
Obsah
1. Výpis struktury datového rámce, využití faktorů
2. Konstrukce datového rámce bez použití faktorů
3. Výpočet a výpis statistických informací o datovém rámci
4. Extrakce vybraných sloupců z datového rámce
5. Extrakce vybraných řádků z datového rámce
6. Přidání nového sloupce do datového rámce
7. Konverze datového rámce na matici
8. Datový rámec získaný z matice – jednoduchý kalendář
10. Sloupcový graf s hodnotami vyčtenými z datového rámce
11. Přidání popisku horizontální osy do grafu
12. Úprava stylu zobrazení grafu
13. Orientace popisků na horizontální ose
14. Přidání liniového grafu do grafu sloupcového
15. Specifikace rozsahu hodnot na vertikální ose
16. Pokus o vytvoření dvou skupin sloupců
17. Zobrazení sloupcového grafu se dvěma skupinami sloupců
19. Repositář s demonstračními příklady
1. Výpis struktury datového rámce, využití faktorů
Na předchozí článek o programovacím jazyku R dnes navážeme, protože si ukážeme některé další operace, které je možné provádět s datovými rámci. Nejprve se podíváme na funkci pojmenovanou str, která slouží pro výpis struktury objektu, tedy i datového rámce:
str package:utils R Documentation
Compactly Display the Structure of an Arbitrary R Object
Description:
Compactly display the internal *str*ucture of an R object, a
diagnostic function and an alternative to ‘summary’ (and to some
extent, ‘dput’). Ideally, only one line for each ‘basic’
structure is displayed. It is especially well suited to compactly
display the (abbreviated) contents of (possibly nested) lists.
The idea is to give reasonable output for *any* R object. It
calls ‘args’ for (non-primitive) function objects.
‘strOptions()’ is a convenience function for setting ‘options(str
= .)’, see the examples.
Usage:
str(object, ...)
## S3 method for class 'data.frame'
str(object, ...)
Vraťme se k demonstračnímu příkladu s datovým rámcem nesoucím informace o popularitě programovacích jazyků. Tento rámec vytvoříme systémem, který již známe z předchozího článku a následně si necháme vytisknout strukturu tohoto rámce funkcí str:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
print(str(languages))
Výsledek by mohl vypadat následovně:
'data.frame': 9 obs. of 4 variables: $ id : int 1 2 3 4 5 6 7 8 9 $ name : Factor w/ 9 levels "C","C#","C++",..: 1 4 7 3 2 9 5 6 8 $ usage : num 15.95 13.48 10.47 7.11 4.58 ... $ change: num 0.74 -3.18 0.59 1.48 1.18 0.83 0.41 0.62 1.33 NULL
Povšimněte si, že jména programovacích jazyků nejsou uložena formou běžných řetězců, ale takzvaných faktorů. Jedná se o datový typ používaný ve chvíli, kdy nějaký sloupec obsahuje množství opakujících se hodnot, například:
height <- c(132,151,162,139,166,147,122)
weight <- c(48,49,66,53,67,52,40)
gender <- c("male","male","female","female","male","female","male")
# Create the data frame.
input_data <- data.frame(height,weight,gender)
print(input_data)
S výsledkem:
height weight gender 1 132 48 male 2 151 49 male 3 162 66 female 4 139 53 female 5 166 67 male 6 147 52 female 7 122 40 male
Výpis faktorů v posledním sloupci:
print(input_data$gender)
S výsledkem:
Levels: female male
2. Konstrukce datového rámce bez použití faktorů
Faktory mohou být velmi užitečné v těch případech, ve kterých se textová (resp. přesněji řečeno řetězcová) data v nějakém sloupci opakují. To však není případ vektoru s programovacími jazyky, takže se pokusme převod řetězců na faktory při konstrukci datových rámců vypnout. Provede se to následujícím způsobem (viz zvýrazněný řádek):
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(languages)
Vytvořený datový rámec vypadá zdánlivě stejně, jako tomu bylo i v prvním demonstračním příkladu:
id name usage change 1 1 C 15.95 0.74 2 2 Java 13.48 -3.18 3 3 Python 10.47 0.59 4 4 C++ 7.11 1.48 5 5 C# 4.58 1.18 6 6 Visual Basic 4.12 0.83 7 7 JavaScript 2.54 0.41 8 8 PHP 2.49 0.62 9 9 R 2.37 1.33
Pokud si ovšem necháme vypsat jeho strukturu funkcí str, poznáme rozdíl:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(str(languages))
Ve struktuře je patrné, že jména programovacích jazyků jsou nyní reprezentována běžnými řetězci:
'data.frame': 9 obs. of 4 variables: $ id : int 1 2 3 4 5 6 7 8 9 $ name : chr "C" "Java" "Python" "C++" ... $ usage : num 15.95 13.48 10.47 7.11 4.58 ... $ change: num 0.74 -3.18 0.59 1.48 1.18 0.83 0.41 0.62 1.33 NULL
3. Výpočet a výpis statistických informací o datovém rámci
Další užitečnou funkcí, s níž se v dnešním článku seznámíme, je funkce nazvaná summary:
help(summary)
summary package:base R Documentation
Object Summaries
Description:
‘summary’ is a generic function used to produce result summaries
of the results of various model fitting functions. The function
invokes particular ‘methods’ which depend on the ‘class’ of the
first argument.
Usage:
summary(object, ...)
## Default S3 method:
summary(object, ..., digits)
## S3 method for class 'data.frame'
summary(object, maxsum = 7,
digits = max(3, getOption("digits")-3), ...)
## S3 method for class 'factor'
summary(object, maxsum = 100, ...)
## S3 method for class 'matrix'
summary(object, ...)
## S3 method for class 'summaryDefault'
format(x, digits = max(3L, getOption("digits") - 3L), ...)
## S3 method for class 'summaryDefault'
print(x, digits = max(3L, getOption("digits") - 3L), ...)
Tato funkce získá z datového rámce data uložená v jednotlivých sloupcích a vypočte z nich různé statistické informace:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(summary(languages))
Výsledek může vypadat následovně:
id name usage change Min. :1 Length:9 Min. : 2.370 Min. :-3.1800 1st Qu.:3 Class :character 1st Qu.: 2.540 1st Qu.: 0.5900 Median :5 Mode :character Median : 4.580 Median : 0.7400 Mean :5 Mean : 7.012 Mean : 0.4444 3rd Qu.:7 3rd Qu.:10.470 3rd Qu.: 1.1800 Max. :9 Max. :15.950 Max. : 1.4800
Popř. při použití faktorů ve sloupci se jmény programovacích jazyků:
id name usage change
Min. :1 C :1 Min. : 2.370 Min. :-3.1800
1st Qu.:3 C# :1 1st Qu.: 2.540 1st Qu.: 0.5900
Median :5 C++ :1 Median : 4.580 Median : 0.7400
Mean :5 Java :1 Mean : 7.012 Mean : 0.4444
3rd Qu.:7 JavaScript:1 3rd Qu.:10.470 3rd Qu.: 1.1800
Max. :9 PHP :1 Max. :15.950 Max. : 1.4800
(Other) :3
Užitečné jsou především statistické informace o numerických sloupcích, u nichž se získá minimum, maximum, průměr, medián a první a třetí kvartil (Q1 a Q3).
4. Extrakce vybraných sloupců z datového rámce
S datovými rámci je možné provádět i různé transformace, popř. extrakce (výběry) určitých dat. V dalším demonstračním příkladu je ukázáno, jak lze získat nový datový rámec, který však bude obsahovat pouze dva vybrané sloupce z rámce původního:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(data.frame(languages$name, languages$change))
Nový datový rámec bude mít skutečně pouze dva sloupce (a všech devět řádků):
languages.name languages.change 1 C 0.74 2 Java -3.18 3 Python 0.59 4 C++ 1.48 5 C# 1.18 6 Visual Basic 0.83 7 JavaScript 0.41 8 PHP 0.62 9 R 1.33
Alternativní příklad s jiným výběrem, který je kompatibilní s dalšími programovacími jazyky:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
d2 = data.frame(languages["name"], languages["usage"])
print(d2)
print(str(d2))
Výsledky:
name usage 1 C 15.95 2 Java 13.48 3 Python 10.47 4 C++ 7.11 5 C# 4.58 6 Visual Basic 4.12 7 JavaScript 2.54 8 PHP 2.49 9 R 2.37 'data.frame': 9 obs. of 2 variables: $ name : chr "C" "Java" "Python" "C++" ... $ usage: num 15.95 13.48 10.47 7.11 4.58 ... NULL
5. Extrakce vybraných řádků z datového rámce
Podobně jako jsme vybrali sloupce můžeme z datového rámce vybírat i řádky. Nejjednodušší je situace ve chvíli, kdy řádky tvoří posloupnost:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(languages[7:9,])
V tomto případě skutečně došlo k výběru řádků 7, 8 a 9 z většího datového rámce:
id name usage change 7 7 JavaScript 2.54 0.41 8 8 PHP 2.49 0.62 9 9 R 2.37 1.33
Nic nám ovšem nebrání v nahodilém výběru řádků, což je ukázáno na dalším demonstračním příkladu:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(languages[c(1, 3, 9),])
S tímto výsledkem:
id name usage change 1 1 C 15.95 0.74 3 3 Python 10.47 0.59 9 9 R 2.37 1.33
Kombinovat můžeme výběr řádků i sloupců, což je vlastně stejný postup, jaký známe při práci s maticemi:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(languages[c(1, 3, 9), c(2, 4)])
Nyní budou výsledky vypadat následovně:
name change 1 C 0.74 3 Python 0.59 9 R 1.33
6. Přidání nového sloupce do datového rámce
Do datového rámce můžeme přidat nový sloupec způsobem, který je ukázán v následujícím demonstračním příkladu. Nejprve zkonstruujeme datový rámec pouze se třemi sloupci a následně přidáme sloupec čtvrtý:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37)
)
print(languages)
languages$change <- c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
print("------------------------------------")
print(languages)
Po spuštění příkladu se zobrazí jak původní rámec s pouhými třemi sloupci, tak i rámec rozšířený o další sloupec:
id name usage 1 1 C 15.95 2 2 Java 13.48 3 3 Python 10.47 4 4 C++ 7.11 5 5 C# 4.58 6 6 Visual Basic 4.12 7 7 JavaScript 2.54 8 8 PHP 2.49 9 9 R 2.37 [1] "------------------------------------" id name usage change 1 1 C 15.95 0.74 2 2 Java 13.48 -3.18 3 3 Python 10.47 0.59 4 4 C++ 7.11 1.48 5 5 C# 4.58 1.18 6 6 Visual Basic 4.12 0.83 7 7 JavaScript 2.54 0.41 8 8 PHP 2.49 0.62 9 9 R 2.37 1.33
Alternativní způsob zápisu známý z jiných programovacích jazyků je taktéž možný a podporovaný:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37)
)
print(languages)
languages["change"] <- c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
print("------------------------------------")
print(languages)
Výsledky:
id name usage 1 1 C 15.95 2 2 Java 13.48 3 3 Python 10.47 4 4 C++ 7.11 5 5 C# 4.58 6 6 Visual Basic 4.12 7 7 JavaScript 2.54 8 8 PHP 2.49 9 9 R 2.37 [1] "------------------------------------" id name usage change 1 1 C 15.95 0.74 2 2 Java 13.48 -3.18 3 3 Python 10.47 0.59 4 4 C++ 7.11 1.48 5 5 C# 4.58 1.18 6 6 Visual Basic 4.12 0.83 7 7 JavaScript 2.54 0.41 8 8 PHP 2.49 0.62 9 9 R 2.37 1.33
V případě, že je přidávaný sloupec kratší (ale datový rámec má délku rovnou celočíselnému násobku délky sloupce), je provedeno rozkopírování dat:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37)
)
print(languages)
languages$change <- c(0, 50, 100)
print("------------------------------------")
print(languages)
Výsledek nyní bude vypadat odlišně:
id name usage 1 1 C 15.95 2 2 Java 13.48 3 3 Python 10.47 4 4 C++ 7.11 5 5 C# 4.58 6 6 Visual Basic 4.12 7 7 JavaScript 2.54 8 8 PHP 2.49 9 9 R 2.37 [1] "------------------------------------" id name usage change 1 1 C 15.95 0 2 2 Java 13.48 50 3 3 Python 10.47 100 4 4 C++ 7.11 0 5 5 C# 4.58 50 6 6 Visual Basic 4.12 100 7 7 JavaScript 2.54 0 8 8 PHP 2.49 50 9 9 R 2.37 100
Opačný postup však možný není – přidávaný sloupec nesmí být delší, než odpovídá délce datového rámce:
languages <- data.frame(
id = c (1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37)
)
print(languages)
languages$change <- seq(1, 50)
print("------------------------------------")
print(languages)
Tentokrát dojde při pokusu o spuštění příkladu k chybě:
id name usage 1 1 C 15.95 2 2 Java 13.48 3 3 Python 10.47 4 4 C++ 7.11 5 5 C# 4.58 6 6 Visual Basic 4.12 7 7 JavaScript 2.54 8 8 PHP 2.49 9 9 R 2.37 Error in `$<-.data.frame`(`*tmp*`, change, value = 1:50) : replacement has 50 rows, data has 9 Calls: $<- -> $<-.data.frame Execution halted
7. Konverze datového rámce na matici
V dalším demonstračním příkladu si ukážeme jednu poměrně často prováděnou operaci – konverzi datového rámce na „obyčejnou“ matici. To pochopitelně není zcela bezproblémové, protože všechny prvky matice musí být stejného datového typu. Pokud jsou řetězce reprezentovány formou faktorů, budou převedeny na celá čísla (indexy):
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
print(languages)
print("-------------------------------")
m <- data.matrix(languages)
print(class(m))
print(m)
Příklad nejprve zobrazí původní datový rámec a posléze vytvořenou matici:
id name usage change
1 1 C 15.95 0.74
2 2 Java 13.48 -3.18
3 3 Python 10.47 0.59
4 4 C++ 7.11 1.48
5 5 C# 4.58 1.18
6 6 Visual Basic 4.12 0.83
7 7 JavaScript 2.54 0.41
8 8 PHP 2.49 0.62
9 9 R 2.37 1.33
[1] "-------------------------------"
[1] "matrix"
id name usage change
[1,] 1 1 15.95 0.74
[2,] 2 4 13.48 -3.18
[3,] 3 7 10.47 0.59
[4,] 4 3 7.11 1.48
[5,] 5 2 4.58 1.18
[6,] 6 9 4.12 0.83
[7,] 7 5 2.54 0.41
[8,] 8 6 2.49 0.62
[9,] 9 8 2.37 1.33
V případě, že se nepoužívají faktory, je situace nepatrně horší:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33),
stringsAsFactors = FALSE
)
print(languages)
print("-------------------------------")
m <- data.matrix(languages)
print(class(m))
print(m)
Nové výsledky budou muset obsahovat hodnoty NA, jinak by prvky matice nebyly stejného typu:
id name usage change
1 1 C 15.95 0.74
2 2 Java 13.48 -3.18
3 3 Python 10.47 0.59
4 4 C++ 7.11 1.48
5 5 C# 4.58 1.18
6 6 Visual Basic 4.12 0.83
7 7 JavaScript 2.54 0.41
8 8 PHP 2.49 0.62
9 9 R 2.37 1.33
[1] "-------------------------------"
[1] "matrix"
id name usage change
[1,] 1 NA 15.95 0.74
[2,] 2 NA 13.48 -3.18
[3,] 3 NA 10.47 0.59
[4,] 4 NA 7.11 1.48
[5,] 5 NA 4.58 1.18
[6,] 6 NA 4.12 0.83
[7,] 7 NA 2.54 0.41
[8,] 8 NA 2.49 0.62
[9,] 9 NA 2.37 1.33
Warning message:
In data.matrix(languages) : NAs introduced by coercion
Alternativně je možné použít funkci t, která kromě transpozice matice provede i příslušnou konverzi:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
print(languages)
print("-------------------------------")
m <- t(languages)
print(class(m))
print(m)
Nyní je výsledkem transponovaná matice:
id name usage change
1 1 C 15.95 0.74
2 2 Java 13.48 -3.18
3 3 Python 10.47 0.59
4 4 C++ 7.11 1.48
5 5 C# 4.58 1.18
6 6 Visual Basic 4.12 0.83
7 7 JavaScript 2.54 0.41
8 8 PHP 2.49 0.62
9 9 R 2.37 1.33
[1] "-------------------------------"
[1] "matrix"
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
id "1" "2" "3" "4" "5" "6" "7"
name "C" "Java" "Python" "C++" "C#" "Visual Basic" "JavaScript"
usage "15.95" "13.48" "10.47" " 7.11" " 4.58" " 4.12" " 2.54"
change " 0.74" "-3.18" " 0.59" " 1.48" " 1.18" " 0.83" " 0.41"
[,8] [,9]
id "8" "9"
name "PHP" "R"
usage " 2.49" " 2.37"
change " 0.62" " 1.33"
8. Datový rámec získaný z matice – jednoduchý kalendář
Podívejme se nyní na způsob zpětné konverze, tj. na vytvoření datového rámce z matice. Použijeme přitom příklad, který již známe z předchozího článku a v němž jsme vytvořili matici se jmény měsíců rozdělených do ročních období. O samotný převod se postará funkce nazvaná as.data.frame:
m <- matrix(
month.abb[c(12, 1:11)],
nrow = 3,
dimnames = list(
c("start", "middle", "end"),
c("Winter", "Spring", "Summer", "Fall")
)
)
print(class(m))
print(m)
print("-------------------------------")
df <- as.data.frame(m)
print(class(df))
print(df)
Povšimněte si, že po převodu na datový rámec došlo k pojmenování řádků a sloupců podle dat získaných z matice:
[1] "matrix"
Winter Spring Summer Fall
start "Dec" "Mar" "Jun" "Sep"
middle "Jan" "Apr" "Jul" "Oct"
end "Feb" "May" "Aug" "Nov"
[1] "-------------------------------"
[1] "data.frame"
Winter Spring Summer Fall
start Dec Mar Jun Sep
middle Jan Apr Jul Oct
end Feb May Aug Nov
Shodný demonstrační příklad, který ovšem tentokrát bude založen na celých (dlouhých) jménech měsíců, bude vypadat následovně:
m <- matrix(
month.name[c(12, 1:11)],
nrow = 3,
dimnames = list(
c("start", "middle", "end"),
c("Winter", "Spring", "Summer", "Fall")
)
)
print(class(m))
print(m)
print("-------------------------------")
df <- as.data.frame(m)
print(class(df))
print(df)
Nyní budou výsledné datové struktury, tedy jak matice, tak i datový rámec, vypadat následovně:
[1] "matrix"
Winter Spring Summer Fall
start "December" "March" "June" "September"
middle "January" "April" "July" "October"
end "February" "May" "August" "November"
[1] "-------------------------------"
[1] "data.frame"
Winter Spring Summer Fall
start December March June September
middle January April July October
end February May August November
9. Funkce rbind() a cbind()
S funkcemi rbind() a cbind() jsme se již setkali v souvislosti s jinými datovými typy. Tyto funkce dokážou spojit několik struktur do jediné a lze je použít i v případě datových rámců. Nejprve si ukažme použití funkce rbind(), která spojuje struktury po řádcích (row):
languages1 <- data.frame(
id = c(1:5),
name = c("C", "Java", "Python", "C++", "C#"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58),
change = c(0.74, -3.18, 0.59, 1.48, 1.18)
)
languages2 <- data.frame(
id = c(1:4),
name = c("Visual Basic", "JavaScript", "PHP", "R"),
usage = c(4.12, 2.54, 2.49, 2.37),
change = c(0.83, 0.41, 0.62, 1.33)
)
print(nrow(languages1))
print(nrow(languages2))
languages <- rbind(languages1, languages2)
print(nrow(languages))
print(languages)
Po spuštění tohoto příkladu dojde ke spojení datového rámce s pěti řádky s datovým rámcem, který má řádky čtyři:
[1] 5 [1] 4 [1] 9 id name usage change 1 1 C 15.95 0.74 2 2 Java 13.48 -3.18 3 3 Python 10.47 0.59 4 4 C++ 7.11 1.48 5 5 C# 4.58 1.18 6 1 Visual Basic 4.12 0.83 7 2 JavaScript 2.54 0.41 8 3 PHP 2.49 0.62 9 4 R 2.37 1.33
Oba datové rámce musí mít stejně pojmenované sloupce:
languages1 <- data.frame(
id = c(1:5),
name = c("C", "Java", "Python", "C++", "C#"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58),
change = c(0.74, -3.18, 0.59, 1.48, 1.18)
)
languages2 <- data.frame(
id = c(1:4),
name = c("Visual Basic", "JavaScript", "PHP", "R"),
usage = c(4.12, 2.54, 2.49, 2.37),
changeXYZZY = c(0.83, 0.41, 0.62, 1.33)
)
print(nrow(languages1))
print(nrow(languages2))
languages <- rbind(languages1, languages2)
print(nrow(languages))
print(languages)
V tomto případě se jeden sloupec odlišuje svým jménem a dojde k chybě:
[1] 5 [1] 4 Error in match.names(clabs, names(xi)) : names do not match previous names Calls: rbind -> rbind -> match.names Execution halted
Podobně můžeme použít funkci cbind() pro spojení datových struktur se stejnou délkou, ale odlišnými sloupci:
id_and_names <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R")
)
usages_and_changes <- data.frame(
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
print(ncol(id_and_names))
print(ncol(usages_and_changes))
languages <- cbind(id_and_names, usages_and_changes)
print(ncol(languages))
print(languages)
S výsledky:
[1] 2 [1] 2 [1] 4 id name usage change 1 1 C 15.95 0.74 2 2 Java 13.48 -3.18 3 3 Python 10.47 0.59 4 4 C++ 7.11 1.48 5 5 C# 4.58 1.18 6 6 Visual Basic 4.12 0.83 7 7 JavaScript 2.54 0.41 8 8 PHP 2.49 0.62 9 9 R 2.37 1.33
Zajímavé je, že pokud má druhý datový rámec menší počet řádků, ovšem je soudělný s počtem řádků prvního datového rámce, je možné provést spojení, protože dojde k opakování hodnot:
id_and_names <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R")
)
usages_and_changes <- data.frame(
usage = c(1, 99, 100),
change = c(0.74, -3.18, 0.59)
)
print(ncol(id_and_names))
print(ncol(usages_and_changes))
languages <- cbind(id_and_names, usages_and_changes)
print(ncol(languages))
print(languages)
Tento příklad bude možné spustit, jeho výsledek bude následující:
[1] 2 [1] 2 [1] 4 id name usage change 1 1 C 1 0.74 2 2 Java 99 -3.18 3 3 Python 100 0.59 4 4 C++ 1 0.74 5 5 C# 99 -3.18 6 6 Visual Basic 100 0.59 7 7 JavaScript 1 0.74 8 8 PHP 99 -3.18 9 9 R 100 0.59
10. Sloupcový graf s hodnotami vyčtenými z datového rámce
Ve druhé části článku se budeme věnovat tvorbě jednoduchých grafů, jejichž vstupní data jsou získána právě z datových rámců. Jedná se totiž o velmi častý požadavek.
Nejprve zobrazíme sloupcový graf obsahující hodnoty vyčtené ze sloupce usage. Sloupcový graf se zobrazuje funkcí barplot():
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
barplot(languages$usage)
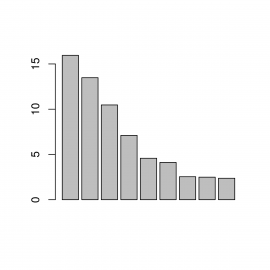
Obrázek 1: Sloupcový graf s hodnotami vyčtenými z datového rámce.
11. Přidání popisku horizontální osy do grafu
Graf z předchozího demonstračního příkladu není v žádném případě dokonalý, například mu chybí popis na osách. Pojmenovaným parametrem names.arg lze specifikovat, který vektor (či seznam) obsahuje popisky na horizontální ose:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
barplot(languages$usage, names.arg=languages$name)
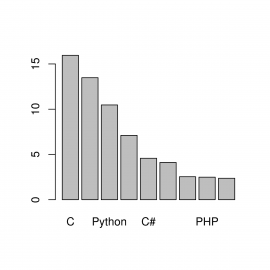
Obrázek 2: Přidání popisků na horizontální ose.
12. Úprava stylu zobrazení grafu
Pokud se stane, že popisky (resp. přesněji řečeno jejich font) jsou příliš velké, lze přes parametry cex.jméno určit relativní velikost písma. V dalším demonstračním příkladu změníme popisky obou os na 80%, resp. na 60%:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
barplot(languages$usage, names.arg=languages$name,
cex.axis = 0.8,
cex.names = 0.6)
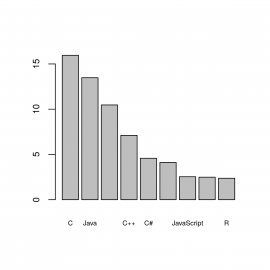
Obrázek 3: Změna velikosti popisků.
13. Orientace popisků na horizontální ose
I přesto, že jsou nyní popisky zobrazeny menším písmem, nevidíme všechny názvy programovacích jazyků. Pokusme se tedy změnit orientaci popisků – otočíme je o 90°, takže nezávisle na délce názvu jazyka budou zobrazeny všechny názvy. Upravený zdrojový kód příkladu bude vypadat takto:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
barplot(languages$usage, names.arg=languages$name,
cex.axis = 0.8,
cex.names = 0.6,
las=2)
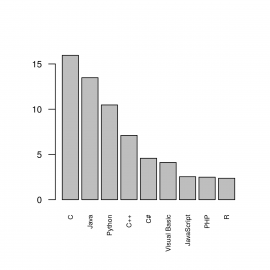
Obrázek 4: Změna orientace popisků na horizontální ose.
14. Přidání liniového grafu do grafu sloupcového
Do sloupcového grafu je možné přidat další průběh, například liniový graf. To je užitečná vlastnost, protože můžeme zobrazit dvě (více nebo méně korelující) veličiny. U liniového průběhu můžeme změnit styl zobrazení bodů a popř. i barvu samotného průběhu. Následující příklad je poněkud umělý, protože v něm vytváříme graf, který zobrazuje používanost (resp. popularitu) programovacích jazyků a meziroční rozdíl v této popularitě:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
plt <- barplot(languages$usage, names.arg=languages$name,
cex.axis = 0.8,
cex.names = 0.6,
las=2)
lines(plt, languages$change, type="o", col="red")
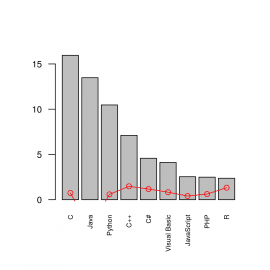
Obrázek 5: Přidání liniového grafu do existujícího sloupcového grafu.
15. Specifikace rozsahu hodnot na vertikální ose
Předchozí graf je možné vylepšit dvěma způsoby:
- Přidáním sekundární vertikální osy s jiným rozsahem hodnot, než má primární osa.
- Změnou rozsahu hodnot u vertikální osy s tím, že měřítko atd. zůstane pro oba zobrazené průběhy totožné.
Dnes si ukážeme první naznačenou možnost, tedy změnu rozsahu hodnot u jediné (primární) vertikální osy. Tento postup má dvě výhody – je jednodušší z hlediska programu a současně bývá i přehlednější pro uživatele, kteří mají někdy problém porozumět grafu s dvojicí průběhů, přičemž každý průběh má jiné měřítko. Pro specifikaci mezních hodnot se používá nepovinný parametr ulim, kterému se ve vektoru předá minimální a maximální hodnota, která může být na grafu zobrazena:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
plt <- barplot(languages$usage, names.arg=languages$name,
ylim=c(-5, 20),
cex.axis = 0.8,
cex.names = 0.6,
las=2)
lines(plt, languages$change, type="o", col="red")
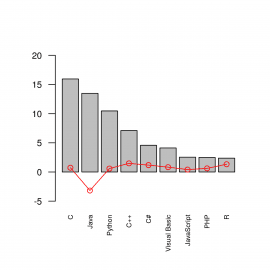
Obrázek 6: Specifikace rozsahu hodnot na vertikální ose.
16. Pokus o vytvoření dvou skupin sloupců
Poměrně často se ve sloupcových grafech musí zobrazit více skupin sloupců (typickým příkladem mohou být výsledky benchmarků). Pokusme se nejdříve o přípravu dat pro takový graf. Vytvoříme si tabulku s příslušnými daty:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
data=t(languages[, c("usage", "change")])
A pro zajímavost si necháme zobrazit její obsah:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] usage 15.95 13.48 10.47 7.11 4.58 4.12 2.54 2.49 2.37 change 0.74 -3.18 0.59 1.48 1.18 0.83 0.41 0.62 1.33
Dále již musíme tato data vykreslit do sloupcového grafu; pochopitelně nesmíme zapomenout na nastavení popisků horizontální osy, doplnění limitů atd.:
barplot(data, names.arg=languages$name,
ylim=c(-5, 20),
cex.axis = 0.8,
cex.names = 0.6,
las=2)
Výsledek ovšem nemusí vypadat přesně podle očekávání, protože skupiny jsou zobrazeny nad sebou (což nemusí být vhodné řešení – záleží na tom, jaká data potřebujeme zobrazit):
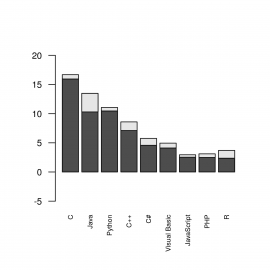
Obrázek 7: Dvě skupiny sloupců zobrazené nad sebou.
17. Zobrazení sloupcového grafu se dvěma skupinami sloupců
Úprava zdrojového kódu příkladu takovým způsobem, aby se sloupce zobrazily vedle sebe a nikoli na sobě, je ve skutečnosti poměrně jednoduchá – musíme použít nepovinný pojmenovaný parametr beside a nastavit ho na hodnotu T neboli TRUE:
barplot(data, names.arg=languages$name,
ylim=c(-5, 20),
cex.axis = 0.8,
cex.names = 0.6,
las=2,
beside=T)
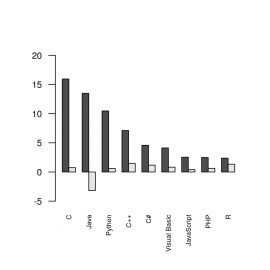
Obrázek 8: Dvě skupiny sloupců zobrazené vedle sebe.
Pro úplnost si ukažme celý zdrojový kód tohoto příkladu:
languages <- data.frame(
id = c(1:9),
name = c("C", "Java", "Python", "C++", "C#", "Visual Basic", "JavaScript", "PHP", "R"),
usage = c(15.95, 13.48, 10.47, 7.11, 4.58, 4.12, 2.54, 2.49, 2.37),
change = c(0.74, -3.18, 0.59, 1.48, 1.18, 0.83, 0.41, 0.62, 1.33)
)
data=t(languages[, c("usage", "change")])
print(data)
barplot(data, names.arg=languages$name,
ylim=c(-5, 20),
cex.axis = 0.8,
cex.names = 0.6,
las=2,
beside=T)
18. Další typy grafů
Dnes jsme se seznámili jen s těmi nejjednoduššími typy grafů a pouze s několika jejich konfiguračními parametry. Složitější grafy a především pak grafy zobrazené s využitím velmi populární knihovny ggplot2 si popíšeme příště. Dnes si na ukázku připomeňme, jak lze vykreslit průběh funkce:
x <- 1:100 y <- sin(x/10) print(x) print(y) plot(x, y)
Po spuštění příkladu se nejprve vypíšou hodnoty vektorů x a y:
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91] 91 92 93 94 95 96 97 98 99 100 [1] 0.09983342 0.19866933 0.29552021 0.38941834 0.47942554 0.56464247 [7] 0.64421769 0.71735609 0.78332691 0.84147098 0.89120736 0.93203909 [13] 0.96355819 0.98544973 0.99749499 0.99957360 0.99166481 0.97384763 [19] 0.94630009 0.90929743 0.86320937 0.80849640 0.74570521 0.67546318 [25] 0.59847214 0.51550137 0.42737988 0.33498815 0.23924933 0.14112001 [31] 0.04158066 -0.05837414 -0.15774569 -0.25554110 -0.35078323 -0.44252044 [37] -0.52983614 -0.61185789 -0.68776616 -0.75680250 -0.81827711 -0.87157577 [43] -0.91616594 -0.95160207 -0.97753012 -0.99369100 -0.99992326 -0.99616461 [49] -0.98245261 -0.95892427 -0.92581468 -0.88345466 -0.83226744 -0.77276449 [55] -0.70554033 -0.63126664 -0.55068554 -0.46460218 -0.37387666 -0.27941550 [61] -0.18216250 -0.08308940 0.01681390 0.11654920 0.21511999 0.31154136 [67] 0.40484992 0.49411335 0.57843976 0.65698660 0.72896904 0.79366786 [73] 0.85043662 0.89870810 0.93799998 0.96791967 0.98816823 0.99854335 [79] 0.99894134 0.98935825 0.96988981 0.94073056 0.90217183 0.85459891 [85] 0.79848711 0.73439710 0.66296923 0.58491719 0.50102086 0.41211849 [91] 0.31909836 0.22288991 0.12445442 0.02477543 -0.07515112 -0.17432678 [97] -0.27176063 -0.36647913 -0.45753589 -0.54402111
A následně se vykreslí graf:
Obrázek 9: Body ležící na sinusovce (bez dalších úprav).
Další příklad převzatý z dokumentace vykreslí histogram a navíc vypíše i podrobnější informace o pseudonáhodném souboru dat:
x <- rnorm(1000) hx <- hist(x, breaks=100, plot=FALSE) print(hx) plot(hx, col=ifelse(abs(hx$breaks) < 1.669, 4, 2))
Obrázek 10: Histogram.

Podrobnější informace o pseudonáhodném souboru dat:
$breaks [1] -3.20 -3.15 -3.10 -3.05 -3.00 -2.95 -2.90 -2.85 -2.80 -2.75 -2.70 -2.65 [13] -2.60 -2.55 -2.50 -2.45 -2.40 -2.35 -2.30 -2.25 -2.20 -2.15 -2.10 -2.05 [25] -2.00 -1.95 -1.90 -1.85 -1.80 -1.75 -1.70 -1.65 -1.60 -1.55 -1.50 -1.45 [37] -1.40 -1.35 -1.30 -1.25 -1.20 -1.15 -1.10 -1.05 -1.00 -0.95 -0.90 -0.85 [49] -0.80 -0.75 -0.70 -0.65 -0.60 -0.55 -0.50 -0.45 -0.40 -0.35 -0.30 -0.25 [61] -0.20 -0.15 -0.10 -0.05 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 [73] 0.40 0.45 0.50 0.55 0.60 0.65 0.70 0.75 0.80 0.85 0.90 0.95 [85] 1.00 1.05 1.10 1.15 1.20 1.25 1.30 1.35 1.40 1.45 1.50 1.55 [97] 1.60 1.65 1.70 1.75 1.80 1.85 1.90 1.95 2.00 2.05 2.10 2.15 [109] 2.20 2.25 2.30 2.35 2.40 2.45 2.50 2.55 2.60 2.65 2.70 2.75 [121] 2.80 2.85 2.90 2.95 3.00 3.05 3.10 3.15 3.20 3.25 3.30 3.35 [133] 3.40 3.45 3.50 $counts [1] 1 0 1 0 0 0 0 1 1 2 1 0 1 2 2 1 0 1 3 1 1 0 5 5 1 [26] 5 5 3 6 1 4 11 6 2 5 12 8 10 8 14 8 15 12 11 16 12 18 8 16 11 [51] 18 13 14 15 16 16 12 18 14 29 24 19 29 23 25 19 18 7 21 15 16 14 20 19 25 [76] 24 18 13 17 7 13 5 14 15 8 10 9 7 9 12 8 9 6 13 5 5 4 3 4 3 [101] 6 2 3 3 1 8 4 1 1 0 1 2 2 1 0 2 1 0 0 0 0 1 0 0 0 [126] 1 1 0 0 0 0 0 1 1 $density [1] 0.02 0.00 0.02 0.00 0.00 0.00 0.00 0.02 0.02 0.04 0.02 0.00 0.02 0.04 0.04 [16] 0.02 0.00 0.02 0.06 0.02 0.02 0.00 0.10 0.10 0.02 0.10 0.10 0.06 0.12 0.02 [31] 0.08 0.22 0.12 0.04 0.10 0.24 0.16 0.20 0.16 0.28 0.16 0.30 0.24 0.22 0.32 [46] 0.24 0.36 0.16 0.32 0.22 0.36 0.26 0.28 0.30 0.32 0.32 0.24 0.36 0.28 0.58 [61] 0.48 0.38 0.58 0.46 0.50 0.38 0.36 0.14 0.42 0.30 0.32 0.28 0.40 0.38 0.50 [76] 0.48 0.36 0.26 0.34 0.14 0.26 0.10 0.28 0.30 0.16 0.20 0.18 0.14 0.18 0.24 [91] 0.16 0.18 0.12 0.26 0.10 0.10 0.08 0.06 0.08 0.06 0.12 0.04 0.06 0.06 0.02 [106] 0.16 0.08 0.02 0.02 0.00 0.02 0.04 0.04 0.02 0.00 0.04 0.02 0.00 0.00 0.00 [121] 0.00 0.02 0.00 0.00 0.00 0.02 0.02 0.00 0.00 0.00 0.00 0.00 0.02 0.02 $mids [1] -3.175 -3.125 -3.075 -3.025 -2.975 -2.925 -2.875 -2.825 -2.775 -2.725 [11] -2.675 -2.625 -2.575 -2.525 -2.475 -2.425 -2.375 -2.325 -2.275 -2.225 [21] -2.175 -2.125 -2.075 -2.025 -1.975 -1.925 -1.875 -1.825 -1.775 -1.725 [31] -1.675 -1.625 -1.575 -1.525 -1.475 -1.425 -1.375 -1.325 -1.275 -1.225 [41] -1.175 -1.125 -1.075 -1.025 -0.975 -0.925 -0.875 -0.825 -0.775 -0.725 [51] -0.675 -0.625 -0.575 -0.525 -0.475 -0.425 -0.375 -0.325 -0.275 -0.225 [61] -0.175 -0.125 -0.075 -0.025 0.025 0.075 0.125 0.175 0.225 0.275 [71] 0.325 0.375 0.425 0.475 0.525 0.575 0.625 0.675 0.725 0.775 [81] 0.825 0.875 0.925 0.975 1.025 1.075 1.125 1.175 1.225 1.275 [91] 1.325 1.375 1.425 1.475 1.525 1.575 1.625 1.675 1.725 1.775 [101] 1.825 1.875 1.925 1.975 2.025 2.075 2.125 2.175 2.225 2.275 [111] 2.325 2.375 2.425 2.475 2.525 2.575 2.625 2.675 2.725 2.775 [121] 2.825 2.875 2.925 2.975 3.025 3.075 3.125 3.175 3.225 3.275 [131] 3.325 3.375 3.425 3.475
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes použitých demonstračních příkladů byly uloženy do nového Git repositáře, který je dostupný na adrese https://github.com/tisnik/r-examples V případě, že z nějakého důvodu nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má stále jen jednotky kilobajtů), můžete namísto toho použít odkazy na jednotlivé demonstrační příklady, které naleznete v následující tabulce:
20. Odkazy na Internetu
- The R Project for Statistical Computing
https://www.r-project.org/ - An Introduction to R
https://cran.r-project.org/doc/manuals/r-release/R-intro.pdf - R (programming language)
https://en.wikipedia.org/wiki/R_(programming_language) - The R Programming Language
https://www.tiobe.com/tiobe-index/r/ - R Markdown
https://rmarkdown.rstudio.com/ - R Markdown: The Definitive Guide
https://bookdown.org/yihui/rmarkdown/ - R Markdown Cheat Sheet
https://rstudio.com/wp-content/uploads/2016/03/rmarkdown-cheatsheet-2.0.pdf - Introduction to R Markdown
https://rmarkdown.rstudio.com/articles_intro.html - R Cheat Sheets
https://blog.sergiouri.be/2016/07/r-cheat-sheets.html - R Cheat Sheet
https://s3.amazonaws.com/quandl-static-content/Documents/Quandl±+R+Cheat+Sheet.pdf - Base R Cheat Sheet
https://rstudio.com/wp-content/uploads/2016/06/r-cheat-sheet.pdf - PYPL PopularitY of Programming Language
https://pypl.github.io/PYPL.html - Tiobe index
https://www.tiobe.com/tiobe-index/ - Stack Overflow: Most Loved, Dreaded & Wanted Programming Languages In 2020
https://fossbytes.com/stack-overflow-most-loved-dreaded-wanted-programming-languages-in-2020/ - How to Install and Use R on Ubuntu
https://itsfoss.com/install-r-ubuntu/ - R programming for beginners – Why you should use R
https://www.youtube.com/watch?v=9kYUGMg_14s - GOTO 2012 • The R Language The Good The Bad & The Ugly
https://www.youtube.com/watch?v=6S9r_YbqHy8 - R vs Python – What should I learn in 2020? | R and Python Comparison
https://www.youtube.com/watch?v=eRP_J2yLjSU - R Programming 101
https://www.youtube.com/c/rprogramming101 - Seriál Tvorba grafů pomocí programu „R“
https://www.root.cz/serialy/tvorba-grafu-pomoci-programu-r/ - Tvorba grafů pomocí programu „R“: úvod
https://www.root.cz/clanky/tvorba-grafu-pomoci-programu-r-1/ - Tvorba grafů pomocí programu „R“: pokročilé funkce
https://www.root.cz/clanky/tvorba-grafu-pomoci-programu-r-pokrocile-funkce/ - Tvorba grafů pomocí programu „R“: vkládání textu, čeština
https://www.root.cz/clanky/grafy-pomoci-programu-r-vkladani-textu-cestina/ - Cesta erka: Krok nultý – instalace & nastavení – prostředí, projekty, package
https://www.jla-data.net/r4su/r4su-environment-setup/ - Cesta erka: Krok první – operace a struktury – proměnné, rovnítka a dolary
https://www.jla-data.net/r4su/r4su-data-structures/ - Cesta erka: Krok druhý – načtení externích dat – csvčka, excely a databáze
https://www.jla-data.net/r4su/r4su-read-data/ - Cesta erka: Krok třetí – manipulace s daty – dplyr, slovesa a pajpy
https://www.jla-data.net/r4su/r4su-manipulate-data/ - Cesta erka: Krok čtvrtý – podání výsledků – ggplot, geomy a estetiky
https://www.jla-data.net/r4su/r4su-report-results/ - Cesta erka: Krok pátý – case study – případ piva v Praze
https://www.jla-data.net/r4su/r4su-case-study-beer/ - V indexu popularity programovacích jazyků TIOBE překvapilo R, Go, Perl, Scratch a Rust
https://www.root.cz/zpravicky/v-indexu-popularity-programovacich-jazyku-tiobe-prekvapilo-r-go-perl-scratch-a-rust/ - Is R Programming SURGING in Popularity in 2020?
https://www.youtube.com/watch?v=Duwn-vImyXE - Using the R programming language in Jupyter Notebook
https://docs.anaconda.com/anaconda/navigator/tutorials/r-lang/ - Using R on Jupyter Notebook
https://dzone.com/articles/using-r-on-jupyternbspnotebook - Graphics, ggplot2
http://r4stats.com/examples/graphics-ggplot2/ - A Practice Data Set
https://r4stats.wordpress.com/examples/mydata/ - Shiny – galerie projektů
https://shiny.rstudio.com/gallery/ - Seriál Programovací jazyk Julia
https://www.root.cz/serialy/programovaci-jazyk-julia/ - Julia (front page)
http://julialang.org/ - Julia – repositář na GitHubu
https://github.com/JuliaLang/julia - Julia (programming language)
https://en.wikipedia.org/wiki/Julia_%28programming_language%29 - IJulia
https://github.com/JuliaLang/IJulia.jl - Introducing Julia
https://en.wikibooks.org/wiki/Introducing_Julia - Julia: the REPL
https://en.wikibooks.org/wiki/Introducing_Julia/The_REPL - Introducing Julia/Metaprogramming
https://en.wikibooks.org/wiki/Introducing_Julia/Metaprogramming - Month of Julia
https://github.com/DataWookie/MonthOfJulia - Learn X in Y minutes (where X=Julia)
https://learnxinyminutes.com/docs/julia/ - New Julia language seeks to be the C for scientists
http://www.infoworld.com/article/2616709/application-development/new-julia-language-seeks-to-be-the-c-for-scientists.html - Julia: A Fast Dynamic Language for Technical Computing
http://karpinski.org/publications/2012/julia-a-fast-dynamic-language - The LLVM Compiler Infrastructure
http://llvm.org/ - Julia: benchmarks
http://julialang.org/benchmarks/ - R Vector
https://www.datamentor.io/r-programming/vector/ - .R File Extension
https://fileinfo.com/extension/r - Lineární regrese
https://cs.wikipedia.org/wiki/Line%C3%A1rn%C3%AD_regrese - lm (funkce)
https://www.rdocumentation.org/packages/stats/versions/3.6.2/topics/lm - quit (funkce)
https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/quit - c (funkce)
https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/c - help (funkce)
https://www.rdocumentation.org/packages/utils/versions/3.6.2/topics/help - Shiny: Introduction to interactive documents
https://shiny.rstudio.com/articles/interactive-docs.html - R Release History 1997–2013
http://timelyportfolio.github.io/rCharts_timeline_r/ - R: atomic vectors
https://renenyffenegger.ch/notes/development/languages/R/data-structures/vector/ - 11 Best R Programming IDE and editors
https://www.dunebook.com/best-r-programming-ide/ - CRAN – The Comprehensive R Archive Network
https://cran.r-project.org/ - R – Arrays
https://www.tutorialspoint.com/r/r_arrays.htm - Array vs Matrix in R Programming
https://www.geeksforgeeks.org/array-vs-matrix-in-r-programming/?ref=rp - Online R Language IDE
https://www.jdoodle.com/execute-r-online/ - Execute R Online (R v3.4.1)
https://www.tutorialspoint.com/execute_r_online.php - Snippets: Run any R code you like. There are over twelve thousand R packages preloaded
https://rdrr.io/snippets/ - R Package Documentation
https://rdrr.io/ - Data Reshaping in R – Popular Functions to Organise Data
https://techvidvan.com/tutorials/data-reshaping-in-r/ - What is an R Data Frame?
https://magoosh.com/data-science/what-is-an-r-data-frame/ - What's a data frame?
https://campus.datacamp.com/courses/free-introduction-to-r/chapter-5-data-frames?ex=1 - data.frame
https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/data.frame - as.data.frame
https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/as.data.frame - table
https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/table - Python Pandas – DataFrame
https://www.tutorialspoint.com/python_pandas/python_pandas_dataframe.htm - The Pandas DataFrame: Make Working With Data Delightful
https://realpython.com/pandas-dataframe/ - Python | Pandas DataFrame
https://www.geeksforgeeks.org/python-pandas-dataframe/ - R – Factors
https://www.tutorialspoint.com/r/r_factors.htm





































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU