
Obsah
1. Pokročilejší operace nabízené systémem RabbitMQ
2. Použití explicitně specifikované fronty pro posílání i pro výběr zpráv
3. Upravené implementace producenta i konzumenta zpráv
4. Zjištění aktuálně vytvořených front a směrovačů příkazem rabbitmqctl
5. Zobecnění předchozích skriptů
6. Specifikace jména fronty použité producentem i konzumentem na příkazové řádce
7. Rozvětvení (fanout) zpráv do většího množství front
8. Konfigurace exchange s navázáním front
9. Poslání zpráv s jejich rozvětvením do trojice front
10. Směrování zpráv do front na základě klíče a nakonfigurovaných výrazů
11. Konfigurace směrování a navázání front se specifikací směrovacího klíče
12. Implementace producenta posílajícího zprávy s tématem (topicem)
14. Prioritní fronty v systému RabbitMQ
15. Konfigurace prioritní fronty
17. Specifikace priority posílané zprávy
18. Pořadí přijatých zpráv s prioritami
19. Repositář s demonstračními příklady
1. Pokročilejší operace nabízené systémem RabbitMQ
V úvodním článku jsme se seznámili se základními vlastnostmi systému RabbitMQ a ukázali jsme si, jakým způsobem je možné použít jednoduchou aplikaci typu producent-konzument, v níž se využije jediná pojmenovaná fronta (queue) a výchozí konfigurace systému pro směrování zpráv do front (exchange). Dnes si ukážeme některé další možnosti, které nám systém RabbitMQ nabízí. Nejprve použijeme výchozí strategii směrování zpráv, ovšem s využitím několika pojmenovaných front. Posléze si ukážeme způsob provedení rozvětvení (fanout) zpráv do většího množství front, což je druhá velmi často používaná strategie (představit si můžeme například její využití v komunikačních programech apod.). Samozřejmě nezapomeneme ani na další strategii směrování zpráv, která se nazývá topic a v níž je možné při konfiguraci směrovače použít specifické regulární výrazy, což umožňuje i tvorbu aplikací s poměrně komplikovaným směrováním zpráv.
V systému RabbitMQ je možné použít i takzvané prioritní fronty (priority queue), které umožňují, aby zprávám posílaným do front byla přiřazena priorita a zprávy byly podle této priority uspořádány (i když přesné pořadí zpráv není systémem zaručeno). I s touto konfigurací se pochopitelně seznámíme, i když se pravděpodobně v praxi nevyužívá tak často (protože podobného chování můžeme dosáhnout využitím několika front). Všechny dnes použité demonstrační příklady budou opět vytvořeny v programovacím jazyku Pythonu a budou postaveny nad knihovnou Pika, kterou jsme využili i minule.
2. Použití explicitně specifikované fronty pro posílání i pro výběr zpráv
Většina demonstračních příkladů, s nimiž jsme se seznámili minule, používala jak pro producenta zpráv, tak i pro jejich konzumenta (konzumenty) shodný modul nazvaný rabbitmq_connect.py s funkcí pojmenovanou connect. Tato funkce je určena pro připojení k systému RabbitMQ, otevření komunikačního kanálu a následně pro vytvoření nové pojmenované fronty přiřazené ke zvolenému kanálu. Fronta se vytvoří pouze ve chvíli, pokud ještě neexistuje, tj. v případě, že RabbitMQ neobsahuje frontu shodného jména:
def connect(where='localhost', queue_name='test'):
connection = pika.BlockingConnection(pika.ConnectionParameters(where))
channel = connection.channel()
# pokus o nové vytvoření fronty ve skutečnosti neovlivní již existující frontu
channel.queue_declare(queue=queue_name)
return connection, channel
Funkce connect sice skutečně může být v praxi použita, ovšem ve chvíli, kdy budeme potřebovat pracovat s větším množstvím front popř. bude nutné nějakým způsobem nakonfigurovat směrování zpráv, nám již současné navázání připojení a otevření kanálu s konfigurací fronty nebude dostačovat a budeme vyžadovat větší flexibilitu.
Z tohoto důvodu budeme v dalších demonstračních příkladech používat upravený modul rabbitmq_connect.py, v němž jsou deklarovány dvě funkce. První z nich (jmenuje se connect) slouží pouze k otevření připojení k běžícímu serveru RabbitMQ (ve výchozím nastavení se jedná o server provozovaný na stejném počítači) a druhá funkce otevře komunikační kanál a pokusí se vytvořit frontu specifikovaného jména (výchozí jméno fronty je „test“). Opět platí, že pokud fronta se zadaným jménem již existuje, nebude mít pokus o její vytvoření žádný vliv ani na RabbitMQ, ani na producenta či konzumenta. Jedná se tedy o idempotentní operaci. Nová podoba modulu rabbitmq_connect bude následující:
import pika
def connect(where='localhost'):
connection = pika.BlockingConnection(pika.ConnectionParameters(where))
return connection
def open_channel(connection, queue_name='test'):
# pokus o nové vytvoření fronty ve skutečnosti neovlivní již existující frontu
channel = connection.channel()
channel.queue_declare(queue=queue_name)
return channel
3. Upravené implementace producenta i konzumenta zpráv
Producent, který bude používat novou implementaci výše popsaného modulu rabbitmq_connect.py, se ve skutečnosti změní jen minimálně. V následujícím zdrojovém kódu enqueue_work.py, v němž se posílá jediná zpráva do fronty „test“, se pouze musí zavolat jak funkce connect(), tak i funkce open_channel(); samozřejmě v tomto vypsaném pořadí. Následně již můžeme do systému poslat zprávy metodou channel.basic_publish() a spojení uzavřít pomocí connection.close():
#!/usr/bin/env python
from rabbitmq_connect import connect, open_channel
connection = connect()
channel = open_channel(connection)
channel.basic_publish(exchange='',
routing_key='test',
body='Hello World!')
print("Sent 'Hello World!'")
connection.close()
V tomto skriptu se zpráva posílá metodou channel.basic_publish. Povšimněte si, že v této metodě specifikujeme tři pojmenované parametry. První z těchto parametrů (exchange) určuje strategii směrování zpráv do front. Výchozí strategií (prázdný řetězec) je směrování do fronty, jejíž název odpovídá řetězci předaného v parametru routing_key. Parametr body obsahuje vlastní tělo zprávy, což je buď řetězec nebo sekvence bajtů.
Na následujícím schématu je naznačeno, že zprávy se nejprve pošlou do exchange a teprve na základě zvolené konfigurace se přesměrují do nějaké fronty popř. se rozvětví (fanout) do většího množství front:

Obrázek 1: Interní konfigurovatelná struktura systému RabbitMQ.
Podobnou úpravu provedeme i v producentovi deseti zpráv poslaných do fronty pojmenované „test“. Základní struktura skriptu zůstává stejná, pouze se namísto jedné zprávy pošle zpráv deset:
#!/usr/bin/env python
from rabbitmq_connect import connect, open_channel
connection = connect()
channel = open_channel(connection)
for i in range(1, 11):
channel.basic_publish(exchange='',
routing_key='test',
body='Hello World! #{i}'.format(i=i))
print("Sent 'Hello World!' ten times")
connection.close()
Konzument zpráv z fronty „test“ je složitější než producent, a to z toho důvodu, že je zapotřebí naprogramovat callback funkci zavolanou automaticky ve chvíli, kdy je z fronty vyzvednuta nová zpráva. Současně budeme s využitím metody channel.basic_qos(prefetch_count=1) specifikovat, že si konzument nemá vyzvedávat větší množství zpráv, což by do určité míry znemožnilo paralelní spuštění většího množství konzumentů (workerů), kteří by se o zprávy spravedlivě dělili. Ovšem postup otevření připojení a získání komunikačního kanálu zůstává zachován:
#!/usr/bin/env python
from time import sleep
from rabbitmq_connect import connect, open_channel
connection = connect()
channel = open_channel(connection)
def on_receive(ch, method, properties, body):
print("Received %r" % body)
sleep(5)
print("Done processing %r" % body)
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_receive,
queue='test',
no_ack=False)
print('Waiting for messages. To exit press CTRL+C')
print("...")
channel.start_consuming()
4. Zjištění aktuálně vytvořených front a směrovačů příkazem rabbitmqctl
V úvodním článku o systému RabbitMQ jsme si mj. řekli, že RabbitMQ se většinou spouští ve funkci démona, resp. služby. Jakmile server běží, je možné použít příkaz rabbitmqctl, který slouží pro změnu konfigurace serveru, pro správu clusterů a v neposlední řadě taktéž pro zjištění užitečných informací o tom, jaké fronty v daném okamžiku existují, jaké jsou k dispozici směrovače (exchange) apod. Vzhledem k tomu, že pro ovlivnění běžících démonů či služeb je nutné mít příslušné oprávnění, budete (v tom nejjednodušším případě) muset rabbitmqctl spouštět s právy Roota, tedy přes su či sudo způsobem:
# systemctl enable rabbitmq-server.service # systemctl start rabbitmq-server.service
popř. (pokud používáte klasický init systém:
# chkconfig rabbitmq-server on # service rabbitmq-server start
Ve chvíli, kdy server systému RabbitMQ běží, můžeme použít již výše zmíněný příkaz rabbitmq. Jedním z dostupných příkazů je zjištění stavu uzlu:
$ sudo rabbitmqctl node_health_check Timeout: 70.0 seconds Checking health of node rabbit@localhost Health check passed
S využitím příkazu rabbitmqctl můžeme zjistit například všechny uživatele, kteří mohou se systémem RabbitMQ pracovat, a to včetně jejich rolí. Ve výchozím nastavení je k dispozici jen jediný uživatel se jménem „guest“:
$ sudo rabbitmqctl list_users Listing users guest [administrator]
Pro zjištění jmen a stavu aktuálně vytvořených a používaných front se použije příkaz rabbitmqctl list_queues. Jeho výstup může vypadat následovně:
$ sudo rabbitmqctl list_queues Listing queues t3 0 testX 0 test 0 t1 2 t2 0
Na tomto výpisu můžeme vidět několik front, které byly vytvořeny již v rámci předchozího článku a v něm uvedených demonstračních příkladů; ve výchozím stavu totiž není k dispozici žádná trvalá fronta (všechny fronty se po vyprázdnění a odpojení klientů zahodí).
Nakonfigurované směrovače získáme příkazem. Každý směrovač má přiřazené jméno a taktéž typ (direct, fanout, headers, topic):
$ sudo rabbitmqctl list_exchanges
Listing exchanges
amq.topic topic
amq.rabbitmq.log topic
amq.headers headers
amq.fanout fanout
direct
amq.rabbitmq.trace topic
amq.match headers
amq.direct direct
Velmi podrobné informace o systému RabbitMQ získáme příkazem:
$ sudo rabbitmqctl report
Výsledek je velmi dlouhý, takže z něj uvedu pouze zajímavé výňatky.
Všichni připojení klienti:
Connections:
pid name port peer_port host peer_host ssl peer_cert_subject peer_cert_issuer peer_cert_validity auth_mechanism ssl_protocol ssl_key_exchange ssl_cipher ssl_hash protocol user vhost timeout frame_max channel_max client_properties connected_at recv_oct recv_cnt send_oct send_cnt send_pend state channels reductions garbage_collection
<rabbit@localhost.3.17007.0> 127.0.0.1:52984 -> 127.0.0.1:5672 5672 52984 127.0.0.1 127.0.0.1 false PLAIN {0,9,1} guest / 60131072 65535 [{"product","Pika Python Client Library"},{"platform","Python 3.6.3"},{"capabilities",[{"authentication_failure_close",true},{"basic.nack",true},{"connection.blocked",true},{"consumer_cancel_notify",true},{"publisher_confirms",true}]},{"information","See http://pika.rtfd.org"},{"version","0.12.0"}] 1546790531378 482 9 745 7 0 running 1 4658 [{max_heap_size,0}, {min_bin_vheap_size,46422}, {min_heap_size,233}, {fullsweep_after,65535}, {minor_gcs,7}]
Strategie směrování:
Exchanges on /:
name type durable auto_delete internal arguments policy
direct true false false []
amq.direct direct true false false []
amq.fanout fanout true false false []
amq.headers headers true false false []
amq.match headers true false false []
amq.rabbitmq.log topic true false true []
amq.rabbitmq.trace topic true false true []
amq.topic topic true false false []
Vazby strategie směrování na fronty:
Bindings on /:
source_name source_kind destination_name destination_kind routing_key argumentsvhost
exchange t1 queue t1 [] /
exchange t2 queue t2 [] /
exchange t3 queue t3 [] /
exchange test queue test [] /
exchange testX queue testX [] /
Připojení konzumenti:
Consumers on /: queue_name channel_pid consumer_tag ack_required prefetch_count arguments test <rabbit@localhost.3.17015.0> ctag1.1066b0a209074f83a46f399e5fd5e6e5 true 1 []
5. Zobecnění předchozích skriptů
Skripty popsané ve druhé a ve třetí kapitole bude lepší z praktických důvodů upravit takovým způsobem, aby producent i konzument nebyly volány přímo z hlavního těla skriptu, ale aby byl jejich kód umístěn do funkcí.
Producent, který po svém spuštění pošle do fronty (přes směrovač) jedinou zprávu, bude upraven takto:
#!/usr/bin/env python
from rabbitmq_connect import connect, open_channel
def run_producer(queue_name):
connection = connect()
channel = open_channel(connection, queue_name)
channel.basic_publish(exchange='',
routing_key=queue_name,
body='Hello World!')
print('Sent \'Hello World!\' message into the queue "{q}"'.format(q=queue_name))
connection.close()
run_producer('test')
Podobným způsobem je upraven i producent deseti zpráv:
#!/usr/bin/env python
from rabbitmq_connect import connect, open_channel
def run_producer(queue_name):
connection = connect()
channel = open_channel(connection)
for i in range(1, 11):
channel.basic_publish(exchange='',
routing_key=queue_name,
body='Hello World! #{i}'.format(i=i))
print('Sent \'Hello World!\' ten times into the queue "{q}"'.format(q=queue_name))
connection.close()
run_producer('test')
A konečně se podívejme na to, jak by bylo možné upravit konzumenta zpráv:
#!/usr/bin/env python
from time import sleep
from rabbitmq_connect import connect, open_channel
def on_receive(ch, method, properties, body):
print("Received %r" % body)
sleep(1)
print("Done processing %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
def run_consumer(queue_name):
connection = connect()
channel = open_channel(connection, queue_name)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_receive,
queue=queue_name,
no_ack=False)
print('Waiting for messages in queue "{q}". To exit press CTRL+C'.format(q=queue_name))
print("...")
channel.start_consuming()
run_consumer('test')
6. Specifikace jména fronty použité producentem i konzumentem na příkazové řádce
Ve druhé části článku si ukážeme použití různých strategií použitých při přijetí zprávy. Na základě nakonfigurované strategie se zpráva zařadí do jedné fronty či do několika front. V současné verzi serveru RabbitMQ jsou podporovány čtyři strategie:
- Nejjednodušší strategie se jmenuje direct. Tato strategie je založena na tom, že samotná zpráva obsahuje klíč (key), který slouží pro výběr správné fronty. Pokud budeme mít k dispozici jedinou frontu a budeme používat jeden klíč, celý broker se nám vlastně zúží na „obyčejnou“ frontu zpráv podporující různé protokoly a nabízejí řešení s vysokou dostupností. Klíč je reprezentován jako běžný řetězec.
- Další strategie se nazývá topic. Jedná se o složitější formu navázání zprávy na frontu, v němž se opět používá klíč uložený ve zprávě. Tento klíč se porovnává se specifickými regulárními výrazy specifikovanými v konfiguraci směrovače. Ve chvíli, kdy klíč odpovídá nějakému regulárnímu výrazu, je zpráva přesměrována do příslušné fronty. Můžeme tak například velmi snadno směrovat zprávy do různých front (a tím pádem i do různých workerů) na základě doménového jména serveru, kde zpráva vznikla apod.
- Třetí strategie používá hlavičky (headers) připojené ke zprávě. To umožňuje detailnější konfiguraci směrování; podrobnosti si popíšeme v navazujícím článku.
- A konečně čtvrtá strategie se nazývá fanout. Při použití této strategie se přijatá zpráva přenese (zduplikuje) do několika nakonfigurovaných front, což znamená, že bude přijata a zpracována několikrát. V praxi se například může jednat o přeposlání zprávy napsané klientem na různé servery implementující nějakou internetovou komunikační službu (Slack atd.).
Při použití všech typů strategií je důležité znát a specifikovat jméno fronty. Proto si nepatrně rozšíříme naše skripty o možnost specifikace jména fronty z příkazového řádku. Začneme producentem jediné zprávy:
#!/usr/bin/env python
from sys import exit, argv
from rabbitmq_connect import connect, open_channel
def run_producer(queue_name):
connection = connect()
channel = open_channel(connection, queue_name)
channel.basic_publish(exchange='',
routing_key=queue_name,
body='Hello World!')
print('Sent \'Hello World!\' message into the queue "{q}"'.format(q=queue_name))
connection.close()
if len(argv) <= 1:
print('Please provide queue name on the CLI')
exit(1)
run_producer(argv[1])
Naprosto stejným způsobem byl upraven producent deseti zpráv:
#!/usr/bin/env python
from sys import exit, argv
from rabbitmq_connect import connect, open_channel
def run_producer(queue_name):
connection = connect()
channel = open_channel(connection)
for i in range(1, 11):
channel.basic_publish(exchange='',
routing_key=queue_name,
body='Hello World! #{i}'.format(i=i))
print('Sent \'Hello World!\' ten times into the queue "{q}"'.format(q=queue_name))
connection.close()
if len(argv) <= 1:
print('Please provide queue name on the CLI')
exit(1)
run_producer(argv[1])
Nakonec upravíme i základní variantu konzumenta zpráv:
#!/usr/bin/env python
from sys import exit, argv
from time import sleep
from rabbitmq_connect import connect, open_channel
def on_receive(ch, method, properties, body):
print("Received %r" % body)
sleep(1)
print("Done processing %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
def run_consumer(queue_name):
connection = connect()
channel = open_channel(connection, queue_name)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_receive,
queue=queue_name,
no_ack=False)
print('Waiting for messages in queue "{q}". To exit press CTRL+C'.format(q=queue_name))
print("...")
channel.start_consuming()
if len(argv) <= 1:
print('Please provide queue name on the CLI')
exit(1)
run_consumer(argv[1])
Informace o frontách, které jsou v daný okamžik k dispozici, můžeme získat příkazem rabbitmqctl list_queues, s nímž jsme se seznámili ve čtvrté kapitole:
$ sudo rabbitmqctl list_queues Listing queues t3 0 testX 0 test 0 t1 2 t2 0 log 0 nova_fronta 0 dalsi_fronta 0
7. Rozvětvení (fanout) zpráv do většího množství front
Z předchozího textu již víme, že v případě potřeby je možné nakonfigurovat rozvětvení (fanout) zpráv, tj. každá zpráva může být doručena většímu množství příjemců. Příkladem může být vzájemná distribuce textových zpráv mezi několika servery implementujícími internetová „kecátka“ (Slack, Mattermost, Jabber/XMPP…). Každý server přitom může současně vystupovat v roli příjemce zpráv i producenta zpráv.
Rozvětvení je možné provést do libovolných front, což ovšem znamená, že do nějaké fronty můžeme zprávy posílat z většího množství směrovačů (exchange). Podívejme se na dva typické případy (stále uvažujeme variantu, kdy celý RabbitMQ běží na jediném stroji):
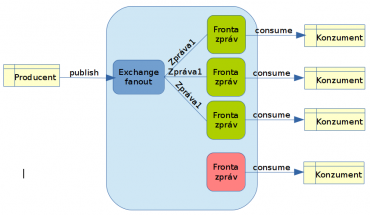
Obrázek 2: Jedna z možných konfigurací rozvětvení. První směrovač (exchange) zkopíruje přijatou zprávu do tří front. Poslední (čtvrtá) fronta není v tomto případě nijak využita – rozvětvení se provádí jen do předem vybraných front.
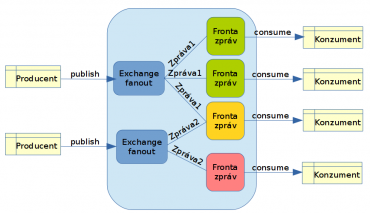
Obrázek 3: Další možná konfigurace rozvětvení, v níž je třetí fronta použita oběma nakonfigurovanými směrovači. Zprávy z obou směrovačů se tedy mohou promíchat.
Pokud si necháme vypsat všechny existující (nakonfigurované) směrovače, zjistíme, že automaticky vytvořený směrovač amq.fanout provádí rozvětvení zpráv do (vybraných) front:
$ sudo rabbitmqctl list_exchanges
Listing exchanges
amq.topic topic
amq.rabbitmq.log topic
amq.headers headers
amq.fanout fanout
direct
amq.rabbitmq.trace topic
amq.match headers
amq.direct direct
Samozřejmě nám ovšem nic nebrání vytvořit si směrovač vlastní. Nový směrovač se vytvoří metodou channel.exchange_declare, přičemž musíme specifikovat jak jméno směrovače v parametru exchange, tak i jeho typ v parametru exchange_type. Typ je specifikován řetězcem „direct“, „topic“, „fanout“ či „headers“, V této kapitole nás zajímá rozvětvení (fanout), takže použijeme typ „fanout“:
def use_fanout(channel, exchange_name='fanout_exchange'):
print(exchange_name)
channel.exchange_declare(exchange=exchange_name,
exchange_type='fanout')
8. Konfigurace exchange s navázáním front
Aby bylo možné vytvořit nový směrovač (exchange) typu fanout, rozšíříme náš modul rabbitmq_connect.py o další funkci nazvanou use_fanout. Této funkci je nutné předat vytvořený komunikační kanál a v nepovinném parametry i jméno směrovače. V případě, že jméno nebude explicitně specifikováno, použije se výchozí jméno „fanout_exchange“:
import pika
def connect(where='localhost'):
connection = pika.BlockingConnection(pika.ConnectionParameters(where))
return connection
def open_channel(connection, queue_name='test'):
# pokus o nové vytvoření fronty ve skutečnosti neovlivní již existující frontu
channel = connection.channel()
channel.queue_declare(queue=queue_name)
return channel
def use_fanout(channel, exchange_name='fanout_exchange'):
print(exchange_name)
channel.exchange_declare(exchange=exchange_name,
exchange_type='fanout')
def bind_queue(channel, queue_name, exchange_name='fanout_exchange'):
channel.queue_declare(queue=queue_name)
channel.queue_bind(exchange=exchange_name,
queue=queue_name)
9. Poslání zpráv s jejich rozvětvením do trojice front
V tento okamžik je již vše připraveno na úpravu nové varianty producenta takovým způsobem, aby se po jeho spuštění vytvořila trojice front nazvaných „fronta1“, „fronta2“ a „fronta3“. Tyto tři fronty budou navázány na nový směrovač typu fanout. Postup je jednoduchý:
use_fanout(channel) bind_queue(channel, 'fronta1') bind_queue(channel, 'fronta2') bind_queue(channel, 'fronta3')
Úplný zdrojový kód producenta bude vypadat takto:
#!/usr/bin/env python
from sys import exit, argv
from rabbitmq_connect import connect, open_channel, use_fanout, bind_queue
def run_producer():
connection = connect()
channel = open_channel(connection)
use_fanout(channel)
bind_queue(channel, 'fronta1')
bind_queue(channel, 'fronta2')
bind_queue(channel, 'fronta3')
for i in range(1, 11):
channel.basic_publish(exchange='fanout_exchange',
routing_key='',
body='Hello World! #{i}'.format(i=i))
print('Sent \'Hello World!\' ten times into three queues "fronta1", "fronta2", and "fronta3"')
connection.close()
run_producer()
Producenta spustíme:
$ python3 enqueue_work.py Sent 'Hello World!' message into three queues "fronta1", "fronta2", and "fronta3"
Nyní by se měl v seznamu směrovačů objevit nový směrovač typu fanout se jménem „fanout_exchange“:
$ sudo rabbitmqctl list_exchanges
Listing exchanges
amq.topic topic
amq.rabbitmq.log topic
amq.headers headers
fanout_exchange fanout
amq.fanout fanout
direct
amq.rabbitmq.trace topic
amq.match headers
amq.direct direct
Současně by měl seznam front obsahovat tři nové fronty:
$ sudo rabbitmqctl list_queues Listing queues t3 0 testX 0 test 0 t1 2 t2 0 fronta2 1 fronta1 1 fronta3 1 xxx 0
Povšimněte si, že každá nová fronta obsahuje jedinou zprávu – poslanou jedenkrát našim producentem a rozvětvenou nově vytvořeným směrovačem.
10. Směrování zpráv do front na základě klíče a nakonfigurovaných výrazů
V tomto okamžiku už víme, jak používat dvě strategie směrování zpráv – direct a fanout. Třetí strategie se jmenuje topic. Tato strategie je založena na využití klíče, který je posílán společně se zprávou. Obsah tohoto klíče je porovnáván se specificky zapsaným regulárním výrazem (nejedná se ovšem o klasický regulární výraz tak, jak ho známe z mnoha nástrojů a knihoven) na směrovače. Pokud klíč nějakému regulárnímu výrazu odpovídá, bude příslušná zpráva přeposlána do fronty, která je s výrazem svázána. Směrovací tabulka může vypadat například takto:
| Výraz | Fronta |
|---|---|
| europe.* | europe_queue |
| asia.* | asia_queue |
| americas.* | americas_queue |
| *.org | org_queue |
| *.*.rabbit | rabbit_queue |
| #.other | other_queue |
Na rozdíl od klasických regulárních výrazů, kde se zástupný znak * používá pro substituci libovolného (i nulového) počtu opakování znaku se v systému RabbitMQ tento znak používá pro určení jednoho (libovolného) slova slova odděleného od dalších slov tečkou. V případě, že je nutné specifikovat libovolné množství slov, použije se namísto znaku * znak #.
Dále si povšimněte použití teček, s nimiž se u klíčů poměrně často setkáme, protože se jimi dají jednoduše zapisovat hierarchické názvy.
11. Konfigurace směrování a navázání front se specifikací směrovacího klíče
Pro vytvoření nového směrovače typu „topic“ použijeme novou pomocnou funkci přidanou do skriptu rabbitmq_connect.py:
def use_topic_exchange(channel, exchange_name='topic_exchange'):
channel.exchange_declare(exchange=exchange_name,
exchange_type='topic')
Nová varianta tohoto skriptu bude vypadat následovně:
import pika
def connect(where='localhost'):
connection = pika.BlockingConnection(pika.ConnectionParameters(where))
return connection
def open_channel(connection, queue_name='test'):
# pokus o nové vytvoření fronty ve skutečnosti neovlivní již existující frontu
channel = connection.channel()
channel.queue_declare(queue=queue_name)
return channel
def use_fanout(channel, exchange_name='fanout_exchange'):
channel.exchange_declare(exchange=exchange_name,
exchange_type='fanout')
def use_topic_exchange(channel, exchange_name='topic_exchange'):
channel.exchange_declare(exchange=exchange_name,
exchange_type='topic')
def bind_queue(channel, queue_name, routing_pattern='', exchange_name='fanout_exchange'):
channel.queue_declare(queue=queue_name)
channel.queue_bind(exchange=exchange_name,
queue=queue_name,
routing_key=routing_pattern)
12. Implementace producenta posílajícího zprávy s tématem (topicem)
Pokud použijeme směrovač typu topic, musíme u každé zprávy zapsat i příslušný klíč obsahující nějaký řetězec. Poslání šesti zpráv do různých tématicky rozdělených front je tedy možné realizovat například následujícím způsobem:
keys = ("europe.cr", "europe.sr", "europe.pl",
"asia.china",
"americas.canada", "americas.chile")
for key in keys:
print(key)
channel.basic_publish(exchange='topic_exchange',
routing_key=key,
body='Hello World! #{k}'.format(k=key))
Následuje výpis úplného zdrojového kódu producenta využívajícího tématicky rozdělené fronty:
#!/usr/bin/env python
from sys import exit, argv
from rabbitmq_connect import connect, open_channel, use_topic_exchange, bind_queue
def run_producer():
connection = connect()
channel = open_channel(connection)
use_topic_exchange(channel)
bind_queue(channel, 'europe_queue',
routing_pattern='europe.*', exchange_name='topic_exchange')
bind_queue(channel, 'asia_queue',
routing_pattern='asia.*', exchange_name='topic_exchange')
bind_queue(channel, 'americas_queue',
routing_pattern='americas.*', exchange_name='topic_exchange')
keys = ("europe.cr", "europe.sr", "europe.pl",
"asia.china",
"americas.canada", "americas.chile")
for key in keys:
print(key)
channel.basic_publish(exchange='topic_exchange',
routing_key=key,
body='Hello World! #{k}'.format(k=key))
print('Sent \'Hello World!\' to all selected regions')
connection.close()
run_producer()
Naproti tomu se konzument nemusí žádným způsobem modifikovat (což je jeden z pozitivních důsledků oddělení obou částí aplikace):
#!/usr/bin/env python
from sys import exit, argv
from time import sleep
from rabbitmq_connect import connect, open_channel
def on_receive(ch, method, properties, body):
print("Received %r" % body)
sleep(1)
print("Done processing %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag)
def run_consumer(queue_name):
connection = connect()
channel = open_channel(connection, queue_name)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_receive,
queue=queue_name,
no_ack=False)
print('Waiting for messages in queue "{q}". To exit press CTRL+C'.format(q=queue_name))
print("...")
channel.start_consuming()
if len(argv) <= 1:
print('Please provide queue name on the CLI')
exit(1)
run_consumer(argv[1])
13. Ukázka směrování v praxi
Před spuštěním producenta popsaného v předchozí kapitole by seznam front neměl obsahovat ani jednu z front „americas_queue“, „asia_queue“ a „europe_queue“. O tom se přesvědčíme snadno:
$ sudo rabbitmqctl list_queues Listing queues t3 0 testX 0 test 0 t1 2 t2 0 fronta2 6 fronta1 16 fronta3 16
Nyní si můžeme zkusit producenta spustit:
$ python3 enqueue_more_work.py europe.cr europe.sr europe.pl asia.china americas.canada americas.chile Sent 'Hello World!' to all selected regions
Vidíme, že producent vytvořil a poslal celkem šest zpráv, které by se měly nějakým způsobem rozdělit mezi tři nakonfigurované regiony: Evropa, Asie, obě Ameriky. Zkusme si tedy vypsat stav všech front:
$ sudo rabbitmqctl list_queues Listing queues t3 0 americas_queue 2 testX 0 test 0 t1 2 asia_queue 1 europe_queue 3 t2 0 fronta2 6 fronta1 16 fronta3 16
V dalším kroku spustíme producenta, který bude zpracovávat zprávy z fronty „americas_queue“. Tato fronta obsahuje dvě zprávy, a obě by se měly správně zpracovat:
$ Waiting for messages in queue "americas_queue". To exit press CTRL+C ... Received b'Hello World! #americas.canada' Done processing b'Hello World! #americas.canada' Received b'Hello World! #americas.chile' Done processing b'Hello World! #americas.chile'
Po novém otestování obsahu front by již fronta „americas_queue“ neměla obsahovat žádné zprávy:
$ sudo rabbitmqctl list_queues Listing queues t3 0 americas_queue 0 testX 0 test 0 t1 2 asia_queue 1 europe_queue 3 t2 0 fronta2 6 fronta1 16 fronta3 16
Nakonec spustíme producenta se specifikací front „asia_queue“ a „europe_queue“. Výsledkem by měly být sice existující, ovšem prázdné fronty:
$ sudo rabbitmqctl list_queues Listing queues t3 0 americas_queue 0 testX 0 test 0 t1 2 asia_queue 0 europe_queue 0 t2 0 fronta2 6 fronta1 16 fronta3 16
14. Prioritní fronty v systému RabbitMQ
Systém RabbitMQ podporuje práci s takzvanými prioritními frontami (priority queue). V případě, že je nějaká fronta nakonfigurována jako prioritní, je možné do ní posílat zprávy s nastavenou prioritou, přičemž zprávy s vyšší prioritou budou přesunuty směrem k začátku fronty. Systém sice nezaručuje, že pořadí zpráv ve frontě bude přesně odpovídat zadané prioritě, ovšem většinou se zpráva skutečně zařadí na správné místo, což ostatně uvidíme i při spuštění dnešních dvou posledních demonstračních příkladů.
Priorita zprávy může být specifikována celým kladným číslem popř. nulou. Prakticky jsme však omezeni hodnotami ležícími v rozsahu 0 až 255, protože priorita zprávy může být reprezentována jediným bajtem.
15. Konfigurace prioritní fronty
Aby bylo možné do zvolené fronty či do několika zvolených front posílat zprávy s nastavenou prioritou, je nutné frontu/fronty náležitým způsobem nakonfigurovat. Při deklaraci nové fronty pomocí channel.queue_declare() můžeme použít nepovinný parametr nazvaný arguments. Hodnotou tohoto parametru je mapa (slovník) obsahující dvojice klíč-hodnota. V našem konkrétním případě musíme specifikovat maximální možnou prioritu, což je teoreticky libovolné celé kladné číslo, ovšem z praktických důvodů jsme omezeni hodnotou 255, protože v přenosovém protokolu je pro prioritu určen jediný bajt (ovšem 256 priorit by mělo být více než dostačující pro prakticky všechny myslitelné případy). Maximální povolená priorita se specifikuje dvojicí, jejímž klíčem je řetězec x-max-priority a hodnotou zvolená priorita:
channel.queue_declare(queue=queue_name, arguments={"x-max-priority": max_priority})
Následující funkce, kterou nalezneme ve skriptu rabbitmq_connect.py, umožňuje specifikovat maximální prioritu zpráv zařazovaných do fronty, přičemž výchozí hodnotou bude priorita 10 (zprávy tedy budou moci mít prioritu v rozsahu od 0 do 10, a to včetně obou krajních hodnot):
def open_channel(connection, queue_name='test', max_priority=10):
# pokus o nové vytvoření fronty ve skutečnosti neovlivní již existující frontu
channel = connection.channel()
channel.queue_declare(queue=queue_name, arguments={"x-max-priority": max_priority})
return channel
16. Vymazání vybrané fronty
V případě, že fronta, u níž chceme nastavit prioritu, již existuje, nebude možné změnit její konfiguraci, tudíž ani specifikovat, že mají být podporovány zprávy s prioritou. Takovou frontu můžeme nejdříve smazat, například následujícím skriptem:
#!/usr/bin/env python
from sys import argv, exit
from rabbitmq_connect import connect
def delete_queue(queue_name):
connection = connect()
channel = connection.channel()
channel.queue_delete(queue=queue_name)
connection.close()
if len(argv) <= 1:
print('Please provide queue name on the CLI')
exit(1)
delete_queue(argv[1])
Stav front před spuštěním tohoto skriptu může vypadat například takto:
$ sudo rabbitmqctl list_queues Listing queues priority_queue 0 test 0 t1 2 t2 0 fronta2 6 fronta1 16 fronta3 16
Vymazání fronty pojmenované „priority_queue“:
$ python3 delete_queue.py priority_queue
Po opětovném vypsání seznamu všech front zjistíme, že fronta „priority_queue“ byla skutečně vymazána:
$ sudo rabbitmqctl list_queues Listing queues test 0 t1 2 t2 0 fronta2 6 fronta1 16 fronta3 16
$ python3 delete_queue.py neexistujici-fronta $ echo $? 0
17. Specifikace priority posílané zprávy
Priorita zprávy poslané do fronty (která priority podporuje) se nastavuje přes vlastnosti (properties) zprávy. V případě použití knihovny Pika jsou vlastnosti zpráv uloženy do objektu typu BasicProperties, který obsahuje všechny vlastnosti zprávy. Samotná priorita se nastavuje v konstruktoru BasicProperties pomocí pojmenovaného parametru priority, který nastavíme na zvolenou prioritu (v našem případě na hodnotu od 0 do 10):
prop = BasicProperties(priority=priority)
Zbylé vlastnosti zprávy obsahují výchozí hodnoty (default).
Ve chvíli, kdy již máme vytvořenou instanci objektu BasicProperties, můžeme tento objekt použít při poslání zprávy:
channel.basic_publish(exchange='',
routing_key='priority_queue_2',
body='Hello World! #{i} msg with priority {p}'.format(i=i, p=priority),
properties=prop)
Úplný zdrojový kód producenta posílajícího zprávy s různou prioritou vypadá takto:
#!/usr/bin/env python
from sys import exit, argv
from rabbitmq_connect import connect, open_channel
from pika.spec import BasicProperties
def run_producer():
connection = connect()
channel = open_channel(connection, queue_name='priority_queue_2', max_priority=10)
for i in range(1, 11):
priority = 5 * (i % 3)
prop = BasicProperties(priority=priority)
channel.basic_publish(exchange='',
routing_key='priority_queue_2',
body='Hello World! #{i} msg with priority {p}'.format(i=i, p=priority),
properties=prop)
connection.close()
run_producer()
Tohoto producenta spustíme zcela stejným způsobem, jako jakéhokoli jiného producenta, s nímž jsme se až doposud setkali:
$ python3 enqueue_more_work.py
Samotný konzument se nemusí měnit – priorita zpráv slouží pouze pro jejich zařazení do front a nemá vliv na to, jak bude vypadat přijatá zpráva.
18. Pořadí přijatých zpráv s prioritami
Ve chvíli, kdy spustíme konzumenta zpráv:
$ python3 consumer.py priority_queue
By se postupně měly začít jednotlivé zprávy zpracovávat:
Received b'Hello World! #1 msg with priority 5' Done processing b'Hello World! #1 msg with priority 5' Received b'Hello World! #2 msg with priority 10' Done processing b'Hello World! #2 msg with priority 10' Received b'Hello World! #5 msg with priority 10' Done processing b'Hello World! #5 msg with priority 10' Received b'Hello World! #8 msg with priority 10' Done processing b'Hello World! #8 msg with priority 10' Received b'Hello World! #4 msg with priority 5' Done processing b'Hello World! #4 msg with priority 5' Received b'Hello World! #7 msg with priority 5' Done processing b'Hello World! #7 msg with priority 5' Received b'Hello World! #10 msg with priority 5' Done processing b'Hello World! #10 msg with priority 5' Received b'Hello World! #3 msg with priority 0' Done processing b'Hello World! #3 msg with priority 0' Received b'Hello World! #6 msg with priority 0' Done processing b'Hello World! #6 msg with priority 0' Received b'Hello World! #9 msg with priority 0' Done processing b'Hello World! #9 msg with priority 0'
Povšimněte si ovšem pořadí zpracovaných zpráv, které jsem pro přehlednost přepsal do tabulky:

| Pořadí | Zpráva # | Priorita |
|---|---|---|
| 1 | 1 | 5 |
| 2 | 2 | 10 |
| 3 | 5 | 10 |
| 4 | 8 | 10 |
| 5 | 4 | 5 |
| 6 | 7 | 5 |
| 7 | 10 | 5 |
| 8 | 3 | 0 |
| 9 | 6 | 0 |
| 10 | 9 | 0 |
Z předchozí tabulky je patrné, že zprávy skutečně byly (až na zprávu zcela první) seřazeny podle priority, což ostatně odpovídá i specifikaci AMQP – priorita zpráv ovlivňuje jejich zařazení do fronty, ovšem není zaručeno zcela přesné pořadí.
Podobným způsobem budou zprávy uspořádány podle priority i po spuštění dvanáctého příkladu:
Waiting for messages in queue "priority_queue_3". To exit press CTRL+C ... Received b'Hello World! #0 msg with priority 100' Done processing b'Hello World! #0 msg with priority 100' Received b'Hello World! #1 msg with priority 99' Done processing b'Hello World! #1 msg with priority 99' Received b'Hello World! #2 msg with priority 98' Done processing b'Hello World! #2 msg with priority 98' Received b'Hello World! #3 msg with priority 97' Done processing b'Hello World! #3 msg with priority 97' Received b'Hello World! #4 msg with priority 96' Done processing b'Hello World! #4 msg with priority 96' Received b'Hello World! #5 msg with priority 95' ... ... ... Done processing b'Hello World! #94 msg with priority 6' Received b'Hello World! #95 msg with priority 5' Done processing b'Hello World! #95 msg with priority 5' Received b'Hello World! #96 msg with priority 4' Done processing b'Hello World! #96 msg with priority 4' Received b'Hello World! #97 msg with priority 3' Done processing b'Hello World! #97 msg with priority 3' Received b'Hello World! #98 msg with priority 2' Done processing b'Hello World! #98 msg with priority 2' Received b'Hello World! #99 msg with priority 1' Done processing b'Hello World! #99 msg with priority 1'
19. Repositář s demonstračními příklady
20. Odkazy na Internetu
- Advanced Message Queuing Protocol
https://www.amqp.org/ - Advanced Message Queuing Protocol na Wikipedii
https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol - Dokumentace k příkazu rabbitmqctl
https://www.rabbitmq.com/rabbitmqctl.8.html - RabbitMQ
https://www.rabbitmq.com/ - RabbitMQ Tutorials
https://www.rabbitmq.com/getstarted.html - RabbitMQ: Clients and Developer Tools
https://www.rabbitmq.com/devtools.html - RabbitMQ na Wikipedii
https://en.wikipedia.org/wiki/RabbitMQ - Streaming Text Oriented Messaging Protocol
https://en.wikipedia.org/wiki/Streaming_Text_Oriented_Messaging_Protocol - Message Queuing Telemetry Transport
https://en.wikipedia.org/wiki/MQTT - Erlang
http://www.erlang.org/ - pika 0.12.0 na PyPi
https://pypi.org/project/pika/ - Introduction to Pika
https://pika.readthedocs.io/en/stable/ - Langohr: An idiomatic Clojure client for RabbitMQ that embraces the AMQP 0.9.1 model
http://clojurerabbitmq.info/ - AMQP 0–9–1 Model Explained
http://www.rabbitmq.com/tutorials/amqp-concepts.html - Part 1: RabbitMQ for beginners – What is RabbitMQ?
https://www.cloudamqp.com/blog/2015–05–18-part1-rabbitmq-for-beginners-what-is-rabbitmq.html - Downloading and Installing RabbitMQ
https://www.rabbitmq.com/download.html - celery na PyPi
https://pypi.org/project/celery/ - Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Použití nástroje RQ (Redis Queue) pro správu úloh zpracovávaných na pozadí
https://www.root.cz/clanky/pouziti-nastroje-rq-redis-queue-pro-spravu-uloh-zpracovavanych-na-pozadi/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Python Celery & RabbitMQ Tutorial
https://tests4geeks.com/python-celery-rabbitmq-tutorial/ - Flower: Real-time Celery web-monitor
http://docs.celeryproject.org/en/latest/userguide/monitoring.html#flower-real-time-celery-web-monitor - Asynchronous Tasks With Django and Celery
https://realpython.com/asynchronous-tasks-with-django-and-celery/ - First Steps with Celery
http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html - node-celery
https://github.com/mher/node-celery - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq - Running multiple workers using Celery
https://serverfault.com/questions/655387/running-multiple-workers-using-celery - celery — Distributed processing
http://docs.celeryproject.org/en/latest/reference/celery.html - Chains
https://celery.readthedocs.io/en/latest/userguide/canvas.html#chains - Routing
http://docs.celeryproject.org/en/latest/userguide/routing.html#automatic-routing - Celery Distributed Task Queue in Go
https://github.com/gocelery/gocelery/ - Python Decorators
https://wiki.python.org/moin/PythonDecorators - Periodic Tasks
http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html - celery.schedules
http://docs.celeryproject.org/en/latest/reference/celery.schedules.html#celery.schedules.crontab - Pros and cons to use Celery vs. RQ
https://stackoverflow.com/questions/13440875/pros-and-cons-to-use-celery-vs-rq - Priority queue
https://en.wikipedia.org/wiki/Priority_queue




































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU