
Obsah
1. Použití nástroje Apache Kafka v aplikacích založených na mikroslužbách
2. Klasické systémy s frontami zpráv – PUSH-PULL
3. Rozesílání zpráv se strategií PUBLISH-SUBSCRIBE
4. Když nejsou možnosti klasických message brokerů dostačující…
5. Shrnutí některých úskalí a problémů klasických message brokerů
6. Práce se zprávami v systému Apache Kafka
11. Použití systému Apache Kafka z různých programovacích jazyků
13. Příklady použití Apache Kafka
17. Apache Kafka ve funkci message brokera s frontami zpráv
1. Použití nástroje Apache Kafka v aplikacích založených na mikroslužbách
Ve čtvrté části seriálu o mikroslužbách se seznámíme se základními vlastnostmi projektu Apache Kafka, který se v posledních několika letech stal velmi populární, a to nikoli pouze u aplikací založených na mikroslužbách, ale i v dalších oborech (zmiňme například oblasti jako Machine Learning, Big data atd.). Díky konceptům, na nichž je projekt Kafka založen, je možné tento systém použít v několika oblastech, například ve funkci distribuovaného logu, databáze událostí (events), zobecněného message brokera, je ústředním prvkem architektur lambda a kappa, příjemci zpráv se mohou sdružovat do skupin atd. Ovšem i další vlastnosti, které projekt Kafka nabízí, jsou velmi užitečné. Jedná se především o možnost nasazení celého clusteru brokerů řízených z jednoho místa, možnost replikace záznamů (zpráv, událostí), řízení, které zprávy mají být zachovány a které (ty starší) smazány apod. Existují samozřejmě i alternativy k tomuto projektu, například v závěru zmíněný NATS Streaming Server, ovšem ty většinou nenabízí všechny výše zmíněné možnosti.

Obrázek 1: Logo nástroje Apache Kafka, kterému se budeme dnes věnovat.
2. Klasické systémy s frontami zpráv – PUSH-PULL
Nástroj Apache Kafka je určen především pro práci s kontinuálním tokem zpráv (popř. událostí), které jsou v Kafce určitým způsobem uloženy (typicky se zaručeným pořadím – viz další text) a je je možné zpracovávat konzumenty (příjemci zpráv), kteří si sami určují, jaké zprávy budou potřebovat a dokonce i v jakém pořadí. Možnosti Kafky rozšiřují a zobecňují vlastnosti klasických message brokerů. Připomeňme si, že většina message brokerů nabízí dva způsoby doručování zpráv. Jedná se o způsob (strategii) nazvaný PUSH-PULL a dále o způsob pojmenovaný PUBLISH-SUBSCRIBE.
První komunikační strategie, která se někdy nazývá PUSH-PULL či pouze queueing, je založena na pojmenovaných frontách zpráv (message queue) implementovaných v message brokerovi. Zpráva bývá v tomto případě doručena jen jedinému konzumentovi a pokud žádný konzument není k frontě připojen, zůstane zpráva ve frontě uložena (teoreticky) po libovolně dlouhou dobu. Message broker v takovém případě typicky podporuje perzistenci zpráv, které tak dokážou přečkat jeho případné restarty. Mnoho message brokerů navíc umožňuje, aby konzumenti potvrzovali zpracování zprávy, popř. je dokonce možné provádět transakce. K pojmenovaným frontám se potom přidávají další specializované fronty na nezpracované zprávy (DLQ – Dead Letters Queue).

Obrázek 2: Komunikační strategie PUSH-PULL.
3. Rozesílání zpráv se strategií PUBLISH-SUBSCRIBE
Druhá komunikační strategie podporovaná většinou message brokerů se nazývá PUBLISH-SUBSCRIBE (neboli zkráceně PUB-SUB) a spočívá v tom, že se zprávy s nastaveným tématem (topic, subject) posílají do message brokera, který tyto zprávy ihned přeposílá konzumentům přihlášeným k danému tématu. V případě, že žádný takový konzument neexistuje, je zpráva zahozena. Pokud konzumentů daného tématu naopak existuje větší množství, je zpráva doručena všem takovým konzumentům. Samotný message broker v tomto případě nepotřebuje zprávy ukládat, takže se většinou nesetkáme ani s podporou pro persistenci zpráv. Příkladem takového systému je například systém NATS (bez dalších rozšíření).

Obrázek 3: Komunikační strategie PUBLISH-SUBSCRIBE.
4. Když nejsou možnosti klasických message brokerů dostačující…
V aplikacích, jejichž architektura je založena na mikroslužbách, se s klasickými message brokery setkáme velmi často. Doručování zpráv typu PUSH-PULL přes message brokera nejenže umožňuje, aby byly obě komunikující strany co nejvíce odděleny, ale je automaticky podporován i load balancing, systém se „vzpamatuje“ i z případných restartů konzumentů a existuje zde i možnost naplánování některých náročnějších úloh až do okamžiku, kdy je k dispozici dostatek systémových prostředků (clearing prováděný v noci atd.). Navíc, pokud je použit kvalitní message broker, je zajištěna persistence zpráv, někdy i jejich replikace a další vlastnosti, které od systému určeného pro mnohdy enormní zátěže očekáváme. Nesmíme zapomenout ani na to, že konzumenti (příjemci zpráv) si nemusí pamatovat, kterou zprávu zpracovávaly naposledy – toto je automaticky zajištěno samotnou sémantikou fungování fronty (konzument tedy může být bezstavový a tím pádem mnohem snadněji škálovatelný atd.).

Obrázek 4: Složitější konfigurace nabízená například systémem RabbitMQ.
I strategie PUBLISH-SUBSCRIBE má v aplikacích založených na mikroslužbách své místo. Jednotlivé komponenty se mohou navzájem informovat o událostech, ke kterým došlo, mohou tímto způsobem předávat příkazy (command) s tím, že opět platí, že producent zpráv nemusí být pevně spojen s případnými konzumenty (a nemusí ani vědět o jejich existenci).
V některých případech nám ovšem nemusí ani jedna z těchto strategií vyhovovat a navíc – PUSH-PULL může být pro mnohé aplikace relativně pomalý způsob předávání zpráv, zejména v porovnání s řešením, s nímž se seznámíme v navazujících kapitolách.
Jedním z problémů může být, že v klasickým message brokerech orientovaných na komunikaci s využitím zpráv je každá zpráva většinou spravována izolovaně od ostatních zpráv. I když některé implementace message brokerů podporují prioritní fronty, není obecně vyžadováno (a ani se to neočekává), aby se zprávy doručovaly přesně v takovém pořadí, v jakém je message broker přijímá (což je u pojmenovaných front problematické).
Dále existují některé problémy, které se s použitím klasickým message brokerů implementují velmi složitě popř. je nelze (na rozumném HW či na cenově dostupném clusteru) implementovat vůbec. Příkladem může být systém pro zaznamenání událostí, ovšem v tom pořadí, v jakém události vznikly a s možností zpětného přehrávání (replay) zpráv/událostí. A právě pro řešení těchto problémů vznikl koncept streamingu zpráv implementovaný právě v systému Apache Kafka.
Partner seriálu o mikroslužbách
V IGNUM mají rádi technologie a staví na nich vlastní mikroslužby, díky kterým je registrace a správa domén, hostingů a e-mailů pro zákazníky hračka. Vymýšlet jednoduchá řešení pro obsluhu složitých systémů a uvádět je v život je výzva. Společnost IGNUM miluje mikroslužby a je proto hrdým partnerem tohoto seriálu.
5. Shrnutí některých úskalí a problémů klasických message brokerů
Shrňme si tedy některá úskalí klasických message brokerů založených na obou výše popsaných komunikačních strategiích. Většina těchto úskalí je do větší či menší míry řešena moderními streaming brokery:
- U strategie PUBLISH-SUBSCRIBE získají zprávu jen ti konzumenti, kteří jsou v daný okamžik přihlášeni k příjmu zpráv. Pokud je nějaký konzument z nějakého důvodu odpojený, zprávu již nikdy později nedostane. V případě streamingu si čtení zpráv od zadaného okamžiku řídí samotný konzument zpráv, pochopitelně s tím omezením, že se starší (většinou mnohem starší) zprávy mohou automaticky odstraňovat na základě kritérií nastavených administrátorem (někdy to ovšem znamená, že si konzument musí pamatovat například offset poslední zpracované zprávy).
- U strategie PUSH-PULL je jednou doručená zpráva z message brokera (přesněji řečeno z fronty implementované v message brokeru) odstraněna a nelze se k ní později vrátit. Tím pádem pochopitelně není umožněna ani podpora pro přehrávání zpráv (replay). I toto je do značné míry vyřešeno v případě nasazení streamingu; vše je omezeno nastavením provedeném administrátorem (a teoreticky existuje pouze jedno omezení na 263-1 zpráv v jedné oblasti, což však v praxi prakticky nelze dosáhnout).
- Původní strategie PUSH-PULL navíc předpokládá, že se zpráva doručí jen jedinému konzumentovi. Někteří message brokeři ovšem podporují i rozšíření funkcionality a implementují tak kombinaci obou strategií, jak PUBLISH-SUBSCRIBE, tak i PUSH-PULL (dobrým příkladem může být RabbitMQ, viz též obrázek číslo 4). Streaming servery používají zobecněnou strategii PUBLISH-SUBSCRIBE, takže toto omezení nemají, pochopitelně při správném nastavení témat a jejich replikací.
- U strategie PUSH-PULL se v případě výchozího chování nijak nespecifikuje maximální počet zpráv ve frontě popř. maximální povolené obsazení místa na disku. V případě, že konzumenti budou delší dobu odpojeni, se může jednat o potenciální problém (opět platí, že u některých message brokerů se můžeme setkat s určitou podporu pro mazání starších zpráv při dosažení administrátorem specifikovaných limitů). Řešení v případě streaming serverů bylo zmíněno výše a ke konkrétním příkladům se vrátíme v dalším článku.
- Problematický může být i relativně nízký výkon přeposílání zpráv systémemPUSH-PULL (přibližně do limitu 100 000 zpráv za sekundu při použití RabbitMQ v clusteru, zatímco systémy založené na Kafce mohou mít i řádově vyšší rychlost práce se zprávami).
6. Práce se zprávami v systému Apache Kafka
V systému Apache Kafka se se zprávami (které se zde ale typicky nazývají záznamy, record, popř. možná poněkud nepřesně události, events) pracuje poněkud odlišným způsobem, který do jisté míry kombinuje jak možnosti klasické fronty zpráv, tak i rozesílání zpráv systémem PUBLISH-SUBSCRIBE. Zprávy se ovšem neukládají do fronty, ale (v tom zcela nejjednodušším případě) do neustále rostoucí sekvence záznamů, přičemž každému záznamu je přiřazeno jednoznačné číslo – offset. Z pohledu zdroje zpráv (publisher) vlastně nedochází k žádné podstatnější změně. Rozdílné je ovšem další zpracování záznamů. Tyto záznamy mohou číst příjemci zpráv (subscribeři), kteří si sami zvolí, od jakého offsetu potřebují zprávy přečíst.
Přečtením ovšem zpráva nezanikne, na rozdíl od klasické fronty, kde operace PULL zprávu z fronty navždy odstraní a message broker ji ihned poté odstraní i ze své paměti a perzistentního úložiště. A je zde i rozdíl oproti systému PUBLISH-SUBSCRIBE, protože subscriber zprávu může získat kdykoli později – nemusí být tedy připraven zprávu zpracovat v ten přesný okamžik, kdy je zpráva message brokerem rozesílána.
To však není jediná změna či vylepšení. Vzhledem k tomu, že příjemci zpráv (subscribeři) si sami volí offset, od kterého chtějí zprávy číst, je možné provádět takzvanou operaci replay, což není nic jiného, než nové zpracování zpráv od jejich začátku, od určitého (třeba i relativně zadaného) časového okamžiku atd. Tato vlastnost má dosti závažné důsledky pro oblasti, v nichž se systém Apache Kafka nasazuje. Umožňuje totiž postupné přidávání nových příjemců zpráv, kteří ihned mohou začít zpracovávat i historické záznamy. Ostatně to je i jeden z důvodů, proč je Apache Kafka tak populární v oblasti strojového učení (machine learning – ML), protože umožňuje prakticky dokonalé oddělení systémů sloužících pro sběr dat od modulů, které tato data nějakým způsobem dále zpracovávají.
+---+---+---+---+---+---+---+---+---+
téma | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ...
+---+---+---+---+---+---+---+---+---+
^ ^
| zápis
čtení
Aby bylo možné konfigurovat a řídit, které zprávy mají být na message brokeru uloženy a které již smazány, specifikuje se takzvaný retention time zajišťující, aby počet zpráv/záznamů nepřekročil časovou mez. Streaming server dokáže omezit i celkový počet zpráv, počet zpráv v tématu a/nebo počet zpráv na jednom serveru v clusteru. Totéž omezení je možné aplikovat na celkovou velikost použitého paměťového či diskového prostoru.
7. Témata a oddíly
Apache Kafka umožňuje ukládání zpráv (zde se ovšem používá termín záznam – record) do různých témat, přičemž každé téma je rozděleno do oddílů neboli partition (samozřejmě je možné pro téma vyhradit pouze jediný oddíl a tvářit se, že máme k dispozici „vylepšenou“ frontu). Rozdělení do oddílů se provádí z několika důvodů. Jedním z nich je rozdělení zátěže, protože jednotlivé oddíly mohou být provozovány na různých počítačích v clusteru.
Dále se dělení provádí z toho důvodu, že každý oddíl obsahuje neměnnou (immutable) sekvenci zpráv. Oddíly pro jednotlivá témata lze zpracovávat v několika brokerech umístěných do clusteru a tak zajistit potřebný load balancing, případnou replikaci zpráv atd. Každá zpráva uložená do oddílu má přiřazen jednoznačný offset (reprezentovaný v Javě typem long). Navíc je možné, aby se pro každé téma udržovalo několik logů (partition logs), což umožňuje připojení většího množství konzumentů zpráv k jednomu tématu s tím, že tito konzumenti budou pracovat paralelně a nezávisle na sobě.
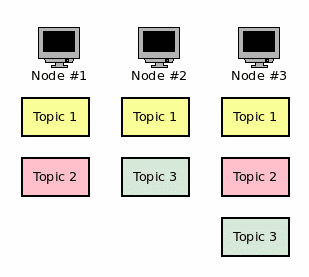
Obrázek 5: Příklad rozdělení témat v clusteru.
8. Replikace
U většiny nasazení Kafky se taktéž počítá s využitím většího množství instancí brokerů, z nichž je vytvořen cluster. Zde se setkáme s důležitým termínem replikace – každý oddíl je typicky replikován na několika message brokerech v clusteru (ovšem nemusí se jednat o všechny brokery, replikace se provádí například na tři brokery ve větším clusteru).
To však není vše, jelikož je ve skutečnosti konfigurace poněkud složitější – každý oddíl totiž může být replikován na více počítačích, přičemž jeden z těchto oddílů je takzvaným „leaderem“ a ostatní jsou „followeři“. Zápis nových zpráv popř. čtení se provádí vždy jen v rámci leaderu, ovšem změny jsou replikovány na všechny kopie oddílu. Ve chvíli, kdy z nějakého (libovolného) důvodu dojde k pádu „leadera“, převezme jeho roli jeden z dalších uzlů. Pokud tedy existuje N uzlů s replikou oddílu, bude systém funkční i ve chvíli, kdy zhavaruje N-1 uzlů!
Téma zpracovávané Kafkou může na clusteru vypadat například následovně:
+---+---+---+---+---+---+
oddíl #0 | 0 | 1 | 2 | 3 | 4 | 5 | ...
+---+---+---+---+---+---+
oddíl #1 | 0 | 1 | 2 | ...
+---+---+---+
oddíl #2 | ...
+---+---+---+---+---+---+---+---+---+
oddíl #3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ...
+---+---+---+---+---+---+---+---+---+
Boxy s čísly odpovídají jednotlivým zprávám, kterým jsou tato pořadová čísla v sekvenci postupně přiřazována. Zápis nových zpráv je prováděn do oblastí označených třemi tečkami. Z tohoto diagramu můžeme odvodit, že každý oddíl obsahuje vlastní sekvenci zpráv/záznamů, ke kterým se postupně připojují záznamy další.
9. Kafka Streams
Při práci se systémem Apache Kafka (typicky z Javy či ze Scaly) se často používá i knihovna nazvaná Kafka Streams. Jedná se o knihovnu určenou pro zjednodušení tvorby mikroslužeb. Tato knihovna je přímo součástí klientů (operace tedy probíhají u klientů a nikoli v brokeru), zatímco vstupní data jsou čteny z Kafky a výstupní data jsou ukládány zpět do Kafky (pochopitelně většinou do odlišného tématu). Předností této knihovny je i to, že kromě vstupně-výstupní datové části je možné aplikace programovat tím způsobem, na který jsou již programátoři zvyklí.
Další informace o Kafka Stream lze získat na adresách:
- Kafka Streams
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Streams - Kafka Streams
http://kafka.apache.org/documentation/streams/ - Kafka Streams (FAQ)
https://cwiki.apache.org/confluence/display/KAFKA/FAQ#FAQ-Streams
10. Ekosystém Apache Kafky
Vzhledem k popularitě Kafky pravděpodobně nebude velkým překvapením, že okolo ní vznikl celý rozsáhlý ekosystém. Jedná se především o:
- Knihovnu Kafka Streams zmíněnou v předchozí kapitole.
- Knihovny umožňující připojení ke Kafce z mnoha programovacích jazyků.
- Konektory pro další služby, produkující proud dat.
- Konektory pro další služby, které naopak proudy dat konzumují.
- Konektory pro různé databáze sloužící pro vstup dat (relační databáze s JDBC driverem, Cassandra, Couchbase atd. atd.)
- Konektory pro databáze pro uložení dat (Amazon S3, Hadoop, …)
- Rozhraní pro systémy pro zpracování logů.
- Již připravení konzumenti zpráv.
- Již připravení producenti zpráv – systémy pro poskytování metrik atd.
- Klient ovládaný z příkazové řádky (kafkacat)
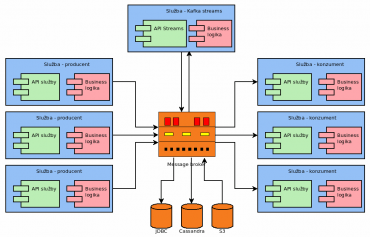
Obrázek 6: Příklad použití ekosystému Kafky (Kafka Streams, konektory pro databáze atd.).
Ekosystém Kafky je ovšem ve skutečnosti ještě rozsáhlejší, protože pro ni například vznikly operátory pro Kubernetes atd. Další informace je možné získat například ze stránek:
- Kafka – ecosystem (Wiki)
https://cwiki.apache.org/confluence/display/KAFKA/Ecosystem - The Kafka Ecosystem – Kafka Core, Kafka Streams, Kafka Connect, Kafka REST Proxy, and the Schema Registry
http://cloudurable.com/blog/kafka-ecosystem/index.html - A Kafka Operator for Kubernetes
https://github.com/krallistic/kafka-operator
11. Použití systému Apache Kafka z různých programovacích jazyků
Samotný systém Apache Kafka je naprogramován ve Scale a částečně i v Javě, takže jeho primární platformou je pochopitelně JVM (Java Virtual Machine). To však pochopitelně neznamená, že se Kafka nedá použít i z dalších programovacích jazyků. Ve skutečnosti existují rozhraní pro prakticky všechny používané a/nebo populární (což není v IT vždy totéž) programovací jazyky. Tato rozhraní jsou vypsána v následující tabulce:
| # | Jazyk/platforma |
|---|---|
| 1 | C/C++ |
| 2 | Python |
| 3 | Go/Golang |
| 4 | Erlang |
| 5 | .NET |
| 6 | Ruby |
| 7 | Node.js |
| 8 | Perl |
| 9 | PHP |
| 10 | Rust |
| 11 | Storm |
| 12 | Scala (DSL jazyk) |
| 13 | Clojure |
| 14 | Clojure |
| 15 | Swift |
| 16 | CLI (stdin/stdout) |
12. Nástroj kafkacat
Součástí ekosystému vytvořeného okolo Apache Kafky je i užitečný nástroj nazvaný kafkacat (autoři ho taktéž označují jako „netcat for Kafka“, v kontextu REST API by se hodilo i „curl for Kafka“). Tento nástroj, který naleznete na adrese https://github.com/edenhill/kafkacat slouží pro komunikaci s brokery přímo z příkazové řádky. Pochopitelně se s velkou pravděpodobností nebude jednat o řešení používané v produkčním kódu, ovšem možnost vytvořit producenta zpráv či jejich konzumenta přímo z CLI je použitelná jak při vývoji, tak i při řešení problémů, které mohou při běhu aplikace nastat. Tento nástroj budeme používat později, při ukázkách nasazení Apache Kafky, takže se jen krátce zmiňme o příkladech použití převzatých z oficiální dokumentace:
Spuštění nového producenta zpráv čtených ze souborů specifikovaných na příkazové řádce:
$ kafkacat -P -b jmeno_brokera -t filedrop -p 0 file1.bin file2.txt /etc/motd dalsi_soubor.tgz
Přečtení posledních 1000 zpráv z tématu „téma1“. Po této operaci se konzument automaticky ukončí, tj. nebude čekat na další zprávy:
$ kafkacat -C -b jmeno_brokera -t tema1 -p 0 -o -1000 -e
Spuštění konzumentů, kteří jsou přihlášení k tématu „téma1“:
$ kafkacat -b jmeno_brokera -G skupina_konzumentů téma1
Přihlásit se lze i k odběru většího množství témat:
$ kafkacat -b jmeno_brokera -G skupina_konzumentů téma1 téma2
13. Příklady použití Apache Kafka
V navazujících kapitolách se zmíníme o některých možnostech použití Apache Kafky. Uvidíme, že možnosti nasazení Kafky jsou skutečně dosti široké a do značné míry přesahují ty oblasti, v nichž jsou nasazováni klasičtí message brokeři. Většina příkladů použití je založena na možnosti přehrávání (replay) uložených záznamů a taktéž na tom, že jednotliví konzumenti zpráv mohou pracovat nezávisle na sobě (a to díky rozšířené strategii PUBLISH-SUBSCRIBE).
14. Logovací platforma
V současnosti se používá poměrně velké množství systémů zajišťujících ukládání a základní zpracování logovacích informací, a to i ve chvíli, kdy se logy zpracovávají z distribuovaných zdrojů. Mezi často používané systémy patří například Splunk, Snare či Logstash.
Ovšem pokud si uvědomíme, jaké jsou základní vlastnosti Apache Kafky, můžeme dojít k závěru, že i Kafku lze pro tento účel použít; a skutečně se takto i používá. Typicky se logovací informace ukládají do zvolených témat, přičemž jednotlivé záznamy jsou čteny buď jedním subscriberem (nejjednodušší případ, pokud se logy zpracovávají jediným systémem) nebo větším množstvím subscriberů (pokud pro zpracování logů máme k dispozici větší množství nástrojů). Výhoda tohoto řešení spočívá v tom, že jednou uložené logovací informace bude možné zpracovat i později nějakým dalším nástrojem, který lze do systému přidat kdykoli později. Taktéž – což vyplývá z vlastností samotného systému Kafka – je možné centrální řízení životnosti logovacích informací, jejich replikace atd.
15. Architektura lambda
Architektura lambda se používá v těch oblastech, v nichž jsou data využívána například na tréning různým modelů, přehrávání situací (sekvence událostí), k nimž již došlo a které byly do Kafky uloženy. Tato architektura je ve skutečnosti velmi přímočará a jejím ústředním prvkem je opět Apache Kafka či jiný streaming broker (NATS Streaming atd.)
Data získávaná z brokera jsou typicky zpracovávána v několika komponentách, přičemž jedna komponenta je optimalizována na získávání výsledků v reálném čase, kdežto další je určena pro dávkové zpracování (a další komponenta agreguje výsledky z této komponenty). Aby tyto dvě komponenty mohly pracovat korektně, musí zdroj dat obsahovat neměnitelné (immutable) záznamy, ke kterým se mohou připojovat záznamy další, ovšem další operace (smazání, modifikace, změna pořadí) již nejsou povoleny. A právě v této oblasti lze s výhodou použít systém Apache Kafka.
16. Architektura kappa
S architekturou nazývanou kappa jsme se již v tomto seriálu setkali. Připomeňme si, že se jedná o jedno z možných řešení pravděpodobně nejpalčivějšího problému, který se při návrhu a nasazování mikroslužeb musí řešit. Jedná se o problém distribuce dat a synchronizace databází jednotlivých mikroslužeb. V architektuře kappa je role databází invertována, protože databáze (přesněji řečeno každá databáze přidružená k určité mikroslužbě) zde slouží pouze ve funkci materializovaného pohledu na data, přičemž skutečná data (dokonce i s historií) jsou uložena právě v Apache Kafka formou záznamů s informacemi o změnách. Každá mikroslužba postupně zpracovává záznamy čtené z Kafky a aplikuje tyto záznamy na svou databázi – tím se provádí její postupná synchronizace s okolním světem.
- Mikroslužby jsou od sebe izolovány, není zapotřebí používat orchestraci atd.
- Pokud se do aplikace přidá nová mikroslužba, naplní se její databáze jednoduše – přehráním všech událostí zaznamenaných v nástroji pro streaming.
- Krátkodobý výpadek nějaké služby nevede ke ztrátě dat, ovšem může vést k viditelnému zpomalení činnosti z pohledu uživatele (potvrzení operace atd. atd.)
- V případě, že je zapotřebí změnit schéma databáze v nějaké mikroslužbě, opět se může její znovunaplnění provést přehráním událostí (čemuž pravděpodobně budeme věřit více, než jednoúčelovému skriptu pro migraci databáze).
- Migrace na zcela jinou databázi (změna dodavatele, přechod SQL→NoSQL či naopak) se opět může provést přehráním událostí.
- A nakonec – celá aplikace získá prakticky zadarmo audit log (audit trail), samozřejmě za předpokladu, že události obsahují všechny důležité informace.

Obrázek 7: Schéma aplikace založené na architektuře kappa.
Jedná se o poměrně novou architekturu, která však v případě aplikací založených na mikroslužbách může přinášet některé dosti podstatné výhody oproti stávajícím řešením (a pochopitelně i nevýhody, například prakticky nemožné zajištění skutečného ACIDu):
17. Apache Kafka ve funkci message brokera s frontami zpráv
Vzhledem k tomu, že Apache Kafka je dnes velmi populární technologií, používá se mnohdy i v těch oblastech, pro něž ve skutečnosti existují i lepší alternativy. Příkladem mohou být řešení, které Apache Kafku používají ve funkci klasického message brokera s frontami zpráv. Popišme si nyní, jak by takové řešení mohlo vypadat. Podrobnosti v případě zájmu najdete v článku Using Kafka as a message queue.

Při této konfiguraci se používá několik témat, především téma nazvané queue, které obsahuje zpracovávané zprávy. Jakmile se zpráva z tohoto tématu přečte nějakým konzumentem, je nutné offset této zprávy poslat společně se značkou START do tématu markers. Ve chvíli, kdy je zpráva v příjemci zpracována (k čemuž ovšem nemusí dojít – příjemce může zhavarovat nebo zprávu nezpracovat), pošle se značka END s offsetem, a to opět do tématu markers. V tomto tématu tedy budou k dispozici informace o rozpracovaných zprávách i o zprávách zpracovaných. A o tyto informace se musí starat další konzument, který zjistí, které zprávy je nutné poslat znovu a případně je zařadí do tématu (tento konzument je ovšem interně poměrně komplikovaný, protože musí zrekonstruovat skutečnou frontu). Celý systém má několik problematických rysů, protože při „vhodném“ pádu některé z komponent se může informace o zpracování zprávy ztratit, popř. bude nezpracovaná zpráva již zahozena.
18. Alternativní řešení
V oblasti nástrojů pro streaming je Apache Kafka v současnosti s velkou pravděpodobností nejpopulárnějším a nejpoužívanějším nástrojem, ovšem pochopitelně se nejedná o jediné řešení nabízející výše popsanou funkcionalitu. Na stránkách Roota jsme se již seznámili se systémem NATS Streaming Server, jenž je založen na message brokeru NATS, který je naprogramován v Go. Předností by měla být vyšší rychlost a menší systémové nároky, ovšem tyto údaje je pro reálně provozované systémy složité až nemožné získat – systémy by musely paralelně běžet jak s NATS Streaming Serverem, tak i s Apache Kafkou a porovnání by se muselo provést až po delší době provozu (ovšem aplikace tohoto typu psané v Go opravdu bývají kvalitní).
19. Odkazy na Internetu
- Understanding Kafka with Legos (video)
https://www.youtube.com/watch?v=Q5wOegcVa8E - Apache Kafka Tutorial For Beginners (video)
https://www.youtube.com/watch?v=U4y2R3v9tlY - Franz Kafka (Wikipedia)
https://en.wikipedia.org/wiki/Franz_Kafka - NATS
https://nats.io/about/ - NATS Streaming Concepts
https://nats.io/documentation/streaming/nats-streaming-intro/ - NATS Streaming Server
https://nats.io/download/nats-io/nats-streaming-server/ - NATS Introduction
https://nats.io/documentation/ - NATS Client Protocol
https://nats.io/documentation/internals/nats-protocol/ - NATS Messaging (Wikipedia)
https://en.wikipedia.org/wiki/NATS_Messaging - Stránka Apache Software Foundation
http://www.apache.org/ - Logstash
https://www.elastic.co/products/logstash - Elasticsearch
https://www.elastic.co/products/elasticsearch - Understanding When to use RabbitMQ or Apache Kafka
https://content.pivotal.io/blog/understanding-when-to-use-rabbitmq-or-apache-kafka - Part 1: Apache Kafka for beginners – What is Apache Kafka?
https://www.cloudkarafka.com/blog/2016–11–30-part1-kafka-for-beginners-what-is-apache-kafka.html - What are some alternatives to Apache Kafka?
https://www.quora.com/What-are-some-alternatives-to-Apache-Kafka - What is the best alternative to Kafka?
https://www.slant.co/options/961/alternatives/~kafka-alternatives - Apache Flume
https://flume.apache.org/index.html - Snare
https://www.snaresolutions.com/ - The Log: What every software engineer should know about real-time data's unifying abstraction
https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying - A super quick comparison between Kafka and Message Queues
https://hackernoon.com/a-super-quick-comparison-between-kafka-and-message-queues-e69742d855a8?gi=e965191e72d0 - Kafka Queuing: Kafka as a Messaging System
https://dzone.com/articles/kafka-queuing-kafka-as-a-messaging-system - Microservices – Not a free lunch!
http://highscalability.com/blog/2014/4/8/microservices-not-a-free-lunch.html - Microservices, Monoliths, and NoOps
http://blog.arungupta.me/microservices-monoliths-noops/ - Microservice Design Patterns
http://blog.arungupta.me/microservice-design-patterns/ - Vision of a microservice revolution
https://www.jolie-lang.org/vision.html - Microservices: a definition of this new architectural term
https://martinfowler.com/articles/microservices.html - Mikroslužby
http://voho.eu/wiki/mikrosluzba/ - Microservice Prerequisites
https://martinfowler.com/bliki/MicroservicePrerequisites.html - Microservices in Practice, Part 1: Reality Check and Service Design (vyžaduje registraci)
https://ieeexplore.ieee.org/document/7819415 - Microservice Trade-Offs
https://www.martinfowler.com/articles/microservice-trade-offs.html - What is a microservice? (from a linguistic point of view)
http://claudioguidi.blogspot.com/2017/03/what-microservice-from-linguisitc.html - Microservices (Wikipedia)
https://en.wikipedia.org/wiki/Microservices - Fallacies of distributed computing (Wikipedia)
https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing - Service (systems architecture)
https://en.wikipedia.org/wiki/Service_(systems_architecture) - Microservices in a Nutshell
https://www.thoughtworks.com/insights/blog/microservices-nutshell - What is Microservices?
https://smartbear.com/solutions/microservices/ - Mastering Chaos – A Netflix Guide to Microservices
https://www.youtube.com/watch?v=CZ3wIuvmHeM&t=17s - Messaging in Microservice Architecture
https://www.youtube.com/watch?v=MkQWQ5f-SEY - Pattern: Messaging
https://microservices.io/patterns/communication-style/messaging.html - Microservices Messaging: Why REST Isn’t Always the Best Choice
https://blog.codeship.com/microservices-messaging-rest-isnt-always-best-choice/ - Protocol buffers
https://developers.google.com/protocol-buffers/ - BSON
http://bsonspec.org/ - Apache Avro!
https://avro.apache.org/ - REST vs Messaging for Microservices – Which One is Best?
https://solace.com/blog/experience-awesomeness-event-driven-microservices/ - How did we end up here?
https://gotocon.com/dl/goto-chicago-2015/slides/MartinThompson_and_ToddMontgomery_HowDidWeEndUpHere.pdf - Scaling microservices with message queues to handle data bursts
https://read.acloud.guru/scaling-microservices-with-message-queue-2d389be5b139 - Microservices: What are smart endpoints and dumb pipes?
https://stackoverflow.com/questions/26616962/microservices-what-are-smart-endpoints-and-dumb-pipes - Common Object Request Broker Architecture
https://en.wikipedia.org/wiki/Common_Object_Request_Broker_Architecture - Enterprise service bus
https://en.wikipedia.org/wiki/Enterprise_service_bus - Microservices vs SOA : What’s the Difference
https://www.edureka.co/blog/microservices-vs-soa/ - Pravda o SOA
https://businessworld.cz/reseni-a-realizace/pravda-o-soa-2980 - Is it a good idea for Microservices to share a common database?
https://www.quora.com/Is-it-a-good-idea-for-Microservices-to-share-a-common-database - Pattern: Shared database
https://microservices.io/patterns/data/shared-database.html - Is a Shared Database in Microservices Actually an Anti-pattern?
https://hackernoon.com/is-shared-database-in-microservices-actually-anti-pattern-8cc2536adfe4 - Shared database in microservices is a problem, yep
https://ayende.com/blog/186914-A/shared-database-in-microservices-is-a-problem-yep - Microservices with shared database? using multiple ORM's?
https://stackoverflow.com/questions/43612866/microservices-with-shared-database-using-multiple-orms - Examples of microservice architecture
https://www.coursera.org/lecture/intro-ibm-microservices/examples-of-microservice-architecture-JXOFj - Microservices: The Rise Of Kafka
https://movio.co/blog/microservices-rise-kafka/ - Building a Microservices Ecosystem with Kafka Streams and KSQL
https://www.confluent.io/blog/building-a-microservices-ecosystem-with-kafka-streams-and-ksql/ - An introduction to Apache Kafka and microservices communication
https://medium.com/@ulymarins/an-introduction-to-apache-kafka-and-microservices-communication-bf0a0966d63 - ACID (computer science)
https://en.wikipedia.org/wiki/ACID_(computer_science) - Distributed transaction
https://en.wikipedia.org/wiki/Distributed_transaction - Two-phase commit protocol
https://en.wikipedia.org/wiki/Two-phase_commit_protocol - Why is 2-phase commit not suitable for a microservices architecture?
https://stackoverflow.com/questions/55249656/why-is-2-phase-commit-not-suitable-for-a-microservices-architecture - 4 reasons why microservices resonate
https://www.oreilly.com/ideas/4-reasons-why-microservices-resonate - Pattern: Microservice Architecture
https://microservices.io/patterns/microservices.html - Pattern: Monolithic Architecture
https://microservices.io/patterns/monolithic.html - Pattern: Saga
https://microservices.io/patterns/data/saga.html - Pattern: Database per service
https://microservices.io/patterns/data/database-per-service.html - Pattern: Access token
https://microservices.io/patterns/security/access-token.html - Databázová integrita
https://cs.wikipedia.org/wiki/Datab%C3%A1zov%C3%A1_integrita - Referenční integrita
https://cs.wikipedia.org/wiki/Referen%C4%8Dn%C3%AD_integrita - Introduction into Microservices
https://specify.io/concepts/microservices - Are Microservices ‘SOA Done Right’?
https://intellyx.com/2015/07/20/are-microservices-soa-done-right/ - The Hardest Part About Microservices: Your Data
https://blog.christianposta.com/microservices/the-hardest-part-about-microservices-data/ - From a monolith to microservices + REST
https://www.slideshare.net/InfoQ/from-a-monolith-to-microservices-rest-the-evolution-of-linkedins-service-architecture - DevOps and the Myth of Efficiency, Part I
https://blog.christianposta.com/devops/devops-and-the-myth-of-efficiency-part-i/ - DevOps and the Myth of Efficiency, Part II
https://blog.christianposta.com/devops/devops-and-the-myth-of-efficiency-part-ii/ - Standing on Distributed Shoulders of Giants: Farsighted Physicists of Yore Were Danged Smart!
https://queue.acm.org/detail.cfm?id=2953944 - Building DistributedLog: High-performance replicated log service
https://blog.twitter.com/engineering/en_us/topics/infrastructure/2015/building-distributedlog-twitter-s-high-performance-replicated-log-servic.html - Turning the database inside-out with Apache Samza
https://www.confluent.io/blog/turning-the-database-inside-out-with-apache-samza/ - Debezium: Stream changes from your databases.
https://debezium.io/ - Change data capture
https://en.wikipedia.org/wiki/Change_data_capture - Apache Samza (Wikipedia)
https://en.wikipedia.org/wiki/Apache_Samza - Storm (event processor)
https://en.wikipedia.org/wiki/Storm_(event_processor) - kappa-architecture.com
http://milinda.pathirage.org/kappa-architecture.com/ - Questioning the Lambda Architecture
https://www.oreilly.com/ideas/questioning-the-lambda-architecture - Lambda architecture
https://en.wikipedia.org/wiki/Lambda_architecture - Event stream processing
https://en.wikipedia.org/wiki/Event_stream_processing - How to beat the CAP theorem
http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html - Kappa Architecture Our Experience
https://events.static.linuxfound.org/sites/events/files/slides/ASPgems%20-%20Kappa%20Architecture.pdf - Messaging Patterns in Event Driven Microservice Architectures
https://www.youtube.com/watch?v=3×Dc4MEYuHI - Why monolithic apps are often better than microservices
https://gigaom.com/2015/11/06/why-monolithic-apps-are-often-better-than-microservices/ - How Enterprise PaaS Can Add Critical Value to Microservices
https://apprenda.com/blog/enterprise-paas-microservices/ - Common React Mistakes: Monolithic Components and a Lack of Abstraction
https://www.pmg.com/blog/common-react-mistakes-monolithic-components-lack-abstraction/ - From monolith to microservices – to migrate or not to migrate?
https://altkomsoftware.pl/en/blog/monolith-microservices/ - Command–query separation
https://en.wikipedia.org/wiki/Command%E2%80%93query_separation - GOTO 2016: Messaging and Microservices (Clemens Vasters)
https://www.youtube.com/watch?v=rXi5CLjIQ9kx - GOTO Amsterdam 2019
https://gotoams.nl/ - Lesson 2 – Kafka vs. Standard Messaging
https://www.youtube.com/watch?v=lwMjjTT1Q-Q - CommandQuerySeparation (Martin Fowler)
https://martinfowler.com/bliki/CommandQuerySeparation.html - Command–query separation
https://en.wikipedia.org/wiki/Command%E2%80%93query_separation - CQRS – Martin Fowler
https://martinfowler.com/bliki/CQRS.html - Lesson 12 – CQRS and Microservices
https://www.youtube.com/watch?v=pUGvXUBfvEE - Message queues - the right way to process and work with realtime data on your servers
https://www.ably.io/blog/message-queues-the-right-way





































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU