
Scrapy je robustní webová Python knihovna pro dolování dat z různých zdrojů. Z vysokoúrovňového pohledu Scrapy exceluje obzvláště při dvou případech užití:
- Když běžný uživatel webu požaduje stáhnout určitá data ze stránky, kterou zrovna prohlíží a libovolně data formátovat. Například je uložit ve formátu JSON nebo CSV či je uložit do databáze za účelem offline prohlížení nebo provedení dalších výpočtů.
- Pokud si uživatel přeje kombinovat data z různých zdrojů a extrahovat je.
S knihovnou Scrapy jsme schopni při jedné konfiguraci provést úlohy, na které bychom s jinými nástroji nebo knihovnami potřebovali mnoho tříd, rozšíření a konfigurací. Z pohledu programátora stojí za zmínku event-based architektura. Ta umožňuje vytvářet kaskády operací, které můžou čistit, formátovat, obohacovat nebo data ukládat například do databáze, přičemž nezaznamenáme žádnou degradaci výkonu.
Technicky řečeno, touto architekturou se Scrapy dokáže zbavit přílišné latence, kterou generuje síť, zpracování dat nebo databáze, zatímco pracuje s tisíci otevřenými spojeními. Jako extrémní příklad můžeme zvolit extrahování například nadpisů z webové stránky, která má sumarizující stránku se stovkou nadpisů v každém odkazu. Scrapy ve výchozí konfiguraci provádí 16 dotazů na webový server paralelně.
Pokud by jeden dotaz čekal na dokončení sekundu, stahoval by 16 stránek za sekundu, čili by generoval 1600 nadpisů za sekundu. Scénář může pokračovat tak, že po stažení a extrahování nadpisu jej chceme uložit do cloudového úložiště, které má velmi špatnou odezvu, téměř 3 sekundy. Za předpokladu, že má být udržena rychlost stahování 16 stránek za sekundu, musíme generovat 4800 paralelních zápisů do databáze (1600×3).
Pro klasickou vícevláknovou aplikaci by to znamenalo alokovat a obsluhovat paralelně 4800 vláken, což by mohlo být pro operační systém zničující, nehledě na to, že by to bylo velmi nevýkonné. Ve světě aplikací Scrapy je ovšem 4800 dotazů do databáze za sekundu naprosto běžnou praxí, nehledě na nároky na paměť, které mají složitost O(n), kde n je počet nadpisů. Oproti tomu vícevláknová architektura alokuje ke každému vytvořenému vláknu signifikantní množství paměti.
Ve zkratce, pomalé nebo nepředvídatelné webové servery, databáze nebo jiné API třetích stran nebudou mít devastující efekt na výkon programu se Scrapy, jelikož provádí paralelně mnoho dotazů a všechny interní operace řídí z jednoho vlákna. To přináší další výhodu, pokud hodláme vedle programu se Scrapy vykonávat další programy na stejném systému. Dále není zapotřebí žádná synchronizace v kódu, tudíž jde o značné zjednodušení celé aplikace oproti vícevláknovým aplikacím.
Od první verze Scrapy uběhla již dekáda, komunitou je dobře otestovaný a použitý v mnoha projektech pro dolování dat z webů. Mezi jeho další přednosti patří:
- práce s poškozenými HTML soubory, Scrapy se dokáže vypořádat se syntaktickými chybami a soubor zpracovat,
- nativní podpora Beautiful Soup, XPath a CSS selektorů,
- Scrapy má rozsáhlou komunitu uživatelů,
- dobře organizovaný a udržovaný kód komunitou,
- stále stoupající počet nových vlastností se soustředěním na kvalitu.
Obecná architektura web crawleru
V této sekci bude vržen detailní pohled na problematiku sběru dat z webových stránek ( web crawling/scraping). Nejprve bude na prototypu webového crawleru vysvětlen princip procházení webových stránek.
Takový typický crawler se skládá z několika procesů, které mohou běžet souběžně na totožném systému nebo i na rozdílných systémech dosažitelných po síti. Každý z těchto procesů se dále skládá z několika pracovních vláken (u architektury Scrapy bude vysvětleno, že v realitě se proces dále nedělí na pracovní vlákna, protože samotné procesy pracují asynchronně a vlákna tudíž nejsou zapotřebí a jen by degradovala výkon), kdy každé z těchto vláken opakovaně vykonává pracovní cyklus.
Na začátku každého cyklu vlákno obdrží URL adresu z datové struktury, kterou generuje poslední část cyklu. Tato část řadí URL adresy podle priority a dalších libovolně definovaných pravidel. Vlákno poté invokuje HTTP klienta, který je zodpovědný za stažení obsahu webové stránky. Nejprve je ovšem proveden dotaz na DNS server, aby HTTP klient věděl, s jakou IP adresou má iniciovat spojení. Ještě před stažením stránky se považuje za korektní chování stáhnout soubor robots.txt, který obsahuje pravidla, kterými by se měl správný webový crawler řídit při následném procházení webu.
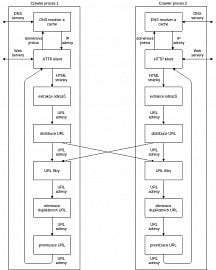
Obecný web crawler
V případě kladného scénáře, kdy stažení stránky uspěje, může být tato stránka uložena do uložiště stažených stránek, aby se předešlo opětovnému stažení totožné stránky. Poté je tato stránka předána modulu, který zajišťuje extrakci odkazů. Jeho práce spočívá v hledání odkazů, které vedou na další stránky daného webu. Jeho vstupem jsou HTML data a výstupem je poté množina hyperlinků (odkazů). Ty jsou poté předány modulu pro distribuci těchto odkazů, který se snaží rovnoměrně rozdělit odkazy mezi všechna pracující vlákna. Tato distribuce může probíhat na základě hašování URL adres, doménových jmen nebo IP adres.
Následně každé z vláken použije modul na filtraci odkazů. Mezi nejběžnější filtry patří například black-list (všechny adresy nalezené na této černé listině jsou zahozeny) nebo kontrola na specifické přípony souborů, které pro dané vlákno nejsou zajímavé. Odkazy, které projdou tímto modulem jsou následně zpracovány v další části starající se o kontrolu duplicit. Tento modul si uchovává všechny stažené adresy a pokud by měla být stažena adresa nacházející se v množině známých adres, bude tato adresa zahozena a propuštěny budou jen ty adresy, které modul vidí poprvé. Výsledné adresy jsou předány modulu, který vytvoří datovou strukturu, do které umístí URL adresy podle priority. Pravidla pro určení priority mohou být opět různá, například může být aplikován regulární výraz, slovník nebo se použije přípona souboru.
Každý moderní webový crawler obsahuje dvě hlavní datové struktury – první datová struktura slouží pro udržování množiny URL adres, které již byly objeveny (mohly a nemusely být staženy) a druhá datová struktura je pouze pro ty adresy, které budou teprve staženy. První struktura (známá jako URL-seen test nebo duplicated URL
eliminator) musí podporovat operace přidání prvku do množiny a kontrolu přítomnosti prvku, zatímco druhá struktura (známá jako frontier) musí podporovat přidání prvku do množiny a selekci prvku (prvkem je zde myšlena konkrétní URL), který se předá HTTP klientovi.
Architektura knihovny Scrapy
Architektura Scrapy je už poněkud konkrétnější a složitější než obecná architektura, ačkoli z ní vychází a následuje její architektonické prvky. Nyní bude konkrétně popsána architektura Scrapy.
Lze si povšimnout tří podobných typů objektů, nad kterými Scrapy operuje – dotazy, odpovědi a prvky. Všichni uživatelští pavouci, které musí uživatel definovat jsou jádrem celé architektury. Pavouci vytváří dotazy, zpracovávají odpovědi a poté generují jednotlivé prvky a další dotazy. Prvek v tomto kontextu představuje libovolnou proměnnou vytvořenou v rámci činnosti pavouka. Každý z prvků, které jsou pavoukem vygenerovány, jsou následně zpracovány sekvencí potrubí (potrubí si lze v tomto kontextu představit jako posloupnost funkcí nebo operací, kdy každá z těchto funkcí přijímá prvek jakožto parametr) použitím metody process_item. Typicky tato metoda nějakým způsobem modifikuje vstupní prvek a posílá jej dále k další funkci v potrubí jednoduše tím, že je prvek použit jako návratová hodnota metody. Příležitostně (například při detekci duplikátního prvku) je požadované chování zahození prvku, což je provedeno výjimkou DropItem. V takovém případě další části potrubí tento prvek nedostanou a tudíž je zastaveno následující zpracování.
Jestliže uživatel definuje metody open_spider a close_spider, budou tyto metody automaticky invokovány při spuštění pavouka, respektive při jeho ukončení. To je ideální příležitost k provedení prerekvizit a k inicializaci externích subjektů (například databáze nebo logovací systémy), popřípadě v konečné fázi k úklidu. Potrubí pro prvky je typicky použito v rámci domény architektury aplikace, například čištění určitých dat nebo častěji vkládání dat do databází. Velká výhoda architektury Scrapy je modulárnost – každý pavouk nebo každá část potrubí může být využita napříč různými projekty.
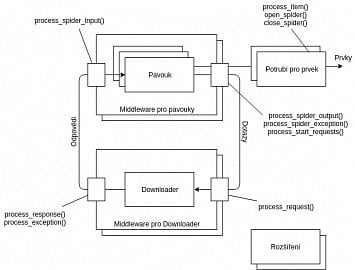
Architektura Scrapy
Typicky jsou z pavouků zasílány dotazy a zpátky jsou do pavouka posílány odpovědi (dotazem a odpovědí je zde myšlen HTTP dotaz a následná HTTP odpověď). Scrapy se automaticky stará o cookies, autentizaci (zde je situace komplikovanější, jelikož musí uživatel naprogramovat chování autentizace, které už Scrapy dokáže automaticky provádět) nebo například cachování. Všechny tyto operace Scrapy zpracovává zcela transparentně, lze tedy jednoduše přidat další vlastnosti, chování nebo modifikovat stávající způsob zpracování. Největší část z této funkcionality je implementována ve formě middleware pro downloadery.
Většinou s těmito moduly běžný uživatel nepřijde do styku, jelikož tyto části Scrapy už jsou sofistikovanější a s technickými detaily implementuje internosti dotazů a odpovědí. Je samozřejmě možné nepoužívat již existující implementaci a pokud se uživatel domnívá, že dokáže tuto funkcionalitu implementovat lépe, popřípadě požaduje jiné chování při stahování webových stránek, je zde prostor pro vlastní implementaci. Typické znaky úspěšného middlewaru spočívají v jeho znovupoužitelnosti v mnoha Scrapy projektech, aby takový middleware mohl být sdílen v komunitě Scrapy programátorů. Hierarchie standardních middlewarů lze vidět na schématu.
Downloader je systém, který provádí skutečnou operaci stahování webových stránek. Tuto část uživatel nebude pravděpodobně nikdy modifikovat (možná jen v případě, kdyby byl spolutvůrce a přispíval by do Scrapy jakožto open-source projektu). Jiná situace je ovšem na poli middlewarů pro pavouky. Jak lze vidět na architektuře Scrapy, ty zpracovávají dotazy po tom, co je zpracuje samotný pavouk a těsně před tím, než je obdrží middleware pro downloader. S middlewarem pro downloader může uživatel například přepsat všechny URL adresy tak, aby používaly HTTPS zabezpečený protokol nehledě na tom, jaké adresy pavouk extrahuje ze stažených stránek.
Takový middleware implementuje funkcionalitu, která je specifická pouze pro daný uživatelský projekt, ale je sdílený skrze všechny pavouky v tomto projektu. Hlavní rozdíl mezi middlewarem pro pavouky a pro downloader je to, že když middleware pro downloader dostane dotaz, měl by v ideálním případě vždy vrátit odpověď. Oproti tomu, pokud middleware pro pavouky zahodí z nějakého důvodu dotaz, ničemu to nevadí – je to naprosto validní chování. Například může nastat situace, kdy pro každý dotaz, který vyjde z pavouka vytvoříme duplikáty, které mírně modifikujeme, pokud takové chování splňuje formální požadavky platformy. Dalo by se říci, že middleware pro pavouky je pro dotazy a odpovědi tím, čím je potrubí pro generované prvky. Rovněž tento middleware obdrží generované prvky, ale obvyklé chování je takové, že s nimi nejsou prováděny žádné operace a nechají se bez jakýchkoli modifikací vplout do potrubí, jelikož tam se operace nad prvky provádějí mnohem snadněji.

Posledním prvkem z architektury Scrapy je modul pro rozšíření. Rozšíření jsou ve světě Scrapy velmi používaná – skoro by se dalo říci, že stejně jako potrubí. Jedná se o čisté třídy původně bez atribut a metod, které jsou načteny při spuštění jádra Scrapy a které mají přístup k celé konfiguraci, ke crawleru, k registru funkcí přiřazených k signálům a je zde možnost rovněž definovat své vlastní signály. Signály jsou považovány za holý základ systému Scrapy, které umožňují invokaci určitých funkcí, když nastane v systému specifická událost (například když je získán prvek z pavouka, popřípadě zahození prvku nebo událost spuštění samotného pavouka).
Samozřejmě Scrapy obsahuje mnoho předdefinovaných signálů, kterým už jen stačí redefinovat funkci, která se v případě zachycení signálu invokuje. Rozšíření se dá vnímat jako specifické místo pro uživatele, kde si může nadefinovat libovolné chování bez ohledu na zbytek systému, ovšem bez jakékoli pomoci ze strany Scrapy. Uživatel musí kromě definování nové funkcionality namapovat tuto funkci na nějaký signál (například zastavení činnosti pavouka po získání daného počtu prvků).
V podstatě se Scrapy chová ke všem třídám jako k middlewarům, čímž je zajištěn čistě modulární systém. Třída, která řídí celou množinu middlewarů se nazývá MiddlewareManager a umožňuje inicializaci všech ostatních middlewarů skrze objekt Crawler nebo Settings implementací metody from_crawler, respektive from_settings. Ačkoli lze objekt s konfigurací získat skze třídu Crawler(crawler.settings), mnohem populárnější přístup je použít metodu from_crawler. Mimojiné platí zásada (spíše související s doménou čistého kódu), že pokud není potřeba Crawler nebo Settings, neimplementujeme je.
Jelikož je Scrapy plně modulární a má k dispozici mnoho funkcí, může s ním být v případě nedostatku informací nevhodně manipulováno. Proto je v následující tabulce přehledně uvedeno, na který problém je vhodné jaké řešení.
| Problém | Řešení |
|---|---|
| Něco, co je specifické pro danou webovou stránku, která má být zpracovávána. | Modifikace pavouka. |
| Modifikace nebo uložení prvku – specifikum pro danou doménu, které může být použito napříč všemi projekty. | Vytvoření potrubí pro prvky. |
| Modifikace nebo zahození dotazu/odpovědi – specifikum pro danou doménu, které může být použito napříč všemi projekty. | Vytvoření middlewaru pro pavouka. |
| Provedení samotného dotazu a zpracování odpovědi – generický problém, například pro podporu konkrétního mechanismu pro autentizaci nebo specifický způsob práce s cookies. | Vytvoření middlewaru pro downloader. |
| Ostatní problémy. | Vytvoření rozšíření. |
Možnosti konfigurace a managementu
Scrapy přichází s velkou funkcionalitou a nástroji, které jsou dostupné skrze konfiguraci. Ta hraje v softwaru obecně velmi důležitou roli, jelikož je to možnost, jak jednoduše měnit chování aplikace a ladit ji. Scrapy není výjimkou a do konfiguračních souborů vkládá velké možnosti, jak měnit chování celého systému a skrze konfigurace umožňuje jeho rozšiřování. Nebudou zde vypsány všechny konfigurační možnosti (k tomu slouží oficiální dokumentace), namísto toho bude vysvětlena úloha, princip a obecně důležitost konfigurace v systémech založených na Scrapy.
Ve Scrapy existuje několik konfiguračních úrovní se zvyšující se prioritou. První úroveň spočívá v původní konfiguraci Scrapy ( scrapy/settings/default_settings.py), která se nachází přímo ve zdrojovém kódu knihovny. Tento konfigurační soubor s největší pravděpodobností uživatel nikdy měnit nebude, je ovšem důležité si uvědomit, kde jsou definovány příkazy používané z příkazové řádky. Tato konfigurace zajišťuje správnou funkčnost příkazů na úrovni příkazové řádky, takže je zajímavá pouze pro ty zkušené uživatele, kteří chtějí přidat svůj vlastní příkaz nebo pozměnit stávající chování nějakého existujícího. Mnohem častěji je užitečnější modifikovat konfiguraci specifickou pro celý projekt ( project_name/settings.py).
Tahle konfigurace je platná pouze pro aktivní projekt a neovlivní jiné projekty v rámci fungování Scrapy, na rozdíl od prvního zmíněného typu konfigurace. Tato úroveň je nejpohodlnější, jelikož soubor settings.py je zabalen do projektu a spolu s ním tedy i nasazován do produkčního prostředí. Další úroveň konfigurace je pouze na úrovni pavouků. Tento typ konfigurace uživateli umožní například zapínat/vypínat určité části potrubí, skze které putují prvky nebo konfigurovat parametry přímo pro pavouka (například počet stránek, které se mají stáhnout, úroveň zanoření pavouka, stránka, na které má pavouk začít a mnoho dalších, viz. oficální dokumentace). Poslední, nejsilnější úroveň, spočívá v zadávání konfiguračních parametrů přímo na příkazové řádce, čímž se přepíšou všechny ostatní konfigurace v konfiguračních souborech.
Scrapy má velké množství konfiguračních kategorií. V diagramu jsou ukázány všechny tyto kategorie s malou ukázkou konkrétních konfiguračních parametrů.

Konfigurace Scrapy
V kategorii analýza lze nakonfigurovat ladicí informace skrze logovací soubory, statistiky nebo možnost připojit se na běžícího pavouka pomocí nástroje telnet. Kategorie výkon umožňuje uzpůsobit výkonnostní charakteristiky různým situacím. Můžeme nakonfigurovat například počet paralelních dotazů, počet paralelních dotazů na jednu doménu, IP adresu nebo počet paralelně generovaných prvků ze stránek vstupujících do potrubí. Tyto vlastnosti chrání vzdálený server poskytující webovou službu před nadbytečnou zátěží, která v mnoha případech není zapotřebí. Kategorie stylu procházení pavouka umožňuje volbu například toho, která stránka se získá jako první nebo definovat maximální hloubku zanoření. Pokud by například uživatel vyžadoval procházení webů algoritmem BFS (Breadth-first search), zvolí hloubku zanoření na kladnou hodnotu (nula značí žádný limit) a jako frontu pro plánovač vybere FIFO (First in, first out).
Nastavení z kategorie proxy je povolena automaticky a využívá proměnných prostředí systému podle konvence Unix (http_proxy ,https_proxy a no_proxy ). Kategorie ukončení umožňuje zastavit činnost pavouka po splnění specifických podmínek definovaných právě v této kategorii. Uživatel může nakonfigurovat například ukončení pavouka po nějakém časovém úseku, po získání určitého počtu prvků, chyb při zpracování nebo po obdržení daného počtu HTTP odpovědí z webu. Poslední kategorie HTTP cache poskytuje konfiguraci pro cachování HTTP dotazů a odpovědí. Můžeme například nastavit chování podle pravidel uvedených v RFC2616 použitímscrapy.contrib.httpcache.RFC2616Policy jakožto hodnotu pro parametr HTTP_CACHE_POLICY} .
Praktická ukázka
Vyzkoušíme si Scrapy například na sběru dat ze skvělého serveru seznam.cz, který je perfektní pro testování skriptů/programů všeho druhu. Zkusíme si posbírat názvy filmů z televizního programu a seznam měst, která má seznam.cz ve své databázi pro přehled o počasí.
Kroky, jak připravit prostředí pro programování v Pythonu má každý bezpochyby automatizované, přesto bude postup představen od základů.
$ mkdir scrapy-test $ cd scrapy-test/ $ python3 -m venv venv $ source venv/bin/activate $ python -m pip install scrapy
Teď, když máme vytvořené prostředí a nainstalovaný Scrapy, můžeme využít jeho cmd nástrojů pro tvorbu projektu.
$ scrapy startproject project_seznamcz $ cd project_seznamcz $ scrapy genspider seznam seznam.cz
Výsledkem předchozích příkazů je vytvořená struktura projektu i s pavoukem, který slouží jako vzor pro začátek. Pro praktickou ukázku nám postačí modifikace čtyř souborů:
- scrapy-test/project_seznamcz/project_seznamcz/spiders/seznam.py
- scrapy-test/project_seznamcz/project_seznamcz/items.py
- scrapy-test/project_seznamcz/project_seznamcz/pipelines.py
- scrapy-test/project_seznamcz/project_seznamcz/settings.py
Logika webového crawleru je v pavouku. Bude uvedena jednoduchá implementace, kdy vytvoříme dvě pravidla. Každé z pravidel bude prohledávat web samostatně a každé má rovněž svoji funkci, která stojí za vytvořením prvků a následným zasláním to potrubí. Pro vyhledání názvu filmů/měst z počasí jsou použity CSS selektory. Pokud se vám nechce vymýšlet dokonalý CSS selektor (Scrapy umí rovněž XPath), Google Chrome je umí vygenerovat. V ukázce si ještě vytvoříme prvky, které ponesou metainformace jako například URL právě analyzované stránky, název projektu nebo datum.
import datetime
import socket
from scrapy.spiders import CrawlSpider
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.loader import ItemLoader
from project_seznamcz.items import ProjectSeznamczItem
class SeznamSpider(CrawlSpider):
name = 'seznam'
allowed_domains = ['seznam.cz']
start_urls = ['https://www.seznam.cz']
rules = (
Rule(LinkExtractor(allow='tv.seznam.cz'), callback='parse_seznam_tv', follow=True),
Rule(LinkExtractor(allow='pocasi.seznam.cz'), callback='parse_seznam_pocasi', follow=True),
)
def parse_seznam_tv(self, response):
loader = ItemLoader(item=ProjectSeznamczItem(), response=response)
self.fill_fields(loader, response)
loader.add_css('titles', '.sheet-tv-programme-title > a')
return loader.load_item()
def parse_seznam_pocasi(self, response):
loader = ItemLoader(item=ProjectSeznamczItem(), response=response)
self.fill_fields(loader, response)
loader.add_css('cities', '#title-loc')
return loader.load_item()
def fill_fields(self, loader, response):
loader.add_value('url', response.url)
loader.add_value('date', datetime.datetime.now().isoformat(' '))
loader.add_value('server', socket.gethostname())
loader.add_value('spider', self.name)
loader.add_value('project', self.settings.get('BOT_NAME'))
Aby měl pavouk kam ukládat informace, potřebuje mít prvky nejdříve definované. K tomu slouží items.py.
from scrapy import Item
from scrapy import Field
class ProjectSeznamczItem(Item):
url = Field()
date = Field()
server = Field()
spider = Field()
project = Field()
titles = Field()
cities = Field()
Teď pavouk analyzuje každou webovou stránku, která vyhovuje definovaným pravidlům a z těchto stránek získá požadované informace. Nyní bychom s těmi informacemi (a samozřejmě i metainformacemi) chtěli dělat další operace. Například uložit do paměťové databáze Redis, nebo zaslat do fronty RabbitMQ, popřípadě uložit do SQL databáze. V ukázce pouze zalogujeme informaci, co za prvky jsme skutečně získali. V souboru pipelines.py vytvoříme definici potrubí.

class ProjectSeznamczPipeline:
def process_item(self, item, spider):
item_keys = item.keys()
if 'titles' in item_keys:
spider.logger.info('[PIPELINE] scraped titles')
elif 'cities' in item_keys:
spider.logger.info('[PIPELINE] scraped cities')
else:
spider.logger.info('[PIPELINE] scraped nothing')
return item
Zde je malý chyták. Aby byl modul s potrubím aktivní, musí se povolit v konfiguračním souboru settings.py. Stačí pouze odkomentovat ty správné řádky kódu.
ITEM_PIPELINES = {
'project_seznamcz.pipelines.ProjectSeznamczPipeline': 300,
}
Činnost pavouka si ověříme pomocí příkazu scrapy crawl seznam.






















 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU