
ZIP je a hlavně byl velmi rozšířený a populární program pro archivaci a kompresi dat. První program PKZIP vznikl již v roce 1989. V současnosti v Linuxu a jiných Unixech použijete patrně open source Info-ZIP (zip a unzip ) a ve Windows například WinZip, 7-Zip nebo třeba PeaZip. Poslední dva najdete i v Linuxu (nedávno se objevila oficiální linuxová verze 7-Zip).
Formát souboru ZIP umožňuje několik kompresních algoritmů: Store (bez komprese), Shrink (LZW), Reduce, Implode, Deflate a další. V současnosti se používá hlavně algoritmus Deflate, protože má nejlepší kompresi. Byl však přidán až do PKZIP 2 v roce 1993. Deflate se také používá v knihovně zlib, v programu gzip a také kupříkladu v souborech PNG, EPUB, ODT a DOCX.
Zajímavá je také vlastní struktura souboru ZIP, kdy až na konci najdeme Central Directory. Zde je seznam souborů, odkaz na jejich polohu v ZIP souboru, jejich kontrolní součet CRC-32, datum vytvoření souboru, velikost komprimovaná a nekomprimovaná a další informace. Patrně se vám již někdy stalo, že jste stáhli ZIP soubor necelý a on se odmítl rozbalit. To právě je způsobené chybějícím Central Directory na konci souboru. Tato vlastnost také umožňuje pěknou hříčku, jak vytvořit soubor, který se chová zároveň jako PNG i jako ZIP.
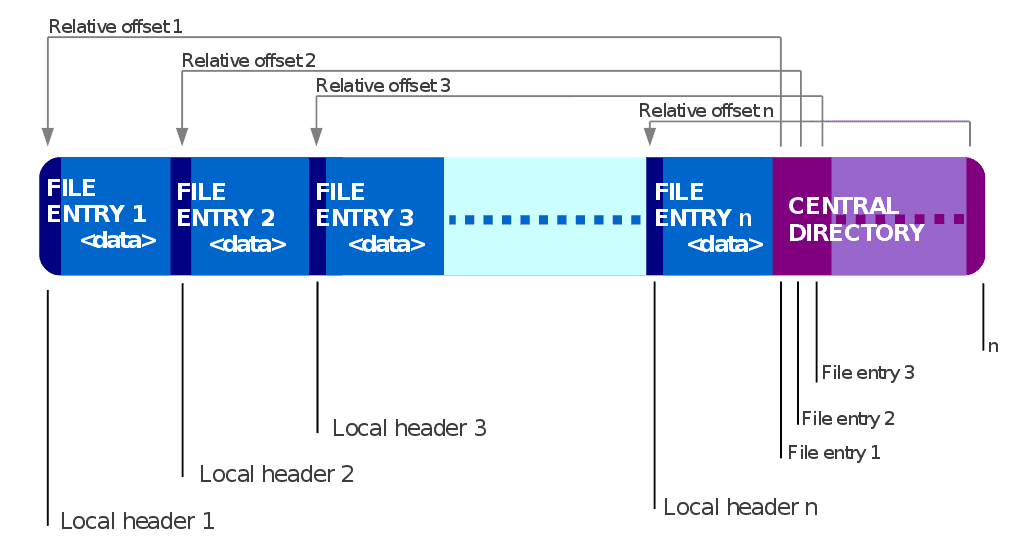
Struktura souboru ZIP
Nedávno se v pěkném článku kompresním algoritmům v souborech ZIP věnoval Hans Wennborg a my si tu s jeho svolením jeho článek přeložíme. Pokud někoho zajímá, jakým algoritmem jsou komprimovány soubory v nějakém souboru ZIP, tak k tomu slouží nástroj zipinfo z již zmíněného Info-ZIP. U jednotlivých souborů můžeme vidět například stor, re, shrk, defS, defF, defN a defX (Deflate superfast, fast, normal a maximum). Info-ZIP umí použít při kompresi jen Store ( -0) a Deflate ( -1 – -2 defF, -2 – -7 defN, -8 – -9 defX), výchozí je volba -6. Dekomprimovat umí samozřejmě všechny algoritmy. Pokud chcete experimentovat s ostatními metodami komprese, můžete použít například hwzip právě od Hanse Wennborga. Také doporučuji se podívat do jeho zdrojových kódů.
Store
Při použití Store jsou data pouze uložena, není provedena žádná komprese. Touto metodou jsou ukládány například prázdné soubory a adresáře. Jinak tento algoritmus není příliš zajímavý.
Shrink, Unshrink
Shrink je variantou kompresního algoritmu LZW (Lempel-Ziv-Welch), který se objevil v roce 1984 ve známém článku. Algoritmus LZW se používá ve starém známém unixovém nástroji Compress, který vytváří soubory .Z. Dále se LZW používá v grafických souborech GIF. LZW však bylo patentované. To pomohlo rozvoji formátu PNG a nástroje gzip, které oba používají svobodný Deflate. Mimochodem LZW patenty vypršely v roce 2004.
Algoritmus LZW
Algoritmus LZW je založen na slovníku. Vstup je rozložen na řetězce, které se nacházejí ve slovníku a výstup jsou kódy, které odkazují na řetězce ve slovníku. Slovník se postupně vytváří a rozšiřuje při kompresi. Přitom se slovník nemusí ukládat do archivu, ale je při dekompresi znovu rekonstruován.
Na začátku jsou ve slovníku všechny povolené jednobajtové znaky. Pokud se ve vstupu objeví řetězec, který již ve slovníku je, automaticky přidáváme řetězec s přidaným dalším znakem ze vstupu.
Příklad
Zkusíme zkomprimovat řetězec s 28 znaky „tri sta tricet tri strikacek“. Jako počáteční slovník použijeme jen písmena. V původním LZW algoritmu jsou ve slovníku všechny osmibitové znaky 0–255. Kódy 256–4095 jsou rezervovány pro další kombinace znaků, které se ve zdroji postupně vyskytnou.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| _ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
Ze vstupu vezmeme znaky, které jsou ve slovníku a jejich kód pošleme na výstup. Tyto znaky rozšíříme o následující znak a automaticky přidáme do slovníku s dalším volným kódem. Tak postupně rozšiřujeme slovník a podobně postupujeme po zbytek vstupního řetězce.
| Vstup | Výstup | Rozšířený slovník |
| T | 20 | |
| R | 18 | TR=27 |
| I | 9 | RI=28 |
| _ | 0 | I_=29 |
| S | 19 | _S=30 |
| T | 20 | ST=32 |
| A | 1 | TA=33 |
| _ | 0 | A_=34 |
| TR | 27 | _TR=35 |
| I | 9 | TRI=36 |
| C | 3 | IC=37 |
| E | 5 | CE=38 |
| T | 20 | ET=39 |
| _TR | 35 | T_TR=40 |
| I | 9 | _TRI=41 |
| _S | 30 | I_S=42 |
| TRI | 36 | _STRI=43 |
| K | 11 | TRIK=44 |
| A | 1 | KA=45 |
| CE | 38 | ACE=46 |
| K | 11 | CEK=47 |
Vstupní řetězec o délce 28 je zkomprimován do kódu o délce 21. Dlouhý anglický text se pomocí LZW zkomprimuje v poměru asi 2:1. Podobně postupujeme při dekompresi, kde také postupně rekonstruujeme rozšířený slovník.
| Vstup | Výstup | Rozšířený slovník |
| 20 | T | |
| 18 | R | TR=27 |
| 9 | I | RI=28 |
| 0 | _ | I_=29 |
| 19 | S | _S=30 |
| 20 | T | ST=32 |
| 1 | A | TA=33 |
| 0 | _ | A_=34 |
| 27 | TR | _TR=35 |
| 9 | I | TRI=36 |
| 3 | C | IC=37 |
| 5 | E | CE=38 |
| 20 | T | ET=39 |
| 35 | _TR | T_TR=40 |
| 9 | I | _TRI=41 |
| 30 | _S | I_S=42 |
| 36 | TRI | _STRI=43 |
| 11 | K | TRIK=44 |
| 1 | A | KA=45 |
| 38 | CE | ACE=46 |
| 11 | K | CEK=47 |
Slovník
Implementace LZW v PKZIP tedy Shrink ukládá slovník jako prefixový strom tzv. trie. To jednak šetří paměť a také zrychluje vyhledávání.
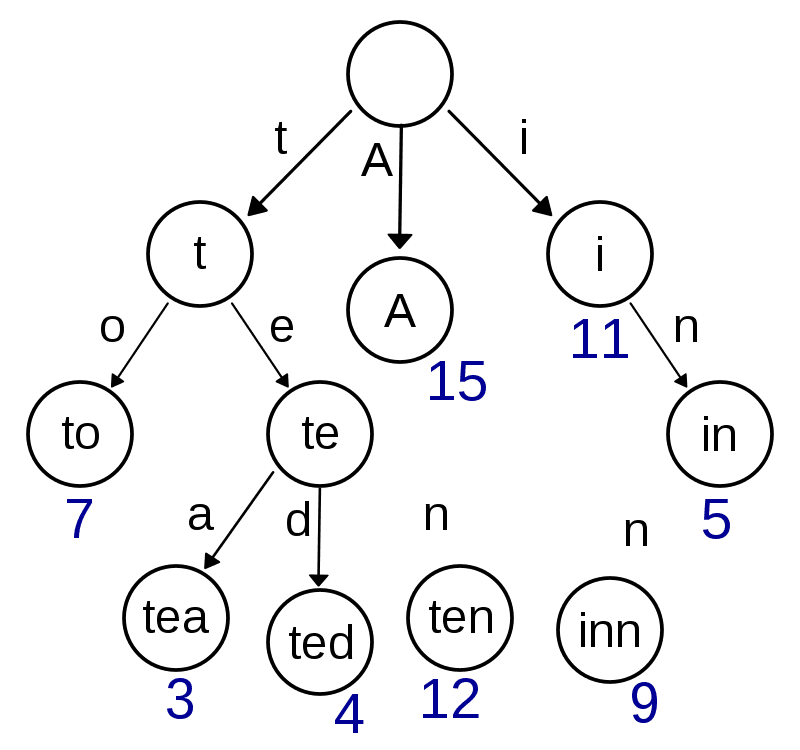
Příklad trie
Další otázkou je, jak dlouhý slovník a tedy jak dlouhé kódy použít. Pro 8bitové bajty musíme použít nejméně 9bitové kódy. Větší kódy umožňují větší slovník a tedy lepší kompresi, ale pro vstupy bez opakování může pak být naopak výstup delší.
Jak jsme již řekli, tak původní LZW algoritmus používal pro 8bitový vstup 12bitové kódy. Většina implementací však používá variabilní délku kódů. Například program Compress začíná na 9 bitech a může dosáhnout až 16 bitů. GIF začíná s 3–9 bity podle barevné hloubky obrázku a může růst až na 12 bitů. U Compress i GIF se kód zvětšuje automaticky.
PKZIP Shrink používá kódy dlouhé 9 – 13 bitů a používá specifický kód (256), jak dekodéru oznámit, že kódy byly zvětšeny.
Plný slovník
Dalším problémem může být plný slovník, jak se řetězce neustále přidávají do slovníku, který je shora omezen maximální dálkou kódu. Například původní Compress v takovém případě nedělá nic, pokračuje zpracovávat vstup, jen již nepřidává nic do slovníku. Problémem je, že slovník už není aktuální a kompresní poměr se postupně zhoršuje.
Druhou možností je smazání slovníku, když se zaplní, a ten se začne vytvářet znova. Takto postupuje například GIF. Smazání slovníku je řízeno speciálním kódem, který kompresor může použít kdykoli, nejen při plném slovníku.
Compress od verze 3.0 po zaplnění slovníku testuje kompresní poměr a když klesne, tak resetuje slovník. Toto se nazývá adaptivní reset.
Shrink jde ještě dále a umožňuje částečný reset, kdy jsou odebrány řetězce, které pod sebou ve stromě již nemají další řetězce a tedy se ve vstupu zatím objevily jen jednou.

Tímto končí povídání o Shrink. Příště se můžete těšit na Reduce.
Hlavní odkazy
- Článek Hanse Wennborga
- Jeho hwzip
- ZIP na Wikipedii anglicky
- ZIP na Wikipedii česky
- LZW na Wikipedii anglicky
- LZW na Wikipedii česky
Seriál vzniká jako překlad původního článku s laskavým svolením původního autora, kterým je Hans Wennborg.



































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU