Než budeme moci zahájit práci na vkládání nových záznamů, musíme vyřešit jednu nutnou záležitost – získání nové hodnoty klíčové položky pro nový záznam. Je to samozřejmě stejné jako v minulých dvou variantách řešení (SQL nebo JOOQ). Pro vyzkoušení funkce si z předchozí ukázkové úlohy zkopírujeme procedury setFocus a new_Record. U Hibernate jsme si již zvykli na to, že pro všechny úlohy používáme dvě možná řešení. V tomto konkrétním případě to budou dokonce tři možné varianty. První z nich je založena na HQL:
private Short maxKFV1() {
SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory();
Session session = sessionFactory.openSession();
Query query = session.createQuery("SELECT max(Table.id) FROM udaje Table");
Short maxid = (Short) query.list().get(0);
session.flush();
sessionFactory.close();
return maxid + 1;
}
Jak je z kódu zřejmé, má 4 sekce. První a třetí jsou již notoricky známé a ta poslední pouze zajistí zvýšení návratové hodnoty nejvyšší klíčové položky. Zajímavá je tedy vlastně pouze druhá sekce. Ta obsahuje samotný HQL dotaz (byla použita varianta s aliasem názvu tabulky, ale klidně by mohla být použita i zkrácená varianta – SELECT max(id) FROM udaje). Druhý příkaz pak do deklarované proměnné ukládá výsledek dotazu, což je samozřejmě pouze jedna jediná hodnota. Více vysvětlení asi představený kód nepotřebuje, a tak se podíváme na druhou variantu. Uvedeme pouze druhou sekci, protože ostatní tři jsou úplně stejné:
private Short maxKFV2() {
...
Criteria criteria = session
.createCriteria(udaje.class)
.setProjection(Projections.max("id"));
Short maxid = (Short) criteria.uniqueResult();
... }
Zde jsme použili nastavení dotazových kritérií, které jsme uváděli při přehledu dotazovacích možností Hibernate. Kromě toho je zde použita i funkce Projections, která slouží právě k tomu, co jsme potřebovali – vrací hodnoty sumárních funkcí. Funkce uniqueResult pak zajistí opět návrat pouze jedné jediné hodnoty z dotazu. Poslední varianta využívá aplikační proceduru a generovaný getter:
private Short maxKFV3() {
...
udaje data = (udaje) session
.createCriteria(udaje.class)
.addOrder(Order.desc("id"))
.setMaxResults(1)
.uniqueResult();
Short maxid = data.getId();
... }
Zde se využívá nejen aplikační třída a kritéria, ale i jeden docela zajímavý trik: záznamy se nejprve setřídí sestupně podle klíčové položky, čímž se omezí počet návratových hodnot na jeden záznam (nikoliv na jednu hodnotu!) a z něj se pak vybere potřebný getter. Nyní je možné přidat proceduru new_Record k akci příslušného tlačítka a do ní přidat volání postupně všech tří výše uvedených funkcí:
pid = maxKFVx();
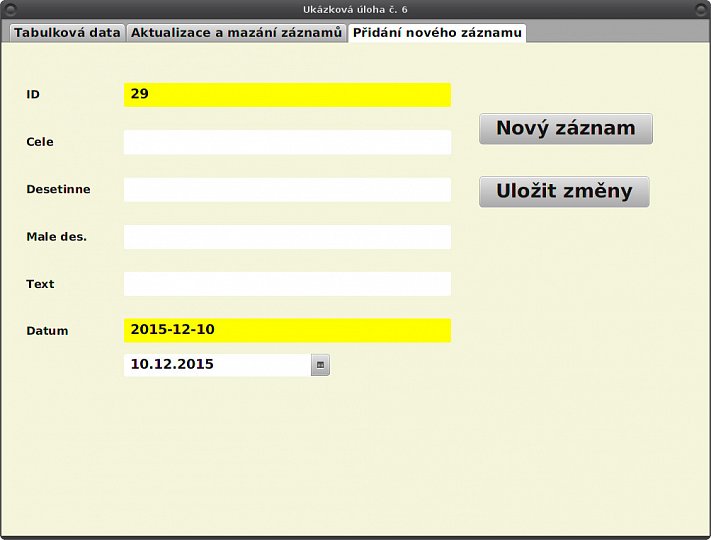
Výsledek spuštění této procedury je pro všechny tři varianty stejný a ukazuje ho první obrázek v první galerii. Tím máme již vše připravené a můžeme se pustit do konstrukce procedury, která zajistí uložení nově zadaného záznamu do tabulky. Zde si opět ukážeme dvě varianty, ta první bude vycházet z HQL:
private void save_Record1() {
SessionFactory sessionFactory = new Configuration().configure().buildSessionFactory();
Session session = sessionFactory.openSession();
session.getTransaction().begin();
Query query = session.createSQLQuery("INSERT INTO udaje VALUES (:ID, :Celec, :Desec, :Malec, :Retez, :Datum)");
query.setParameter("ID",pid.shortValue());
query.setParameter("Celec",Integer.valueOf(n_Cele.getText()));
query.setParameter("Desec",Double.valueOf(n_Desetinne.getText()));
query.setParameter("Malec",Double.valueOf(n_Maledes.getText()));
query.setParameter("Retez",n_Text.getText());
query.setParameter("Datum",java.sql.Date.valueOf(dp_Datum.getValue()));
query.executeUpdate();
session.getTransaction().commit();
session.flush();
sessionFactory.close();
viewTable();
sr_Button.setDisable(true);
n_ID.setText("");
tabPane.getSelectionModel().select(0);
}
Čtyři z pěti použitých sekcí jsou celkem očekávané a komentované v předchozím textu. Proto se zaměříme pouze na druhou, výkonnou sekci. V ní jsou dva typy příkazů – samotný HQL dotaz a pak nastavení všech nově zadávaných hodnot jednotlivých položek vkládaného záznamu. K nim asi není také moc co dodat a tak se zaměříme na dotaz. V předchozí větě jsme uvedli, že se jedná o HQL příkaz. Ono to vlastně ale tak není, protože HQL tuto konstrukci nepodporuje. Proto bylo nutné použít nativní SQL dotaz a funkci createSQLQuery. Pokud bychom se snažili použít funkce createQuery, dostaneme chybové hlášení o špatném formátu dotazu (i když bude naprosto stejný!). Dál pak následuje dotaz, kde jsou formální parametry pro jednotlivé položky a těm se pak přiřazují skutečné hodnoty z editačních polí. Proceduru můžeme přiřadit k akci příslušného tlačítka a vyzkoušet. Výsledek je vidět na druhém obrázku první galerie. Pro druhou variantu, které je postavené na generovaných setterech, uvedeme pouze výkonnou část a odlišný příkaz pro uložení nových hodnot záznamu:
private void save_Record2() {
...
udaje radek = new udaje();
radek.setId(pid.shortValue());
radek.setCelecis(Integer.valueOf(n_Cele.getText()));
radek.setDescis(Double.valueOf(n_Desetinne.getText()));
radek.setMaledes(Double.valueOf(n_Maledes.getText()));
radek.setRetezec(n_Text.getText());
radek.setDatum(java.sql.Date.valueOf(dp_Datum.getValue()));
session.save(radek);
... }
Pro nově vytvořenou instanci aplikační třídy se nastavují hodnoty příslušných setterů a nakonec je celý takový vytvořený záznam uložen. Jenom krátká poznámka: pro uložení je možné použít i jiný příkaz, který má tento tvar:
session.saveOrUpdate(radek);
Tuto verzi můžeme opět vyzkoušet a výsledek vidíme na třetím obrázku v první galerii. Tím bychom mohli ukončit další kapitolu našeho seriálu o frameworku Hibernate. Dalo by se o něm samozřejmě psát mnohem déle a podrobněji, ale to není naším primárním cílem. Uvedené příklady a postupy jsou pro zájemce určitě dostatečné proto, aby si udělali obrázek o jeho možnostech. Také nemá smysl dlouze popisovat rozdíly a výhody či nevýhody představených možností (SQL, JOOQ, Hibernate). Je to totiž celkem individuální záležitost a také hodně záleží na typu aplikace, pro kterou by se měl ten který nástroj použít. Navíc se o tom dá najít solidní množství informací a některé zdroje zde také byly uvedeny. Kapitolu uzavřeme přílohou s konečnou verzí příslušné třídy: samexam6.java.
Jednu kapitolu jsme uzavřeli a do konce našeho seriálu nám zbývají jenom dvě, které budou ve srovnání s ostatními docela stručné. V té první se zaměříme na trochu jiný typ databáze a možnosti jejího využití v aplikacích JavaFX. Doposud jsme pro ukládání dat používali „klasický“ databázový stroj, který je trvale spuštěný ve formě serveru a je možné se k němu nějakým způsobem přihlásit a využít uložená data. Vedle toho existují ještě tzv. embedded (vestavěné) databáze. Ty nepoužívají žádné běhové části či servery (většinou, některé mají obě možnosti), ale data ukládají ve formě nějakých souborů na disku (dost z nich má možnosti zakládání i použití tzv. in-memory databází, které jsou uloženy pouze dočasně v operační paměti). Těchto databází existuje celá řada a na linuxové platformě je asi nejznámější SQLite. Jenom pro určitý přehled (možností je mnohem více a pořád se mění a aktualizují) uvedeme následující odkaz: Embedded Database.
My si širokou nabídku ještě zúžíme a zaměříme se na ty databáze, které mají nějaký užší vztah k Javě nebo JavaFX. I tak dostaneme celkem slušnou nabídku a není vůbec jednoduché si z ní vybrat. O této problematice se dá najít velmi mnoho informací a tak pro stručný přehled (zdaleka ne úplný) použijeme jeden zdroj: Java Database. Z výše uvedeného přehledu asi můžeme s klidem hned na počátku vyřadit dva zástupce, kteří se hodí pouze na vybrané typy úloh – Neo4J (klasická „grafová“ databáze z rodiny NoSQL) a OrientDB (prezentovaná jako grafově-dokumentová NoSQL databáze). Další zástupce je sice zajímavý, ale pro naše ukázkové účely přece jenom trochu nevhodný – ObjectDB (jak už napovídá název, jedná se o objektovou databázi, což si můžeme jednoduše představit jako v tomto a minulém dílu představenou kombinaci relační databáze a ORM).
Ze zbylých tří zástupců je asi nejznámější Apache Derby, která je už docela dlouhou dobu častou součástí Java aplikací pro desktop i web. Podle různých informací se ale zdá, že proti posledním dvěma zástupcům trochu ztrácí dech. Pro naše účely to sice není žádná podstatná záležitost, ale přece jenom jsme ji nakonec z výběru vyřadili. Rozhodování o dvou zbývajících bylo trochu složitější, ale nakonec jsme se shodli, že nejlepší variantou bude H2 Database. Důvodů pro její konečnou volbu bylo několik (zde je přehled nejdůležitějších vlastností z webu projektu: H2 Features), takže jenom pár příkladů bez ohledu na jejich váhu při volbě:
- možnost využití na více platformách
- relační databázový systém
- možnosti volby módu = kompatibility s mnoha databázovými servery a systémy
- možnost použití pro desktopové i webové aplikace
- možnost využít v embedded režimu (soubory s daty uložené na disku nebo v paměti), serverovém nebo smíšeném režimu
- pro speciální potřeby možnost využití námi probíraných nástrojů Hibernate a JOOQ
- vlastní manažer pro administraci
- podpora formátů CSV a XML
- a ještě některé další vlastnosti…
Kromě již uvedených vlastností je určitě velkou výhodou H2 database vlastní webové stránky, kde je obsaženo velmi mnoho informací, návodů, příkladů atd. V našem seriálu budeme vycházet hlavně z PDF verze dokumentace, kde je na více než 180 stranách obsaženo velmi mnoho užitečných informací. Aktuální verze se vztahuje k poslední vývojové verzi (1.4.190, označená jako Beta), kterou budeme používat. Stažení jsou k dispozici zde: H2 Download. Odtud si stáhneme platformě nezávislý archiv s názvem h2–2015–10–11.zip a rozbalíme ho do vybraného adresáře. Jeho obsah je vidět na prvním obrázku ve druhé galerii. Pro naše potřeby jsou zajímavé pouze dva podadresáře – ./h2/docs (obsahuje dokumentaci včetně souboru h2.pdf) a ./h2/bin (zde je jediný soubor, který použijeme v naší aplikaci – h2–1.4.190.jar). Tento soubor překopírujeme do naší ukázkové aplikace, konkrétně do adresáře libs.
My pak následně využijeme přítomnost manažera pro administraci a vytvoříme si základní kostru databáze. Pro její uložení si v aplikace vytvoříme nový adresář Data. Pak už stačí buď dvojklik na příslušný soubor v adresáři libs nebo spuštění terminálového příkazu
java -jar h2-1.4.190.jar
Po spuštění přítomné jednoduché aplikace se nám otevře defaultní webový prohlížeč a v něm základní okno manažeru, jak to ukazuje druhý obrázek druhé galerie. Kromě jiného si můžeme všimnout, že pro spuštění aplikace byla použita vnitřní smyčka na IP adrese
http://127.0.1.1:8082
Co je ještě důležitější, tak je nová ikona, které se nalézá v pravém horním rohu obrazovky, resp. na pravém konci horního panelu pod názvem H2 Database Engine. Ta nám jednoznačně říká, že je manažerská aplikace spuštěná a my tak můžeme otevřít okno ve webovém prohlížeči a nebo použít některý ze tří příkazů, které jsou v aplikaci k dispozici – viz třetí obrázek ve druhé galerii. Příkazy jsou velmi jednoduché – první (H2 Console) otevře webový prohlížeč s manažerem, druhý (Status informuje o stavu aplikace včetně možnosti spuštění webové konzole – viz čtvrtý obrázek druhé galerie), třetí (Exit) pak ukončí běh manažerské aplikace a k jejímu dalšímu použití bychom museli provést nové spuštění dle popisu výše. Jak je z obrázků patrné, vzhledem k nastavení tmavého tématu nejsou některé texty příliš čitelné, takže změníme vzhled, aby bylo možné lépe popsat možnosti administrace.
V horní části okna aplikace je volba jazykové varianty (i když je nastaveno na anglickou verzi, tak prohlížeč samozřejmě respektuje lokální nastavení. Pátý obrázek ve druhé galerii nám ukazuje, že možností jazykových variant je opravdu hodně). Dále následují tři položky hlavního menu. Ta první nám umožní nastavit základní předvolby H2 systému, jak to ukazuje šestý obrázek druhé galerie. Je zde možnost omezit připojení pouze lokálních nebo vzdálených klientů, zabezpečení spojení pomocí šifrování, číslo portu webového serveru a dole je pak přehled o činnosti aplikace. My zde nebudeme nic měnit. Druhá položka hlavního menu obsahuje slušnou sestavu nástrojů, které mohou velmi dobře posloužit pro správu databází – viz sedmý obrázek ve druhé galerii. Opět nebudeme žádný nástroj testovat, jenom ukážeme jeden pro příklad na osmém obrázku druhé galerie. Zajímavá je tam informace o tom, jakým terminálovým příkazem se dá požadovaná funkce spustit (příkaz se kontextově doplňuje podle obsahu editačních polí). Poslední položkou menu je jednoduchá nápověda (viz poslední obrázek ve druhé galerii), kde jsou jednak vysvětlení významu ikon, důležité příkazy a klávesové zkratky a také ukázky SQL příkazů.
To by asi k popisu hlavního menu mohlo stačit a podíváme se do spodního formuláře, kde jsou k dispozici údaje pro přihlášení k databázi. Jako první se zde objevuje nastavení databázového konektoru (ovladače). Jak ukazuje první obrázek ve třetí galerii, je výběr celkem rozsáhlý (krátký popis připojení ovladače byl k vidění v nápovědě). Pro nás ale nejsou ostatní volby zajímavé, protože budeme vždy používat pouze první nabízenou variantu H2 Embedded. Proto necháme vše nastavené tak, jak to je po spuštění a klikneme na tlačítko Vyzkoušet připojení. Druhý obrázek třetí galerie nám ukazuje jednak to, že zkouška proběhla úspěšně (což je celkem zajímavé, protože jsme vlastně nic nenastavili…), ale kromě toho se v domovském adresáři objevil nový soubor s názvem test.mv.db. Než to vysvětlíme podrobněji, tak zkusíme použít druhé tlačítko Připojit. Jak ukazuje třetí obrázek ve třetí galerii, tak se nám otevřela vlastní manažerská aplikace a my zde vidíme, že je připraveno informační schéma databáze a seznam uživatelů (je zatím pouze jeden, který byl nastaven automaticky při spuštění aplikace). H2 je nastavena tak (dá se to změnit pomocí položky JDBC URL, kde se přidá příkaz IFEXISTS=TRUE, viz PDF dokumentace na straně 39), že při každém pokusu o připojení databáze jí automaticky vytvoří, pokud tato neexistuje. To samozřejmě platí i pro případ, že se to připojení navazuje z JavaFX aplikace a je třeba si na to dávat pozor (nebo toho naopak využít…).
Pokusnou databázi tedy máme vytvořenou a nezbývá, než zkusit vytvořit nějakou tabulku. To velmi jednoduché a výsledek je vidět na čtvrtém obrázku třetí galerie. To by asi jako ukázka mohlo stačit a pustíme se do přípravy tabulek a dalších součástí naší nové ukázkové úlohy. Jako první si samozřejmě musíme vytvořit příslušnou databázi na správném místě, vytvořit tabulky, naplnit je daty atd. Proto se znovu vrátíme do manažerské aplikace a vyplníme tentokrát všechny údaje, jak to ukazuje pátý obrázek ve třetí galerii. Soubor s databází umístíme do aplikačního adresáře Data, doplníme také název připojení a přihlašovací údaje. Po zkoušce připojení se na příslušném místě objeví příslušný soubor, jak to ukazuje šestý obrázek třetí galerie. Pro uložení vytvořeného připojení použijeme tlačítko Uložit a budeme se k němu moci vracet kdykoliv do budoucna. Tímto máme připravenou databázi a následně si vytvoříme potřebnou strukturu. Ta se bude konkrétně skládat ze dvou tabulek a jednoho pohledu. První tabulka bude velmi podobná již dříve používané PG tabulce udaje a bude velmi jednoduchá:
CREATE TABLE zkusebni ( hid integer, hcele integer , hdes numeric (12,4) , hmale numeric (8,6), hretez character (32), hdatum date );
Druhou tabulku si zatím pouze připravíme pro použití v další zkušební úloze. I když se to na první pohled nezdá, je zde použita jedna „vychytávka“ – i když nebylo přímo definováno žádné klíčové pole, tak byl u toho prvního použit datový typ IDENTITY (což by asi nejlépe odpovídalo PG datovému typu BIGSERIAL, či INTEGER AUTO_INCREMENT z MySQL). V PDF dokumentaci se můžeme na straně 169 dočíst, že typ má stejný rozsah jako BIGINT (oba jsou do aplikací JavaFX mapované jako typ Long), jedná se o automaticky zvyšovanou hodnotu, která není nikdy znovu použita ani v případě, že se vrací zpět nedokončená transakce:
CREATE TABLE prihlaseni ( klic IDENTITY, uzivatel VARCHAR (30), heslo VARCHAR (255), pristup CHAR (1) );
Abychom trochu více objasnili funkci klíčové položky, tak po založení nové tabulky zkusíme přidat také nějaká data:
INSERT INTO prihlaseni (uzivatel, heslo, pristup) VALUES ('fxguide','fxguide','a');
Jak je možné si všimnout, není zde vůbec první položka zastoupena. To vychází z její vlastnosti automatického zvyšování a není třeba (ani by to vlastně nešlo) jí explicitně zadávat. O úspěchu vložení dat nás přesvědčí nejenom výsledek dotazu (viz sedmý obrázek ve třetí galerii), ale i dotaz na obsah tabulky. Zde je možné využít vlastnost administrační aplikace a pro vytvoření dotazu pro zobrazení všech dat z tabulky stačí kliknout na její název v levém sloupci s přehledem součástí databáze. Příslušný dotaz se automaticky zobrazí v příslušném okně a je možné ho pouze spustit. Další podrobnosti k této tabulce si necháme na další díla a podíváme se na poslední součást – databázový pohled:
CREATE OR REPLACE VIEW h2pohled AS SELECT * FROM zkusebni ORDER BY hid;
Jak je z příkazu zřejmé, v pohledu budou všechny záznamy z příslušné tabulky s tím rozdílem, že budou seřazené podle prvního pole. Aby bylo možné funkce pohledu ověřit, tak vložíme do tabulky zkusebni 10 záznamů tak, jak to ukazuje SQL příkaz (cíleně nejsou srovnané dle první položky):

INSERT INTO zkusebni VALUES (2,22,2.2,0.2,'222222','2002-02-02'), (4,44,4.4,0.4,'444444','2004-04-04'), (6,66,6.6,0.6,'666666','2006-06-06'), (8,88,8.8,0.8,'888888','2008-08-08'), (10,100,10.0,1.0,'101010','2010-10-10'), (9,99,9.9,0.9,'999999','2009-09-09'), (7,77,7.7,0.7,'777777','2007-07-07'), (5,55,5.5,0.5,'555555','2005-05-05'), (3,33,3.3,0.3,'33333','2001-03-03'), (1,11,1.1,0.1,'111111','2001-01-01');
Výsledek dotazu na pohled pak ukazuje jeho funkčnost – viz osmý obrázek třetí galerie. Poslední dva obrázky ve třetí galerii pak ukazují výsledky dotazů na samotnou tabulku i nově vytvořený pohled. Z obrázků jasně vyplývá, že obojí se chová prakticky stejně a při dotazech lze obě možnosti libovolně využívat jako plnohodnotné zástupce. Tím bychom ukončili základní přípravu databáze H2 pro využití v aplikaci JavaFX, a to si necháme na příští díl.
V dnešním dílu jsme ukončili kapitolu o Hibernate ukázkou možností pro vkládání nových záznamů do tabulky. Zahájili jsme také novou kapitolu o H2 databázi. V příštím dílu budeme pokračovat s H2 databází a ukážeme si její připojení z JavaFX aplikace, konfiguraci JOOQ a zobrazení záznamů v tabulce ve widgetu pomocí H2 a JOOQ.


































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU