Obsah
1. Pohled pod kapotu JVM – přednosti a zápory využití JNI při optimalizacích
2. První demonstrační příklad JNITest1
3. Překlad a spuštění prvního demonstračního příkladu
5. Druhý demonstrační příklad JNITest2: rekurzivní výpočet prvků Fibonacciho řady
6. Výsledky běhu druhého demonstračního příkladu
7. Třetí demonstrační příklad JNITest3: nerekurzivní výpočet prvků Fibonacciho řady
8. Výsledky běhu třetího demonstračního příkladu
9. Repositář se zdrojovými soubory i se skripty pro překlad
1. Pohled pod kapotu JVM – přednosti a zápory využití JNI při optimalizacích
V předchozích částech seriálu o programovacím jazyku Java i o virtuálním stroji Javy jsme si popsali některé možnosti optimalizace aplikací naprogramovaných v Javě. Ještě jsme se však nezmínili o možnosti využití rozhraní JNI (Java Native Interface), díky jehož existenci je možné z Javy relativně jednoduše volat nativní funkce a metody, tj. programový kód, který byl přeložen přímo do strojového kódu cílového mikroprocesoru. Využití JNI s sebou nese klady, ale samozřejmě i zápory. Mezi kladné vlastnosti patří možnost využití nepřeberného množství nativních sdílených knihoven dostupných v operačním systému i fakt, že kritickou část aplikace je možné (po implementaci v C, C++ atd.) přeložit takovým překladačem, který produkuje rychlejší či menší strojový kód, než JIT překladače typu klient i server. Příkladem, kdy by bylo využití rozhraní JNI vhodné, je například nějaké výpočetní jádro přeložené pomocí gcc či icc.
JNI však není a ani nemůže být samospasitelná technologie. Při jeho využití je totiž nutné, aby virtuální stroj Javy spojil dva nesourodé světy – svět Javy s automatickým správcem paměti a nepřímo používanými referencemi se světem jazyků C/C++ s manuální či poloautomatickou správou paměti, ukazateli a dalšími nízkoúrovňovými operacemi. Problémy nastávají zejména při předávání parametrů nativním funkcím a metodám – je totiž nutné zajistit buď kopii těchto parametrů, nebo je nutné příslušné javovské objekty označit takovým způsobem, aby s nimi nebylo v průběhu spuštění nativní funkce manipulováno například při správě paměti. Ani samotné volání nativní funkce či metody není zcela jednoduché, takže se může stát, že nativní kód přeložený optimalizujícím překladačem bude ve skutečnosti pomalejší než obdobný kód naprogramovaný v Javě a přeložený někdy poněkud naivním JIT překladačem. Podrobnosti si ukážeme na poněkud extrémním demonstračním příkladu popsaném v následujících kapitolách.
2. První demonstrační příklad JNITest1
V dnešním prvním demonstračním příkladu je ukázáno, jakým způsobem je možné zajistit překlad a následné volání nativní funkce (resp. statické metody), která sečte své dva celočíselné parametry a vrátí výsledek tohoto součtu. Aby bylo možné porovnat rychlost volání a běhu této nativní metody s obdobnou Javovskou metodou, najdeme v demonstračním příkladu jak hlavičku nativní metody native public static int nativeAdd(int x, int y), tak i implementaci podobného javovského kódu public static int javaAdd(int x, int y). Tyto dvě metody jsou následně volány v jednoduchém benchmarku a následně je vypsán výsledek tohoto testu.
/**
* Jednoduchy benchmark pro porovnani rychlosti nativni funkce a JITovane metody.
*
* @author Pavel Tisnovsky
*/
public class JNITest1 {
/**
* Pocet opakovani zahrivaci faze benchmarku.
*/
private static final int WARMUP_ITERS = 200000;
/**
* Pocet opakovani merene faze benchmarku.
*/
private static final int BENCHMARK_ITERS = 200000;
/**
* Nativni metoda, ktera vrati soucet svych dvou argumentu.
*/
native public static int nativeAdd(int x, int y);
/**
* Javovska metoda, ktera vrati soucet svych dvou argumentu.
*/
public static int javaAdd(int x, int y) {
return x+y;
}
/**
* Spusteni benchmarku.
*/
private static void runJNIBenchmarks() {
warmup();
benchmark();
}
/**
* Vypis vypocteneho vysledku (jen pro kontrolu).
*/
private static void printResult(int result) {
System.out.print(" result=");
System.out.println(result);
}
/**
* Zahrivaci faze benchmarku.
*/
private static void warmup() {
System.out.println("Warmup phase...");
int result = 0;
// donutime JIT k prekladu
for (int i = 0; i < WARMUP_ITERS; i++) {
result += javaAdd(i, i);
}
printResult(result);
result = 0;
// taktez zde donutime JIT k prekladu
for (int i = 0; i < WARMUP_ITERS; i++) {
result += nativeAdd(i, i);
}
printResult(result);
System.out.println("done");
}
/**
* Vlastni mereny benchmark.
*/
private static void benchmark() {
System.out.println("Benchmark phase...");
long t1, t2, delta_t;
// provest test a zmerit cas behu prvniho testu
t1 = System.nanoTime();
int result = 0;
for (int i = 0; i < BENCHMARK_ITERS; i++) {
result += javaAdd(i, i);
}
t2 = System.nanoTime();
delta_t = t2 - t1;
printResult(result);
// vypis casu pro prvni test
System.out.format("JITted method time: %,12d ns\n", delta_t);
// provest test a zmerit cas behu druheho testu
t1 = System.nanoTime();
result = 0;
for (int i = 0; i < BENCHMARK_ITERS; i++) {
result += nativeAdd(i, i);
}
t2 = System.nanoTime();
delta_t = t2 - t1;
printResult(result);
// vypis casu pro druhy test
System.out.format("native function time: %,12d ns\n", delta_t);
System.out.println("done");
}
/**
* Spusteni benchmarku.
*/
public static void main(String[] args) {
System.loadLibrary("JNITest1");
runJNIBenchmarks();
}
}
Povšimněte si ještě prvního příkazu ve funkci main(), který zajistí načtení a inicializaci sdílené nativní knihovny obsahující implementaci metody nativeAdd():
3. Překlad a spuštění prvního demonstračního příkladu
Zdrojový kód prvního demonstračního příkladu se, jak je to běžné, přeloží překladačem javac:
javac JNITest1.java
Po tomto překladu však ještě není možné benchmark spustit, protože nám chybí implementace nativní funkce nativeAdd(). Nejdříve si tedy necháme vytvořit hlavičkový soubor nazvaný JNITest1.h, v němž bude uvedena přesná hlavička této funkce (s ošetřením jejího názvu při použití jazyka C++ namísto céčka):
javah JNITest1
Hlavičkový soubor JNITest1.h může vypadat následovně:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class JNITest1 */
#ifndef _Included_JNITest1
#define _Included_JNITest1
#ifdef __cplusplus
extern "C" {
#endif
#undef JNITest1_WARMUP_ITERS
#define JNITest1_WARMUP_ITERS 200000L
#undef JNITest1_BENCHMARK_ITERS
#define JNITest1_BENCHMARK_ITERS 200000L
/*
* Class: JNITest1
* Method: nativeAdd
* Signature: (II)I
*/
JNIEXPORT jint JNICALL Java_JNITest1_nativeAdd
(JNIEnv *, jclass, jint, jint);
#ifdef __cplusplus
}
#endif
#endif
Povšimněte si způsobu přejmenování nativní metody, kterou musíme implementovat.
Na základě tohoto hlavičkového souboru již můžeme vytvořit zdrojový soubor nazvaný JNITest1.c, v němž bude funkce implementována:
#include <jni.h>
#include "JNITest1.h"
JNIEXPORT jint JNICALL Java_JNITest1_nativeAdd
(JNIEnv *jni_env, jclass klass, jint x, jint y)
{
return x+y;
}
Následuje překlad tohoto souboru, což může v případě Linuxu vypadat následovně (cestu k jni.h a dalším potřebným souborům bude samozřejmě nutné upravit na základě konfigurace konkrétní distribuce Linuxu):
gcc -shared -I/usr/lib/jvm/java-7-openjdk/include/ -o libJNITest1.so JNITest1.c
Na systému Windows s nainstalovanou JDK 7 by mohl překlad s využitím mingw vypadat následovně:
gcc -shared -I"c:\Program Files\Java\jdk1.7.0_25\include" -o JNITest1.dll JNITest1.c
V obou případech by měla vzniknout sdílená dynamicky linkovaná knihovna pojmenovaná v závislosti na použitém operačním systému buď libJNITest1.so či JNITest1.dll. Tyto názvy je zapotřebí zkontrolovat a dodržet, protože v případě jejich změny by došlo k chybě při volání System.loadLibrary(„JNITest1“)!
4. Výsledky běhu prvního demonstračního příkladu při použití interpretru, JIT typu klient i JIT typu server
Nyní si vyzkoušíme, zda bude nativní metoda nativeAdd() skutečně rychlejší než metoda javaAdd(), která bude buď intepretovaná či přeložená JIT překladačem typu klient a server.
Interpret:
Interpret se na Linuxu i Windows spustí stejným příkazem, ovšem na Linuxu je navíc nutné nastavit i proměnnou prostředí LD_LIBRARY_PATH takovým způsobem, aby virtuální stroj Javy našel sdílenou knihovnu libJNITest1.so:
export LD_LIBRARY_PATH=. java -Xint JNITest1
Výsledky jsou poměrně zajímavé, neboť volání nativní knihovny je pomalejší:
Warmup phase...
result=1345094336
result=1345094336
done
Benchmark phase...
result=1345094336
JITted method time: 32 152 970 ns
result=1345094336
native function time: 43 650 520 ns
done
JIT Client:
Spuštění proběhne následovně:
export LD_LIBRARY_PATH=. java -client JNITest1
I zde je volání nativní metody pomalejší:
Warmup phase...
result=1345094336
result=1345094336
done
Benchmark phase...
result=1345094336
JITted method time: 6 236 268 ns
result=1345094336
native function time: 9 170 438 ns
done
JIT Server:
export LD_LIBRARY_PATH=. java -server JNITest1
Zde do času běhu benchmarku zasáhl relativně pomalý JIT překladač typu server:
Warmup phase...
result=1345094336
result=1345094336
done
Benchmark phase...
result=1345094336
JITted method time: 41 682 394 ns
result=1345094336
native function time: 19 539 912 ns
done
5. Druhý demonstrační příklad JNITest2: rekurzivní výpočet prvků Fibonacciho řady
Výsledky představené v předchozí kapitole jsou dosti zajímavé, neboť ukazují, že při volání velmi jednoduché nativní metody (v níž není implementována žádná programová smyčka a podobné dlouhotrvající operace) je samotná režie volání velmi velká, což znamená, že vlastně nemá smysl se pokoušet podobné nativní metody implementovat (pokud k tomu nejsme donuceni například kvůli použití externí nativní knihovny atd.). Podívejme se tedy na poněkud složitější metodu – rekurzivní výpočet n-tého prvku Fibonacciho řady. Tato metoda bude opět implementována dvakrát – jednou v nativním kódu (nativeFibonacci) a podruhé ve formě klasické javovské metody (fibonacci):
/**
* Jednoduchy benchmark pro porovnani rychlosti nativni funkce a JITovane metody.
*
* @author Pavel Tisnovsky
*/
public class JNITest2 {
/**
* Pocet opakovani zahrivaci faze benchmarku.
*/
private static final int WARMUP_ITERS = 20000;
/**
* Pocet opakovani merene faze benchmarku.
*/
private static final int BENCHMARK_ITERS = 20000;
/**
* Nativni metoda pro vypocet n-teho prvku Fibonacciho posloupnosti.
* Pro vypocet je pouzit rekurzivni algoritmus.
*/
native public static int nativeFibonacci(int n);
/**
* Javovska metoda pro vypocet n-teho prvku Fibonacciho posloupnosti.
* Pro vypocet je pouzit rekurzivni algoritmus.
*/
public static int fibonacci(int n) {
return n<2 ? n : fibonacci(n-2) + fibonacci(n-1);
}
/**
* Spusteni benchmarku.
*/
private static void runJNIBenchmarks(int n) {
warmup(n);
benchmark(n);
}
/**
* Vypis vypocteneho vysledku (jen pro kontrolu).
*/
private static void printResult(int result) {
System.out.print(" result=");
System.out.println(result);
}
/**
* Zahrivaci faze benchmarku.
*/
private static void warmup(int n) {
System.out.println("Warmup phase...");
int result = 0;
// donutime JIT k prekladu
for (int i = 0; i < WARMUP_ITERS; i++) {
result = fibonacci(n);
}
printResult(result);
result = 0;
// taktez zde donutime JIT k prekladu
for (int i = 0; i < WARMUP_ITERS; i++) {
result = nativeFibonacci(n);
}
printResult(result);
System.out.println("done");
}
/**
* Vlastni mereny benchmark.
*/
private static void benchmark(int n) {
System.out.println("Benchmark phase...");
long t1, t2, delta_t;
// provest test a zmerit cas behu prvniho testu
t1 = System.nanoTime();
int result = 0;
for (int i = 0; i < BENCHMARK_ITERS; i++) {
result = fibonacci(n);
}
t2 = System.nanoTime();
delta_t = t2 - t1;
printResult(result);
// vypis casu pro prvni test
System.out.format("JITted method time: %,12d ns\n", delta_t);
// provest test a zmerit cas behu druheho testu
t1 = System.nanoTime();
result = 0;
for (int i = 0; i < BENCHMARK_ITERS; i++) {
result = nativeFibonacci(n);
}
t2 = System.nanoTime();
delta_t = t2 - t1;
printResult(result);
// vypis casu pro druhy test
System.out.format("native function time: %,12d ns\n", delta_t);
System.out.println("done");
}
/**
* Spusteni benchmarku.
*/
public static void main(String[] args) {
System.loadLibrary("JNITest2");
for (int n = 1; n < 20; n++) {
System.out.println("------------------------");
System.out.println("n=" + n);
runJNIBenchmarks(n);
}
}
}
Opět si necháme vygenerovat hlavičkový soubor, jehož název bude tentokrát JNITest2.h:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class JNITest2 */
#ifndef _Included_JNITest2
#define _Included_JNITest2
#ifdef __cplusplus
extern "C" {
#endif
#undef JNITest2_WARMUP_ITERS
#define JNITest2_WARMUP_ITERS 20000L
#undef JNITest2_BENCHMARK_ITERS
#define JNITest2_BENCHMARK_ITERS 20000L
/*
* Class: JNITest2
* Method: nativeFibonacci
* Signature: (I)I
*/
JNIEXPORT jint JNICALL Java_JNITest2_nativeFibonacci
(JNIEnv *, jclass, jint);
#ifdef __cplusplus
}
#endif
#endif
Samotnou nativní metodu budeme implementovat velmi jednoduše (soubor JNITest2.c):
#include <jni.h>
#include "JNITest2.h"
jint fibonacci(jint n)
{
return n<2 ? n : fibonacci(n-2) + fibonacci(n-1);
}
JNIEXPORT jint JNICALL Java_JNITest2_nativeFibonacci
(JNIEnv *jni_env, jclass klass, jint n)
{
return fibonacci(n);
}
6. Výsledky běhu druhého demonstračního příkladu
Překlad nyní provedeme dvakrát – jednou bez optimalizací a podruhé s několika optimalizacemi.
Překlad bez optimalizací na Linuxu a na Windows s mingw:
gcc -O0 -shared -I"c:\Program Files\Java\jdk1.7.0_25\include" -o JNITest2.dll JNITest2.c gcc -shared -I/usr/lib/jvm/java-7-openjdk/include/ -o libJNITest2.so JNITest2.c
Překlad s optimalizacemi na Linuxu a na Windows s mingw:
gcc -O3 -fold-unroll-all-loops -floop-optimize -shared -I"c:\Program Files\Java\jdk1.7.0_25\include" -o JNITest2.dll JNITest2.c gcc -O3 -shared -I/usr/lib/jvm/java-7-openjdk/include/ -o libJNITest2.so JNITest2.c
Samotný benchmark se spustí následovně:
export LD_LIBRARY_PATH=. java -Xcomp JNITest2
Podívejme se nyní na výsledky běhu tohoto benchmarku při vypnutí optimalizací při překladu nativní metody:
n JIT native ===================== 1 152 1071 2 277 1605 3 996 3948 4 1743 5474 5 2230 9068 6 4645 13760 7 9964 21679 8 15302 35106 9 26647 53639 10 44890 86215 11 78455 138448 12 127187 228011 13 200884 366488 14 342134 616792 15 534243 984997 16 875859 1576525 17 1410611 2603379 18 2288594 4188336 19 3685208 6719390
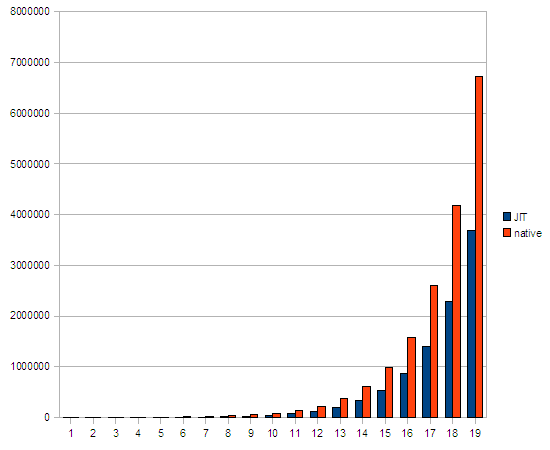
Zde tedy JIT „vyhrál“ nad voláním JNI funkce.
Při použití optimalizací při překladu nativní metody dosáhneme jen nepatrného vylepšení:
n JIT native ===================== 1 152 923 2 277 1446 3 1243 1946 4 1622 4394 5 2218 6777 6 4644 11728 7 9868 18542 8 15458 29869 9 29031 48274 10 46052 79005 11 76271 126847 12 128107 206372 13 202225 332576 14 338846 549137 15 535432 888210 16 877552 1440197 17 1410780 2313733 18 2277419 3780225 19 3672948 6098898
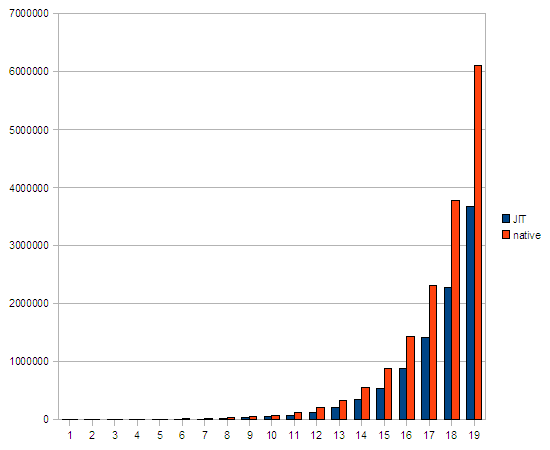
I zde je patrné, že JIT „vyhrál“ nad voláním JNI funkce.
7. Třetí demonstrační příklad JNITest3: nerekurzivní výpočet prvků Fibonacciho řady
Problémem v předchozím benchmarku byla rekurzivní povaha algoritmu, s nímž se gcc nevyrovnal zcela dobře – což pravděpodobně bude námět na diskuzi pod článkem ;-). Proto se na závěr pokusme změřit, jestli nebude výhodnější přepsat původní rekurzivní algoritmus na nerekurzivní podobu. To je v případě výpočtu prvků Fibonacciho řady poměrně jednoduché – ostatně se sami můžete podívat na těla metod nativeFibonacci() a fibonacci() implementovaných v dnešním třetím benchmarku nazvaném JNITest3:
/**
* Jednoduchy benchmark pro porovnani rychlosti nativni funkce a JITovane metody.
*
* @author Pavel Tisnovsky
*/
public class JNITest3 {
/**
* Pocet opakovani zahrivaci faze benchmarku.
*/
private static final int WARMUP_ITERS = 20000;
/**
* Pocet opakovani merene faze benchmarku.
*/
private static final int BENCHMARK_ITERS = 20000;
/**
* Nativni metoda pro vypocet n-teho prvku Fibonacciho posloupnosti.
* Pro vypocet je pouzit nerekurzivni algoritmus.
*/
native public static int nativeFibonacci(int n);
/**
* Javovska metoda pro vypocet n-teho prvku Fibonacciho posloupnosti.
* Pro vypocet je pouzit nerekurzivni algoritmus.
*/
public static int fibonacci(int n) {
if (n<2) return n;
int n0 = 1;
int n1 = 1;
for (int i = 1; i < n - 1; i++) {
int n2 = n0 + n1;
n0 = n1;
n1 = n2;
}
return n1;
}
/**
* Spusteni benchmarku.
*/
private static void runJNIBenchmarks(int n) {
warmup(n);
benchmark(n);
}
/**
* Vypis vypocteneho vysledku (jen pro kontrolu).
*/
private static void printResult(int result) {
System.out.print(" result=");
System.out.println(result);
}
/**
* Zahrivaci faze benchmarku.
*/
private static void warmup(int n) {
System.out.println("Warmup phase...");
int result = 0;
// donutime JIT k prekladu
for (int i = 0; i < WARMUP_ITERS; i++) {
result = fibonacci(n);
}
printResult(result);
result = 0;
// taktez zde donutime JIT k prekladu
for (int i = 0; i < WARMUP_ITERS; i++) {
result = nativeFibonacci(n);
}
printResult(result);
System.out.println("done");
}
/**
* Vlastni mereny benchmark.
*/
private static void benchmark(int n) {
System.out.println("Benchmark phase...");
long t1, t2, delta_t;
int result;
// provest test a zmerit cas behu prvniho testu
t1 = System.nanoTime();
result = 0;
for (int i = 0; i < BENCHMARK_ITERS; i++) {
result = fibonacci(n);
}
t2 = System.nanoTime();
delta_t = t2 - t1;
printResult(result);
// vypis casu pro prvni test
System.out.format("JITted method time: %,12d ns\n", delta_t);
// provest test a zmerit cas behu druheho testu
t1 = System.nanoTime();
result = 0;
for (int i = 0; i < BENCHMARK_ITERS; i++) {
result = nativeFibonacci(n);
}
t2 = System.nanoTime();
delta_t = t2 - t1;
printResult(result);
// vypis casu pro druhy test
System.out.format("native function time: %,12d ns\n", delta_t);
System.out.println("done");
}
/**
* Spusteni benchmarku.
*/
public static void main(String[] args) {
System.loadLibrary("JNITest3");
for (int n = 1; n < 47; n++) {
System.out.println("------------------------");
System.out.println("n=" + n);
runJNIBenchmarks(n);
}
}
}
Vygenerovaný hlavičkový soubor:
/* DO NOT EDIT THIS FILE - it is machine generated */
#include <jni.h>
/* Header for class JNITest3 */
#ifndef _Included_JNITest3
#define _Included_JNITest3
#ifdef __cplusplus
extern "C" {
#endif
#undef JNITest3_WARMUP_ITERS
#define JNITest3_WARMUP_ITERS 20000L
#undef JNITest3_BENCHMARK_ITERS
#define JNITest3_BENCHMARK_ITERS 20000L
/*
* Class: JNITest3
* Method: nativeFibonacci
* Signature: (I)I
*/
JNIEXPORT jint JNICALL Java_JNITest3_nativeFibonacci
(JNIEnv *, jclass, jint);
#ifdef __cplusplus
}
#endif
#endif
Zdrojový soubor JNITest3.c s implementací nativní metody pro výpočet prvků Fibonacciho řady:
#include <jni.h>
#include "JNITest3.h"
JNIEXPORT jint JNICALL Java_JNITest3_nativeFibonacci
(JNIEnv *jni_env, jclass klass, jint n)
{
if (n < 2) return n;
jint n0 = 1;
jint n1 = 1;
jint i;
for (i = 1; i < n - 1; i++) {
jint n2 = n0 + n1;
n0 = n1;
n1 = n2;
}
return n1;
}
8. Výsledky běhu třetího demonstračního příkladu
Při překladu nativní metody byla nejprve opět zakázána jakákoli optimalizace:
gcc -O0 -shared -I"c:\Program Files\Java\jdk1.7.0_25\include" -o JNITest3.dll JNITest3.c gcc -O0 -shared -I/usr/lib/jvm/java-7-openjdk/include/ -o libJNITest3.so JNITest3.c
Posléze byla optimalizace naopak provedena, a to i se žádostí o rozbalení smyčky atd.:
gcc -O3 -funroll-all-loops -floop-optimize -shared -I"c:\Program Files\Java\jdk1.7.0_25\include" -o JNITest3.dll JNITest3.c gcc -O3 -funroll-all-loops -floop-optimize -shared -I/usr/lib/jvm/java-7-openjdk/include/ -o libJNITest3.so JNITest3.c
Výsledky při nepoužití optimalizace při překladu opět mluví proti použití JNI:
n JIT native ===================== 1 415 942 2 438 1019 3 498 1236 4 621 1492 5 757 1762 6 882 2119 7 1005 2376 8 1138 2751 9 1278 3029 10 1896 3328 11 1672 3621 12 1712 3881 13 2745 4232 14 1987 4447 15 2065 4765 16 2260 5171 17 2679 5325 18 2518 5655 19 2896 5951 20 3653 6110 21 3490 6469 22 3134 6616 23 3161 6981 24 3515 7385 25 3403 7530 26 3678 7963 27 3693 8016 28 3941 8349 29 4619 8661 30 4694 9055 31 4266 9262 32 4267 9464 33 4503 9555 34 5335 9810 35 5373 10414 36 4825 10656 37 5229 10696 38 5129 11184 39 5238 11208 40 5662 11615 41 5549 11838 42 5728 12129 43 5815 12398 44 6013 12621 45 6085 13006 46 6734 13109

Pokud byly optimalizace zapnuty, jsou již výsledky pro JNI mnohem příznivější:

n JIT native ===================== 1 415 901 2 438 955 3 498 1111 4 634 1184 5 753 1208 6 879 1104 7 1005 1242 8 1138 1311 9 1268 1310 10 2324 1192 11 1666 1351 12 1712 1406 13 2751 1435 14 2624 1349 15 2065 1451 16 2260 1509 17 2678 1533 18 2517 1377 19 2902 1576 20 6558 1631 21 3563 1661 22 3134 1494 23 3143 1689 24 3456 1735 25 3403 1759 26 3672 1611 27 3693 1809 28 3932 1877 29 4626 1882 30 4682 1745 31 4202 1929 32 4267 1969 33 4792 2013 34 5335 1853 35 5378 2087 36 4825 2090 37 5197 2126 38 5122 2057 39 5244 2181 40 5599 2789 41 5565 2612 42 5725 2361 43 5815 2745 44 6013 2863 45 6082 2445 46 6831 2245

Na předchozím grafu stojí za povšimnutí fakt, že volání nativní metody začíná být výhodnější až ve chvíli, kdy se programová smyčka opakuje přibližně desetkrát. Při menším počtu opakování jsou veškeré výhody nativní optimalizované metody převáženy režií při volání JNI:

9. Repositář se zdrojovými soubory i se skripty pro překlad
Následuje – v tomto seriálu již tradiční – kapitola s odkazy na zdrojové kódy uložené do Mercurial repositáře. V následující tabulce najdete odkazy na prozatím nejnovější verzi dnes použitých benchmarků i skripty určené pro jejich překlad a spuštění:
10. Odkazy na Internetu
- MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - GC safe-point (or safepoint) and safe-region
http://xiao-feng.blogspot.cz/2008/01/gc-safe-point-and-safe-region.html - Safepoints in HotSpot JVM
http://blog.ragozin.info/2012/10/safepoints-in-hotspot-jvm.html - Java theory and practice: Synchronization optimizations in Mustang
http://www.ibm.com/developerworks/java/library/j-jtp10185/ - How to build hsdis
http://hg.openjdk.java.net/jdk7/hotspot/hotspot/file/tip/src/share/tools/hsdis/README - Java SE 6 Performance White Paper
http://www.oracle.com/technetwork/java/6-performance-137236.html - Lukas Stadler's Blog
http://classparser.blogspot.cz/2010/03/hsdis-i386dll.html - How to build hsdis-amd64.dll and hsdis-i386.dll on Windows
http://dropzone.nfshost.com/hsdis.htm - PrintAssembly
https://wikis.oracle.com/display/HotSpotInternals/PrintAssembly - The Java Virtual Machine Specification: 3.14. Synchronization
http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-3.html#jvms-3.14 - The Java Virtual Machine Specification: 8.3.1.4. volatile Fields
http://docs.oracle.com/javase/specs/jls/se7/html/jls-8.html#jls-8.3.1.4 - The Java Virtual Machine Specification: 17.4. Memory Model
http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.4 - The Java Virtual Machine Specification: 17.7. Non-atomic Treatment of double and long
http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.7 - Open Source ByteCode Libraries in Java
http://java-source.net/open-source/bytecode-libraries - ASM Home page
http://asm.ow2.org/ - Seznam nástrojů využívajících projekt ASM
http://asm.ow2.org/users.html - ObjectWeb ASM (Wikipedia)
http://en.wikipedia.org/wiki/ObjectWeb_ASM - Java Bytecode BCEL vs ASM
http://james.onegoodcookie.com/2005/10/26/java-bytecode-bcel-vs-asm/ - BCEL Home page
http://commons.apache.org/bcel/ - Byte Code Engineering Library (před verzí 5.0)
http://bcel.sourceforge.net/ - Byte Code Engineering Library (verze >= 5.0)
http://commons.apache.org/proper/commons-bcel/ - BCEL Manual
http://commons.apache.org/bcel/manual.html - Byte Code Engineering Library (Wikipedia)
http://en.wikipedia.org/wiki/BCEL - BCEL Tutorial
http://www.smfsupport.com/support/java/bcel-tutorial!/ - Bytecode Engineering
http://book.chinaunix.net/special/ebook/Core_Java2_Volume2AF/0131118269/ch13lev1sec6.html - Bytecode Outline plugin for Eclipse (screenshoty + info)
http://asm.ow2.org/eclipse/index.html - Javassist
http://www.jboss.org/javassist/ - Byteman
http://www.jboss.org/byteman - Java programming dynamics, Part 7: Bytecode engineering with BCEL
http://www.ibm.com/developerworks/java/library/j-dyn0414/ - The JavaTM Virtual Machine Specification, Second Edition
http://java.sun.com/docs/books/jvms/second_edition/html/VMSpecTOC.doc.html - The class File Format
http://java.sun.com/docs/books/jvms/second_edition/html/ClassFile.doc.html - javap – The Java Class File Disassembler
http://docs.oracle.com/javase/1.4.2/docs/tooldocs/windows/javap.html - javap-java-1.6.0-openjdk(1) – Linux man page
http://linux.die.net/man/1/javap-java-1.6.0-openjdk - Using javap
http://www.idevelopment.info/data/Programming/java/miscellaneous_java/Using_javap.html - Examine class files with the javap command
http://www.techrepublic.com/article/examine-class-files-with-the-javap-command/5815354 - aspectj (Eclipse)
http://www.eclipse.org/aspectj/ - Aspect-oriented programming (Wikipedia)
http://en.wikipedia.org/wiki/Aspect_oriented_programming - AspectJ (Wikipedia)
http://en.wikipedia.org/wiki/AspectJ - EMMA: a free Java code coverage tool
http://emma.sourceforge.net/ - Cobertura
http://cobertura.sourceforge.net/ - jclasslib bytecode viewer
http://www.ej-technologies.com/products/jclasslib/overview.html




































