Obsah
2. Rozšíření instrukční sady MMX
3. Rozšíření instrukční sady SSE2
4. Použití MMX a SSE2 v System.arraycopy()
5. Blokové přesuny dat pomocí MMX
6. Blokové přesuny dat pomocí SSE2
7. Funkce System.arraycopy() a přesuny nezarovnaných dat
8. Demonstrační benchmark ArrayCopyTest3.java
11. Výsledky běhu benchmarku – Intel Celeron M, 32bitový režim
12. Výsledky běhu benchmarku – Intel Xeon, 64bitový režim
13. Výsledky běhu benchmarku – AMD Opteron, 64bitový režim
1. Pohled pod kapotu JVM – základy optimalizace aplikací naprogramovaných v Javě (použití MMX a SSE2)
Při implementaci a především pak při optimalizaci funkce System.arraycopy() se museli programátoři potýkat s relativně velkým množstvím problémů. První problém se týká kopií prvků v případě, že celkový počet přenesených bajtů není zarovnán na hodnotu 4 či 8. Druhý problém spočívá v kopiích prvků, které již od začátku nejsou zarovnány. Tento problém nastává v praxi poměrně často, neboť si musíme uvědomit, že System.arraycopy() lze použít i pro pole typu byte[], short[] či char[], zatímco moderní mikroprocesory mají 32bitové či 64bitové sběrnice upravené a optimalizované pro přenos dat zarovnaných na násobky 4, 8 či někdy i 16 bajtů, což u výše zmíněných polí nelze zaručit (přesněji řečeno je samotný začátek pole zarovnán správně, ovšem offset může být nastaven například na liché číslo, popř. číslo nedělitelné 4, 8 či 16). Touto problematikou i způsobem jejího řešení se budeme zabývat v následujících kapitolách. Nejprve si však řekneme základní informace o rozšíření instrukčních sad MMX a SSE2, neboť právě tato rozšíření jsou při kopii polí využívána.
2. Rozšíření instrukční sady MMX
Instrukční sada mikroprocesorů řady x86 začala být poměrně brzy doplňována o další instrukce, které v některých případech tvořily ucelené rozšíření instrukční sady o celou množinu instrukcí orientovaných na určitý problém (operace nad vektory celých čísel, operace nad vektory čísel s plovoucí řádovou čárkou atd.). Jedním ze známých a dodnes používaných rozšíření původní instrukční sady je rozšiřující sada instrukcí nazvaná MMX (MultiMedia eXtension, později taktéž rozepisováno jako Matrix Math eXtension). Toto rozšíření bylo navrženo v roce 1996 ve firmě Intel a od roku 1997 jí začaly být vybavovány prakticky všechny nové procesory této firmy, které patřily do rodiny x86 (připomeňme si, že se tehdy ještě jednalo o 32bitové mikroprocesory, protože k rozšíření na 64bitovou ALU došlo u mainstreamových čipů až o několik let později).
Prvním mikroprocesorem s podporou MMX byl čip Pentium P55C nabízený od začátku roku 1997. Později došlo k implementaci MMX i na čipy Pentium II a procesory konkurenčních společností, konkrétně na čipy AMD K6 a taktéž na Cyrix M2 (6×86MX) a IDT C6. Na tomto místě je nutné říci, že se vlastně nejednalo o nijak přelomovou technologii, protože v instrukční sadě MMX jsou použity instrukce analogické instrukcím ze SPARC VIS (VIS=Visual Instruction Set), MIPS MDMX či HP-PA MAX-1 a HP-PA MAX-2 (opět se tedy jedná o technologii inspirovanou RISCovými procesory).
V rámci instrukční sady MMX se na původně prakticky ryze skalární platformu x86 přidalo celkem 57 nových instrukcí a čtyři datové typy, které byly těmito instrukcemi podporovány. Jeden z nově zaváděných datových typů je skalární, další tři nové datové typy jsou představovány dvouprvkovým, čtyřprvkovým a osmiprvkovým vektorem:
| Datový typ | Bitová šířka operandu | Počet prvků vektoru |
|---|---|---|
| packed byte | 8 bitů | 8 |
| packed word | 16 bitů | 4 |
| packed doubleword | 32 bitů | 2 |
| quadword | 64 bitů | 1 |
Inženýři ve firmě Intel stáli při návrhu instrukční sady MMX před požadavkem na vytvoření výkonných instrukcí provádějících SIMD operace, na druhou stranu však bylo nutné šetřit počtem tranzistorů a tím pádem i plochou čipu, na němž byl mikroprocesor vytvořen. Pravděpodobně právě z tohoto důvodu se rozhodli učinit poněkud problematický krok – navrhli MMX instrukce takovým způsobem, aby mohly pracovat s osmicí 64bitových registrů rozdělených na jeden, dva, čtyři či osm prvků. Ovšem nejednalo se o nové registry rozšiřující původní sadu registrů procesoru Pentium, ale o část registrů využívaných matematickým koprocesorem (FPU). Ten na platformě x86 prováděl operace s osmicí 80bitových registrů uspořádaných do zásobníku (u matematického koprocesoru Intel 8087 byly používány čistě zásobníkové instrukce, později byly přidány i další adresovací režimy, které umožňovaly registry adresovat přímo, což se ukázalo být výhodnější především kvůli možnostem provádění různých optimalizací).
V případě instrukcí MMX se sice registry adresovaly přímo (popř. se adresovala slova uložená v operační paměti, která mohla tvořit jeden z operandů), ale kvůli tomu, že jak FPU, tak i jednotka MMX pracovala se shodnými registry (horních 16 bitů nebylo využito), bylo současné používání SIMD operací a operací s hodnotami uloženými v systému plovoucí řádové čárky poměrně komplikované, což je škoda, protože právě souběžná práce superskalárního CPU (u mikroprocesorů Pentium byly vytvořeny dvě instrukční pipeline „u“ a „v“), jednotky MMX a navíc ještě matematického koprocesoru by v mnoha případech mohla vést k citelnému nárůstu výpočetního výkonu. V následující tabulce jsou vypsána jména registrů tak, jak jsou použita v instrukcích matematického koprocesoru, i ve formě používané jednotkou MMX:
| Registr FPU | bity 79–64 | bity 63–0 |
|---|---|---|
| ST0 | nepoužito | MMX0 |
| ST1 | nepoužito | MMX1 |
| ST2 | nepoužito | MMX2 |
| ST3 | nepoužito | MMX3 |
| ST4 | nepoužito | MMX4 |
| ST5 | nepoužito | MMX5 |
| ST6 | nepoužito | MMX6 |
| ST7 | nepoužito | MMX7 |
Pro přesuny mezi těmito registry a operační pamětí se používá instrukce movq. Způsob použití registrů MMX? při kopii prvků pole uvidíme v navazujících kapitolách.
3. Rozšíření instrukční sady SSE2
V roce 1999 firma Intel navrhla další rozšíření původní instrukční sady mikroprocesorů řady x86. Toto rozšíření bylo pojmenováno SSE (Streaming SIMD Extensions). Díky zavedení této technologie došlo k přidání osmi nových pracovních registrů s – na platformě x86 doposud nevídanou – šířkou 128 bitů. Vzhledem k tomu, že se změnil počet pracovních registrů, bylo nutné některé části systému i aplikací upravit takovým způsobem, aby při přepnutí kontextu nedocházelo ke vzájemnému přepisování těchto registrů (ovšem jen za předpokladu, že operační systém práci s instrukcemi SSE povolil).
Rozšiřující instrukční sada SSE obsahovala sedmdesát nových instrukcí orientovaných většinou na práci s vektory obsahujícími čtyři čísla typu single. Jednalo se o výrazné zlepšení oproti možnostem nabízeným konkurenční sadou 3DNow!, protože při práci s reálnými čísly s jednoduchou přesností bylo možné teoreticky dosáhnout až dvojnásobného výpočetního výkonu v porovnání s 3DNow! a čtyřnásobného výkonu oproti práci se skalárním matematickým koprocesorem.
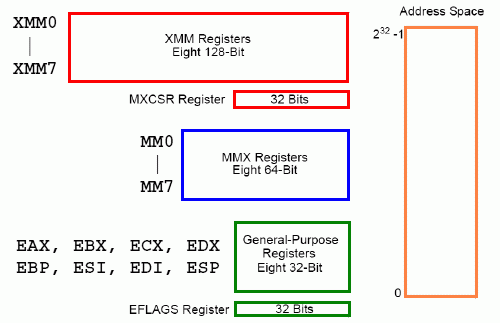
Obrázek 1: Zjednodušený programátorský model mikroprocesoru x86 s podporou MMX a SSE (i SSE2). V rámci MMX došlo k přidání osmice 64bitových registrů sdílených s FPU (modrý rámeček), zatímco v rámci SSE bylo přidáno osm registrů 128bitových a 32bitového řídicího registru MXCSR (dva červené rámečky).
Zatímco se v rozšiřující instrukční sadě SSE nacházelo „pouze“ 70 nových instrukcí, byli tvůrci instrukční sady SSE2 mnohem velkorysejší, protože navrhli a posléze i implementovali hned 144 nových instrukcí, což přibližně odpovídá počtu všech základních instrukcí procesorů x86 (pokud samozřejmě nepočítáme všechny povolené adresní režimy). Tento velký počet nových instrukcí souvisí jak s podporou šesti různých datových typů (včetně více než dvaceti konverzních funkcí), tak i s novými režimy přístupu k prvkům uloženým ve vektorech a se zcela novými operacemi, které byly navrženy pro podporu algoritmů pro 3D grafiku a práci s videem. Z našeho pohledu je důležitá především instrukce movdqu umožňující přenos celého vektoru i z nezarovnané adresy.
4. Použití MMX a SSE2 v System.arraycopy()
V předchozích dvou kapitolách jsme si (velmi stručně) popsali základní vlastnosti rozšíření instrukční sady MMX a SSE2. Podívejme se nyní na způsob použití těchto rozšíření v implementaci funkce System.arraycopy(). Ve zdrojových kódech Hotspotu můžeme nalézt ve funkci generate_disjoint_copy() mj. i následující podmínku (s poněkud matoucí poznámkou :-), v níž se virtuální stroj rozhoduje, zda se pro kopii prvků polí použijí instrukce MMX nebo SSE2. Tento rozeskok je řízen jak dopředu detekovanými možnostmi mikroprocesoru, tak i volbou UseXMMForArrayCopy popsanou v předchozí části seriálu:
//
// Copy 8-byte chunks through MMX registers, 8 per iteration of the loop
//
if (UseXMMForArrayCopy)
{
xmm_copy_forward(from, to_from, rax);
}
else
{
mmx_copy_forward(from, to_from, rax);
}
5. Blokové přesuny dat pomocí MMX
Funkce nazvaná mmx_copy_forward() využívá pro generování strojového kódu pro kopii prvků polí všech osm registrů MMX, o nichž jsme se zmínili ve druhé kapitole. Již při zavolání této funkce je zaručeno, že se bude v každé iteraci kopírovat 64 bajtů, případné zbylé bajty na konci již jsou kopírovány v jiné části kódu (mj. i v závěrečné části této funkce, která bude začínat na návěští L_copy8_bytes). Povšimněte si, jakým způsobem je vlastně strojový kód generován – hlavní smyčka pro kopii začíná generováním návěští L_copy64_bytes_loop a vlastní smyčka je vlastně osmkrát „rozbalena“, proto se na konci počitadlo zvyšuje o hodnotu 64 (8 bajtů × 8 rozbalení smyčky). Registry MMX jsou zde použity z toho důvodu, že instrukce movq nedokáže přenášet data z paměti do paměti:
// Copy 64 bytes chunks
//
// Inputs:
// from - source array address
// to_from - destination array address - from
// qword_count - 8-bytes element count, negative
//
void mmx_copy_forward(Register from, Register to_from, Register qword_count) {
assert( VM_Version::supports_mmx(), "supported cpu only" );
Label L_copy_64_bytes_loop, L_copy_64_bytes, L_copy_8_bytes, L_exit;
// Copy 64-byte chunks
__ jmpb(L_copy_64_bytes);
__ align(OptoLoopAlignment);
__ BIND(L_copy_64_bytes_loop);
__ movq(mmx0, Address(from, 0));
__ movq(mmx1, Address(from, 8));
__ movq(mmx2, Address(from, 16));
__ movq(Address(from, to_from, Address::times_1, 0), mmx0);
__ movq(mmx3, Address(from, 24));
__ movq(Address(from, to_from, Address::times_1, 8), mmx1);
__ movq(mmx4, Address(from, 32));
__ movq(Address(from, to_from, Address::times_1, 16), mmx2);
__ movq(mmx5, Address(from, 40));
__ movq(Address(from, to_from, Address::times_1, 24), mmx3);
__ movq(mmx6, Address(from, 48));
__ movq(Address(from, to_from, Address::times_1, 32), mmx4);
__ movq(mmx7, Address(from, 56));
__ movq(Address(from, to_from, Address::times_1, 40), mmx5);
__ movq(Address(from, to_from, Address::times_1, 48), mmx6);
__ movq(Address(from, to_from, Address::times_1, 56), mmx7);
__ addptr(from, 64);
__ BIND(L_copy_64_bytes);
__ subl(qword_count, 8);
__ jcc(Assembler::greaterEqual, L_copy_64_bytes_loop);
__ addl(qword_count, 8);
__ jccb(Assembler::zero, L_exit);
//
// length is too short, just copy qwords
//
__ BIND(L_copy_8_bytes);
__ movq(mmx0, Address(from, 0));
__ movq(Address(from, to_from, Address::times_1), mmx0);
__ addptr(from, 8);
__ decrement(qword_count);
__ jcc(Assembler::greater, L_copy_8_bytes);
__ BIND(L_exit);
__ emms();
}
6. Blokové přesuny dat pomocí SSE2
Výše popsaná funkce mmx_copy_forward() byla vlastně velmi jednoduchá a výsledný strojový kód lze spustit na všech mikroprocesorech s podporou MMX. Druhá alternativně používaná funkce generující strojový kód pro kopii prvků pole se jmenuje xmm_copy_forward() (rozdíl v názvech je v prefixu mmx/xmm!). Zde již můžeme nalézt zajímavou novinku – na základě hodnoty přepínače UseUnalignedLoadStores (taktéž popsaného minule) je zde provedeno rozhodnutí, zda se ve vytvořené programové smyčce použije instrukce movdqu umožňující přesun potenciálně nezarovnaných 128 bitů (16 bajtů), nebo zda se má použít nám již známá instrukce movq, která však dokáže přenést jen osm bajtů, tudíž musí být smyčka rozbalena osmkrát. Ve druhém případě se vlastně nevyužijí všechny možnosti, která nám SSE2 a její 128bitové registry dávají, což se odrazí na výsledné výkonnosti vygenerovaného strojového kódu funkce System.arraycopy():
// Copy 64 bytes chunks
//
// Inputs:
// from - source array address
// to_from - destination array address - from
// qword_count - 8-bytes element count, negative
//
void xmm_copy_forward(Register from, Register to_from, Register qword_count) {
assert( UseSSE >= 2, "supported cpu only" );
Label L_copy_64_bytes_loop, L_copy_64_bytes, L_copy_8_bytes, L_exit;
// Copy 64-byte chunks
__ jmpb(L_copy_64_bytes);
__ align(OptoLoopAlignment);
__ BIND(L_copy_64_bytes_loop);
if(UseUnalignedLoadStores) {
__ movdqu(xmm0, Address(from, 0));
__ movdqu(Address(from, to_from, Address::times_1, 0), xmm0);
__ movdqu(xmm1, Address(from, 16));
__ movdqu(Address(from, to_from, Address::times_1, 16), xmm1);
__ movdqu(xmm2, Address(from, 32));
__ movdqu(Address(from, to_from, Address::times_1, 32), xmm2);
__ movdqu(xmm3, Address(from, 48));
__ movdqu(Address(from, to_from, Address::times_1, 48), xmm3);
} else {
__ movq(xmm0, Address(from, 0));
__ movq(Address(from, to_from, Address::times_1, 0), xmm0);
__ movq(xmm1, Address(from, 8));
__ movq(Address(from, to_from, Address::times_1, 8), xmm1);
__ movq(xmm2, Address(from, 16));
__ movq(Address(from, to_from, Address::times_1, 16), xmm2);
__ movq(xmm3, Address(from, 24));
__ movq(Address(from, to_from, Address::times_1, 24), xmm3);
__ movq(xmm4, Address(from, 32));
__ movq(Address(from, to_from, Address::times_1, 32), xmm4);
__ movq(xmm5, Address(from, 40));
__ movq(Address(from, to_from, Address::times_1, 40), xmm5);
__ movq(xmm6, Address(from, 48));
__ movq(Address(from, to_from, Address::times_1, 48), xmm6);
__ movq(xmm7, Address(from, 56));
__ movq(Address(from, to_from, Address::times_1, 56), xmm7);
}
__ addl(from, 64);
__ BIND(L_copy_64_bytes);
__ subl(qword_count, 8);
__ jcc(Assembler::greaterEqual, L_copy_64_bytes_loop);
__ addl(qword_count, 8);
__ jccb(Assembler::zero, L_exit);
//
// length is too short, just copy qwords
//
__ BIND(L_copy_8_bytes);
__ movq(xmm0, Address(from, 0));
__ movq(Address(from, to_from, Address::times_1), xmm0);
__ addl(from, 8);
__ decrement(qword_count);
__ jcc(Assembler::greater, L_copy_8_bytes);
__ BIND(L_exit);
}
7. Funkce System.arraycopy() a přesuny nezarovnaných dat
Funkci System.arraycopy() je možné využít pro přesuny prvků mezi poli různých typů. Minule se v benchmarku používala pole typu int [], ovšem velmi často se můžeme setkat s kopií prvků mezi poli typu byte [] (obrázky atd.) a především pak char [] (stačí se podívat do zdrojového kódu třídy String). U polí typu byte[] a char[] nastává problém se zarovnáním kopírovaných prvků, neboť i když první prvek pole je zarovnán vždy, kvůli možnosti specifikace offsetu je možné kopii zahájit na adrese, která není dělitelná ani osmi a dokonce ani čtyřmi. Jak (a zda vůbec) se problém se zarovnáním projeví, v praxi zjistíme pomocí jednoduchého benchmarku, jehož zdrojový kód bude popsán v navazující kapitole.
8. Demonstrační benchmark ArrayCopyTest3.java
Demonstrační benchmark nazvaný ArrayCopyTest3.java se v mnoha ohledech podobá minule popsanému benchmarku ArrayCopy2.java, jsou zde však tři podstatné rozdíly. První rozdíl spočívá samozřejmě ve faktu, že se namísto polí typu int[] kopírují prvky mezi poli typu byte[]. Došlo taktéž k rozšíření metod testArrayCopy*, protože byly přidány metody, v nichž je použit shodný offset jak pro zdrojové, tak i pro cílové pole. Nejdůležitější změnou však je, že se celý benchmark rozdělil na dvě části – kopie prvků s nezarovnanými offsety a kopie prvků zarovnaných na 16 bitů (2 bajty), 32 bitů (4 bajty) a 64 bitů (8 bajtů). To mj. znamená, že při běhu benchmarku dostaneme vždy čtyři výsledky pro každý z osmi testů:
/**
* Benchmark pro zjisteni intrinsic "funkci" implementujicich
* @link System#arraycopy(java.lang.Object, int, java.lang.Object, int, int).
* V tomto benchmarku se provadi kopie prvku typu byte s ruznym zarovnanim dat.
*
* @author Pavel Tisnovsky
*/
public class ArrayCopyTest3 {
private static final int ARRAYS_LENGTH = 50000;
private static final int WARMUP_ITERS = 20000;
private static final int BENCHMARK_ITERS = 20000;
/** Pole pouzivana pro kopii prvku v benchmarku */
static byte[] src = new byte[ARRAYS_LENGTH];
static byte[] dest = new byte[ARRAYS_LENGTH];
/** Kopie mezi rozdilnymi poli, oba offsety jsou nulove */
public static void testArrayCopy1(int offset, int length) {
System.arraycopy(src, 0, dest, 0, length);
}
/** Kopie mezi rozdilnymi poli, nulovy je jen druhy offset */
public static void testArrayCopy2(int offset, int length) {
System.arraycopy(src, offset, dest, 0, length);
}
/** Kopie mezi rozdilnymi poli, nulovy je jen prvni offset */
public static void testArrayCopy3(int offset, int length) {
System.arraycopy(src, 0, dest, offset, length);
}
/** Kopie mezi rozdilnymi poli, oba offsety jsou shodne */
public static void testArrayCopy4(int offset, int length) {
System.arraycopy(src, offset, dest, offset, length);
}
/** Kopie prvku v jednom poli, oba offsety jsou nulove */
public static void testArrayCopy5(int offset, int length) {
System.arraycopy(src, 0, src, 0, length);
}
/** Kopie prvku v jednom poli, nulovy je jen druhy offset */
public static void testArrayCopy6(int offset, int length) {
System.arraycopy(src, offset, src, 0, length);
}
/** Kopie prvku v jednom poli, nulovy je jen prvni offset */
public static void testArrayCopy7(int offset, int length) {
System.arraycopy(src, 0, src, offset, length);
}
/** Kopie prvku v jednom poli, oba offsety jsou shodne */
public static void testArrayCopy8(int offset, int length) {
System.arraycopy(src, offset, src, offset, length);
}
/**
* Spusteni vsech benchmarku.
*/
private static void runSimpleBenchmarks() {
warmup();
// zarovnani dat
int align = 1;
for (int test = 1; test <= 4; test++) {
// spustit jednotlivy bechmark
benchmarkWithAlignedArray(test, align);
align *= 2;
}
}
/**
* Zahrivaci faze benchmarku.
*/
private static void warmup() {
System.out.println("Warmup phase...");
// donutime JIT k prekladu, soucasne se vsak neprekroci
// meze poli
for (int j = 0; j < 10; j++) {
System.out.print(j);
System.out.print(' ');
for (int i = 0; i < WARMUP_ITERS; i++) {
testArrayCopy1(i, i);
testArrayCopy2(i, i);
testArrayCopy3(i, i);
testArrayCopy4(i, i);
testArrayCopy5(i, i);
testArrayCopy6(i, i);
testArrayCopy7(i, i);
testArrayCopy8(i, i);
}
}
System.out.println(" done");
}
/**
* Benchmark se zarovanim
*/
private static void benchmarkWithAlignedArray(int benchmarkNo, int align) {
long t1, t2, delta_t;
long total_t = 0;
System.out.println("Benchmark #" + benchmarkNo);
for (int testNo = 1; testNo <= 8; testNo++) {
// provest test a zmerit cas behu testu
t1 = System.nanoTime();
for (int i = 0; i < BENCHMARK_ITERS; i++) {
// vypocet adresy pro zarovnani
int offset = align == 0 ? i : i - (i % align);
// skarede, ale zde nelze pouzit reflexi
// (stale cekame na moznost pouziti referenci na metody!)
for (int j = 0; j < 10; j++) {
switch (testNo) {
case 1: testArrayCopy1(offset, offset); break;
case 2: testArrayCopy2(offset, offset); break;
case 3: testArrayCopy3(offset, offset); break;
case 4: testArrayCopy4(offset, offset); break;
case 5: testArrayCopy5(offset, offset); break;
case 6: testArrayCopy6(offset, offset); break;
case 7: testArrayCopy7(offset, offset); break;
case 8: testArrayCopy8(offset, offset); break;
}
}
}
t2 = System.nanoTime();
delta_t = t2 - t1;
total_t += delta_t;
// vypis casu pro jeden test
System.out.format("Method ArrayCopyTest.testArrayCopy%d time: %,12d ns\n", testNo, delta_t);
}
System.out.format("Total time: %,12d\n", total_t);
}
/**
* Start benchmarku.
*/
public static void main(String[] args) {
runSimpleBenchmarks();
}
}
// finito
9. Bajtkód benchmarku
Ještě před zveřejněním výsledků benchmarku se podívejme na bajtkód všech osmi testovacích metod testArrayCopy1. Z následujícího výpisu je patrné, že překladač javac neprovedl žádné optimalizace, což je ovšem očekávatelné chování:
public static void testArrayCopy1(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iconst_0
4: getstatic #3 // Field dest:[B
7: iconst_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy2(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iload_0
4: getstatic #3 // Field dest:[B
7: iconst_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy3(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iconst_0
4: getstatic #3 // Field dest:[B
7: iload_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy4(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iload_0
4: getstatic #3 // Field dest:[B
7: iload_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy5(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iconst_0
4: getstatic #2 // Field src:[B
7: iconst_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy6(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iload_0
4: getstatic #2 // Field src:[B
7: iconst_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy7(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iconst_0
4: getstatic #2 // Field src:[B
7: iload_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
public static void testArrayCopy8(int, int);
Code:
0: getstatic #2 // Field src:[B
3: iload_0
4: getstatic #2 // Field src:[B
7: iload_0
8: iload_1
9: invokestatic #4 // Method java/lang/System.arraycopy:(Ljava/lang/Object;ILjava/lang/Object;II)V
12: return
10. Spuštění benchmarku
Konečně se dostáváme k běhu dnešního testovacího benchmarku. Ten byl postupně spuštěn na třech počítačích vybavených různými typy mikroprocesorů. Spuštění na každém počítači proběhlo celkem čtyřikrát a použily se přitom všechny kombinace přepínačů UseXMMForArrayCopy a UseUnalignedLoadStores. První volba CompileThreshold je zde pouze pro jistotu, aby se zaručilo, že k JIT kompilaci dojde již v zahřívací fázi benchmarku:
java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3
11. Výsledky běhu benchmarku – Intel Celeron M, 32bitový režim
První běh benchmarku proběhl na počítači s mikroprocesorem Intel Celeron M, tj. použit byl 32bitový režim. Výsledky jsou zde velmi zajímavé a ukazují na to, že použití přepínače UseUnalignedLoadStores je zde kontraproduktivní, nezávisle na zarovnání:
















java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 582 159 462 ns Method ArrayCopyTest.testArrayCopy2 time: 1 020 880 866 ns Method ArrayCopyTest.testArrayCopy3 time: 908 134 414 ns Method ArrayCopyTest.testArrayCopy4 time: 566 883 780 ns Method ArrayCopyTest.testArrayCopy5 time: 385 383 616 ns Method ArrayCopyTest.testArrayCopy6 time: 910 200 318 ns Method ArrayCopyTest.testArrayCopy7 time: 917 916 942 ns Method ArrayCopyTest.testArrayCopy8 time: 388 817 852 ns Total time: 5 680 377 250 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 594 311 568 ns Method ArrayCopyTest.testArrayCopy2 time: 880 523 922 ns Method ArrayCopyTest.testArrayCopy3 time: 869 595 718 ns Method ArrayCopyTest.testArrayCopy4 time: 558 030 980 ns Method ArrayCopyTest.testArrayCopy5 time: 384 607 262 ns Method ArrayCopyTest.testArrayCopy6 time: 860 973 950 ns Method ArrayCopyTest.testArrayCopy7 time: 869 157 392 ns Method ArrayCopyTest.testArrayCopy8 time: 386 541 026 ns Total time: 5 403 741 818 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 551 635 474 ns Method ArrayCopyTest.testArrayCopy2 time: 763 892 336 ns Method ArrayCopyTest.testArrayCopy3 time: 763 726 676 ns Method ArrayCopyTest.testArrayCopy4 time: 557 804 972 ns Method ArrayCopyTest.testArrayCopy5 time: 382 451 680 ns Method ArrayCopyTest.testArrayCopy6 time: 767 211 474 ns Method ArrayCopyTest.testArrayCopy7 time: 775 241 824 ns Method ArrayCopyTest.testArrayCopy8 time: 384 974 906 ns Total time: 4 946 939 342 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 548 616 934 ns Method ArrayCopyTest.testArrayCopy2 time: 555 296 834 ns Method ArrayCopyTest.testArrayCopy3 time: 565 167 360 ns Method ArrayCopyTest.testArrayCopy4 time: 556 930 838 ns Method ArrayCopyTest.testArrayCopy5 time: 383 483 374 ns Method ArrayCopyTest.testArrayCopy6 time: 576 107 578 ns Method ArrayCopyTest.testArrayCopy7 time: 580 265 926 ns Method ArrayCopyTest.testArrayCopy8 time: 383 883 706 ns Total time: 4 149 752 550
java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 784 363 376 ns Method ArrayCopyTest.testArrayCopy2 time: 952 110 396 ns Method ArrayCopyTest.testArrayCopy3 time: 966 767 286 ns Method ArrayCopyTest.testArrayCopy4 time: 772 235 298 ns Method ArrayCopyTest.testArrayCopy5 time: 684 697 358 ns Method ArrayCopyTest.testArrayCopy6 time: 937 867 800 ns Method ArrayCopyTest.testArrayCopy7 time: 969 225 420 ns Method ArrayCopyTest.testArrayCopy8 time: 686 645 370 ns Total time: 6 753 912 304 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 771 479 616 ns Method ArrayCopyTest.testArrayCopy2 time: 895 695 404 ns Method ArrayCopyTest.testArrayCopy3 time: 937 790 140 ns Method ArrayCopyTest.testArrayCopy4 time: 769 634 130 ns Method ArrayCopyTest.testArrayCopy5 time: 683 443 844 ns Method ArrayCopyTest.testArrayCopy6 time: 916 239 076 ns Method ArrayCopyTest.testArrayCopy7 time: 943 044 996 ns Method ArrayCopyTest.testArrayCopy8 time: 685 717 038 ns Total time: 6 603 044 244 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 764 334 014 ns Method ArrayCopyTest.testArrayCopy2 time: 847 251 258 ns Method ArrayCopyTest.testArrayCopy3 time: 885 242 398 ns Method ArrayCopyTest.testArrayCopy4 time: 767 676 340 ns Method ArrayCopyTest.testArrayCopy5 time: 680 948 834 ns Method ArrayCopyTest.testArrayCopy6 time: 867 578 420 ns Method ArrayCopyTest.testArrayCopy7 time: 891 481 460 ns Method ArrayCopyTest.testArrayCopy8 time: 684 789 266 ns Total time: 6 389 301 990 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 763 448 706 ns Method ArrayCopyTest.testArrayCopy2 time: 773 788 570 ns Method ArrayCopyTest.testArrayCopy3 time: 773 850 868 ns Method ArrayCopyTest.testArrayCopy4 time: 768 479 234 ns Method ArrayCopyTest.testArrayCopy5 time: 683 120 062 ns Method ArrayCopyTest.testArrayCopy6 time: 785 139 170 ns Method ArrayCopyTest.testArrayCopy7 time: 789 182 424 ns Method ArrayCopyTest.testArrayCopy8 time: 682 502 384 ns Total time: 6 019 511 418
java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 1 334 243 318 ns Method ArrayCopyTest.testArrayCopy2 time: 1 361 655 740 ns Method ArrayCopyTest.testArrayCopy3 time: 1 362 195 476 ns Method ArrayCopyTest.testArrayCopy4 time: 1 231 543 956 ns Method ArrayCopyTest.testArrayCopy5 time: 1 735 656 348 ns Method ArrayCopyTest.testArrayCopy6 time: 1 295 616 344 ns Method ArrayCopyTest.testArrayCopy7 time: 1 358 155 018 ns Method ArrayCopyTest.testArrayCopy8 time: 1 464 517 138 ns Total time: 11 143 583 338
Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 1 327 318 696 ns Method ArrayCopyTest.testArrayCopy2 time: 1 280 500 174 ns Method ArrayCopyTest.testArrayCopy3 time: 1 319 262 364 ns Method ArrayCopyTest.testArrayCopy4 time: 1 133 852 486 ns Method ArrayCopyTest.testArrayCopy5 time: 1 733 376 170 ns Method ArrayCopyTest.testArrayCopy6 time: 1 244 037 998 ns Method ArrayCopyTest.testArrayCopy7 time: 1 316 091 012 ns Method ArrayCopyTest.testArrayCopy8 time: 1 307 733 804 ns Total time: 10 662 172 704 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 1 317 418 274 ns Method ArrayCopyTest.testArrayCopy2 time: 1 179 543 490 ns Method ArrayCopyTest.testArrayCopy3 time: 1 233 368 208 ns Method ArrayCopyTest.testArrayCopy4 time: 954 346 712 ns Method ArrayCopyTest.testArrayCopy5 time: 1 767 438 320 ns Method ArrayCopyTest.testArrayCopy6 time: 1 157 340 110 ns Method ArrayCopyTest.testArrayCopy7 time: 1 241 038 734 ns Method ArrayCopyTest.testArrayCopy8 time: 998 609 040 ns Total time: 9 849 102 888 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 1 315 249 284 ns Method ArrayCopyTest.testArrayCopy2 time: 1 390 619 758 ns Method ArrayCopyTest.testArrayCopy3 time: 1 405 160 712 ns Method ArrayCopyTest.testArrayCopy4 time: 1 327 227 622 ns Method ArrayCopyTest.testArrayCopy5 time: 1 740 936 070 ns Method ArrayCopyTest.testArrayCopy6 time: 1 339 399 280 ns Method ArrayCopyTest.testArrayCopy7 time: 1 399 582 348 ns Method ArrayCopyTest.testArrayCopy8 time: 1 624 700 904 ns Total time: 11 542 875 978
java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 1 783 176 632 ns Method ArrayCopyTest.testArrayCopy2 time: 1 661 709 520 ns Method ArrayCopyTest.testArrayCopy3 time: 1 779 508 848 ns Method ArrayCopyTest.testArrayCopy4 time: 1 815 211 430 ns Method ArrayCopyTest.testArrayCopy5 time: 2 453 363 766 ns Method ArrayCopyTest.testArrayCopy6 time: 1 592 581 460 ns Method ArrayCopyTest.testArrayCopy7 time: 1 776 573 838 ns Method ArrayCopyTest.testArrayCopy8 time: 2 470 235 742 ns Total time: 15 332 361 236 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 1 766 891 324 ns Method ArrayCopyTest.testArrayCopy2 time: 1 556 098 890 ns Method ArrayCopyTest.testArrayCopy3 time: 1 703 022 310 ns Method ArrayCopyTest.testArrayCopy4 time: 1 688 697 026 ns Method ArrayCopyTest.testArrayCopy5 time: 2 451 716 908 ns Method ArrayCopyTest.testArrayCopy6 time: 1 529 903 942 ns Method ArrayCopyTest.testArrayCopy7 time: 1 689 830 970 ns Method ArrayCopyTest.testArrayCopy8 time: 2 227 066 290 ns Total time: 14 613 227 660 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 1 776 224 912 ns Method ArrayCopyTest.testArrayCopy2 time: 1 421 730 416 ns Method ArrayCopyTest.testArrayCopy3 time: 1 506 859 672 ns Method ArrayCopyTest.testArrayCopy4 time: 1 430 964 830 ns Method ArrayCopyTest.testArrayCopy5 time: 2 436 675 050 ns Method ArrayCopyTest.testArrayCopy6 time: 1 425 725 334 ns Method ArrayCopyTest.testArrayCopy7 time: 1 505 594 706 ns Method ArrayCopyTest.testArrayCopy8 time: 1 774 720 810 ns Total time: 13 278 495 730 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 1 761 900 744 ns Method ArrayCopyTest.testArrayCopy2 time: 1 686 475 518 ns Method ArrayCopyTest.testArrayCopy3 time: 1 872 410 602 ns Method ArrayCopyTest.testArrayCopy4 time: 1 942 591 306 ns Method ArrayCopyTest.testArrayCopy5 time: 2 446 848 694 ns Method ArrayCopyTest.testArrayCopy6 time: 1 652 086 506 ns Method ArrayCopyTest.testArrayCopy7 time: 1 861 271 196 ns Method ArrayCopyTest.testArrayCopy8 time: 2 707 789 676 ns Total time: 15 931 374 242
12. Výsledky běhu benchmarku – Intel Xeon, 64bitový režim
Další počítač byl vybaven čtyřmi mikroprocesory Intel Xeon, ovšem při běhu byl využit jen jediný z těchto čipů:
processor : 0 vendor_id : GenuineIntel cpu family : 6 model : 15 model name : Intel(R) Xeon(R) CPU X3220 @ 2.40GHz stepping : 11 cpu MHz : 1600.000 cache size : 4096 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 4 apicid : 0 initial apicid : 0 fpu : yes fpu_exception : yes cpuid level : 10 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx lm constant_tsc arch_perfmon pebs bts rep_good aperfmperf pni dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm lahf_lm dts tpr_shadow vnmi flexpriority bogomips : 4800.53 clflush size : 64 cache_alignment : 64 address sizes : 36 bits physical, 48 bits virtual power management:
I zde jsou výsledky poměrně zajímavé. Především je patrná problematická kopie prvků na stejné místo v operační paměti (shodné zdrojové a cílové pole, shodné offsety), což poněkud překvapivě není JIT překladačem zdetekováno. Dále zde můžeme vidět, jak pomáhá zarovnání prvků na 2, 4 a 8 bajtů, což je pochopitelné, neboť Intel Xeon je 64bitový mikroprocesor. Přepínač UseUnalignedLoadStores zde má navíc pozitivní efekt, na rozdíl od mikroprocesoru Intel Celeron M:















java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 150,253,975 ns Method ArrayCopyTest.testArrayCopy2 time: 387,015,315 ns Method ArrayCopyTest.testArrayCopy3 time: 311,134,882 ns Method ArrayCopyTest.testArrayCopy4 time: 490,229,219 ns Method ArrayCopyTest.testArrayCopy5 time: 108,898,195 ns Method ArrayCopyTest.testArrayCopy6 time: 386,127,506 ns Method ArrayCopyTest.testArrayCopy7 time: 308,954,311 ns Method ArrayCopyTest.testArrayCopy8 time: 1,259,313,819 ns Total time: 3,401,927,222 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 148,035,135 ns Method ArrayCopyTest.testArrayCopy2 time: 352,216,529 ns Method ArrayCopyTest.testArrayCopy3 time: 289,365,053 ns Method ArrayCopyTest.testArrayCopy4 time: 441,759,013 ns Method ArrayCopyTest.testArrayCopy5 time: 108,672,719 ns Method ArrayCopyTest.testArrayCopy6 time: 353,356,766 ns Method ArrayCopyTest.testArrayCopy7 time: 287,850,435 ns Method ArrayCopyTest.testArrayCopy8 time: 1,094,764,136 ns Total time: 3,076,019,786 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 145,689,088 ns Method ArrayCopyTest.testArrayCopy2 time: 284,079,621 ns Method ArrayCopyTest.testArrayCopy3 time: 244,568,776 ns Method ArrayCopyTest.testArrayCopy4 time: 344,351,130 ns Method ArrayCopyTest.testArrayCopy5 time: 108,618,008 ns Method ArrayCopyTest.testArrayCopy6 time: 286,872,077 ns Method ArrayCopyTest.testArrayCopy7 time: 243,825,301 ns Method ArrayCopyTest.testArrayCopy8 time: 765,544,075 ns Total time: 2,423,548,076 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 145,472,753 ns Method ArrayCopyTest.testArrayCopy2 time: 150,435,476 ns Method ArrayCopyTest.testArrayCopy3 time: 155,575,448 ns Method ArrayCopyTest.testArrayCopy4 time: 150,576,347 ns Method ArrayCopyTest.testArrayCopy5 time: 108,542,178 ns Method ArrayCopyTest.testArrayCopy6 time: 155,649,938 ns Method ArrayCopyTest.testArrayCopy7 time: 155,055,840 ns Method ArrayCopyTest.testArrayCopy8 time: 108,755,286 ns Total time: 1,130,063,266
java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 150,317,175 ns Method ArrayCopyTest.testArrayCopy2 time: 387,483,951 ns Method ArrayCopyTest.testArrayCopy3 time: 311,097,061 ns Method ArrayCopyTest.testArrayCopy4 time: 490,243,696 ns Method ArrayCopyTest.testArrayCopy5 time: 108,917,514 ns Method ArrayCopyTest.testArrayCopy6 time: 386,151,866 ns Method ArrayCopyTest.testArrayCopy7 time: 308,851,362 ns Method ArrayCopyTest.testArrayCopy8 time: 1,259,389,483 ns Total time: 3,402,452,108 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 148,451,477 ns Method ArrayCopyTest.testArrayCopy2 time: 352,161,760 ns Method ArrayCopyTest.testArrayCopy3 time: 288,472,709 ns Method ArrayCopyTest.testArrayCopy4 time: 441,780,629 ns Method ArrayCopyTest.testArrayCopy5 time: 108,678,846 ns Method ArrayCopyTest.testArrayCopy6 time: 353,355,277 ns Method ArrayCopyTest.testArrayCopy7 time: 287,836,930 ns Method ArrayCopyTest.testArrayCopy8 time: 1,094,791,997 ns Total time: 3,075,529,625 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 146,111,416 ns Method ArrayCopyTest.testArrayCopy2 time: 284,095,704 ns Method ArrayCopyTest.testArrayCopy3 time: 245,878,613 ns Method ArrayCopyTest.testArrayCopy4 time: 344,335,579 ns Method ArrayCopyTest.testArrayCopy5 time: 108,625,014 ns Method ArrayCopyTest.testArrayCopy6 time: 286,870,378 ns Method ArrayCopyTest.testArrayCopy7 time: 243,807,748 ns Method ArrayCopyTest.testArrayCopy8 time: 765,619,350 ns Total time: 2,425,343,802 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 145,504,646 ns Method ArrayCopyTest.testArrayCopy2 time: 150,413,097 ns Method ArrayCopyTest.testArrayCopy3 time: 155,591,185 ns Method ArrayCopyTest.testArrayCopy4 time: 150,637,178 ns Method ArrayCopyTest.testArrayCopy5 time: 108,555,157 ns Method ArrayCopyTest.testArrayCopy6 time: 155,693,763 ns Method ArrayCopyTest.testArrayCopy7 time: 155,051,413 ns Method ArrayCopyTest.testArrayCopy8 time: 108,751,122 ns Total time: 1,130,197,561
java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 293,162,313 ns Method ArrayCopyTest.testArrayCopy2 time: 437,410,295 ns Method ArrayCopyTest.testArrayCopy3 time: 487,553,409 ns Method ArrayCopyTest.testArrayCopy4 time: 688,942,719 ns Method ArrayCopyTest.testArrayCopy5 time: 290,957,296 ns Method ArrayCopyTest.testArrayCopy6 time: 437,137,649 ns Method ArrayCopyTest.testArrayCopy7 time: 486,103,241 ns Method ArrayCopyTest.testArrayCopy8 time: 990,002,519 ns Total time: 4,111,269,441 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 291,383,874 ns Method ArrayCopyTest.testArrayCopy2 time: 415,546,370 ns Method ArrayCopyTest.testArrayCopy3 time: 460,015,314 ns Method ArrayCopyTest.testArrayCopy4 time: 632,019,304 ns Method ArrayCopyTest.testArrayCopy5 time: 290,781,297 ns Method ArrayCopyTest.testArrayCopy6 time: 416,637,669 ns Method ArrayCopyTest.testArrayCopy7 time: 458,586,799 ns Method ArrayCopyTest.testArrayCopy8 time: 889,958,282 ns Total time: 3,854,928,909 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 290,979,742 ns Method ArrayCopyTest.testArrayCopy2 time: 374,632,385 ns Method ArrayCopyTest.testArrayCopy3 time: 405,152,949 ns Method ArrayCopyTest.testArrayCopy4 time: 518,406,102 ns Method ArrayCopyTest.testArrayCopy5 time: 290,772,484 ns Method ArrayCopyTest.testArrayCopy6 time: 375,564,692 ns Method ArrayCopyTest.testArrayCopy7 time: 403,586,675 ns Method ArrayCopyTest.testArrayCopy8 time: 689,828,765 ns Total time: 3,348,923,794 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 290,891,370 ns Method ArrayCopyTest.testArrayCopy2 time: 294,150,448 ns Method ArrayCopyTest.testArrayCopy3 time: 295,781,195 ns Method ArrayCopyTest.testArrayCopy4 time: 291,827,693 ns Method ArrayCopyTest.testArrayCopy5 time: 290,690,920 ns Method ArrayCopyTest.testArrayCopy6 time: 294,430,379 ns Method ArrayCopyTest.testArrayCopy7 time: 294,471,100 ns Method ArrayCopyTest.testArrayCopy8 time: 290,869,381 ns Total time: 2,343,112,486
java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 293,392,397 ns Method ArrayCopyTest.testArrayCopy2 time: 437,436,143 ns Method ArrayCopyTest.testArrayCopy3 time: 487,564,074 ns Method ArrayCopyTest.testArrayCopy4 time: 688,843,577 ns Method ArrayCopyTest.testArrayCopy5 time: 290,909,880 ns Method ArrayCopyTest.testArrayCopy6 time: 437,097,680 ns Method ArrayCopyTest.testArrayCopy7 time: 486,009,540 ns Method ArrayCopyTest.testArrayCopy8 time: 989,898,576 ns Total time: 4,111,151,867 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 291,373,156 ns Method ArrayCopyTest.testArrayCopy2 time: 415,460,120 ns Method ArrayCopyTest.testArrayCopy3 time: 459,955,630 ns Method ArrayCopyTest.testArrayCopy4 time: 631,970,012 ns Method ArrayCopyTest.testArrayCopy5 time: 290,724,598 ns Method ArrayCopyTest.testArrayCopy6 time: 416,585,025 ns Method ArrayCopyTest.testArrayCopy7 time: 458,523,902 ns Method ArrayCopyTest.testArrayCopy8 time: 889,837,330 ns Total time: 3,854,429,773 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 290,968,433 ns Method ArrayCopyTest.testArrayCopy2 time: 374,555,839 ns Method ArrayCopyTest.testArrayCopy3 time: 405,089,400 ns Method ArrayCopyTest.testArrayCopy4 time: 518,407,880 ns Method ArrayCopyTest.testArrayCopy5 time: 291,004,878 ns Method ArrayCopyTest.testArrayCopy6 time: 375,508,215 ns Method ArrayCopyTest.testArrayCopy7 time: 403,562,766 ns Method ArrayCopyTest.testArrayCopy8 time: 689,779,529 ns Total time: 3,348,876,940 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 290,873,806 ns Method ArrayCopyTest.testArrayCopy2 time: 294,123,182 ns Method ArrayCopyTest.testArrayCopy3 time: 295,750,289 ns Method ArrayCopyTest.testArrayCopy4 time: 291,802,565 ns Method ArrayCopyTest.testArrayCopy5 time: 290,665,220 ns Method ArrayCopyTest.testArrayCopy6 time: 294,399,761 ns Method ArrayCopyTest.testArrayCopy7 time: 294,466,604 ns Method ArrayCopyTest.testArrayCopy8 time: 290,837,821 ns Total time: 2,342,919,248
13. Výsledky běhu benchmarku – AMD Opteron, 64bitový režim
Poslední test proběhl na počítači vybaveném osmicí mikroprocesorů AMD Quad-Core Opteron:

processor : 0 vendor_id : AuthenticAMD cpu family : 16 model : 2 model name : Quad-Core AMD Opteron(tm) Processor 2350 stepping : 3 cpu MHz : 1000.000 cache size : 512 KB physical id : 0 siblings : 4 core id : 0 cpu cores : 4 apicid : 0 fpu : yes fpu_exception : yes cpuid level : 5 wp : yes flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm 3dnowext 3dnow constant_tsc nonstop_tsc pni cx16 popcnt lahf_lm cmp_legacy svm extapic cr8_legacy altmovcr8 abm sse4a misalignsse 3dnowprefetch osvw bogomips : 3989.99 TLB size : 1024 4K pages clflush size : 64 cache_alignment : 64 address sizes : 48 bits physical, 48 bits virtual power management: ts ttp tm stc 100mhzsteps hwpstate [8]
Zde jsou výsledky velmi vyrovnané, bez ohledu na zarovnání a použití přepínačů UseXMMForArrayCopy a UseUnalignedLoadStores. Jedinou výjimkou je opět kopie prvků na sebe sama ve stejném poli a se shodným offsetem, zejména v případě nezarovnaných dat (offset není dělitelný osmi):
















java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 149,266,000 ns Method ArrayCopyTest.testArrayCopy2 time: 249,969,000 ns Method ArrayCopyTest.testArrayCopy3 time: 224,961,000 ns Method ArrayCopyTest.testArrayCopy4 time: 301,420,000 ns Method ArrayCopyTest.testArrayCopy5 time: 143,368,000 ns Method ArrayCopyTest.testArrayCopy6 time: 234,235,000 ns Method ArrayCopyTest.testArrayCopy7 time: 213,358,000 ns Method ArrayCopyTest.testArrayCopy8 time: 1,154,655,000 ns Total time: 2,671,232,000 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 142,888,000 ns Method ArrayCopyTest.testArrayCopy2 time: 230,755,000 ns Method ArrayCopyTest.testArrayCopy3 time: 213,826,000 ns Method ArrayCopyTest.testArrayCopy4 time: 277,550,000 ns Method ArrayCopyTest.testArrayCopy5 time: 141,704,000 ns Method ArrayCopyTest.testArrayCopy6 time: 222,858,000 ns Method ArrayCopyTest.testArrayCopy7 time: 202,097,000 ns Method ArrayCopyTest.testArrayCopy8 time: 845,650,000 ns Total time: 2,277,328,000 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 142,702,000 ns Method ArrayCopyTest.testArrayCopy2 time: 208,558,000 ns Method ArrayCopyTest.testArrayCopy3 time: 200,345,000 ns Method ArrayCopyTest.testArrayCopy4 time: 234,583,000 ns Method ArrayCopyTest.testArrayCopy5 time: 142,902,000 ns Method ArrayCopyTest.testArrayCopy6 time: 204,007,000 ns Method ArrayCopyTest.testArrayCopy7 time: 186,366,000 ns Method ArrayCopyTest.testArrayCopy8 time: 232,387,000 ns Total time: 1,551,850,000 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 142,688,000 ns Method ArrayCopyTest.testArrayCopy2 time: 166,772,000 ns Method ArrayCopyTest.testArrayCopy3 time: 168,386,000 ns Method ArrayCopyTest.testArrayCopy4 time: 147,190,000 ns Method ArrayCopyTest.testArrayCopy5 time: 143,243,000 ns Method ArrayCopyTest.testArrayCopy6 time: 164,366,000 ns Method ArrayCopyTest.testArrayCopy7 time: 156,452,000 ns Method ArrayCopyTest.testArrayCopy8 time: 142,863,000 ns Total time: 1,231,960,000
java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:-UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 149,846,000 ns Method ArrayCopyTest.testArrayCopy2 time: 247,209,000 ns Method ArrayCopyTest.testArrayCopy3 time: 227,488,000 ns Method ArrayCopyTest.testArrayCopy4 time: 302,458,000 ns Method ArrayCopyTest.testArrayCopy5 time: 143,474,000 ns Method ArrayCopyTest.testArrayCopy6 time: 235,238,000 ns Method ArrayCopyTest.testArrayCopy7 time: 213,341,000 ns Method ArrayCopyTest.testArrayCopy8 time: 1,155,744,000 ns Total time: 2,674,798,000 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 143,034,000 ns Method ArrayCopyTest.testArrayCopy2 time: 227,141,000 ns Method ArrayCopyTest.testArrayCopy3 time: 216,618,000 ns Method ArrayCopyTest.testArrayCopy4 time: 280,975,000 ns Method ArrayCopyTest.testArrayCopy5 time: 143,226,000 ns Method ArrayCopyTest.testArrayCopy6 time: 225,851,000 ns Method ArrayCopyTest.testArrayCopy7 time: 204,318,000 ns Method ArrayCopyTest.testArrayCopy8 time: 847,147,000 ns Total time: 2,288,310,000 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 142,781,000 ns Method ArrayCopyTest.testArrayCopy2 time: 206,391,000 ns Method ArrayCopyTest.testArrayCopy3 time: 200,550,000 ns Method ArrayCopyTest.testArrayCopy4 time: 237,726,000 ns Method ArrayCopyTest.testArrayCopy5 time: 142,831,000 ns Method ArrayCopyTest.testArrayCopy6 time: 205,559,000 ns Method ArrayCopyTest.testArrayCopy7 time: 188,201,000 ns Method ArrayCopyTest.testArrayCopy8 time: 232,530,000 ns Total time: 1,556,569,000 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 142,672,000 ns Method ArrayCopyTest.testArrayCopy2 time: 163,804,000 ns Method ArrayCopyTest.testArrayCopy3 time: 172,232,000 ns Method ArrayCopyTest.testArrayCopy4 time: 152,889,000 ns Method ArrayCopyTest.testArrayCopy5 time: 142,836,000 ns Method ArrayCopyTest.testArrayCopy6 time: 164,437,000 ns Method ArrayCopyTest.testArrayCopy7 time: 158,228,000 ns Method ArrayCopyTest.testArrayCopy8 time: 143,126,000 ns Total time: 1,240,224,000
java -server -XX:CompileThreshold=10000 -XX:-UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 200,516,000 ns Method ArrayCopyTest.testArrayCopy2 time: 188,695,000 ns Method ArrayCopyTest.testArrayCopy3 time: 220,978,000 ns Method ArrayCopyTest.testArrayCopy4 time: 200,452,000 ns Method ArrayCopyTest.testArrayCopy5 time: 215,284,000 ns Method ArrayCopyTest.testArrayCopy6 time: 177,400,000 ns Method ArrayCopyTest.testArrayCopy7 time: 210,219,000 ns Method ArrayCopyTest.testArrayCopy8 time: 1,008,838,000 ns Total time: 2,422,382,000 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 196,126,000 ns Method ArrayCopyTest.testArrayCopy2 time: 176,397,000 ns Method ArrayCopyTest.testArrayCopy3 time: 215,512,000 ns Method ArrayCopyTest.testArrayCopy4 time: 194,907,000 ns Method ArrayCopyTest.testArrayCopy5 time: 214,823,000 ns Method ArrayCopyTest.testArrayCopy6 time: 174,391,000 ns Method ArrayCopyTest.testArrayCopy7 time: 205,960,000 ns Method ArrayCopyTest.testArrayCopy8 time: 739,572,000 ns Total time: 2,117,688,000 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 195,898,000 ns Method ArrayCopyTest.testArrayCopy2 time: 169,772,000 ns Method ArrayCopyTest.testArrayCopy3 time: 205,281,000 ns Method ArrayCopyTest.testArrayCopy4 time: 184,077,000 ns Method ArrayCopyTest.testArrayCopy5 time: 214,285,000 ns Method ArrayCopyTest.testArrayCopy6 time: 168,742,000 ns Method ArrayCopyTest.testArrayCopy7 time: 196,480,000 ns Method ArrayCopyTest.testArrayCopy8 time: 200,333,000 ns Total time: 1,534,868,000 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 195,146,000 ns Method ArrayCopyTest.testArrayCopy2 time: 158,979,000 ns Method ArrayCopyTest.testArrayCopy3 time: 190,278,000 ns Method ArrayCopyTest.testArrayCopy4 time: 164,419,000 ns Method ArrayCopyTest.testArrayCopy5 time: 214,066,000 ns Method ArrayCopyTest.testArrayCopy6 time: 157,164,000 ns Method ArrayCopyTest.testArrayCopy7 time: 179,507,000 ns Method ArrayCopyTest.testArrayCopy8 time: 173,350,000 ns Total time: 1,432,909,000
java -server -XX:CompileThreshold=10000 -XX:+UseXMMForArrayCopy -XX:+UseUnalignedLoadStores ArrayCopyTest3 Warmup phase... 0 1 2 3 4 5 6 7 8 9 done Benchmark #1 Method ArrayCopyTest.testArrayCopy1 time: 202,619,000 ns Method ArrayCopyTest.testArrayCopy2 time: 186,705,000 ns Method ArrayCopyTest.testArrayCopy3 time: 221,659,000 ns Method ArrayCopyTest.testArrayCopy4 time: 204,394,000 ns Method ArrayCopyTest.testArrayCopy5 time: 217,842,000 ns Method ArrayCopyTest.testArrayCopy6 time: 178,402,000 ns Method ArrayCopyTest.testArrayCopy7 time: 210,449,000 ns Method ArrayCopyTest.testArrayCopy8 time: 1,020,494,000 ns Total time: 2,442,564,000 Benchmark #2 Method ArrayCopyTest.testArrayCopy1 time: 197,996,000 ns Method ArrayCopyTest.testArrayCopy2 time: 177,941,000 ns Method ArrayCopyTest.testArrayCopy3 time: 217,767,000 ns Method ArrayCopyTest.testArrayCopy4 time: 198,722,000 ns Method ArrayCopyTest.testArrayCopy5 time: 217,220,000 ns Method ArrayCopyTest.testArrayCopy6 time: 175,509,000 ns Method ArrayCopyTest.testArrayCopy7 time: 205,956,000 ns Method ArrayCopyTest.testArrayCopy8 time: 747,727,000 ns Total time: 2,138,838,000 Benchmark #3 Method ArrayCopyTest.testArrayCopy1 time: 197,015,000 ns Method ArrayCopyTest.testArrayCopy2 time: 171,053,000 ns Method ArrayCopyTest.testArrayCopy3 time: 206,438,000 ns Method ArrayCopyTest.testArrayCopy4 time: 186,913,000 ns Method ArrayCopyTest.testArrayCopy5 time: 216,747,000 ns Method ArrayCopyTest.testArrayCopy6 time: 169,362,000 ns Method ArrayCopyTest.testArrayCopy7 time: 195,872,000 ns Method ArrayCopyTest.testArrayCopy8 time: 202,696,000 ns Total time: 1,546,096,000 Benchmark #4 Method ArrayCopyTest.testArrayCopy1 time: 196,602,000 ns Method ArrayCopyTest.testArrayCopy2 time: 159,434,000 ns Method ArrayCopyTest.testArrayCopy3 time: 190,690,000 ns Method ArrayCopyTest.testArrayCopy4 time: 166,287,000 ns Method ArrayCopyTest.testArrayCopy5 time: 217,335,000 ns Method ArrayCopyTest.testArrayCopy6 time: 158,155,000 ns Method ArrayCopyTest.testArrayCopy7 time: 178,859,000 ns Method ArrayCopyTest.testArrayCopy8 time: 175,414,000 ns Total time: 1,442,776,000
14. Repositář s benchmarkem
Následuje – v tomto seriálu již tradiční – kapitola s odkazy na zdrojové kódy uložené do Mercurial repositáře. V následující tabulce najdete odkazy na prozatím nejnovější verzi dnes použitého benchmarku i výsledku běhu tohoto benchmarku:
| # | Zdrojový soubor/skript | Umístění souboru v repositáři |
|---|---|---|
| 1 | ArrayCopyTest3.java | http://icedtea.classpath.org/people/ptisnovs/jvm-tools/file/b32c0ecc3d9e/jit/ArrayCopyTest3/ArrayCopyTest3.java |
| 2 | celeron_m.txt | http://icedtea.classpath.org/people/ptisnovs/jvm-tools/file/b32c0ecc3d9e/jit/ArrayCopyTest3/celeron_m.txt |
| 3 | xeon.txt | http://icedtea.classpath.org/people/ptisnovs/jvm-tools/file/b32c0ecc3d9e/jit/ArrayCopyTest3/xeon.txt |
| 4 | opteron.txt | http://icedtea.classpath.org/people/ptisnovs/jvm-tools/file/b32c0ecc3d9e/jit/ArrayCopyTest3/opteron.txt |
15. Odkazy na Internetu
- MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - GC safe-point (or safepoint) and safe-region
http://xiao-feng.blogspot.cz/2008/01/gc-safe-point-and-safe-region.html - Safepoints in HotSpot JVM
http://blog.ragozin.info/2012/10/safepoints-in-hotspot-jvm.html - Java theory and practice: Synchronization optimizations in Mustang
http://www.ibm.com/developerworks/java/library/j-jtp10185/ - How to build hsdis
http://hg.openjdk.java.net/jdk7/hotspot/hotspot/file/tip/src/share/tools/hsdis/README - Java SE 6 Performance White Paper
http://www.oracle.com/technetwork/java/6-performance-137236.html - Lukas Stadler's Blog
http://classparser.blogspot.cz/2010/03/hsdis-i386dll.html - How to build hsdis-amd64.dll and hsdis-i386.dll on Windows
http://dropzone.nfshost.com/hsdis.htm - PrintAssembly
https://wikis.oracle.com/display/HotSpotInternals/PrintAssembly - The Java Virtual Machine Specification: 3.14. Synchronization
http://docs.oracle.com/javase/specs/jvms/se7/html/jvms-3.html#jvms-3.14 - The Java Virtual Machine Specification: 8.3.1.4. volatile Fields
http://docs.oracle.com/javase/specs/jls/se7/html/jls-8.html#jls-8.3.1.4 - The Java Virtual Machine Specification: 17.4. Memory Model
http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.4 - The Java Virtual Machine Specification: 17.7. Non-atomic Treatment of double and long
http://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.7 - Open Source ByteCode Libraries in Java
http://java-source.net/open-source/bytecode-libraries - ASM Home page
http://asm.ow2.org/ - Seznam nástrojů využívajících projekt ASM
http://asm.ow2.org/users.html - ObjectWeb ASM (Wikipedia)
http://en.wikipedia.org/wiki/ObjectWeb_ASM - Java Bytecode BCEL vs ASM
http://james.onegoodcookie.com/2005/10/26/java-bytecode-bcel-vs-asm/ - BCEL Home page
http://commons.apache.org/bcel/ - Byte Code Engineering Library (před verzí 5.0)
http://bcel.sourceforge.net/ - Byte Code Engineering Library (verze >= 5.0)
http://commons.apache.org/proper/commons-bcel/ - BCEL Manual
http://commons.apache.org/bcel/manual.html - Byte Code Engineering Library (Wikipedia)
http://en.wikipedia.org/wiki/BCEL - BCEL Tutorial
http://www.smfsupport.com/support/java/bcel-tutorial!/ - Bytecode Engineering
http://book.chinaunix.net/special/ebook/Core_Java2_Volume2AF/0131118269/ch13lev1sec6.html - Bytecode Outline plugin for Eclipse (screenshoty + info)
http://asm.ow2.org/eclipse/index.html - Javassist
http://www.jboss.org/javassist/ - Byteman
http://www.jboss.org/byteman - Java programming dynamics, Part 7: Bytecode engineering with BCEL
http://www.ibm.com/developerworks/java/library/j-dyn0414/ - The JavaTM Virtual Machine Specification, Second Edition
http://java.sun.com/docs/books/jvms/second_edition/html/VMSpecTOC.doc.html - The class File Format
http://java.sun.com/docs/books/jvms/second_edition/html/ClassFile.doc.html - javap – The Java Class File Disassembler
http://docs.oracle.com/javase/1.4.2/docs/tooldocs/windows/javap.html - javap-java-1.6.0-openjdk(1) – Linux man page
http://linux.die.net/man/1/javap-java-1.6.0-openjdk - Using javap
http://www.idevelopment.info/data/Programming/java/miscellaneous_java/Using_javap.html - Examine class files with the javap command
http://www.techrepublic.com/article/examine-class-files-with-the-javap-command/5815354 - aspectj (Eclipse)
http://www.eclipse.org/aspectj/ - Aspect-oriented programming (Wikipedia)
http://en.wikipedia.org/wiki/Aspect_oriented_programming - AspectJ (Wikipedia)
http://en.wikipedia.org/wiki/AspectJ - EMMA: a free Java code coverage tool
http://emma.sourceforge.net/ - Cobertura
http://cobertura.sourceforge.net/ - jclasslib bytecode viewer
http://www.ej-technologies.com/products/jclasslib/overview.html




































