Obsah
1. Použití nástroje RQ (Redis Queue) pro správu úloh zpracovávaných na pozadí
2. Instalace knihovny RQ a všech přidružených utilit
3. Přečtení informací o stavu front
4. Implementace workera, který úlohy zpracuje
5. Jednoduchý skript pro naplánování úloh
6. Propojení a spuštění celého systému
7. Spuštění a využití dvou workerů
9. Zpracování parametrů předaných workerům
10. Použití většího množství pojmenovaných front
11. Plánování úloh do vybraných front
12. Čtení výsledků jednotlivých úloh zpracovaných workery
13. Výsledky skriptu, který zadá práci workerům a čte jejich výsledky
14. Zpracování úloh, které zhavarovaly
15. Opětovné spuštění zhavarovaných úloh
16. Využití burst režimu workerů
17. Jednoduchá aplikace (dashboard) pro sledování stavu front i workerů
18. Základní operace prováděné na dashboardu
19. Repositář s demonstračními příklady
1. Použití nástroje RQ (Redis Queue) pro správu úloh zpracovávaných na pozadí
V předchozích dvou článcích [1] [2] jsme se seznámili se základními vlastnosti databáze Redis, a to především z pohledu vývojářů používajících programovací jazyk Python a knihovnu https://github.com/andymccurdy/redis-py. Dnes si ukážeme jedno z velmi elegantních a nutno říci, že i užitečných využití Redisu. Jedná se o projekt nazvaný jednoduše RQ neboli plným jménem Redis Queue. Nástroj RQ umožňuje vytváření takzvaných úloh (zde se ovšem používá termín job, nikoli task), které jsou ukládány do zvolené fronty. Následně si úlohy z fronty vyzvedává takzvaný worker, který zadanou úlohu zpracuje a uloží případný výsledek do Redisu, odkud si tento výsledek může kdokoli, kdo zná identifikátor úlohy, přečíst. Samotná úloha (job) není nic složitého – jedná se o pouhé určení funkce (a jejích parametrů) implementované v Pythonu a přímo volané z workeru.
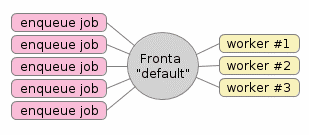
Obrázek 1: Typická konfigurace systému založeného například na zde popisovaném nástroji RQ. Zde se konkrétně používá jediná fronta nazvaná „default“, do které se mohou úlohy přidávat několika programy (těch může být libovolné množství). Samotné zpracování úloh je reprezentováno ve workerech, kterých taktéž může být libovolné množství podle požadavků aplikace, dostupných zdrojů atd. atd. Navíc je možné, aby v systému existovalo větší množství pojmenovaných front. Fronty je tak možné rozdělit podle priority, typu zpracovávaných úloh apod. Existuje dokonce jedna fronta, do níž se ukládají ty úlohy, na nichž worker zhavaroval.
Elegance a užitečnost celého tohoto systému spočívá v tom, že úlohy je možné vytvářet v několika zcela nezávislých procesech (například se může jednat o webovou službu, dále o CLI utilitku apod.), samotných workerů může být taktéž prakticky libovolné množství (můžeme celý systém škálovat na pozadí) a dokonce můžeme použít několik front, přičemž každé frontě je přiděleno jednoznačné jméno. Jednotliví workeři se potom připojují ke specifikovaným frontám. Konfigurace (nebo chcete-li správa) celého systému založeného na RQ je taktéž jednoduchá, protože si vystačíme s běžícím Redisem, utilitkou RQ popsanou dále, implementací workera (což může být ve skutečnosti otázka pouhých několika řádků v Pythonu) a konečně implementací skriptu či aplikace, která bude do fronty přidávat další úlohy (opět se jedná o pouhých několik řádků v Pythonu). Vše si samozřejmě ukážeme na několika demonstračních příkladech.

Obrázek 2: Podobných systémů jako Redis Queue ve skutečnosti existuje více. Na tomto obrázku je ukázána architektura nástroje Celery, který je složitější, ale současně i mocnější, než RQ.
Zdroj obrázku: https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2
2. Instalace knihovny Rq a všech přidružených utilit
Knihovnu RQ si před jejím otestováním samozřejmě nejdříve musíme nainstalovat, a to klasicky s využitím dnes již prakticky standardního nástroje pip3 (nebo pip), protože tato knihovna je samozřejmě registrována i na PyPI (Python Package Indexu). Pro jednoduchost provedeme instalaci jen pro právě aktivního uživatele, takže použijeme přepínač –user:
$ pip3 install --user rq
Collecting rq
Downloading https://files.pythonhosted.org/packages/1d/3f/e05539962949aecd83496736f73abd36bd811884a20f68f691b59805125e/rq-0.12.0-py2.py3-none-any.whl (54kB)
100% |████████████████████████████████████████████████████████████████████████████████████████████████| 61kB 856kB/s
Requirement already satisfied: click>=5.0 in ./.local/lib/python3.6/site-packages (from rq)
Requirement already satisfied: redis>=2.7.0 in ./.local/lib/python3.6/site-packages (from rq)
Installing collected packages: rq
Successfully installed rq-0.12.0
You are using pip version 9.0.1, however version 18.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
Po instalaci by měl být na cestě (PATH) dostupný i nástroj nazvaný jednoduše rq. I tuto skutečnosti si samozřejmě můžeme otestovat:
$ whereis -b rq rq: /home/tester/.local/bin/rq
V případě, že rq nebyl nalezen, vypište si pro jistotu obsah proměnné prostředí PATH a ujistěte se, že obsahuje mj. i adresář ~/.local/bin/. Přidání tohoto adresáře je snadné, například můžeme upravit soubor .bashrc (pokud pochopitelně používáte BASH):
export PATH=$PATH:~/.local/bin/
Pokud byl zmíněný příkaz rq nalezen, můžeme ho pro otestování spustit a zjistit, zda vypisuje svoji nápovědu:
Usage: rq [OPTIONS] COMMAND [ARGS]... RQ command line tool. Options: --version Show the version and exit. --help Show this message and exit. Commands: empty Empty given queues. info RQ command-line monitor. requeue Requeue failed jobs. resume Resumes processing of queues, that where... suspend Suspends all workers, to resume run `rq... worker Starts an RQ worker.
3. Přečtení informací o stavu front
První užitečnou pomůckou, kterou nám (jakožto administrátorům i programátorům) nástroj RQ poskytuje, jsou informace o stavu všech front. Tato informace se získá příkazem rq info. RQ se v tomto případě pokusí připojit k běžícímu Redisu a získat z databáze potřebné základní informace o všech frontách. V našem případě nám server Redisu prozatím neběží, takže by se mělo vypsat následující chybové hlášení:
$ rq info Error 111 connecting to localhost:6379. Connection refused.
Spuštění samotného serveru Redisu je, jak jsme si již řekli v předchozích dvou článcích, velmi snadné, takže si jen ve stručnosti připomeňme, že budeme používat konfigurační soubor uložený do adresáře ~/redis. A přímo z tohoto adresáře Redis spustíme:
$ cd ~/redis $ redis-server redis.conf
Ve chvíli, kdy již server Redisu běží (lze ověřit v jeho logu redis.log), by měl příkaz rq info vypsat informace o všech frontách. Prozatím jsme ještě vlastně vůbec nespustili ani jednoho workera ani jsme nevytvořili jedinou úlohu. Příkaz by tedy měl vypsat tuto informaci:
- nejsou používány žádné fronty
- nebyly do nich tudíž ani uloženy žádné úlohy
- nepracují žádní workeři
- neexistující workeři pochopitelně nejsou připojeni k frontám
Ověřme si to:
$ rq info 0 queues, 0 jobs total 0 workers, 0 queues Updated: 2018-11-26 18:14:33.032764
Pokud se skutečně vypsaly výše uvedené informace, měl by být jak Redis, tak i nástroj RQ dobře nakonfigurován a můžeme se začít připravovat na vytvoření prvního skutečně fungujícího příkladu.
4. Implementace workera, který úlohy zpracuje
Celé nastavení Redisu a nástroje RQ provádíme především z toho důvodu, aby bylo možné plánovat a rozdělovat nějakou práci (například zpracování transakce, analýzu dat, uložení analyzovaných dat apod.) mezi větší množství takzvaných workerů. Dalším důvodem je vzájemné oddělení (decoupling) jednotlivých modulů celého systému, což například zlepšuje testovatelnost a umožňuje snadnější výměnu jednotlivých částí. Navíc se může zvýšit robustnost celého systému, protože i ty úlohy, které z nějakého důvodu zhavarovaly, je možné spustit později.
Zcela nejjednodušším typem workera je z pohledu nástroje RQ jediná funkce naprogramovaná v Pythonu, která po svém (nepřímém) zavolání vykoná nějakou předem naprogramovanou činnost. Této funkci se typicky předávají nějaké parametry, funkce může mít (a velmi často i mívá) vedlejší efekty a dokonce může vracet zpět nějaký výsledek, který může být na určitou dobu uložen do Redisu a posléze je ho možné vyzvednout a dále zpracovat. Ovšem většinou se spoléháme spíše na vedlejší efekt workeru, kterým může být například uložení hodnot do databáze, poslání e-mailu, naplánování nové úlohy (!) apod.
Podívejme se nyní, jak může vypadat implementace velmi jednoduchého workeru, který neočekává žádné parametry a ani nikam neukládá žádné výsledky. Ten po svém zavolání pouze vypíše informaci na standardní výstup, počká několik sekund (tedy simuluje práci :-), vypíše druhou zprávu o dokončení své důležité práce a následně je ukončen:
from time import sleep
def do_work():
print("Working")
sleep(2)
print("Done")
Zdrojový kód s workerem může být uložen kdekoli, ovšem musíme mít na paměti, že tento zdrojový kód musí být dostupný (viditelný) z nástroje RQ (protože právě z RQ bude worker spouštěn). V praxi to může znamenat jednoduše to, že příkaz rq worker budeme muset startovat ze stejného adresáře, v němž se nachází implementace workera (nepatrně složitější bude situace ve chvíli, kdy je worker implementován jako celá knihovna nebo modul).
5. Jednoduchý skript pro naplánování úloh
Druhý skript slouží pro vytváření (plánování) nových úloh a pro jejich poslání do fronty, odkud si úlohu později převezme nějaký worker. Nejdříve se zajistí připojení do Redisu a získání objektu představujícího frontu (zde se konkrétně bude jednat o výchozí frontu nazvanou jednoduše „default“):
q = Queue(connection=Redis())
Následně se do této fronty vloží nová úloha, která bude provedena workerem, jenž implementuje funkci „do_work“. Zde si povšimněte především toho, že do metody Queue.enqueue předáváme referenci na funkci implementovanou workerem. Nejedná se o pouhé jméno, ale o skutečnou referenci, takže je nutné importovat modul s workerem:
result = q.enqueue(do_work)
Samotná návratová hodnota metody Queue.enqueue ovšem není výsledkem práce workera (ten je totiž spuštěn asynchronně v předem neznámém čase), ale reference na objekt, který můžeme použít pro čtení výsledků z Redisu popř. pro zjištění, zda již výsledky existují.
Úplný skript, po jehož spuštění se do fronty přidá jedna nová úloha, vypadá následovně:
from redis import Redis from rq import Queue from worker import do_work q = Queue(connection=Redis()) result = q.enqueue(do_work) print(result)
V praxi se samozřejmě může naplánovat větší množství úloh (jinak by existence fronty postrádala význam a postačoval by jednodušší mailbox), což je odsimulováno dalším skriptem, který do fronty postupně vloží zadání deseti úloh:
from redis import Redis
from rq import Queue
from worker import do_work
q = Queue(connection=Redis())
for i in range(10):
result = q.enqueue(do_work)
print(result)
6. Propojení a spuštění celého systému
Nyní tedy máme připraveny čtyři části celého systému:
- Databázi Redis, již běžící jako server.
- Systém RQ startující workery, prozatím neběžící.
- Skript implementující workera.
- Skript, který workerům nepřímo zadává úlohy.
Nejprve spustíme skript, který workerům přidá úlohy, které budou uloženy do fronty nazvané „default“:
$ python3 enqueue_work.py 12:30:12 RQ worker 'rq:worker:localhost.12549' started, version 0.12.0 12:30:12 *** Listening on default... 12:30:12 Cleaning registries for queue: default ... ... ...
Po dokončení skriptu znovu spustíme rq info a získáme aktuální stav front. Výstup by měl vypadat následovně:
$ rq info default |██ 10 1 queues, 1 jobs total localhost.28046 busy: default 0 workers, 1 queues Updated: 2018-11-23 18:06:24.461996
Ve druhém bloku se zobrazují informace o workerech, kteří mohou být typicky ve stavu „busy“ nebo „idle“.
Můžeme samozřejmě spustit i druhý skript, který do fronty přidá dalších deset úloh:
$ python3 enqueue_more_work.py <Job e3e800c4-a8e1-41c8-8f34-ab7a8f3264dd: worker.do_work()> <Job 940d4b54-4960-41b3-90b1-3218a01f22f9: worker.do_work()> <Job 4129bfce-5982-4ab6-b0ee-8d1cf8f888a8: worker.do_work()> <Job ecb5b410-5fe0-4251-b910-827ad5f8e657: worker.do_work()> <Job c9ca571a-c5ac-4c76-8c22-d573969a313f: worker.do_work()> <Job 186eea65-6b1d-4535-8f50-e9cf0cf55cba: worker.do_work()> <Job 76f55862-9cc4-4a47-beb3-eb8078e8f1dd: worker.do_work()> <Job bf2a96e0-6de8-4434-9e80-86f96e5a8a23: worker.do_work()> <Job 925e0f63-927f-424f-bcde-091dfa0d9940: worker.do_work()> <Job 4c2790b1-4992-482f-8576-699e38576992: worker.do_work()>
Opětovným spuštěním příkazu rq info se přesvědčíme o tom, že se úlohy do fronty „default“ skutečně vložily:
$ rq info default |██████████████████████████████ 11 1 queues, 11 jobs total localhost.28046 busy: default 0 workers, 1 queues Updated: 2018-11-23 18:06:24.461996
Může ovšem taktéž nastat situace, kdy nastane na straně workera chyba. V tomto případě se úloha uloží do fronty nazvané „failed“ a situace bude nepatrně odlišná od situace předchozí:
$ rq info default |██████████████████████████████ 10 failed |██████ 2 2 queues, 12 jobs total localhost.28046 busy: default 1 workers, 2 queues Updated: 2018-11-23 18:06:24.461996
V této chvíli již tedy máme úlohy připraveny ve frontě, takže můžeme spustit workera (prozatím jediného) a to příkazem:
$ rq worker 12:30:12 RQ worker 'rq:worker:localhost.12549' started, version 0.12.0 12:30:12 *** Listening on default... 12:30:12 Cleaning registries for queue: default
Jakmile je worker připojen, měl by začít z fronty odebírat jednotlivé úlohy a postupně je zpracovávat:
12:30:12 default: worker.do_work() (df740da4-96f9-4c84-a2c3-b333f2882237) Working Done 12:30:35 default: Job OK (fd78d637-0209-4137-b0b7-a156ae6776f3) 12:30:35 Result is kept for 500 seconds ... ... ... 12:30:14 default: Job OK (df740da4-96f9-4c84-a2c3-b333f2882237) 12:30:14 Result is kept for 500 seconds 12:30:14 default: worker.do_work() (e3e800c4-a8e1-41c8-8f34-ab7a8f3264dd) Working Done ... ... ... 12:30:35 default: worker.do_work() (4c2790b1-4992-482f-8576-699e38576992) Working Done 12:30:37 default: Job OK (4c2790b1-4992-482f-8576-699e38576992) 12:30:37 Result is kept for 500 seconds
Pokud v průběhu zpracovávání úloh pustíme na dalším terminálu příkaz rq info, mělo by být patrné, že worker skutečně pracuje a postupně vybírá prvky z fronty „default“:
$ rq info default |██████ 3 1 queues, 3 jobs total localhost.28046 busy: default 1 workers, 1 queues Updated: 2018-11-23 18:06:42.148104
Popř. pokud je již vytvořena fronta „failed“, zůstane její obsah nezměněn:
$ rq info default |███ 1 failed |██████ 2 2 queues, 3 jobs total localhost.28046 busy: default 1 workers, 2 queues Updated: 2018-11-23 18:06:42.148104
Takto bude vypadat situace ve chvíli, kdy worker dokončil všechny mu přidělené úlohy:
$ rq info default | 0 1 queues, 0 jobs total localhost.28046 idle: default 1 workers, 1 queues Updated: 2018-11-23 18:06:50.867752
Alternativní konec práce workera – standardní úlohy byly dokončeny, ovšem zůstává několik úloh ve frontě „failed“:
$ rq info failed |██████ 2 default | 0 2 queues, 2 jobs total localhost.28046 idle: default 1 workers, 2 queues Updated: 2018-11-23 18:06:50.867752
7. Spuštění a využití dvou workerů
Nic nám samozřejmě nebrání využít flexibility systému RQ a spustit několik na sobě nezávislých workerů. To se provádí snadno – spustíme příkaz rq worker tolikrát, kolik workerů budeme potřebovat. Pro ilustraci nyní pustíme dva workery, každý na jiném terminálu (v praxi byste pravděpodobně provedli spuštění na pozadí pomocí nástroje nohup a &, vytvoření klasické služby atd. atd.).
První terminál:
$ rq worker 12:36:57 RQ worker 'rq:worker:localhost.12619' started, version 0.12.0 12:36:57 *** Listening on default... 12:36:57 Cleaning registries for queue: default
Druhý terminál:
$ rq worker 12:36:51 RQ worker 'rq:worker:localhost.12614' started, version 0.12.0 12:36:51 *** Listening on default... 12:36:51 Cleaning registries for queue: default
Pokud nyní spustíme skript enqueue_more_work.py pro vytvoření nových úloh, budou se workeři v provádění úloh střídat – podle toho, který worker je v daný okamžik zaneprázdněný a který nikoli. Pokud jsou oba workeři připraveni přijímat úlohy, záleží jen na plánovači operačního systému, který worker úlohu získá a zpracuje (to je jedna z vlastností RQ: nesnaží se reimplementovat ty činnosti, pro které již existuje vhodné a ověřené řešení):
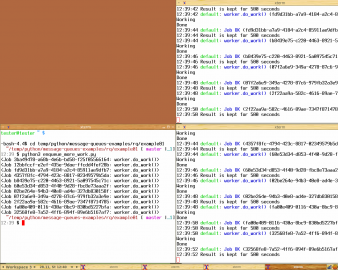
Obrázek 3: Na dvojici terminálů napravo jsou spuštěny workeři. V levém terminálu pak skript, který do fronty „default“ přidává nové úlohy. Tyto úlohy jsou automaticky odebírány a zpracovávány jednotlivými workery systémem „kdo dřív přijde, ten dřív mele“.
Pokud nyní spustíme příkaz rq info, zobrazí se informace o větším množství workerů:
$ rq info default |███ 4 1 queues, 4 jobs total localhost.29010 busy: default localhost.28864 busy: default 2 workers, 1 queues Updated: 2018-11-23 18:08:11.005553
Alternativní zobrazení ve chvíli, kdy existuje i fronta s úlohami, které zhavarovaly:
$ rq info default |█ 1 failed |██ 2 2 queues, 3 jobs total localhost.29010 busy: default localhost.28864 busy: default 2 workers, 2 queues Updated: 2018-11-23 18:08:13.012523
Po dokončení všech úloh se zobrazí:
$ rq info default | 0 1 queues, 2 jobs total localhost.28864 idle: default localhost.29010 idle: default 2 workers, 1 queues Updated: 2018-11-23 18:08:34.512040
Popř.:
$ rq info default | 0 failed |██ 2 2 queues, 2 jobs total localhost.28864 idle: default localhost.29010 idle: default 2 workers, 2 queues Updated: 2018-11-23 18:08:39.268931
8. Předání parametrů workerům
V úvodních kapitolách jsme si řekli, že workerům je možné předávat nějaké parametry o úlohách, které mají zpracovat (což je ostatně logické). Provádí se to snadno. Nejprve se podívejme na implementaci samotného workera, konkrétně na funkci, kterou jsme pojmenovali do_work. Tuto funkci můžeme přepsat takovým způsobem, aby akceptovala nějaký parametr. Nová podoba funkce může vypadat následovně:
from time import sleep
def do_work(param):
print("Working, received parameter {}".format(param))
sleep(2)
print("Done")
Jak se však parametr dostane do fronty? Tento parametr (nebo více parametrů) se předá metodě Queue.enqueue. Původně jsme tuto metodu volali takto:
result = q.enqueue(do_work)
Můžeme však použít i nepovinný parametr (parametry), které se v daném pořadí předají workeru:
result = q.enqueue(do_work, 0)
Upravený skript pro vytvoření nové úlohy může vypadat následovně:
from redis import Redis from rq import Queue from worker import do_work q = Queue(connection=Redis()) result = q.enqueue(do_work, 0) print(result)
Samozřejmě můžeme vytvořit více úloh, přičemž každá úloha bude (později) spuštěna s jiným parametrem:
from redis import Redis
from rq import Queue
from worker import do_work
q = Queue(connection=Redis())
for i in range(10):
result = q.enqueue(do_work, i)
print(result)
9. Zpracování parametrů předaných workerům
Pokud nyní spustíme jednoho workera, můžeme sledovat, že skutečně přijímá parametry úlohy a současně, že se úlohy zpracovávají v tom pořadí, v jakém byly vloženy do fronty:
$ rq worker 11:58:29 default: Job OK (1e26c193-e17e-4a7d-8dbe-75646af3cee3) 11:58:29 Result is kept for 500 seconds 11:58:31 default: worker.do_work(0) (5f937d3a-2b52-47a0-b0fd-cb00ed1adbc7) Working, received parameter 0 Done 11:58:33 default: Job OK (5f937d3a-2b52-47a0-b0fd-cb00ed1adbc7) 11:58:33 Result is kept for 500 seconds 11:58:33 default: worker.do_work(1) (8c9b59a9-6a75-47fb-92c8-5ddab6f84668) Working, received parameter 1 Done 11:58:35 default: Job OK (8c9b59a9-6a75-47fb-92c8-5ddab6f84668) 11:58:35 Result is kept for 500 seconds 11:58:35 default: worker.do_work(2) (deae6704-0b5d-4835-a2fd-edfa807d40f3) Working, received parameter 2 Done 11:58:37 default: Job OK (deae6704-0b5d-4835-a2fd-edfa807d40f3) 11:58:37 Result is kept for 500 seconds 11:58:37 default: worker.do_work(3) (e1104446-a1b8-4f18-8dbb-5ed0052aa492) Working, received parameter 3 Done 11:58:39 default: Job OK (e1104446-a1b8-4f18-8dbb-5ed0052aa492) 11:58:39 Result is kept for 500 seconds 11:58:39 default: worker.do_work(4) (8d4329c2-b74e-4ac3-a8e5-10956bb65ce6) Working, received parameter 4 Done 11:58:41 default: Job OK (8d4329c2-b74e-4ac3-a8e5-10956bb65ce6) 11:58:41 Result is kept for 500 seconds 11:58:41 default: worker.do_work(5) (6edbd9cd-39b9-46e5-a2da-720cabbbf84b) Working, received parameter 5 Done ... ... ...
10. Použití většího množství pojmenovaných front
V této kapitole si ukážeme, jakým způsobem je možné nakonfigurovat a použít větší množství front. Opět začneme implementací workera. Ve skutečnosti se v jeho zdrojovém kódu nemusí nic měnit, protože worker je volaný z utilitky rq a tudíž přímo s frontami nemusí komunikovat:
from time import sleep
def do_work(param):
print("Working, received parameter {}".format(param))
sleep(2)
print("Done")
Liší se však způsob spuštění workera. Nyní můžeme utilitě rq předat jak jméno workera (resp. skriptu, kde je implementovaný), tak i jméno fronty, přes kterou se workeru mají předávat úlohy:
$ rq worker low 13:22:53 RQ worker 'rq:worker:localhost.4409' started, version 0.12.0 13:22:53 *** Listening on low... 13:22:53 Cleaning registries for queue: low 13:22:53 low: worker.do_work(0) (84c123db-0584-45e9-8372-ee2136b93e5e) Working, received parameter 0 Done 13:22:55 low: Job OK (84c123db-0584-45e9-8372-ee2136b93e5e) 13:22:55 Result is kept for 500 seconds 13:22:55 low: worker.do_work(1) (f24ad99e-b289-4be0-8769-5957bbdc4dc3) Working, received parameter 1 Done
Dokonce můžeme specifikovat i větší množství front, zde konkrétně front se jmény „low“ a „high“:
$ rq worker low high 15:37:37 RQ worker 'rq:worker:localhost.29635' started, version 0.12.0 15:37:37 *** Listening on low, high... 15:37:37 Cleaning registries for queue: low 15:37:37 Cleaning registries for queue: high 15:37:37 high: worker.do_work(8) (267314d3-4a0f-4fa2-883e-3ce6b8afc711)
Příkaz rq info by měl nyní zobrazit informaci o minimálně třech frontách:
$ rq info default | 0 high | 0 low | 0 3 queues, 0 jobs total localhost.29635 idle: low, high 1 workers, 3 queues Updated: 2018-11-28 15:38:15.500669
11. Plánování úloh do vybraných front
Pokud budeme chtít naplánovat úlohu do jiné fronty, než je výchozí fronta pojmenovaná „default“, je nutné jméno fronty specifikovat již při inicializaci objektu Queue. Jméno fronty se předává v prvním parametru konstruktoru:
q_low = Queue("low", connection=Redis())
q_high = Queue("high", connection=Redis())
Po spuštění následujícího skriptu se vytvoří dvacet úloh, přičemž deset z nich se vloží do fronty nazvané „low“ a zbylých deset do fronty pojmenované „high“:
from redis import Redis
from rq import Queue
from worker import do_work
q_low = Queue("low", connection=Redis())
q_high = Queue("high", connection=Redis())
for i in range(10):
result = q_low.enqueue(do_work, i)
result = q_high.enqueue(do_work, i)
print(result)
Výchozí stav front před spuštěním předchozího skriptu může být následující:
$ rq info failed |██ 2 default | 0 2 queues, 2 jobs total localhost.4312 idle: default 1 workers, 2 queues Updated: 2018-11-26 13:21:08.333807
Ihned po spuštění (pokud neběží workeři) získáme informaci o dvou nových frontách, z nichž každá obsahuje deset úloh:
$ rq info low |██████████ 10 failed |██ 2 default | 0 high |██████████ 10 4 queues, 22 jobs total localhost.4312 idle: default 1 workers, 4 queues Updated: 2018-11-26 13:22:06.236766
Ve chvíli, kdy spustíme jediného workera příkazem rq worker low, zpracuje worker pouze úlohy z fronty „low“ a zbylé fronty bude ignorovat:
$ rq info low | 0 high |██████████ 10 default | 0 failed |██ 2 4 queues, 12 jobs total localhost.4430 busy: high 1 workers, 4 queues
12. Čtení výsledků jednotlivých úloh zpracovaných workery
Prozatím jsme si neukázali, jakým způsobem je možné číst výsledky vytvořené jednotlivými workery. Výsledkem je myšlena návratová hodnota funkce, kterou je worker implementován. Tyto výsledky se ukládají zpět do Redisu, kde jsou ovšem (pokud neprovedeme odlišnou konfiguraci) zachovány pouze po určitou dobu – ve výchozím nastavení se jedná o 500 sekund. V případě, že nějaký nástroj či aplikace zná ID příslušné úlohy, může si výsledek z Redisu přečíst. Ovšem čtení je možné provést i jednodušším způsobem, a to přímo ze skriptu, který úlohy vytváří. Návratovou hodnotou metody Queue.enqueue je totiž objekt představující právě vytvořenou úlohu a přes tento objekt se můžeme pokusit přečíst výsledky: jednoduše přečteme hodnotu atributu result:
q = Queue(connection=Redis()) job = q.enqueue(do_work, 42) result = job.result print(result)
Ve skutečnosti ovšem získáme prakticky ve všech případech pouze hodnotu None, protože se snažíme výsledky přečíst ihned poté, co byla úloha vložena do fronty. Hodnota None značí, že prozatím žádný výsledek není k dispozici. Ukažme si tedy nepatrně složitější příklad, v němž vytvoříme několik úloh, počkáme sedm sekund a teprve poté se pokusíme přečíst výsledky úloh. Sedm sekund je zvoleno proto, aby se některé úlohy stihly dokončit a jiné nikoli:
from redis import Redis
from rq import Queue
from time import sleep
from worker import do_work
q_low = Queue("low", connection=Redis())
q_high = Queue("high", connection=Redis())
jobs = []
for i in range(10):
job = q_low.enqueue(do_work, i)
jobs.append(job)
job = q_high.enqueue(do_work, i)
jobs.append(job)
print("Zzz")
sleep(7)
print("Reading job results")
for job in jobs:
print(job)
result = job.result
if result is not None:
print(result)
13. Výsledky skriptu, který zadá práci workerům a čte jejich výsledky
Po spuštění výše popsaného skriptu můžeme získat následující výsledky. Vždy je zobrazen řetězec reprezentující každou úlohu a pokud je již známý výsledek, je ihned zobrazen na následujícím řádku:
Zzz Reading job results <Job 31caa957-b8a2-401d-a3fd-2c0c7167c53c: worker.do_work(0)> <Job 25ae9c85-532d-4b3c-ba8b-1195b20d3603: worker.do_work(0)> 1.0 <Job 30f8572e-297e-499a-91c7-ff0097c82071: worker.do_work(1)> <Job d0547019-f429-40d9-8ef4-b7efcae31833: worker.do_work(1)> 0.5 <Job 09f7b366-feaa-4a2f-8686-665f23236848: worker.do_work(2)> <Job 597cd7ec-25eb-4569-af94-8ee3777369c2: worker.do_work(2)> 0.3333333333333333 <Job e733712b-483c-4161-8b3a-2bcc3d1891cc: worker.do_work(3)> <Job 23c50496-049b-4b24-a26f-5889af66e97e: worker.do_work(3)> <Job fb1dfce7-8c19-4d1f-a8ec-59b01576cd6b: worker.do_work(4)> <Job 70f62ea9-e9c8-40b5-a8d4-cd4742fee063: worker.do_work(4)> <Job f4b022d1-e5ea-4001-b1c3-de0338c669d6: worker.do_work(5)> <Job 345b2470-92a1-4169-af2e-3b8b283aba56: worker.do_work(5)>
14. Získání informací o úlohách, které zhavarovaly
Již v předchozích kapitolách jsme se zmínili o tom, že některé úlohy mohou zhavarovat, a to z různých důvodů. Nyní si toto chování odsimulujeme na nepatrně upraveném workerovi, který zhavaruje (vyhodí výjimku) na řádku s příkazem assert:
from time import sleep
def do_work():
print("Working")
sleep(2)
assert False
print("Done")
Workera spustíme:
$ rq worker 16:59:02 RQ worker 'rq:worker:localhost.32100' started, version 0.12.0 16:59:02 *** Listening on default... 16:59:02 Cleaning registries for queue: default
Takto upravený worker při pokusu o vykonání úlohy pochopitelně vyhodí výjimku, což je systémem RQ správně detekováno:
16:59:03 default: worker.do_work() (c5468250-e2c5-494f-8bd8-f1f51b9a81f2)
Working
16:59:05 AssertionError
Traceback (most recent call last):
File "/home/tester/.local/lib/python3.6/site-packages/rq/worker.py", line 793, in perform_job
rv = job.perform()
File "/home/tester/.local/lib/python3.6/site-packages/rq/job.py", line 599, in perform
self._result = self._execute()
File "/home/tester/.local/lib/python3.6/site-packages/rq/job.py", line 605, in _execute
return self.func(*self.args, **self.kwargs)
File "./worker.py", line 7, in do_work
assert False
AssertionError
Traceback (most recent call last):
File "/home/tester/.local/lib/python3.6/site-packages/rq/worker.py", line 793, in perform_job
rv = job.perform()
File "/home/tester/.local/lib/python3.6/site-packages/rq/job.py", line 599, in perform
self._result = self._execute()
File "/home/tester/.local/lib/python3.6/site-packages/rq/job.py", line 605, in _execute
return self.func(*self.args, **self.kwargs)
File "./worker.py", line 7, in do_work
assert False
AssertionError
16:59:05 Moving job to 'failed' queue
Taková úloha se automaticky přesune do fronty nazvané „failed“, takže stav front může vypadat například následovně:
$ rq info low |███████████ 11 failed |███ 3 default | 0 high |███████████ 11 4 queues, 25 jobs total localhost.32100 idle: default 1 workers, 4 queues Updated: 2018-11-28 16:59:51.713251
Veškeré informace o úloze jsou tedy uloženy zpět do Redisu, odkud je můžeme získat. Poslední skript slouží k získání všech informací o úlohách, které zhavarovaly. Vypíše se typ úlohy, kdy byla spuštěna, samotná výjimka apod.:
from redis import Redis
from rq import Queue
from time import sleep
from worker import do_work
q_failed = Queue("failed", connection=Redis())
print("Reading failed jobs")
job_ids = q_failed.job_ids
print(job_ids)
for job_id in job_ids:
print(job_id)
job = q_failed.fetch_job(job_id)
print(job.origin)
print(job.enqueued_at)
print(job.started_at)
print(job.ended_at)
print(job.exc_info)
V našem případě bychom měli získat přibližně následující informace (samozřejmě se mohou lišit časová razítka):
Reading failed jobs
['62d5d473-cc31-4738-8397-7dd18b09fe64']
62d5d473-cc31-4738-8397-7dd18b09fe64
default
2018-11-28 16:24:45.094810
2018-11-28 16:24:45.103332
2018-11-28 16:24:47.107423
Traceback (most recent call last):
File "/home/tester/.local/lib/python3.6/site-packages/rq/worker.py", line 793, in perform_job
rv = job.perform()
File "/home/tester/.local/lib/python3.6/site-packages/rq/job.py", line 599, in perform
self._result = self._execute()
File "/home/tester/.local/lib/python3.6/site-packages/rq/job.py", line 605, in _execute
return self.func(*self.args, **self.kwargs)
File "./worker.py", line 7, in do_work
assert False
AssertionError
15. Opětovné spuštění zhavarovaných úloh
Po opravě workera (spuštění workera bez chyb atd.) můžeme všechny úlohy, které zhavarovaly, znovu spustit, a to následujícím způsobem:
$ rq requeue --all Requeueing 1 jobs from failed queue [####################################] 100%
16. Využití burst režimu workerů
V případě potřeby je možné workery (či jen jednoho vybraného workera) spustit v takzvaném burst režimu. Worker pracující v tomto režimu se pokusí zpracovat všechny úlohy ze specifikované fronty (front) a následně se ukončí. Jedná se tedy o koncept dávkového zpracování (když například do systému přidáme výkonný stroj ve chvíli, kdy je nutné dokončit nějaké úlohy, ovšem tento stroj se nemá stát součástí „clusteru“):
$ rq worker --burst high low default
Pokud žádné úlohy na workera nečekají, je ihned ukončen; viz poslední vypsaná zpráva:
16:49:32 RQ worker 'rq:worker:localhost.30308' started, version 0.12.0 16:49:32 *** Listening on default, low, high... 16:49:32 Cleaning registries for queue: default 16:49:32 Cleaning registries for queue: low 16:49:32 Cleaning registries for queue: high 16:49:32 RQ worker 'rq:worker:localhost.30308' done, quitting
17. Jednoduchá aplikace (dashboard) pro sledování stavu front i workerů
Na adrese rq-dashboard najdeme užitečnou aplikaci sloužící pro sledování stavu front i workerů v systému RQ. Jde o jednoduchou utilitu (typu dashboard) naprogramovanou v Pythonu a využívající knihovnu Flask pro tvorbu webových aplikací.
Samotná instalace dashboardu se provádí stejným způsobem, jako instalace jakéhokoli jiného Pythonovského balíčku. Podobně jako ve druhé kapitole i nyní provedeme instalaci pouze pro aktuálně přihlášeného uživatele příkazem pip3 install –user:
$ pip3 install --user rq-dashboard
Collecting rq-dashboard
Downloading https://files.pythonhosted.org/packages/ac/7b/e86764f563744d4244bb52eda4b09bff7ba78e9f97fdf3e5ad006d165ec0/rq-dashboard-0.3.12.tar.gz (95kB)
100% |████████████████████████████████| 102kB 1.0MB/s
Requirement already satisfied: rq>=0.3.8 in ./.local/lib/python3.6/site-packages (from rq-dashboard)
Requirement already satisfied: Flask in ./.local/lib/python3.6/site-packages (from rq-dashboard)
Requirement already satisfied: redis in ./.local/lib/python3.6/site-packages (from rq-dashboard)
Collecting arrow (from rq-dashboard)
Downloading https://files.pythonhosted.org/packages/e0/86/4eb5228a43042e9a80fe8c84093a8a36f5db34a3767ebd5e1e7729864e7b/arrow-0.12.1.tar.gz (65kB)
100% |████████████████████████████████| 71kB 2.4MB/s
Requirement already satisfied: click>=5.0 in ./.local/lib/python3.6/site-packages (from rq>=0.3.8->rq-dashboard)
Requirement already satisfied: Jinja2>=2.4 in ./.local/lib/python3.6/site-packages (from Flask->rq-dashboard)
Requirement already satisfied: itsdangerous>=0.21 in ./.local/lib/python3.6/site-packages (from Flask->rq-dashboard)
Requirement already satisfied: Werkzeug>=0.7 in ./.local/lib/python3.6/site-packages (from Flask->rq-dashboard)
Requirement already satisfied: python-dateutil in ./.local/lib/python3.6/site-packages (from arrow->rq-dashboard)
Requirement already satisfied: MarkupSafe>=0.23 in ./.local/lib/python3.6/site-packages (from Jinja2>=2.4->Flask->rq-dashboard)
Requirement already satisfied: six>=1.5 in /usr/lib/python3.6/site-packages (from python-dateutil->arrow->rq-dashboard)
Installing collected packages: arrow, rq-dashboard
Running setup.py install for arrow ... done
Running setup.py install for rq-dashboard ... done
Successfully installed arrow-0.12.1 rq-dashboard-0.3.12
Po úspěšné (alespoň doufejme) instalaci se dashboard spustí příkazem rq-dashboard:
$ rq-dashboard RQ Dashboard version 0.3.12 * Running on http://0.0.0.0:9181/ (Press CTRL+C to quit) ... ... ...
Povšimněte si adresy, na které je dashboard dostupný. Pokud tuto adresu (včetně portu!) zadáte do webového prohlížeče s podporou JavaScriptu, dashboard se zobrazí a je s ním možné provádět základní operace s frontami.
18. Základní operace prováděné na dashboardu
Zdlouhavý popis dashboardu a jeho funkcí je pravděpodobně zbytečný, protože je vše dobře patrné z následujících screenshotů:
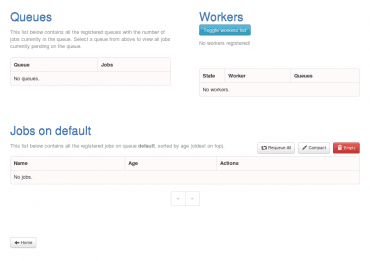
Obrázek 4: Takto vypadá dashboard ve chvíli, kdy systém RQ neobsahuje žádné fronty a nejsou k němu připojeni ani žádní workeři.
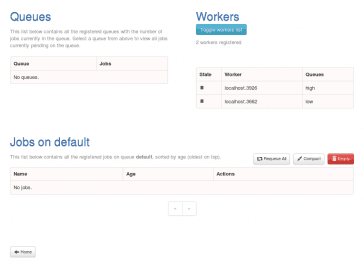
Obrázek 5: Zobrazení dvou workerů, přičemž první z nich přebírá úlohy z fronty pojmenované „high“ a druhý z fronty „low“. Workeři jsou ve stavu „idle“.
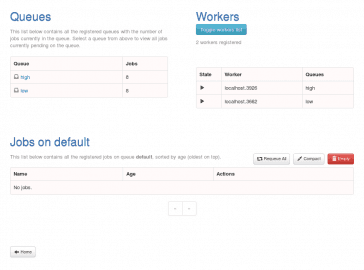
Obrázek 6: Do front „high“ i „low“ byly přidány úlohy, workeři je začali zpracovávat.

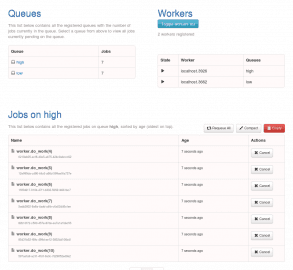
Obrázek 7: Zobrazení všech úloh, které jsou v dané chvíli ve frontě „high“.
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů naprogramovaných v Pythonu byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/message-queues-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:
20. Odkazy na Internetu
- Databáze Redis (nejenom) pro vývojáře používající Python
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python/ - Databáze Redis (nejenom) pro vývojáře používající Python (dokončení)
https://www.root.cz/clanky/databaze-redis-nejenom-pro-vyvojare-pouzivajici-python-dokonceni/ - Redis Queue (RQ)
https://www.fullstackpython.com/redis-queue-rq.html - Full Stack Python: web development
https://www.fullstackpython.com/web-development.html - Introducing RQ
https://nvie.com/posts/introducing-rq/ - Asynchronous Tasks with Flask and Redis Queue
https://testdriven.io/asynchronous-tasks-with-flask-and-redis-queue - rq-dashboard
https://github.com/eoranged/rq-dashboard - Stránky projektu Redis
https://redis.io/ - Introduction to Redis
https://redis.io/topics/introduction - Try Redis
http://try.redis.io/ - Redis tutorial, April 2010 (starší, ale pěkně udělaný)
https://static.simonwillison.net/static/2010/redis-tutorial/ - Python Redis
https://redislabs.com/lp/python-redis/ - Redis: key-value databáze v paměti i na disku
https://www.zdrojak.cz/clanky/redis-key-value-databaze-v-pameti-i-na-disku/ - Praktický úvod do Redis (1): vaše distribuovaná NoSQL cache
http://www.cloudsvet.cz/?p=253 - Praktický úvod do Redis (2): transakce
http://www.cloudsvet.cz/?p=256 - Praktický úvod do Redis (3): cluster
http://www.cloudsvet.cz/?p=258 - Connection pool
https://en.wikipedia.org/wiki/Connection_pool - Instant Redis Sentinel Setup
https://github.com/ServiceStack/redis-config - How to install REDIS in LInux
https://linuxtechlab.com/how-install-redis-server-linux/ - Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format - Lempel–Ziv–Welch
https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Welch - Redis Persistence
https://redis.io/topics/persistence - Redis persistence demystified
http://oldblog.antirez.com/post/redis-persistence-demystified.html - Redis reliable queues with Lua scripting
http://oldblog.antirez.com/post/250 - Ost (knihovna)
https://github.com/soveran/ost - NoSQL
https://en.wikipedia.org/wiki/NoSQL - Shard (database architecture)
https://en.wikipedia.org/wiki/Shard_%28database_architecture%29 - What is sharding and why is it important?
https://stackoverflow.com/questions/992988/what-is-sharding-and-why-is-it-important - What Is Sharding?
https://btcmanager.com/what-sharding/ - Redis clients
https://redis.io/clients - Category:Lua-scriptable software
https://en.wikipedia.org/wiki/Category:Lua-scriptable_software - Seriál Programovací jazyk Lua
https://www.root.cz/serialy/programovaci-jazyk-lua/ - Redis memory usage
http://nosql.mypopescu.com/post/1010844204/redis-memory-usage - Ukázka konfigurace Redisu pro lokální testování
https://github.com/tisnik/presentations/blob/master/redis/redis.conf - Resque
https://github.com/resque/resque - Nested transaction
https://en.wikipedia.org/wiki/Nested_transaction - Publish–subscribe pattern
https://en.wikipedia.org/wiki/Publish%E2%80%93subscribe_pattern - Messaging pattern
https://en.wikipedia.org/wiki/Messaging_pattern - Using pipelining to speedup Redis queries
https://redis.io/topics/pipelining - Pub/Sub
https://redis.io/topics/pubsub - ZeroMQ distributed messaging
http://zeromq.org/ - ZeroMQ: Modern & Fast Networking Stack
https://www.igvita.com/2010/09/03/zeromq-modern-fast-networking-stack/ - Publish/Subscribe paradigm: Why must message classes not know about their subscribers?
https://stackoverflow.com/questions/2908872/publish-subscribe-paradigm-why-must-message-classes-not-know-about-their-subscr - Python & Redis PUB/SUB
https://medium.com/@johngrant/python-redis-pub-sub-6e26b483b3f7 - Message broker
https://en.wikipedia.org/wiki/Message_broker - RESP Arrays
https://redis.io/topics/protocol#array-reply - Redis Protocol specification
https://redis.io/topics/protocol - Redis Pub/Sub: Intro Guide
https://www.redisgreen.net/blog/pubsub-intro/ - Redis Pub/Sub: Howto Guide
https://www.redisgreen.net/blog/pubsub-howto/ - Comparing Publish-Subscribe Messaging and Message Queuing
https://dzone.com/articles/comparing-publish-subscribe-messaging-and-message - Apache Kafka
https://kafka.apache.org/ - Iron
http://www.iron.io/mq - kue (založeno na Redisu, určeno pro node.js)
https://github.com/Automattic/kue - Cloud Pub/Sub
https://cloud.google.com/pubsub/ - Introduction to Redis Streams
https://redis.io/topics/streams-intro - glob (programming)
https://en.wikipedia.org/wiki/Glob_(programming) - Why and how Pricing Assistant migrated from Celery to RQ – Paris.py
https://www.slideshare.net/sylvinus/why-and-how-pricing-assistant-migrated-from-celery-to-rq-parispy-2 - Enqueueing internals
http://python-rq.org/contrib/ - queue — A synchronized queue class
https://docs.python.org/3/library/queue.html - Queues
http://queues.io/ - Windows Subsystem for Linux Documentation
https://docs.microsoft.com/en-us/windows/wsl/about - RestMQ
http://restmq.com/ - ActiveMQ
http://activemq.apache.org/ - Amazon MQ
https://aws.amazon.com/amazon-mq/ - Amazon Simple Queue Service
https://aws.amazon.com/sqs/ - Celery: Distributed Task Queue
http://www.celeryproject.org/ - Disque, an in-memory, distributed job queue
https://github.com/antirez/disque - rq-dashboard
https://github.com/eoranged/rq-dashboard - Projekt RQ na PyPi
https://pypi.org/project/rq/ - rq-dashboard 0.3.12
https://pypi.org/project/rq-dashboard/ - Job queue
https://en.wikipedia.org/wiki/Job_queue - Why we moved from Celery to RQ
https://frappe.io/blog/technology/why-we-moved-from-celery-to-rq


































