
Obsah
1. Programovací jazyk Rust – slepá cesta vývoje či dlouho očekávaná náhrada céčka?
2. Základy, na nichž je postaven programovací jazyk Rust
3. Rozdíly mezi Rustem a klasickými kompilovanými jazyky (C, C++)
4. Rust versus vysokoúrovňové programovací jazyky
5. Výkon aplikací naprogramovaných v Rustu
6. Instalace Rustu v libovolné distribuci Linuxu z dodávaného tarballu
7. Instalace Rustu na Fedoře z oficiálních balíčků
8. Syntaxe a sémantika programů napsaných v Rustu
9. Základní (primitivní) datové typy
10. Řetězce aneb překvapivě rozsáhlá problematika
11. Neměnitelné hodnoty a jejich význam při tvorbě a ladění aplikací
12. Kontrola operací prováděných s proměnnými různých typů
13. Základní řídicí struktury vs výrazy
14. Programové smyčky loop a while
15. Programová smyčka for a iterátory
1. Programovací jazyk Rust – slepá cesta vývoje, či dlouho očekávaná náhrada céčka?
Programovací jazyky C a C++ pravděpodobně není nutné čtenářům Roota podrobněji představovat, protože se jedná o velmi populární a často používané jazyky [1] [2], které jsou v současnosti využívány jak pro psaní firmware a systémového software, tak i pro vývoj některých aplikací, u nichž vyžadujeme vysoký výpočetní výkon popř. specifický přístup k paměti či k periferním zařízením. Především jazyku C (céčku) se někdy přezdívá „čitelnější assembler“ či „přenositelný assembler“, což je samozřejmě nadsázka, která ovšem vystihuje fakt, že v céčku (a tím pádem i v C++) můžeme v případě potřeby využívat i dosti nízkoúrovňové operace, například přímý přístup do paměti, používat bitová pole, unie, datové typy, které korespondují se šířkou aritmeticko-logických jednotek i datových sběrnic, atd.
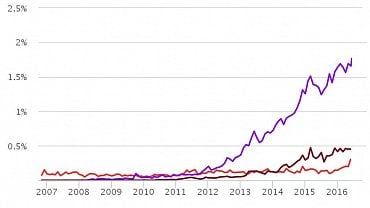
Obrázek 1: Relativní počet commitů do open source projektů sledovaných na OpenHubu. Modrý průběh: Go, červený průběh: D, rezavá barva: Rust. Pokud si stejný graf zobrazíte přímo na stránkách OpenHubu, uvidíte výrazné skoky v posledních dvou měsících, protože tento server se stává známý tím, jak pomalu zpracovává statistické informace o sledovaných repositářích. Proto jsou poslední dva měsíce ze zde zobrazeného grafu odstraněny. Jazyky C a C++ jsem schválně nepřidával, ty mají totiž výrazně větší počet commitů, takže by se zbývající tři jazyky krčily schovány na x-ové ose :-)
Velká volnost programátorů při použití C a C++ je samozřejmě pro některé aplikace výhodná, na druhou stranu je však nutné, aby si programátor sám zajistil korektní správu paměti, což se stává problematické zejména ve chvíli, kdy se složitost aplikace a tím i provázanost všech komponent zvyšuje. Ovšem nutnost zajištění korektní správy paměti i v tak základních situacích, jako je práce s řetězci (alokace dostatečně velkého bloku, dealokace až ve chvíli, kdy opravdu řetězec není nikde používán), vede k poměrně typickým chybám, na které jsou programy psané v céčku (a částečně i C++) náchylné. Problematických míst v návrhu jazyka je ovšem více; například vlastnost, že se pro jediný příkaz v řídicí struktuře nemusí vytvářet blok {}, vedla ke známému „goto failu“ [3].
2. Základy, na nichž je postaven programovací jazyk Rust
Cílem autorů programovacího jazyka Rust je vytvoření takového nástroje, který by umožňoval efektivní běh aplikací a v případě potřeby i nízkoúrovňový přístup k paměti a periferním zařízením, ovšem s ohledem na bezpečnost aplikací, podporu pro paralelní běh částí kódu a taktéž tak, aby měl vývojář co nejlepší možnosti při správě prostředků (sem spadá jak paměť, tak například i otevřené soubory, připojení do databáze, samozřejmě objekty atd.). Přitom je dbáno na to, aby žádný rys jazyka nevyžadoval zbytečně složitou infrastrukturu – typickým příkladem by byl garbage collector. Namísto plnohodnotného automatického správce paměti (garbage collectoru) je tedy Rust založen na takovém typovém systému, který zajistí správnou alokaci a dealokaci paměti odlišnými prostředky. Právě typový systém a důraz na použití neměnných (immutable) hodnot jsou nejvýraznějšími vlastnostmi Rustu.
Na rozdíl od některých dalších jazyků (Java je asi nejlepším příkladem) si Rust nevynucuje použití OOP. Je to jen volitelná část jazyka, která je navíc v některých ohledech od klasického třídního OOP odlišná. Podobně si Rust nevynucuje použití FP (funkcionálního programování), i když sám má mnohé funkcionální rysy.
Programovací jazyk Rust je v porovnání s dnes nejčastěji používanými jazyky poměrně nový, protože jeho první verze se objevila teprve v roce 2010 a první stabilní verze (1.0.0) loni (ve skutečnosti celý projekt vznikl ještě o trošku dříve, konkrétně v roce 2006, ovšem v dosti odlišné podobě). Samotný jazyk se navíc ještě poměrně aktivně vyvíjí, přičemž se nejedná jen o nějaké kosmetické úpravy (přejmenování funkce ze základní knihovny či přidání parametru do funkce), ale mnohdy o zásadní změny v syntaxi i sémantice. Z tohoto důvodu budou všechny příklady spolehlivě pracovat na verzi 1.11 (dostupná ve Fedoře 24) a taktéž ve verzi 1.12 (poslední stabilní verze vydaná před pouhými jedenácti dny).
3. Rozdíly mezi Rustem a klasickými kompilovanými jazyky (C, C++)
Jazyk Rust je orientován na tvorbu podobných nástrojů a aplikací, pro něž se v současnosti používá klasické céčko, C++ či (prozatím v mnohem menší míře) jazyk D. Největším rozdílem mezi Rustem a C/C++ je již zmíněný typový systém. Ten zajišťuje, že například nelze vytvořit neinicializovaný ukazatel, v čase překladu je možné otestovat přístup k dealokované paměti, je kontrolována správná inicializace proměnných atd. Na druhou stranu je ovšem někdy nutné v nízkoúrovňovém kódu provádět potenciálně nebezpečné operace (resp. operace, které pedantický překladač považuje za nebezpečné). I to je umožněno, a to díky existenci bloku unsafe {}. Oproti C++ je vylepšena kontrola správnosti šablon, takže s Rustem pravděpodobně soutěž o nejdelší chybové hlášení nevyhrajete. :-)
Došlo také ke zpřísnění základní syntaxe tam, kde to má smysl. Příkladem je sice dobře míněný, ale špatně zapsaný kód s přebývajícím středníkem:
int main(void)
{
int cnt = 0;
for (int i = 0; i != 10; i++);
cnt++;
return cnt;
}
V Rustu je nutné ve strukturovaných konstrukcích použít vždy bloky, a to i v případě, že je v nich jen jediný příkaz.
Došlo též k náhradě konstrukce switch-case za obecnější konstrukci match, která, kromě jiného, nevyžaduje pouhé porovnávání s konstantami, ale nabízí namísto toho plnohodnotný pattern matching.
Další změny se týkají spíše sémantiky, kterou si podrobněji popíšeme v dalším textu i v následujících pokračováních tohoto seriálu.
4. Rust versus vysokoúrovňové programovací jazyky
Rust se sice nesnaží přímo konkurovat takovým jazykům, jako je Python či Ruby, ovšem i přesto se k nim může přibližovat z pohledu produktivity i obecně bezpečnějších výsledných aplikací, než je tomu u stále zmiňované dvojice C/C++. To jsou samozřejmě jen poměrně obtížně měřitelné hodnoty, takže je nutné podobná prohlášení brát poněkud s rezervou; osobně si myslím, že například v Pythonu budete stále produktivnější (o to delší budou testy :-). Mnohem blíže má Rust spíše k programovacímu jazyku Go, který čistě náhodou vznikl ve zhruba stejné době, konkrétně v roce 2009 (lze jen spekulovat o tom, že Rust i Go vznikly příhodně ve chvíli, kdy se díky IoT dostala k nízkoúrovňovému programování skupina mladších vývojářů, kteří si neprošli klasickým kolečkem Pascal-C). Oproti Rustu však Go obsahuje i plnohodnotného automatického správce paměti se všemi výhodami ale i nevýhodami, které to v praxi přináší. Podobně je tomu i při porovnání s Javou, ovšem s tou podstatnou připomínkou, že nároky JVM jsou o několik řádů vyšší než runtime Rustu (což opět asi nebude velké překvapení).
5. Výkon aplikací naprogramovaných v Rustu
Vzhledem k poměrně silnému tvrzení, že by Rust mohl nahradit C/C++ i v těch aplikacích, kde je kritickým faktorem výkon a/nebo paměťové požadavky, není divu, že si programátoři napsali benchmarky pro potvrzení tohoto tvrzení, popř. rozšířili stávající sadu benchmarků právě o tento jazyk. Naleznete je například na adresách:
- Rust programs versus C++ g++
https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=rust&lang2=gpp - Benchmarks of different languages
https://github.com/kostya/benchmarks
Při pohledu na tyto benchmarky je nutné mít na paměti, že se testují pouze velmi krátké prográmky (mnohdy jen mikrobenchmarky), které nemusí mít mnoho společného s rozsáhlejšími aplikacemi a už vůbec ne například s dlouhodobě běžícími serverovými službami. Taktéž se zde neměří například škálovatelnost nebo různé „pozastavení“ aplikací kvůli práci garbage collectoru (to se samozřejmě netýká Rustu, ale některých s ním porovnávaných jazyků).
6. Instalace Rustu v libovolné distribuci Linuxu z dodávaného tarballu
V dalších kapitolách si již budeme ukazovat demonstrační příklady, takže si alespoň ve stručnosti popišme, jakým způsobem je možné Rust nainstalovat.
Překladač jazyka Rust i jeho podpůrné knihovny je sice možné přeložit pro různé platformy (samozřejmě včetně ARMů) a operační systémy (včetně Androidu a iOS), ovšem oficiálně dostupné jsou prozatím jen archivy (tarball atd.) či instalační balíčky (.msi) určené pro Linux běžící na platformě i686 a x86–64, Mac (na téže platformě) a MS Windows. Tyto archivy naleznete na adrese https://www.rust-lang.org/en-US/downloads.html. Ukažme si lokální instalaci na 64bitovém Linuxu. Instalaci je zde možné provést několika způsoby:
- Použitím skriptu rustup.sh
- Stažením tarballu, jeho rozbalením a ručním spuštěním instalace
- Instalací z repositářů vaší distribuce (viz též popis v další kapitole). Balíčky naleznete i pro další distribuce, například pro Debian apod.
Nejlepší je použít třetí možnost, ale jen za předpokladu, že vaše distribuce nabízí Rust verze 1.11.x či 1.12.x. Starší verze tohoto jazyka totiž nemusí být ve všech ohledech kompatibilní, neboť Rust se stále ještě poměrně bouřlivě vyvíjí.
Instalace s využitím skriptu rustup.sh je snadná, pokud tedy máte ve zvyku přímo a bez prohlédnutí spouštět skripty stažené z Internetu :-). Přepínače předané nástroji curl zajistí, že interpret shellu dostane na vstupu skutečný skript a nikoli chybové hlášení při nějakých problémech se síťovým připojením:
curl -sSf https://static.rust-lang.org/rustup.sh | sh
Druhá možnost je nepatrně, ale skutečně jen nepatrně pracnější a vyžaduje tři kroky.
1. stažení příslušného tarballu, zde konkrétně pro 64bitový Linux:
wget https://static.rust-lang.org/dist/rust-1.12.1-x86_64-unknown-linux-gnu.tar.gz
2. rozbalení tarballu:
tar xvfz rust-1.12.1-x86_64-unknown-linux-gnu.tar.gz
3. spuštění instalačního skriptu. Zde je nutné mít práva pro zápis do adresářů /usr/local a /etc, které patří rootovi:
sudo install.sh
7. Instalace Rustu na Fedoře z oficiálních balíčků
Vzhledem k tomu, že se balíček s Rustem dostal do repositářů Fedory, je na této distribuci instalace velmi jednoduchá a bezproblémová. Stačí využít nástroj dnf (popř. pro staromilce yum), a to následujícím způsobem:
# dnf install rust
Na čisté instalaci Fedory 24 se kromě Rustu (tedy překladače a podpůrných knihoven) nainstalují i některé knihovny z projektu LLVM, žádné další závislé balíčky by se neměly doinstalovávat:
Last metadata expiration check: 2:59:24 ago on Mon Oct 31 11:45:04 2016. Dependencies resolved. ================================================================================ Package Arch Version Repository Size ================================================================================ Installing: llvm-libs x86_64 3.8.0-1.fc24 Fedora 11 M rust x86_64 1.11.0-3.fc24 updates 40 M Transaction Summary ================================================================================ Install 2 Packages Total download size: 50 M Installed size: 122 M Is this ok [y/N]:
Typický průběh instalace:
Downloading Packages: (1/2): llvm-libs-3.8.0-1.fc24.x86_64.rpm 7.2 MB/s | 11 MB 00:01 (2/2): rust-1.11.0-3.fc24.x86_64.rpm 2.8 MB/s | 40 MB 00:14 -------------------------------------------------------------------------------- Total 3.2 MB/s | 50 MB 00:15 Running transaction check Transaction check succeeded. Running transaction test Transaction test succeeded. Running transaction Installing : llvm-libs-3.8.0-1.fc24.x86_64 1/2 Installing : rust-1.11.0-3.fc24.x86_64 2/2 Verifying : rust-1.11.0-3.fc24.x86_64 1/2 Verifying : llvm-libs-3.8.0-1.fc24.x86_64 2/2 Installed: llvm-libs.x86_64 3.8.0-1.fc24 rust.x86_64 1.11.0-3.fc24 Complete!
Závěrečná rychlá kontrola, zda se překladač skutečně nainstaloval:
$ rustc --version rustc 1.11.0
Povšimněte si, že se nainstalovala verze 1.11.0, zatímco poslední stabilní verze dostupná na stránkách tohoto projektu je 1.12.1. Případné problémy tedy mohou být způsobeny změnami v překladači či knihovnách, ke kterým mezi oběma verzemi došlo.
8. Syntaxe a sémantika programů napsaných v Rustu
V následujících kapitolách se seznámíme se základní syntaxí a sémantikou programů napsaných v Rustu. Nebude se v žádném případě jednat o referenční příručku, navíc některé oblasti (alespoň prozatím) zcela přeskočíme a budeme se jim podrobněji věnovat v navazujících pokračováních tohoto článku.
Pro začátek si ukažme typický školní příklad „Hello world!“ uložený v souboru hello_world.rs, v němž je deklarována funkce main bez parametrů a bez uvedení návratového typu. V této funkci se volá makro println! pro výpis řetězce na standardní výstup:
fn main() {
println!("Hello world!");
}
Překlad se provede příkazem:
rustc hello_world.rs
Výsledkem překladu je spustitelný soubor nazvaný hello_world (nikoli tedy a.out či a.exe, tohoto historického balastu se tvůrci Rustu zbavili).
9. Základní (primitivní) datové typy
Termín „primitivní datový typ“ může být pro mnoho čtenářů zpočátku poněkud matoucí, protože jeho význam se v případě programovacího jazyka Rust odlišuje například od Javy. V Javě se tímto termínem označují celočíselné typy (byte, short, int, long), číselné typy s plovoucí řádovou čárkou (float, double), pravdivostní typ boolean a typ „znak“ (char), tedy celkem pouze osm typů. V jazyce Rust se naproti tomu pod termínem „primitivní datový typ“ rozumí jakýkoli typ, který je přímo zabudován a specifikován v jazyce, takže záběr je zde větší (spadají sem například i funkce).
Všechny v současnosti podporované primitivní datové typy jsou vypsány v následující tabulce. Povšimněte si především toho, jak se striktně a nezávisle na platformě rozlišují celá čísla s různou bitovou šířkou, že typ char zde má šířku 32 bitů (na rozdíl od Javy, kde je char vlastně pro uložení kódu znaku nedostatečný a jde jen o „půlznak“) a že mezi základní typy patří i pole, seznam pevné délky (tedy n-tice) a funkce:
| bool | může (nepřekvapivě) nabývat hodnot true nebo false |
| char | reprezentuje znak v Unicode (interně má šířku čtyři bajty) |
| i8 | celé číslo se znaménkem (signed) o šířce 8 bitů |
| i16 | celé číslo se znaménkem (signed) o šířce 16 bitů |
| i32 | celé číslo se znaménkem (signed) o šířce 32 bitů |
| i64 | celé číslo se znaménkem (signed) o šířce 64 bitů |
| u8 | celé číslo bez znaménka (unsigned) o šířce 8 bitů |
| u16 | celé číslo bez znaménka (unsigned) o šířce 16 bitů |
| u32 | celé číslo bez znaménka (unsigned) o šířce 32 bitů |
| u64 | celé číslo bez znaménka (unsigned) o šířce 64 bitů |
| isize | celé číslo se znaménkem odpovídající šířce ukazatele |
| usize | celé číslo bez znaménka odpovídající šířce ukazatele |
| f32 | 32bitové číslo reprezentované v systému plovoucí řádové čárky (single, float) |
| f64 | 64bitové číslo reprezentované v systému plovoucí řádové čárky (double) |
| array | pole (implicitně neměnné) |
| slice | v podstatě „pohled“ na vybranou část pole |
| str | jeden z několika datových typů pro reprezentaci řetězců |
| tuple | seznam pevné délky, má v jazyku mnoho použití |
| funkce | funkce jsou zde plnohodnotným datovým typem |
Přesný význam posledních pěti typů, které jsou nejzajímavější, si řekneme příště.
10. Řetězce aneb překvapivě rozsáhlá problematika
V jazyku Rust jsou řetězce interně ukládány s využitím kódování UTF-8, což sice může znít překvapivě, ovšem přináší to i některé výhody. Autoři tohoto jazyka správně poukazují na to, že v současnosti prakticky všechny webové služby, XML soubory, velká část HTML stránek atd. stejně kódování UTF-8 používají, takže nemá význam neustále provádět konverzi mezi tímto kódováním a například UCS-4 (UTF-32). Navíc je při zpracování rozsáhlých XML souborů formát UTF-8 výhodnější z hlediska spotřeby operační paměti. Největší nevýhodou použití UTF-8 je nemožnost získat a vrátit n-tý znak v řetězci v konstantním čase. Pokud by se tato operace prováděla velmi často, lze samozřejmě použít vhodný objekt, který například „obaluje“ pole čtyřbajtových širokých znaků v UCS-4/UTF-32.
Mimochodem: řešení založené na formátu UTF-16, které částečně používá například Java, je vlastně polovičaté a přináší ty horší vlastnosti z obou světů – znaky jsou stále ukládány v proměnném počtu bajtů, ale spotřeba paměti je u běžných řetězců (konfigurační soubory, angličtina…) v porovnání s UTF-8 dvojnásobná.
Poznámka: existují i speciální typy nazvané CStr, CString, OsStr a OsString, které nabízí reprezentaci řetězců ve formátu kompatibilním s céčkem (což je nutné při použití FFI neboli foreign function interface, dnes de facto standardního rozhraní pro volání funkcí naprogramovaných v odlišném programovacím jazyce), resp. s použitou platformou. Podrobnostem bude věnován samostatný článek.
11. Neměnitelné hodnoty a jejich význam při tvorbě a ladění aplikací
Jazyk Rust poměrně striktně rozlišuje mezi měnitelnými a neměnitelnými proměnnými. Například následující kód je po syntaktické stránce naprosto v pořádku, ale přesto se ho nepodaří přeložit. V kódu je deklarována lokální neměnitelná proměnná i, s tím, že si její typ odvodí překladač (type inference). Následně se v programové smyčce snažíme postupně měnit hodnotu této proměnné a vypisovat ji na standardní výstup makrem println!:
fn main() {
let i = 0;
while i<10 {
println!("pocitadlo: {}", i);
i = i + 1;
}
}
Pokusme se o překlad:
rustc while_loop.rs
Překladač by měl vypsat následující chybové hlášení:
while_loop.rs:5:9: 5:18 error: re-assignment of immutable variable `i` [E0384]
while_loop.rs:5 i = i + 1;
^~~~~~~~~
while_loop.rs:5:9: 5:18 help: run `rustc --explain E0384` to see a detailed explanation
while_loop.rs:2:9: 2:10 note: prior assignment occurs here
while_loop.rs:2 let i = 0;
^
error: aborting due to previous error
Pokud explicitně vyžadujeme použití měnitelné (mutable) proměnné, je nutné deklaraci provést takto:
fn main() {
let mut i = 0;
while i<10 {
println!("pocitadlo: {}", i);
i = i + 1;
}
}
Poznámka: použití neměnitelných proměnných má svůj význam, protože immutable proměnné lze bez problémů použít v jiném vláknu, program se snadněji testuje (menší stavový prostor), překladač může provádět agresivnější optimalizace atd. Zajímavé je, že – podobně jako v některých FP jazycích – jsou v Rustu proměnné ve výchozím stavu immutable a ne naopak.
Poznámka 2: povšimněte si, že okolo podmínek se nemusí psát kulaté závorky.
12. Kontrola operací prováděných s proměnnými různých typů
Předchozí zdrojový kód byl přeložen v pořádku z toho důvodu, že si překladač dovedl odvodit typ proměnné i z hodnoty, kterou je proměnná inicializována. V případě potřeby je však možné typ uvést i explicitně, například takto (použijeme 32bitové celé číslo se znaménkem):
fn main() {
let mut i:i32 = 0;
while i<200 {
println!("pocitadlo: {}", i);
i = i + 1;
}
}
Podívejme se nyní, co se stane, když ve zdrojovém kódu budeme specifikovat, že typ proměnné i je osmibitové celé číslo se znaménkem:
fn main() {
let mut i:i8 = 0;
while i<200 {
println!("pocitadlo: {}", i);
i = i + 1;
}
}
Překladač není příliš spokojen, protože porovnáváme hodnotu –128..127 s konstantou 200:
while_loop.rs:3:11: 3:16 warning: comparison is useless due to type limits, #[warn(unused_comparisons)] on by default
while_loop.rs:3 while i<200 {
^~~~~
while_loop.rs:3:13: 3:16 warning: literal out of range for i8, #[warn(overflowing_literals)] on by default
while_loop.rs:3 while i<200 {
Naproti tomu překladač céčka následující (sémanticky prakticky totožný) zdrojový kód přeloží bez problémů:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
signed char i = 0;
while (i<200) {
printf("%d\n", i);
i++;
}
return 0;
Otázka pro čtenáře: jak se vlastně bude tento program chovat při překladu na architektuře i386 či x86–64? Dá se předpokládat (za jakých okolností), že na jiných architekturách bude chování odlišné? A specifikuje takové chování norma ANSI C?
13. Základní řídicí struktury vs výrazy
Zajímavé je, že sémantika řídicí struktury if-else se oproti C/C++ změnila, protože nyní je celá tato struktura výrazem, což znamená, že její výsledek lze přiřadit do proměnné, předat volané funkci, použít ve složitějším výrazu (což bude poněkud nepřehledné) atd. Jedná se tak vlastně o alternativu k mnohdy ne příliš čitelnému ternárnímu operátoru ?:. Ostatně se podívejme na jednoduchý příklad, v němž se do lokální proměnné value_type přiřazuje řetězec (typ proměnné je opět automaticky odvozen překladačem):
fn if_expression(value:i32) {
let value_type =
if value < 0 {
"zaporna"
}
else {
if value == 0 {
"nulova"
}
else {
"kladna"
}
};
println!("Hodnota {} je {}", value, value_type);
}
fn main() {
if_expression(0);
if_expression(10);
if_expression(-10);
}
Po překladu a spuštění dostaneme očekávaný výsledek:
Hodnota 0 je nulova Hodnota 10 je kladna Hodnota -10 je zaporna
Zkusme nyní změnit typ parametru value z celého čísla se znaménkem na číslo bez znaménka:
fn if_expression(value:u32) {
let value_type =
if value < 0 {
"zaporna"
}
else {
if value == 0 {
"nulova"
}
else {
"kladna"
}
};
println!("Hodnota {} je {}", value, value_type);
}
fn main() {
if_expression(0);
if_expression(10);
if_expression(-10);
}
Překladač nyní podle očekávání ohlásí chybu:
if_expression.rs:20:19: 20:22 error: unary negation of unsigned integer
if_expression.rs:20 if_expression(-10);
^~~
error: aborting due to previous error
Pokud pouze zakomentujeme zmíněný řádek:
fn main() {
if_expression(0);
if_expression(10);
// if_expression(-10);
}
Stále nebude překladač zcela spokojen, protože se v podmínce provádí porovnání kladné (či nulové) hodnoty s nulou v relaci „je ostře menší než“:
if_expression.rs:3:8: 3:17 warning: comparison is useless due to type limits, #[warn(unused_comparisons)] on by default
if_expression.rs:3 if value < 0 {
14. Programové smyčky loop a while
V jazyce Rust nalezneme několik typů programových smyček. Nejjednodušší je smyčka loop, která je nekonečná, což znamená, že v Rustu nemusíme provádět triky typu while(1) či for (;;). Nekonečnou smyčku lze opustit příkazem break:
fn main() {
let mut i = 0;
loop {
println!("pocitadlo: {}", i);
i = i + 1;
if i >= 10 {
break;
}
}
}
Druhá smyčka typu while s testem na začátku již byla ukázána v předchozích kapitolách.
Poznámka: smyčka typu do-while sice v Rustu není implementována, ale existují způsoby, jak ji v případě potřeby simulovat smyčkou while. Celý trik spočívá v tom, že i blok {} je výrazem (vrací se poslední vypočtená hodnota), takže lze vytvořit smyčku s prázdným tělem a naopak podmínkou tvořenou programovým blokem. Vypadá to divně, nikdo to pravděpodobně nepoužívá, ale ukazují se zde další vlastnosti Rustu.
15. Programová smyčka for a iterátory
Zajímavá a především užitečná je smyčka typu for, která se syntakticky i sémanticky podobá podobně pojmenované smyčce z Pythonu. Tuto smyčku lze využít pro iteraci nad libovolným iterátorem, což je objekt s metodou .next() (k dispozici jsou ovšem i další metody jako .skip(n) a .take(n)). Mezi iterátory patří i typ range, který lze vytvořit zápisem min..max. Podívejme se na velmi jednoduchý příklad se smyčkou typu for:
fn main() {
for i in 1..10 {
println!("pocitadlo: {}", i)
}
}
Po spuštění snadno zjistíme, že se smyčka provede pro hodnoty od min (včetně) do max (kromě):
pocitadlo: 1 pocitadlo: 2 pocitadlo: 3 pocitadlo: 4 pocitadlo: 5 pocitadlo: 6 pocitadlo: 7 pocitadlo: 8 pocitadlo: 9
Prozatím jen experimentálně byla do jazyka přidána i podpora pro zápis min…max (se třemi tečkami), specifikující iterátor procházející oběma mezemi (tedy včetně min i max).

Iterovat lze ale například i přes všechny prvky vektoru:
let vektor = vec![1, 2, 3, 4];
for i in &vektor {
println!("{}", i);
}
Nepatrnou úpravou zdrojového kódu lze metodou .iter() získat iterátor i pro pole a procházet tak všemi prvky pole:
let array = [1, 2, 3, 4];
for i in array.iter() {
println!("{}", i);
}
16. Odkazy na Internetu
- Rust – home page
https://www.rust-lang.org/en-US/ - Rust – Frequently Asked Questions
https://www.rust-lang.org/en-US/faq.html - The Rust Programming Language
https://doc.rust-lang.org/book/ - Rust (programming language)
https://en.wikipedia.org/wiki/Rust_%28programming_language%29 - Go – home page
https://golang.org/ - Stack Overflow – Most Loved, Dreaded, and Wanted language
https://stackoverflow.com/research/developer-survey-2016#technology-most-loved-dreaded-and-wanted - Rust vs Go (dva roky staré hodnocení, od té doby došlo k posunům v obou jazycích)
http://jaredforsyth.com/2014/03/22/rust-vs-go/ - Rust vs Go: My experience
https://www.reddit.com/r/golang/comments/21m6jq/rust_vs_go_my_experience/ - Friends of Rust (Organizations running Rust in production)
https://www.rust-lang.org/en-US/friends.html - Rust programs versus C++ g++
https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=rust&lang2=gpp - Další benchmarky (nejedná se o reálné příklady „ze života“)
https://github.com/kostya/benchmarks - Go na Redditu
https://www.reddit.com/r/golang/ - Rust vs. Go
http://vschart.com/compare/rust/vs/go-language - Abstraction without overhead: traits in Rust
https://blog.rust-lang.org/2015/05/11/traits.html - Of the emerging systems languages Rust, D, Go and Nim, which is the strongest language and why?
https://www.quora.com/Of-the-emerging-systems-languages-Rust-D-Go-and-Nim-which-is-the-strongest-language-and-why - Chytré ukazatele (moderní verze jazyka C++) [MSDN]
https://msdn.microsoft.com/cs-cz/library/hh279674.aspx - UTF-8 Everywhere
http://utf8everywhere.org/ - Rust by Example
http://rustbyexample.com/ - Rust oficiálně ve Fedoře
https://mojefedora.cz/rust-oficialne-ve-fedore/ - Resource acquisition is initialization
https://en.wikipedia.org/wiki/Resource_acquisition_is_initialization - TIOBE index (October 2016)
http://www.tiobe.com/tiobe-index/ - Porovnání Go, D a Rustu na OpenHubu:
https://www.openhub.net/languages/compare?language_name[]=-1&language_name[]=-1&language_name[]=dmd&language_name[]=golang&language_name[]=rust&language_name[]=-1&measure=commits - String Types in Rust
http://www.suspectsemantics.com/blog/2016/03/27/string-types-in-rust/




































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU