Ještě, než se pustíme do vlastní práce s novými funkcemi PG, tak si je jenom krátce představíme. Abychom nemuseli nosit dříví do lesa, tak pouze odkazem na již existující prameny včetně nejnovější verze PG:
DB Stored Procedure, PG Function, PL/pgSQL
Co tedy bude konkrétně naším cílem (samozřejmě prostřednictvím PG funkcí):
- vytvoříme čtyři nové PG funkce
- pomocí první funkce si vytvoříme dvě nové tabulky
- nové tabulky naplníme daty ze stávající tabulky a daty náhodně generovanými
- ve druhé funkci vytvoříme tři nové pohledy
- ve třetí funkci definujeme několik operací nad tabulkou
- ve čtvrté funkci definujeme příkaz pro smazání záznamu na základě zadaných kritérií
- vytvoříme procedury a funkce JavaFX, které nám umožní nové funkce PG volat a využívat jejich vlastnosti
Opět jako již dříve zde upozorníme, že náš seriál není tutoriálem pro tvorbu PG funkcí, takže některé příkazy nebudeme podrobněji komentovat. S tímto upozorněním přikročíme k vytvoření první uvedené funkce. Její kompletní kód je v příloze initData.sql. V této funkce bude použit procedurální jazyk PL/pgSQL a bude se skládat ze dvou částí. V první z nich si vytvoříme dvě nové tabulky. Abychom nemuseli složitě popisovat jejich strukturu, tak uvedeme konkrétní kód:
EXECUTE 'DROP TABLE IF EXISTS udaje CASCADE;'; EXECUTE 'DROP TABLE IF EXISTS pocty CASCADE;'; EXECUTE 'CREATE TABLE udaje ( id smallint NOT NULL, celecis integer NOT NULL, descis numeric (12,2) NOT NULL, maledes numeric (8,6) NOT NULL, retezec character (32) NOT NULL, datum date NOT NULL, CONSTRAINT udaje_id UNIQUE(id)) WITH (OIDS=FALSE);'; EXECUTE 'CREATE TABLE pocty ( kod character(6), pocet integer, CONSTRAINT pocty_kod UNIQUE(kod)) WITH (OIDS=FALSE);';
První dva příkazy odstraňují uvedené tabulky, pokud tyto již existují. Další dva příkazy obě tabulky vytvářejí. Toto řešení je zvoleno proto, aby se daná PG funkce mohla spouštět opakovaně dle potřeby. V dalším kroku jsou použity údaje ze stávající tabulky obce, ty jsou uložené do nově vytvořené tabulky a druhý sloupec této tabulky je doplněn o náhodně generovaná celá čísla:
FOR rec IN SELECT kod FROM obce LOOP sid = (random() * 100000)::integer + 1000; INSERT INTO pocty VALUES (rec.kod,sid); END LOOP;
Poslední krok pak naplní druhou novou tabulku náhodně generovanými daty různých typů:
FOR i IN 1..25 LOOP sid = (random() * 250)::integer + 10; fid = (random() * 250) + 10; str = md5(random()::text); dat = date (now() + trunc (random() * 365) * '1 day'::interval); INSERT INTO udaje VALUES (i, sid, fid, fid / 1000000, str, dat); END LOOP;
Nově vytvořenou tabulku udaje použijeme v další PG funkci a vytvoříme si tři pohledy. Je to ukázka toho, jak je možné použít pohled pro zobrazení sumárních dat nebo složitějších dotazů. V našem konkrétním příkladu jsou v tabulce pocty uloženy kódy obcí z příslušné tabulky a ve druhém sloupci pak celá čísla (čistě náhodná, bez návaznosti na realitu!), která budou představovat počet obyvatel jednotlivých obcí. Příslušná procedura je v příloze initView.sql. Zde je použit jazyk SQL, takže jenom upozorníme na rozdíly v provádění výkonných příkazů oproti předešlé funkci v jazyce PL/pgSQL:
CREATE OR REPLACE VIEW pohled1 AS SELECT o.*, p.pocet FROM obce o, pocty p WHERE o.kod=p.kod ORDER BY o.ckraje;
Tento pohled zobrazí všechny původní data z tabulky obce a k nim přiřadí příslušný počet obyvatel dané obce z tabulky pocty. Výpis je seřazen podle čísla kraje.
CREATE OR REPLACE VIEW pohled2 AS SELECT o.ckraje, o.kraj, o.cokresu, o.okres, sum(p.pocet) FROM obce o, pocty p WHERE o.kod=p.kod GROUP BY o.ckraje, o.kraj, o.cokresu, o.okres ORDER BY o.ckraje, o.cokresu;
Druhý pohled ukazuje součet počtu obyvatel pro jednotlivé okresy, řazení je podle čísla kraje a okresu.
CREATE OR REPLACE VIEW pohled3 AS SELECT o.ckraje, o.kraj, sum(p.pocet) FROM obce o, pocty p WHERE o.kod=p.kod GROUP BY o.ckraje, o.kraj ORDER BY o.ckraje;
Poslední pohled ukazuje součet počtu obyvatel pro jednotlivé kraje, řazení je podle čísla kraje. Poslední PG funkce se bude od těch předchozích lišit v několika věcech. První z nich už je samotný začátek, kde jsou kromě názvu definované i parametry volání a také typ návratové hodnoty:
CREATE OR REPLACE FUNCTION intCount ( tabname character varying, colname character varying, type integer) RETURNS integer AS
Jak je z předchozího kódu vidět, parametrem je zde název tabulky, název sloupce a typ akce, který má PG funkce provést. Pak následují dva příkazy, které jsme zatím nepoužili. První z nich na základě parametru typu akce rozhodne, která se vlastně bude provádět:
CASE
WHEN type=0 THEN EXECUTE 'SELECT max (' || quote_ident(colname) || ') FROM ' || quote_ident(tabname)::regclass INTO ret;
WHEN type=1 THEN EXECUTE 'SELECT min (' || quote_ident(colname) || ') FROM ' || quote_ident(tabname)::regclass INTO ret;
WHEN type=2 THEN EXECUTE 'SELECT count (' || quote_ident(colname) || ') FROM ' || quote_ident(tabname)::regclass INTO ret;
WHEN type=3 THEN EXECUTE 'SELECT sum (' || quote_ident(colname) || ') FROM ' || quote_ident(tabname)::regclass INTO ret;
END CASE;
Jak je z kódu patrné, všechny čtyři akce jsou poměrně jednoduché: za použití funkcí MAX, MIN, COUNT, SUM předávají odpovídající hodnotu ze zadané tabulky a sloupce. Pak následuje další příkaz, který jsme ještě neviděli. Ten souvisí s tím, že tato funkce vrací nějakou (konkrétně celočíselnou) návratovou hodnotu:
RETURN ret;
Celý kód funkce je v příloze initCount.sql. Poslední funkce provádí mazání záznamu ze zadané tabulky, který je definován názvem příslušného sloupce a hodnotou, která se má pro smazání vybrat. Je to vlastně obdoba klasického SQL příkazu:
DELETE FROM tablename WHERE columnname = value;
Kód funkce pak vypadá následovně:
CREATE OR REPLACE FUNCTION delrow(tablename character varying, colname character varying, item integer) RETURNS void AS $BODY$ BEGIN EXECUTE ''DELETE FROM '' || quote_ident(tablename)::regclass || '' WHERE '' || quote_ident(colname) || ''=$1'' USING item; END; $BODY$ LANGUAGE plpgsql VOLATILE COST 100;
Na závěr jenom upozornění na to, že v obou posledních funkcích byly použity příkazy, které jsou pro PG funkce doporučované a které zajistí vysokou bezpečnost a odolnost výkonných akcí proti snaze o vložení potenciálně nebezpečného kódu, např. SQL Injection. Kód poslední funkce je pak v příloze delRow.sql.
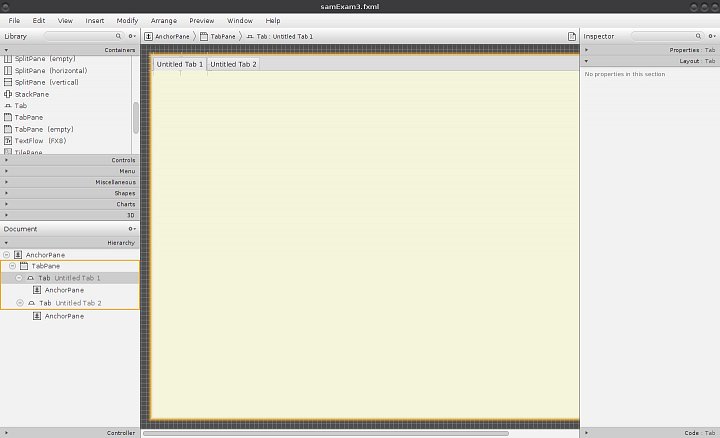
Všechny potřebné PG funkce už máme připravené a můžeme se pustit do ukázky, jak je propojit s JavaFX aplikací. Vytvoříme si proto další zkušební formulář a ukážeme si na něm nejen možnosti volání PG funkcí, ale také další zajímavé GUI widgety. Nový formulář nazveme podle očekávání samExam3.fxml a uložíme ho do adresáře GUI-Files. Vložíme do něj kořenový kontejner AnchorPane, zvětšíme jeho velikost na 1000 × 730 bodů a přidáme CSS soubor. Tím dostaneme základ pro další práci. V daném případě si zobrazíme data, pro která jsme si vytvořili pohledy. Vzhledem k tomu, že máme tři pohledy, tak si ukážeme vlastně tři tabulky. Bylo by samozřejmě možné použít pro tento účel tři samostatné formuláře, ale je to asi zbytečné. Proto využijeme další z nabídky widgetů – ve skupině Containers jsou dokonce dva – TabPane a TabPane (empty). My použijeme ten první jmenovaný a umístíme ho do kořenového kontejneru. Jak to vypadá po jeho umístění a zvětšení nám ukazuje první obrázek galerie. Jak je z obrázku patrné, vznikly nám automaticky dvě záložky s nějakým názvem a každá z nich obsahuje svůj kořenový kontejner. My si zvýšíme počet záložek na tři pravým klikem na titulek první záložky a volbou Duplicate. Následně změníme nadpisy záložek tak, jak nám to ukazuje druhý obrázek v galerii.
Následně si do každé záložky přidáme widget SplitPane (horizontal), zvětšíme je na maximum a nastavíme tak, aby nahoře bylo 10% výšky (Divider Position = 0.1). Do spodních kontejnerů si vložíme widget TableView (není třeba se obávat, nezapomněli jsme na widget ScrollPane!). Při této příležitosti si ukážeme, jak se dají také widgety přidávat. Třeba v levém sloupci hierarchie widgetů si klikneme pravým tlačítkem a vybere možnost Wrap in a z nabídnutého seznamu pak ScrollPane (opačně to pak lze provést pomocí volby Unwrap). A tabulka se nám poslušně přesune do vybraného typu kontejneru! Uděláme to samozřejmě pro všechny tři tabulky a také nastavíme příslušný počet sloupců (5, 4 a 3). Nakonec provedeme pojmenování tabulek a sloupců podle minulého příkladu (nebudeme vymýšlet nic složitého a tabulkám dáme názvy table1 – table3 a sloupcům col11 – col33). Do všech záložek (do horní části SplitPane) také musíme přidat tlačítka pro spuštění akce, doplnit jejich názvy a názvy akcí. Úplně nakonec přidáme název třídy kontroléru (jfxapp.samexam3) a celý formulář uložíme.
Známým způsobem necháme vygenerovat kostru kontroléru (Full), v IJI vytvoříme novou třídu samexam3.java a kód do ní vložíme. Do třídy mainForm přidáme další proceduru pro otevření nového formuláře a k příslušnému tlačítku doplníme její volání. Pak můžeme zkusit aplikaci spustit a nové okno otevřít. Výsledek pak ukazuje třetí obrázek galerie. Zkusíme si ještě otevřít soubor main.css a přidat jeden řádek:
.tab-label {-fx-font-size: 13pt; -fx-font-weight: bold;}
Jak se změnil výsledný vzhled nového okna ukazuje čtvrtý obrázek v galerii. Jak se zdá, máme vše připravené k tomu, abychom mohli pomocí tlačítek zobrazit data. Zdání ale jako obvykle klame, a tak máme před sebou dva problémy:
- pro zobrazení dat nebudeme používat přímo tabulku, ale vytvořené pohledy. A ty jsme ještě nevolali, takže vlastně nevíme jak na to.
- pro zobrazení dat budeme potřebovat nejenom pohledy, ale také tabulky, ze kterých pohledy čerpají data. Původní tabulku obce máme samozřejmě k dispozici, ale jak je to vlastně s tabulkou pocty?
První problém je velmi jednoduchý a jednoduše řešitelný: v dotazu, kterým jsme v předchozích příkladech získávali data přímo z tabulek, jenom nahradíme název tabulky názvem příslušného pohledu. Kdo chce, může si to samozřejmě vyzkoušet přímo v PG, kdy stačí zadat dotaz typu
select * from pohled1;
Druhý problém je nutné trochu více rozebrat. V předchozí činnosti jsme vytvořili celkem 4 PG funkce. K našemu aktuálnímu příkladu se vztahují dvě z nich – initData vytvoří tabulku pocty a naplní ji náhodnými daty. PG funkce initView pak vytvoří tři pohledy. Z tohoto úhlu se zdá vše v pořádku. Ale ono to v pořádku být nemusí! Záleží totiž na tom, jestli jsme PG funkce nejen vytvořili (spustili příslušný dotaz, který je přiřadí do hierarchie databázových objektů), ale také spustili! Vytvoření funkce je samozřejmě nutnou podmínkou, spuštění funkce už ale nikoliv… Zkusíme si to předvést na příkladu. Vezměme situaci, kdy máme vytvořené PG funkce, které ale nebyly nikdy spuštěné. Tím pádem neexistují ani tabulka pocty, ani tři pohledy. Tím pádem nám krachne už spuštění dotazu na pohled, protože tento jaksi neexistuje. Pokud bychom spustili PG funkci initView, tak se pohledy vytvoří a jdou samozřejmě také zavolat. Problém ale nastane v samotném provádění dotazu v pohledu vzhledem k neexistenci tabulky pocty (a na tu se dotaz v konstrukci pohledu odkazuje).
Pokud se na celou věc podíváme z pohledu uživatele aplikace, tak ten o databázi vlastně nic neví a když se to tak vezme, tak by k ní neměl mít ani žádný přímý přístup. Řešení se tedy nabízí dvoje:
- vše ponechat na administrátorovi/správci aplikace nebo prostě někom, kdo zajistí aktuální stav databáze tak, aby bylo vše v pořádku
- přímo v aplikaci testovat, jestli je vše OK a podle toho rozhodnout, jestli je třeba PG funkce spustit či nikoliv.
Pro naše účely samozřejmě připadá v úvahu pouze druhá varianta, abychom si ukázali další možnosti spolupráce JavaFX aplikace a PG. Z tohoto důvodu si vytvoříme třístupňovou kontrolu tak, abychom vždy mohli použít nejvhodnější řešení. Stupně kontroly budou následující:
- zjistíme, jestli máme k dispozici obě potřebné PG funkce (initData a initView). Pokud jedna z nich nebude v databázi k dispozici, aplikace se ukončí
- zkontrolujeme přítomnost jednoho ze tří pohledů. Pokud nebude k dispozici, tak spustíme příslušnou PG funkce. Kontrola jednoho stačí, protože spuštěním PG funkce se vytvoří všechny tři
- ověříme přítomnost tabulky pocty. Pokud není k dispozici, spustíme příslušnou PG funkci
Kód umístíme do procedury, která se spouští při otevření formuláře. Znovu použijeme již dříve probíraná dialogová okna a ukážeme si tři nové věci: volání PG funkcí, zobrazení dat z pohledů a také několik zajímavých funkcí, které nám pomohou zkontrolovat přítomnost různých součástí PG. Jako první provedeme kontrolu přítomnosti PG funkcí v databázi. K tomu využijeme systémovou funkci pg_proc. Dále použijeme obecnější možnost dotazu, který vrací přímo logickou proměnnou: funkce EXISTS. Konkrétně budeme potřebovat k vyhodnocení nějakou aplikační funkci, která provede příslušný dotaz do databáze a vrátí logickou hodnotu. Začneme tedy tím, že si vytvoříme dvě privátní proměnné, kam uložíme dotazy na přítomnost obou PG funkcí:
private String checkF1 = "SELECT EXISTS ( SELECT 1 FROM pg_proc WHERE proname = 'initview');"; private String checkF2 = "SELECT EXISTS ( SELECT 1 FROM pg_proc WHERE proname = 'initdata');";
Pak vytvoříme funkci, která bude volat dotazy a vrátí logickou hodnotu. Funkce je velmi podobná těm již dříve použitým, takže uvedeme pouze její deklaraci, návratovou proměnnou a výkonný příkaz:
private boolean checkItem (final String query) {
boolean item = false;
while (rs.next()) { item = rs.getBoolean(1); }
return item;
Abychom mohli vytvořit konečnou proceduru na ověření PG funkcí, musíme do aktuální třídy z těch předchozích zkopírovat deklarace proměnných (CONN, host, nform2) a procedury pro přihlášení k databázi, ověření jeho úspěšnosti a obě volání dialogových oken (conDB, logOK, dialogMessage, questMessage). Pak již můžeme přejít do procedury initialize a provést první z uvedených kontrol:
@FXML void initialize() {
if(logOK()) { //1
if (!checkItem(checkF1) || !checkItem(checkF2)) { //2
dialogMessage("Jedna nebo obě potřebné PG funkce nejsou k dispozici. Aplikace bude ukončena!","Kontrola PG funkcí",'E'); //3
Platform.exit(); //4
}
else { dialogMessage("Obě potřebné funkce jsou v databázi k dispozici","Kontrola PG funkcí",'I'); //5
}
}
else { System.out.println("FALSE"); Platform.exit(); } } //6
Očíslované jsou pouze výkonné řádky, takže si je krátce popíšeme:
- 1 – kontroluje se správné přihlášení do databáze. Pokud je úspěšné, pokračuje se na dalším řádku
- 2 – kontroluje se nepřítomnost obou PG funkcí pomocí negací a operátoru OR
- 3 – pokud jedna z funkcí není k dispozici, objeví se dialogové okno s chybou
- 4 – po zavření dialogového okna se ukončí aplikace
- 5 – pokud jsou obě funkce nalezené, objeví se oznamovací dialogové okno. Po jeho zavření se otevře formulář
- 6 – pokud se nepodaří přihlásit k databázi, tak se aplikace opět ukončí
Jako první případ budeme předpokládat, že jsou obě PG funkce k dispozici (a raději ověříme, jestli opravu jsou), aplikaci přeložíme a spustíme. Při otevření příslušného formuláře se nám objeví dialogové okno, které je vidět na předposledním obrázku galerie. Můžeme zkusit ověřit i druhou variantu, kdy kontrola jednu z funkcí nenalezne. Pokud nechceme mazat a znovu přidávat některou z funkcí přímo v databázi, můžeme situaci simulovat „poškozením“ jejího názvu v dotazu, např. takto:

private String checkF1 = "SELECT EXISTS ( SELECT 1 FROM pg_proc WHERE proname = 'initviewer');";
Pak můžeme vyzkoušet, jak otevření formuláře vypadá. Objeví se dialog, jak to ukazuje poslední obrázek v galerii a po jeho ukončení se ukončí i aplikace. První krok tedy máme vyřešený a můžeme se pustit do dalších dvou. To si ale necháme až na příští díl. Dosavadní kód je v příloze samexam3.java.
V dnešním dílu jsme se věnovali pokročilejším funkcím PG jako jsou pohledy a uložené procedury. Díl byl zakončen ukázkou, jak tyto funkce využít v rámci aplikace JavaFX, i když zatím pouze okrajově. V příštím dílu ukončíme kontrolu a ukážeme si zobrazení tabulkových dat pomocí pohledů.



































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU