
Obsah
1. Operace s daty uloženými v binárních souborech v knihovnách NumPy a Pandas
2. Uložení obsahu vektoru do textového souboru se specifikací oddělovače
3. Uložení obsahu vektoru do binárního souboru
4. Načtení obsahu vektoru z textového popř. binárního souboru
5. Uložení obsahu matice do textového souboru se specifikací oddělovače i do souboru binárního
6. Standardní binární soubor knihovny NumPy
7. Standardní binární soubor pro vektory
8. Uložení a načtení matice do/ze standardního binárního souboru
9. Binární soubory a knihovna Pandas
10. Načtení obsahu datové řady z binárního souboru s konverzí
11. Načtení obsahu datového rámce z binárního souboru se specifikací formátu
12. Vygenerování binárního souboru se dvěma sloupci čísel s různou reprezentací
13. Načtení binárního souboru s různými typy sloupců do datového rámce
16. Načtení obsahu datového rámce z binárního souboru obsahujícího řetězce pevné délky
17. Převod sekvence bajtů na řetězec
18. Repositář s demonstračními příklady
19. Odkazy na předchozí části seriálu o knihovně Pandas
1. Operace s daty uloženými v binárních souborech v knihovnách NumPy a Pandas
Poměrně často se v praxi můžeme setkat s požadavkem analýzy dat uložených v binárních souborech. S těmito soubory dokáže do určité míry pracovat jak knihovna NumPy, tak i knihovna Pandas. Dnes si představíme základní metody ukládání i načítání binárních dat; v navazujícím článku si pak ukážeme některé pokročilé (resp. spíše pouze pokročilejší) metody, například přeskakování bloků v binárních souborech, využití mmap u obrovských souborů, které se celé nevejdou do operační paměti atd.
Pro prohlížení obsahu binárních souborů lze použít například nějakou formu hexadecimálního prohlížeče. Co si však pod pojmenováním „hexadecimální prohlížeč“ nebo „hexadecimální editor“ máme představit? Jedná se o aplikace, které vstupní binární soubor (tj. soubor, který může mít libovolný obsah, jenž není nijak interpretován) zobrazí typickým způsobem ve formě hexadecimálních hodnot (tj. číselných hodnot využívajících při zobrazení šestnáctkovou soustavu) umístěných do sloupců (viz též první obrázek). Ve skutečnosti je však možné mnoho těchto prohlížečů a editorů nakonfigurovat takovým způsobem, že se namísto hexadeciálních hodnot používají hodnoty reprezentované v osmičkové soustavě, v soustavě dvojkové či dokonce v desítkové soustavě (což ovšem v naprosté většině případů není moc praktické).
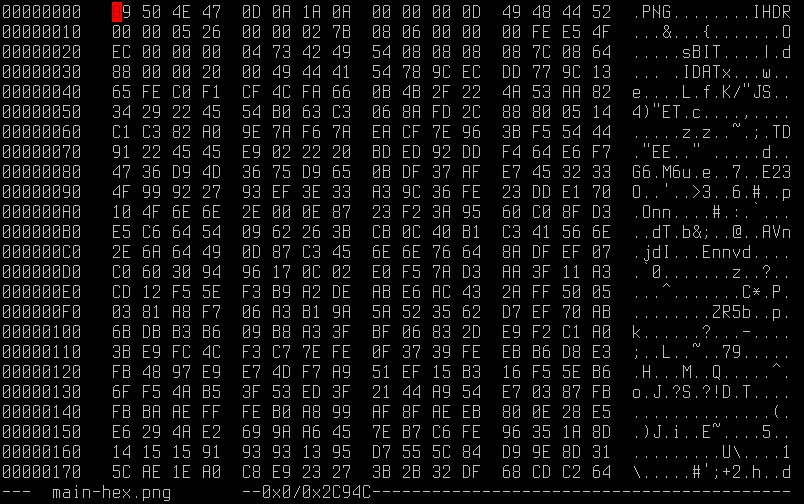
Obrázek 1: Pohled na typický hexadecimální editor spuštěný na terminálu s osmdesáti sloupci a dvaceti pěti textovými řádky. Plocha terminálu je rozdělena do čtyř oblastí – sloupec adres, sloupec s hexadecimálními hodnotami, sloupec s textovou reprezentací bajtů a konečně na stavový a příkazový řádek (v některých případech obsahují hexadecimální editory i řádek s menu).
Hexadecimálních prohlížečů a editorů existuje (pro Linux) relativně velké množství. První dva nástroje nazvané od a hexdump (zkráceně hd) pracují jako relativně jednoduché jednosměrné filtry (navíc bývají nainstalovány společně se základním sadou nástrojů), ovšem další nástroj pojmenovaný xxd již může být použit pro obousměrný převod (filtraci), tj. jak pro transformaci původního binárního souboru do čitelného tvaru (většinou s využitím šestnáctkové soustavy), tak i pro zpětný převod. Díky tomu je možné xxd použít například ve funkci pluginu do běžných textových editorů. Další nástroj pojmenovaný hexdiff dokáže porovnat obsah dvou binárních souborů a poslední zmíněný nástroj mcview je, na rozdíl od předchozí čtveřice, aplikací s interaktivním ovládáním a plnohodnotným textovým uživatelským prostředím.
Ukažme si nyní některé možnosti nabízené nástrojem od (ovšem bez problémů lze přeskočit na další kapitolu s popisem možností knihoven NumPy a posléze i Pandas, ostatně právě v dalších kapitolách využijeme i další formáty podporované tímto nástrojem).
Výpis obsahu binárního souboru v osmičkové soustavě s použitím výchozího nastavení (povšimněte si oddělení hvězdičkou po 256 bajtech, což je historicky daná hodnota odpovídající jedné stránce paměti a/nebo jednomu sektoru):
od a.out 0000000 042577 043114 000401 000001 000000 000000 000000 000000 0000020 000002 000050 000001 000000 100124 000000 000064 000000 0000040 000230 000000 001000 002400 000064 000040 000001 000050 0000060 000004 000003 000001 000000 000000 000000 100000 000000 0000100 100000 000000 000140 000000 000140 000000 000005 000000 0000120 100000 000000 070001 161640 000000 161640 000000 167400 0000140 011501 000000 060400 060545 064542 000400 000011 000000 0000160 000406 000410 027000 064163 072163 072162 061141 027000 0000200 062564 072170 027000 051101 027115 072141 071164 061151 0000220 072165 071545 000000 000000 000000 000000 000000 000000 0000240 000000 000000 000000 000000 000000 000000 000000 000000 * 0000300 000013 000000 000001 000000 000006 000000 100124 000000 0000320 000124 000000 000014 000000 000000 000000 000000 000000 0000340 000004 000000 000000 000000 000021 000000 000003 070000 0000360 000000 000000 000000 000000 000140 000000 000024 000000 0000400 000000 000000 000000 000000 000001 000000 000000 000000 0000420 000001 000000 000003 000000 000000 000000 000000 000000 0000440 000164 000000 000041 000000 000000 000000 000000 000000 0000460 000001 000000 000000 000000 0000470
Přepnutí do šestnáctkové soustavy, ovšem se sdružením bajtů do 16bitových slov:
od -h a.out 0000000 457f 464c 0101 0001 0000 0000 0000 0000 0000020 0002 0028 0001 0000 8054 0000 0034 0000 0000040 0098 0000 0200 0500 0034 0020 0001 0028 0000060 0004 0003 0001 0000 0000 0000 8000 0000 0000100 8000 0000 0060 0000 0060 0000 0005 0000 0000120 8000 0000 7001 e3a0 0000 e3a0 0000 ef00 0000140 1341 0000 6100 6165 6962 0100 0009 0000 0000160 0106 0108 2e00 6873 7473 7472 6261 2e00 0000200 6574 7478 2e00 5241 2e4d 7461 7274 6269 0000220 7475 7365 0000 0000 0000 0000 0000 0000 0000240 0000 0000 0000 0000 0000 0000 0000 0000 * 0000300 000b 0000 0001 0000 0006 0000 8054 0000 0000320 0054 0000 000c 0000 0000 0000 0000 0000 0000340 0004 0000 0000 0000 0011 0000 0003 7000 0000360 0000 0000 0000 0000 0060 0000 0014 0000 0000400 0000 0000 0000 0000 0001 0000 0000 0000 0000420 0001 0000 0003 0000 0000 0000 0000 0000 0000440 0074 0000 0021 0000 0000 0000 0000 0000 0000460 0001 0000 0000 0000 0000470
Explicitní žádost, aby hodnoty bajtů nebyly spojovány do větších slov:
od -t x1 a.out 0000000 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 0000020 02 00 28 00 01 00 00 00 54 80 00 00 34 00 00 00 0000040 98 00 00 00 00 02 00 05 34 00 20 00 01 00 28 00 0000060 04 00 03 00 01 00 00 00 00 00 00 00 00 80 00 00 0000100 00 80 00 00 60 00 00 00 60 00 00 00 05 00 00 00 0000120 00 80 00 00 01 70 a0 e3 00 00 a0 e3 00 00 00 ef 0000140 41 13 00 00 00 61 65 61 62 69 00 01 09 00 00 00 0000160 06 01 08 01 00 2e 73 68 73 74 72 74 61 62 00 2e 0000200 74 65 78 74 00 2e 41 52 4d 2e 61 74 74 72 69 62 0000220 75 74 65 73 00 00 00 00 00 00 00 00 00 00 00 00 0000240 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 * 0000300 0b 00 00 00 01 00 00 00 06 00 00 00 54 80 00 00 0000320 54 00 00 00 0c 00 00 00 00 00 00 00 00 00 00 00 0000340 04 00 00 00 00 00 00 00 11 00 00 00 03 00 00 70 0000360 00 00 00 00 00 00 00 00 60 00 00 00 14 00 00 00 0000400 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 0000420 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 0000440 74 00 00 00 21 00 00 00 00 00 00 00 00 00 00 00 0000460 01 00 00 00 00 00 00 00 0000470
Zákaz výpisu oddělovací hvězdičky:
od -v -t x1 a.out 0000000 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 0000020 02 00 28 00 01 00 00 00 54 80 00 00 34 00 00 00 0000040 98 00 00 00 00 02 00 05 34 00 20 00 01 00 28 00 0000060 04 00 03 00 01 00 00 00 00 00 00 00 00 80 00 00 0000100 00 80 00 00 60 00 00 00 60 00 00 00 05 00 00 00 0000120 00 80 00 00 01 70 a0 e3 00 00 a0 e3 00 00 00 ef 0000140 41 13 00 00 00 61 65 61 62 69 00 01 09 00 00 00 0000160 06 01 08 01 00 2e 73 68 73 74 72 74 61 62 00 2e 0000200 74 65 78 74 00 2e 41 52 4d 2e 61 74 74 72 69 62 0000220 75 74 65 73 00 00 00 00 00 00 00 00 00 00 00 00 0000240 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000260 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000300 0b 00 00 00 01 00 00 00 06 00 00 00 54 80 00 00 0000320 54 00 00 00 0c 00 00 00 00 00 00 00 00 00 00 00 0000340 04 00 00 00 00 00 00 00 11 00 00 00 03 00 00 70 0000360 00 00 00 00 00 00 00 00 60 00 00 00 14 00 00 00 0000400 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 0000420 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 0000440 74 00 00 00 21 00 00 00 00 00 00 00 00 00 00 00 0000460 01 00 00 00 00 00 00 00 0000470
Výpis 128 bajtů od offsetu 64 (počet bajtů i offset se zadává desítkově):
od -j 64 -N 128 -v -t x1 a.out 0000100 00 80 00 00 60 00 00 00 60 00 00 00 05 00 00 00 0000120 00 80 00 00 01 70 a0 e3 00 00 a0 e3 00 00 00 ef 0000140 41 13 00 00 00 61 65 61 62 69 00 01 09 00 00 00 0000160 06 01 08 01 00 2e 73 68 73 74 72 74 61 62 00 2e 0000200 74 65 78 74 00 2e 41 52 4d 2e 61 74 74 72 69 62 0000220 75 74 65 73 00 00 00 00 00 00 00 00 00 00 00 00 0000240 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000260 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000300
Výpis 128 bajtů od offsetu 64 (počet bajtů i offset se zadává v šestnáctkové soustavě):
od -j 0x40 -N 0x80 -v -t x1 a.out 0000100 00 80 00 00 60 00 00 00 60 00 00 00 05 00 00 00 0000120 00 80 00 00 01 70 a0 e3 00 00 a0 e3 00 00 00 ef 0000140 41 13 00 00 00 61 65 61 62 69 00 01 09 00 00 00 0000160 06 01 08 01 00 2e 73 68 73 74 72 74 61 62 00 2e 0000200 74 65 78 74 00 2e 41 52 4d 2e 61 74 74 72 69 62 0000220 75 74 65 73 00 00 00 00 00 00 00 00 00 00 00 00 0000240 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000260 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0000300
Každé čtyři bajty jsou považovány za číslo ve formátu single/float podle IEEE 754. Zde se sice jedná o zcela nesmyslný výstup, ovšem při načítán binárních souborů s poli se může hodit:
od -t f4 a.out 0000000 13073.374 9.2196e-41 0 0 0000020 3.673423e-39 1e-45 4.6035e-41 7.3e-44 0000040 2.13e-43 6.0188984e-36 2.938809e-39 3.673421e-39 0000060 2.75512e-40 1e-45 0 4.5918e-41 0000100 4.5918e-41 1.35e-43 1.35e-43 7e-45 0000120 4.5918e-41 -5.9190996e+21 -5.902958e+21 -3.9614081e+28 0000140 6.907e-42 2.6445587e+20 2.3585495e-38 1.3e-44 0000160 2.497999e-38 4.5935344e+24 7.683702e+31 2.919121e-11 0000200 7.871993e+31 2.0742511e+11 7.1362664e+31 1.07658465e+21 0000220 1.8179291e+31 0 0 0 0000240 0 0 0 0 * 0000300 1.5e-44 1e-45 8e-45 4.6035e-41 0000320 1.18e-43 1.7e-44 0 0 0000340 6e-45 0 2.4e-44 1.5845638e+29 0000360 0 0 1.35e-43 2.8e-44 0000400 0 0 1e-45 0 0000420 1e-45 4e-45 0 0 0000440 1.63e-43 4.6e-44 0 0 0000460 1e-45 0 0000470
Následující příklad vypíše část sektoru ze zvoleného blokového zařízení, dejte si ovšem pozor, že od bude poctivě „seekovat“ na zadaný offset:
sudo od -j 100000000 -N 256 -v -t x1 /dev/sda1 ... ... ...
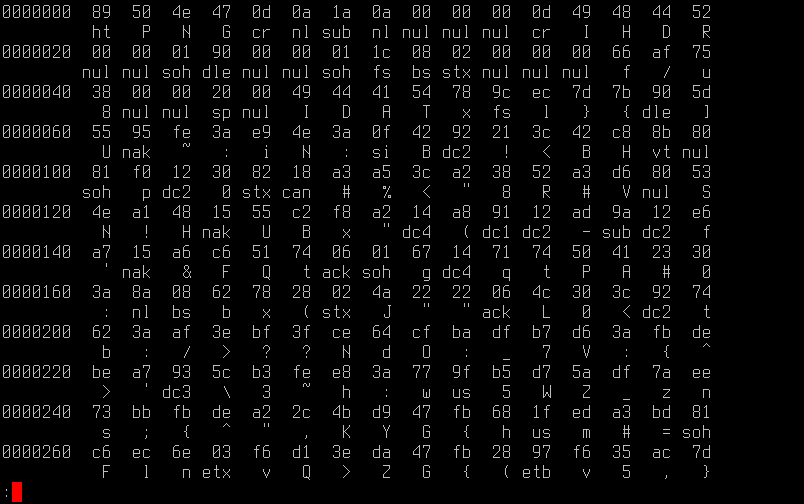
Obrázek 2: Alternativní způsob, kdy se kromě kódů znaků zobrazí i jejich jméno v ASCII.
2. Uložení obsahu vektoru do textového souboru se specifikací oddělovače
Začneme tím nejjednodušším možným případem; konkrétně se bude jednat o uložení obsahu desetiprvkového vektoru do textového souboru, a to navíc se specifikací oddělovače jednotlivých prvků. Jako oddělovat zvolíme čárku:
"""Uložení obsahu vektoru do textového souboru se specifikací oddělovače."""
import numpy as np
# vektor obsahující celočíselné 8bitové hodnoty (byte)
v = np.linspace(1, 10, 10, dtype="b")
print(v)
v.tofile("vector1.txt", sep=",")
Obsah vygenerovaného souboru by měl vypadat následovně – jedná se o jediný řádek se všemi hodnotami:
1,2,3,4,5,6,7,8,9,10
Alternativně je možné si zvolit formát jednotlivých prvků. Ve výchozím nastavení odpovídá formát „nejčitelnější“ variantě, ovšem snadno můžeme například zajistit, aby se hodnoty prvků umístily do uvozovek, apostrofů atd. atd.:
"""Uložení obsahu vektoru do textového souboru se specifikací oddělovače a
formátu jednotlivých prvků."""
import numpy as np
# vektor obsahující celočíselné 8bitové hodnoty (byte)
v = np.linspace(1, 10, 10, dtype="b")
print(v)
v.tofile("vector2.txt", sep=",", format='"%s"')
Výsledek:
"1","2","3","4","5","6","7","8","9","10"
3. Uložení obsahu vektoru do binárního souboru
V případě, že se oddělovač neuvede, bude vektor uložen do binárního souboru. V takovém případě záleží konkrétní způsob uložení na tom, jakého typu jsou prvky vektoru. Abychom si vše ilustrovali, budeme do binárního souboru ukládat vektory s prvky různých typů a následně se podíváme na délku i obsah výsledného souboru.
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující celočíselné 8bitové hodnoty (byte)
v = np.linspace(1, 10, 10, dtype="b")
print(v)
v.tofile("vector3.bin")
Soubor s délkou deseti bajtů:
$ od -t x1 vector3.bin 0000000 01 02 03 04 05 06 07 08 09 0a 0000012
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující celočíselné 16bitové hodnoty (half integer)
v = np.linspace(1, 10, 10, dtype="h")
print(v)
v.tofile("vector4.bin")
Vytvoří se soubor s délkou dvaceti bajtů, který si prohlédneme odlišným způsobem – dekadicky:
$ od -t d2 vector4.bin 0000000 1 2 3 4 5 6 7 8 0000020 9 10 0000024
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující celočíselné 32bitové hodnoty (integer)
v = np.linspace(1, 10, 10, dtype="i")
print(v)
v.tofile("vector5.bin")
V tomto případě si soubor prohlédneme jak „dekadicky“, tak i s hexadecimálním výstupem:
$ od -t d4 vector5.bin 0000000 1 2 3 4 0000020 5 6 7 8 0000040 9 10 0000050 $ od -t x1 vector5.bin 0000000 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 0000020 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00 0000040 09 00 00 00 0a 00 00 00 0000050
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující celočíselné 64bitové hodnoty (long integer)
v = np.linspace(1, 10, 10, dtype="l")
print(v)
v.tofile("vector6.bin")
Výsledky:
$ od -t d8 vector6.bin 0000000 1 2 0000020 3 4 0000040 5 6 0000060 7 8 0000100 9 10 0000120 $ od -t x1 vector6.bin 0000000 01 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 0000020 03 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 0000040 05 00 00 00 00 00 00 00 06 00 00 00 00 00 00 00 0000060 07 00 00 00 00 00 00 00 08 00 00 00 00 00 00 00 0000100 09 00 00 00 00 00 00 00 0a 00 00 00 00 00 00 00 0000120
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující hodnoty s plovoucí řádovou čárkou
# s jednoduchou přesností (float, single)
v = np.linspace(1, 10, 10, dtype="f")
print(v)
v.tofile("vector7.bin")
V tomto případě je nejvýhodnější formát f4:
$ od -t f4 vector7.bin 0000000 1 2 3 4 0000020 5 6 7 8 0000040 9 10 0000050 $ od -t x1 vector7.bin 0000000 00 00 80 3f 00 00 00 40 00 00 40 40 00 00 80 40 0000020 00 00 a0 40 00 00 c0 40 00 00 e0 40 00 00 00 41 0000040 00 00 10 41 00 00 20 41 0000050
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující hodnoty s plovoucí řádovou čárkou
# s dvojitou přesností (double)
v = np.linspace(1, 10, 10, dtype="d")
print(v)
v.tofile("vector8.bin")
Výsledky:
$ od -t f8 vector8.bin 0000000 1 2 0000020 3 4 0000040 5 6 0000060 7 8 0000100 9 10 0000120 $ od -t x1 vector8.bin 0000000 00 00 00 00 00 00 f0 3f 00 00 00 00 00 00 00 40 0000020 00 00 00 00 00 00 08 40 00 00 00 00 00 00 10 40 0000040 00 00 00 00 00 00 14 40 00 00 00 00 00 00 18 40 0000060 00 00 00 00 00 00 1c 40 00 00 00 00 00 00 20 40 0000100 00 00 00 00 00 00 22 40 00 00 00 00 00 00 24 40 0000120
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující hodnoty s plovoucí řádovou čárkou
# s poloviční přesností (half)
v = np.linspace(1, 10, 10, dtype="e")
print(v)
v.tofile("vector9.bin")
Tento formát není nástrojem od podporován, takže si budeme muset vystačit s převodem na hexadecimální hodnoty:
$ od -t x1 vector9.bin 0000000 00 3c 00 40 00 42 00 44 00 45 00 46 00 47 00 48 0000020 80 48 00 49 0000024
4. Načtení obsahu vektoru z textového popř. binárního souboru
Opakem uložení vektoru je jeho načtení ze souboru. To je většinou triviální, což si ostatně ukážeme na několika příkladech. Nejdříve načtení obsahu vektoru z textového souboru se specifikací oddělovače:
"""Načtení obsahu vektoru z textového souboru se specifikací oddělovače."""
import numpy as np
v = np.fromfile("vector1.txt", sep=",")
print(v)
Specifikovat můžeme i konverzi na kýžený datový typ:
"""Načtení obsahu vektoru z textového souboru se specifikací oddělovače a s konverzí."""
import numpy as np
v = np.fromfile("vector1.txt", sep=",").astype("i")
print(v)
Pokus o načtení vektoru z binárního souboru bez uvedení datového typu většinou povede k chybě:
"""Načtení obsahu vektoru z binárního souboru (nekorektní použití)."""
import numpy as np
v = np.fromfile("vector4.bin")
print(v)
V naprosté většině případů je nutné specifikovat, jakého typu jsou prvky vektoru v době, kdy došlo k jeho uložení do binárního souboru:
"""Načtení obsahu vektoru z binárního souboru s konverzí."""
import numpy as np
v = np.fromfile("vector4.bin", dtype="h")
print(v)
5. Uložení obsahu matice do textového souboru se specifikací oddělovače i do souboru binárního
Naprosto stejným způsobem jako s vektory se pracuje s maticemi, protože pro metodu tofile se stále jedná o pouhou sekvenci prvků (ztrácí se tedy informace o tvaru – „shape“ matice!):
"""Uložení obsahu matice do textového souboru se specifikací oddělovače."""
import numpy as np
# matice obsahující celočíselné 8bitové hodnoty (byte)
m = np.linspace(1, 12, 12, dtype="b").reshape(3, 4)
print(m)
m.tofile("matrix1.txt", sep=",")
Uložení matice do binárního souboru je opět snadné:
"""Uložení obsahu matice do binárního souboru."""
import numpy as np
# matice obsahující celočíselné 8bitové hodnoty (byte)
m = np.linspace(1, 12, 12, dtype="b").reshape(3, 4)
print(m)
m.tofile("matrix2.bin")
Při načítání matice ve skutečnosti získáme pouhý jednorozměrný vektor, který je nutné na matici převést metodou reshape:
"""Načtení obsahu matice z textového souboru se specifikací oddělovače."""
import numpy as np
m = np.fromfile("matrix1.txt", sep=",").reshape(3, 4)
print(m)
Provést můžeme i přetypování prvků po jejich načtení:
"""Načtení obsahu matice z textového souboru se specifikací oddělovače."""
import numpy as np
m = np.fromfile("matrix1.txt", sep=",").reshape(3, 4).astype("b")
print(m)
Následující příklad bude funkční pouze za předpokladu, že prvky matice měly formát int64. Obecně je vhodné při každém načítání binárních souborů použít explicitní specifikaci typu prvků:
"""Načtení obsahu matice z binárního souboru bez specifikace formátu."""
import numpy as np
m = np.fromfile("matrix2.bin").reshape(3, 4)
print(m)
Takto je to správně – explicitně uvádíme jak typ prvků, tak i požadovaný výsledný tvar matice:
"""Načtení obsahu matice z binárního souboru se specifikací formátu."""
import numpy as np
m = np.fromfile("matrix2.bin", dtype="b").reshape(3, 4)
print(m)
6. Standardní binární soubor knihovny NumPy
Z předchozích kapitol je patrné, že je sice možné n-rozměrná pole ukládat do binárních souborů, ale bude se jednat skutečně pouze o čisté hodnoty prvků. Žádné další informace se neuloží – tedy ani typ prvků ani tvar pole. To není ani zdaleka ideální situace a proto byl vyvinut dnes již standardní binární formát určený pro ukládání n-rozměrných polí. Tento formát se nazývá NPY a jeho popis lze nalézt na stránce https://numpy.org/devdocs/reference/generated/numpy.lib.format.html. Jedná se o přímou serializaci pole do souboru, ovšem před vlastní hodnoty prvků je uložena jednoduchá hlavička se všemi důležitými informacemi – včetně endianity, kterou jsme prozatím vůbec neřešili.
7. Standardní binární soubor pro vektory
Vektor s prvky libovolného typu se uloží do standardního binárního formátu funkcí save. Té je možné (a vhodné) předat parametr allow_pickle=False aby se zabránilo případné serializaci objektů:
"""Uložení obsahu vektoru do standardního binárního souboru."""
import numpy as np
# vektor obsahující hodnoty s plovoucí řádovou čárkou
# s poloviční přesností (half)
v = np.linspace(1, 10, 10, dtype="e")
print(v)
np.save("vector.npy", v, allow_pickle=False)
Výsledný soubor si vypíšeme jak v hexadecimálním tvaru, tak i jako sekvenci znaků:
$ od -t x1z -v vector.npy
0000000 93 4e 55 4d 50 59 01 00 76 00 7b 27 64 65 73 63 >.NUMPY..v.{'desc<
0000020 72 27 3a 20 27 3c 66 32 27 2c 20 27 66 6f 72 74 >r': '<f2', 'fort<
0000040 72 61 6e 5f 6f 72 64 65 72 27 3a 20 46 61 6c 73 >ran_order': Fals<
0000060 65 2c 20 27 73 68 61 70 65 27 3a 20 28 31 30 2c >e, 'shape': (10,<
0000100 29 2c 20 7d 20 20 20 20 20 20 20 20 20 20 20 20 >), } <
0000120 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 > <
0000140 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 > <
0000160 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 0a > .<
0000200 00 3c 00 40 00 42 00 44 00 45 00 46 00 47 00 48 >.<.@.B.D.E.F.G.H<
0000220 80 48 00 49 >.H.I<
0000224
Hlavička v tomto případě obsahuje mj. i informace o typu prvků „f2“ i o tvaru pole (v čitelném tvaru). Samotná data začínají na offsetu 128 (tedy 200 oktalově).
Tento binární soubor s obsahem vektoru lze načíst velmi snadno, a to konkrétně funkcí numpy.load():
"""Přečtení obsahu vektoru ze standardního binárního souboru."""
import numpy as np
v = np.load("vector.npy")
print(v)
print(v.dtype)
8. Uložení a načtení matice do/ze standardního binárního souboru
Naprosto stejným způsobem jako s vektory se v případě standardního binárního souboru NPY pracuje s maticemi. Uložení matice:
"""Uložení obsahu matice do standardního binárního souboru."""
import numpy as np
# matice obsahující celočíselné 8bitové hodnoty (byte)
m = np.linspace(1, 12, 12, dtype="b").reshape(3, 4)
print(m)
np.save("matrix1.npy", m, allow_pickle=False)
Zpětné načtení matice:
"""Přečtení obsahu matice ze standardního binárního souboru."""
import numpy as np
m = np.load("matrix1.npy")
print(m)
print(m.dtype)
Přitom je vytvořen tento soubor:
$ od -Ax -t x1z -v matrix1.npy
000000 93 4e 55 4d 50 59 01 00 76 00 7b 27 64 65 73 63 >.NUMPY..v.{'desc<
000010 72 27 3a 20 27 7c 69 31 27 2c 20 27 66 6f 72 74 >r': '|i1', 'fort<
000020 72 61 6e 5f 6f 72 64 65 72 27 3a 20 46 61 6c 73 >ran_order': Fals<
000030 65 2c 20 27 73 68 61 70 65 27 3a 20 28 33 2c 20 >e, 'shape': (3, <
000040 34 29 2c 20 7d 20 20 20 20 20 20 20 20 20 20 20 >4), } <
000050 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 > <
000060 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 > <
000070 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 0a > .<
000080 01 02 03 04 05 06 07 08 09 0a 0b 0c >............<
00008c
Stejný příklad, ovšem s maticí obsahující prvky typu „float“:
"""Uložení obsahu matice do standardního binárního souboru."""
import numpy as np
m = np.linspace(1, 12, 12, dtype="f").reshape(3, 4)
print(m)
np.save("matrix2.npy", m, allow_pickle=False)
Zpětné načtení matice:
"""Přečtení obsahu matice ze standardního binárního souboru."""
import numpy as np
m = np.load("matrix2.npy")
print(m)
print(m.dtype)
Druhý binární soubor má obsah:
$ od -Ax -t x1z -v matrix2.npy
000000 93 4e 55 4d 50 59 01 00 76 00 7b 27 64 65 73 63 >.NUMPY..v.{'desc<
000010 72 27 3a 20 27 3c 66 34 27 2c 20 27 66 6f 72 74 >r': '<f4', 'fort<
000020 72 61 6e 5f 6f 72 64 65 72 27 3a 20 46 61 6c 73 >ran_order': Fals<
000030 65 2c 20 27 73 68 61 70 65 27 3a 20 28 33 2c 20 >e, 'shape': (3, <
000040 34 29 2c 20 7d 20 20 20 20 20 20 20 20 20 20 20 >4), } <
000050 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 > <
000060 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 > <
000070 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 0a > .<
000080 00 00 80 3f 00 00 00 40 00 00 40 40 00 00 80 40 >...?...@..@@...@<
000090 00 00 a0 40 00 00 c0 40 00 00 e0 40 00 00 00 41 >...@...@...@...A<
0000a0 00 00 10 41 00 00 20 41 00 00 30 41 00 00 40 41 >...A.. A..0A..@A<
0000b0
9. Binární soubory a knihovna Pandas
Práce s n-dimenzionálními poli uloženými do binárních souborů je přímočará, protože všechny prvky vektorů, matic i vícedimenzionálních polí musí být stejného typu. To znamená, že binární soubory obsahují prvky uložené v jediném formátu. Ovšem v případě knihovny Pandas je situace odlišná, neboť datové rámce (data frame) obecně mohou mít každý sloupec jiného typu. Tato skutečnost se odráží i v tom, že do knihovny Pandas lze načítat datové soubory s poměrně flexibilní binární strukturou. Dnes si ukážeme základní práci s binárními soubory, u nichž je nutné dodržet pouze jedinou podmínku – všechny řádky musí mít shodnou délku (počítanou v bajtech) a i všechny prvky musí být stejně široké. V praxi to tedy znamená především to, že jsme omezeni na řetězce pevné délky (což je ovšem v binárních souborech velmi časté a mnohdy i užitečné – zejména při nutnosti častých seeků na n-tý záznam.
10. Načtení obsahu datové řady z binárního souboru s konverzí
Začneme nejdříve tím nejjednodušším možným případem, konkrétně s načtením datové řady (Series). Nejprve do binárního souboru uložíme běžný vektor, konkrétně desetiprvkový vektor s 16bitovými celými čísly:
"""Uložení obsahu vektoru do binárního souboru."""
import numpy as np
# vektor obsahující celočíselné 16bitové hodnoty (half integer)
v = np.linspace(1, 10, 10, dtype="h")
print(v)
v.tofile("vector4.bin")
Tento vektor můžeme zpětně načíst (což již velmi dobře známe z předchozích kapitol). A následně tento vektor převedeme na datovou řadu konstruktorem pandas.Series:
"""Načtení obsahu datové řady z binárního souboru s konverzí."""
import numpy as np
import pandas as pd
v = np.fromfile("vector4.bin", dtype="h")
s = pd.Series(v)
print(s)
print()
print(s.describe())
Výsledkem je podle očekávání datová řada s deseti prvky a automaticky vytvořenými indexy:
0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 dtype: int16 count 10.00000 mean 5.50000 std 3.02765 min 1.00000 25% 3.25000 50% 5.50000 75% 7.75000 max 10.00000 dtype: float64
11. Načtení obsahu datového rámce z binárního souboru se specifikací formátu
Podobně přímočaré je načtení datového rámce v případě, že všechny sloupce datového rámce mají shodný formát. V tomto případě načteme běžnou matici a tu na datový rámec převedeme:
"""Načtení obsahu datového rámce z binárního souboru se specifikací formátu."""
import numpy as np
import pandas as pd
m = np.fromfile("matrix2.bin", dtype="b").reshape(3, 4)
df = pd.DataFrame(m)
print(df)
print()
print(df.info())
print()
print(df.describe())
Tento skript po svém spuštění nejdříve vypíše obsah matice a poté i informace o zkonstruovaném datovém rámci:
0 1 2 3
0 1 2 3 4
1 5 6 7 8
2 9 10 11 12
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 3 non-null int8
1 1 3 non-null int8
2 2 3 non-null int8
3 3 3 non-null int8
dtypes: int8(4)
memory usage: 140.0 bytes
None
0 1 2 3
count 3.0 3.0 3.0 3.0
mean 5.0 6.0 7.0 8.0
std 4.0 4.0 4.0 4.0
min 1.0 2.0 3.0 4.0
25% 3.0 4.0 5.0 6.0
50% 5.0 6.0 7.0 8.0
75% 7.0 8.0 9.0 10.0
max 9.0 10.0 11.0 12.0
12. Vygenerování binárního souboru se dvěma sloupci čísel s různou reprezentací
Pro vytvoření binárního souboru, který obsahuje dva sloupce numerických hodnot (každý ovšem s odlišnou reprezentací) poslouží následující zdrojový kód napsaný v ANSI C. Každý pomyslný řádek obsahuje celočíselnou hodnotu typu int a taktéž hodnotu reprezentovanou v systému plovoucí řádové čárky (float). Povšimněte si, že tento program může vygenerovat soubory různé délky (podle šířky typu int) a navíc nikde nespecifikujeme endianitu hodnot. Výsledek tedy nebude přenositelný na různé architektury:
#include <stdio.h>
int main(void) {
FILE *fout;
int i;
fout = fopen("binary_df_1.bin", "w");
if (!fout) {
return 1;
}
for (i=1; i<11; i++) {
float x = 1.0/i;
fwrite(&i, sizeof(int), 1, fout);
fwrite(&x, sizeof(float), 1, fout);
}
fclose(fout);
return 0;
}
Na platformě x86–64 by měl vzniknout soubor o délce přesně osmdesáti bajtů, protože jak typ int, tak i float jsou uloženy ve čtyřech bajtech:
$ od -t x1 binary_df_1.bin 0000000 01 00 00 00 00 00 80 3f 02 00 00 00 00 00 00 3f 0000020 03 00 00 00 ab aa aa 3e 04 00 00 00 00 00 80 3e 0000040 05 00 00 00 cd cc 4c 3e 06 00 00 00 ab aa 2a 3e 0000060 07 00 00 00 25 49 12 3e 08 00 00 00 00 00 00 3e 0000100 09 00 00 00 39 8e e3 3d 0a 00 00 00 cd cc cc 3d 0000120
01 00 00 00
13. Načtení binárního souboru s různými typy sloupců do datového rámce
Binární soubor vytvořený programem uvedeným v předchozí kapitole lze relativně snadno načíst do datového rámce. Celý postup se přitom skládá z několika kroků:
- Specifikace typů dat pro jednotlivé sloupce
- Načtení binárního souboru do specifického n-dimenzionálního pole (s n-ticemi)
- Konverze tohoto pole na běžný datový rámec
Povšimněte si, jakým způsobem jsou definovány typy sloupců – uvedeme mapování mezi názvem sloupce a kódem jeho datového typu, kde například „u4“ znamená celočíselnou hodnotu bez znaménka uloženou ve čtyřech bajtech, „f4“ hodnotu typu float uloženou ve čtyřech bajtech atd.:
# specifikace typů dat jednotlivých sloupců
dt = np.dtype([
("i", "u4"),
("x", "f4")
])
Úplný skript vypadá následovně:
"""Načtení obsahu datového rámce z binárního souboru se specifikací formátu."""
import numpy as np
import pandas as pd
# specifikace typů dat jednotlivých sloupců
dt = np.dtype([
("i", "u4"),
("x", "f4")
])
np_data = np.fromfile("binary_df_1.bin", dtype=dt)
print(np_data)
print(np_data.ndim)
print(np_data.dtype)
df = pd.DataFrame(np_data)
print(df)
print()
print(df.info())
print()
print(df.describe())
Skript po svém spuštění nejdříve vypíše obsah načteného pole. Z tohoto výpisu je patrné, že se jedná o n-tice:
[( 1, 1. ) ( 2, 0.5 ) ( 3, 0.33333334) ( 4, 0.25 ) ( 5, 0.2 ) ( 6, 0.16666667) ( 7, 0.14285715) ( 8, 0.125 ) ( 9, 0.11111111) (10, 0.1 )]
Dále se vypíše počet dimenzí tohoto pole (což je v tomto případě konkrétně jednodimenzionální vektor) a datový typ prvků:
1
[('i', '<u4'), ('x', '<f4')]
A nakonec se vypíše vytvořený datový rámec a další informace o tomto rámci:
i x
0 1 1.000000
1 2 0.500000
2 3 0.333333
3 4 0.250000
4 5 0.200000
5 6 0.166667
6 7 0.142857
7 8 0.125000
8 9 0.111111
9 10 0.100000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 i 10 non-null uint32
1 x 10 non-null float32
dtypes: float32(1), uint32(1)
memory usage: 208.0 bytes
None
i x
count 10.00000 10.000000
mean 5.50000 0.292897
std 3.02765 0.277265
min 1.00000 0.100000
25% 3.25000 0.129464
50% 5.50000 0.183333
75% 7.75000 0.312500
max 10.00000 1.000000
14. Specifikace endianity dat
Při specifikaci typů prvků uložených v jednotlivých sloupcích lze specifikovat i jejich endianitu. Provádí se to pomocí znaků < a >. Například na architektuře x86–64 se očekává little endian a tedy:
dt = np.dtype([
("i", "<u4"),
("x", "<f4")
])
Schválně se ale podívejme na to, co se stane, pokud při načítání binárního souboru s little endian budeme u celočíselných prvků definovat opačnou endianitu, tedy big endian (viz zvýrazněný programový řádek):
"""Načtení obsahu datového rámce z binárního souboru se specifikací formátu."""
import numpy as np
import pandas as pd
dt = np.dtype([
("i", ">u4"),
("x", "<f4")
])
np_data = np.fromfile("binary_df_1.bin", dtype=dt)
print(np_data)
print(np_data.ndim)
print(np_data.dtype)
df = pd.DataFrame(np_data)
print(df)
print()
print(df.info())
print()
print(df.describe())
Z vypsaných výsledků je patrné, že se data sice načetla, ale například místo hodnoty 1 dostaneme hodnotu 16777216 atd. Je tak tomu z toho důvodu, že jedničku lze reprezentovat jako sekvenci bajtů 00 00 00 01, ovšem my jsme namísto toho načetli 01 00 00 00, což se na celé číslo převede formou 1×224:
[( 16777216, 1. ) ( 33554432, 0.5 ) ( 50331648, 0.33333334)
( 67108864, 0.25 ) ( 83886080, 0.2 ) (100663296, 0.16666667)
(117440512, 0.14285715) (134217728, 0.125 ) (150994944, 0.11111111)
(167772160, 0.1 )]
1
[('i', '>u4'), ('x', '<f4')]
i x
0 16777216 1.000000
1 33554432 0.500000
2 50331648 0.333333
3 67108864 0.250000
4 83886080 0.200000
5 100663296 0.166667
6 117440512 0.142857
7 134217728 0.125000
8 150994944 0.111111
9 167772160 0.100000
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 i 10 non-null >u4
1 x 10 non-null float32
dtypes: float32(1), uint32(1)
memory usage: 208.0 bytes
None
i x
count 1.000000e+01 10.000000
mean 9.227469e+07 0.292897
std 5.079554e+07 0.277265
min 1.677722e+07 0.100000
25% 5.452595e+07 0.129464
50% 9.227469e+07 0.183333
75% 1.300234e+08 0.312500
max 1.677722e+08 1.000000
15. Vygenerování binárního souboru se dvěma sloupci čísel s různou reprezentací a se sloupcem s řetězci
Ve dvanácté kapitole jsme si ukázali program napsaný v ANSI C, který po svém spuštění vytvořil binární soubor obsahující dva sloupce číselných hodnot. Tento program nyní nepatrně upravíme takovým způsobem, aby se ukládal ještě jeden sloupec hodnot – tentokrát ovšem řetězců. Pro jednoduchost prozatím budeme generovat řetězce pevné délky (a dokonce se ani nebude jednat o klasické céčkovské řetězce, protože nebude ukládána koncová nula). Ostatně s řetězci pevné délky se v binárních souborech můžeme setkat relativně často:
#include <stdio.h>
char* names[] = {
"odd ",
"even"
};
int main(void) {
FILE *fout;
int i;
fout = fopen("binary_df_2.bin", "w");
if (!fout) {
return 1;
}
for (i=1; i<11; i++) {
float x = 1.0/i;
fwrite(&i, sizeof(int), 1, fout);
fwrite(&x, sizeof(float), 1, fout);
fwrite(names[i%2], 4, 1, fout);
}
fclose(fout);
return 0;
}
Výsledkem by měl být na platformě x86–64 binární soubor o délce 120 bajtů – to konkrétně znamená, že každý řádek obsahuje přesně dvanáct bajtů (čtyři pro celočíselnou hodnotu, další čtyři pro hodnotu s plovoucí řádovou čárkou a poslední čtyři bajty pro uložení čtyřech znaků řetězce):
$ od -t x1 binary_df_2.bin 0000000 01 00 00 00 00 00 80 3f 65 76 65 6e 02 00 00 00 0000020 00 00 00 3f 6f 64 64 20 03 00 00 00 ab aa aa 3e 0000040 65 76 65 6e 04 00 00 00 00 00 80 3e 6f 64 64 20 0000060 05 00 00 00 cd cc 4c 3e 65 76 65 6e 06 00 00 00 0000100 ab aa 2a 3e 6f 64 64 20 07 00 00 00 25 49 12 3e 0000120 65 76 65 6e 08 00 00 00 00 00 00 3e 6f 64 64 20 0000140 09 00 00 00 39 8e e3 3d 65 76 65 6e 0a 00 00 00 0000160 cd cc cc 3d 6f 64 64 20 0000170
16. Načtení obsahu datového rámce z binárního souboru obsahujícího řetězce pevné délky
Binární soubor vytvořený v rámci předchozí kapitoly je možné načíst do datového rámce knihovny Pandas. Musíme ovšem opět explicitně specifikovat datové typy jednotlivých sloupců. První dva typy (pro celá čísla i typ float) již známe, takže nám zbývá určit, že další čtyři bajty obsahují znaky (tedy dohromady řetězec). Použijeme kód „S4“:
dt = np.dtype([
("i", "<u4"),
("x", "<f4"),
("type", "S4"),
])
Celý skript, který binární soubor načte a vytvoří z něho datový rámec, bude vypadat takto:
"""Načtení obsahu datového rámce z binárního souboru se specifikací formátu."""
import numpy as np
import pandas as pd
dt = np.dtype([
("i", "<u4"),
("x", "<f4"),
("type", "S4"),
])
np_data = np.fromfile("binary_df_2.bin", dtype=dt)
print(np_data)
print(np_data.ndim)
print(np_data.dtype)
df = pd.DataFrame(np_data)
print(df)
print()
print(df.info())
print()
print(df.describe())
Po spuštění tohoto skriptu se nejprve vypíše informace o surových načtených datech:
[( 1, 1. , b'even') ( 2, 0.5 , b'odd ')
( 3, 0.33333334, b'even') ( 4, 0.25 , b'odd ')
( 5, 0.2 , b'even') ( 6, 0.16666667, b'odd ')
( 7, 0.14285715, b'even') ( 8, 0.125 , b'odd ')
( 9, 0.11111111, b'even') (10, 0.1 , b'odd ')]
1
[('i', '<u4'), ('x', '<f4'), ('type', 'S4')]
Dále se již vypíše obsah samotného datového rámce, metainformace o tomto rámci a statistika:
i x type
0 1 1.000000 b'even'
1 2 0.500000 b'odd '
2 3 0.333333 b'even'
3 4 0.250000 b'odd '
4 5 0.200000 b'even'
5 6 0.166667 b'odd '
6 7 0.142857 b'even'
7 8 0.125000 b'odd '
8 9 0.111111 b'even'
9 10 0.100000 b'odd '
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 i 10 non-null uint32
1 x 10 non-null float32
2 type 10 non-null object
dtypes: float32(1), object(1), uint32(1)
memory usage: 288.0+ bytes
None
i x
count 10.00000 10.000000
mean 5.50000 0.292897
std 3.02765 0.277265
min 1.00000 0.100000
25% 3.25000 0.129464
50% 5.50000 0.183333
75% 7.75000 0.312500
max 10.00000 1.000000
17. Převod sekvence bajtů na řetězec
Demonstrační příklad z předchozí kapitoly ve skutečnosti nevytvořil sloupec „type“ obsahující řetězce, protože se jednalo o sekvenci bajtů, která se v Pythonu liší od skutečných řetězců, v nichž se mohou vyskytovat všechny znaky Unicode. Pro převod sekvence bajtů na řetězec pochopitelně musíme znát způsob kódování. Můžeme předpokládat například dnes pravděpodobně nejpoužívanější kódování UTF-8. Potom bude konverze obsahu sloupce „type“ vypadat následovně:
df["type"] = df["type"].str.decode("utf-8")
Předchozí demonstrační příklad můžeme snadno přepsat do podoby, která vytvoří datový rámec, v jehož sloupci „type“ již bude uložený skutečný řetězec:
"""Načtení obsahu datového rámce z binárního souboru se specifikací formátu."""
import numpy as np
import pandas as pd
dt = np.dtype([
("i", "<u4"),
("x", "<f4"),
("type", "S4"),
])
np_data = np.fromfile("binary_df_2.bin", dtype=dt)
print(np_data)
print(np_data.ndim)
print(np_data.dtype)
df = pd.DataFrame(np_data)
df["type"] = df["type"].str.decode("utf-8")
print(df)
print()
print(df.info())
print()
print(df.describe())
Po spuštění se nejprve vypíše informace o surových načtených datech:
[( 1, 1. , b'even') ( 2, 0.5 , b'odd ')
( 3, 0.33333334, b'even') ( 4, 0.25 , b'odd ')
( 5, 0.2 , b'even') ( 6, 0.16666667, b'odd ')
( 7, 0.14285715, b'even') ( 8, 0.125 , b'odd ')
( 9, 0.11111111, b'even') (10, 0.1 , b'odd ')]
1
[('i', '<u4'), ('x', '<f4'), ('type', 'S4')]
A posléze se vypíše i datový rámec vytvořený konverzí i základní metainformace a statistické informace o tomto rámci:
i x type
0 1 1.000000 even
1 2 0.500000 odd
2 3 0.333333 even
3 4 0.250000 odd
4 5 0.200000 even
5 6 0.166667 odd
6 7 0.142857 even
7 8 0.125000 odd
8 9 0.111111 even
9 10 0.100000 odd
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 i 10 non-null uint32
1 x 10 non-null float32
2 type 10 non-null object
dtypes: float32(1), object(1), uint32(1)
memory usage: 288.0+ bytes
None
i x
count 10.00000 10.000000
mean 5.50000 0.292897
std 3.02765 0.277265
min 1.00000 0.100000
25% 3.25000 0.129464
50% 5.50000 0.183333
75% 7.75000 0.312500
max 10.00000 1.000000
18. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů určených pro Python 3 a nejnovější stabilní verzi knihoven Numpy a Pandas byly uloženy do Git repositáře dostupného na adrese https://github.com/tisnik/most-popular-python-libs. V případě, že nebudete chtít klonovat celý repositář (ten je ovšem stále velmi malý, dnes má velikost zhruba několik desítek kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následujících tabulkách.
Příklady určené pouze pro knihovnu Numpy:

| # | Demonstrační příklad | Stručný popis příkladu | Cesta |
|---|---|---|---|
| 1 | vector_to_file1.py | uložení obsahu vektoru do textového souboru se specifikací oddělovače | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file1.py |
| 2 | vector_to_file2.py | uložení obsahu vektoru do textového souboru se specifikací oddělovače a formátu jednotlivých prvků | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file2.py |
| 3 | vector_to_file3.py | uložení obsahu vektoru s prvky typu „byte“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file3.py |
| 4 | vector_to_file4.py | uložení obsahu vektoru s prvky typu „half integer“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file4.py |
| 5 | vector_to_file5.py | uložení obsahu vektoru s prvky typu „integer“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file5.py |
| 6 | vector_to_file6.py | uložení obsahu vektoru s prvky typu „long integer“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file6.py |
| 7 | vector_to_file7.py | uložení obsahu vektoru s prvky typu „single“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file7.py |
| 8 | vector_to_file8.py | uložení obsahu vektoru s prvky typu „double“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file8.py |
| 9 | vector_to_file9.py | uložení obsahu vektoru s prvky typu „half“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_to_file9.py |
| 10 | vector_from_file1.py | načtení obsahu vektoru z textového souboru se specifikací oddělovače | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_from_file1.py |
| 11 | vector_from_file2.py | načtení obsahu vektoru z textového souboru se specifikací oddělovače a s konverzí | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_from_file2.py |
| 12 | vector_from_file3.py | načtení obsahu vektoru z binárního souboru (nekorektní použití) | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_from_file3.py |
| 13 | vector_from_file4.py | načtení obsahu vektoru z binárního souboru s konverzí | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_from_file4.py |
| 14 | vector_save.py | uložení obsahu vektoru do standardního binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_save.py |
| 15 | vector_load.py | načtení obsahu vektoru ze standardního binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/vector_load.py |
| 16 | matrix_save1.py | uložení matice s prvky typu „byte“ do standardního binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_save1.py |
| 17 | matrix_save2.py | uložení matice s prvky typu „float“ do standardního binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_save2.py |
| 18 | matrix_load1.py | načtení matice s prvky typu „byte“ ze standardního binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_load1.py |
| 19 | matrix_load2.py | načtení matice s prvky typu „float“ ze standardního binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_load2.py |
| 20 | matrix_to_file1.py | export obsahu matice do textového souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_to_file1.py |
| 21 | matrix_to_file2.py | export obsahu matice do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_to_file2.py |
| 22 | matrix_from_file1.py | načtení matice z textového souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_from_file1.py |
| 23 | matrix_from_file2.py | načtení matice z textového souboru s konverzí na jiný typ | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_from_file2.py |
| 24 | matrix_from_file3.py | načtení matice z binárního souboru bez specifikace formátu | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_from_file3.py |
| 25 | matrix_from_file4.py | načtení matice z binárního souboru se specifikací formátu | https://github.com/tisnik/most-popular-python-libs/blob/master/numpy/matrix_from_file4.py |
Příklady určené pro knihovnu Pandas:
| # | Demonstrační příklad | Stručný popis příkladu | Cesta |
|---|---|---|---|
| 1 | vector_to_file4.py | uložení obsahu vektoru s prvky typu „half integer“ do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/vector_to_file4.py |
| 2 | matrix_to_file2.py | export obsahu matice do binárního souboru | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/matrix_to_file2.py |
| 3 | binary_df1.c | vygenerování binárního souboru s prvky různých typů | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/binary_df1.c |
| 4 | binary_df2.c | vygenerování binárního souboru s prvky různých typů, včetně řetězců | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/binary_df2.c |
| 5 | serie_from_file.py | načtení obsahu datové řady z binárního souboru s konverzí | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/serie_from_file.py |
| 6 | dataframe_from_file1.py | načtení obsahu datového rámce z binárního souboru se specifikací formátu společného pro všechny sloupce | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/dataframe_from_file1.py |
| 7 | dataframe_from_file2.py | načtení obsahu datového rámce z binárního souboru se specifikací formátu | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/dataframe_from_file2.py |
| 8 | dataframe_from_file3.py | načtení obsahu datového rámce z binárního souboru se specifikací formátu i endianity | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/dataframe_from_file3.py |
| 9 | dataframe_from_file4.py | načtení obsahu datového rámce z binárního souboru se specifikací formátu i endianity, bytové pole | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/dataframe_from_file4.py |
| 10 | dataframe_from_file5.py | načtení obsahu datového rámce z binárního souboru se specifikací formátu i endianity, řetězce | https://github.com/tisnik/most-popular-python-libs/blob/master/pandas/dataframe_from_file5.py |
19. Odkazy na předchozí části seriálu o knihovně Pandas
Popisem knihovny Pandas (a do jisté míry i Numpy) jsme se již na stránkách Roota zabývali. Pod tímto odstavcem naleznete odkazy na jednotlivé články, které již o knihovně Pandas vyšly:
- Knihovna Pandas: základy práce s datovými rámci
https://www.root.cz/clanky/knihovna-pandas-zaklady-prace-s-datovymi-ramci/ - Knihovna Pandas: zobrazení obsahu datových rámců, vykreslení grafů a validace dat
https://www.root.cz/clanky/knihovna-pandas-zobrazeni-obsahu-datovych-ramcu-vykresleni-grafu-a-validace-dat/ - Knihovna Pandas: práce s datovými řadami (series)
https://www.root.cz/clanky/knihovna-pandas-prace-s-datovymi-radami-series/ - Knihovna Pandas: pokročilejší práce s datovými řadami (series)
https://www.root.cz/clanky/knihovna-pandas-pokrocilejsi-prace-s-datovymi-radami-series/ - Knihovna Pandas: spojování datových rámců s využitím append, concat, merge a join
https://www.root.cz/clanky/knihovna-pandas-spojovani-datovych-ramcu-s-vyuzitim-append-concat-merge-a-join/ - Knihovna Pandas: použití metody groupby, naformátování a export tabulek pro tisk
https://www.root.cz/clanky/knihovna-pandas-pouziti-metody-groupby-naformatovani-a-export-tabulek-pro-tisk/ - Knihovna Pandas: práce se seskupenými záznamy, vytvoření multiindexů
https://www.root.cz/clanky/knihovna-pandas-prace-se-seskupenymi-zaznamy-vytvoreni-multiindexu/
20. Odkazy na Internetu
- A Simple File Format for NumPy Arrays
https://docs.scipy.org/doc/numpy-1.14.2/neps/npy-format.html - numpy.lib.format
https://numpy.org/devdocs/reference/generated/numpy.lib.format.html - The NumPy array: a structure for efficient numerical computation
https://arxiv.org/pdf/1102.1523.pdf - numpy.ndarray.tofile
https://numpy.org/doc/stable/reference/generated/numpy.ndarray.tofile.html#numpy.ndarray.tofile - numpy.fromfile
https://numpy.org/doc/stable/reference/generated/numpy.fromfile.html - How to read part of binary file with numpy?
https://stackoverflow.com/questions/14245094/how-to-read-part-of-binary-file-with-numpy - How to read binary files in Python using NumPy?
https://stackoverflow.com/questions/39762019/how-to-read-binary-files-in-python-using-numpy - numpy.save
https://numpy.org/doc/stable/reference/generated/numpy.save.html#numpy.save - numpy.load
https://numpy.org/doc/stable/reference/generated/numpy.load.html#numpy.load - Loading binary data to NumPy/Pandas
https://towardsdatascience.com/loading-binary-data-to-numpy-pandas-9caa03eb0672 - Combining Data in Pandas With merge(), .join(), and concat()
https://realpython.com/pandas-merge-join-and-concat/ - Repositář python-tabulate na GitHubu
https://github.com/astanin/python-tabulate - python-tabulate na PyPi
https://pypi.org/project/tabulate/ - Understanding Pandas groupby() function
https://www.askpython.com/python-modules/pandas/pandas-groupby-function - Python Pandas – GroupBy
https://www.tutorialspoint.com/python_pandas/python_pandas_groupby.htm - Pandas GroupBy: Group Data in Python
https://pythonspot.com/pandas-groupby/ - JOIN
https://cs.wikipedia.org/wiki/JOIN - Plotting with matplotlib
https://pandas.pydata.org/pandas-docs/version/0.13/visualization.html - Plot With Pandas: Python Data Visualization for Beginners
https://realpython.com/pandas-plot-python/ - Pandas Dataframe: Plot Examples with Matplotlib and Pyplot
https://queirozf.com/entries/pandas-dataframe-plot-examples-with-matplotlib-pyplot - Opulent-Pandas na PyPi
https://pypi.org/project/opulent-pandas/ - pandas_validator na PyPi
https://pypi.org/project/pandas_validator/ - pandas-validator (dokumentace)
https://pandas-validator.readthedocs.io/en/latest/ - 7 Best Python Libraries for Validating Data
https://www.yeahhub.com/7-best-python-libraries-validating-data/ - Universally unique identifier (Wikipedia)
https://en.wikipedia.org/wiki/Universally_unique_identifier - Nullable integer data type
https://pandas.pydata.org/pandas-docs/stable/user_guide/integer_na.html - pandas.read_csv
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html - How to define format when using pandas to_datetime?
https://stackoverflow.com/questions/36848514/how-to-define-format-when-using-pandas-to-datetime - Pandas : skip rows while reading csv file to a Dataframe using read_csv() in Python
https://thispointer.com/pandas-skip-rows-while-reading-csv-file-to-a-dataframe-using-read_csv-in-python/ - Skip rows during csv import pandas
https://stackoverflow.com/questions/20637439/skip-rows-during-csv-import-pandas - Denni kurz
https://www.cnb.cz/cs/financni_trhy/devizovy_trh/kurzy_devizoveho_trhu/denni_kurz.txt - UUID objects according to RFC 4122 (knihovna pro Python)
https://docs.python.org/3.5/library/uuid.html#uuid.uuid4 - Object identifier (Wikipedia)
https://en.wikipedia.org/wiki/Object_identifier - Digital object identifier (Wikipedia)
https://en.wikipedia.org/wiki/Digital_object_identifier - voluptuous na (na PyPi)
https://pypi.python.org/pypi/voluptuous - Repositář knihovny voluptuous na GitHubu
https://github.com/alecthomas/voluptuous - pytest-voluptuous 1.0.2 (na PyPi)
https://pypi.org/project/pytest-voluptuous/ - pytest-voluptuous (na GitHubu)
https://github.com/F-Secure/pytest-voluptuous - schemagic 0.9.1 (na PyPi)
https://pypi.python.org/pypi/schemagic/0.9.1 - Schemagic / Schemagic.web (na GitHubu)
https://github.com/Mechrophile/schemagic - schema 0.6.7 (na PyPi)
https://pypi.python.org/pypi/schema - schema (na GitHubu)
https://github.com/keleshev/schema - XML Schema validator and data conversion library for Python
https://github.com/brunato/xmlschema - xmlschema 0.9.7
https://pypi.python.org/pypi/xmlschema/0.9.7 - jsonschema 2.6.0
https://pypi.python.org/pypi/jsonschema - warlock 1.3.0
https://pypi.python.org/pypi/warlock - Python Virtual Environments – A Primer
https://realpython.com/python-virtual-environments-a-primer/ - pip 1.1 documentation: Requirements files
https://pip.readthedocs.io/en/1.1/requirements.html - unittest.mock — mock object library
https://docs.python.org/3.5/library/unittest.mock.html - mock 2.0.0
https://pypi.python.org/pypi/mock - An Introduction to Mocking in Python
https://www.toptal.com/python/an-introduction-to-mocking-in-python - Unit testing (Wikipedia)
https://en.wikipedia.org/wiki/Unit_testing - Unit testing
https://cs.wikipedia.org/wiki/Unit_testing - Test-driven development (Wikipedia)
https://en.wikipedia.org/wiki/Test-driven_development - Pip (dokumentace)
https://pip.pypa.io/en/stable/ - 5 Differences between clojure.spec and Schema
https://lispcast.com/clojure.spec-vs-schema/ - Schema: Clojure(Script) library for declarative data description and validation
https://github.com/plumatic/schema - clojure.spec – Rationale and Overview
https://clojure.org/about/spec



































