
Obsah
1. Knihovna Pandas: práce s datovými řadami (series)
3. Počet prvků v datové řadě versus specifikace indexů
4. Konstrukce datové řady ze slovníku, vliv pořadí klíčů
5. Vytvoření nové datové řady z řady stávající – výběr prvků na základě jejich indexů
6. Základní statistické informace o prvcích uložených v datové řadě
7. Vektorové operace nad všemi prvky datové řady
8. Výběr prvků z datové řady na základě podmínky
9. Konverze mezi různými datovými typy datové řady
10. Použití hodnot None, resp. numpy.nan
11. Vykreslení hodnot prvků z datové řady formou grafu
12. Liniový (spojnicový) graf a graf s vyplněnou plochou pod liniovým grafem
13. Vertikální i horizontální sloupcové grafy
14. Graf s KDE (Kernel density estimation)
17. Vyhlazení průběhu na grafu
18. Graf s několika průběhy získanými z datové řady, použití podgrafů
19. Repositář s demonstračními příklady
1. Knihovna Pandas: práce s datovými řadami (series)
Ve druhém článku o knihovně Pandas jsme se seznámili s tabulkou nových datových typů, které jsou v rámci této knihovny do Pythonu přidány:
| # | Datový typ | Stručný popis |
|---|---|---|
| 1 | Series | odvozeno od 1D pole knihovny Numpy, rozšířeno o popis os |
| 2 | DataFrame | reprezentace dat uložených do tabulky s popisem os (sloupců, řádků) |
| 3 | DatetimeTZDtype | datum s přidanou informací o časové zóně |
| 4 | PeriodDtype | reprezentace časové periody (offsetu) |
| 5 | IntervalDtype | reprezentace numerického intervalu (odvozeno od dalších typů, například int64 atd.) |
| 6 | Int8Dtype | typ int8 rozšířený pro podporu hodnoty pandas.NA |
| 7 | Int16Dtype | typ int16 rozšířený pro podporu hodnoty pandas.NA |
| 8 | Int32Dtype | typ int32 rozšířený pro podporu hodnoty pandas.NA |
| 9 | Int64Dtype | typ int64 rozšířený pro podporu hodnoty pandas.NA |
| 10 | UInt8Dtype | typ uint8 rozšířený pro podporu hodnoty pandas.NA |
| 11 | UInt16Dtype | typ uint16 rozšířený pro podporu hodnoty pandas.NA |
| 12 | UInt32Dtype | typ uint32 rozšířený pro podporu hodnoty pandas.NA |
| 13 | UInt64Dtype | typ uint64 rozšířený pro podporu hodnoty pandas.NA |
| 14 | CategoricalDtype | kategorie (odvozeno od jazyka R, bude popsáno příště) |
| 15 | SparseDtype | použito pro ukládání řídkých polí (bude popsáno příště) |
| 16 | StringDtype | rozšíření řetězců; prozatím ve fázi experimentálního rozšíření |
| 17 | BooleanDtype | rozšíření pravdivostního typu; prozatím ve fázi experimentálního rozšíření |
Základním stavebním kamenem knihovny Pandas je přitom typ Series (datová řada), který zapouzdřuje jednodimenzionální pole z knihovny Numpy. Datová řada představuje uspořádaný sloupec údajů, které mají shodný typ (například int64 nebo float64 atd.), přičemž každému prvku je přiřazen index. Nemusí se přitom jednat o celé číslo, protože indexem mohou být i řetězce atd. – což je mimochodem velmi užitečné, jak uvidíme dále. Instance třídy Series mají několik užitečných atributů:
| # | Atribut | Stručný popis |
|---|---|---|
| 1 | index | indexy prvků v řadě |
| 2 | values | hodnoty prvků ve formě 1D pole |
| 3 | size | počet prvků v řadě |
| 4 | name | jméno řady (pokud je specifikováno) |
| 5 | dtype | typ prvků uložených v datové řadě |
| 6 | hasnans | test, zda je nějaký prvek roven NaN |
Dále instance této třídy podporují několik desítek metod; s některými z nich se seznámíme v dalším textu.
2. Konstrukce datové řady
Nejprve si ukážeme, jakým způsobem se datové řady vytváří. Nejjednodušší je situace ve chvíli, kdy jsou hodnoty, které se mají převést na datovou řadu, připraveny ve formě seznamů nebo n-tic (ve smyslu základních datových typů programovacího jazyka Python). Z takto připravených hodnot se datová řada připraví přímočaře, a to konstruktorem pandas.Series. V dalším příkladu předáváme konstruktoru n-tici, proto se používá dvojice kulatých závorek:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series((1, 2, 3, 4, 5, 6))
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
Povšimněte si, že v tomto případě jsou indexy prvků v datové řadě dopočteny automaticky (první sloupec ve výpisu). Současně se uloží i informace, že index je tvořen generátorem RangeIndex:
Series: 0 1 1 2 2 3 3 4 4 5 5 6 dtype: int64 Index: RangeIndex(start=0, stop=6, step=1) Values: [1 2 3 4 5 6]
Specifikovat je možné i indexy jednotlivých prvků. Ty se předávají ve druhém parametru konstruktoru pandas.Series:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series(('a', 'b', 'c', 'd', 'e', 'f'), (1, 2, 3, 4, 5, 6))
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
Výsledek bude vypadat takto:
Series: 1 a 2 b 3 c 4 d 5 e 6 f dtype: object Index: Int64Index([1, 2, 3, 4, 5, 6], dtype='int64') Values: ['a' 'b' 'c' 'd' 'e' 'f']
3. Počet prvků v datové řadě versus specifikace indexů
Při konstrukci datové řady je zapotřebí zaručit, že počet prvků bude odpovídat počtu zadaných indexů (samozřejmě za předpokladu, že indexy explicitně potřebujeme nastavit). Například následující příklad je plně funkční, protože počet prvků (1, 2, 3, 4, 5 a 6) přesně odpovídá počtu zadaných indexů, tedy ‚a‘, ‚b‘, ‚c‘, ‚d‘, ‚e‘ a ‚f‘:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
Výsledek:
Series: a 1 b 2 c 3 d 4 e 5 f 6 dtype: int64 Index: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object') Values: [1 2 3 4 5 6]
Naproti tomu další příklad skončí s chybou, protože počet prvků a indexů si neodpovídá:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series(range(1, 10), ('a', 'b', 'c'))
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
Chyba:
Traceback (most recent call last):
File "series_04.py", line 6, in <;module>
s = pandas.Series(range(1, 10), ('a', 'b', 'c'))
File "/home/ptisnovs/.local/lib/python3.6/site-packages/pandas/core/series.py", line 314, in __init__
f"Length of passed values is {len(data)}, "
ValueError: Length of passed values is 9, index implies 3.
Totéž ovšem platí i naopak, pokud bude počet indexů větší než počet prvků:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series(range(1, 3), ('a', 'b', 'c', 'd', 'e', 'f', 'g'))
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
S chybou:
Traceback (most recent call last):
File "series_04.py", line 6, in <;module>
s = pandas.Series(range(1, 3), ('a', 'b', 'c', 'd', 'e', 'f', 'g'))
File "/home/ptisnovs/.local/lib/python3.6/site-packages/pandas/core/series.py", line 314, in __init__
f"Length of passed values is {len(data)}, "
ValueError: Length of passed values is 2, index implies 7.
4. Konstrukce datové řady ze slovníku, vliv pořadí klíčů
Poměrně často, zvláště pokud jsou datové řady tvořeny relativně malým počtem prvků (statisíce až miliony prvků), je možné řadu i s indexy vytvořit přímo ze slovníku (dictionary). Důležité přitom je, že je zachováno pořadí prvků ze slovníku (což je nová vlastnost kodifikovaná v Pythonu 3.8). Příklad použití:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
input_data = {
"a": 1,
"b": 2,
"c": 3,
"d": 4,
"e": 5,
"f": 6,
}
print("Input data:")
print(input_data)
print()
s = pandas.Series(input_data)
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
S výsledkem (povšimněte si pořadí prvků ve výsledné datové řadě):
Input data:
{'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
Series:
a 1
b 2
c 3
d 4
e 5
f 6
dtype: int64
Index:
Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
Values:
[1 2 3 4 5 6]
Prvky ve vstupním slovníku můžeme prohodit:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
input_data = {
"f": 6,
"e": 5,
"d": 4,
"c": 3,
"b": 2,
"a": 1,
}
print("Input data:")
print(input_data)
print()
s = pandas.Series(input_data)
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
Tato změna se projeví i v pořadí prvků ve výsledné datové řadě:
Input data:
{'f': 6, 'e': 5, 'd': 4, 'c': 3, 'b': 2, 'a': 1}
Series:
f 6
e 5
d 4
c 3
b 2
a 1
dtype: int64
Index:
Index(['f', 'e', 'd', 'c', 'b', 'a'], dtype='object')
Values:
[6 5 4 3 2 1]
Nic nám ovšem nebrání použít i zpětně kompatibilní datovou strukturu OrderedDict, kterou lze použít takto:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
from collections import OrderedDict
input_data = OrderedDict()
input_data["f"] = 6
input_data["e"] = 5
input_data["d"] = 4
input_data["c"] = 3
input_data["b"] = 2
input_data["a"] = 1
print("Input data:")
print(input_data)
print()
s = pandas.Series(input_data)
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
S tímto (očekávaným) výsledkem:
Input data:
OrderedDict([('f', 6), ('e', 5), ('d', 4), ('c', 3), ('b', 2), ('a', 1)])
Series:
f 6
e 5
d 4
c 3
b 2
a 1
dtype: int64
Index:
Index(['f', 'e', 'd', 'c', 'b', 'a'], dtype='object')
Values:
[6 5 4 3 2 1]
5. Vytvoření nové datové řady z řady stávající – výběr prvků na základě jejich indexů
Datovou řadu je možné vytvořit z řady již existující, a to výběrem indexů těch prvků, které mají být přidány do nové řady. Podobně je možné změnit (mutovat) stávající datovou řadu. Pro oba zmíněné účely se používá metoda nazvaná pandas.Series.reindex, které se předá seznam, popř. pole indexů vybíraných prvků. Samozřejmě nám nic nebrání v tom, aby se některé prvky opakovaly a jiné naopak nebyly použity vůbec:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
s = s.reindex(['d', 'a', 'b', 'c', 'd', 'a', 'a', 'a'])
print("Reindexed:")
print()
print("Series:")
print(s)
print()
print("Index:")
print(s.index)
print()
print("Values:")
print(s.values)
print()
S výsledkem:
Series: a 1 b 2 c 3 d 4 e 5 f 6 dtype: int64 Index: Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object') Values: [1 2 3 4 5 6] Reindexed: Series: d 4 a 1 b 2 c 3 d 4 a 1 a 1 a 1 dtype: int64 Index: Index(['d', 'a', 'b', 'c', 'd', 'a', 'a', 'a'], dtype='object') Values: [4 1 2 3 4 1 1 1]
6. Základní statistické informace o prvcích uložených v datové řadě
Z datové řady, pochopitelně za předpokladu, že obsahuje numerické hodnoty, lze získat i většinu základních statistických informací – tedy součet prvků, jejich součin, minimální hodnotu, maximální hodnotu, průměrnou hodnotu, medián, kvantil, směrodatnou odchylku atd. K tomuto účelu se používají metody objektu Series, jejichž názvy jsou v oblasti statisticky zavedené:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
print("sum", s.sum(), sep="\t")
print("prod", s.prod(), sep="\t")
print("min", s.min(), sep="\t")
print("max", s.max(), sep="\t")
print("median", s.median(), sep="\t")
print("std", s.std(), sep="\t")
print("var", s.var(), sep="\t")
print("quantile", s.quantile(0.01), sep="\t")
Výsledek:
sum 21 prod 720 min 1 max 6 median 3.5 std 1.8708286933869707 var 3.5 quantile 1.05
Užitečné je, že pokud je nějaká hodnota v datové řadě vynechána, výpočty ji přeskočí – tudíž není vyhozena výjimka atd. Pandas se v tomto ohledu tedy chová podobně, jako výpočty v programovacím jazyku R:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series((1, 2, None, 4, 5, 6), ('a', 'b', 'c', 'd', 'e', 'f'))
print("sum", s.sum(), sep="\t")
print("prod", s.prod(), sep="\t")
print("min", s.min(), sep="\t")
print("max", s.max(), sep="\t")
print("median", s.median(), sep="\t")
print("std", s.std(), sep="\t")
print("var", s.var(), sep="\t")
print("quantile", s.quantile(0.01), sep="\t")
Výsledky:
sum 18.0 prod 240.0 min 1.0 max 6.0 median 4.0 std 2.073644135332772 var 4.3 quantile 1.04
7. Vektorové operace nad všemi prvky datové řady
Třída pandas.Series kromě dalších věcí přetěžuje některé operátory programovacího jazyka Python takovým způsobem, aby bylo například možné sečíst odpovídající prvky ze dvou datových řad, popř. aby se ke každému prvky řady přičetla určitá skalární konstanta. Ukažme si několik příkladů. Nejdříve kombinaci datové řady a skalární hodnoty:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
s1 = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
print(s1 + 10)
print(s1 - 10)
print(s1 * 10)
print(s1 / 10)
print(s1 % 2)
S výsledky:
a 11 b 12 c 13 d 14 e 15 f 16 dtype: int64 a -9 b -8 c -7 d -6 e -5 f -4 dtype: int64 a 10 b 20 c 30 d 40 e 50 f 60 dtype: int64 a 0.1 b 0.2 c 0.3 d 0.4 e 0.5 f 0.6 dtype: float64 a 1 b 0 c 1 d 0 e 1 f 0 dtype: int64
Vynásobení všech prvků konstantou s úpravou datové řady:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
s1 = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
s1 = s1 * 2
print(s1)
Dtto, ale se zkráceným zápisem:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
s1 = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
s1 *= 2
print(s1)
Použít je možné i relační operátory. Výsledkem bude nová datová řada obsahující hodnoty True a False:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
s1 = pandas.Series(range(1, 7), ('a', 'b', 'c', 'd', 'e', 'f'))
print(s1 > 3)
print(s1 < 3)
print(s1 % 2 == 0)
Výsledek by měl vypadat následovně:
a False b False c False d True e True f True dtype: bool a True b True c False d False e False f False dtype: bool a False b True c False d True e False f True dtype: bool
Podporovány jsou i hodnoty None a NA, které se vyhodnotí na False:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
s1 = pandas.Series((1, 2, None, 4, 5, 6), ('a', 'b', 'c', 'd', 'e', 'f'))
print(s1 > 3)
print(s1 < 3)
print(s1 % 2 == 0)
S výsledky:
a False b False c False d True e True f True dtype: bool a True b True c False d False e False f False dtype: bool a False b True c False d True e False f True dtype: bool
Podobné operace lze provádět i na dvojicí datových řad za předpokladu, že obsahují shodné indexy prvků:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import numpy as np import pandas s1 = pandas.Series(range(1, 7)) s2 = pandas.Series(np.repeat(100, 6)) print(s1 + s2) print(s1 - s2) print(s1 * s2) print(s1 / s2) print(s1 > s2) print(s1 < s2)
Výsledky mohou v tomto případě vypadat následovně:
0 101 1 102 2 103 3 104 4 105 5 106 dtype: int64 0 -99 1 -98 2 -97 3 -96 4 -95 5 -94 dtype: int64 0 100 1 200 2 300 3 400 4 500 5 600 dtype: int64 0 0.01 1 0.02 2 0.03 3 0.04 4 0.05 5 0.06 dtype: float64 0 False 1 False 2 False 3 False 4 False 5 False dtype: bool 0 True 1 True 2 True 3 True 4 True 5 True dtype: bool
Další podobně koncipované operace, tentokrát s uložením výsledků:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import numpy as np import pandas s1 = pandas.Series(range(1, 7)) s2 = pandas.Series(np.repeat(100, 6)) print(s1) s1 += s2 print(s1) s1 *= s2 print(s1)
8. Výběr prvků z datové řady na základě podmínky
Knihovna Pandas (přesněji řečeno knihovna Numpy volaná přes Pandas) nám dále umožňuje výběr prvků z datové řady na základě vyhodnocení podmínky pro každý prvek. V tomto případě je nutné podmínku zapsat do hranatých (indexových) závorek. Pokud se podmínka vyhodnotí na True, bude prvek použit ve výsledku, v opačném případě bude zahozen. Vybírat tedy můžeme prvky menší nebo větší než nějaká hodnota, prvky dělitelné dvěma atd.:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import numpy as np import pandas s1 = pandas.Series(range(1, 7)) s2 = pandas.Series(range(50)) print(s1[s1<3]) print(s1[s1>3]) print(s2[s2 % 2 == 0]) print(s2[s2 % 2 != 0]) print(s2[s2 % 3 == 0])
Výsledky:
0 1 1 2 dtype: int64 3 4 4 5 5 6 dtype: int64 0 0 2 2 4 4 6 6 8 8 10 10 12 12 14 14 16 16 18 18 20 20 22 22 24 24 26 26 28 28 30 30 32 32 34 34 36 36 38 38 40 40 42 42 44 44 46 46 48 48 dtype: int64 1 1 3 3 5 5 7 7 9 9 11 11 13 13 15 15 17 17 19 19 21 21 23 23 25 25 27 27 29 29 31 31 33 33 35 35 37 37 39 39 41 41 43 43 45 45 47 47 49 49 dtype: int64 0 0 3 3 6 6 9 9 12 12 15 15 18 18 21 21 24 24 27 27 30 30 33 33 36 36 39 39 42 42 45 45 48 48 dtype: int64
Nic nám ovšem nebrání provádět výběr na základě logické operace aplikované na odlišnou datovou řadu, což je ukázáno v dalším příkladu: prvky z první řady s1 jsou vybírány na základě vyhodnocení podmínky pro prvky řady s2:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import numpy as np import pandas s1 = pandas.Series(range(1, 7)) s2 = pandas.Series(range(-3, 3)) print(s1[s2 >= 0]) print(s1[s2 < 0]) print(s1[s2 != 0])
Nyní by měly výsledky vypadat takto:
3 4 4 5 5 6 dtype: int64 0 1 1 2 2 3 dtype: int64 0 1 1 2 2 3 4 5 5 6 dtype: int64
9. Konverze mezi různými datovými typy datové řady
Často se setkáme i s nutností konvertovat hodnoty uložené do datové řady tak, aby byl interně použit určitý specifický datový typ. Příkladem může být import dat, provedení nějaké operace s těmito daty (výpočet atd.) a následné uložení dat do jiného formátu, přičemž například výpočty vyžadují použití datového typu float64 atd. Pro přetypování se používá metoda astype, které se předá výsledný datový typ (i ve formátu řetězce):
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series((100, 200, 300, 400, 500, 600))
print(s.dtypes)
print(s)
print()
s = s.astype('int32')
print(s.dtypes)
print(s)
print()
s =s.astype('int8')
print(s.dtypes)
print(s)
Po spuštění tohoto příkladu je patrné, že se hodnoty v celé datové řadě skutečně zkonvertovaly:
int64 0 100 1 200 2 300 3 400 4 500 5 600 dtype: int64 int32 0 100 1 200 2 300 3 400 4 500 5 600 dtype: int32
Převod na typ int8 vede (pochopitelně) ke ztrátě informace:
int8 0 100 1 -56 2 44 3 -112 4 -12 5 88 dtype: int8
Taktéž je možné využít automatickou konverzi na ten nejlepší datový typ, což je ukázáno na následujícím příkladu, kdy se datová řada obsahující hodnoty float32 převede na typ Int64. Pro automatickou konverzi se používá metoda convert_dtypes:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import pandas s = pandas.Series((100, 200, 300, 400, 500, 600), dtype="float32") print(s.dtypes) print(s) print() s = s.convert_dtypes() print(s.dtypes) print(s) print()
S následujícím výsledkem:
float32 0 100.0 1 200.0 2 300.0 3 400.0 4 500.0 5 600.0 dtype: float32 Int64 0 100 1 200 2 300 3 400 4 500 5 600 dtype: Int64
Dtto pro datovou řadu obsahující obecné objekty:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import pandas s = pandas.Series((100, 200, 300, 400, 500, 600), dtype="O") print(s.dtypes) print(s) print() s = s.convert_dtypes() print(s.dtypes) print(s) print()
Opět vidíme, že se konverze provedla na typ Int64:
object 0 100 1 200 2 300 3 400 4 500 5 600 dtype: object Int64 0 100 1 200 2 300 3 400 4 500 5 600 dtype: Int64
Mimochodem – podporován je i typ float16, který je v některých případech užitečný:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import pandas
s = pandas.Series((100, 200, 300, 400, 500, 600))
print(s.dtypes)
print(s)
print()
s = s.astype('float16')
print(s.dtypes)
print(s)
print()
S výsledkem:
int64 0 100 1 200 2 300 3 400 4 500 5 600 dtype: int64 float16 0 100.0 1 200.0 2 300.0 3 400.0 4 500.0 5 600.0 dtype: float16
10. Použití hodnot None, resp. numpy.nan
Při konverzi je nutné počítat s tím, že vstupní data mohou obsahovat hodnoty None, resp. numpy.nan. Vyzkoušejme si tedy, jak na tyto hodnoty zareaguje konverzní funkce convert_dtypes popsaná v předchozí kapitole:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import pandas s = pandas.Series((100, 200, 300, None, 400, 500, 600)) print(s.dtypes) print(s) print() s = s.convert_dtypes() print(s.dtypes) print(s) print()
Výsledkem je převod na Int64 (s velkým „I“ na začátku):
float64 0 100.0 1 200.0 2 300.0 3 NaN 4 400.0 5 500.0 6 600.0 dtype: float64 Int64 0 100 1 200 2 300 3 <NA> 4 400 5 500 6 600 dtype: Int64
Povodně v případě, že jedna z hodnot je typu float64:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import pandas s = pandas.Series((100.1, 200, 300, None, 400, 500, 600)) print(s.dtypes) print(s) print() s = s.convert_dtypes() print(s.dtypes) print(s) print()
S výsledkem (bez převodu na jiný typ):
float64 0 100.1 1 200.0 2 300.0 3 NaN 4 400.0 5 500.0 6 600.0 dtype: float64 float64 0 100.1 1 200.0 2 300.0 3 NaN 4 400.0 5 500.0 6 600.0 dtype: float64
Na vstupu taktéž mnohdy nalezneme hodnotu numpy.nan a nikoli Null:
#!/usr/bin/env python3 # vim: set fileencoding=utf-8 import pandas import numpy s = pandas.Series((100, 200, 300, numpy.nan, 400, 500, 600)) print(s.dtypes) print(s) print() s = s.convert_dtypes() print(s.dtypes) print(s) print()
Taková datová řada se převede na typ Int64 a numpy.nan se převede na NA:
float64 0 100.0 1 200.0 2 300.0 3 NaN 4 400.0 5 500.0 6 600.0 dtype: float64 Int64 0 100 1 200 2 300 3 <NA> 4 400 5 500 6 600 dtype: Int64
11. Vykreslení hodnot prvků z datové řady formou grafu
Již v předchozím článku jsme se zabývali popisem vykreslení grafů z hodnot uložených v datovém rámci. Grafy je ovšem možné vytvářet i z běžné datové řady, a to podobným způsobem – primárně s využitím knihovny Matplotlib. U každé datové řady jsou k dispozici následující metody sloužící k vykreslení grafů:
| # | Metoda | Stručný popis |
|---|---|---|
| 1 | pandas.Series.plot | graf vybraný parametrem kind |
| 2 | pandas.Series.plot.area | oblast pod průběhem je vyplněna barvou (pro kladné hodnoty) |
| 3 | pandas.Series.plot.bar | sloupcový graf s vertikálně orientovanými sloupci |
| 4 | pandas.Series.plot.barh | sloupcový graf s horizontálně orientovanými sloupci |
| 5 | pandas.Series.plot.box | krabicový diagram |
| 6 | pandas.Series.plot.density | diagram založený na KDE |
| 7 | pandas.Series.plot.hist | histogram (bude použit příště) |
| 8 | pandas.Series.plot.kde | diagram založený na KDE |
| 9 | pandas.Series.plot.line | stejné jako pandas.Series.plot |
| 10 | pandas.Series.plot.pie | koláčový diagram |
| 11 | pandas.Series.hist | histogram (bude použit příště) |
V navazujících kapitolách si některé z těchto grafů ukážeme.
12. Liniový (spojnicový) graf a graf s vyplněnou plochou pod liniovým grafem
Prvním typem grafu, s nímž se v dnešním článku seznámíme, je takzvaný spojnicový či liniový graf. Ten se poměrně často využívá například ve finančnictví (kde bývá různě upravován do svíčkového grafu atd). Vytvoření takového grafu z datové řady je většinou triviální, což je ostatně ukázáno i v dalším demonstračním příkladu:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# tisk obsahu Series
print(s)
# vytvoření grafu
s.plot()
# uložení grafu
plt.savefig("series_plot_01.png")
# vykreslení grafu
plt.show()
Výsledný graf by měl vypadat následovně:
Obrázek 1: Jednoduchý liniový graf.
Vytvořit je možné i graf s vyplněnou plochou pod liniovým grafem (nebo nad liniovým grafem pro záporné hodnoty). V tomto případě je možné využít (resp. spíše zneužít) metodu pandas.Series.plot.area tak, jak je ukázáno v dalším demonstračním příkladu:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# tisk obsahu Series
print(s)
# vytvoření grafu
s.plot.area(stacked=False)
# uložení grafu
plt.savefig("series_plot_02.png")
# vykreslení grafu
plt.show()
Obrázek 2: Graf s vyplněnou plochou pod liniovým grafem.
13. Vertikální i horizontální sloupcové grafy
Jedním z nejjednodušších typů grafů podporovaných Pandasem je sloupcový graf, který může být podle konkrétních požadavků orientován jak horizontálně tak i vertikálně. Tento typ grafu se vytváří zavoláním metody pandas.Series.plot.bar, popř. pandas.Series.plot.barh. Podívejme se nyní na jednoduchý příklad vertikálního sloupcového grafu:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 20)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# tisk obsahu Series
print(s)
# vytvoření grafu
s.plot.bar(grid=True)
# uložení grafu
plt.savefig("series_plot_03.png")
# vykreslení grafu
plt.show()
Obrázek 3: Vertikální sloupcový graf.
Horizontální sloupcový graf, v němž jsou sloupce vodorovné, se ze vstupních dat vykreslí takto:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 20)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# tisk obsahu Series
print(s)
# vytvoření grafu
s.plot.barh(grid=True)
# uložení grafu
plt.savefig("series_plot_04.png")
# vykreslení grafu
plt.show()
Obrázek 4: Horizontální sloupcový graf.
14. Graf s KDE (Kernel density estimation)
V knihovně Pandas nalezneme i metodu nazvanou pandas.Series.plot.kde, která slouží pro vykreslení zobecněného histogramu s využitím KDE neboli Kernel density estimation. Narozdíl od histogramu umožňuje KDE lépe popsat skutečné chování dat, kterých se předpokládá, že tvoří spojitou funkci:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# tisk obsahu Series
print(s)
# vytvoření grafu
s.plot.kde(grid=True)
# uložení grafu
plt.savefig("series_plot_05.png")
# vykreslení grafu
plt.show()
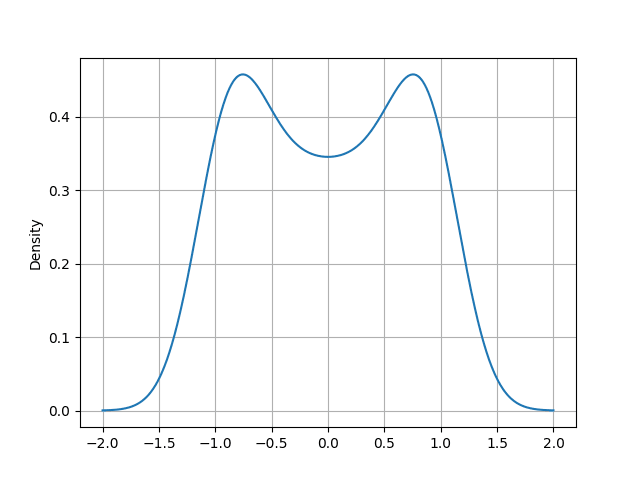
Obrázek 5: Graf s KDE (Kernel density estimation).
15. Koláčový diagram
Dalším typem grafu, s nímž se v dnešním článku seznámíme, jsou takzvané koláčové grafy, které již každý čtenář zcela jistě viděl. Tyto typy grafů se používají v případě, že nás nezajímají absolutní hodnoty, ale hodnoty relativní, konkrétně vzájemné poměry. I tyto grafy je možné v případě datových řad využít a jejich výhodou je, že v implicitním nastavení jsou vykresleny ve 2D tvaru (protože trojrozměrné koláčové diagramy jsou z hlediska přehlednosti i poměrů vykreslených hodnot prakticky to vůbec nejhorší možné řešení – možná právě proto se s nimi tak často setkáme, pravděpodobně nejvíce ve chvíli, kdy nás mají tyto diagramy za úkol zmást).
Budeme vykreslovat datovou řadu získanou z tohoto souboru:
Sep 2020 Sep 2019 Change Language Ratings Changep 1 2 change C 15.95 +0.74 2 1 change Java 13.48 -3.18 3 3 Python 10.47 +0.59 4 4 C++ 7.11 +1.48 5 5 C# 4.58 +1.18 6 6 Visual Basic 4.12 +0.83 7 7 JavaScript 2.54 +0.41 8 9 change PHP 2.49 +0.62 9 19 change R 2.37 +1.33 10 8 change SQL 1.76 -0.19 11 14 change Go 1.46 +0.24 12 16 change Swift 1.38 +0.28 13 20 change Perl 1.30 +0.26 14 12 change Assembly language 1.30 -0.08 15 15 Ruby 1.24 +0.03 16 18 change MATLAB 1.10 +0.04 17 11 change Groovy 0.99 -0.52 18 33 change Rust 0.92 +0.55 19 10 change Objective-C 0.85 -0.99 20 24 change Dart 0.77 +0.13
Z tohoto souboru získáme sloupec Ratings s hodnotami datové řady a sloupec Language bude sloužit namísto indexů:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# přečtení zdrojových dat
df = pandas.read_csv("tiobe.tsv", sep="\t")
# specifikace indexu - má se získat ze sloupce Language
df.set_index("Language", inplace=True)
# pro jistotu si datový rámec zobrazíme
print(df)
# konstrukce struktury Series - datové řady z datového rámce
s = pandas.Series(df["Ratings"])
# tisk obsahu Series
print(s)
# vytvoření grafu
s.plot.pie()
# uložení grafu
plt.savefig("series_plot_06.png")
# vykreslení grafu
plt.show()
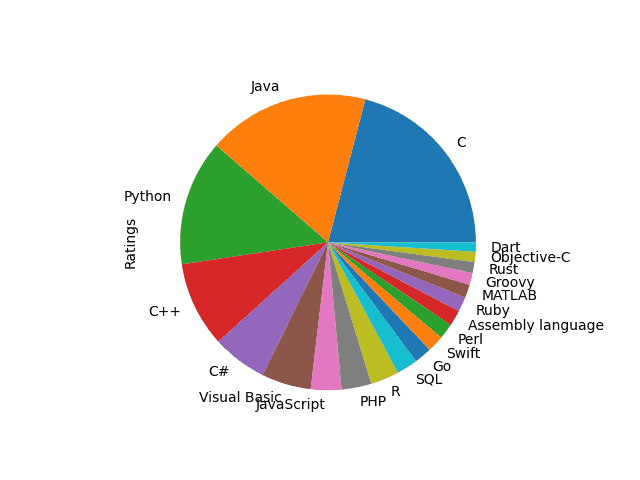
Obrázek 6: Koláčový graf vykreslený předchozím demonstračním příkladem.
16. Data obsahující šum
Data ukládaná do datových řad nebo datových rámců obsahují mnohdy i určitý šum. Ten si můžeme – prozatím velmi primitivním způsobem – nasimulovat například pomocí metody pandas.Series.map, která ovlivní každý prvek datové řady:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# přidání šumu
s2 = s.map(lambda x: x+np.random.rand()/2)
# tisk obsahu Series
print(s2)
# vytvoření grafu
s2.plot(grid=True)
# uložení grafu
plt.savefig("series_plot_07.png")
# vykreslení grafu
plt.show()
Tento příklad sice ukazuje použití map, ovšem rychlejší bude „vektorový“ přístup. Zde se ukazuje možnost vektorového součtu datové řady a pole v Numpy:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce datové struktury Series
s = pandas.Series(data=np.sin(r), index=r)
# šum
s2 = np.random.rand(100)/2
# přidání šumu k původní řadě
s3 = s + s2
# tisk obsahu Series
print(s3)
# vytvoření grafu
s3.plot(grid=True)
# uložení grafu
plt.savefig("series_plot_07_B.png")
# vykreslení grafu
plt.show()
Po spuštění tohoto příkladu by se měl zobrazit následující graf:
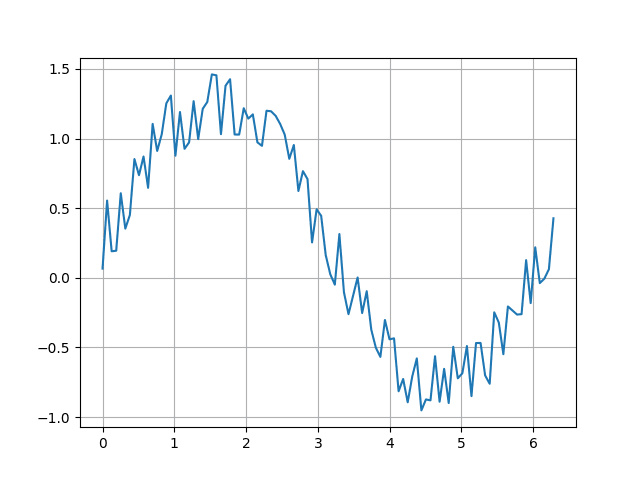
Obrázek 7: Zašuměná data.
17. Vyhlazení průběhu na grafu
V této kapitole si ve stručnosti popíšeme, jak lze vyhladit průběh zobrazený na grafu. Nejdříve si připravíme novou datovou řadu, která sice vychází z původní sinusovky, ale přidává do ní šum. Následně s využitím posuvného okna (rolling) průběh vyhladíme, přičemž se pro vyhlazení (jednoduchý moving average) použije okno široké dva vzorky:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# přidání šumu
s2 = s.map(lambda x: x+np.random.rand()/2)
# vyhlazení (moving average)
s3 = s2.rolling(2).mean()
# tisk obsahu Series
print(s3)
# vytvoření grafu
s3.plot(grid=True)
# uložení grafu
plt.savefig("series_plot_08.png")
# vykreslení grafu
plt.show()
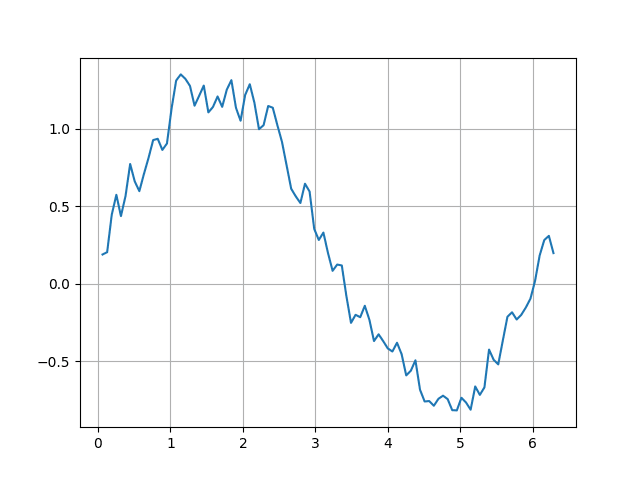
Obrázek 8: Částečné vyhlazení původně zašuměných dat.
Oblast, ze které se berou vzorky pro vyhlazení, ovšem může být i širší, například dvacet vzorků:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
# přidání šumu
s2 = s.map(lambda x: x+np.random.rand()/2)
# vyhlazení (moving average)
s3 = s2.rolling(20).mean()
# tisk obsahu Series
print(s3)
# vytvoření grafu
s3.plot(grid=True)
# uložení grafu
plt.savefig("series_plot_09.png")
# vykreslení grafu
plt.show()
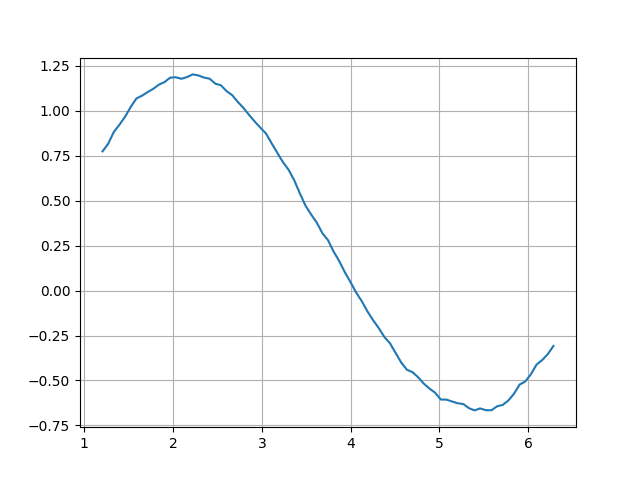
Obrázek 9: Vyhlazení zašuměných dat s využitím širší oblasti.
A konečně je možné využít i další metody vyhlazení, například s váhováním vzorků založeným na slavné Gaussově funkci:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
s2 = s.map(lambda x: x+np.random.rand()/2)
s3 = s2.rolling(10, win_type="gaussian").sum(std=3)
# tisk obsahu Series
print(s3)
# vytvoření grafu
s3.plot(grid=True)
# uložení grafu
plt.savefig("series_plot_10.png")
# vykreslení grafu
plt.show()
Výsledek bude vypadat následovně:
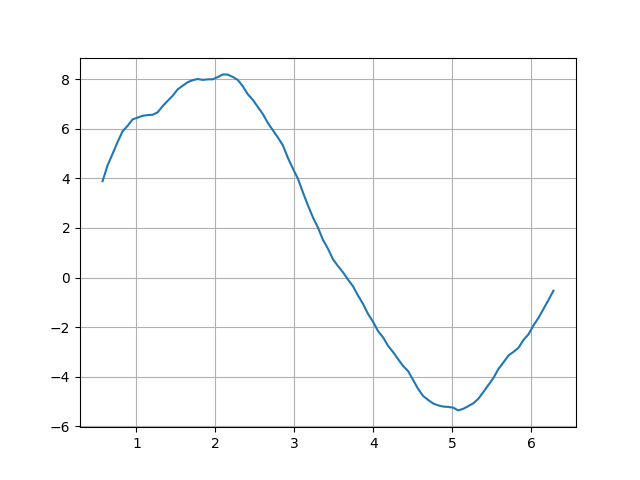
Obrázek 10: Použití Gaussovy funkce pro výpočet vah vzorků při vyhlazování.
18. Graf s několika průběhy získanými z datové řady, použití podgrafů
Často se setkáme s požadavkem zobrazit do jednoho grafu průběhy získané z několika datových řad. V takových případech už není možné použít nějakou metodu pandas.Series.plot.xxx, ale budeme muset zkombinovat možnosti knihoven Pandas i Matplotlib. To je ukázáno v následujícím demonstračním příkladu, v němž jsou nejdříve vytvořeny tři datové řady s, s2 a s3 a následně jsou všechny tyto řady vykresleny funkcí matplotlib.pyplot.plot (ony řetězce „–“ a „-“ popisují styl vykreslení):
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
s2 = s.map(lambda x: x+np.random.rand()/2)
s3 = s2 - s
# vytvoření grafu
plt.plot(s, "--", s2, "-", s3, "-")
# uložení grafu
plt.savefig("series_plot_11.png")
# vykreslení grafu
plt.show()
S výsledkem:
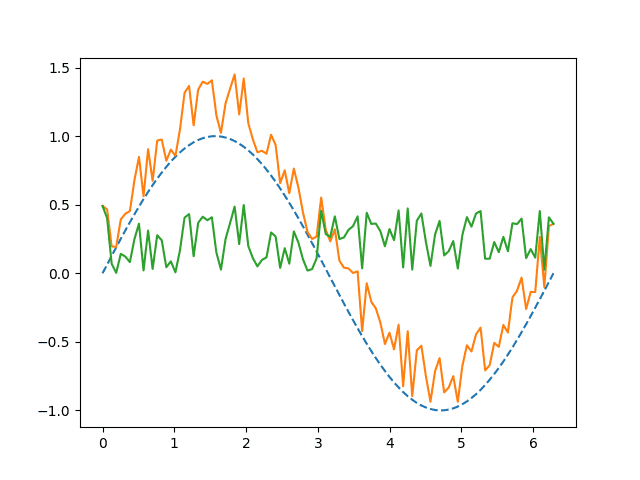
Obrázek 11: Graf se třemi průběhy; hodnoty byly získány ze tří datových řad.
Druhý požadavek vychází z potřeby zobrazit na jednu plochu více grafů. V tomto případě se někdy mluví o podgrafech, což však v daném kontextu nemá matematický význam. V dnešním posledním demonstračním příkladu je ukázáno, jak se na ploše pro zobrazení grafu vytvoří místo pro čtyři podgrafy, které se následně využije. Hodnota „221“ znamená „mřížka o rozměrech 2×2 buňky, první buňka v této mřížce“:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
import numpy as np
import pandas
import matplotlib.pyplot as plt
# hodnoty na x-ové ose
r = np.linspace(0, 2*np.pi, 100)
# konstrukce struktury Series - datové řady
s = pandas.Series(data=np.sin(r), index=r)
s2 = s.map(lambda x: x+np.random.rand()/2)
s3 = s2 - s
# vytvoření grafu
plt.subplot(221)
plt.plot(s)
plt.subplot(222)
plt.plot(s2)
plt.subplot(223)
plt.plot(s3)
# uložení grafu
plt.savefig("series_plot_12.png")
# vykreslení grafu
plt.show()
S výsledkem:
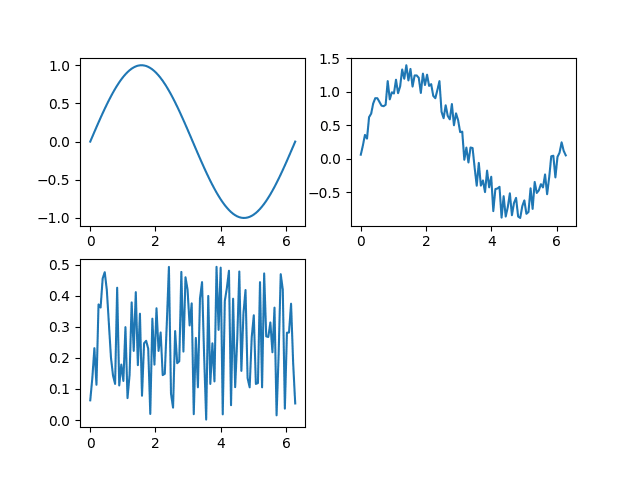
Obrázek 12: Tři grafy (podgrafy) vykreslené na jedinou společnou plochu.

19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů určených pro Python 3 a nejnovější stabilní verzi knihovny Pandas byly uloženy do Git repositáře dostupného na adrese https://github.com/tisnik/most-popular-python-libs. V případě, že nebudete chtít klonovat celý repositář (ten je ovšem stále velmi malý, dnes má velikost zhruba několik desítek kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:
Některé demonstrační příklady načítají následující soubory s daty:
20. Odkazy na Internetu
- Plotting with matplotlib
https://pandas.pydata.org/pandas-docs/version/0.13/visualization.html - Plot With Pandas: Python Data Visualization for Beginners
https://realpython.com/pandas-plot-python/ - Pandas Dataframe: Plot Examples with Matplotlib and Pyplot
https://queirozf.com/entries/pandas-dataframe-plot-examples-with-matplotlib-pyplot - Opulent-Pandas na PyPi
https://pypi.org/project/opulent-pandas/ - pandas_validator na PyPi
https://pypi.org/project/pandas_validator/ - pandas-validator (dokumentace)
https://pandas-validator.readthedocs.io/en/latest/ - 7 Best Python Libraries for Validating Data
https://www.yeahhub.com/7-best-python-libraries-validating-data/ - Universally unique identifier (Wikipedia)
https://en.wikipedia.org/wiki/Universally_unique_identifier - Nullable integer data type
https://pandas.pydata.org/pandas-docs/stable/user_guide/integer_na.html - pandas.read_csv
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html - How to define format when using pandas to_datetime?
https://stackoverflow.com/questions/36848514/how-to-define-format-when-using-pandas-to-datetime - Pandas : skip rows while reading csv file to a Dataframe using read_csv() in Python
https://thispointer.com/pandas-skip-rows-while-reading-csv-file-to-a-dataframe-using-read_csv-in-python/ - Skip rows during csv import pandas
https://stackoverflow.com/questions/20637439/skip-rows-during-csv-import-pandas - Denni kurz
https://www.cnb.cz/cs/financni_trhy/devizovy_trh/kurzy_devizoveho_trhu/denni_kurz.txt - UUID objects according to RFC 4122 (knihovna pro Python)
https://docs.python.org/3.5/library/uuid.html#uuid.uuid4 - Object identifier (Wikipedia)
https://en.wikipedia.org/wiki/Object_identifier - Digital object identifier (Wikipedia)
https://en.wikipedia.org/wiki/Digital_object_identifier - voluptuous na (na PyPi)
https://pypi.python.org/pypi/voluptuous - Repositář knihovny voluptuous na GitHubu
https://github.com/alecthomas/voluptuous - pytest-voluptuous 1.0.2 (na PyPi)
https://pypi.org/project/pytest-voluptuous/ - pytest-voluptuous (na GitHubu)
https://github.com/F-Secure/pytest-voluptuous - schemagic 0.9.1 (na PyPi)
https://pypi.python.org/pypi/schemagic/0.9.1 - Schemagic / Schemagic.web (na GitHubu)
https://github.com/Mechrophile/schemagic - schema 0.6.7 (na PyPi)
https://pypi.python.org/pypi/schema - schema (na GitHubu)
https://github.com/keleshev/schema - XML Schema validator and data conversion library for Python
https://github.com/brunato/xmlschema - xmlschema 0.9.7
https://pypi.python.org/pypi/xmlschema/0.9.7 - jsonschema 2.6.0
https://pypi.python.org/pypi/jsonschema - warlock 1.3.0
https://pypi.python.org/pypi/warlock - Python Virtual Environments – A Primer
https://realpython.com/python-virtual-environments-a-primer/ - pip 1.1 documentation: Requirements files
https://pip.readthedocs.io/en/1.1/requirements.html - unittest.mock — mock object library
https://docs.python.org/3.5/library/unittest.mock.html - mock 2.0.0
https://pypi.python.org/pypi/mock - An Introduction to Mocking in Python
https://www.toptal.com/python/an-introduction-to-mocking-in-python - Unit testing (Wikipedia)
https://en.wikipedia.org/wiki/Unit_testing - Unit testing
https://cs.wikipedia.org/wiki/Unit_testing - Test-driven development (Wikipedia)
https://en.wikipedia.org/wiki/Test-driven_development - Pip (dokumentace)
https://pip.pypa.io/en/stable/ - 5 Differences between clojure.spec and Schema
https://lispcast.com/clojure.spec-vs-schema/ - Schema: Clojure(Script) library for declarative data description and validation
https://github.com/plumatic/schema - clojure.spec – Rationale and Overview
https://clojure.org/about/spec






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU