Klasické metody fulltextového hledání
Než se pustíme do nových technologií, pojďme si krátce připomenout klasický přístup k fulltextovému hledání, jehož základem je invertovaný index. V invertovaném indexu jsou uložena slova a ke každému slovu pak seznam dokumentů, které ho obsahují. Po zadání uživatelského dotazu se hledají dokumenty obsahující všechna jeho slova. V podstatě se tedy jedná o hledání klíčových slov, která uživatel zadal. Tento přístup k fulltextovému hledání má však několik docela zásadních omezení.
Prvním omezením je práce se slovy jako s textovými řetězci bez znalosti jejich významu. Zadá-li uživatel například jednoduchý dotaz „mobilní telefon červený“, mohou se najít dokumenty obsahující textové řetězce „výkonný mobilní telefon červený“ nebo „kryt na mobilní telefon červený“. Záměr uživatele je jasný, chce červený mobilní telefon, ale pravděpodobně nechce kryt na mobilní telefon. První dokument by tedy měl mít vyšší relevanci. Jen na základě textové shody ale není možné relevanci těchto dokumentů vůči dotazu správně určit. Klasické metody výpočtu textové relevance, jako například BM25, vidí nějaká slova okolo, ale nedokáží rozlišit, zda se význam dokumentu vůči dotazu nemění (slovo „výkonný“ navíc), nebo mění (slovo „kryt“ navíc).
Dalším omezením je hledání dokumentů obsahujících nějakou reformulaci dotazu, například dokument „výkonný mobil červený“ není možné textovou shodou s dotazem „mobilní telefon červený“ najít, i když je k dotazu relevantní.
Hledání Seznamu bylo donedávna založeno na klasickém přístupu, kde byly základem invertované indexy a omezení z toho plynoucí jsme se snažili řešit jak na úrovni rozvoje dotazu (přidáváním reformulací, které se mohou v dokumentu vyskytovat), tak i na úrovni relevance (přidáváním nových features pro strojově učený relevanční model). Postupem času jsme ovšem narazili na technologické limity, kdy bylo další zvyšování kvality velmi obtížné a časově náročné a zlepšení neodpovídalo vynaloženým prostředkům. Bylo tedy nutné zkusit nový přístup, naučit search engine ve větší míře pracovat s významem textu. To umožňují tzv. jazykové modely.
Jazykové modely
Jazykové modely jsou nástrojem, jak naučit stroj (počítač) chápat význam přirozeného jazyka. Slovo chápat je v tomto kontextu možná příliš silné, jedná se spíše o abstraktní matematickou reprezentaci významu, nicméně z pohledu uživatele to tak může pro některé úlohy vypadat. Uživatel může mít pocit, že počítač rozumí přirozenému jazyku. Nejlepších výsledků dosahují jazykové modely založené na neuronových sítích, které pro reprezentaci významu textu používají matematický vektor. Tyto vektory mají jednu klíčovou vlastnost: vektory významově blízkých textů jsou si blízké, a naopak vektory významově vzdálených textů jsou od sebe vzdálené. Jako metrika vzdálenosti se nejčastěji používá úhel mezi vektory ve formě cosine similarity/distance.

Obrázek ilustruje možný výstup modelu. Vektory textů „mobilní telefon červený“ a „mobil červený“ jsou si blízké, protože texty nesou prakticky stejný význam. Analogicky jsou si blízké i vektory textů „kryt na mobilní telefon červený“ a „kryt na mobil červený“. Naopak vektory textů „mobilní telefon červený“ a „kryt na mobilní telefon červený“ jsou navzájem více vzdálené i přes vysokou textovou shodu, protože slovo „kryt“ mění zásadním způsobem význam textu.
Jazykových modelů založených na neuronových sítích existuje celá řada a prošly v uplynulé dekádě bouřlivým vývojem. Mezi nejznámější patří:
Word2vec i fastText jsou si velmi podobné, oba modely pracují na úrovni jednotlivých slov a výpočet vektoru slova je bezkontextový. Model tedy nedokáže rozlišit slova, která podle kontextu mění význam (například ubytovací kolej versus železniční kolej) a přiřazuje jim nezávisle na kontextu stejný vektor. Model také neumí pracovat s relativní významností jednotlivých slov (méně častá slova obvykle nesou více informace než například spojky a předložky). FastText oproti Word2vecu dokáže navíc z podčástí slov generovat vektory i pro neznámá slova.
BERT model řeší oba hlavní nedostatky jeho předchůdců, výpočet vektoru pro slovo je kontextový a dokáže také pracovat s relativní významností jednotlivých slov vzhledem k celému zpracovávanému textu. Modely vycházející z BERTa dosahují state-of-the-art výsledků na velkém množství úloh zpracování textu (například strojový překlad, oprava překlepů či lemmatizace). Nevýhodou je ovšem složitá struktura modelu (neuronové sítě) a z toho plynoucí vysoká výpočetní náročnost jak procesu učení, tak i inference (výpočtu výstupu modelu).
Poznámka: BERT nepracuje se slovy jako takovými, ale používá WordPiece tokenizaci, kdy jsou jednotlivá slova rozdělena na jeden nebo více tokenů. To umožňuje udržet celkový počet možných vstupních tokenů v rozumných mezích (řádově desítky tisíc) a také to zlepšuje inferenci neznámých slov, protože nové neznámé slovo se skládá ze známých tokenů. Pro člověka je ale snazší uvažovat o významu jednotlivých slov, ne tokenů, proto pro jednoduchost předpokládejme, že i BERT pracuje na úrovni slov.
V Seznamu nepoužíváme přímo BERT, ale jeho derivát, model ELECTRA, který je vnitřní strukturou identický s BERT modelem. Oba modely se liší jen procesem učení, ELECTRA se učí jiným způsobem (méně náročným na výpočetní výkon). Pro jednoduchost můžeme považovat oba modely za identické, praktické rozdíly jsou minimální.
Model jako takový je nutné před použitím naučit na konkrétní jazyk (nebo více jazyků pro multilinguální model), což je výpočetně a časově náročný proces. Existují volně dostupné předučené modely, primárně ovšem pro angličtinu, a protože naše hledání cílí hlavně na češtinu, museli jsme náš model naučit úplně od základu.
Učení modelu ELECTRA
Učení modelu ELECTRA má dvě fáze, pre-training a fine-tuning.
Pre-training je unsupervised fáze učení, při které se model snaží naučit obecný (kontextový) význam jednotlivých slov z velkého množství textu v přirozeném jazyce (například z obsahu Wikipedie nebo jiných článků vyskytujících se na internetu). Existují různé úlohy, na kterých je možné model učit. Mezi nejpoužívanější patří predikce maskovaných slov, kdy se v průběhu učení v textu náhodně zamaskují některá slova a úkolem modelu je jejich predikce z kontextu. Fragment učicích dat může vypadat například takto:
[MASK] je svobodný operační systém, jehož původním autorem je [MASK] Torvalds.
Pro znalého čtenáře root.cz je jednoduché doplnit maskovaná slova Linux a Linus, protože má znalost o tom, že Linux je svobodný operační systém a jeho autorem je Linus Torvalds. Stejnou znalost se snaží získat i model v průběhu učení. Výsledkem pre-training fáze učení je pak obecný jazykový model, který má kontextovou znalost jednotlivých slov a dokáže určit, která slova jsou si významem blízká v závislosti na kontextu.
Druhou fází učení je fine-tuning, kdy se předučený model doučí na konkrétní úlohu. Jedná se o supervised fázi učení a provádí se obvykle na anotovaných (nebo jinak získaných) učicích datech, kdy se modelu předkládají pozitivní a negativní příklady a model se je učí co nejlépe predikovat. Model je možné učit na celou řadu různých úloh jako například detekci spamu nebo klasifikaci uživatelských recenzí na pozitivní a negativní.
Výpočetní náročnost procesu učení je vysoká. ELECTRA-Small model (konkrétní varianta modelu ELECTRA obsahující cca 14 milionů parametrů) jsme v pre-training fázi učili na mixu 250 GB dat korpusu (obsah převážně českých článků na internetu) a 50 GB dat uživatelských dotazů. Celá pre-training fáze učení trvala asi 20 dní na GeForce RTX2080 Ti GPU. Ve fine-tuning fázi jsme model učili na 1,5 milionu anotovaných párů dotaz-dokument na stejném GPU, fine-tuning fáze pak trvala asi den. Pro ELECTRA-Base a ELECTRA-Large modely je výpočetní náročnost učení ještě vyšší.
Použití modelu ELECTRA pro relevanční úlohu
Stanovení relevance dokumentu vzhledem k dotazu je jednou z nejdůležitějších úloh hledání. Výsledné pořadí dokumentů je dané primárně jejich relevancí a je klíčové, aby nejrelevantnější dokumenty byly na nejvyšších pozicích. Pro určení relevance se používají modely učené na anotovaných dvojicích dotaz-dokument. Anotace obvykle vytváří člověk expertním srovnáním dotazu a dokumentu.
Použití modelu ELECTRA pro predikci relevance dokumentu vzhledem k dotazu je celkem přímočarý proces. Model se ve fine-tuning fázi učí predikovat relevanci, co nejlépe odpovídající anotaci, na následujícím vstupu:
[CLS] dotaz [SEP] dokument [SEP]
[CLS] a [SEP] jsou speciální tokeny a první [SEP] token dává modelu informaci o tom, kde je na vstupu hranice mezi dotazem a dokumentem. Tento přístup dává nejlepší výsledky co se týče kvality, bohužel ale za cenu vysoké výpočetní náročnosti. Inference ELECTRA-Small modelu má na CPU latenci asi 70 ms a s využitím distilace a kvantizace je ji možné snížit asi na 10 ms. Relevanci potřebujeme vyhodnotit pro co největší počet nalezených dokumentů. Pokud bychom uvažovali 1000 nalezených dokumentů na dotaz (což je poměrně malé číslo), stálo by vyhodnocení jejich relevance vůči dotazu pomocí ELECTRA modelu 10 sekund strojového času. Hardware pro takové řešení by byl extrémně drahý, a to i s použitím GPU místo CPU.
Bylo tedy nutné hledat jinou cestu, jak využít ELECTRu pro zlepšení relevance a přitom udržet nároky na hardware v přijatelných mezích. Řešení se našlo ve formě siamského modelu, kdy se model rozdělí na dvě části, první pro zpracování dotazu a druhou pro zpracování dokumentu. Výstupem první části je vektor dotazu, druhé pak vektor dokumentu. Jak již bylo řečeno dříve, vektory zde reprezentují význam dotazu a dokumentu, relevance se tedy vyhodnocuje na základě sémantické shody dotazu a dokumentu, nikoliv textové shody.
Model se ve fine-tuning fázi učí na metriku vzdálenosti vektorů tak, aby vzdálenost vektoru dotazu a vektoru relevantního dokumentu byla co nejmenší, a naopak vzdálenost vektoru dotazu a vektoru nerelevantního dokumentu co největší. Rozdělení modelu na dvě části (dotazovou a dokumentovou) umožňuje přesun výpočtu vektoru dokumentu do indexační fáze a ve fázi hledání pak stačí spočítat pouze vektor dotazu. Finální výpočet relevance pomocí výpočtu vzdálenosti vektoru dotazu a vektoru dokumentu je pak již velice rychlý (asi 100 ns). Kvalita relevance je o něco nižší než v případě nesiamského modelu, nicméně je to vyváženo mnohem nižšími požadavky na hardware.
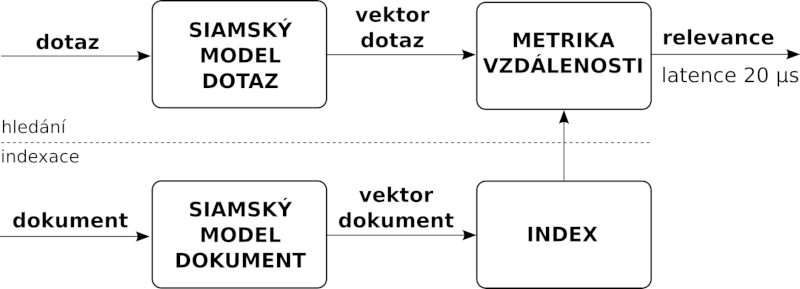
Tradičně se spočítané vektory porovnávají pomocí kosinové podobnosti. V našem řešení jsme se rozhodli tuto jednoduchou funkci nahradit malým modelem (neuronovou sítí), do kterého vstupují vektory dotazu a dokumentu a který je určený také na relevanční úlohu. Vyhodnocení takového modelu má latenci asi 20 μs, a oproti jednoduché kosinové podobnosti poskytuje netriviálně lepší výsledky.
Použití modelu ELECTRA pro hledání dokumentů
Výpočtu relevance a následnému řazení dokumentů ovšem předchází ještě jedna neméně důležitá úloha. Z indexu všech dokumentů je nutné předvybrat množinu kandidátních dokumentů, které by mohly být relevantní k dotazu. Klasickým přístupem je invertovaný index, kde se hledají dokumenty obsahující slova z dotazu. Takto je ale možné najít pouze dokumenty, které mají textovou shodu s dotazem. Pokud chceme najít i dokumenty, které textovou shodu s dotazem nemají a přitom jsou relevantní, musíme použít jiné metody.
ELECTRu je možné použít i pro hledání dokumentů na základě sémantické (nikoliv textové) shody s dotazem a řešení je vlastně velice podobné relevanční úloze. Siamský model je naučený tak, aby vzdálenost vektoru dotazu a vektorů relevantních dokumentů byla co nejmenší, což prakticky znamená, že model mapuje vektor dotazu do prostoru vektorů dokumentů. Úlohu hledání relevantních dokumentů je tak možné jednoduše převést na klasickou úlohu hledání nejbližších sousedů ve vektorovém prostoru.

Během indexace se zkonstruuje prostorový index vektorů dokumentů, ve kterém je posléze možné hledat nejbližší dokumenty k vektoru dotazu.
K indexaci vektorů dokumentů nicméně není možné použít klasické datové struktury jako R-tree nebo k-d tree, kvůli jevu zvanému jako prokletí dimenzionality, který způsobuje, že výkon klasických prostorových indexů degraduje pro mnohodimenzionální prostory prakticky na úroveň brute-force hledání. Vektory jazykových modelů mají počet dimenzí řádově ve stovkách (ELECTRA-Small 256 dimenzí, ELECTRA-Base 768 dimenzí a ELECTRA-Large 1024 dimenzí). Problém exaktního hledání v mnohodimenzionálním prostoru zatím bohužel nemá žádné uspokojivé řešení, všechny známe metody mají nízký výkon a nejsou prakticky použitelné pro prostory se stovkami dimenzí.
Existují však aproximativní metody s dostatečným výkonem, které jsou založené na předpokladu, že vlastně není nutné vždy najít nejlepší řešení a někdy se můžeme spokojit i s nějakým horším, ve smyslu nalezení vzdálenějších vektorů na úkor těch skutečně nejbližších. Tento stupeň volnosti navíc umožňuje zrychlit hledání pomocí aproximativních metod až o tři řády ve srovnání s exaktními metodami. Kvalita aproximativního hledání se pak měří jako recall, který udává poměr mezi nalezenými nejbližšími vektory a skutečně existujícími nejbližšími vektory. Trade-off mezi rychlostí hledání a kvalitou (recallem) je nastavitelný. Existuje celá řada hotových řešení aproximativního hledání, dobrý přehled včetně měření výkonu je možné nalézt na ann-benchmarks.
Hledání dokumentů na základě sémantické shody dotazu a dokumentu ve vektorovém prostoru má jednu zajímavou vlastnosti. K libovolnému dotazu (vektoru) vždy v prostoru dokumentů existují nějaké nejbližší dokumenty (vektory), prostorový index tedy pro jakýkoliv dotaz vždy vrátí jeho nejbližší dokumenty a nemůže se stát, že se žádné dokumenty nenajdou. To může být výhoda v případě složitých smysluplných dotazů, kdy jiné metody hledání na základě textové shody selhávají, ale i nevýhoda v případě nesmyslných dotazu, kde platí garbage in – garbage out. Na nesmyslné dotazy relevantní dokumenty neexistují.
Reálné fungování prostorového sémantického indexu nejlépe ozřejmí praktická ukázka. Uživatelé zadávají dotazy také v přirozeném jazyce, například „jak docílit dobrý stav vody v bazénu“, a očekávají, že na ně dostanou relevantní výsledky. Pro klasické metody hledání pomocí klíčových slov je odbavení takového dotazu poměrně složitá úloha, protože v relevantních dokumentech se pravděpodobně nebudou vyskytovat slova „docílit“ nebo „stav“. V následující tabulce jsou nejlepší dokumenty nalezené v prostorovém vektorovém indexu na dotaz „jak docílit dobrý stav vody v bazénu“:
Výsledky neodpovídají výslednému SERPu Seznam.cz hledání, protože se jedná o hledání pouze na jednom svazku, kde je zaindexováno jen asi 20 milionů dokumentů, a navíc jsou dokumenty řazeny pouze podle vzdálenosti vektorů dotazu a dokumentu (metrikou je cosine distance) bez seřazení relevančním modelem. Přesto je patrné, že nalezené dokumenty docela dobře odpovídají záměru uživatele, který chce najít informace o úpravě a údržbě vody v bazénu. Na dotaz formulovaný v přirozeném jazyce je tedy možné najít i dokumenty, které jsou relevantní, a přitom mají malou textovou shodu, například „docílit dobrý stav vody“ v dotazu versus „kvalita vody na prvním místě“ v dokumentu.
Technické řešení
Celá infrastruktura hledání běží na Linuxu stejně jako všechny ostatní služby provozované v Seznamu. Vlastní hledání běží v Kubernetes, indexační úlohy pak v OpenStacku.
Pro učení modelů se používá Python a frameworky PyTorch a transformers. Naučené modely se exportují do onnx formátu pro produkční využití. Učení modelů běží na GPU, používáme převážně GeForce RTX2080 Ti.
Hledací engine je napsaný v C++(17), což byla především pragmatická volba. C++ nám umožňuje jednoduše použít potřebné knihovny (převážně také napsané v C++), poskytuje vysoký výkon a má dobrou podporu pro použití AVX instrukcí jak formou automatické vektorizace, tak i přímo pomocí intrinsics. Pro komunikaci mezi jednotlivými komponentami hledání se používá gRPC framework, čímž je daný i threading model, kód provozovaný pod gRPC musí být thread-safe.
Při výběru řešení pro aproximativní hledání v mnohorozměrném prostoru padla volba na hnswlib pro relativně vysoký výkon a jednoduchost implementace. Knihovnu hnswlib máme upravenou na použití FP16 čísel z důvodu úspory paměti. Poloviční floating point přesnost nemá negativní vliv na kvalitu prostorového indexu a nepřináší ani snížení výkonu. Je sice nutné provádět zpětnou konverzi FP16 → FP32 navíc, ale s využitím AVX instrukcí se jedná o velice rychlou operaci, a naopak se ušetří čas čtením menšího množství dat z RAM. V současné době existují i výkonnější řešení pro aproximativní hledání, například knihovna ScaNN, která ale byla zveřejněna až v době, kdy byl vývoj našeho projektu v pokročilé fázi a nedávalo smysl měnit core technologii, jelikož by to oddálilo termín dokončení. Aproximativní hledání v prostorovém indexu není rychlostní bottleneck, i s použitím hnswlib dosahujeme latence řádově v milisekundách s recallem větším jak 95 %.
Jako inferenční framework pro ELECTRu a další neuronové sítě používáme onnxruntime. Inference modelů se provádí na CPU s použitím kvantizace a využitím AVX-512 VNNI instrukční sady, Intelem marketingově označované jako Deep Learning Boost. CPU je tady opět spíše pragmatickou volbou, má nižší výkon oproti GPU, ale výhodou CPU je „dostupnost“, na CPU musí úloha běžet tak jako tak a není tedy třeba hardware navíc ve formě GPU, nákladově to vychází lépe.
Tokenizace textu pro ELECTRu využívá HuggingFace Tokenizers knihovnu v Rustu, nad kterou máme napsaný Rust wrapper exportující C bindingy a nad nimi ještě C++ wrapper, zapouzdřující tokenizer do objektu pro jednoduché použití v C++.
Relevanční model je postavený na gradient boosted decision trees, konkrétně na knihovně CatBoost. Do relevančního modelu vstupuje celá řada features (sémantické podobnosti dotazu a dokumentu, textové relevance, features dotazu, features dokumentu…) a je základní komponentou pro řazení dokumentů podle relevance. Features sémantické podobnosti dotazu a dokumentu ELECTRA modelu jsou pro relevanční model nejdůležitější, přispívají nejvíce k výsledné predikci konečné relevance dokumentu.

Malá revoluce
Jazykové modely, konkrétně především BERT a jeho deriváty, způsobily malou revoluci ve zpracování textu a obecně přirozeného jazyka. S jejich pomocí je možné celou řadu úloh, nejen v oblasti hledání, řešit novými přístupy a dosáhnout vyšší kvality. Daní za to je ovšem vysoká výpočetní náročnost a potřeba velkého množství učicích dat.
Jedná se o poměrně nové technologie, které se nám podařilo produkčně nasadit do fulltextového hledání Seznamu teprve nedávno a víme, že jsme ještě plně nevyužili potenciál, který nabízejí. To je pro nás výzva a zároveň i cesta, jak dále pokračovat v rozvoji hledání a zlepšování jeho kvality.