
Obsah
1. RISCové mikroprocesory s komprimovanými instrukčními sadami
2. Stručná charakteristika „klasických“ RISCových architektur
3. Přednosti „klasických“ RISCových architektur
4. Přechod do světa embedded CPU a mikrořadičů
6. Způsoby přepínání mezi klasickou a komprimovanou instrukční sadou
8. Pracovní a speciální registry používané v instrukční sadě MIPS16e
10. Podmíněné skoky v instrukční sadě MIPS16e
11. Seznam instrukcí v sadě MIPS16e
1. RISCové mikroprocesory s komprimovanými instrukčními sadami
Již v několika článcích, v nichž jsme se věnovali problematice mikroprocesorových jader s architekturou RISC, jsme se zmínili o použití těchto mikroprocesorů v různých embedded zařízeních, mikrořadičích (MCU) či SoC (System on Chip). Tato aplikační oblast se hned v několika ohledech liší od oblasti, pro kterou byla původní „klasická“ RISCová architektura navržena, tj. pro výkonné pracovní stanice, servery a počítače specializované na provádění rychlých výpočtů. Právě z tohoto určitého rozporu v použití procesorů RISC v současnosti plyne i snaha použít v moderních RISC různé „komprimované“ instrukční sady, což je označení pro takové instrukční sady (či mnohem častěji doplnění původních instrukčních sad), v nichž se vyskytují instrukce s kratšími instrukčními slovy o šířce šestnáct bitů, zatímco klasické RISCové architektury používají 32bitová instrukční slova. V dnešním článku i navazujícím článku se zmíníme o některých vlastnostech komprimovaných instrukčních sad MIPS16e, ARM Thumb a RISC-V „C“.

Obrázek 1: Jedna z prvních verzí v minulosti velmi oblíbeného osmibitového mikroprocesoru Zilog Z80 s komplexní instrukční sadou (CISC).
2. Stručná charakteristika „klasických“ RISCových architektur
Při zpětném pohledu do historie mikroprocesorů a jejich instrukčních sad je zajímavé si položit otázku, co vlastně vedlo ke vzniku architektury RISC, když minimálně první tři generace mikroprocesorů byly většinou založeny na mikroprogramovém řadiči a CISC instrukcích s mnohdy velmi komplikovaným kódováním a chováním, které (alespoň teoreticky) mohly přiblížit assembler k vyšším programovacím jazykům.

Obrázek 2: I 32bitový mikroprocesor AMD 386DX je typickým zástupcem mikroprocesorů s komplexní instrukční sadou – CISC.
Na základě několika paralelně běžících výzkumů provedených jak v akademických institucích, tak i například vedených interně ve firmě IBM a CDC se zjistilo, že většina vývojářů programujících v assembleru a navíc i naprostá většina tehdejších překladačů nevyužívá ani zdaleka všechny dostupné instrukce a jejich adresní režimy – na mnoha platformách se využívalo přibližně jen 30% všech možných instrukčních kódů. Konstruktéři procesorů, resp. přesněji řečeno návrháři instrukčních sad si uvědomili, že investice do složitého procesoru typu CISC je vlastně v mnoha případech zbytečná, protože jeho velká část zůstane nevyužita. Navíc byly CISC procesory kvůli mikroprogramovému řadiči poměrně složité (i když mnohem méně složité, než v případě použití obvodového řadiče) a tak se některé firmy i akademické instituce začaly poohlížet po odlišné konstrukci procesorů – tyto procesory byly teprve o několik let později souhrnně označeny zkratkou RISC neboli Reduced Instruction Set Code (v některých případech se tato zkratka taktéž používala ve významu Reduced Instruction Set Computer).

Obrázek 3: Mikroprocesor PA RISC firmy Hewlett-Packard, který je zde zobrazen spolu s dalšími podpůrnými obvody a paměťmi cache.
Zatímco při návrhu procesorů typu CISC se jejich konstruktéři řídili filozofií „more is better“ (asi nejvíce se tato koncepce uplatnila v SYMBOL Machine), začala se v případě procesorů typu RISC uplatňovat přesně opačná filozofie „less is better“. Mělo se tedy jednat o procesory s jednoduchou interní architekturou a malým množstvím instrukcí. Mnohdy byla instrukční sada osekána pouze na 32 instrukcí, zatímco u procesorů CISC se v některých případech jednalo i o stovky více či méně složitých instrukcí s mnoha adresními režimy. Ovšem z toho, že procesory RISC mají jednoduchou architekturu a velmi malý instrukční soubor v žádném případě nevyplývá, že by byly méně výkonné, než procesory CISC vyráběné porovnatelnou technologií. Ve skutečnosti tomu bylo právě naopak, protože první komerčně dostupné mikroprocesory RISC měly vyšší výpočetní rychlost než jakékoli v té době dostupné mikroprocesory CISC. Důvodů pro tuto vysokou výkonnost je více; o některých z nich se zmíníme v následující kapitole.

Obrázek 4: Mikroprocesor s instrukční sadou MIPS. Čipy obsahující jádra těchto RISCových mikroprocesorů se dnes používají v mnoha vestavěných zařízeních, například přehrávačích videa, routerech atd.
3. Přednosti „klasických“ RISCových architektur
První vlastností, která nejvíce odlišuje původní procesory s architekturou CISC od procesorů RISC je velmi malý počet instrukcí tvořících instrukční sadu procesorů RISC a taktéž striktní oddělení instrukcí pro načítání/ukládání dat do operační paměti a na druhé straně instrukcí pro provádění aritmetických a logických operací – i z tohoto důvodu se někdy procesory RISC nazývají procesory s architekturou Load–Store.
Zatímco instrukce určené pro načítání a ukládání dat do operační paměti pracují s přímou adresou čteného či zapisovaného slova, pracují instrukce aritmetické a logické striktně pouze s pracovními registry. Díky tomu se významně zjednodušuje instrukční dekodér a taktéž má naprostá většina instrukcí shodnou délku, protože například není nutné počítat s tím, že některý z operandů instrukce ADD může být zadán s využitím složitého adresního režimu (to u RISC není možné). Z konstantní délky všech instrukcí taktéž nepřímo vyplývá to, že některé procesory RISC načítají z operační paměti celá 16bitová nebo 32bitová slova a vůbec neobsahují možnost adresování jednotlivých bajtů, což ještě více zjednodušuje interní architekturu procesoru.
Druhou typickou vlastností procesorů s architekturou RISC je použití velkého množství pracovních registrů. V závislosti na použité instrukční sadě se většinou jedná o 16, 32 nebo 64 v dané chvíli dostupných registrů, přičemž jejich celkový počet může být i vyšší díky použití registrových oken. Konstruktéři procesorů RISC přistoupili k použití většího množství pracovních registrů z více důvodů. Například měli díky neexistenci mikroprogramového řadiče k dispozici dostatečnou plochu čipu na realizaci pracovních registrů, protože při použití 32 registrů po 32 bitech to znamená nutnost realizovat pouze 1024 bitů pomocí klopných obvodů.

Obrázek 5: Vývoj osmibitových mikroprocesorů CISC, na němž je patrné, že i tyto v podstatě velmi jednoduché mikroprocesory byly implementovány s využitím poměrně velkého množství tranzistorů.
Navíc lze do jednodušší instrukční sady relativně snadno zakomponovat i bity nutné pro adresování pracovních registrů (5 bitů v případě 32 registrů, tj. 10 bitů u dvouadresového kódu). Třetí důvod je však mnohem důležitější: operace prováděné s pracovními registry jsou mnohem rychlejší při porovnání s operacemi prováděnými s daty načítanými z operační paměti, už jen z toho důvodu, že se neblokuje externí datová a adresová sběrnice. A navíc – v rozporu s očekáváními konstruktérů čipů CISC – se v případě velkého množství pracovních registrů zjednodušuje práce překladače, který si například může některé registry rezervovat pro předávání argumentů, jiné ponechat pro počitadla smyček atd. (to byl alespoň prvotní předpoklad, který však nemusí být vždy splněn, viz též následující kapitoly).

Obrázek 6: Ultra SPARC II – další v minulosti velmi často používaný mikroprocesor s architekturou RISC
Zdroj: Wikipedia.
4. Přechod do světa embedded CPU a mikrořadičů
Vzhledem k vysokému výpočetnímu výkonu mikroprocesorů RISC není divu, že prakticky všechny výkonné grafické a pracovní stanice procesory s touto architekturou používaly. Připomeňme si, že na začátku tohoto období ještě byla hodinová frekvence mikroprocesorů srovnatelná s dobou přístupu k DRAM, takže se první generace procesorů RISC obešla bez nutnosti použití instrukčních cache. Posléze se však hodinová frekvence mikroprocesorů zvyšovala a tak bylo nutné do počítače (či dokonce přímo na čip s CPU) přidat instrukční cache, což nebylo velkým problémem v pracovních stanicích (kde se do ceny započítával i drahý disk, velká DRAM, grafický subsystém atd.), ale pro mnohé další aplikační oblasti bylo toto řešení již méně akceptovatelné.

Obrázek 7: Čipy StrongARM založené na architektuře ARMv4 byly v minulosti velmi oblíbené. Zajímavé je, že původně tyto čipy vyvinula společnost Digital Equipment Corporation ve spolupráci s firmou ARM a později byla tato technologie prodána Intelu. Současně se jedná o dobrý příklad použití RISCových procesorů v jiné oblasti, než jsou výkonné pracovní a grafické stanice.
Touto novou aplikační oblastí jsou mikrořadiče, embedded procesory a SoC. V této oblasti, především u mikrořadičů, můžeme sledovat vývoj, který (s mnohaletým zpožděním) kopíruje vývoj, který se stal v oblasti pracovních stanic a později desktopů, tj. přechod od osmibitových a 16bitových CPU k CPU 32bitovým (to taktéž koresponduje se změnou kernelů a používaných programovacích jazyků). Oblast osmibitových a 16bitových MCU se zdá být saturovaná a poměrně stabilní, zatímco trh s 32bitovými čipy poměrně rychle roste. To představuje pro výrobce RISCových procesorů velmi důležitou oblast, v níž se mohou projevit výhody komprimovaných instrukčních sad, a to především z toho důvodu, že MCU mívají užší datovou sběrnici, menší kapacitu instrukční cache a především pak ROM s instrukcemi implementovanou relativně pomalou technologií Flash. Je zde tedy patrná snaha o dosažení větší hustoty strojového kódu.

Obrázek 8: Čipy XMC4000 založené na jádru Cortex-M0. Aplikační oblast: embedded zařízení.
Autor původní fotky: Davewave88.
5. Umění kompromisu
Cílem autorů „komprimovaných“ instrukčních sad bylo na jedné straně zachování většiny výhod původních RISCových čipů (jednoduchá pipeline, vyšší frekvence hodin, obecně vyšší výpočetní výkon, jednoduchá struktura čipu), na straně druhé pak umožnění zakódování vybraných instrukcí v 16bitových slovech a nikoli ve slovech 32bitových. Už jen z těchto dvou požadavků plyne, že bylo nutné udělat množství kompromisů, protože je pochopitelné, že v 216 možných kódech není možné reprezentovat všech teoretických 232 kombinací.

Obrázek 9: Jiné zapouzdření čipů XMC4000 založených na jádru Cortex-M0.
Autor původní fotky: Davewave88.
Podívejme se, jak tento problém vyřešili tvůrci komprimované instrukční sady MIPS16e. Ti navrhli instrukce takovým způsobem, že většinu z nich bylo možné jednoduchým dekodérem rozšířit na původní 32bitové instrukce, takže samotný dekodér znamenal jen velmi malé zvýšení složitosti CPU (povšimněte si, že se jedná o zcela odlišný přístup, než který byl z druhé strany řešen u architektury x86, kde se mnohdy velmi složité CISC instrukce rozkládají na jednoduší mikrooperace, ale nikoli pouhým dekódováním). Vraťme se však k MIPS16e. To, že většina komprimovaných instrukcí je obrazem původních 32bitových instrukcí současně znamená i možnost provedení relativně malých úprav v překladačích. Zbývá tak určit, jak vlastní komprimaci provést:
- Snížením počtu bitů operačního kódu (reprezentovat lze jen některé instrukce)
- Snížením počtu registrů v instrukčním slově
- Zmenšením šířky konstant v instrukčním slově
První bod byl vyřešen s využitím statické analýzy existujících binárních souborů, což je jediná rozumná možnost, která však na druhou stranu reflektuje jen současný stav překladačů. Druhý bod byl řešen taktéž na základě analýzy, kde se ukázalo, že překladače v rámci jedné funkci používají typicky osm či méně pracovních registrů (což je zvláštní, protože při návrhu RISC se počítalo s přesným opakem). Proto sice byla zachována možnost práce se všemi 32 registry, ale pouze osm z nich je dostupných ve všech operacích. Navíc se musel zmenšit původně tříadresový kód na dvouadresový. Třetí bod, tj. zmenšení šířky konstant, si vyžádal zavedení nové zvláštní instrukce EXTEND popsané dále.

Obrázek 10: Mezi další čipy založené na jádru Cortex-M0 patří integrované obvody STM32 F0.
6. Způsoby přepínání mezi klasickou a komprimovanou instrukční sadou
Tvůrci komprimovaných instrukčních sad museli nalézt vhodný způsob přepínání mezi novou instrukční sadou a původní RISCovou sadou. Na hardwarové úrovni je to (pravděpodobně) jednoduché – na základě stavového bitu se pouze vyřadí z činnosti výše zmíněný dekodér instrukcí. Na úrovni instrukční sady do značné míry záleží na tom, zda původní instrukční sada obsahuje možnost několika bity vyjádřit, že instrukce je jen 16bitová. U původních RISCových procesorů se s ničím takovým nepočítalo, což znamená, že instrukční sady MIPS16e a ARM Thumb je nutné povolit nějakou speciální instrukcí, kterou je typicky instrukce skoku. Mnohem větší možnosti nabízí instrukční sady v architektuře RISC-V, které jsou od začátku navrhnuty takovým způsobem, aby se na základě hodnoty dvou nejnižších bitů instrukce dalo rozhodnout, zda se jedná o 16bitovou instrukci či o instrukci delší. Díky tomu lze oba způsoby kódování instrukcí „mixovat“ i v rámci jedné funkce a to bez nutnosti pamatovat si stav procesoru (u ARMu: RISC Mode/Thumb Mode) a provádět speciální skoky. Nezávisle na způsobu přepínání však existence jak původní RISCové sady, tak i sady „komprimované“ dovoluje velkou flexibilitu.
| # | Architektura | Způsob přepnutí ISA |
|---|---|---|
| 1 | MIPS | spec. instrukce skoku, návrat ze subrutiny, zpracování přerušení |
| 2 | ARM | spec. instrukce skoku, zpracování přerušení |
| 3 | RISC-V | každá instrukce má dva bity pro rozlišení mezi ISA |
7. Instrukční sada MIPS16e
První komprimovanou instrukční sadou, s níž se dnes seznámíme, je sada nazvaná MIPS16e. Některé informace o této instrukční sadě jsme si již řekli v předchozích kapitolách, ovšem další informace je nutné doplnit. Tato instrukční sada doplňuje instrukce MIPS I a MIPS II (32bitové operandy) i MIPS III (64bitové operandy). Připomeňme si, že původní RISCová MIPS pracuje s 32 registry, z nichž každý má šířku 32 bitů a operační kódy instrukcí jsou taktéž 32bitové. Tato velká šířka instrukcí umožnila, aby byla většina ALU instrukcí doplněna o bitový posun operandu; samozřejmě byl podporován tříadresový kód, tj. použití dvou zdrojových registrů a jednoho registru cílového. Kvůli snížení počtu instrukcí je jeden z pracovních registrů nulový (konstantní nula) a navíc se nepoužívají žádné příznakové bity, protože podmíněný skok je proveden pouze na základě toho, zda je vybraný pracovní registr roven jinému registru či nikoli. Speciální význam mají dva registry HI a LO používané v násobičce a děličce. Naprostá většina těchto vlastností musela být s přechodem na MIPS16e změněna.
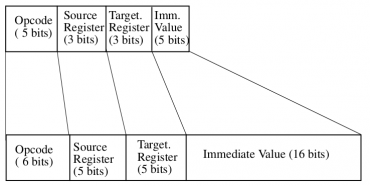
Obrázek 11: Zjednodušené schéma překódování instrukcí MIPS16e a MIPS I,II,III.
8. Pracovní a speciální registry používané v instrukční sadě MIPS16e
V instrukční sadě MIPS16e se naproti tomu možnosti použití registrů snížily, protože většina ALU instrukcí používá dvouadresový kód (jeden ze zdrojových registrů je současně i registrem cílovým) a navíc mnoho operací dokáže pracovat jen s osmi registry r0..r7 mapovanými na původní registry $16, $17, $2..$7 (první dva registry jsou tedy mapovány jinak, než posledních šest registrů, a to kvůli používané volací konvenci). Navíc se používá původní registr $24 ve významu nového podmínkového registru T. Aby bylo možné pracovat se všemi původními pracovními registry, mají programátoři k dispozici instrukce MOV32R a MOVR32 pro přenosy dat. Přidány byly i možnosti relativního adresování s využitím registru SP či PC jakožto bázového registru, což například zjednodušilo návrh céčkových zásobníkových rámců a PIC (Position Independent Code). Poslední dva registry nazvané HI a LO jsou využívány násobičkou a děličkou pro uložení výsledků:
| Režim MIPS16e | MIPS I,II,III |
|---|---|
| r0 | $16 |
| r1 | $17 |
| r2 | $2 |
| r3 | $3 |
| r4 | $4 |
| r5 | $5 |
| r6 | $6 |
| r7 | $7 |
| T | $24 |
| HI | HI |
| LO | LO |
9. Speciální instrukce EXTEND
V kontextu RISCových instrukčních sad je poměrně zajímavá existence instrukce pojmenované EXTEND. Tato šestnáctibitová instrukce (tj. instrukce, jejíž slovo má šířku šestnáct bitů) obsahuje konstantu o šířce 11 bitů, která se pouze zapamatuje (= pravděpodobně uloží do záchytného registru, který je součástí dekodéru); žádný další vliv tato instrukce na činnost mikroprocesoru nemá. Další instrukce, která následuje za EXTEND, může těchto 11 bitů použít k rozšíření velikosti konstanty, protože v MIPS16e je pro uložení konstanty možné použít pouze pět bitů v instrukčním slově, což je pro mnoho operací nedostatečné. Díky EXTEND se tedy možnosti použití konstant rozšiřují na 16 bitů, tj. na stejnou velikost, jakou již měla původní instrukční sada MIPS.

Obrázek 12: Výkonná a na dobu svého vzniku revoluční grafická stanice Onyx 2 vybavená systémem Infinite Reality. Tato grafická stanice je postavena na bázi mikroprocesorů R10000 vycházejících z původní architektury MIPS.
10. Podmíněné skoky v instrukční sadě MIPS16e
Připomeňme si, že původní instrukční sada mikroprocesorů MIPS se vyznačuje dvěma zvláštnostmi. První z nich je absence registru příznaků (flags), protože konstruktéři tohoto mikroprocesoru usoudili, že by používání příznaků typu zero, carry, overflow atd. mohlo vést ke vzniku konfliktů, kdy by na výsledek jedné instrukce čekala instrukce další. Kvůli absenci příznaků jsou v původní RISCové instrukční sadě pouze dva podmíněné skoky beq (branch on equal) a bne (branch on not equal), při nichž se skok provede/neprovede na základě porovnání obsahu dvou pracovních registrů, jejichž indexy jsou přímo součástí instrukčního slova – jedná se tedy o instrukce I-type. Povšimněte si, že díky existenci registru $zero se vlastně zadarmo instrukční sada rozšiřuje o pseudoinstrukce bz (branch on zero) a bnz (branch on non zero). Dále se použití příznaků nahradilo logickými instrukcemi slt (set on less than) a slti (set on less than immediate).
U komprimované instrukční sady MIPS16e by toto schéma podmíněných skoků nemělo moc velký význam, a to zejména proto, že po zakódování dvou registrů pro porovnání (2×3 bity) by již v instrukčním slovu zbylo jen málo bitů na uložení relativní adresy skoku (offsetu). Z tohoto důvodu tvůrci sady MIPS16e zvolili zajímavé řešení, kterým se vlastně částečně vrátili zpět k některým CISCovým procesorům – přidali podporu pro registr nazvaný T, do něhož se ukládá výsledek porovnání. V závislosti na tom, zda je hodnota uložená do registru T nulová či nikoli, je možné provést podmíněný skok s využitím instrukcí nazvaných bteqz (Branch on T Equal to Zero) a btnez (Branch on T Not Equal to Zero). Navíc je možné provést podmíněný skok na základě porovnání jakéhokoli pracovního registru r0 až r7 s nulou, a to s využitím instrukcí beqz (Branch on Equal to Zero) a bnez (Branch on Not Equal to Zero).
Podmíněné skoky stále doplňují instrukce slti, sltiu a cmpi, v nichž se porovnává hodnota vybraného pracovního registru s konstantou. Dále se pro nastavení hodnoty registru T používají instrukce cmp, slt a sltu.

Obrázek 13: Laboratoř specializovaná na simulace a vizualizace, jejíž nezbytnou součástí jsou stroje Onyx 2 Infinite Reality, což znamená, že se jedná o další způsob využití mikroprocesorů s architekturou RISC.
11. Seznam instrukcí v sadě MIPS16e
V této kapitole budou zmíněny všechny instrukce, které je možné reprezentovat v instrukční sadě MIPS16e. Instrukce jsou podle své funkce rozděleny do několika kategorií.
Instrukce typu Load a Store
| # | Zkratka | Význam |
|---|---|---|
| 1 | LB | load byte (8bit) |
| 2 | LBU | load byte unsigned |
| 3 | LH | load half word (16bit) |
| 4 | LHU | load half word unsigned |
| 5 | LW | load word (32bit) |
| 6 | SB | store byte (8bit) |
| 7 | SH | store half word (16bit) |
| 8 | SW | store word (32bit) |
Instrukce obsahující konstantu (immediate)
U těchto instrukcí je konstanta součástí instrukčního slova a její šířku je možné rozšířit s využitím prefixové instrukce EXTEND:

| # | Zkratka | Význam |
|---|---|---|
| 1 | ADDIU | Add Immediate Unsigned |
| 2 | CMPI | Compare Immediate |
| 3 | LI | Load Immediate |
| 4 | SLTI | Set on Less Than Immediate |
| 5 | SLTIU | Set on Less Than Immediate Unsigned |
ALU instrukce pracující s dvojicí registrů
| # | Zkratka | Význam |
|---|---|---|
| 1 | ADD | Add Unsigned |
| 2 | AND | AND |
| 3 | CMP | Compare |
| 4 | MOVE | Move |
| 5 | NEG | Negate |
| 6 | NOT | Not |
| 7 | OR | OR |
| 8 | SEB | Sign-Extend Byte |
| 9 | SEH | Sign-Extend Halfword |
| 10 | SLT | Set on Less Than |
| 11 | SLTU | Set on Less Than Unsigned |
| 12 | SUBU | Subtract Unsigned |
| 13 | XOR | Exclusive OR |
| 14 | ZEB | Zero-extend Byte |
| 15 | ZEH | Zero-Extend Halfword |
Násobení a dělení, přesuny dat do registrů HI a LO
Při násobení a dělení se používají pro uložení výsledků speciální registry nazvané HI a LO, protože násobička a dělička může (ale nemusí!) pracovat nezávisle na ALU. Proto musí existovat instrukce umožňující přenos dat z těchto dvou speciálních registrů:
| # | Zkratka | Význam |
|---|---|---|
| 1 | DIV | Divide |
| 2 | DIVU | Divide Unsigned |
| 3 | MFHI | Move From HI |
| 4 | MFLO | Move From LO |
| 5 | MULT | Multiply |
| 6 | MULTU | Multiply Unsigned |
Aritmetické a logické posuny
| # | Zkratka | Význam |
|---|---|---|
| 1 | SRA | Shift Right Arithmetic |
| 2 | SRAV | Shift Right Arithmetic Variable |
| 3 | SLL | Shift Left Logical |
| 4 | SLLV | Shift Left Logical Variable |
| 5 | SRL | Shift Right Logical |
| 6 | SRLV | Shift Right Logical Variable |
Skoky a podmíněné větvení
| # | Zkratka | Význam |
|---|---|---|
| 1 | B | Branch Unconditional |
| 2 | BEQZ | Branch on Equal to Zero |
| 3 | BNEZ | Branch on Not Equal to Zero |
| 4 | BTEQZ | Branch on T Equal to Zero |
| 5 | BTNEZ | Branch on T Not Equal to Zero |
| 6 | JAL | Jump and Link |
| 7 | JALR | Jump and Link Register |
| 8 | JALRC | Jump and Link Register Compact |
| 9 | JALX | Jump and Link Exchange |
| 10 | JR | Jump Register |
| 11 | JRC | Jump Register Compact |
Ostatní instrukce
| # | Zkratka | Význam |
|---|---|---|
| 1 | RESTORE | restore registers |
| 2 | SAVE | save registers |
| 3 | BREAK | break |
| 4 | EXTEND | rozšíření šířky konstanty další instrukce |

Obrázek 14: Server s architekturou Onyx 3000.
12. Odkazy na Internetu
- An Introduction to Lock-Free Programming
http://preshing.com/20120612/an-introduction-to-lock-free-programming/ - Sequential consistency
https://en.wikipedia.org/wiki/Sequential_consistency - Understanding Atomic Operations
https://jfdube.wordpress.com/2011/11/30/understanding-atomic-operations/ - Load-link/store-conditional
https://en.wikipedia.org/wiki/Load-link/store-conditional - The RISC-V Compressed Instruction Set Manual
http://riscv.org/spec/riscv-compressed-spec-v1.7.pdf - Carry bits, The Architect's Trap
http://yarchive.net/comp/carry_bit.html - Microprocessor Design/ALU Flags
https://en.wikibooks.org/wiki/Microprocessor_Design/ALU_Flags - Flags register in an out-of-order processor
http://cs.stackexchange.com/questions/42095/flags-register-in-an-out-of-order-processor - AMD Am29000
https://en.wikipedia.org/wiki/AMD_Am29000 - Status register
https://en.wikipedia.org/wiki/Status_register - AMD Am29000 microprocessor family
http://www.cpu-world.com/CPUs/29000/ - AMD 29k (Streamlined Instruction Processor) ID Guide
http://www.cpushack.com/Am29k.html - AMD Am29000 (Wikipedia)
http://en.wikipedia.org/wiki/AMD_Am29000 - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Comparing four 32-bit soft processor cores
http://www.eetimes.com/author.asp?section_id=14&doc_id=1286116 - RISC-V Instruction Set
http://riscv.org/download.html#spec_compressed_isa - RISC-V Spike (ISA Simulator)
http://riscv.org/download.html#isa-sim - RISC-V (Wikipedia)
https://en.wikipedia.org/wiki/RISC-V - David Patterson (Wikipedia)
https://en.wikipedia.org/wiki/David_Patterson_(computer_scientist) - OpenRISC (oficiĂĄlnĂ strĂĄnky projektu)
http://openrisc.io/ - OpenRISC architecture
http://openrisc.io/architecture.html - EmulĂĄtor OpenRISC CPU v JavaScriptu
http://s-macke.github.io/jor1k/demos/main.html - OpenRISC (Wikipedia)
https://en.wikipedia.org/wiki/OpenRISC - OpenRISC – instrukce
http://sourceware.org/cgen/gen-doc/openrisc-insn.html - OpenRISC – slajdy z pĹednĂĄĹĄky o projektu
https://iis.ee.ethz.ch/~gmichi/asocd/lecturenotes/Lecture6.pdf - Maska mikroprocesoru RISC 1
http://www.cs.berkeley.edu/~pattrsn/Arch/RISC1.jpg - Maska mikroprocesoru RISC 2
http://www.cs.berkeley.edu/~pattrsn/Arch/RISC2.jpg - C.E. Sequin and D.A.Patterson: Design and Implementation of RISC I
http://www.eecs.berkeley.edu/Pubs/TechRpts/1982/CSD-82–106.pdf - Berkeley RISC
http://en.wikipedia.org/wiki/Berkeley_RISC - Great moments in microprocessor history
http://www.ibm.com/developerworks/library/pa-microhist.html - Microprogram-Based Processors
http://research.microsoft.com/en-us/um/people/gbell/Computer_Structures_Principles_and_Examples/csp0167.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - A Brief History of Microprogramming
http://www.cs.clemson.edu/~mark/uprog.html - What is RISC?
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/whatis/ - RISC vs. CISC
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/risccisc/ - RISC and CISC definitions:
http://www.cpushack.com/CPU/cpuAppendA.html - FPGA
https://cs.wikipedia.org/wiki/Programovateln%C3%A9_hradlov%C3%A9_pole - The Evolution of RISC
http://www.ibm.com/developerworks/library/pa-microhist.html#sidebar1 - SPARC Processor Family Photo
http://thenetworkisthecomputer.com/site/?p=243 - SPARC: Decades of Continuous Technical Innovation
http://blogs.oracle.com/ontherecord/entry/sparc_decades_of_continuous_technical - The SPARC processors
http://www.top500.org/2007_overview_recent_supercomputers/sparc_processors - Reduced instruction set computing (Wikipedia)
http://en.wikipedia.org/wiki/Reduced_instruction_set_computer - MIPS architecture (Wikipedia)
http://en.wikipedia.org/wiki/MIPS_architecture - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - Classic RISC pipeline (Wikipedia)
http://en.wikipedia.org/wiki/Classic_RISC_pipeline - R2000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R2000_(microprocessor) - R3000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R3000 - R4400 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R4400 - R8000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R8000 - R10000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R10000 - SPARC (Wikipedia)
http://en.wikipedia.org/wiki/Sparc - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit





































{kind=link}
{kind=link}