Obsah
1. Nástroj huey aneb další užitečná knihovna pro práci s frontami úloh v Pythonu
2. Základní vlastnosti systému huey
3. Porovnání Huey s dalšími podobně koncipovanými nástroji
5. Instalace a spuštění Redisu
6. Ověření základní funkcionality Redisu
7. Naprogramování a spuštění konzumenta zpráv (workera)
8. Naplánování úlohy pro workera
9. Čekání na výsledek činnosti workera
11. Větší množství úloh zpracovaných jediným workerem
12. Větší množství úloh zpracovaných množinou workerů
13. Získání dalších informací o úloze
14. Chování systému při havárii úlohy ve workerovi
15. Naplánování periodicky se opakující úlohy
16. Korektní spuštění skupiny úloh
18. Plánování různých úloh s odlišnou implementací workerů
19. Repositář s demonstračními příklady
1. Nástroj huey aneb další užitečná knihovna pro práci s frontami úloh v Pythonu
V poněkud nepravidelně vycházejícím seriálu o message brokerech a na nich založených technologiích jsme se již setkali s relativně velkým množstvím projektů určených pro programovací jazyk Python, které vývojářům zprostředkovávají vysokoúrovňové rozhraní k message brokerům popř. pro naplánování asynchronně spouštěných úloh. Jen pro úplnost si připomeňme, že se jedná především o projekty nazvané RQ (Redis Queue) (pravděpodobně nejsnadněji použitelný systém vůbec), Celery (ten naproti tomu nabízí největší možnosti konfigurace) či Dramatiq. Na podobném způsobu práce, tj. na plánování úloh s jejich pozdějším a navíc i asynchronním zpracováním (více) workery je založen i projekt nazvaný Huey, jímž se budeme zabývat v dnešním článku.
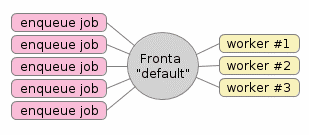
Obrázek 1: Typická a již několikrát ukázaná konfigurace systému s frontami úloh. Zde se konkrétně používá jediná fronta nazvaná „default“, do které se mohou úlohy přidávat několika programy (těch může být libovolné množství). Samotné zpracování úloh je reprezentováno ve workerech, kterých taktéž může být libovolné množství podle požadavků aplikace, dostupných zdrojů atd. atd. Navíc je možné, aby v systému existovalo větší množství pojmenovaných front. Fronty je tak možné rozdělit podle priority, typu zpracovávaných úloh apod. Existuje dokonce jedna fronta, do níž se ukládají ty úlohy, na nichž worker zhavaroval (což si vysvětlíme v dalším textu).
Zdrojové kódy tohoto projektu nalezneme na GitHubu, konkrétně na stránce https://github.com/coleifer/huey. K dispozici je pochopitelně i dokumentace nasdílená na stránkách Read the Docs a celý projekt je dostupný i ve formě běžného Pythonovského balíčku na serveru Python Package Index (PyPI). Celá instalace, kterou si popíšeme v navazujících kapitolách, je prakticky bezproblémová, ovšem následně je nutné zvolit metodu pro uložení jednotlivých úloh, což již většinou vyžaduje konfiguraci Redisu, SQLite či dalších služeb.
2. Základní vlastnosti systému huey
Základní koncept, na němž je huey postaven, se prakticky neliší od podobně koncipovaných projektů zmíněných již v úvodní kapitole. Jedná se o plánování úloh zpracovávaných samostatně běžícími workery, kteří mohou výsledky posílat (přes message brokera) zpět. Navíc má ovšem Huey i několik zajímavých vlastností, které ho do jisté míry odlišují od klasických systémů pro plánování úloh. Zejména mají vývojáři a administrátoři poměrně velkou volnost ve volbě systému pro uložení zpráv (reprezentujících jednotlivé úlohy). Použít lze Redis (což se zdá být v této oblasti klasické a v praxi ověřené řešení), SQLite a popř. i uložení zpráv pouze v operační paměti. Zajímavější jsou ovšem možnosti spouštění workerů. Těch může být prakticky libovolné množství a lze použít spuštění každého workera ve vlastním procesu (tj. každý worker poběží zcela izolovaně od ostatních workerů), ve vláknech jediného procesu popř. lze použít takzvané greenlety. Záleží tedy na konkrétních požadavcích, který způsob je nejvíc vyhovující, samozřejmě ovšem s tím, že multivláknové řešení nutně dříve či později narazí na Global interpreter lock – GIL, s čímž je nutné počítat.
Ovšem i přesto, že je Huey pojat poměrně minimalisticky, v něm nalezneme i další relativně pokročilé techniky. Například je umožněno naplánování úloh na určitou dobu popř. až po uplynutí nějaké doby (což vzdáleně odpovídá možnostem příkazů cron a at). Dále je možné vytvořit úlohy spouštěné opakovaně, tedy opět podobným způsobem, jaký známe na úrovni operačního systému a nástroje cron. Úlohy je možné i prioritizovat popř. si zvolit, kam se mají uložit jejich výsledky (na které se tedy nemusí aktivně čekat). A konečně je podporována i tvorba pipeline a zřetězení úloh, což je téma, kterému se budeme věnovat v pozdějším textu.
3. Porovnání Huey s dalšími podobně koncipovanými nástroji
V následující tabulce jsou pro větší přehlednost porovnány čtyři systémy s implementací front zpráv (většinou spojených i s plánováním úloh) pro programovací jazyk Python, samozřejmě včetně dnes popisovaného projektu Huey:
| # | Vlastnost | Dramatiq | Celery | Huey | RQ |
|---|---|---|---|---|---|
| 1 | podpora Pythonu 2 | ❌ | ✓ | ✓ | ✓ |
| 2 | jednoduchá implementace | ✓ | ❌ | ✓ | ✓ |
| 3 | automatické přeposlání zhavarovaných úloh | ✓ | ❌ | ✓ | ❌ |
| 4 | zajištění doručení úlohy | ✓ | ❌ | ❌ | ❌ |
| 5 | omezení počtu zpráv | ✓ | ❌ | ✓ | ❌ |
| 6 | specifikace priority úlohy | ✓ | ❌ | ❌ | ❌ |
| 7 | úlohy naplánované na pozdější dobu | ✓ | ✓ | ✓ | ❌ |
| 8 | plánování úloh ve stylu cronu | ❌ | ✓ | ✓ | ❌ |
| 9 | podpora pro kolony (pipeline) | ✓ | ✓ | ✓ | ❌ |
| 10 | možnost uložení výsledků do databáze (Redis…) | ✓ | ✓ | ✓ | ✓ |
| 11 | automatické znovunačtení kódu workera při změně | ✓ | ❌ | ❌ | ❌ |
| 12 | podpora RabbitMQ jako brokera | ✓ | ✓ | ✓ | ❌ |
| 13 | podpora Redisu jako brokera | ✓ | ✓ | ✓ | ✓ |
| 14 | podpora brokera umístěného v paměti | ✓ | ❌ | ✓ | ❌ |
| 15 | podpora greenletů | ✓ | ✓ | ✓ | ❌ |
4. Instalace balíčku huey
Již v úvodní kapitole jsme si řekli, že na serveru PyPi je k dispozici balíček huey, což mj. znamená, že by instalace měla být velmi jednoduchá. Projekt neobsahuje žádné nativní části a lze ho (podle očekávání) nainstalovat i lokálně, tj. pro aktuálně přihlášeného uživatele:
$ pip3 install --user huey
Collecting huey
Downloading https://files.pythonhosted.org/packages/c8/9e/251085ab3369ca71448812cac43ec3fc6f23dd9dd8df162b8bbe8024b672/huey-2.2.0.tar.gz (622kB)
100% |████████████████████████████████| 624kB 896kB/s
Installing collected packages: huey
Running setup.py install for huey ... done
Successfully installed huey-2.2.0
Rychlá kontrola instalace provedená přímo v REPLu programovacího jazyka Python může vypadat například takto:
$ python3
Python 3.6.6 (default, Jul 19 2018, 16:29:00)
[GCC 7.3.1 20180303 (Red Hat 7.3.1-5)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import huey
>>> help(huey)
Help on package huey:
NAME
huey
PACKAGE CONTENTS
api
bin (package)
constants
Před použitím tohoto balíčku však ještě musíme doinstalovat Redis použitý pro uložení úloh a popř. i jejich výsledků.
5. Instalace a spuštění Redisu
Systém Huey může používat hned několik způsobů ukládání zpráv do nějakého úložiště, které by mělo přežít restart samotného plánovače úloh. Nejlépe se mi osvědčilo použití již několikrát zmíněného systému Redis (viz též články Databáze Redis (nejenom) pro vývojáře používající Python a Databáze Redis (nejenom) pro vývojáře používající Python (dokončení), v nichž jsme se s tímto systémem alespoň na základní úrovni seznámili), takže si před odzkoušením demonstračních příkladů Redis nainstalujeme a spustíme. Samotná instalace je ve skutečnosti velmi snadná, protože systém Redis je dnes nabízen jako standardní balíček ve většině Linuxových distribucí. Příkladem mohou být distribuce založené na RPM balíčcích, v nichž se dnes instalace provede následovně:
$ sudo dnf install redis
popř. na starších systémech:
$ sudo yum install redis
Na systémech založených na Debianu (včetně Ubuntu) lze pro instalaci použít příkaz:
$ apt-get install redis-server
Teoreticky je možné pro práci s Redisem, přesněji řečeno pro jeho spuštění jako služby, ponechat většinu standardních nastavení, ovšem výhodnější bude (zejména pro první seznamování) minimálně omezit viditelnost běžícího serveru pouze pro lokální procesy. Jedno z možných nastavení bylo popsáno zde. Toto nastavení je možné získat příkazem:
$ wget https://raw.githubusercontent.com/tisnik/presentations/master/redis/redis.conf
Po nastavení (popř. po ponechání standardního nastavení) je možné systém Redis spustit jako službu (démona), a to příkazem:
$ redis-server redis.conf
Služba redis by se měla spustit, což je patrné i při pohledu do logovacího souboru:
15018:C 13 Jun 20:28:15.250 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
15018:C 13 Jun 20:28:15.250 # Redis version=4.0.10, bits=64, commit=00000000, modified=0, pid=15018, just started
15018:C 13 Jun 20:28:15.250 # Configuration loaded
15018:C 13 Jun 20:28:15.250 * supervised by systemd, will signal readiness
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 4.0.10 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 15018
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
15018:M 13 Jun 20:28:15.253 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
15018:M 13 Jun 20:28:15.253 # Server initialized
15018:M 13 Jun 20:28:15.254 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_
15018:M 13 Jun 20:28:15.254 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues wi
15018:M 13 Jun 20:28:15.254 * DB loaded from disk: 0.000 seconds
15018:M 13 Jun 20:28:15.254 * Ready to accept connections
6. Ověření základní funkcionality Redisu
Na druhém terminálu pak již můžeme spustit klienta Redisu, který uživatelům nabízí interaktivní příkazový řádek:
$ redis-cli
Pokud služba neběží popř. pokud běží na neznámém portu, vypíše se:
Could not connect to Redis at 127.0.0.1:6379: Connection refused Could not connect to Redis at 127.0.0.1:6379: Connection refused
Po doufejme že úspěšném připojení si příkazem „ping“ můžeme otestovat, jestli se klient připojí k serveru a zda od něj dokáže získávat odpovědi:
127.0.0.1:6379> ping PONG 127.0.0.1:6379> ping test "test"
K dispozici je i neinteraktivní příkaz „help“:
127.0.0.1:6379> help
redis-cli 4.0.10
To get help about Redis commands type:
"help @<group>" to get a list of commands in <group>
"help <command>" for help on <command>
"help <tab>" to get a list of possible help topics
"quit" to exit
To set redis-cli preferences:
":set hints" enable online hints
":set nohints" disable online hints
Set your preferences in ~/.redisclirc
7. Naprogramování a spuštění konzumenta zpráv (workera)
Nyní si již můžeme vytvořit jednoduchého konzumenta zpráv neboli workera. Ten bude obsahovat funkci add, která však nebude volána přímo jiným kódem, ale nepřímo – přes frontu zpráv a tedy i s využitím message brokera:
def add(a, b):
"""Úloha pro součet dvou hodnot."""
return a + b
Samotnou funkci je nutné opatřit dekorátorem huey.task(), přičemž huey je objekt získaný konstruktorem FileHuey, RedisHuey, SqliteHuey popř. MemoryHuey, tedy podle toho, jaká metoda pro meziuložení zpráv má být použita. V našem případě používáme systém Redis a tudíž využijeme konstruktor nazvaný RedisHuey. Úplný zdrojový kód workera může vypadat následovně:
"""Úloha pro součet dvou hodnot."""
from huey import RedisHuey
huey = RedisHuey()
@huey.task()
def add(a, b):
"""Úloha pro součet dvou hodnot."""
return a + b
Workera spustíme příkazem:
$ huey_consumer.py adder.huey
Po spuštění by se na terminálu měla objevit zpráva o tom, že byl konzument (worker) spuštěn, a to v jediném procesu a jediném vláknu. Taktéž se zobrazí informace o tom, jaký příkaz (posílaný do fronty) či příkazy jsou dostupné:
[2020-06-16 17:42:26,765] INFO:huey.consumer:MainThread:Huey consumer started with 1 thread, PID 28279 at 2020-06-16 15:42:26.765337 [2020-06-16 17:42:26,765] INFO:huey.consumer:MainThread:Scheduler runs every 1 second(s). [2020-06-16 17:42:26,765] INFO:huey.consumer:MainThread:Periodic tasks are enabled. [2020-06-16 17:42:26,765] INFO:huey.consumer:MainThread:The following commands are available: + adder.add
Tento terminál i s běžícím workerem si nechte otevřený na pozadí. Plánovač úloh bude spuštěn v jiném terminálu.
8. Naplánování úlohy pro workera
V dalším kroku pro workera naplánujeme úlohu. Worker dokáže – alespoň prozatím – pouze sečíst dvě čísla (popř. jiné objekty, například spojit řetězce nebo seznamy), takže naplánování úlohy může vypadat v první verzi následovně:
"""Vytvoření úlohy.""" from adder import add r = add(1, 2) print(r)
Tento skript, který by měl být umístěn ve stejném adresáři jako worker, spustíme:
$ python3 call_adder.py
Měla by se na jeho standardní výstup vypsat zpráva podobná této zprávě:
<Result: task 310a2bf1-a82b-4fe3-9fce-d6171f168fe9>
A současně by se na terminálu se spuštěným workerem měla vypsat zpráva o tom, že byla úloha spuštěna a o několik milisekund později i dokončena. Povšimněte si, že UUID úlohy skutečně odpovídá identifikátoru vypsaného v předchozím skriptu:
[2020-06-16 17:43:41,179] INFO:huey:Worker-1:Executing adder.add: 11bbcf0d-2b24-4c3e-9a2a-3122ef94e225 [2020-06-16 17:43:41,180] INFO:huey:Worker-1:adder.add: 11bbcf0d-2b24-4c3e-9a2a-3122ef94e225 executed in 0.000s
Co to tedy znamená? Úloha byla evidentně naplánována, byla dokonce workerem provedena (a to asynchronně), ovšem my prozatím nevíme, jakým způsobem získat výsledek – proměnná r totiž tímto výsledkem není, protože se jedná o objekt představující samotnou úlohu (job).
9. Čekání na výsledek činnosti workera
Výsledek úlohy je teoreticky možné získat přímým zavoláním r() (budeme se tedy k r chovat jako k běžné funkci), ovšem v praxi to nebude tak jednoduché, protože úloha je spuštěna a vyhodnocena asynchronně, tedy nezávisle na kódu/skriptu, který ji vyvolal. Proto – pokud skutečně potřebujeme na výsledek úlohy počkat – je nutné při volání r() použít nepovinný parametr blocking nastavený na hodnotu True. Existence tohoto parametru zajistí, že volající skript bude skutečně čekat na dokončení úlohy. Taktéž je možné specifikovat i timeout, který umožní zadání maximálního času čekání (což je pro některé řešené problémy vhodnější, než obecně nekonečné čekání):
"""Vytvoření úlohy.""" from adder import add r = add(1, 2) print(r) print(r()) print(r(blocking=True))
Chování při spuštění ověří, že první volání r() prozatím nevrátí správný výsledek (přesněji řečeno vrátí None), kdežto druhé volání již ano:
<Result: task d5cddf26-9b4f-4653-aa4d-89d7d7d14be6> None 3
10. Déletrvající úloha
Nyní workera zastavíme, a to konkrétně v jeho vlastním terminálu klávesovou zkratkou Ctrl+C:
^C[2020-06-13 20:35:02,002] INFO:huey.consumer:MainThread:Received SIGINT [2020-06-13 20:35:02,002] INFO:huey.consumer:MainThread:Shutting down gracefully... [2020-06-13 20:35:02,883] INFO:huey.consumer:MainThread:All workers have stopped. [2020-06-13 20:35:02,884] INFO:huey.consumer:MainThread:Consumer exiting.
Spustíme totiž jiného workera, který bude obsahovat stejný algoritmus součtu, ovšem s přidanou pětisekundovou prodlevou (viz též je úplný zdrojový kód):
"""Úloha pro součet dvou hodnot."""
from huey import RedisHuey
from time import sleep
huey = RedisHuey()
@huey.task()
def add(a, b):
"""Úloha pro součet dvou hodnot."""
sleep(5)
return a + b
Upravený kód workera je uložen v souboru slow_adder.py a spuštěn tedy bude takto:
$ huey_consumer.py slow_adder.huey [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:Huey consumer started with 1 thread, PID 29059 at 2020-06-16 15:53:15.881169 [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:Scheduler runs every 1 second(s). [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:Periodic tasks are enabled. [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:The following commands are available: + slow_adder.add
Znovu zkusíme naplánovat úlohu a získat její výsledky:
"""Vytvoření úlohy.""" from slow_adder import add r = add(1, 2) print(r) print(r()) print(r(blocking=True))
Po spuštění získáme poslední řádek až s přibližně pětisekundovým zpožděním:
<Result: task 287017ca-9435-4c76-9070-3a23c31bc6c0> None 3
Totéž zpoždění je velmi dobře viditelné i v logu workera:
[2020-06-16 19:45:55,423] INFO:huey:Worker-1:Executing slow_adder.add: 287017ca-9435-4c76-9070-3a23c31bc6c0 [2020-06-16 19:46:00,427] INFO:huey:Worker-1:slow_adder.add: 287017ca-9435-4c76-9070-3a23c31bc6c0 executed in 5.003s
11. Větší množství úloh zpracovaných jediným workerem
Zajímavější bude pozorování toho, co se stane, pokud naplánujeme úloh více a posléze budeme čekat na dokončení všech takto naplánovaných úloh. Toto se již totiž do větší míry podobá reálnému použití, i když obecně platí, že čekání na více úloh ve smyčce tohoto typu není ten nejlepší možný přístup (možná by bylo lepší přidat timeout a čekat ve smyčce na naplnění všech deseti výsledků):
"""Vytvoření úlohy."""
from slow_adder import add
rs = []
print("Queueing...")
for i in range(1, 11):
r = add(i, i)
rs.append(r)
print("Done, waiting for results...")
for r in rs:
print(r(blocking=True))
Při sledování činnosti bude patrné, že výsledky budou přijímány s pětisekundovým intervalem:
$ python3 wait_for_slow_adder.py Queueing... Done, waiting for results... 2 4 6 8 10 12 14 16 18 20
Totéž by mělo být patrné i z logů jediného workera:
17:52 $ huey_consumer.py slow_adder.huey [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:Huey consumer started with 1 thread, PID 29059 at 2020-06-16 15:53:15.881169 [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:Scheduler runs every 1 second(s). [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:Periodic tasks are enabled. [2020-06-16 17:53:15,881] INFO:huey.consumer:MainThread:The following commands are available: + slow_adder.add [2020-06-16 17:53:50,863] INFO:huey:Worker-1:Executing slow_adder.add: 6a81c5f5-5c62-430c-9571-bbe2e6c5e6c8 [2020-06-16 17:53:55,868] INFO:huey:Worker-1:slow_adder.add: 6a81c5f5-5c62-430c-9571-bbe2e6c5e6c8 executed in 5.005s [2020-06-16 18:14:03,225] INFO:huey:Worker-1:Executing slow_adder.add: 6d2c4d61-d9fa-4507-949a-c457183c99fe [2020-06-16 18:14:08,229] INFO:huey:Worker-1:slow_adder.add: 6d2c4d61-d9fa-4507-949a-c457183c99fe executed in 5.004s [2020-06-16 18:14:08,230] INFO:huey:Worker-1:Executing slow_adder.add: 8ede5add-7341-48c5-ba6f-2a4e5c183915 [2020-06-16 18:14:13,235] INFO:huey:Worker-1:slow_adder.add: 8ede5add-7341-48c5-ba6f-2a4e5c183915 executed in 5.005s [2020-06-16 18:14:13,238] INFO:huey:Worker-1:Executing slow_adder.add: d2343825-4168-42f0-b383-58065b5c5bea [2020-06-16 18:14:18,243] INFO:huey:Worker-1:slow_adder.add: d2343825-4168-42f0-b383-58065b5c5bea executed in 5.005s [2020-06-16 18:14:18,247] INFO:huey:Worker-1:Executing slow_adder.add: f901373b-b425-42ae-92f1-5e4fd9d47b97 [2020-06-16 18:14:23,252] INFO:huey:Worker-1:slow_adder.add: f901373b-b425-42ae-92f1-5e4fd9d47b97 executed in 5.005s [2020-06-16 18:14:23,255] INFO:huey:Worker-1:Executing slow_adder.add: 4972e02b-3614-4c07-b04e-0e52d6c8eedb [2020-06-16 18:14:28,259] INFO:huey:Worker-1:slow_adder.add: 4972e02b-3614-4c07-b04e-0e52d6c8eedb executed in 5.004s [2020-06-16 18:14:28,262] INFO:huey:Worker-1:Executing slow_adder.add: 9a4017bc-f48e-4e55-99a2-d76ebeb0ddcb [2020-06-16 18:14:33,267] INFO:huey:Worker-1:slow_adder.add: 9a4017bc-f48e-4e55-99a2-d76ebeb0ddcb executed in 5.004s [2020-06-16 18:14:33,270] INFO:huey:Worker-1:Executing slow_adder.add: 2ce3cd7a-507e-4cfc-a8ae-0e48290d530b [2020-06-16 18:14:38,276] INFO:huey:Worker-1:slow_adder.add: 2ce3cd7a-507e-4cfc-a8ae-0e48290d530b executed in 5.005s [2020-06-16 18:14:38,277] INFO:huey:Worker-1:Executing slow_adder.add: a687133a-758f-4188-9559-57cb1f0bc4c7 [2020-06-16 18:14:43,283] INFO:huey:Worker-1:slow_adder.add: a687133a-758f-4188-9559-57cb1f0bc4c7 executed in 5.005s [2020-06-16 18:14:43,286] INFO:huey:Worker-1:Executing slow_adder.add: e4d13adf-b12f-4581-bf82-798906c7966c [2020-06-16 18:14:48,291] INFO:huey:Worker-1:slow_adder.add: e4d13adf-b12f-4581-bf82-798906c7966c executed in 5.005s [2020-06-16 18:14:48,292] INFO:huey:Worker-1:Executing slow_adder.add: c52de7c6-1348-4671-92d6-fd62a7f6e0bf [2020-06-16 18:14:53,293] INFO:huey:Worker-1:slow_adder.add: c52de7c6-1348-4671-92d6-fd62a7f6e0bf executed in 5.000s
12. Větší množství úloh zpracovaných množinou workerů
V případě, že úloha zpracovávaná workerem je dokončena v relativně dlouhém časovém intervalu a my budeme potřebovat zpracovat větší množství úloh, nezbývá nám nic jiného, než spustit více workerů, kteří mohou pracovat paralelně. Jednou z nabízených možností je spuštění každého workera v samostatném procesu, což sice může být paměťově náročnější (každý proces bude mít k dispozici svůj interpret Pythonu i celý příslušný virtuální stroj), ovšem na druhou stranu jsou od sebe jednotliví workeři velmi dobře izolováni. Dalším příkazem spustíme pět paralelně pracujících workerů:
20:36 $ huey_consumer.py slow_adder.huey --workers 5 --worker-type process [2020-06-13 20:36:29,417] INFO:huey.consumer:15725:Huey consumer started with 5 process, PID 15725 at 2020-06-13 18:36:29.417824 [2020-06-13 20:36:29,417] INFO:huey.consumer:15725:Scheduler runs every 1 second(s). [2020-06-13 20:36:29,418] INFO:huey.consumer:15725:Periodic tasks are enabled. [2020-06-13 20:36:29,418] INFO:huey.consumer:15725:The following commands are available: + slow_adder.add
Opět si necháme naplánovat deset úloh s čekáním na jejich dokončení:
$ python3 wait_for_slow_adder.py Queueing... Done, waiting for results...
Nyní je ovšem situace odlišná a na terminálu by se po cca pěti sekundách měla zobrazit první pětice výsledků:
2 4 6 8 10
A po dalších pěti sekundách zbývající pětice výsledků:
12 14 16 18 20
Totéž chování je patrné i z logů workerů:
[2020-06-16 18:17:04,680] INFO:huey:30147:Executing slow_adder.add: 16145f55-a982-4441-b760-24dce2dad5cd [2020-06-16 18:17:04,681] INFO:huey:30149:Executing slow_adder.add: 81b86138-53e9-4389-837a-97a05326b1ba [2020-06-16 18:17:04,681] INFO:huey:30151:Executing slow_adder.add: 73aa8385-eba8-4a4d-a05f-e7062dbfb5db [2020-06-16 18:17:04,681] INFO:huey:30148:Executing slow_adder.add: 15ec6957-d0e6-46f0-af0e-f6562c760fe7 [2020-06-16 18:17:04,681] INFO:huey:30150:Executing slow_adder.add: b092275b-4937-45df-8d67-f46a312dc451 [2020-06-16 18:17:09,685] INFO:huey:30148:slow_adder.add: 15ec6957-d0e6-46f0-af0e-f6562c760fe7 executed in 5.004s [2020-06-16 18:17:09,686] INFO:huey:30150:slow_adder.add: b092275b-4937-45df-8d67-f46a312dc451 executed in 5.004s [2020-06-16 18:17:09,686] INFO:huey:30149:slow_adder.add: 81b86138-53e9-4389-837a-97a05326b1ba executed in 5.005s [2020-06-16 18:17:09,687] INFO:huey:30151:slow_adder.add: 73aa8385-eba8-4a4d-a05f-e7062dbfb5db executed in 5.006s [2020-06-16 18:17:09,687] INFO:huey:30147:slow_adder.add: 16145f55-a982-4441-b760-24dce2dad5cd executed in 5.006s [2020-06-16 18:17:09,689] INFO:huey:30148:Executing slow_adder.add: 86811c84-2ac9-444e-b773-a5c5c6de9929 [2020-06-16 18:17:09,690] INFO:huey:30150:Executing slow_adder.add: 3b3e92ef-c6b1-4f5b-ab1d-6f289344f801 [2020-06-16 18:17:09,690] INFO:huey:30151:Executing slow_adder.add: 421c61f8-f1eb-4c39-bc3f-abbd285e2629 [2020-06-16 18:17:09,690] INFO:huey:30149:Executing slow_adder.add: 23951a5b-310a-4d82-b0bf-f7f75f7a035d [2020-06-16 18:17:09,690] INFO:huey:30147:Executing slow_adder.add: 84ba86a8-6ebf-43f9-b7a5-be0e384eb2d3 [2020-06-16 18:17:14,694] INFO:huey:30148:slow_adder.add: 86811c84-2ac9-444e-b773-a5c5c6de9929 executed in 5.005s [2020-06-16 18:17:14,695] INFO:huey:30149:slow_adder.add: 23951a5b-310a-4d82-b0bf-f7f75f7a035d executed in 5.004s [2020-06-16 18:17:14,695] INFO:huey:30150:slow_adder.add: 3b3e92ef-c6b1-4f5b-ab1d-6f289344f801 executed in 5.005s [2020-06-16 18:17:14,696] INFO:huey:30151:slow_adder.add: 421c61f8-f1eb-4c39-bc3f-abbd285e2629 executed in 5.005s [2020-06-16 18:17:14,696] INFO:huey:30147:slow_adder.add: 84ba86a8-6ebf-43f9-b7a5-be0e384eb2d3 executed in 5.005s
Všechny vytvořené procesy s workery i jejich koordinátorem si samozřejmě můžeme snadno zobrazit:
$ ps ax |grep huey 15725 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15727 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15728 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15729 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15730 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15731 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15732 pts/1 S+ 0:00 /usr/bin/python3 /home/ptisnovs/.local/bin/huey_consumer.py adder.huey --workers 5 --worker-type process 15780 pts/7 S+ 0:00 grep huey
13. Získání dalších informací o úloze
Objekt, který je získán po naplánování úlohy, obsahuje potenciálně zajímavé informace. Především je v atributu id uložen jednoznačný identifikátor úlohy neboli UUID. Ten je možné použít ve chvíli, kdy se například hledají problémy v celém systému (ztracené úlohy, nedokončené úlohy atd.). Kromě toho však v atributu task nalezneme další objekt s podrobnějšími informacemi o naplánované úloze, zejména argumenty předané do workera, plánované dokončení úlohy, počet pokusů o její dokončení, prioritu atd. Následující skript tyto informace zobrazí (a to dokonce bez toho, aby musel běžet worker):
"""Vytvoření úlohy a vypsání podrobnějších informací o úloze."""
from adder import add
r = add(1, 2)
print("result id:\t", r.id)
print("task object:\t", r.task)
print("arguments:\t", r.task.args)
print("planned ETA:\t", r.task.eta)
print("retries:\t", r.task.retries)
print("priority:\t", r.task.priority)
Výsledek může vypadat následovně:
result id: 3f130490-d74a-41c1-92a0-bddbb754b9a7 task object: adder.add: 3f130490-d74a-41c1-92a0-bddbb754b9a7 arguments: (1, 2) planned ETA: None retries: 0 priority: None
14. Chování systému při havárii úlohy ve workerovi
V prakticky každém systému pro plánování a vykonávání asynchronně běžících úloh je nutné se nějakým způsobem vypořádat se stavem, kdy v úloze dojde k chybě, což v Pythonu znamená, když dojde k vyhození výjimky. Tento stav si můžeme nasimulovat a to velmi snadno – předáme do funkce add celé číslo a řetězec, což jsou pochopitelně dvě hodnoty, které nelze (v Pythonu) sečíst:
"""Vytvoření úlohy.""" from adder import add r = add(1, "foo") print(r) print(r()) print(r(blocking=True))
Po spuštění nastane zajímavá situace – nejprve získáme namísto výsledku hodnotu None, protože celé asynchronní zpracování nějakou dobu trvá. A posléze dojde k vyhození výjimky z funkce r(blocking=True), tj. systém se chová takovým způsobem, jakoby výjimka vznikla lokálně a nikoli ve zcela jiném procesu:
<Result: task 334016fa-26f6-4397-a1dd-2dcb9a96c5a1>
None
Traceback (most recent call last):
File "wait_for_adder_failure.py", line 8, in
print(r(blocking=True))
File "/home/ptisnovs/.local/lib/python3.6/site-packages/huey/api.py", line 853, in __call__
return self.get(*args, **kwargs)
File "/home/ptisnovs/.local/lib/python3.6/site-packages/huey/api.py", line 895, in get
raise TaskException(result.metadata)
huey.exceptions.TaskException: TypeError("unsupported operand type(s) for +: 'int' and 'str'",)
Výjimku ostatně uvidíme i v logu workera, což je užitečné při pozdějším zkoumání jaká úloha a proč zhavarovala:
[2020-06-17 17:54:12,500] INFO:huey:Worker-1:Executing adder.add: 334016fa-26f6-4397-a1dd-2dcb9a96c5a1
[2020-06-17 17:54:12,500] ERROR:huey:Worker-1:Unhandled exception in task 334016fa-26f6-4397-a1dd-2dcb9a96c5a1.
Traceback (most recent call last):
File "/home/ptisnovs/.local/lib/python3.6/site-packages/huey/api.py", line 359, in _execute
task_value = task.execute()
File "/home/ptisnovs/.local/lib/python3.6/site-packages/huey/api.py", line 723, in execute
return func(*args, **kwargs)
File "/home/ptisnovs/src/message-queues-examples/huey/adder.py", line 11, in add
return a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Výjimku můžeme snadno zachytit:
"""Vytvoření úlohy."""
from adder import add
r = add(1, "foo")
print(r)
print(r())
try:
print(r(blocking=True))
except Exception as e:
print("Exception detected!", e)
S výsledkem:
<Result: task b4e7e80f-c50f-4a09-aa42-e8d44809152a>
None
Exception detected! TypeError("unsupported operand type(s) for +: 'int' and 'str'",)
15. Naplánování periodicky se opakující úlohy
Systém Huey umožňuje naplánování periodicky se opakujících úloh. Přitom lze použít zápis podobný tomu, který se používá v cronu, viz též https://crontab.guru/. Příklad úlohy spuštěné každou minutu:
"""Periodicky se opakující úloha."""
from huey import crontab
from huey import RedisHuey
huey = RedisHuey()
@huey.periodic_task(crontab(minute='*'))
def periodic():
print("*** NOW ***")
Taková úloha nemá mít žádné parametry ani nesmí vracet žádné výsledky konstrukcí return. Ovšem i přesto lze výsledky uchovat, a to přímo do Redisu či podobného systému. Podrobnosti si řekneme příště.
O tom, že je úloha skutečně spouštěna se zadanou periodou, se lze přesvědčit pohledem do logu workera:
$ huey_consumer.py periodic.huey [2020-06-17 18:59:07,980] INFO:huey.consumer:MainThread:Huey consumer started with 1 thread, PID 11784 at 2020-06-17 16:59:07.980863 [2020-06-17 18:59:07,980] INFO:huey.consumer:MainThread:Scheduler runs every 1 second(s). [2020-06-17 18:59:07,981] INFO:huey.consumer:MainThread:Periodic tasks are enabled. [2020-06-17 18:59:07,981] INFO:huey.consumer:MainThread:The following commands are available: + periodic.periodic [2020-06-17 18:59:07,985] INFO:huey.consumer.Scheduler:Scheduler:Enqueueing periodic task periodic.periodic: 6f50745c-1be5-4d41-9def-035f1e02afa2. [2020-06-17 18:59:07,986] INFO:huey:Worker-1:Executing periodic.periodic: 6f50745c-1be5-4d41-9def-035f1e02afa2 *** NOW *** [2020-06-17 18:59:07,986] INFO:huey:Worker-1:periodic.periodic: 6f50745c-1be5-4d41-9def-035f1e02afa2 executed in 0.000s [2020-06-17 19:00:07,982] INFO:huey.consumer.Scheduler:Scheduler:Enqueueing periodic task periodic.periodic: f4f10a24-2f3b-4491-9b1d-5bf14bfa71a3. [2020-06-17 19:00:07,984] INFO:huey:Worker-1:Executing periodic.periodic: f4f10a24-2f3b-4491-9b1d-5bf14bfa71a3 *** NOW *** [2020-06-17 19:00:07,984] INFO:huey:Worker-1:periodic.periodic: f4f10a24-2f3b-4491-9b1d-5bf14bfa71a3 executed in 0.000s [2020-06-17 19:01:07,981] INFO:huey.consumer.Scheduler:Scheduler:Enqueueing periodic task periodic.periodic: 03f3fa18-d39c-4ebb-8525-3b1c7858337c. [2020-06-17 19:01:07,983] INFO:huey:Worker-1:Executing periodic.periodic: 03f3fa18-d39c-4ebb-8525-3b1c7858337c *** NOW *** [2020-06-17 19:01:07,983] INFO:huey:Worker-1:periodic.periodic: 03f3fa18-d39c-4ebb-8525-3b1c7858337c executed in 0.000s
Podobným způsobem lze vytvořit například úlohu spouštěnou každých pět minut:
"""Periodicky se opakující úloha."""
from huey import crontab
from huey import RedisHuey
huey = RedisHuey()
@huey.periodic_task(crontab(minute='*/5'))
def periodic():
print("*** NOW ***")
16. Korektní spuštění skupiny úloh
Již v předchozím textu jsme si ukázali jeden způsob čekání na dokončení několika úloh. Ovšem prezentovaný způsob nebyl v žádném případě dokonalý, protože pro naplánování několika úloh a na případné získání jejích výsledků (s případným čekáním) je určen objekt typu „skupina úloh“ s mnohem jednodušším rozhraním. Jeho základní způsob použití je ukázán v dalším skriptu:
"""Vytvoření deseti úloh."""
from slow_adder import add
print("Queueing...")
rg = add.map([(i, i) for i in range(1, 11)])
print("Done, waiting for results...")
print(rg.get(blocking=True))
Povšimněte si, že čekání na dokončení úloh a na získání jejich výsledků je provedeno jediným zavoláním metody get s případným použitím parametru blocking=True. Výsledky jsou získány ve formě seznamu:
Queueing... Done, waiting for results... [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
17. Prioritní úlohy
Systém Huey dokáže pracovat i s úlohami s různou prioritou, které fronty používají poněkud odlišným způsobem. Jedná se o potenciálně velmi užitečnou vlastnost, takže se jí podrobněji a s několika demonstračními příklady budeme věnovat v další části tohoto seriálu.
18. Plánování různých úloh s odlišnou implementací workerů
Podívejme se ještě na způsob naplánování a spuštění úloh realizovaných různými funkcemi ve workeru. Upravený worker má s využitím dekorátoru označeny tři funkce, které realizují různé úlohy. Jedná se o součet, součet s prodlevou (ten již známe z předchozích kapitol) a součin:
"""Několik různých úloh."""
from huey import RedisHuey
from time import sleep
huey = RedisHuey()
@huey.task()
def add(a, b):
"""Úloha pro rychlý součet dvou hodnot."""
return a + b
@huey.task()
def slow_add(a, b):
"""Úloha pro pomalý součet dvou hodnot."""
sleep(5)
return a + b
@huey.task()
def mul(a, b):
"""Úloha pro součin dvou hodnot."""
return a * b
Příslušné úlohy lze samozřejmě přímo použít, což je ukázáno v následujícím skriptu, který vytvoří celkem třicet úloh – dvacet na součet, deset na násobení – a následně počká na jejich dokončení:
"""Vytvoření různých úloh."""
from three_tasks import add, slow_add, mul
rs = []
print("Queueing...")
for i in range(1, 11):
rs.append(add(i, i))
rs.append(slow_add(i, i))
rs.append(mul(i, i))
print("Done, waiting for results...")
for r in rs:
print(r(blocking=True))
Následně spustíme celkem pět workerů (nikoli patnáct):
$ huey_consumer.py three_tasks.huey --workers 5 --worker-type process [2020-06-16 20:59:50,392] INFO:huey.consumer:2416:Huey consumer started with 5 process, PID 2416 at 2020-06-16 18:59:50.392372 [2020-06-16 20:59:50,392] INFO:huey.consumer:2416:Scheduler runs every 1 second(s). [2020-06-16 20:59:50,392] INFO:huey.consumer:2416:Periodic tasks are enabled. [2020-06-16 20:59:50,392] INFO:huey.consumer:2416:The following commands are available: + three_tasks.add + three_tasks.slow_add + three_tasks.mul
Výsledky budou vypočteny a vráceny v tomto pořadí (nemusí být však zachováno zcela přesně, protože sleep ani přepínání procesů s workery nijak neřídíme):

Queueing... Done, waiting for results... 2 2 1 4 4 4 6 6 9 8 8 16 10 10 25 12 12 36 14 14 49 16 16 64 18 18 81 20 20 100
Z výpisu logů workerů je patrné prodlení způsobené tím, že workeři začnou počítat součet s vloženým voláním funkce sleep (viz zvýrazněné části):
[2020-06-16 21:01:00,580] INFO:huey:2423:Executing three_tasks.add: ca9bff2e-20ac-4628-9245-629bd6d0aaee [2020-06-16 21:01:00,580] INFO:huey:2419:Executing three_tasks.slow_add: 7092e846-70e0-40cf-967f-e6cf18ba78fe [2020-06-16 21:01:00,581] INFO:huey:2423:three_tasks.add: ca9bff2e-20ac-4628-9245-629bd6d0aaee executed in 0.000s [2020-06-16 21:01:00,581] INFO:huey:2421:Executing three_tasks.mul: d025b88c-e3c7-4f7b-83e3-e67a471f2cef [2020-06-16 21:01:00,581] INFO:huey:2421:three_tasks.mul: d025b88c-e3c7-4f7b-83e3-e67a471f2cef executed in 0.000s [2020-06-16 21:01:00,581] INFO:huey:2422:Executing three_tasks.add: dd703c69-2810-41b0-b238-13a1f5628a0d [2020-06-16 21:01:00,581] INFO:huey:2420:Executing three_tasks.slow_add: 01ee6a98-122e-40c8-8581-43dffee96f12 [2020-06-16 21:01:00,581] INFO:huey:2422:three_tasks.add: dd703c69-2810-41b0-b238-13a1f5628a0d executed in 0.000s ... ... ... [2020-06-16 21:01:05,593] INFO:huey:2420:three_tasks.mul: 0397de3a-644c-4da2-878b-32c6f909af1b executed in 0.000s [2020-06-16 21:01:05,593] INFO:huey:2420:Executing three_tasks.add: a2fa2818-5ceb-423a-bc5d-b10d1798cb6d [2020-06-16 21:01:05,594] INFO:huey:2420:three_tasks.add: a2fa2818-5ceb-423a-bc5d-b10d1798cb6d executed in 0.000s [2020-06-16 21:01:05,594] INFO:huey:2420:Executing three_tasks.slow_add: 07ab94fb-80b5-44db-b4b5-7be716649115 [2020-06-16 21:01:10,593] INFO:huey:2421:three_tasks.slow_add: f6199751-1d66-433a-85b2-6b1a7bfb0acc executed in 5.001s [2020-06-16 21:01:10,593] INFO:huey:2423:three_tasks.slow_add: 37cf126f-b4ed-49cf-bbc5-6e16d6399f4b executed in 5.001s [2020-06-16 21:01:10,594] INFO:huey:2422:three_tasks.slow_add: 28339d2f-ed94-43b0-99f6-ec74e28c6948 executed in 5.004s [2020-06-16 21:01:10,595] INFO:huey:2419:three_tasks.slow_add: 77f10038-afff-4f80-ab7c-8f79eb749818 executed in 5.004s [2020-06-16 21:01:10,596] INFO:huey:2421:Executing three_tasks.mul: f1cdc9f4-ffcc-49e2-980a-912d430e8157 [2020-06-16 21:01:10,596] INFO:huey:2421:three_tasks.mul: f1cdc9f4-ffcc-49e2-980a-912d430e8157 executed in 0.000s [2020-06-16 21:01:10,599] INFO:huey:2420:three_tasks.slow_add: 07ab94fb-80b5-44db-b4b5-7be716649115 executed in 5.005s
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů vyvinutých v programovacím jazyku Python byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/message-queues-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má stále ještě doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce. Každý příklad obsahuje implementaci workera či workerů a taktéž skript pro naplánování úloh:
20. Odkazy na Internetu
- Dokumentace k systému Huey
https://huey.readthedocs.io/en/latest/ - Balíček s projektem Huey
https://pypi.org/project/huey/ - Repositář Huey na GitHubu
https://github.com/coleifer/huey - Looking for an alternative to Celery? Try Huey
https://hub.packtpub.com/looking-for-alternative-celery-try-huey/ - Celery vs. Huey vs. other?
https://www.reddit.com/r/django/comments/2swfz2/celery_vs_huey_vs_other/ - POSIX message queues in Linux
https://www.softprayog.in/programming/interprocess-communication-using-posix-message-queues-in-linux - How is a message queue implemented in the Linux kernel?
https://unix.stackexchange.com/questions/6930/how-is-a-message-queue-implemented-in-the-linux-kernel/6935 - ‘IPCS’ command in Linux with examples
https://www.geeksforgeeks.org/ipcs-command-linux-examples/ - System V IPC: Message Queues
https://nitish712.blogspot.com/2012/11/system-v-ipc-message-queues.html - How to create, check and delete IPC share memory, semaphare and message queue on linux
https://fibrevillage.com/sysadmin/225-how-to-create-check-and-delete-ipc-share-memory-semaphare-and-message-queue-on-linux - MQ_OVERVIEW(7): Linux Programmer's Manual
http://man7.org/linux/man-pages/man7/mq_overview.7.html - mq_overview (7) – Linux Man Pages
https://www.systutorials.com/docs/linux/man/7-mq_overview/ - POSIX.4 Message Queues (+ rozšíření QNX)
https://users.pja.edu.pl/~jms/qnx/help/watcom/clibref/mq_overview.html - System V message queues in Linux
https://www.softprayog.in/programming/interprocess-communication-using-system-v-message-queues-in-linux - Linux System V and POSIX IPC Examples
http://hildstrom.com/projects/ipc_sysv_posix/index.html - Programming Tutorial – Linux: Message Queues
https://ccppcoding.blogspot.com/2013/03/linux-message-queues.html - Go wrapper for POSIX Message Queues
https://github.com/syucream/posix_mq - Stránka projektu NSQ
https://nsq.io/ - Dokumentace k projektu NSQ
https://nsq.io/overview/design.html - Dokumentace ke klientovi pro Go
https://godoc.org/github.com/nsqio/go-nsq - Dokumentace ke klientovi pro Python
https://pynsq.readthedocs.io/en/latest/ - Binární tarbally s NSQ
https://nsq.io/deployment/installing.html - GitHub repositář projektu NSQ
https://github.com/nsqio/nsq - Klienti pro NSQ
https://nsq.io/clients/client_libraries.html - Klient pro Go
https://github.com/nsqio/go-nsq - Klient pro Python
https://github.com/nsqio/pynsq - An Example of Using NSQ From Go
http://tleyden.github.io/blog/2014/11/12/an-example-of-using-nsq-from-go/ - Go Go Gadget
https://word.bitly.com/post/29550171827/go-go-gadget - Simplehttp
https://github.com/bitly/simplehttp - Dramatiq: simple task processing
https://dramatiq.io/ - Cookbook (for Dramatiq)
https://dramatiq.io/cookbook.html - Balíček dramatiq na PyPi
https://pypi.org/project/dramatiq/ - Dramatiq dashboard
https://github.com/Bogdanp/dramatiq_dashboard - Dramatiq na Redditu
https://www.reddit.com/r/dramatiq/ - A Dramatiq broker that can be used with Amazon SQS
https://github.com/Bogdanp/dramatiq_sqs - nanomsg na GitHubu
https://github.com/nanomsg/nanomsg - Referenční příručka knihovny nanomsg
https://nanomsg.org/v1.1.5/nanomsg.html - nng (nanomsg-next-generation)
https://github.com/nanomsg/nng - Differences between nanomsg and ZeroMQ
https://nanomsg.org/documentation-zeromq.html - NATS
https://nats.io/about/ - NATS Streaming Concepts
https://nats.io/documentation/streaming/nats-streaming-intro/ - NATS Streaming Server
https://nats.io/download/nats-io/nats-streaming-server/ - NATS Introduction
https://nats.io/documentation/ - NATS Client Protocol
https://nats.io/documentation/internals/nats-protocol/ - NATS Messaging (Wikipedia)
https://en.wikipedia.org/wiki/NATS_Messaging - Stránka Apache Software Foundation
http://www.apache.org/ - Informace o portu 5672
http://www.tcp-udp-ports.com/port-5672.htm - Třída MessagingHandler knihovny Qpid Proton
https://qpid.apache.org/releases/qpid-proton-0.27.0/proton/python/api/proton._handlers.MessagingHandler-class.html - Třída Event knihovny Qpid Proton
https://qpid.apache.org/releases/qpid-proton-0.27.0/proton/python/api/proton._events.Event-class.html - package stomp (Go)
https://godoc.org/github.com/go-stomp/stomp - Go language library for STOMP protocol
https://github.com/go-stomp/stomp - python-qpid-proton 0.26.0 na PyPi
https://pypi.org/project/python-qpid-proton/ - Qpid Proton
http://qpid.apache.org/proton/ - Using the AMQ Python Client
https://access.redhat.com/documentation/en-us/red_hat_amq/7.1/html-single/using_the_amq_python_client/ - Apache ActiveMQ
http://activemq.apache.org/ - Apache ActiveMQ Artemis
https://activemq.apache.org/artemis/ - Apache ActiveMQ Artemis User Manual
https://activemq.apache.org/artemis/docs/latest/index.html - KahaDB
http://activemq.apache.org/kahadb.html - Understanding the KahaDB Message Store
https://access.redhat.com/documentation/en-US/Fuse_MQ_Enterprise/7.1/html/Configuring_Broker_Persistence/files/KahaDBOverview.html - Command Line Tools (Apache ActiveMQ)
https://activemq.apache.org/activemq-command-line-tools-reference.html - stomp.py 4.1.21 na PyPi
https://pypi.org/project/stomp.py/ - Stomp Tutorial
https://access.redhat.com/documentation/en-US/Fuse_Message_Broker/5.5/html/Connectivity_Guide/files/FMBConnectivityStompTelnet.html - Heartbeat (computing)
https://en.wikipedia.org/wiki/Heartbeat_(computing) - Apache Camel
https://camel.apache.org/ - Red Hat Fuse
https://developers.redhat.com/products/fuse/overview/ - Confusion between ActiveMQ and ActiveMQ-Artemis?
https://serverfault.com/questions/873533/confusion-between-activemq-and-activemq-artemis - Staré stránky projektu HornetQ
http://hornetq.jboss.org/ - Snapshot JeroMQ verze 0.4.4
https://oss.sonatype.org/content/repositories/snapshots/org/zeromq/jeromq/0.4.4-SNAPSHOT/ - Difference between ActiveMQ vs Apache ActiveMQ Artemis
http://activemq.2283324.n4.nabble.com/Difference-between-ActiveMQ-vs-Apache-ActiveMQ-Artemis-td4703828.html - Microservices communications. Why you should switch to message queues
https://dev.to/matteojoliveau/microservices-communications-why-you-should-switch-to-message-queues–48ia - Stomp.py 4.1.19 documentation
https://stomppy.readthedocs.io/en/stable/ - Repositář knihovny JeroMQ
https://github.com/zeromq/jeromq/ - ØMQ – Distributed Messaging
http://zeromq.org/ - ØMQ Community
http://zeromq.org/community - Get The Software
http://zeromq.org/intro:get-the-software - PyZMQ Documentation
https://pyzmq.readthedocs.io/en/latest/ - Module: zmq.decorators
https://pyzmq.readthedocs.io/en/latest/api/zmq.decorators.html - ZeroMQ is the answer, by Ian Barber
https://vimeo.com/20605470 - ZeroMQ RFC
https://rfc.zeromq.org/ - ZeroMQ and Clojure, a brief introduction
https://antoniogarrote.wordpress.com/2010/09/08/zeromq-and-clojure-a-brief-introduction/ - zeromq/czmq
https://github.com/zeromq/czmq - golang wrapper for CZMQ
https://github.com/zeromq/goczmq - ZeroMQ version reporting in Python
http://zguide.zeromq.org/py:version - A Go interface to ZeroMQ version 4
https://github.com/pebbe/zmq4 - Broker vs. Brokerless
http://zeromq.org/whitepapers:brokerless - Learning ØMQ with pyzmq
https://learning-0mq-with-pyzmq.readthedocs.io/en/latest/ - Céčková funkce zmq_ctx_new
http://api.zeromq.org/4–2:zmq-ctx-new - Céčková funkce zmq_ctx_destroy
http://api.zeromq.org/4–2:zmq-ctx-destroy - Céčková funkce zmq_bind
http://api.zeromq.org/4–2:zmq-bind - Céčková funkce zmq_unbind
http://api.zeromq.org/4–2:zmq-unbind - Céčková C funkce zmq_connect
http://api.zeromq.org/4–2:zmq-connect - Céčková C funkce zmq_disconnect
http://api.zeromq.org/4–2:zmq-disconnect - Céčková C funkce zmq_send
http://api.zeromq.org/4–2:zmq-send - Céčková C funkce zmq_recv
http://api.zeromq.org/4–2:zmq-recv - Třída Context (Python)
https://pyzmq.readthedocs.io/en/latest/api/zmq.html#context - Třída Socket (Python)
https://pyzmq.readthedocs.io/en/latest/api/zmq.html#socket - Python binding
http://zeromq.org/bindings:python - Why should I have written ZeroMQ in C, not C++ (part I)
http://250bpm.com/blog:4 - Why should I have written ZeroMQ in C, not C++ (part II)
http://250bpm.com/blog:8 - About Nanomsg
https://nanomsg.org/ - Advanced Message Queuing Protocol
https://www.amqp.org/ - Advanced Message Queuing Protocol na Wikipedii
https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol - Dokumentace k příkazu rabbitmqctl
https://www.rabbitmq.com/rabbitmqctl.8.html - RabbitMQ
https://www.rabbitmq.com/ - RabbitMQ Tutorials
https://www.rabbitmq.com/getstarted.html - RabbitMQ: Clients and Developer Tools
https://www.rabbitmq.com/devtools.html - RabbitMQ na Wikipedii
https://en.wikipedia.org/wiki/RabbitMQ - Streaming Text Oriented Messaging Protocol
https://en.wikipedia.org/wiki/Streaming_Text_Oriented_Messaging_Protocol - Message Queuing Telemetry Transport
https://en.wikipedia.org/wiki/MQTT - Erlang
http://www.erlang.org/ - pika 0.12.0 na PyPi
https://pypi.org/project/pika/ - Introduction to Pika
https://pika.readthedocs.io/en/stable/ - Langohr: An idiomatic Clojure client for RabbitMQ that embraces the AMQP 0.9.1 model
http://clojurerabbitmq.info/ - AMQP 0–9–1 Model Explained
http://www.rabbitmq.com/tutorials/amqp-concepts.html - Part 1: RabbitMQ for beginners – What is RabbitMQ?
https://www.cloudamqp.com/blog/2015–05–18-part1-rabbitmq-for-beginners-what-is-rabbitmq.html - Downloading and Installing RabbitMQ
https://www.rabbitmq.com/download.html - celery na PyPi
https://pypi.org/project/celery/ - Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Python Celery & RabbitMQ Tutorial
https://tests4geeks.com/python-celery-rabbitmq-tutorial/ - Flower: Real-time Celery web-monitor
http://docs.celeryproject.org/en/latest/userguide/monitoring.html#flower-real-time-celery-web-monitor - Asynchronous Tasks With Django and Celery
https://realpython.com/asynchronous-tasks-with-django-and-celery/ - First Steps with Celery
http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html - node-celery
https://github.com/mher/node-celery - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queue – A thread-safe FIFO implementation
https://pymotw.com/2/Queue/ - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq - Running multiple workers using Celery
https://serverfault.com/questions/655387/running-multiple-workers-using-celery - celery — Distributed processing
http://docs.celeryproject.org/en/latest/reference/celery.html - Chains
https://celery.readthedocs.io/en/latest/userguide/canvas.html#chains - Routing
http://docs.celeryproject.org/en/latest/userguide/routing.html#automatic-routing - Celery Distributed Task Queue in Go
https://github.com/gocelery/gocelery/ - Python Decorators
https://wiki.python.org/moin/PythonDecorators - Periodic Tasks
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html - celery.schedules
http://docs.celeryproject.org/en/latest/reference/celery.schedules.html#celery.schedules.crontab - Pros and cons to use Celery vs. RQ
https://stackoverflow.com/questions/13440875/pros-and-cons-to-use-celery-vs-rq - Priority queue
https://en.wikipedia.org/wiki/Priority_queue - Jupyter
https://jupyter.org/ - How IPython and Jupyter Notebook work
https://jupyter.readthedocs.io/en/latest/architecture/how_jupyter_ipython_work.html - Context Managers
http://book.pythontips.com/en/latest/context_managers.html