
Obsah
1. Podpora SIMD operací v GCC s využitím intrinsic: technologie SSE
2. Nové typy vektorů, nimiž je možné provádět SIMD operace
3. Intrinsics dostupné v překladači GCC C pro využití technologie SSE
4. Součet 128bitových vektorů s celočíselnými prvky
5. Překlad všech čtyř operací součtu do assembleru s povolením SSE operací
6. Součet dvou vektorů s prvky typu float a double
7. Překlad obou operací součtu do assembleru s povolením SSE operací
8. Porovnání celočíselných prvků instrukcemi pcmpeqb128 a pcmpgtb128
9. Překlad obou operací porovnání do assembleru s povolením SSE operací
10. Všech šest relačních operací pro vektory s prvky typu float
11. Překlad všech šesti operací porovnání do assembleru s povolením SSE operací
13. Instrukce určené pro přeskupení, promíchání a výběr prvků uložených ve dvojici vektorů
14. Instrukce shufps a její intrinsic
15. Překlad demonstračního příkladu do assembleru
16. Instrukce unpckhps a unpcklps a jejich intrinsics
17. Překlad demonstračního příkladu do assembleru
18. Příloha – soubor Makefile použitý v článcích o SIMD operacích
19. Repositář s demonstračními příklady
1. Podpora SIMD operací v GCC s využitím intrinsic: technologie SSE
Na předchozí článek o nepřímém využití SIMD operací založeném na použití intrinsic v překladači GCC C dnes navážeme. Minule jsme se zabývali především dnes již poněkud zastaralou (ale stále podporovanou) instrukční sadou MMX s 64bitovými vektory. Dnes se zaměříme na technologii SSE se 128bitovými vektory, kterých je navíc mnohem více, než tomu je v případě MMX. A vzhledem k tomu, že SSE byla představena již před více než dvaceti lety, je dnes široce podporována (neboli čipy, které ji nepodporovaly, již zastaraly; o to zajímavější je fakt, že stále ještě nejsme v situaci, kdy všechny významné překladače a interpretry dokáží provádět kvalitní autovektorizaci).
Na platformě x86–64 je (v oblasti SIMD operací) dostupných několik skupin intrinsic, které jsou vypsány v následující tabulce:
| Technologie | Hlavičkový soubor |
|---|---|
| MMX | mmintrin.h |
| SSE1 | xmmintrin.h |
| SSE2 | emmintrin.h |
| SSE4.1 | smmintrin.h |
| AVX2 | avx2intrin.h |
Nejprve se (pro krátké zopakování) zaměřme na pracovní registry využívané v technologii SSE. U mikroprocesorů implementujících instrukční sadu SSE je využita nová sada registrů pojmenovaných XMM0 až XMM7. Na 64bitové platformě (původně architektura AMD 64, dnes pochopitelně podporováno i Intelem) navíc došlo k přidání dalších osmi registrů se jmény XMM8 až XMM15 využitelných pouze v 64bitovém režimu. Všechny nové registry mají šířku 128 bitů, což je oproti MMX znatelné vylepšení. Navíc byl přidán ještě řídicí registr MXCSR, o jehož významu se zmíníme později:
| # | Typ registrů | Počet registrů | Bitová šířka registru | Příklady |
|---|---|---|---|---|
| 1 | Pracovní registry SSE | 8 | 128 bitů | XMM0 .. XMM7 (XMM15) |
| 2 | Řídicí registr SSE | 1 | 32 bitů | MXCSR |
Obrázek 1: Sada nových pracovních registrů přidaných v rámci rozšíření instrukční sady SSE.
V rámci technologie SSE byla instrukční sada mikroprocesorů s architekturou x86 (a později x86–64) rozšířena o několik typů instrukcí, které většinou pracovaly s již výše zmíněnými registry XMM*, popř. taktéž s operační pamětí nebo s obecnými celočíselnými 32bitovými registry procesorů x86, tj. například s registrem EAX. Všechny nové instrukce je možné rozdělit do několika kategorií:
| # | Kategorie | Příklad instrukce |
|---|---|---|
| 1 | Přenosy dat | MOVUPS, MOVAPS, MOVHPS, MOVLPS… |
| 2 | Aritmetické operace | ADDPS, SUBPS, MULPS, DIVPS, RCPPS… |
| 3 | Porovnání | CMPEQSS, CMPEQPS, CMPLTSS, CMPNLTSS, … |
| 4 | Logické operace | ANDPS, ANDNPS, ORPS, XORPS |
| 5 | Přenosy mezi prvky vektorů (shuffle) a konverze | SHUFPS, UNPCKHPS, UNPCKLPS |
| 6 | Načtení dat do cache | PREFETCH0, … |
Obrázek 2: Některé instrukce zavedené v rámci SSE pracují pouze s dvojicí skalárních hodnot.
Technologie SSE2 představená v roce 2000 vývojářům přinesla nové instrukce a samozřejmě i podstatné změny v interní struktuře vektorové výpočetní jednotky (například dále zmíněnou podporu datového typu double), ovšem počet registrů ani jejich bitová šířka se nijak nezměnila. Programátoři používající, ať již přímo či nepřímo, rozšíření instrukční sady SSE2 mohli do osmice 128bitových registrů pojmenovaných XMM* ukládat celkem šest různých typů vektorů. Základ zůstal nezměněn – jednalo se o čtyřprvkové vektory obsahující čísla reprezentovaná ve formátu plovoucí řádové čárky, přičemž každé číslo bylo uloženo v 32 bitech (4×32=128 bitů), což odpovídá typu single/float definovanému v normě IEEE 754. Kromě toho byly v rámci SSE2 ještě zavedeny dvouprvkové vektory obsahující taktéž hodnoty reprezentované ve formátu plovoucí řádové čárky, ovšem tentokrát se jedná o čísla uložená v 64 bitech (2×64=128) odpovídající dvojité přesnosti (double) z normy IEEE 754.
Zbývají nám ovšem ještě čtyři další podporované datové typy. Jedná se o vektory s celočíselnými prvky: šestnáctiprvkové vektory s osmibitovými hodnotami, osmiprvkové vektory s šestnáctibitovými hodnotami, čtyřprvkové vektory s 32bitovými hodnotami a konečně dvouprvkové vektory s 64bitovými celočíselnými hodnotami.

Obrázek 3: Nové typy vektorů, s kterými je nově možné nativně pracovat na mikroprocesorech podporujících technologii SSE2.
2. Nové typy vektorů, nimiž je možné provádět SIMD operace
Při použití technologie SSE (SSE2 atd.) se používají vektory o šířce 128 bitů. Tyto vektory je možné rozdělit na celočíselné prvky popř. na prvky s hodnotami reprezentovanými s využitím systému plovoucí řádové čárky. V následující tabulce jsou všechny možné a podporované kombinace vypsány:
| Typ v C | Význam | Deklarace |
|---|---|---|
| _v16qi | 16 celočíselných prvků, každý o šířce 8bitů (pro C++) | typedef char __v16qi __attribute__ ((__vector_size__ (16))); |
| _v16qs | 16 celočíselných prvků se znaménkem, každý o šířce 8bitů | typedef signed char __v16qs __attribute__ ((__vector_size__ (16))); |
| _v8hi | 8 celočíselných prvků se znaménkem, každý o šířce 16bitů | typedef short __v8hi __attribute__ ((__vector_size__ (16))); |
| _v4si | 4 celočíselné prvky se znaménkem, každý o šířce 32bitů | typedef int __v4si __attribute__ ((__vector_size__ (16))); |
| _v2di | 2 celočíselné prvky se znaménkem, každý o šířce 64bitů | typedef long long __v2di __attribute__ ((__vector_size__ (16))); |
| _v16qu | 16 celočíselných prvků bez znaménka, každý o šířce 8bitů | typedef unsigned char __v16qu __attribute__ ((__vector_size__ (16))); |
| _v8hu | 8 celočíselných prvků bez znaménka, každý o šířce 16bitů | typedef unsigned short __v8hu __attribute__ ((__vector_size__ (16))); |
| _v4su | 4 celočíselné prvky bez znaménka, každý o šířce 32bitů | typedef unsigned int __v4su __attribute__ ((__vector_size__ (16))); |
| _v2du | 2 celočíselné prvky bez znaménka, každý o šířce 64bitů | typedef unsigned long long __v2du __attribute__ ((__vector_size__ (16))); |
| _v4sf | čtyři prvky typu float | typedef float __v4sf __attribute__ ((__vector_size__ (16))); |
| _v2df | dva prvky typu double | typedef double __v2df __attribute__ ((__vector_size__ (16))); |
3. Intrinsics dostupné v překladači GCC C pro využití technologie SSE
Pro prakticky každou SSE instrukci (z původního SSE 1) existuje příslušná intrinsic. Všechny tyto intrinsic jsou vypsány pod tímto odstavcem (typy parametrů a návratových hodnot byly uvedeny v předchozí kapitole):
int __builtin_ia32_comieq (v4sf, v4sf); int __builtin_ia32_comineq (v4sf, v4sf); int __builtin_ia32_comilt (v4sf, v4sf); int __builtin_ia32_comile (v4sf, v4sf); int __builtin_ia32_comigt (v4sf, v4sf); int __builtin_ia32_comige (v4sf, v4sf); int __builtin_ia32_ucomieq (v4sf, v4sf); int __builtin_ia32_ucomineq (v4sf, v4sf); int __builtin_ia32_ucomilt (v4sf, v4sf); int __builtin_ia32_ucomile (v4sf, v4sf); int __builtin_ia32_ucomigt (v4sf, v4sf); int __builtin_ia32_ucomige (v4sf, v4sf); v4sf __builtin_ia32_addps (v4sf, v4sf); v4sf __builtin_ia32_subps (v4sf, v4sf); v4sf __builtin_ia32_mulps (v4sf, v4sf); v4sf __builtin_ia32_divps (v4sf, v4sf); v4sf __builtin_ia32_addss (v4sf, v4sf); v4sf __builtin_ia32_subss (v4sf, v4sf); v4sf __builtin_ia32_mulss (v4sf, v4sf); v4sf __builtin_ia32_divss (v4sf, v4sf); v4sf __builtin_ia32_cmpeqps (v4sf, v4sf); v4sf __builtin_ia32_cmpltps (v4sf, v4sf); v4sf __builtin_ia32_cmpleps (v4sf, v4sf); v4sf __builtin_ia32_cmpgtps (v4sf, v4sf); v4sf __builtin_ia32_cmpgeps (v4sf, v4sf); v4sf __builtin_ia32_cmpunordps (v4sf, v4sf); v4sf __builtin_ia32_cmpneqps (v4sf, v4sf); v4sf __builtin_ia32_cmpnltps (v4sf, v4sf); v4sf __builtin_ia32_cmpnleps (v4sf, v4sf); v4sf __builtin_ia32_cmpngtps (v4sf, v4sf); v4sf __builtin_ia32_cmpngeps (v4sf, v4sf); v4sf __builtin_ia32_cmpordps (v4sf, v4sf); v4sf __builtin_ia32_cmpeqss (v4sf, v4sf); v4sf __builtin_ia32_cmpltss (v4sf, v4sf); v4sf __builtin_ia32_cmpless (v4sf, v4sf); v4sf __builtin_ia32_cmpunordss (v4sf, v4sf); v4sf __builtin_ia32_cmpneqss (v4sf, v4sf); v4sf __builtin_ia32_cmpnltss (v4sf, v4sf); v4sf __builtin_ia32_cmpnless (v4sf, v4sf); v4sf __builtin_ia32_cmpordss (v4sf, v4sf); v4sf __builtin_ia32_maxps (v4sf, v4sf); v4sf __builtin_ia32_maxss (v4sf, v4sf); v4sf __builtin_ia32_minps (v4sf, v4sf); v4sf __builtin_ia32_minss (v4sf, v4sf); v4sf __builtin_ia32_andps (v4sf, v4sf); v4sf __builtin_ia32_andnps (v4sf, v4sf); v4sf __builtin_ia32_orps (v4sf, v4sf); v4sf __builtin_ia32_xorps (v4sf, v4sf); v4sf __builtin_ia32_movss (v4sf, v4sf); v4sf __builtin_ia32_movhlps (v4sf, v4sf); v4sf __builtin_ia32_movlhps (v4sf, v4sf); v4sf __builtin_ia32_unpckhps (v4sf, v4sf); v4sf __builtin_ia32_unpcklps (v4sf, v4sf); v4sf __builtin_ia32_cvtpi2ps (v4sf, v2si); v4sf __builtin_ia32_cvtsi2ss (v4sf, int); v2si __builtin_ia32_cvtps2pi (v4sf); int __builtin_ia32_cvtss2si (v4sf); v2si __builtin_ia32_cvttps2pi (v4sf); int __builtin_ia32_cvttss2si (v4sf); v4sf __builtin_ia32_rcpps (v4sf); v4sf __builtin_ia32_rsqrtps (v4sf); v4sf __builtin_ia32_sqrtps (v4sf); v4sf __builtin_ia32_rcpss (v4sf); v4sf __builtin_ia32_rsqrtss (v4sf); v4sf __builtin_ia32_sqrtss (v4sf); v4sf __builtin_ia32_shufps (v4sf, v4sf, int); void __builtin_ia32_movntps (float *, v4sf); int __builtin_ia32_movmskps (v4sf);
nt __builtin_ia32_comisdeq (v2df, v2df); int __builtin_ia32_comisdlt (v2df, v2df); int __builtin_ia32_comisdle (v2df, v2df); int __builtin_ia32_comisdgt (v2df, v2df); int __builtin_ia32_comisdge (v2df, v2df); int __builtin_ia32_comisdneq (v2df, v2df); int __builtin_ia32_ucomisdeq (v2df, v2df); int __builtin_ia32_ucomisdlt (v2df, v2df); int __builtin_ia32_ucomisdle (v2df, v2df); int __builtin_ia32_ucomisdgt (v2df, v2df); int __builtin_ia32_ucomisdge (v2df, v2df); int __builtin_ia32_ucomisdneq (v2df, v2df); v2df __builtin_ia32_cmpeqpd (v2df, v2df); v2df __builtin_ia32_cmpltpd (v2df, v2df); v2df __builtin_ia32_cmplepd (v2df, v2df); v2df __builtin_ia32_cmpgtpd (v2df, v2df); v2df __builtin_ia32_cmpgepd (v2df, v2df); v2df __builtin_ia32_cmpunordpd (v2df, v2df); v2df __builtin_ia32_cmpneqpd (v2df, v2df); v2df __builtin_ia32_cmpnltpd (v2df, v2df); v2df __builtin_ia32_cmpnlepd (v2df, v2df); v2df __builtin_ia32_cmpngtpd (v2df, v2df); v2df __builtin_ia32_cmpngepd (v2df, v2df); v2df __builtin_ia32_cmpordpd (v2df, v2df); v2df __builtin_ia32_cmpeqsd (v2df, v2df); v2df __builtin_ia32_cmpltsd (v2df, v2df); v2df __builtin_ia32_cmplesd (v2df, v2df); v2df __builtin_ia32_cmpunordsd (v2df, v2df); v2df __builtin_ia32_cmpneqsd (v2df, v2df); v2df __builtin_ia32_cmpnltsd (v2df, v2df); v2df __builtin_ia32_cmpnlesd (v2df, v2df); v2df __builtin_ia32_cmpordsd (v2df, v2df); v2di __builtin_ia32_paddq (v2di, v2di); v2di __builtin_ia32_psubq (v2di, v2di); v2df __builtin_ia32_addpd (v2df, v2df); v2df __builtin_ia32_subpd (v2df, v2df); v2df __builtin_ia32_mulpd (v2df, v2df); v2df __builtin_ia32_divpd (v2df, v2df); v2df __builtin_ia32_addsd (v2df, v2df); v2df __builtin_ia32_subsd (v2df, v2df); v2df __builtin_ia32_mulsd (v2df, v2df); v2df __builtin_ia32_divsd (v2df, v2df); v2df __builtin_ia32_minpd (v2df, v2df); v2df __builtin_ia32_maxpd (v2df, v2df); v2df __builtin_ia32_minsd (v2df, v2df); v2df __builtin_ia32_maxsd (v2df, v2df); v2df __builtin_ia32_andpd (v2df, v2df); v2df __builtin_ia32_andnpd (v2df, v2df); v2df __builtin_ia32_orpd (v2df, v2df); v2df __builtin_ia32_xorpd (v2df, v2df); v2df __builtin_ia32_movsd (v2df, v2df); v2df __builtin_ia32_unpckhpd (v2df, v2df); v2df __builtin_ia32_unpcklpd (v2df, v2df); v16qi __builtin_ia32_paddb128 (v16qi, v16qi); v8hi __builtin_ia32_paddw128 (v8hi, v8hi); v4si __builtin_ia32_paddd128 (v4si, v4si); v2di __builtin_ia32_paddq128 (v2di, v2di); v16qi __builtin_ia32_psubb128 (v16qi, v16qi); v8hi __builtin_ia32_psubw128 (v8hi, v8hi); v4si __builtin_ia32_psubd128 (v4si, v4si); v2di __builtin_ia32_psubq128 (v2di, v2di); v8hi __builtin_ia32_pmullw128 (v8hi, v8hi); v8hi __builtin_ia32_pmulhw128 (v8hi, v8hi); v2di __builtin_ia32_pand128 (v2di, v2di); v2di __builtin_ia32_pandn128 (v2di, v2di); v2di __builtin_ia32_por128 (v2di, v2di); v2di __builtin_ia32_pxor128 (v2di, v2di); v16qi __builtin_ia32_pavgb128 (v16qi, v16qi); v8hi __builtin_ia32_pavgw128 (v8hi, v8hi); v16qi __builtin_ia32_pcmpeqb128 (v16qi, v16qi); v8hi __builtin_ia32_pcmpeqw128 (v8hi, v8hi); v4si __builtin_ia32_pcmpeqd128 (v4si, v4si); v16qi __builtin_ia32_pcmpgtb128 (v16qi, v16qi); v8hi __builtin_ia32_pcmpgtw128 (v8hi, v8hi); v4si __builtin_ia32_pcmpgtd128 (v4si, v4si); v16qi __builtin_ia32_pmaxub128 (v16qi, v16qi); v8hi __builtin_ia32_pmaxsw128 (v8hi, v8hi); v16qi __builtin_ia32_pminub128 (v16qi, v16qi); v8hi __builtin_ia32_pminsw128 (v8hi, v8hi); v16qi __builtin_ia32_punpckhbw128 (v16qi, v16qi); v8hi __builtin_ia32_punpckhwd128 (v8hi, v8hi); v4si __builtin_ia32_punpckhdq128 (v4si, v4si); v2di __builtin_ia32_punpckhqdq128 (v2di, v2di); v16qi __builtin_ia32_punpcklbw128 (v16qi, v16qi); v8hi __builtin_ia32_punpcklwd128 (v8hi, v8hi); v4si __builtin_ia32_punpckldq128 (v4si, v4si); v2di __builtin_ia32_punpcklqdq128 (v2di, v2di); v16qi __builtin_ia32_packsswb128 (v8hi, v8hi); v8hi __builtin_ia32_packssdw128 (v4si, v4si); v16qi __builtin_ia32_packuswb128 (v8hi, v8hi); v8hi __builtin_ia32_pmulhuw128 (v8hi, v8hi); void __builtin_ia32_maskmovdqu (v16qi, v16qi); v2df __builtin_ia32_loadupd (double *); void __builtin_ia32_storeupd (double *, v2df); v2df __builtin_ia32_loadhpd (v2df, double const *); v2df __builtin_ia32_loadlpd (v2df, double const *); int __builtin_ia32_movmskpd (v2df); int __builtin_ia32_pmovmskb128 (v16qi); void __builtin_ia32_movnti (int *, int); void __builtin_ia32_movnti64 (long long int *, long long int); void __builtin_ia32_movntpd (double *, v2df); void __builtin_ia32_movntdq (v2df *, v2df); v4si __builtin_ia32_pshufd (v4si, int); v8hi __builtin_ia32_pshuflw (v8hi, int); v8hi __builtin_ia32_pshufhw (v8hi, int); v2di __builtin_ia32_psadbw128 (v16qi, v16qi); v2df __builtin_ia32_sqrtpd (v2df); v2df __builtin_ia32_sqrtsd (v2df); v2df __builtin_ia32_shufpd (v2df, v2df, int); v2df __builtin_ia32_cvtdq2pd (v4si); v4sf __builtin_ia32_cvtdq2ps (v4si); v4si __builtin_ia32_cvtpd2dq (v2df); v2si __builtin_ia32_cvtpd2pi (v2df); v4sf __builtin_ia32_cvtpd2ps (v2df); v4si __builtin_ia32_cvttpd2dq (v2df); v2si __builtin_ia32_cvttpd2pi (v2df); v2df __builtin_ia32_cvtpi2pd (v2si); int __builtin_ia32_cvtsd2si (v2df); int __builtin_ia32_cvttsd2si (v2df); long long __builtin_ia32_cvtsd2si64 (v2df); long long __builtin_ia32_cvttsd2si64 (v2df); v4si __builtin_ia32_cvtps2dq (v4sf); v2df __builtin_ia32_cvtps2pd (v4sf); v4si __builtin_ia32_cvttps2dq (v4sf); v2df __builtin_ia32_cvtsi2sd (v2df, int); v2df __builtin_ia32_cvtsi642sd (v2df, long long); v4sf __builtin_ia32_cvtsd2ss (v4sf, v2df); v2df __builtin_ia32_cvtss2sd (v2df, v4sf); void __builtin_ia32_clflush (const void *); void __builtin_ia32_lfence (void); void __builtin_ia32_mfence (void); v16qi __builtin_ia32_loaddqu (const char *); void __builtin_ia32_storedqu (char *, v16qi); v1di __builtin_ia32_pmuludq (v2si, v2si); v2di __builtin_ia32_pmuludq128 (v4si, v4si); v8hi __builtin_ia32_psllw128 (v8hi, v8hi); v4si __builtin_ia32_pslld128 (v4si, v4si); v2di __builtin_ia32_psllq128 (v2di, v2di); v8hi __builtin_ia32_psrlw128 (v8hi, v8hi); v4si __builtin_ia32_psrld128 (v4si, v4si); v2di __builtin_ia32_psrlq128 (v2di, v2di); v8hi __builtin_ia32_psraw128 (v8hi, v8hi); v4si __builtin_ia32_psrad128 (v4si, v4si); v2di __builtin_ia32_pslldqi128 (v2di, int); v8hi __builtin_ia32_psllwi128 (v8hi, int); v4si __builtin_ia32_pslldi128 (v4si, int); v2di __builtin_ia32_psllqi128 (v2di, int); v2di __builtin_ia32_psrldqi128 (v2di, int); v8hi __builtin_ia32_psrlwi128 (v8hi, int); v4si __builtin_ia32_psrldi128 (v4si, int); v2di __builtin_ia32_psrlqi128 (v2di, int); v8hi __builtin_ia32_psrawi128 (v8hi, int); v4si __builtin_ia32_psradi128 (v4si, int); v4si __builtin_ia32_pmaddwd128 (v8hi, v8hi); v2di __builtin_ia32_movq128 (v2di);
Zapomenout nesmíme ani na rozšíření SSE3 s několika novými instrukcemi a k nim příslušejícími intrinsics:
sse3v2df __builtin_ia32_addsubpd (v2df, v2df) v2df __builtin_ia32_addsubps (v2df, v2df) v2df __builtin_ia32_haddpd (v2df, v2df) v2df __builtin_ia32_haddps (v2df, v2df) v2df __builtin_ia32_hsubpd (v2df, v2df) v2df __builtin_ia32_hsubps (v2df, v2df) v16qi __builtin_ia32_lddqu (char const *) void __builtin_ia32_monitor (void *, unsigned int, unsigned int) v2df __builtin_ia32_movddup (v2df) v4sf __builtin_ia32_movshdup (v4sf) v4sf __builtin_ia32_movsldup (v4sf) void __builtin_ia32_mwait (unsigned int, unsigned int)
4. Součet 128bitových vektorů s celočíselnými prvky
Nejprve si pro jednoduchost ukažme, jak lze provádět součty 128bitových vektorů, v nichž jsou uloženy celočíselné prvky. Na výběr jsou čtyři typy těchto vektorů:
- 16 prvků s šířkou 8bitů (char)
- 8 prvků s šířkou 16bitů (short)
- 4 prvky s šířkou 32bitů (int)
- 2 prvky s šířkou 64bitů (long)
Součet dvou vektorů s šestnácti prvky typu char:
#include <stdio.h>
#include <xmmintrin.h>
int main(void)
{
__v16qi x = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
__v16qi y = x;
__v16qi z;
int i;
z = __builtin_ia32_paddb128(x, y);
for (i = 0; i < sizeof(x) / sizeof(char); i++) {
printf("%2d %2d %2d %2d\n", i, x[i], y[i], z[i]);
}
}
Výsledky:
0 1 1 2 1 2 2 4 2 3 3 6 3 4 4 8 4 5 5 10 5 6 6 12 6 7 7 14 7 8 8 16 8 9 9 18 9 10 10 20 10 11 11 22 11 12 12 24 12 13 13 26 13 14 14 28 14 15 15 30 15 16 16 32
Součet dvou vektorů s osmi prvky typu short:
#include <stdio.h>
#include <xmmintrin.h>
int main(void)
{
__v8hi x = { 1, 2, 3, 4, 5, 6, 7, 8 };
__v8hi y = x;
__v8hi z;
int i;
z = __builtin_ia32_paddw128(x, y);
for (i = 0; i < sizeof(x) / sizeof(short int); i++) {
printf("%2d %2d %2d %2d\n", i, x[i], y[i], z[i]);
}
}
Výsledky:
0 1 1 2 1 2 2 4 2 3 3 6 3 4 4 8 4 5 5 10 5 6 6 12 6 7 7 14 7 8 8 16
Součet dvou vektorů se čtyřmi prvky typu int:
#include <stdio.h>
#include <xmmintrin.h>
int main(void)
{
__v4si x = { 1, 2, 3, 4 };
__v4si y = x;
__v4si z;
int i;
z = __builtin_ia32_paddd128(x, y);
for (i = 0; i < sizeof(x) / sizeof(int); i++) {
printf("%2d %2d %2d %2d\n", i, x[i], y[i], z[i]);
}
}
Výsledky:
0 1 1 2 1 2 2 4 2 3 3 6 3 4 4 8
Součet dvou vektorů se dvěma prvky typu long:
#include <stdio.h>
#include <xmmintrin.h>
int main(void)
{
__v2di x = { 1, 2 };
__v2di y = x;
__v2di z;
int i;
z = __builtin_ia32_paddq128(x, y);
for (i = 0; i < sizeof(x) / sizeof(long int); i++) {
printf("%2d %2Ld %2Ld %2Ld\n", i, x[i], y[i], z[i]);
}
}
Výsledky:
0 1 1 2 1 2 2 4
5. Překlad všech čtyř operací součtu do assembleru s povolením SSE operací
Podívejme se nyní na způsob překladu všech čtyř výše uvedených operací součtu do assembleru. Pro stručnost bude uveden jen samotný výpočet a instrukce určené pro načtení vektorů do registrů a pro uložení výsledku zpět do paměti (na zásobník):
z = __builtin_ia32_paddb128(x, y); 30: 66 0f 6f 45 d0 movdqa xmm0,XMMWORD PTR [rbp-0x30] 35: 66 0f 6f 4d c0 movdqa xmm1,XMMWORD PTR [rbp-0x40] 3a: 66 0f fc c1 paddb xmm0,xmm1 3e: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
z = __builtin_ia32_paddw128(x, y); 30: 66 0f 6f 45 d0 movdqa xmm0,XMMWORD PTR [rbp-0x30] 35: 66 0f 6f 4d c0 movdqa xmm1,XMMWORD PTR [rbp-0x40] 3a: 66 0f fd c1 paddw xmm0,xmm1 3e: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
z = __builtin_ia32_paddd128(x, y); 30: 66 0f 6f 45 d0 movdqa xmm0,XMMWORD PTR [rbp-0x30] 35: 66 0f 6f 4d c0 movdqa xmm1,XMMWORD PTR [rbp-0x40] 3a: 66 0f fe c1 paddd xmm0,xmm1 3e: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
z = __builtin_ia32_paddq128(x, y); 30: 66 0f 6f 45 d0 movdqa xmm0,XMMWORD PTR [rbp-0x30] 35: 66 0f 6f 4d c0 movdqa xmm1,XMMWORD PTR [rbp-0x40] 3a: 66 0f d4 c1 paddq xmm0,xmm1 3e: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
6. Součet dvou vektorů s prvky typu float a double
Mnoho výpočtů se v praxi provádí s prvky typu float a double, tedy nad numerickými hodnotami s plovoucí řádovou čárkou. „Vektorové“ varianty základních aritmetických operací samozřejmě existují a jsou dostupné i přes intrinsic. Podívejme se nejdříve na součet dvou vektorů s prvky typu float:
#include <stdio.h>
#include <xmmintrin.h>
int main(void)
{
__v4sf x = { 1.0, 2.0, 3.0, 4.0 };
__v4sf y = { 0.1, 0.1, 0.1, 0.1 };
__v4sf z;
int i;
z = __builtin_ia32_addps(x, y);
for (i = 0; i < sizeof(x) / sizeof(float); i++) {
printf("%2d %f %f %f\n", i, x[i], y[i], z[i]);
}
}
Výsledky:
0 1.000000 0.100000 1.100000 1 2.000000 0.100000 2.100000 2 3.000000 0.100000 3.100000 3 4.000000 0.100000 4.100000
Součet prvků typu double uložených do dvojice vektorů:
#include <stdio.h>
#include <xmmintrin.h>
int main(void)
{
__v2df x = { 1.0, 2.0 };
__v2df y = { 0.1, 0.1 };
__v2df z;
int i;
z = __builtin_ia32_addpd(x, y);
for (i = 0; i < sizeof(x) / sizeof(double); i++) {
printf("%2d %lf %lf %lf\n", i, x[i], y[i], z[i]);
}
}
Výsledky:
0 1.000000 0.100000 1.100000 1 2.000000 0.100000 2.100000
7. Překlad obou operací součtu do assembleru s povolením SSE operací
Intrinsic v předchozích dvou zdrojových kódech nám napovídají, jak asi bude vypadat výsledek překladu do assembleru.
Součet dvou vektorů s prvky typu float:
z = __builtin_ia32_addps(x, y); 31: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] 35: 0f 28 4d c0 movaps xmm1,XMMWORD PTR [rbp-0x40] 39: 0f 58 c1 addps xmm0,xmm1 3c: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Délka instrukce addps je pouhé tři bajty.
Součet prvků typu double uložených do dvojice vektorů:
z = __builtin_ia32_addpd(x, y); 33: 66 0f 28 45 d0 movapd xmm0,XMMWORD PTR [rbp-0x30] 38: 66 0f 28 4d c0 movapd xmm1,XMMWORD PTR [rbp-0x40] 3d: 66 0f 58 c1 addpd xmm0,xmm1 41: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
8. Porovnání celočíselných prvků instrukcemi pcmpeqb128 a pcmpgtb128
V praxi se poměrně často setkáme s nutností porovnání hodnot uložených ve dvou polích. Takové operace lze převést do „vektorizované“ podoby s využitím SIMD intrinsic. Pro vektory s celočíselnými operandy pro tento účel existují instrukce pcmpeqX128 a pcmpgtX128, kde se za X dosadí konkrétní datový typ. Například pro vektory s prvky typu char se použijí instrukce se jmény pcmpeqb128 a pcmpgtb128, kde eqz znamená test na rovnost a gt test na relaci „větší než“. Ostatní relace lze z těchto dvou odvodit, a to buď prohozením vektorů nebo negací výsledků.
Pokusme se nyní porovnat prvky dvou vektorů, z nichž každý obsahuje šestnáct prvků typu char. Celý kód může vypadat následovně:
#include <stdio.h>
#include <xmmintrin.h>
void print_results(const char *title, __v16qi *x, __v16qi *y, __v16qi *z)
{
int i;
puts(title);
for (i = 0; i < sizeof(*x) / sizeof(char); i++) {
printf("%2d %2d %2d %s\n", i, (*x)[i], (*y)[i], (*z)[i] == 0 ? "no":"yes");
}
putchar('\n');
}
int main(void)
{
__v16qi x = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 };
__v16qi y = { 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8 };
__v16qi z;
z = __builtin_ia32_pcmpeqb128(x, y);
print_results(" # x y x==y?", &x, &y, &z);
z = __builtin_ia32_pcmpgtb128(x, y);
print_results(" # x y x>y?", &x, &y, &z);
}
Výsledek získaný po spuštění tohoto demonstračního příkladu:
# x y x==y? 0 1 8 no 1 2 8 no 2 3 8 no 3 4 8 no 4 5 8 no 5 6 8 no 6 7 8 no 7 8 8 yes 8 9 8 no 9 10 8 no 10 11 8 no 11 12 8 no 12 13 8 no 13 14 8 no 14 15 8 no 15 16 8 no # x y x>y? 0 1 8 no 1 2 8 no 2 3 8 no 3 4 8 no 4 5 8 no 5 6 8 no 6 7 8 no 7 8 8 no 8 9 8 yes 9 10 8 yes 10 11 8 yes 11 12 8 yes 12 13 8 yes 13 14 8 yes 14 15 8 yes 15 16 8 yes
Vidíme, že výsledky jsou korektní.
9. Překlad obou operací porovnání do assembleru s povolením SSE operací
První intrinsic __builtin_ia32_pcmpeqb128 byla podle očekávání přeložena do strojové instrukce pcmpeqb:
z = __builtin_ia32_pcmpeqb128(x, y); d7: 66 0f 6f 45 d0 movdqa xmm0,XMMWORD PTR [rbp-0x30] dc: 66 0f 6f 4d c0 movdqa xmm1,XMMWORD PTR [rbp-0x40] e1: 66 0f 74 c1 pcmpeqb xmm0,xmm1 e5: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Druhá intrinsic __builtin_ia32_pcmpgtb128 byla přeložena do strojové instrukce pcmpgtb:
z = __builtin_ia32_pcmpgtb128(x, y); 104: 66 0f 6f 4d d0 movdqa xmm1,XMMWORD PTR [rbp-0x30] 109: 66 0f 6f 45 c0 movdqa xmm0,XMMWORD PTR [rbp-0x40] 10e: 66 0f 64 c1 pcmpgtb xmm0,xmm1 112: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
10. Všech šest relačních operací pro vektory s prvky typu float
Zatímco pro vektory s celočíselnými prvky jsou k dispozici pouze instrukce určené pro porovnání prvků vektorů na relace typu „shodný“ a „větší než“ (s tím, že zbylé relace lze „dopočítat)“, je tomu v případě prvků typu float a double poněkud jinak, protože v tomto případě nabízí instrukční soubor všech šest relačních operací.
Z tohoto důvodu nalezneme v GCC těchto šest intrinsic (příslušná relace je vybrána pomocí dvojice zvýrazněných znaků se zřejmým významem zavedeným již před 70 lety ve FORTRANu):
- __builtin_ia32_cmpeqps
- __builtin_ia32_cmpgtps
- __builtin_ia32_cmpltps
- __builtin_ia32_cmpgeps
- __builtin_ia32_cmpleps
- __builtin_ia32_cmpneqps
Všech šest těchto operací otestujeme v příkladu, v němž se porovnává dvojice vektorů, z nichž každý obsahuje čtveřici hodnot typu float/single. Hodnoty uložené ve vektorech jsou zvoleny takovým způsobem, aby výsledky byly pro každé porovnání odlišné:
#include <stdio.h>
#include <xmmintrin.h>
void print_results(const char *title, __v4sf *x, __v4sf *y, __v4sf *z)
{
int i;
puts(title);
for (i = 0; i < sizeof(*x) / sizeof(float); i++) {
printf("%2d %3.1f %3.1f %s\n", i, (*x)[i], (*y)[i], (*z)[i] == 0 ? "no":"yes");
}
putchar('\n');
}
int main(void)
{
__v4sf x = { 1, 2.5, 2.5, 4 };
__v4sf y = { 2.5, 2.5, 2.5, 2.5 };
__v4sf z;
z = __builtin_ia32_cmpeqps(x, y);
print_results(" # x y x==y?", &x, &y, &z);
z = __builtin_ia32_cmpgtps(x, y);
print_results(" # x y x>y?", &x, &y, &z);
z = __builtin_ia32_cmpltps(x, y);
print_results(" # x y x<y?", &x, &y, &z);
z = __builtin_ia32_cmpgeps(x, y);
print_results(" # x y x>=y?", &x, &y, &z);
z = __builtin_ia32_cmpleps(x, y);
print_results(" # x y x<=y?", &x, &y, &z);
z = __builtin_ia32_cmpneqps(x, y);
print_results(" # x y x!=y?", &x, &y, &z);
}
Výsledky získané po spuštění budou vypadat následovně:
# x y x==y? 0 1.0 2.5 no 1 2.5 2.5 yes 2 2.5 2.5 yes 3 4.0 2.5 no # x y x>y? 0 1.0 2.5 no 1 2.5 2.5 no 2 2.5 2.5 no 3 4.0 2.5 yes # x y x<y? 0 1.0 2.5 yes 1 2.5 2.5 no 2 2.5 2.5 no 3 4.0 2.5 no # x y x>=y? 0 1.0 2.5 no 1 2.5 2.5 yes 2 2.5 2.5 yes 3 4.0 2.5 yes # x y x<=y? 0 1.0 2.5 yes 1 2.5 2.5 yes 2 2.5 2.5 yes 3 4.0 2.5 no # x y x!=y? 0 1.0 2.5 yes 1 2.5 2.5 no 2 2.5 2.5 no 3 4.0 2.5 yes
11. Překlad všech šesti operací porovnání do assembleru s povolením SSE operací
Opět se nyní podívejme na to, jak je všech šest intrinsic z předchozího demonstračního příkladu přeloženo do assembleru ve chvíli, kdy je povoleno použití SIMD instrukcí.
Test na rovnost:
z = __builtin_ia32_cmpeqps(x, y); eb: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] ef: 0f 28 4d c0 movaps xmm1,XMMWORD PTR [rbp-0x40] f3: 0f c2 c1 00 cmpeqps xmm0,xmm1 f7: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Test na relaci „větší než“ (prohozené vstupy):
z = __builtin_ia32_cmpgtps(x, y); 116: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] 11a: 0f 28 4d c0 movaps xmm1,XMMWORD PTR [rbp-0x40] 11e: 0f c2 c1 01 cmpltps xmm0,xmm1 122: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Test na relaci „menší než“:
z = __builtin_ia32_cmpltps(x, y); 141: 0f 28 4d d0 movaps xmm1,XMMWORD PTR [rbp-0x30] 145: 0f 28 45 c0 movaps xmm0,XMMWORD PTR [rbp-0x40] 149: 0f c2 c1 01 cmpltps xmm0,xmm1 14d: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Test na relaci „větší nebo rovno“: (prohozené vstupy)
z = __builtin_ia32_cmpgeps(x, y); 16c: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] 170: 0f 28 4d c0 movaps xmm1,XMMWORD PTR [rbp-0x40] 174: 0f c2 c1 02 cmpleps xmm0,xmm1 178: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Test na relaci „menší nebo rovno“:
z = __builtin_ia32_cmpleps(x, y); 197: 0f 28 4d d0 movaps xmm1,XMMWORD PTR [rbp-0x30] 19b: 0f 28 45 c0 movaps xmm0,XMMWORD PTR [rbp-0x40] 19f: 0f c2 c1 02 cmpleps xmm0,xmm1 1a3: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Test na relaci „nerovnost“:
z = __builtin_ia32_cmpneqps(x, y); 1c2: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] 1c6: 0f 28 4d c0 movaps xmm1,XMMWORD PTR [rbp-0x40] 1ca: 0f c2 c1 04 cmpneqps xmm0,xmm1 1ce: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
12. Unární operace pro výpočet převrácené hodnoty, druhé odmocniny a převrácené hodnoty druhé odmocniny
Dále v instrukční sadě SSE nalezneme trojici instrukcí, které pracují s jedním vstupním vektorem s prvky typu single/float a double. Tyto instrukce provádí „vektorový“ (tedy paralelní) výpočet převrácené hodnoty, druhé odmocniny a taktéž převrácené hodnoty druhé odmocniny. Tyto instrukce se tedy mohou využít například v 2D a 3D grafice, například pro normalizaci vektorů atd. Podívejme se nyní na způsob použití intrinsic vytvořených pro podporu těchto tří funkcí:
#include <stdio.h>
#include <xmmintrin.h>
void print_results(const char *title, __v4sf *x, __v4sf *y)
{
int i;
puts(title);
for (i = 0; i < sizeof(*x) / sizeof(float); i++) {
printf("%2d %5.2f %3.1f\n", i, (*x)[i], (*y)[i]);
}
putchar('\n');
}
int main(void)
{
__v4sf x = { 1, 2, 4, 10 };
__v4sf y;
y = __builtin_ia32_rcpps(x);
print_results(" # x 1/x", &x, &y);
y = __builtin_ia32_sqrtps(x);
print_results(" # x sqrt(x)", &x, &y);
y = __builtin_ia32_rsqrtps(x);
print_results(" # x 1/sqrt(x)", &x, &y);
}
Po překladu a spuštění tohoto demonstračního příkladu by se měla zobrazit trojice tabulek s převrácenými hodnotami vstupních prvků, s druhou odmocninou těchto prvků a převrácenou hodnotou druhé odmocniny:
# x 1/x 0 1.00 1.0 1 2.00 0.5 2 4.00 0.2 3 10.00 0.1 # x sqrt(x) 0 1.00 1.0 1 2.00 1.4 2 4.00 2.0 3 10.00 3.2 # x 1/sqrt(x) 0 1.00 1.0 1 2.00 0.7 2 4.00 0.5 3 10.00 0.3
Překlad do assembleru vypadá následovně:
Výpočet převrácené hodnoty:
y = __builtin_ia32_rcpps(x); a8: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] ac: 0f 53 c0 rcpps xmm0,xmm0 af: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Výpočet druhé odmocniny:
y = __builtin_ia32_sqrtps(x); ca: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] ce: 0f 51 c0 sqrtps xmm0,xmm0 d1: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
Výpočet převrácené hodnoty druhé odmocniny:
y = __builtin_ia32_rsqrtps(x); ec: 0f 28 45 d0 movaps xmm0,XMMWORD PTR [rbp-0x30] f0: 0f 52 c0 rsqrtps xmm0,xmm0 f3: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
13. Instrukce určené pro přeskupení, promíchání a výběr prvků uložených ve dvojici vektorů
SIMD operace jsou v prvé řadě určeny pro paralelní výpočty založené na provádění jedné zvolené operace nad všemi korespondujícími prvky dvou vstupních vektorů popř. jediného vstupního vektoru (viz například operace ukázané v rámci předchozí kapitoly, které pracují s jediným vstupním vektorem). Ovšem v mnoha případech nejsou vstupní data, konkrétně jednotlivé prvky, nad nimiž se mají „vektorové“ výpočty provádět, uspořádána v takovém pořadí, aby je bylo možné přímo přenést do vektorů. Totéž platí pro výsledky vektorových operací – mnohdy je potřebujeme nějakým způsobem přeuspořádat. Pro tyto účely se do instrukčních sad pro SIMD operace vkládají instrukce, které jsou určeny pro konverzi dat, přeskupení, promíchání, popř. pro výběr prvků typicky uložených v jednom vektoru nebo ve dvojici vektorů. S vybranými instrukcemi z této dnes již poměrně rozsáhlé skupiny skupiny se seznámíme v dalším textu.
14. Instrukce shufps a její intrinsic
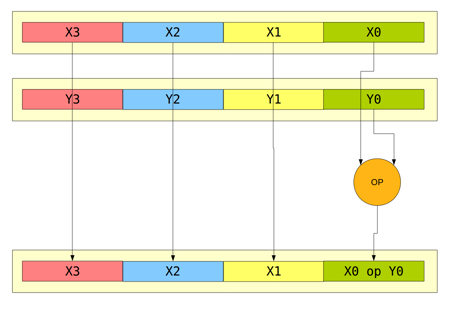
Nejsložitější instrukcí, s níž se dnes seznámíme, je instrukce nazvaná shufps, která provádí „shuffling“ prvků ve dvou vstupních vektorech s vytvořením cílového vektoru. Vektory přitom obsahují čtveřici hodnot typu single/float. Prvky těchto dvou vektorů si můžeme označit x3, x2, x1, x0 a y3, y2, y1, y0. Instrukce shufps vytvoří výsledný vektor se strukturou [yn, yn, xn, xn], kde indexy n v rozsahu 0..3 jsou umístěny v osmibitové celočíselné konstantě – vždy dva bity pro každý prvek vektoru. Pokud například bude tato konstanta rovna nule, bude výsledkem vektor [y0, y0, x0, x0]. V případě, že zde bude uloženo například binární číslo 11001001 tedy 11 00 10 01, bude výsledný vektor obsahovat prvky [y3, y0, x2, x1]. Jedná se tedy o poměrně univerzální operaci:
#include <stdio.h>
#include <xmmintrin.h>
void print_results(const char *title, __v4sf * x, __v4sf * y, __v4sf * z)
{
int i;
puts(title);
for (i = 0; i < sizeof(*x) / sizeof(float); i++) {
printf("%2d %2.0f %2.0f %2.0f\n", i, (*x)[i], (*y)[i], (*z)[i]);
}
putchar('\n');
}
int main(void)
{
__v4sf x = { 1, 2, 3, 4 };
__v4sf y = { 6, 7, 8, 9 };
__v4sf z;
/* ------------------------------------- */
/* | x3 | x2 | x1 | x0 | */
/* | y2 | y2 | y1 | y0 | */
/* | y3..y0 | y3..y0 | x3..x0 | x3..x0 | */
/* ------------------------------------- */
z = __builtin_ia32_shufps(x, y, 0);
print_results(" # x y z", &x, &y, &z);
z = __builtin_ia32_shufps(x, y, 0b11110000);
print_results(" # x y z", &x, &y, &z);
z = __builtin_ia32_shufps(x, y, 0b10100101);
print_results(" # x y z", &x, &y, &z);
}
Výsledky operace shufps jsou zobrazeny v posledním sloupci:
# x y z 0 1 6 1 1 2 7 1 2 3 8 6 3 4 9 6 # x y z 0 1 6 1 1 2 7 1 2 3 8 9 3 4 9 9 # x y z 0 1 6 2 1 2 7 2 2 3 8 8 3 4 9 8
15. Překlad demonstračního příkladu do assembleru
Instrukce shufps se přeloží takovým způsobem, že její délka je rovna čtyřem bajtům, což je poněkud zvláštní, protože mnoho SIMD instrukcí s operandem typu „vektor floatů“ má délku jen tří bajtů:
z = __builtin_ia32_shufps(x, y, 0b11110000); f5: 0f 28 4d d0 movaps xmm1,XMMWORD PTR [rbp-0x30] f9: 0f 28 45 c0 movaps xmm0,XMMWORD PTR [rbp-0x40] fd: 0f c6 c1 f0 shufps xmm0,xmm1,0xf0 101: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
16. Instrukce unpckhps a unpcklps a jejich intrinsics
Poslední dvě instrukce, s nimiž se dnes seznámíme, se jmenují unpckhps a unpcklps. Tyto dvě instrukce mají na vstupu dva vektory se čtyřmi prvky typu float/single. Tyto prvky si opět můžeme označit x3, x2, x1, x0 a y3, y2, y1, y0. Instrukce unpckhps (h od slova high) z této vstupní osmice vytvoří vektor [x2, y2, x3, y3], což znamená promíchání obou vektorů resp. jejich horních polovin. A instrukce unpcklps vytvoří vektor [x0, y0, x1, y1]:
#include <stdio.h>
#include <xmmintrin.h>
void print_results(const char *title, __v4sf * x, __v4sf * y, __v4sf * z)
{
int i;
puts(title);
for (i = 0; i < sizeof(*x) / sizeof(float); i++) {
printf("%2d %2.0f %2.0f %2.0f\n", i, (*x)[i], (*y)[i], (*z)[i]);
}
putchar('\n');
}
int main(void)
{
__v4sf x = { 1, 2, 3, 4 };
__v4sf y = { 6, 7, 8, 9 };
__v4sf z;
z = __builtin_ia32_unpckhps(x, y);
print_results(" # x y z", &x, &y, &z);
z = __builtin_ia32_unpcklps(x, y);
print_results(" # x y z", &x, &y, &z);
}
Podívejme se nyní na výsledky získané těmito dvěma instrukcemi, které osvětlí jejich funkci:
# x y z 0 1 6 3 1 2 7 8 2 3 8 4 3 4 9 9 # x y z 0 1 6 1 1 2 7 6 2 3 8 2 3 4 9 7
Z výsledků je patrné, že první instrukce skutečně přečte a promíchá poslední dvojici z obou vstupních vektorů, kdežto druhá instrukce zpracuje první dvojici z obou vektorů.
17. Překlad demonstračního příkladu do assembleru
Výše uvedené intrinsics pojmenované __builtin_ia32_unpckhps a __builtin_ia32_unpcklps se do assembleru překládají následujícím způsobem:
z = __builtin_ia32_unpckhps(x, y); ca: 0f 28 4d d0 movaps xmm1,XMMWORD PTR [rbp-0x30] ce: 0f 28 45 c0 movaps xmm0,XMMWORD PTR [rbp-0x40] d2: 0f 15 c1 unpckhps xmm0,xmm1 d5: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
a:
z = __builtin_ia32_unpcklps(x, y); f4: 0f 28 4d d0 movaps xmm1,XMMWORD PTR [rbp-0x30] f8: 0f 28 45 c0 movaps xmm0,XMMWORD PTR [rbp-0x40] fc: 0f 14 c1 unpcklps xmm0,xmm1 ff: 0f 29 45 e0 movaps XMMWORD PTR [rbp-0x20],xmm0
18. Příloha – soubor Makefile použitý v článcích o SIMD operacích
Následující soubor Makefile byl použit pro překlad zdrojových kódů všech výše uvedených demonstračních příkladů do objektového kódu jeho s následným disassemblingem do assembleru (resp. přesněji řečeno do assembleru zkombinovaného s hexadecimálním výpisem obsahu souboru s objektovým kódem). Makefile obsahuje i instrukce pro překlad demonstračních příkladů z předchozích článků o SIMD operacích:
CC=gcc
OBJDUMP=objdump
all: simd04_1.lst simd04_2.lst \
simd04B_1.lst simd04B_2.lst \
simd07_1.lst simd07_2.lst \
simd08_1.lst simd08_2.lst \
simd12_1.lst simd12_2.lst \
simd13_1.lst simd13_2.lst simd13_3.lst simd13_4.lst \
simd14_1.lst simd14_2.lst simd14_3.lst simd14_4.lst \
simd15_1.lst simd15_2.lst simd15_3.lst simd15_4.lst \
simd16_1.lst simd16_2.lst simd16_3.lst simd16_4.lst \
simd17_1.lst simd17_2.lst simd17_3.lst simd17_4.lst \
simd18_1.lst simd18_2.lst simd18_3.lst simd18_4.lst \
intrinsic_mmx_1.lst \
intrinsic_mmx_2.lst \
intrinsic_mmx_3.lst \
intrinsic_mmx_4.lst \
intrinsic_mmx_5.lst \
intrinsic_sse_1.lst \
intrinsic_sse_2.lst \
intrinsic_sse_3.lst \
intrinsic_sse_4.lst \
intrinsic_sse_5.lst \
intrinsic_sse_6.lst \
intrinsic_sse_7.lst \
intrinsic_sse_8.lst \
intrinsic_sse_9.lst \
intrinsic_sse_A.lst \
intrinsic_sse_B.lst
clean:
rm *.lst
rm *.o
%.lst: %.o
objdump -d -M intel -S $< > $@
simd04_1.o: simd04.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd04_2.o: simd04.c
gcc -c -O0 -g -o $@ $<
simd04B_1.o: simd04B.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd04B_2.o: simd04B.c
gcc -c -O0 -g -o $@ $<
simd07_1.o: simd07.c
gcc -c -mno-sse -g -o $@ $<
simd07_2.o: simd07.c
gcc -c -g -o $@ $<
simd08_1.o: simd08.c
gcc -c -mno-sse -g -o $@ $<
simd08_2.o: simd08.c
gcc -c -g -o $@ $<
simd12_1.o: simd12.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd12_2.o: simd12.c
gcc -c -O0 -g -o $@ $<
simd13_1.o: simd13.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd13_2.o: simd13.c
gcc -c -O0 -g -o $@ $<
simd13_3.o: simd13.c
gcc -c -O3 -mno-sse -g -o $@ $<
simd13_4.o: simd13.c
gcc -c -O3 -g -o $@ $<
simd14_1.o: simd14.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd14_2.o: simd14.c
gcc -c -O0 -g -o $@ $<
simd14_3.o: simd14.c
gcc -c -O3 -mno-sse -g -o $@ $<
simd14_4.o: simd14.c
gcc -c -O3 -g -o $@ $<
simd15_1.o: simd15.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd15_2.o: simd15.c
gcc -c -O0 -g -o $@ $<
simd15_3.o: simd15.c
gcc -c -O3 -mno-sse -g -o $@ $<
simd15_4.o: simd15.c
gcc -c -O3 -g -o $@ $<
simd16_1.o: simd16.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd16_2.o: simd16.c
gcc -c -O0 -g -o $@ $<
simd16_3.o: simd16.c
gcc -c -O3 -mno-sse -g -o $@ $<
simd16_4.o: simd16.c
gcc -c -O3 -g -o $@ $<
simd17_1.o: simd17.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd17_2.o: simd17.c
gcc -c -O0 -g -o $@ $<
simd17_3.o: simd17.c
gcc -c -O3 -mno-sse -g -o $@ $<
simd17_4.o: simd17.c
gcc -c -O3 -g -o $@ $<
simd18_1.o: simd18.c
gcc -c -O0 -mno-sse -g -o $@ $<
simd18_2.o: simd18.c
gcc -c -O0 -g -o $@ $<
simd18_3.o: simd18.c
gcc -c -O3 -mno-sse -g -o $@ $<
simd18_4.o: simd18.c
gcc -c -O3 -g -o $@ $<
intrinsic_mmx_1.o: intrinsic_mmx_1.c
gcc -c -O0 -g -o $@ $<
intrinsic_mmx_2.o: intrinsic_mmx_2.c
gcc -c -O0 -g -o $@ $<
intrinsic_mmx_3.o: intrinsic_mmx_3.c
gcc -c -O0 -g -o $@ $<
intrinsic_mmx_4.o: intrinsic_mmx_4.c
gcc -c -O0 -g -o $@ $<
intrinsic_mmx_5.o: intrinsic_mmx_5.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_1.o: intrinsic_sse_1.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_2.o: intrinsic_sse_2.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_3.o: intrinsic_sse_3.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_4.o: intrinsic_sse_4.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_5.o: intrinsic_sse_5.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_6.o: intrinsic_sse_6.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_7.o: intrinsic_sse_7.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_8.o: intrinsic_sse_8.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_9.o: intrinsic_sse_9.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_A.o: intrinsic_sse_A.c
gcc -c -O0 -g -o $@ $<
intrinsic_sse_B.o: intrinsic_sse_B.c
gcc -c -O0 -g -o $@ $<
19. Repositář s demonstračními příklady
Demonstrační příklady napsané v jazyku C, které jsou určené pro překlad pomocí překladače GCC C, byly uložen do Git repositáře, který je dostupný na adrese https://github.com/tisnik/presentations. Jednotlivé demonstrační příklady si můžete v případě potřeby stáhnout i jednotlivě bez nutnosti klonovat celý (dnes již velmi rozsáhlý) repositář:
| # | Příklad | Stručný popis | Adresa |
|---|---|---|---|
| 1 | simd01.c | vektor celých čísel typu short int | https://github.com/tisnik/presentations/blob/master/SIMD/simd01.c |
| 2 | simd02.c | ukázka použití vektorů s celočíselnými typy bez znaménka | https://github.com/tisnik/presentations/blob/master/SIMD/simd02.c |
| 3 | simd03.c | ukázka použití vektorů s celočíselnými typy se znaménkem | https://github.com/tisnik/presentations/blob/master/SIMD/simd03.c |
| 4 | simd04.c | paralelní součet celočíselných prvků vektorů | https://github.com/tisnik/presentations/blob/master/SIMD/simd04.c |
| 5 | simd04B.c | úprava pro další datové typy | https://github.com/tisnik/presentations/blob/master/SIMD/simd04B.c |
| 6 | simd05.c | přístup k jednotlivým prvkům vektorů | https://github.com/tisnik/presentations/blob/master/SIMD/simd05.c |
| 7 | simd05B.c | korektnější výpočet počtu prvků vektoru | https://github.com/tisnik/presentations/blob/master/SIMD/simd05B.c |
| 8 | simd05C.c | definice typu vektoru | https://github.com/tisnik/presentations/blob/master/SIMD/simd05C.c |
| 9 | simd06.c | vektor čísel s plovoucí řádovou čárkou | https://github.com/tisnik/presentations/blob/master/SIMD/simd06.c |
| 10 | simd07.c | paralelní součet prvků vektorů (typ float) | https://github.com/tisnik/presentations/blob/master/SIMD/simd07.c |
| 11 | simd08.c | paralelní součet prvků vektorů (typ double) | https://github.com/tisnik/presentations/blob/master/SIMD/simd08.c |
| 12 | simd09.c | překročení délky vektoru | https://github.com/tisnik/presentations/blob/master/SIMD/simd09.c |
| 13 | simd10.c | přístup k jednotlivým prvkům vektorů | https://github.com/tisnik/presentations/blob/master/SIMD/simd10.c |
| 14 | simd11.c | překročení délky vektoru | https://github.com/tisnik/presentations/blob/master/SIMD/simd11.c |
| 15 | simd12.c | dlouhý vektor s 256 bajty | https://github.com/tisnik/presentations/blob/master/SIMD/simd12.c |
| 16 | simd13.c | operace součtu pro vektory s celočíselnými prvky rozličné bitové šířky bez znaménka | https://github.com/tisnik/presentations/blob/master/SIMD/simd13.c |
| 17 | simd14.c | operace součtu pro vektory s celočíselnými prvky rozličné bitové šířky se znaménkem | https://github.com/tisnik/presentations/blob/master/SIMD/simd14.c |
| 18 | simd15.c | operace součtu pro vektory s prvky rozličné bitové šířky s plovoucí řádovou čárkou | https://github.com/tisnik/presentations/blob/master/SIMD/simd15.c |
| 19 | simd16.c | operace součtu pro dlouhé vektory s prvky rozličné bitové šířky s plovoucí řádovou čárkou | https://github.com/tisnik/presentations/blob/master/SIMD/simd16.c |
| 20 | simd17.c | všechny podporované binární operace nad vektory s celočíselnými prvky se znaménkem | https://github.com/tisnik/presentations/blob/master/SIMD/simd17.c |
| 21 | simd18.c | všechny podporované binární operace nad vektory s prvky typu float | https://github.com/tisnik/presentations/blob/master/SIMD/simd18.c |
| 23 | intrinsic_mmx1.c | intrinsic pro technologii MMX: instrukce paddb | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_mmx1.c |
| 24 | intrinsic_mmx2.c | intrinsic pro technologii MMX: instrukce paddw | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_mmx2.c |
| 25 | intrinsic_mmx3.c | intrinsic pro technologii MMX: instrukce paddb (přetečení) | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_mmx3.c |
| 26 | intrinsic_mmx4.c | intrinsic pro technologii MMX: instrukce paddsb (saturace) | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_mmx4.c |
| 27 | intrinsic_mmx5.c | intrinsic pro technologii MMX: instrukce pupckhbw (kombinace dvou vektorů) | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_mmx5.c |
| 28 | intrinsic_sse1.c | součet dvou vektorů s šestnácti prvky typu char instrukcí paddb128 | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse1.c |
| 29 | intrinsic_sse2.c | součet dvou vektorů s osmi prvky typu short instrukcí paddw128 | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse2.c |
| 30 | intrinsic_sse3.c | součet dvou vektorů se čtyřmi prvky typu int instrukcí paddd128 | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse3.c |
| 31 | intrinsic_sse4.c | součet dvou vektorů se dvěma prvky typu long instrukcí paddq128 | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse4.c |
| 32 | intrinsic_sse5.c | součet dvou vektorů se čtyřmi prvky typu float instrukcí addps | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse5.c |
| 33 | intrinsic_sse6.c | součet dvou vektorů se dvěma prvky typu double instrukcí addpd | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse6.c |
| 34 | intrinsic_sse7.c | porovnání celočíselných prvků instrukcemi pcmpeqb128 a pcmpgtb128 | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse7.c |
| 35 | intrinsic_sse8.c | všech šest relačních operací pro vektory s prvky typu float | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse8.c |
| 36 | intrinsic_sse9.c | unární operace pro výpočet převrácené hodnoty, druhé odmocniny a převrácené hodnoty druhé odmocniny | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse9.c |
| 37 | intrinsic_sse_A.c | instrukce shufps a její intrinsic | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse_A.c |
| 38 | intrinsic_sse_B.c | instrukce unpckhps a unpcklps a jejich intrinsics | https://github.com/tisnik/presentations/blob/master/SIMD/intrinsic_sse_B.c |
| 39 | Makefile | Makefile pro překlad demonstračních příkladů | https://github.com/tisnik/presentations/blob/master/SIMD/Makefile |
Soubory vzniklé překladem z jazyka C do assembleru procesorů x86–64:

Soubory vzniklé překladem z jazyka C do assembleru procesorů ARMv8:
| # | Příklad | Stručný popis | Adresa |
|---|---|---|---|
| 1 | simd04_1.lst | překlad zdrojového kódu simd04_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd04_1.lst |
| 2 | simd04_2.lst | překlad zdrojového kódu simd04_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd04_2.lst |
| 3 | simd04B1.lst | překlad zdrojového kódu simd04B1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd04B1.lst |
| 4 | simd04B2.lst | překlad zdrojového kódu simd04B2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd04B2.lst |
| 5 | simd07_1.lst | překlad zdrojového kódu simd07_1.c s přepínači -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd07_1.lst |
| 6 | simd07_2.lst | překlad zdrojového kódu simd07_2.c s přepínači -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd07_2.lst |
| 7 | simd08_1.lst | překlad zdrojového kódu simd08_1.c s přepínači -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd08_1.lst |
| 8 | simd08_2.lst | překlad zdrojového kódu simd08_2.c s přepínači -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd08_2.lst |
| 9 | simd12_1.lst | překlad zdrojového kódu simd12_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd12_1.lst |
| 10 | simd12_2.lst | překlad zdrojového kódu simd12_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd12_2.lst |
| 11 | simd13_1.lst | překlad zdrojového kódu simd13_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd13_1.lst |
| 12 | simd13_2.lst | překlad zdrojového kódu simd13_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd13_2.lst |
| 13 | simd13_3.lst | překlad zdrojového kódu simd13_3.c s přepínači -O3 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd13_3.lst |
| 14 | simd13_4.lst | překlad zdrojového kódu simd13_4.c s přepínači -O3 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd13_4.lst |
| 15 | simd14_1.lst | překlad zdrojového kódu simd14_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd14_1.lst |
| 16 | simd14_2.lst | překlad zdrojového kódu simd14_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd14_2.lst |
| 17 | simd14_3.lst | překlad zdrojového kódu simd14_3.c s přepínači -O3 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd14_3.lst |
| 18 | simd14_4.lst | překlad zdrojového kódu simd14_4.c s přepínači -O3 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd14_4.lst |
| 19 | simd15_1.lst | překlad zdrojového kódu simd15_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd15_1.lst |
| 20 | simd15_2.lst | překlad zdrojového kódu simd15_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd15_2.lst |
| 21 | simd15_3.lst | překlad zdrojového kódu simd15_3.c s přepínači -O3 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd15_3.lst |
| 22 | simd15_4.lst | překlad zdrojového kódu simd15_4.c s přepínači -O3 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd15_4.lst |
| 23 | simd16_1.lst | překlad zdrojového kódu simd16_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd16_1.lst |
| 24 | simd16_2.lst | překlad zdrojového kódu simd16_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd16_2.lst |
| 25 | simd16_3.lst | překlad zdrojového kódu simd16_3.c s přepínači -O3 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd16_3.lst |
| 26 | simd16_4.lst | překlad zdrojového kódu simd16_4.c s přepínači -O3 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd16_4.lst |
| 27 | simd17_1.lst | překlad zdrojového kódu simd17_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd17_1.lst |
| 28 | simd17_2.lst | překlad zdrojového kódu simd17_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd17_2.lst |
| 29 | simd17_3.lst | překlad zdrojového kódu simd17_3.c s přepínači -O3 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd17_3.lst |
| 30 | simd17_4.lst | překlad zdrojového kódu simd17_4.c s přepínači -O3 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd17_4.lst |
| 31 | simd18_1.lst | překlad zdrojového kódu simd18_1.c s přepínači -O0 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd18_1.lst |
| 32 | simd18_2.lst | překlad zdrojového kódu simd18_2.c s přepínači -O0 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd18_2.lst |
| 33 | simd18_3.lst | překlad zdrojového kódu simd18_3.c s přepínači -O3 -march=armv8-a+nosimd -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd18_3.lst |
| 34 | simd18_4.lst | překlad zdrojového kódu simd18_4.c s přepínači -O3 -g | https://github.com/tisnik/presentations/blob/master/SIMD/simd18_4.lst |
20. Odkazy na Internetu
- GCC documentation: Extensions to the C Language Family
https://gcc.gnu.org/onlinedocs/gcc/C-Extensions.html#C-Extensions - GCC documentation: Using Vector Instructions through Built-in Functions
https://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Bulldozer (microarchitecture)
https://en.wikipedia.org/wiki/Bulldozer_(microarchitecture) - SIMD Instructions Considered Harmful
https://www.sigarch.org/simd-instructions-considered-harmful/ - GCC Compiler Intrinsics
https://iq.opengenus.org/gcc-compiler-intrinsics/ - Scalable_Vector_Extension_(SVE)
https://en.wikipedia.org/wiki/AArch64#Scalable_Vector_Extension_(SVE) - FADD/FADDP/FIADD — Add
https://www.felixcloutier.com/x86/fadd:faddp:fiadd - ADDPS — Add Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/addps - ADDPD — Add Packed Double-Precision Floating-Point Values
https://www.felixcloutier.com/x86/addpd - FDIV/FDIVP/FIDIV — Divide
https://www.felixcloutier.com/x86/fdiv:fdivp:fidiv - IDIV — Signed Divide
https://www.felixcloutier.com/x86/idiv - PADDB/PADDW/PADDD/PADDQ — Add Packed Integers
https://www.felixcloutier.com/x86/paddb:paddw:paddd:paddq - PSUBB/PSUBW/PSUBD — Subtract Packed Integers
https://www.felixcloutier.com/x86/psubb:psubw:psubd - PMULLW — Multiply Packed Signed Integers and Store Low Result
https://www.felixcloutier.com/x86/pmullw - PUNPCKLBW/PUNPCKLWD/PUNPCKLDQ/PUNPCKLQDQ — Unpack Low Data
https://www.felixcloutier.com/x86/punpcklbw:punpcklwd:punpckldq:punpcklqdq - PUNPCKHBW/PUNPCKHWD/PUNPCKHDQ/PUNPCKHQDQ — Unpack High Data
https://www.felixcloutier.com/x86/punpckhbw:punpckhwd:punpckhdq:punpckhqdq - PACKUSWB — Pack with Unsigned Saturation
https://www.felixcloutier.com/x86/packuswb - ADDPS — Add Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/addps - SUBPS — Subtract Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/subps - MULPS — Multiply Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/mulps - DIVPS — Divide Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/divps - CBW/CWDE/CDQE — Convert Byte to Word/Convert Word to Doubleword/Convert Doubleword to Quadword
https://www.felixcloutier.com/x86/cbw:cwde:cdqe - PAND — Logical AND
https://www.felixcloutier.com/x86/pand - POR — Bitwise Logical OR
https://www.felixcloutier.com/x86/por - PXOR — Logical Exclusive OR
https://www.felixcloutier.com/x86/pxor - Improve the Multimedia User Experience
https://www.arm.com/technologies/neon - NEON Technology (stránky ARM)
https://developer.arm.com/technologies/neon - SIMD Assembly Tutorial: ARM NEON – Xiph.org
https://people.xiph.org/~tterribe/daala/neon_tutorial.pdf - Ne10
http://projectne10.github.io/Ne10/ - NEON and Floating-Point architecture
http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.den0024a/BABIGHEB.html - An Introduction to ARM NEON
http://peterdn.com/post/an-introduction-to-ARM-NEON.aspx - ARM NEON Intrinsics Reference
http://infocenter.arm.com/help/topic/com.arm.doc.ihi0073a/IHI0073A_arm_neon_intrinsics_ref.pdf - Arm Neon Intrinsics vs hand assembly
https://stackoverflow.com/questions/9828567/arm-neon-intrinsics-vs-hand-assembly - ARM NEON Optimization. An Example
http://hilbert-space.de/?p=22 - AArch64 NEON instruction format
https://developer.arm.com/docs/den0024/latest/7-aarch64-floating-point-and-neon/73-aarch64-neon-instruction-format - ARM SIMD instructions
https://developer.arm.com/documentation/dht0002/a/Introducing-NEON/What-is-SIMD-/ARM-SIMD-instructions - Learn the architecture – Migrate Neon to SVE Version 1.0
https://developer.arm.com/documentation/102131/0100/?lang=en - 1.2.2. Comparison between NEON technology and other SIMD solutions
https://developer.arm.com/documentation/den0018/a/Introduction/Comparison-between-ARM-NEON-technology-and-other-implementations/Comparison-between-NEON-technology-and-other-SIMD-solutions?lang=en - NEON Programmer’s Guide
https://documentation-service.arm.com/static/63299276e68c6809a6b41308 - Brain Floating Point – nový formát uložení čísel pro strojové učení a chytrá čidla
https://www.root.cz/clanky/brain-floating-point-ndash-novy-format-ulozeni-cisel-pro-strojove-uceni-a-chytra-cidla/ - Other Built-in Functions Provided by GCC
https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html - GCC: 6.60 Built-in Functions Specific to Particular Target Machines
https://gcc.gnu.org/onlinedocs/gcc/Target-Builtins.html#Target-Builtins - PCMPEQB/PCMPEQW/PCMPEQD — Compare Packed Data for Equal
https://www.felixcloutier.com/x86/pcmpeqb:pcmpeqw:pcmpeqd - PCMPGTB/PCMPGTW/PCMPGTD — Compare Packed Signed Integers for Greater Than
https://www.felixcloutier.com/x86/pcmpgtb:pcmpgtw:pcmpgtd - SHUFPS — Packed Interleave Shuffle of Quadruplets of Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/shufps - UNPCKHPS — Unpack and Interleave High Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/unpckhps - UNPCKLPS — Unpack and Interleave Low Packed Single-Precision Floating-Point Values
https://www.felixcloutier.com/x86/unpcklps - Top 10 Craziest Assembly Language Instructions
https://www.youtube.com/watch?v=Wz_xJPN7lAY - Intel x86: let's take a look at one of the most complex instruction set!
https://www.youtube.com/watch?v=KBLy23B38-c - x64 Assembly Tutorial 58: Intro to AVX
https://www.youtube.com/watch?v=yAvuHd8cBJY - AVX512 (1 of 3): Introduction and Overview
https://www.youtube.com/watch?v=D-mM6X5×nTY - AVX512 (2 of 3): Programming AVX512 in 3 Different Ways
https://www.youtube.com/watch?v=I3efQKLgsjM - AVX512 (3 of 3): Deep Dive into AVX512 Mechanisms
https://www.youtube.com/watch?v=543a1b-cPmU
Autor: Pavel Tišnovský 2022





































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU