Všechny operace s řetězci uloženými v poli zajistí, že se nezmění délka řetězce – kratší řetězce jsou doplněny na plnou délku, potenciálně delší řetězce jsou uříznuty, opět tak, aby se řetězec nezvětšil nebo nedošlo k přepisu paměti, která mu nepatří. Toto chování se někdy nazývá Prokrústéovo přiřazení podle postavy Prokrústéa z řecké mytologie (ten ovšem nepracoval s řetězci, ale s lidmi :-).
Obrázek 10: Editace programu na ZX Spectru v řádkovém editoru.
Interně jsou řetězce uloženy ve formátu naznačeném na osmém obrázku. Povšimněte si, že pro jméno řetězce zbylo jen pět bitů, takže jméno může být jen jednopísmenné. Délka řetězce je – z pohledu kapacity operační paměti ZX Spectra – neomezená, což je velký rozdíl oproti klasickým „Pascalovským řetězcům“ omezeným na 255 znaků.
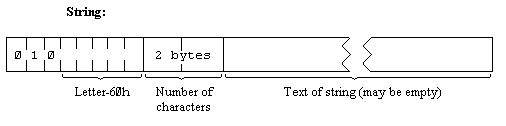
Obrázek 11: Formát uložení řetězců.
10. Řetězce v Atari BASICu
Poněkud odlišným způsobem je uložení řetězců realizováno v Atari BASICu. V tomto dialektu BASICu je totiž nutné velikost řetězce předem určit příkazem DIM, který současně i provede alokaci paměti pro řetězec. V paměti jsou přitom uloženy dvě struktury, které řetězec plně popisují – jedná se především o sekvenci znaků v kódování ATASCII (odvozeno od ASCII doplněním spodních 32 znaků a změnou několika běžných znaků) a taktéž o strukturu o délce osmi bajtů, která obsahuje typ proměnné (první bajt), index jména proměnné s řetězcem (druhý bajt), adresu začátku řetězce (přesněji řečeno offset), alokovanou délku řetězce (maximálně 32767 znaků) a aktuální délku řetězce (opět maximálně 32767 znaků). To znamená, že i když je například provedena alokace pro řetězec o délce 1000 znaků, může v něm být reálně uloženo jen deset znaků.

Obrázek 12: Po inicializaci interpretru Atari Basicu je k dispozici 37902 volných bajtů. Po alokaci řetězce o délce deseti znaků přijdeme celkem o 20 bajtů – dva bajty zabere název proměnné, osm bajtů struktura popsaná výše (typ+index proměnné, adresa řetězce, jeho maximální délka a aktuální délka) a zbylých 10 bajtů je vyhrazeno pro vlastní řetězec.
Veškeré operace s řetězci jsou zcela bezpečné, protože nikdy nedojde k překročení jeho délky (přepisu jiné paměti); při spojování řetězců dojde k ukončení na předem stanoveném limitu. Mimochodem: poměrně častým trikem bylo uložení strojových instrukcí do řetězce, zjištění adresy řetězce funkcí ADR a „spuštění řetězce“ další funkcí USR.

Obrázek 13: Pokud alokujeme další řetězec o maximální kapacitě 100 znaků, přijdeme o 110 bajtů. Opět platí, že „chybějících“ deset bajtů bylo použito pro jméno proměnné, její typ, adresu+délku+maximální délku řetězce.
Vzhledem k tomu, že Atari BASIC neumožňuje ukládat řetězce do polí, bylo možné operátor indexování () „přetížit“ takovým způsobem, že je možné přistupovat jak k jednotlivým znakům řetězce, tak i k podřetězci (jedná se tedy o slicing). Tento operátor je možné použít i na levé straně přiřazovacího příkazu pro změnu vybrané části řetězce:
10 DIM S$(15),T$(15),Q$(15) vypíše se 20 S$="ATASIC":PRINT S$ ATASIC 30 Q$=S$(3,5):PRINT Q$ ASI 40 T$="RI_BA":PRINT T$ RI_BA 50 S$(7,13)="T$:PRINT S$ ATASICRI_BA 60 S$=S$(1,6):PRINT S$ ATASIC 70 T$(6,9)=S$(4,6):PRINT T$ RI_BASIC 80 S$(4)=T$:PRINT S$ ATARI_BASIC 90 Q$=S$(1):PRINT Q$ ATARI_BASIC 100 Q$=S$(1,1):PRINT Q$ A

Obrázek 14: Z výpisu adres řetězců je zřejmé, že jsou v paměti uloženy těsně za sebou (první řetězec má délku 10 znaků) a že se nepočítá s žádným ukončovacím znakem.
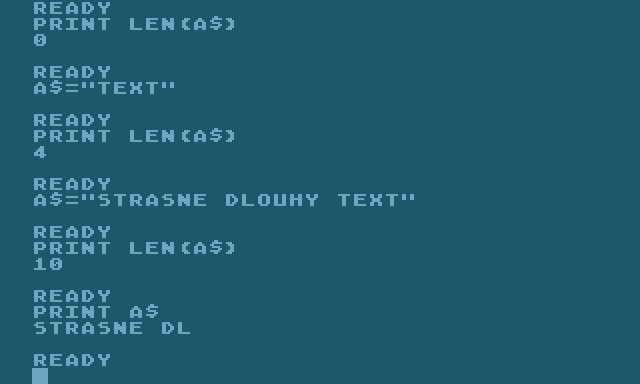
Obrázek 15: Do řetězce A$ o kapacitě deseti znaků můžeme uložit kratší text a zjistit jeho délku. Při snaze o uložení delšího textu nedojde k žádné chybě a už vůbec ne k přepisu cizí paměti – řetězec se pouze na příslušném místě odřízne.
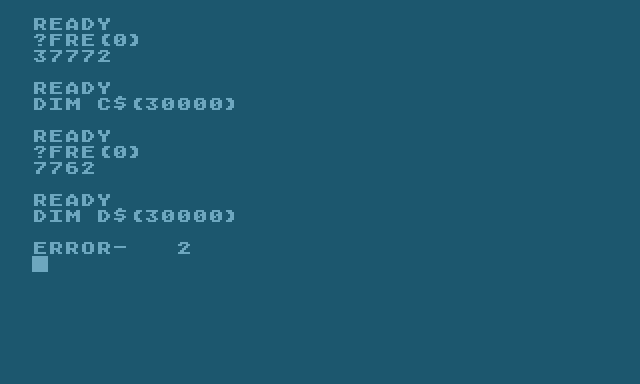
Obrázek 16: Pokus o alokaci řetězce, který se již nevejde do volné operační paměti samozřejmě skončí s chybou a proměnná nebude vytvořena.
11. Příchod moderních programovacích jazyků – automatická správa paměti, problematika „širokých“ znaků
„I always thought it was a rite of passage for all C++ programmers to write their own string library“
Jazyk C i Pascal (například Turbo Pascal před rozšířením o OOP) je možné považovat za klasické překládané jazyky, které se v devadesátých letech používaly pro tvorbu většiny aplikací. Postupně se však začaly rozšiřovat moderní (a „moderní“) programovací jazyky, ať již kompilované (C++) nebo skriptovací (zpočátku TCL a Perl, později Python a Ruby, ať dodržíme pořadí jejich vzniku). Většina těchto jazyků více či méně úspěšně řešila problematiku automatické správy paměti při práci s řetězci. Příkladem jednoho řešení může být Delphi 2 používající alokaci řetězců na haldě (heapu) s počítáním referencí (což je řešení, které například u klasického C nelze použít).
Navíc se s příchodem desktopových aplikací a rozsáhlých databází používaných mezinárodními firmami začala ukazovat potřeba rozumného a unifikovaného kódování znaků různých abeced, protože řešení spočívající v použití kódových stránek (u nás CP852 neboli PC Latin 2, ISO-8859–2 neboli ISO Latin 2, KOI-8 CS2 definovaná CSN 36 9103, neoficiální ale o to povedenější stránka bratrů Kamenických, Windows-1250, MacOS CE atd.) vede u mezinárodně používaných aplikací k mnoha problémům (ostatně i dnes ještě narazíme například na webové stránky, jejichž kódování neodpovídá hlavičce posílané serverem a podobné špeky).

Obrázek 17: Spolu s rozšiřováním Fortranu z mainframů firmy IBM na další architektury se zvyšovala potřeba standardizace tohoto jazyka. Postupně vzniklo několik norem, například ANSI norma FORTRAN 66, FORTRAN 77, či ANSI/ISO standard Fortran 90 (názvy standardů jsou uvedeny správně – jméno jazyka se skutečně postupem času změnilo z „FORTRAN“ na „Fortran“).
12. Řetězce podporující Unicode
Do mnoha jazyků se začala z výše uvedených důvodů postupně přidávat podpora pro takzvané „široké znaky“. Jazyk C byl v rámci standardu C90 rozšířen o typ wchar_t (ten ovšem nemá pevně specifikovanou šířku), a v roce 2011 o typy char16_t a char32_t s explicitní šířkou, ovšem bez specifikace kódování (většinou char16_t používá UCS-2 a char32_t UCS-4). Podobně bylo rozšířeno i zmíněné Delphi, nejdříve o typ AnsiString v Delphi 2 a později o Unicodestring v Delphi 2009. Přechod na „široké znaky“ se samozřejmě nevyhnul ani skriptovacím jazykům, takže například Python používal buď UCS-2 (typicky ve verzi pro Windows) nebo UCS-4 při překladu na Linuxu (ovšem jedná se o volitelné nastavení, které lze změnit při překladu). Další příklady, včetně novinek přidaných do Pythonu 3.3, jsou uvedeny v navazujících kapitolách.
V současnosti se můžeme nejčastěji setkat se čtyřmi interními reprezentacemi řetězců:
- 8bitové kódování (ASCII, kódové stránky, některé aplikace „zkousnou“ i UTF-8)
- 16bitové kódování, typicky UCS-2 (ovšem nevyhovuje například z toho důvodu, že budou problémy na čínském trhu), existuje i ve variantě UTF-16, což je to nehorší z obou světů :-)
- 32bitové kódování, typicky UCS-4
- variabilní délka znaků, UTF-8 (používáno například v Rustu)
13. Formát řetězců v Javě
V Javě se na řetězce můžeme dívat dvěma pohledy. Na jednu stranu se jedná o pouhou třídu, jejíž instance lze vytvářet s využitím operátoru new, na stranu druhou však pro práci s řetězci existuje podpora v samotné syntaxi a sémantice tohoto programovacího jazyka, protože do programů je možné zapisovat řetězcové literály (konstantní řetězce) a navíc pro řetězce existují přetížené verze operátorů + a += (nikoli však již operátoru ==, což stále vede ke vzniku mnohdy těžko objevitelných sémantických chyb). To však není vše, protože řetězcové literály jsou ukládány v constant poolu (http://www.root.cz/clanky/pohled-pod-kapotu-jvm-2-cast-podrobnejsi-analyza-obsahu-constant-poolu), takže řetězce jsou skutečně na platformě Java zpracovávány jiným způsobem, než další třídy a jejich instance (navíc s JDK7 existuje pro řetězce speciální forma rozeskoku switch – viz též http://www.root.cz/clanky/novinky-v-nbsp-jdk-7-aneb-mirny-pokrok-v-nbsp-mezich-zakona-1/).
Z hlediska vývojáře je důležitý taktéž fakt, že řetězce jsou neměnitelné (immutable), což s sebou přináší jak některé výhody, tak i komplikace, především ve chvíli, kdy se mají s řetězci provádět složitější operace. Interně řetězce vypadají poměrně jednoduše, alespoň při prvním pohledu, protože jsou tvořeny polem char[], což znamená, že každý prvek tohoto pole má velikost šestnáct bitů. Pro většinu abeced platí, že každý znak uložený v tomto poli skutečně odpovídá jednomu znaku dané abecedy (latinky, azbuky, alfabety …), ovšem ve skutečnosti není možné v rozsahu 0..216 reprezentovat libovolný znak definovaný v normě Unicode. To platí pouze pro znaky s kódem 0×0000 až 0×FFFF, které se někdy označují názvem Basic Multilingual Plane (BMP), které jsou v řetězci uloženy stylem jeden_znak_abecedy == 1 char. Pro znaky s vyšším kódem (až 0×10FFFF) je nutné v řetězci vyhradit pár hodnot typu char, tento pár se jmenuje surrogate pair.
14. Způsob ukládání řetězců na haldě v JVM
Na haldě (kde se alokují všechny objekty, tj. referenční datové typy), je každý řetězec představován dvěma objekty – instancí třídy String a instancí pole char[] – toto pole je sice atributem třídy String, ovšem pole jsou, chápána jako objekty, tudíž se namísto pole ukládá pouze jeho reference. To s sebou nese určitou (osobně bych řekl, že velmi velkou) režii, která vede k tomu, že řetězce používané v typických Javovských aplikacích spotřebují daleko větší množství operační paměti, než je na první pohled patrné.
Nejprve se podívejme na to, jak je uložena každá instance třídy String:
| # | Velikost (B) | Struktura | Popis |
|---|---|---|---|
| 1 | 8 | HEADER | hlavička objektu (přiřazena každému objektu na haldě) |
| 2 | 4 | int offset | atribut offset instance třídy String |
| 3 | 4 | int count | atribut count instance třídy String |
| 4 | 4 | int hash | atribut hash instance třídy String |
| 5 | 4 | char[] | reference na pole znaků |
Celková velikost paměti pro uložení instance třídy String je tedy minimálně 24 bajtů, a to pouze v případě, že reference na objekty má šířku 32 bitů a nikoli 64 bitů (i to je možné v případě větších kapacit hald). Oněch 24 bajtů se označuje shallow size („mělká velikost“ značící, že nebereme v úvahu velikosti objektových atributů) a je stejná pro všechny instance třídy String.
To však samozřejmě není vše, protože instance třídy String se pouze odkazuje na pole char[], které je na haldě uloženo následovně:
| # | Velikost (B) | Struktura | Popis |
|---|---|---|---|
| 1 | 8 | HEADER | hlavička objektu (přiřazena každému objektu na haldě) |
| 2 | 4 | int length | délka pole = délka řetězce ve znacích |
| 3 | x | length*2 | vlastní obsah řetězce |
| 4 | 0 nebo 2 | PADDING | výplň, aby celková délka objektu byla dělitelná čtyřmi (někdy osmi) |
I pro pole char[], které bude obsahovat pouze jeden znak, tedy bude na haldě alokována paměť o velikosti šestnácti bajtů!
15. Nové trendy při práci s řetězci
Konečně se dostáváme k programovacím jazyků, jejichž autoři se nebáli s řetězci pracovat poněkud neortodoxním způsobem. Jedná se především o jazyk Rust a kupodivu taktéž o Python, přesněji řečeno Python od verze 3.3, v níž došlo sice k méně známé, ale o to důležitější změně. Problematice práce s řetězci v Rustu jsme se již relativně podrobně věnovali (ovšem chystám ještě doplnění tohoto článku na základě dotazů), takže se podívejme, jak s řetězci pracuje Python, konkrétně Python 3.3 a vyšší. Předchozí verze Pythonu totiž mohly být zkompilovány buď s podporou UCS-2 nebo UCS-4 [1].
16. Python 3.3 s flexibilní reprezentací řetězců
V programovacím jazyku Python verze 3.3 došlo k poměrně významné změně, která se týká způsobu interního uložení řetězců. Autoři Pythonu si totiž uvědomili, že na jednu stranu je sice důležité podporovat Unicode (a to celé Unicode, žádný subset typu BMP, vzhledem k normě GB 18030) ovšem v mnoha případech to vede k tomu, že se do operační paměti ukládá až čtyřikrát větší množství dat, než je skutečně nutné, protože mnoho řetězců používaných v každodenní praxi obsahuje pouze ASCII znaky. Navíc větší množství dat uložených v paměti znamená, že se při manipulaci s nimi bude hůře využívat procesorová cache. Proto došlo v rámci PEP 393 k takové úpravě, která zajistí možnost uložení řetězců ve třech formátech, což je naznačeno v tabulce:
| Šířka znaku | Kódování | Prefix při zápisu kódu |
|---|---|---|
| 1 bajt | Latin-1 | \x |
| 2 bajty | UCS-2 | \u |
| 4 bajty | UCS-4 | \U |
Tyto změny by měly být pro programátory i uživatele zcela transparentní, takže by se nemělo stát, že by například do řetězce původně uloženého s kódováním Latin-1 (nadmnožina ASCII) nešel uložit například znak v azbuce – ostatně řetězce jsou v Pythonu neměnitelné, takže se konverze provede v rámci prováděné operace automaticky.
17. Otestování velikosti objektů typu řetězec v Pythonu 3.4.3
Podívejme se nyní, jak je výběr formátu pro uložení řetězce prováděn při interpretaci řetězcového literálu. Nejprve importujeme modul sys, který nabízí funkci getsizeof():
Python 3.4.3 (default, Nov 17 2016, 01:08:31) [GCC 4.8.4] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sys
Zjistíme velikost objektu reprezentujícího prázdný řetězec. Tato velikost se může lišit podle verze Pythonu a použité architektury, nás však budou zajímat rozdíly oproti této hodnotě:
>>> sys.getsizeof("")
49
Zjistíme velikost objektu řetězce s jedním ASCII znakem (měla by být o jedničku vyšší, než hodnota předchozí) a taktéž velikost objektu řetězce s jedenácti znaky (bude se lišit o deset bajtů oproti hodnotě předchozí). Výsledek je zřejmý – každý znak je v tomto případě reprezentován jediným bajtem:
>>> sys.getsizeof("e")
50
>>> sys.getsizeof("e 123456789")
60
Nyní vytvoříme řetězec s ne-ASCII znakem. Velikost příslušného objektu se zvětší (opět nás však bude zajímat rozdíl oproti této velikosti, ne její absolutní hodnota):
>>> sys.getsizeof("ě")
76
Dále vypočteme velikost řetězce s ne-ASCII znakem, po němž následuje deset ASCII znaků. Vidíme, že každý znak je uložen ve dvou bajtech – prvním znakem byl určen interní formát řetězce:
>>> sys.getsizeof("ě 123456789")
96
Zkusme si nyní vytvořit řetězec s jediným znakem, který nepatří do BPM, tedy ho nelze reprezentovat v UCS-2. Posléze k tomuto znaku přidáme dalších deset znaků a snadno zjistíme, že v tomto případě je každý znak reprezentován čtyřmi bajty ((120–80)/10):

>>> sys.getsizeof("\U0001ffff")
80
>>> sys.getsizeof("\U0001ffff 123456789")
120
18. Interní reprezentace řetězce v Pythonu 3.4.3
Jen pro zajímavost se můžeme podívat, jak celý objekt s řetězcem vypadá. U ASCII řetězců:
>>> bytearray((ctypes.c_byte*sys.getsizeof("Hello world!")).from_address(id("Hello world!")))
bytearray(b'\x02\x00\x00\x00\x00\x00\x00\x00\x00\x89\x96\x00
\x00\x00\x00\x00\x0c\x00\x00\x00\x00\x00\x00\x00\x17L\xc6c\x01
\xc0\x08a\xe4\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00
\x00\x00\x00Hello world!\x00')
U řetězců reprezentovaných v UCS-2:
>>> bytearray((ctypes.c_byte*sys.getsizeof("ěščřžýáíéúů")).from_address(id("ěščřžýáíéúů")))
bytearray(b'\x02\x00\x00\x00\x00\x00\x00\x00\x00\x89\x96\x00
\x00\x00\x00\x00\x0b\x00\x00\x00\x00\x00\x00\x00\x98\xd8J\xd9
\xd5\xb7\xd0\x9d\xa8\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00
\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00
\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x1b
\x01a\x01\r\x01Y\x01~\x01\xfd\x00\xe1\x00\xed\x00\xe9\x00\xfa
\x00o\x01\x00\x00')
19. Odkazy na Internetu
- The Most Expensive One-byte Mistake: Did Ken, Dennis, and Brian choose wrong with NUL-terminated text strings?
http://queue.acm.org/detail.cfm?id=2010365 - UCSD Pascal
https://en.wikipedia.org/wiki/UCSD_Pascal - D Language: Strings
https://dlang.org/spec/arrays.html#strings - The History Behind the Definition of a ‚String‘
https://stackoverflow.com/questions/880195/the-history-behind-the-definition-of-a-string - Libc: Representation of Strings
https://www.gnu.org/software/libc/manual/html_node/Representation-of-Strings.html - ATARI BASIC
http://www.atariarchives.org/dere/chapt10.php - BASIC (Wikipedia EN)
http://en.wikipedia.org/wiki/BASIC - BASIC (Wikipedia CZ)
http://cs.wikipedia.org/wiki/BASIC - Turbo BASIC (Wikipedia CZ)
http://cs.wikipedia.org/wiki/Turbo_BASIC - Sinclair BASIC (Wikipedia CZ)
http://cs.wikipedia.org/wiki/Sinclair_BASIC - More BASIC Computer Games
http://www.atariarchives.org/morebasicgames/ - Dartmouth College Computation Center: 1964 – The original Dartmouth BASIC manual
http://www.bitsavers.org/pdf/dartmouth/BASIC_Oct64.pdf - The Original BASIC
http://www.truebasic.com/ - BASIC – Beginners All-purpose Symbolic Instruction Code
http://hopl.murdoch.edu.au/showlanguage.prx?exp=176 - Universal Coded Character Set
https://en.wikipedia.org/wiki/Universal_Coded_Character_Set - UTF-16
https://en.wikipedia.org/wiki/UTF-16 - PEP 393 – Flexible String Representation
https://www.python.org/dev/peps/pep-0393/ - In-memory size of a Python structure
https://stackoverflow.com/questions/1331471/in-memory-size-of-a-python-structure - What is internal representation of string in Python 3.x
https://stackoverflow.com/questions/1838170/what-is-internal-representation-of-string-in-python-3-x#9079985 - How to profile memory usage in Python
https://www.pluralsight.com/blog/tutorials/how-to-profile-memory-usage-in-python - What's the rationale for null terminated strings?
https://stackoverflow.com/questions/4418708/whats-the-rationale-for-null-terminated-strings - Unicode
https://en.wikipedia.org/wiki/Unicode - The Development of the C Language
https://www.bell-labs.com/usr/dmr/www/chist.html - Borland Pascal Wiki: String operations
http://borlandpascal.wikia.com/wiki/String_operations - Pascal Strings
https://www.tutorialspoint.com/pascal/pascal_strings.htm - PChar – Null terminated strings
https://www.freepascal.org/docs-html/ref/refsu12.html - Comparison of Pascal and C
https://en.wikipedia.org/wiki/Comparison_of_Pascal_and_C - FORTRAN 66
http://fortranwiki.org/fortran/show/FORTRAN+66 - Fortran: strings
https://en.wikibooks.org/wiki/Fortran/strings - Strings in Atari BASIC
http://www.cyberroach.com/analog/an11/strings.htm - String Arrays in Atari BASIC
http://www.atarimagazines.com/compute/issue11/52_1_STRING_ARRAYS_IN_ATARI_BASIC.php - An Atari BASIC Tutorial
http://www.cyberroach.com/analog/an25/basictutorial.htm - Basic Multilingual Plane
https://en.wikipedia.org/wiki/Plane_(Unicode)#Basic_Multilingual_Plane






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU