
Obsah
1. Knihovna Pandas: zobrazení datových rámců, vykreslení grafů a validace dat
2. Nové datové typy podporované knihovnou Pandas
3. Zobrazení obsahu datového rámce
4. Zobrazení podrobnějších informací o datovém rámci
5. Základní statistické informace o datech uložených v rámci
6. Jazyk Python a knihovna Matplotlib
7. Zobrazení jednoduchého grafu
8. Kooperace mezi Pandas a Matplotlibem
9. Přímé vykreslení grafu bez použití knihovny Matplotlib
10. Přidání klouzavého průměru do grafu
11. Vylepšený výpočet klouzavého průměru
12. Od liniových grafů ke grafům sloupcovým
13. Výběr části datového rámce při vykreslování grafu
14. Zobecnění předchozího příkladu – zpracování numerických dat ve všech sloupcích
16. Validace s využitím knihovny Voluptuous
17. Validace s využitím knihovny Opulent Pandas
18. Repositář s demonstračními příklady a datovými soubory
19. Články s informacemi o různých způsobech validace datových struktur
1. Knihovna Pandas: zobrazení datových rámců, vykreslení grafů a validace dat
Ve druhém článku o knihovně Pandas se budeme zabývat třemi tématy. Nejprve si ukážeme způsob zobrazení datových rámců, a to jak jejich obsahu, tak i struktury, velikosti, základních statistických informací atd. Dále si popíšeme, jak lze zobrazit jednoduché grafy (prozatím grafy liniové a taktéž grafy sloupcové) s využitím možností nabízených jak knihovnou Pandas, tak i knihovnou Matplotlib. A konečně v závěrečné části článku si ukážeme některé možnosti validace dat uložených v datových rámcích.
Připomeňme si, že knihovna Pandas nabízí uživatelům-programátorům tuto funkcionalitu:
- Načtení dat z různých datových zdrojů do datových rámců (CSV, TSV, databáze, tabulkové procesory, …).
- Programová konstrukce datových rámců.
- Prohlížení obsahu datových rámců.
- Iterace nad daty, řazení a další podobné operace (bude ukázáno příště).
- Spojování, seskupování a změna tvaru dat (taktéž bude ukázáno příště).
- Práce s takzvanými sériemi (většinou získanými z datových rámců).
- Vykreslování grafů z údajů získaných z datových rámců (základy si ukážeme dnes, další příklady v navazujících článcích).
2. Nové datové typy podporované knihovnou Pandas
Společně s knihovnou Pandas je dodávána i deklarace nových datových typů, které jsou vypsány v tabulce pod tímto odstavcem. Důležité jsou především první dva typy, tedy Series odvozený od jednodimenzionálního pole knihovny Numpy a DataFrame popsaný v předchozím článku. Nesmíme ovšem zapomenout ani na datové typy určené pro reprezentaci časových údajů, popř. o rozšíření typů z knihovny Numpy o možnost reprezentace neexistující hodnoty: NULL, resp. N/A:
| # | Datový typ | Stručný popis |
|---|---|---|
| 1 | Series | odvozeno od 1D pole knihovny Numpy, rozšířeno o popis os |
| 2 | DataFrame | reprezentace dat uložených do tabulky s popisem os (sloupců, řádků) |
| 3 | DatetimeTZDtype | datum s přidanou informací o časové zóně |
| 4 | PeriodDtype | reprezentace časové periody (offsetu) |
| 5 | IntervalDtype | reprezentace numerického intervalu (odvozeno od dalších typů, například int64 atd.) |
| 6 | Int8Dtype | typ int8 rozšířený pro podporu hodnoty pandas.NA |
| 7 | Int16Dtype | typ int16 rozšířený pro podporu hodnoty pandas.NA |
| 8 | Int32Dtype | typ int32 rozšířený pro podporu hodnoty pandas.NA |
| 9 | Int64Dtype | typ int64 rozšířený pro podporu hodnoty pandas.NA |
| 10 | UInt8Dtype | typ uint8 rozšířený pro podporu hodnoty pandas.NA |
| 11 | UInt16Dtype | typ uint16 rozšířený pro podporu hodnoty pandas.NA |
| 12 | UInt32Dtype | typ uint32 rozšířený pro podporu hodnoty pandas.NA |
| 13 | UInt64Dtype | typ uint64 rozšířený pro podporu hodnoty pandas.NA |
| 14 | CategoricalDtype | kategorie (odvozeno od jazyka R, bude popsáno příště) |
| 15 | SparseDtype | použito pro ukládání řídkých polí (bude popsáno příště) |
| 16 | StringDtype | rozšíření řetězců; prozatím ve fázi experimentálního rozšíření |
| 17 | BooleanDtype | rozšíření pravdivostního typu; prozatím ve fázi experimentálního rozšíření |
3. Zobrazení obsahu datového rámce
V praktické části dnešního článku si nejdříve ukážeme způsob získání a popř. i výpisu základních informací o datových rámcích. Samotné zobrazení obsahu datového rámce je triviální – postačuje referenci na datový rámec předat funkci print, která automaticky obsah datového rámce převede na řetězec, který následně vypíše:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df)
Výsledek:
země měna množství kód kurz 0 Austrálie dolar 1 AUD 16.231 1 Brazílie real 1 BRL 4.160 2 Bulharsko lev 1 BGN 13.467 3 Čína žen-min-pi 1 CNY 3.381 4 Dánsko koruna 1 DKK 3.536 5 EMU euro 1 EUR 26.340 6 Filipíny peso 100 PHP 46.038 7 Hongkong dolar 1 HKD 2.864 8 Chorvatsko kuna 1 HRK 3.481 9 Indie rupie 100 INR 29.950 10 Indonesie rupie 1000 IDR 1.567 11 Island koruna 100 ISK 16.330 12 Izrael nový šekel 1 ILS 6.649 13 Japonsko jen 100 JPY 21.383 14 Jižní Afrika rand 1 ZAR 1.445 15 Kanada dolar 1 CAD 17.011 16 Korejská republika won 100 KRW 1.990 17 Maďarsko forint 100 HUF 7.328 18 Malajsie ringgit 1 MYR 5.425 19 Mexiko peso 1 MXN 1.104 20 MMF ZPČ 1 XDR 31.598 21 Norsko koruna 1 NOK 2.471 22 Nový Zéland dolar 1 NZD 15.416 23 Polsko zlotý 1 PLN 5.900 24 Rumunsko leu 1 RON 5.405 25 Rusko rubl 100 RUB 29.180 26 Singapur dolar 1 SGD 16.530 27 Švédsko koruna 1 SEK 2.577 28 Švýcarsko frank 1 CHF 24.363 29 Thajsko baht 100 THB 73.313 30 Turecko lira 1 TRY 2.911 31 USA dolar 1 USD 22.201 32 Velká Británie libra 1 GBP 29.464
Zobrazit lze i část datového rámce. Prvních n řádků (ve výchozím nastavení pět řádků) se vypíše metodou head:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.head())
Výsledek:
země měna množství kód kurz 0 Austrálie dolar 1 AUD 16.231 1 Brazílie real 1 BRL 4.160 2 Bulharsko lev 1 BGN 13.467 3 Čína žen-min-pi 1 CNY 3.381 4 Dánsko koruna 1 DKK 3.536
4. Zobrazení podrobnějších informací o datovém rámci
O datových rámcích je možné získat i další informace. Důležitá je mnohdy informace o typech sloupců, což je problematika, které jsme se již částečně dotkli minule:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.dtypes)
Výsledek ukazuje, jakého datového typu jsou položky v jednotlivých sloupcích:
země object měna object množství int64 kód object kurz float64 dtype: object
V dalším textu využijeme uspořádaný seznam jmen všech sloupců:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.columns)
Výsledek, se kterým je možné nakládat jako s běžnou sekvencí:
Index(['země', 'měna', 'množství', 'kód', 'kurz'], dtype='object')
Podrobnější informace o datovém rámci, obsazení paměti atd. zajistí funkce info:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.info())
Výsledek:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 33 entries, 0 to 32 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 země 33 non-null object 1 měna 33 non-null object 2 množství 33 non-null int64 3 kód 33 non-null object 4 kurz 33 non-null float64 dtypes: float64(1), int64(1), object(3) memory usage: 1.4+ KB
U této funkce (info) lze řídit podrobnost informací parametrem verbose:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.info(verbose=False))
Výsledek je nyní méně podrobný:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 33 entries, 0 to 32 Columns: 5 entries, země to kurz dtypes: float64(1), int64(1), object(3) memory usage: 1.4+ KB None
Další informace se týkají os (axes), tedy osy vertikální i horizontální (v rámci tabulky), dále počtu dimenzí (prakticky vždy dvě), tvaru (počet řádků×počet sloupců) a velikosti (výsledek počet řádků×počet sloupců):
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print("Axes: ", df.axes)
print("Ndim: ", df.ndim)
print("Size: ", df.size)
print("Shape: ", df.shape)
Výsledek:
Axes: [RangeIndex(start=0, stop=33, step=1), Index(['země', 'měna', 'množství', 'kód', 'kurz'], dtype='object')] Ndim: 2 Size: 165 Shape: (33, 5)
5. Základní statistické informace o datech uložených v rámci
Metodou describe lze získat základní (a mnohdy velmi užitečné) statistické informace o záznamech uložených v datovém rámci. Podívejme se nyní na způsob použití této metody:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading data file with custom format. separator + skip rows specification."""
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.describe())
S výsledkem:
množství kurz count 33.000000 33.000000 mean 55.272727 14.879061 std 174.929141 15.649135 min 1.000000 1.104000 25% 1.000000 3.381000 50% 1.000000 7.328000 75% 100.000000 22.201000 max 1000.000000 73.313000
import pandas
df = pandas.read_csv("denni_kurz.txt", sep="|", skiprows=1)
df["kurz"] = pandas.to_numeric(df["kurz"].str.replace(',','.'), errors='coerce')
print(df.describe().info())
Tentokrát získáme tento výstup:
<class 'pandas.core.frame.DataFrame'> Index: 8 entries, count to max Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 množství 8 non-null float64 1 kurz 8 non-null float64 dtypes: float64(2) memory usage: 192.0+ bytes None
6. Jazyk Python a knihovna Matplotlib
S knihovnou Matplotlib jsme se již na tomto serveru několikrát setkali (viz též odkazy na další informační zdroje uvedené na konci článku), takže již víme, že Matplotlib je knihovna určená pro programovací jazyk Python, která slouží k tvorbě a částečně i k interaktivním úpravám různých typů grafů, například klasických grafů funkcí jedné proměnné, ovšem i mnoha grafů více či méně složitějších (grafy více funkcí, trojrozměrné grafy, polární grafy, zobrazení kontur atd.). Možnosti knihovny Matplotlib jsou skutečně značně široké a přitom je její použití poměrně jednoduché a snadno pochopitelné, pokud samozřejmě vynecháme některé pokročilejší operace. Jednou ze zajímavých možností představuje použití této knihovny v interaktivním prostředí IPython, popř. IPython Notebook, zejména v kombinaci s další populární Pythonovskou knihovnou Numpy. A v kontextu tohoto článku je ještě důležitější to, že Matplotlib dokáže velmi dobře kooperovat i s knihovnou Pandas.
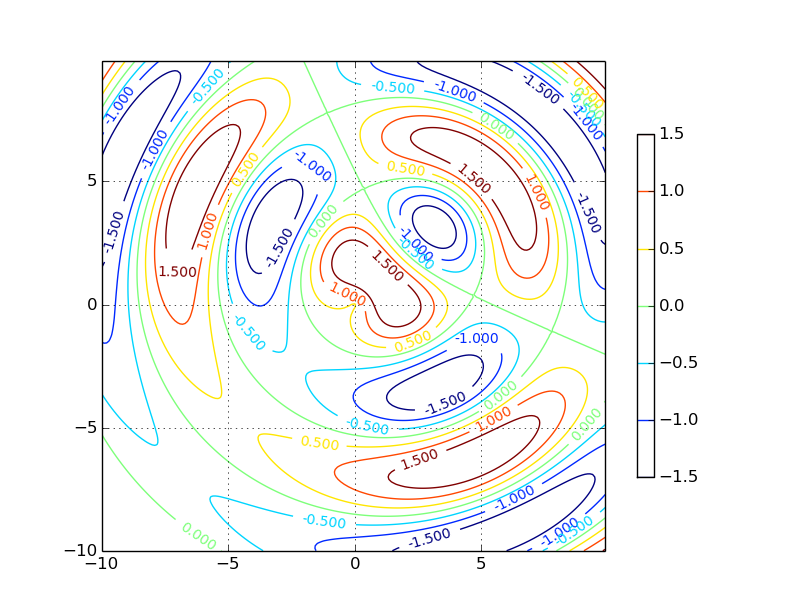
Obrázek 1: Jeden typ grafu podporovaný knihovnou Matplotlib – Funkce typu z=f(x,y) zobrazená formou vrstevnic.
7. Zobrazení jednoduchého grafu
V dalším demonstračním příkladu si ukážeme, jakým způsobem je možné vykreslit jednoduchý liniový graf, a to zcela bez použití knihovny Pandas. Použijeme pouze základní knihovnu csv, dále knihovnu Numpy pro výpočet regresní přímky a konečně knihovnu Matplotlib pro vykreslení grafu z dat načtených ze souboru typu CSV:
#!/usr/bin/env python3
import sys
import csv
import numpy as np
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" kafka_lags.py input_file.csv")
print("Example:")
print(" kafka_lags.py overall.csv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_csv = sys.argv[1]
# Try to open the CSV file specified.
with open(input_csv) as csv_input:
# And open this file as CSV
csv_reader = csv.reader(csv_input)
# Skip header
next(csv_reader, None)
rows = 0
# Read all rows from the provided CSV file
data = [(row[0], int(row[1])) for row in csv_reader]
print(data)
# Linear regression
time = [item[0] for item in data]
messages = [item[1] for item in data]
# Linear regression
x = np.arange(0, len(messages))
coef = np.polyfit(x, messages, 1)
poly1d_fn = np.poly1d(coef)
# Create new histogram graph
plt.plot(messages, "b", poly1d_fn(np.arange(0, len(messages))), 'y--')
# Title of a graph
plt.title("Messages in Kafka")
# Add a label to x-axis
plt.xlabel("Time")
# Add a label to y-axis
plt.ylabel("Messages")
plt.legend(loc="upper right")
# Set the plot layout
plt.tight_layout()
# And save the plot into raster format and vector format as well
plt.savefig("kafka_lags.png")
plt.savefig("kafka_lags.svg")
# Try to show the plot on screen
plt.show()
Po spuštění tohoto příkladu by se měl vykreslit tento graf:

Obrázek 2: Graf zobrazený předchozím demonstračním příkladem.
8. Kooperace mezi Pandas a Matplotlibem
Předchozí příklad byl ve skutečnosti zbytečně složitý a současně ne vždy plně funkční. Data jsme totiž načítali s využitím standardní knihovny csv bez jejich kontroly. A v tomto konkrétním případě byla vstupní data získána exportem z Grafany, která (z nějakého důvodu) přidává na konec souboru prázdný řádek, který není zpracován korektně. Příklad tedy změníme, a to tak, že CSV načteme přímo do datového rámce, což je bezpečnější a současně i z pohledu programátora kratší řešení:
#!/usr/bin/env python3
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_kafka_lags_pandas.py input_file.csv")
print("Example:")
print(" plot_kafka_lags_pandas.py overall.csv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_csv = sys.argv[1]
df = pd.read_csv(input_csv)
print(df.info())
print(df.describe())
# Linear regression
time = df["Time"]
messages = df["topic : uploads"]
# Linear regression
x = np.arange(0, len(messages))
coef = np.polyfit(x, messages, 1)
poly1d_fn = np.poly1d(coef)
# Create new histogram graph
plt.plot(messages, "b", poly1d_fn(np.arange(0, len(messages))), 'y--')
# Title of a graph
plt.title("Messages in Kafka")
# Add a label to x-axis
plt.xlabel("Time")
# Add a label to y-axis
plt.ylabel("Messages")
plt.legend(loc="upper right")
# Set the plot layout
plt.tight_layout()
# And save the plot into raster format and vector format as well
plt.savefig("kafka_lags_pandas.png")
plt.savefig("kafka_lags_pandas.svg")
# Try to show the plot on screen
plt.show()
Výsledek by v tomto případě měl vypadat takto:

Obrázek 3: Graf zobrazený předchozím demonstračním příkladem.
9. Přímé vykreslení grafu bez použití knihovny Matplotlib
Ve skutečnosti je možné jít ve zjednodušování a zkracování programového kódu ještě dále, protože se o vytvoření grafu může postarat přímo knihovna Pandas. Objekt představující datový rámec podporuje i metodu plot pro přímé vykreslení grafu:
df = pd.read_csv(input_csv) # Create new histogram graph df.plot(x="Time", y="topic : uploads")
Samotné vykreslení grafu (či jeho tisk) je provedeno přes Matplotlib:
plt.show()
Úplný zdrojový kód takto upraveného příkladu vypadá následovně (můžeme vidět, že vykreslení je skutečně otázka několika programových řádků):
#!/usr/bin/env python3
import sys
import pandas as pd
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_kafka_lags_pandas_2.py input_file.csv")
print("Example:")
print(" plot_kafka_lags_pandas_2.py overall.csv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_csv = sys.argv[1]
df = pd.read_csv(input_csv)
print(df.info())
print(df.describe())
# Create new histogram graph
df.plot(x="Time", y="topic : uploads")
# Try to show the plot on screen
plt.show()
Výsledek prozatím vypadá jednodušeji, což je ovšem cena za to, že má celý skript délku jen několika řádků:

Obrázek 4: Graf zobrazený předchozím demonstračním příkladem. Povšimněte si, že formátování údajů na osách v žádném případě není dokonalé, takže se mnohdy „ručním“ úpravám na úrovni Matplotlibu nevyhneme.
10. Přidání klouzavého průměru do grafu
Zkusme nyní do grafu přidat i druhý průběh s klouzavým průměrem (tedy s„vyhlazenou“ křivkou). Výpočet klouzavého průměru je relativně přímočarý, pouze musíme zajistit, že se do datového rámce přidá další sloupec s výsledky. Povšimněte si, jak se využívají nám již známé metody df.shape, popř. df.iloc:
for i in range(0, df.shape[0]-2):
df.loc[df.index[i+2], 'SMA_3'] = np.round(((df.iloc[i, 1]+ df.iloc[i+1, 1] +df.iloc[i+2, 1])/3),1)
Nevýhodou tohoto přístupu je fakt, že pokud bude nutné změnit „okno“ pro výpočet klouzavého průměru, bude se muset změnit i samotný zdrojový kód. Lepší řešení si ukážeme v navazující kapitole.
Úplný zdrojový kód takto upraveného demonstračního příkladu vypadá následovně:
#!/usr/bin/env python3
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_kafka_lags_pandas_sma_3.py input_file.csv")
print("Example:")
print(" plot_kafka_lags_pandas_sma_3.py overall.csv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_csv = sys.argv[1]
df = pd.read_csv(input_csv)
for i in range(0, df.shape[0]-2):
df.loc[df.index[i+2], 'SMA_3'] = np.round(((df.iloc[i,1]+ df.iloc[i+1,1] +df.iloc[i+2,1])/3),1)
print(df)
print(df.info())
print(df.describe())
# Create new histogram graph
df.plot(x="Time", y=["topic : uploads", "SMA_3"])
# Try to show the plot on screen
plt.show()
S výsledkem:

Obrázek 5: Graf zobrazený předchozím demonstračním příkladem.
11. Vylepšený výpočet klouzavého průměru
V předchozí kapitole ukázaný výpočet klouzavého průměru byl sice funkční, ovšem nepříliš přehledný. Existuje však i možnost použít při výpočtu přímo možností nabízených samotnou knihovnou Pandas, konkrétně metody rolling a mean. Takto jednoduše lze do datového rámce přidat další sloupec, který bude obsahovat klouzavý průměr hodnot ze sloupce druhého (druhý sloupec má index=1):
df['SMA_3'] = df.iloc[:,1].rolling(window=3).mean()
Výsledný datový rámec bude vypadat následovně:
Time topic : uploads SMA_3 0 2020-12-01 06:14:00 13 NaN 1 2020-12-01 06:14:20 13 NaN 2 2020-12-01 06:14:40 9 11.666667 3 2020-12-01 06:15:00 18 13.333333 4 2020-12-01 06:15:20 18 15.000000 ... ... ... ... 1076 2020-12-01 12:12:40 33 29.666667 1077 2020-12-01 12:13:00 31 30.666667 1078 2020-12-01 12:13:20 31 31.666667 1079 2020-12-01 12:13:40 17 26.333333 1080 2020-12-01 12:14:00 6 18.000000
Úplný zdrojový kód tohoto příkladu:
#!/usr/bin/env python3
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_kafka_lags_pandas_sma_3.py input_file.csv")
print("Example:")
print(" plot_kafka_lags_pandas_sma_3.py overall.csv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_csv = sys.argv[1]
df = pd.read_csv(input_csv)
df['SMA_3'] = df.iloc[:,1].rolling(window=3).mean()
print(df)
print(df.info())
print(df.describe())
# Create new histogram graph
df.plot(x="Time", y=["topic : uploads", "SMA_3"])
# Try to show the plot on screen
plt.show()
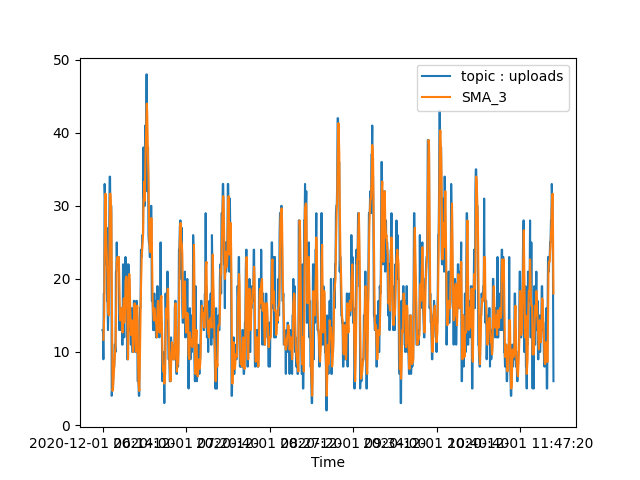
Obrázek 6: Graf zobrazený předchozím demonstračním příkladem.
Změna příkladu tak, aby se počítal klouzavý průměr z dvaceti hodnot, je otázkou jediné úpravy (zvýrazněné tučně):
#!/usr/bin/env python3
import sys
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_kafka_lags_pandas_sma_20.py input_file.csv")
print("Example:")
print(" plot_kafka_lags_pandas_sma_20.py overall.csv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_csv = sys.argv[1]
df = pd.read_csv(input_csv)
df['SMA_20'] = df.iloc[:,1].rolling(window=20).mean()
print(df)
print(df.info())
print(df.describe())
# Create new histogram graph
df.plot(x="Time", y=["topic : uploads", "SMA_20"])
# Try to show the plot on screen
plt.show()
# Create new histogram graph
df.plot(x="Time", y="SMA_20")
# Try to show the plot on screen
plt.show()

Obrázek 7: Graf zobrazený předchozím demonstračním příkladem.

Obrázek 8: Křivka zobrazující pouze průběh klouzavého průměru.
12. Od liniových grafů ke grafům sloupcovým
Vykreslit je možné i sloupcové grafy. V následujícím demonstračním příkladu budou zpracovávána tato data (výsledky benchmarků):
Width Height ANSI C Cython #1 Cython #2 Cython #3 Numba #1/interpret Numba #2 Numba #3 Numba #4 2048 0 0,00 0,03 0,02 0,03 0,03 0,76 5,92 5,89 2048 100 0,06 1,03 0,22 0,08 1,84 2,18 6,22 6,20 2048 200 0,11 2,10 0,42 0,14 3,59 3,56 6,60 6,58 2048 300 0,17 3,17 0,61 0,21 5,56 4,92 6,94 6,93 2048 400 0,23 4,04 0,81 0,26 7,16 6,38 7,30 7,33 2048 500 0,29 5,05 0,99 0,31 9,63 7,90 7,64 7,67 2048 600 0,34 6,16 1,19 0,37 11,62 9,27 8,01 8,04 2048 700 0,40 7,04 1,38 0,43 12,56 10,52 8,38 8,37 2048 800 0,46 8,17 1,56 0,48 14,20 11,99 8,70 8,83 2048 900 0,52 9,51 1,81 0,56 16,23 13,58 9,09 9,19 2048 1000 0,58 10,63 2,18 0,60 17,91 14,89 9,41 9,41 2048 1100 0,64 11,11 2,24 0,66 19,58 16,68 9,90 9,77 2048 1200 0,70 12,48 2,36 0,72 23,49 18,01 10,19 10,15 2048 1300 0,75 13,09 2,67 0,78 23,08 19,33 10,47 10,57 2048 1400 0,81 14,26 2,75 0,83 25,22 20,30 11,11 10,91 2048 1500 0,87 16,19 3,01 0,89 26,88 22,10 11,24 11,47 2048 1600 0,92 16,83 3,13 0,96 28,87 23,56 11,64 11,55 2048 1700 0,98 17,41 3,33 1,01 30,80 24,73 11,98 11,92 2048 1800 1,04 18,25 3,52 1,07 33,12 26,90 12,51 12,71 2048 1900 1,10 20,10 3,71 1,13 33,82 28,46 12,67 12,84 2048 2000 1,16 20,80 3,97 1,18 37,45 29,40 13,44 13,01 2048 2100 1,21 22,08 4,13 1,24 37,80 30,15 13,52 13,39 2048 2200 1,27 23,65 4,49 1,30 39,46 32,09 13,75 13,81 2048 2300 1,33 23,51 4,48 1,36 42,15 33,15 14,07 14,21 2048 2400 1,39 25,66 4,70 1,42 44,28 35,19 14,31 14,38 2048 2500 1,45 25,77 5,07 1,50 46,78 36,94 14,85 14,84 2048 2600 1,51 26,98 5,28 1,53 46,53 38,30 15,12 15,39 2048 2700 1,58 27,82 5,52 1,60 48,47 40,44 15,56 15,40 2048 2800 1,63 28,56 5,48 1,66 50,65 40,87 15,70 15,96 2048 2900 1,68 29,92 5,74 1,73 54,63 44,21 16,49 16,23 2048 3000 1,85 30,59 6,04 1,77 53,87 42,86 16,78 16,46 2048 3100 1,80 31,48 6,11 1,87 55,37 45,98 16,88 17,18 2048 3200 1,85 33,32 6,37 1,89 58,27 45,04 17,12 17,49 2048 3300 1,92 37,60 6,55 1,94 59,18 49,68 17,68 17,79 2048 3400 1,97 36,76 6,72 2,35 61,80 53,67 17,99 17,84 2048 3500 2,03 35,78 6,89 2,06 66,23 52,20 18,99 18,69
Povšimněte si, jaký znak je použit pro reprezentaci plovoucí desetinné čárky/tečky. Data je nutné načíst a posléze zkonvertovat hodnoty v příslušných sloupcích, například takto:
data_columns = ["ANSI C", "Cython #1", "Cython #2", "Cython #3", "Numba #1/interpret", "Numba #2", "Numba #3", "Numba #4"]
for data_column in data_columns:
df[data_column] = pd.to_numeric(df[data_column].str.replace(',', '.'), errors='coerce')
Vykreslení běžného liniového grafu:
df.plot(x="Height", y=data_columns)

Obrázek 9: Liniový graf.
Vykreslení sloupcového grafu je mírně odlišné a vypadá takto:
df.plot.bar(x="Height", y=data_columns)

Obrázek 10: Sloupcový graf.
Opět si pro úplnost ukažme celý zdrojový kód skriptu, který zajistí vykreslení grafů:
#!/usr/bin/env python3
import sys
import pandas as pd
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_benchmark_results_line_chart.py ")
print("Example:")
print(" plot_benchmark_results_line_chart.py data.tsv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_file = sys.argv[1]
df = pd.read_csv(input_file, sep="\t")
data_columns = ["ANSI C", "Cython #1", "Cython #2", "Cython #3", "Numba #1/interpret", "Numba #2", "Numba #3", "Numba #4"]
for data_column in data_columns:
df[data_column] = pd.to_numeric(df[data_column].str.replace(',', '.'), errors='coerce')
print(df)
print()
print(df.info())
print()
print(df.describe())
print()
# Create new histogram graph
df.plot(x="Height", y=data_columns)
# Try to show the plot on screen
plt.show()
#!/usr/bin/env python3
import sys
import pandas as pd
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_benchmark_results_bar_chart.py ")
print("Example:")
print(" plot_benchmark_results_bar_chart.py data.tsv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_file = sys.argv[1]
df = pd.read_csv(input_file, sep="\t")
data_columns = ["ANSI C", "Cython #1", "Cython #2", "Cython #3", "Numba #1/interpret", "Numba #2", "Numba #3", "Numba #4"]
for data_column in data_columns:
df[data_column] = pd.to_numeric(df[data_column].str.replace(',', '.'), errors='coerce')
print(df)
print()
print(df.info())
print()
print(df.describe())
print()
# Create new histogram graph
df.plot.bar(x="Height", y=data_columns)
# Try to show the plot on screen
plt.show()
13. Výběr části datového rámce při vykreslování grafu
Předchozí sloupcový graf nebyl příliš přehledný, protože obsahoval mnoho údajů s rozdílným měřítkem. Samozřejmě nám nic nebrání v tom, abychom z datového rámce vybrali pouze určité řádky. Třída, jejímiž jsou datové rámce instancemi, přetěžuje operátor pro indexaci, takže je možné například napsat:
df = df[5:10]
Tímto přiřazením dojde ke zúžení datového rámce na pět řádků a tudíž i k vykreslení odlišného grafu:

Obrázek 11: Zmenšení datového rámce na pět řádků.
#!/usr/bin/env python3
import sys
import pandas as pd
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_benchmark_results_bar_chart_2.py ")
print("Example:")
print(" plot_benchmark_results_bar_chart_2.py data.tsv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_file = sys.argv[1]
df = pd.read_csv(input_file, sep="\t")
df = df[5:10]
data_columns = ["ANSI C", "Cython #1", "Cython #2", "Cython #3", "Numba #1/interpret", "Numba #2", "Numba #3", "Numba #4"]
for data_column in data_columns:
df[data_column] = pd.to_numeric(df[data_column].str.replace(',', '.'), errors='coerce')
print(df)
print()
print(df.info())
print()
print(df.describe())
print()
# Create new histogram graph
df.plot.bar(x="Height", y=data_columns)
# Try to show the plot on screen
plt.show()
14. Zobecnění předchozího příkladu – zpracování numerických dat ve všech sloupcích
Seznam sloupců:
data_columns = ["ANSI C", "Cython #1", "Cython #2", "Cython #3", "Numba #1/interpret", "Numba #2", "Numba #3", "Numba #4"]
lze nahradit za:
data_columns = df.columns[1:]
což vede k obecnějšímu příkladu, v němž se jména sloupců v explicitně zapsané podobě nevyskytují:
#!/usr/bin/env python3
import sys
import pandas as pd
import matplotlib.pyplot as plt
# Check if command line argument is specified (it is mandatory).
if len(sys.argv) < 2:
print("Usage:")
print(" plot_benchmark_results.py ")
print("Example:")
print(" plot_benchmark_results.py data.tsv")
sys.exit(1)
# First command line argument should contain name of input CSV.
input_file = sys.argv[1]
df = pd.read_csv(input_file, sep="\t")
df = df[10:]
data_columns = df.columns[1:]
for data_column in data_columns:
df[data_column] = pd.to_numeric(df[data_column].str.replace(',', '.'), errors='coerce')
print(df)
print()
print(df.info())
print()
print(df.describe())
print()
# Create new histogram graph
df.plot.bar(x=df.columns[0], y=data_columns)
# Try to show the plot on screen
plt.show()
15. Validace dat v Pythonu
V závěrečné části článku se ve stručnosti budeme zabývat problematikou validace dat v datových rámcích. Validaci dat je možné využít v mnoha oblastech. Představme si například dokumentovou databázi, složitý konfigurační soubor nebo asi nejlépe klasickou webovou službu, která přijme data ve formátu JSON, převede je knihovní funkcí do nativní datové struktury (typicky do slovníku seznamů či hierarchicky uspořádaných slovníků) a následně provede validaci této struktury, ovšem nikoli programově (testováním jednotlivých atributů), ale na základě deklarativního popisu této struktury. Například můžeme specifikovat, že v atributu nazvaném „price“ by mělo být uloženo nezáporné číslo menší než 100000, v atributu pojmenovaném „valid_from“ musí být uložen řetězec odpovídající skutečnému datu (to už nelze otestovat primitivním regulárním výrazem, ale složitějším predikátem) a v atributu „login“ bude buď nick uživatele nebo bude tento atribut obsahovat null/None (popř. alternativně nebude existovat vůbec).
V případě formátu JSON je samozřejmě možné validaci provádět už nad vstupními daty přes JSON Schema, dtto při použití jazyka XML pomocí XML Schema (a dalších podobných nástrojů), ovšem možnosti těchto nástrojů jsou omezené – stále se totiž jedná „pouze“ o DSL, v nichž se složitější kritéria zapisují velmi složitě a většinou i nečitelně.
Nás dnes ovšem bude zajímat především validace tabulkových dat reprezentovaných v knihovně Pandas datovými rámci.
16. Validace s využitím knihovny Voluptuous
Ukažme si nejprve validaci dat s využitím obecné validační knihovny Voluptuous. V příkladu je použito velmi jednoduché schéma předepisující typy dat ve sloupcích:
schema = Schema((int, int, float))
Datovým rámcem můžeme procházet s využitím iterátoru a postupně validovat jeho řádky převedené na pojmenované n-tice (což není nejrychlejší řešení – výhodnější je procházení daty po sloupcích a nikoli po řádcích):
for record in df.itertuples():
validate_item(schema, record)
Celý příklad:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
from voluptuous import Schema
from voluptuous import Invalid
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
def validate_item(schema, data):
try:
print("\n\n")
print(schema)
print(data)
schema(data)
print("pass")
except Exception as e:
print(e)
def validate_data_frame(data_frame):
print()
print("Validation")
print("---------------------------")
schema = Schema((int, int, float))
for record in df.itertuples():
validate_item(schema, record)
df = pandas.read_csv("missing_integer_values.csv")
print_data_frame(df)
validate_data_frame(df)
Ve druhém příkladu je ukázán vlastní validátor představovaný funkcí, která pro nevalidní data vyhodí výjimku:
def pos(value):
if type(value) is not int or value <= 0:
raise Invalid("positive integer value expected, but got {v} instead".format(v=value))
Příklad použití ve schématu:
schema = Schema((pos, pos, float))
Celý příklad:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
from voluptuous import Schema
from voluptuous import Invalid
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
def validate_item(schema, data):
try:
print("\n\n")
print(schema)
print(data)
schema(data)
print("pass")
except Exception as e:
print(e)
def pos(value):
if type(value) is not int or value <= 0:
raise Invalid("positive integer value expected, but got {v} instead".format(v=value))
def validate_data_frame(data_frame):
print()
print("Validation")
print("---------------------------")
schema = Schema((pos, pos, float))
for record in df.itertuples():
validate_item(schema, record)
df = pandas.read_csv("missing_integer_values.csv")
print_data_frame(df)
validate_data_frame(df)
Test, zda třetí sloupec neobsahuje hodnoty NaN:
def pos(value):
if type(value) is not int or value <= 0:
raise Invalid("positive integer value expected, but got {v} instead".format(v=value))
def nnat(value):
if type(value) is not float or math.isnan(value):
raise Invalid("non-NaN value expected, but got {v} instead".format(v=value))
schema = Schema((pos, pos, nnat))
Celý příklad:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import math
from voluptuous import Schema
from voluptuous import Invalid
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
def validate_item(schema, data):
try:
print("\n\n")
print(schema)
print(data)
schema(data)
print("pass")
except Exception as e:
print(e)
def pos(value):
if type(value) is not int or value <= 0:
raise Invalid("positive integer value expected, but got {v} instead".format(v=value))
def nnat(value):
if type(value) is not float or math.isnan(value):
raise Invalid("non-NaN value expected, but got {v} instead".format(v=value))
def validate_data_frame(data_frame):
print()
print("Validation")
print("---------------------------")
schema = Schema((pos, pos, nnat))
for record in df.itertuples():
validate_item(schema, record)
df = pandas.read_csv("missing_integer_values.csv")
print_data_frame(df)
validate_data_frame(df)
Schéma popisující záznam v datovém rámci ve formě mapy_
schema = Schema({
"Index": int,
"_1": posint,
"_2": posint,
"Change": Any(str, float),
"Language": str,
"Ratings": posfloat,
"Changep": float,
})
V tomto případě je ovšem průchod datovým rámcem odlišný a vypadá následovně:
for record in df.itertuples():
schema(record._asdict())
Celý příklad:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import math
from voluptuous import Schema
from voluptuous import Invalid
from voluptuous import Any
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
def validate_item(schema, data):
try:
print("\n")
# print(schema)
print(data)
schema(data._asdict())
print("pass")
except Exception as e:
print(e)
def posint(value):
if type(value) is not int or value <= 0:
raise Invalid("positive integer value expected, but got {v} instead".format(v=value))
def posfloat(value):
if type(value) is not float or value <= 0:
raise Invalid("positive float value expected, but got {v} instead".format(v=value))
def validate_data_frame(data_frame):
print()
print("Validation")
print("---------------------------")
schema = Schema({
"Index": int,
"_1": posint,
"_2": posint,
"Change": Any(str, float),
"Language": str,
"Ratings": posfloat,
"Changep": float,
})
for record in df.itertuples():
validate_item(schema, record)
df = pandas.read_csv("tiobe.tsv", sep="\t")
print_data_frame(df)
validate_data_frame(df)
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import math
from voluptuous import Schema
from voluptuous import Invalid
from voluptuous import Any
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
def validate_item(schema, data):
try:
print("\n")
# print(schema)
print(data)
schema(data._asdict())
print("pass")
except Exception as e:
print(e)
def posint(value):
if type(value) is not int or value <= 0:
raise Invalid("positive integer value expected, but got {v} instead".format(v=value))
def posfloat(value):
if type(value) is not float or value <= 0:
raise Invalid("positive float value expected, but got {v} instead".format(v=value))
def validate_data_frame(data_frame):
print()
print("Validation")
print("---------------------------")
schema = Schema({
"Index": int,
"Year2020": posint,
"Year2019": posint,
"Change": Any(str, float),
"Language": str,
"Ratings": posfloat,
"Changep": float,
})
for record in df.itertuples():
validate_item(schema, record)
colnames = ("Year2020", "Year2019", "Change", "Language", "Ratings", "Changep")
df = pandas.read_csv("tiobe.tsv", sep="\t", names=colnames, header=1)
print_data_frame(df)
validate_data_frame(df)
17. Validace s využitím knihovny Opulent Pandas
Přímo pro účely validace datových rámců je určena knihovna nazvaná Opulent Pandas. Opět si ukažme způsob jejího použití. Schéma dvousloupcového datového rámce může vypadat takto:
schema = Schema({
Required('Block size'): [TypeValidator(int)],
Required('Time to read'): [TypeValidator(int)],
})
Validace obsahu celého rámce je v tomto případě přímočará:
schema.validate(data_frame)
Celý příklad:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import math
from opulent_pandas import Schema, TypeValidator, Required
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
def validate_data_frame(data_frame):
schema = Schema({
Required('Block size'): [TypeValidator(int)],
Required('Time to read'): [TypeValidator(int)],
})
schema.validate(data_frame)
df = pandas.read_csv("integer_values.csv")
print_data_frame(df)
validate_data_frame(df)
Vytvoření vlastního validátoru – ten je tvořen třídou s metodou validate:
class PosintValidator(BaseValidator):
def validate(self, values):
if not (values > 0).all():
raise Error("positive integer value expected")
Schéma s vlastním validátorem a jeho použití pro validaci obsahu celého rámce:
schema = Schema({
Required('Block size'): [PosintValidator()],
Required('Time to read'): [PosintValidator()],
})
schema.validate(data_frame)
Úplný kód příkladu:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import math
from opulent_pandas import Schema, Required, BaseValidator, Error
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
class PosintValidator(BaseValidator):
def validate(self, values):
if not (values > 0).all():
raise Error("positive integer value expected")
def validate_data_frame(data_frame):
schema = Schema({
Required('Block size'): [PosintValidator()],
Required('Time to read'): [PosintValidator()],
})
schema.validate(data_frame)
df = pandas.read_csv("integer_values.csv")
print_data_frame(df)
validate_data_frame(df)
Vzhledem k tomu, že implementace Any nefunguje správně (alespoň ne v současné verzi knihovny), je nutné některé validátory napsat tak, že iterují přes celý sloupec:
class NotNaNValidator(BaseValidator):
def validate(self, values):
for value in values:
if math.isnan(value):
raise Error("regular float value expected, but got: {}".format(value))
A opět ukázka celého příkladu:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import math
from opulent_pandas import Schema, Required, BaseValidator, Error
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
class PosintValidator(BaseValidator):
def validate(self, values):
if not (values > 0).all():
raise Error("positive integer value expected")
class NotNaNValidator(BaseValidator):
def validate(self, values):
for value in values:
if math.isnan(value):
raise Error("regular float value expected, but got: {}".format(value))
def validate_data_frame(data_frame):
schema = Schema({
Required('Block size'): [PosintValidator()],
Required('Time to read'): [NotNaNValidator()],
})
schema.validate(data_frame)
df = pandas.read_csv("missing_integer_values.csv")
print_data_frame(df)
validate_data_frame(df)
Nepatrně složitější zápis vlastního validátoru:
class IntOrNAValidator(BaseValidator):
def validate(self, values):
for value in values:
if (type(value) == np.int64):
return
if not (pandas.isna(value)):
raise Error("Int value or NA expected")
Použitý v příkladu:
#!/usr/bin/env python3
# vim: set fileencoding=utf-8
"""Reading CSV file that contains column with integer values (some are missing)."""
import pandas
import numpy as np
import math
from opulent_pandas import Schema, Required, BaseValidator, TypeValidator, Error, Any
def print_data_frame(df):
print("Data frame")
print("---------------------------")
print(df)
print()
print("Column types")
print("---------------------------")
print(df.dtypes)
class PosintValidator(BaseValidator):
def validate(self, values):
if not (values > 0).all():
raise Error("positive integer value expected")
class IntOrNAValidator(BaseValidator):
def validate(self, values):
for value in values:
if (type(value) == np.int64):
return
if not (pandas.isna(value)):
raise Error("Int value or NA expected")
def validate_data_frame(data_frame):
schema = Schema({
Required('Block size'): [PosintValidator()],
Required('Time to read'): [IntOrNAValidator()],
})
schema.validate(data_frame)
df = pandas.read_csv("missing_integer_values.csv", dtype={"Time to read": "Int64"})
print_data_frame(df)
validate_data_frame(df)
18. Repositář s demonstračními příklady a datovými soubory
Zdrojové kódy všech dnes popsaných demonstračních příkladů určených pro Python 3 a nejnovější stabilní verzi knihovny Pandas byly uloženy do Git repositáře dostupného na adrese https://github.com/tisnik/most-popular-python-libs. V případě, že nebudete chtít klonovat celý repositář (ten je ovšem stále velmi malý, dnes má velikost zhruba několik desítek kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:

Demonstrační příklady načítají následující soubory s daty:
benchmarks1.tsvbenchmarks2.tsv19. Články s informacemi o různých způsobech validace datových struktur
V této kapitole jsou uvedeny odkazy na články, v nichž jsme se zabývali různými způsoby validace datových struktur. Pravděpodobně nejlepší přístup nalezneme v knihovně clojure.spec určené pro jazyk Clojure, ovšem i pro Python existuje několik velmi užitečných knihoven, například již výše zmíněná a použitá knihovna Voluptuous:
- Validace dat s využitím knihovny spec v Clojure 1.9.0
https://www.root.cz/clanky/validace-dat-s-vyuzitim-knihovny-spec-v-clojure-1–9–0/ - Validace dat s využitím knihovny spec v Clojure 1.9.0 (dokončení)
https://www.root.cz/clanky/validace-dat-s-vyuzitim-knihovny-spec-v-clojure-1–9–0-dokonceni/ - Validace datových struktur v Pythonu pomocí knihoven Schemagic a Schema
https://www.root.cz/clanky/validace-datovych-struktur-v-pythonu-pomoci-knihoven-schemagic-a-schema/ - Validace datových struktur v Pythonu (2. část)
https://www.root.cz/clanky/validace-datovych-struktur-v-pythonu-2-cast/ - Validace datových struktur v Pythonu (dokončení)
https://www.root.cz/clanky/validace-datovych-struktur-v-pythonu-dokonceni/
20. Odkazy na Internetu
- Plotting with matplotlib
https://pandas.pydata.org/pandas-docs/version/0.13/visualization.html - Plot With Pandas: Python Data Visualization for Beginners
https://realpython.com/pandas-plot-python/ - Pandas Dataframe: Plot Examples with Matplotlib and Pyplot
https://queirozf.com/entries/pandas-dataframe-plot-examples-with-matplotlib-pyplot - Opulent-Pandas na PyPi
https://pypi.org/project/opulent-pandas/ - pandas_validator na PyPi
https://pypi.org/project/pandas_validator/ - pandas-validator (dokumentace)
https://pandas-validator.readthedocs.io/en/latest/ - 7 Best Python Libraries for Validating Data
https://www.yeahhub.com/7-best-python-libraries-validating-data/ - Universally unique identifier (Wikipedia)
https://en.wikipedia.org/wiki/Universally_unique_identifier - Nullable integer data type
https://pandas.pydata.org/pandas-docs/stable/user_guide/integer_na.html - pandas.read_csv
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html - How to define format when using pandas to_datetime?
https://stackoverflow.com/questions/36848514/how-to-define-format-when-using-pandas-to-datetime - Pandas : skip rows while reading csv file to a Dataframe using read_csv() in Python
https://thispointer.com/pandas-skip-rows-while-reading-csv-file-to-a-dataframe-using-read_csv-in-python/ - Skip rows during csv import pandas
https://stackoverflow.com/questions/20637439/skip-rows-during-csv-import-pandas - Denni kurz
https://www.cnb.cz/cs/financni_trhy/devizovy_trh/kurzy_devizoveho_trhu/denni_kurz.txt - UUID objects according to RFC 4122 (knihovna pro Python)
https://docs.python.org/3.5/library/uuid.html#uuid.uuid4 - Object identifier (Wikipedia)
https://en.wikipedia.org/wiki/Object_identifier - Digital object identifier (Wikipedia)
https://en.wikipedia.org/wiki/Digital_object_identifier - voluptuous na (na PyPi)
https://pypi.python.org/pypi/voluptuous - Repositář knihovny voluptuous na GitHubu
https://github.com/alecthomas/voluptuous - pytest-voluptuous 1.0.2 (na PyPi)
https://pypi.org/project/pytest-voluptuous/ - pytest-voluptuous (na GitHubu)
https://github.com/F-Secure/pytest-voluptuous - schemagic 0.9.1 (na PyPi)
https://pypi.python.org/pypi/schemagic/0.9.1 - Schemagic / Schemagic.web (na GitHubu)
https://github.com/Mechrophile/schemagic - schema 0.6.7 (na PyPi)
https://pypi.python.org/pypi/schema - schema (na GitHubu)
https://github.com/keleshev/schema - XML Schema validator and data conversion library for Python
https://github.com/brunato/xmlschema - xmlschema 0.9.7
https://pypi.python.org/pypi/xmlschema/0.9.7 - jsonschema 2.6.0
https://pypi.python.org/pypi/jsonschema - warlock 1.3.0
https://pypi.python.org/pypi/warlock - Python Virtual Environments – A Primer
https://realpython.com/python-virtual-environments-a-primer/ - pip 1.1 documentation: Requirements files
https://pip.readthedocs.io/en/1.1/requirements.html - unittest.mock — mock object library
https://docs.python.org/3.5/library/unittest.mock.html - mock 2.0.0
https://pypi.python.org/pypi/mock - An Introduction to Mocking in Python
https://www.toptal.com/python/an-introduction-to-mocking-in-python - Unit testing (Wikipedia)
https://en.wikipedia.org/wiki/Unit_testing - Unit testing
https://cs.wikipedia.org/wiki/Unit_testing - Test-driven development (Wikipedia)
https://en.wikipedia.org/wiki/Test-driven_development - Pip (dokumentace)
https://pip.pypa.io/en/stable/ - 5 Differences between clojure.spec and Schema
https://lispcast.com/clojure.spec-vs-schema/ - Schema: Clojure(Script) library for declarative data description and validation
https://github.com/plumatic/schema - clojure.spec – Rationale and Overview
https://clojure.org/about/spec

































