
Článek navazuje na Řízení změn záznamů v relační databázi.
Historie záznamů
Jakákoliv změna v reálném životě se děje v čase. A čas, jako významný faktor, musí být v databázi zohledněn. Určitý stav, určité hodnoty, platily do té doby, než došlo k jejich změně. Od data změny hodnot došlo i ke změně stavu. Situace se změnila. Je zcela jiná než před změnou. Na tyto změny musí reagovat i údaje v databázi. A to nejen při vkládání nových záznamů. Čas musí být zohledněn i při úpravě záznamů, ale zejména při čtení (výběru) záznamů. Pouze v závislosti na čase, pro který data získáváme, získáváme platné hodnoty. Tak, jak v uvedený okamžik platily.
K vysvětlení problematiky nejlépe poslouží schématické obrázky. Ty jsou rozděleny na sekce (A) a (B). Sekce (A) představují současná obvyklá řešení. Tak, jak jsme se je naučili používat a jak s nimi denně pracujeme. Netvrdím, že konkrétní implementace čtenářů nemůže být více sofistikovaná. Ale pro náš výklad a pochopení souvislostí a rozdílů to bude stačit.
Sekce (B) pak prezentují řešení, která implementuje Digital Data Cube Framework (dále jen DDCF). Jde o celý soubor logiky chování, který byl vyvinut za účelem řízení změn záznamů (historie dat) v čase. Dnes se budeme zabývat pouze databázovou částí, a to způsoby ukládání, modifikací a rekonstrukcí záznamů v proměnlivém čase.
Ukládání a změny záznamů

Obrázek 1. ukazuje ideální případ klasického založení záznamu v tabulce v čase (tn) na časové ose (t). Ideální proto, že v tuto chvíli ignorujeme aspekty, popsané v kapitole „1.4. Kontrola integrity“. Je vidět, že oba způsoby pracují stejně a očekávaně. V tabulce byl v čase (tn) založen nový záznam.
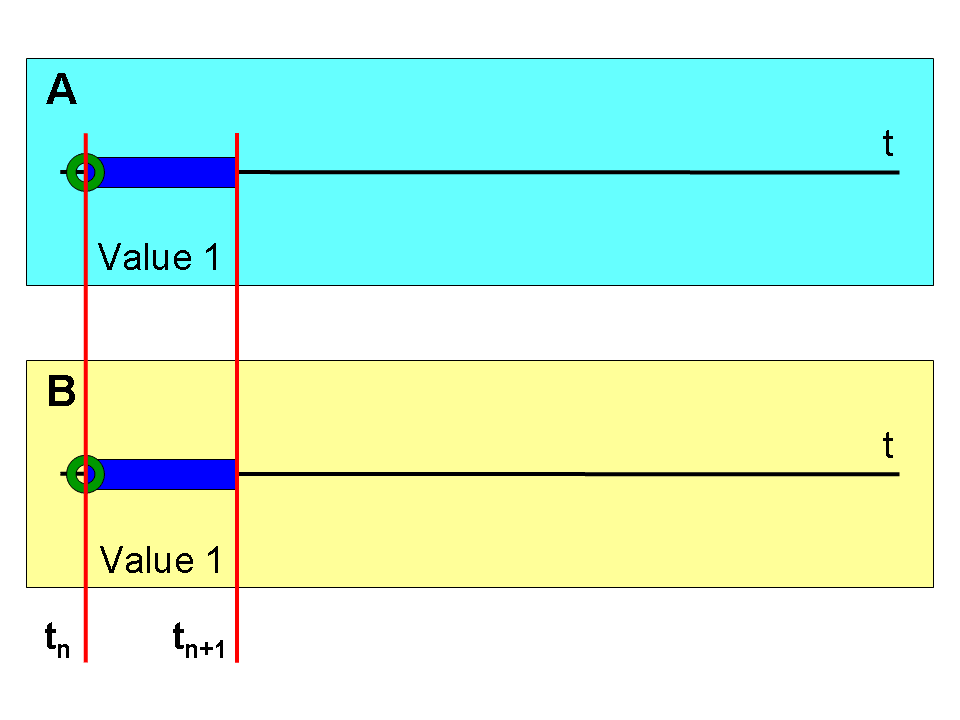
Obrázek 2. ukazuje provedení dotazu do databáze v čase (tn+1) příkazem SELECT. Vidíme, že se obě řešení (A) i (B) opět chovají očekávaně. Návratová hodnota je v obou případech totožná. Dostáváme hodnotu („Value 1“).

Obrázek 3. je již mnohem zajímavější. V čase (tn+1) jsme provedli změnu záznamu (UPDATE). Jak můžeme vidět, v tomto případě se již obě řešení rozcházejí. V případě řešení (A) došlo k okamžitému přepsání původní hodnoty na hodnotu novou („Value 2“). Tím jsme nenávratně ztratili původní hodnotu („Value 1“). Co se stalo v případě použití řešení (B), lépe pochopíme na Obrázku 4.

Provedeme dotaz (SELECT) v čase (tn+2), kde (tn+1) < (tn+2). Vidíme, že v případě řešení (B) dostáváme novou aktuální hodnotu („Value 2“). Původní hodnota („Value 1“) je ovšem zachována! Řešení (A) o tu svou přišlo.

Obrázek 5. ukazuje další provedení změny záznamu (UPDATE) v čase (tn+2). U řešení (A) došlo opět k okamžité změně z hodnoty („Value 2“) na novou hodnotu („Value 3“). Původní hodnota („Value 2“) byla opět nenávratně ztracena. Otázkou je, jaká byla původní hodnota?
Řešení (B) ponechává původní hodnotu („Value 2“) uchovánu. Nová hodnota („Value 3“) je platná až od data (tn+2).
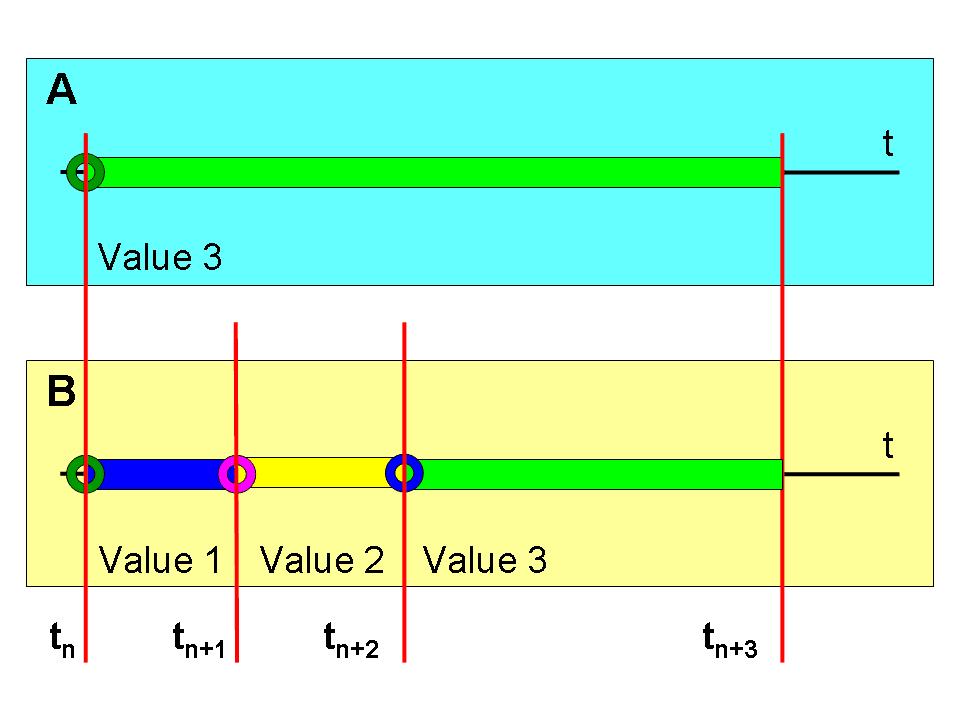
Opakovaný dotaz do databáze (SELECT) v čase (tn+3) nám vrátí očekávané hodnoty. Řešení (A) stále vrací („Value 3“), řešení (B) vrací také („Value 3“).

Obrázek 7. ukazuje, že při použití standardního řešení (A) přicházíme o řadu možností. Nemůžeme řešit historii provedených změn ani případnou rekonstrukci hodnot záznamů do původní podoby. Nemůžeme vyhodnotit záznamy k určitému datumu. Žádné předchozí hodnoty neznáme. Vůbec netušíme, že nějaké předchozí hodnoty byly. Na základě čeho se rozhodujeme? To je velmi nebezpečné a z mého pohledu nepoužitelné. Návratové hodnoty neodpovídají realitě!
Použití řešení (B) naopak umožňuje tzv. „cestování v čase“. Můžeme se dotazovat do databáze na jakékoliv datum v minulosti. Vždy dostáváme aktuální hodnoty pro zvolené datum. Platné záznamy jsou vybírány z intervalu <(tn), (tn+1)). Tzn., že:
((tn) <= zadané datum < (tn+1)) = návratová hodnota
Na Obrázku 7. vidíme, že pro interval <(tn), (tn+1)) dostáváme hodnotu („Value 1“), pro interval<(tn+1), (tn+2)) hodnotu („Value 2“) a pro interval <(tn+2), (tn+3)) pak hodnotu („Value 3“). Vždy obdržíme platné hodnoty pro zadaný čas. Tak, jak v reálném světě skutečně existovaly.
V případě řešení (A) dostáváme vždy poslední pseudo hodnotu („Value 3“). Z tohoto pohledu nemají příkazy (SELECT) do databáze v proměnném čase žádný smysl.
Důležité je, že se dá pro každého uživatele nastavit, zda a jak hluboko do historie může jít. Ne každému uživateli budeme chtít takové informace z historie zpřístupnit.

Obrázek 8. ukazuje, že se změny nemusí provádět přesně v daný čas. Dnes, v čase (tactual) zjistíme, že záznam (BA) nebyl ještě opraven. Můžeme jej změnit zpětně, jak ukazuje (BB). Nebo víme, že záznam (BA) bude muset být změněn již za několik dnů. Můžeme si jej připravit a opravit s budoucím datem, jak ukazuje (BC). Změny můžeme provádět pouze na záznamu v tzv. „schváleném stavu“. Platnost nové změny nemůže nastat dříve, než byla změna předchozí. Tzn., že:
(tn) < (tn+1)
Vyřazení a obnovení záznamů
Fyzicky lze odstranit pouze záznamy, na které se neodkazují jiné záznamy. To bývá v relační databázi zřídka. Je-li mazaný záznam referencován jiným záznamem, příkaz DELETE vyhodí výjimku. Smazání se neprovede. Jiná situace nastane, pokud nejsou zapnuty cizí klíče nebo zapnuty jsou a je nastaveno kaskádovité mazání. Výsledkem můžeme být překvapeni. Odstraněním nesprávných záznamů dojde k narušení integrity.

Obrázek 9. ukazuje situaci pro řešení (B), kdy byl záznam (BA) v čase (tn+2) vyřazen. Dotaz do databáze (SELECT) v časovém intervalu <(tn+2), (tactual)) nám pro (BA) vždy vrátí „NULL“. Standardní nastavení vyřazené záznamy ignoruje. Systém se chová tak, jako by vyřazené záznamy již neexistovaly.
Někdy je ale potřebujeme vidět. Zobrazení můžeme explicitně zapnout pro všechny tabulky. Zapnutí zobrazení vyřazených záznamů vidíme u verze (BB) v čase (tn+2). V tomto případě dotaz (SELECT) v intervalu <(tn+2), (tn+3)) vrací i vyřazené záznamy. Ty se pouze zobrazují. Nelze je modifikovat. Lze je pouze obnovit. Po vypnutí zobrazování v čase (tn+3) se dotazy (SELECT) chovají stejně, jak je popsáno v předchzím odstavci.
Vyřazené záznamy je možné opětovně obnovit. To je vidět u verze (BC) v čase (tn+3). Po obnovení nabývá záznam původních hodnot. Dotaz do databáze (SELECT) v intervalu <(tn+3), (tactual)) nám pro (BC) již vrací plnohodnotný obnovený záznam se všemi jeho referencemi.
Samozřejmě, že existuje i možnost použití příkazu DELETE. Musí být možnost záznam fyzicky odstranit. Jde ale o nenávratnou změnu. Je to možné pouze za splnění určitých specifických podmínek. A takové oprávnění není přiděleno každému uživateli.
Rekonstrukce záznamu
Někdy nastává situace, kdy provedené změny záznamu nejsou korektní. Z různých důvodů. V takovém případě nám systém DDCF umožňuje tyto změny stornovat a vrátit se k předcházejícímu stavu.

Obrázek 10. ukazuje řešení (B), kdy změna záznamu na pozici (BA) v čase (tn+3) nebyla korektní. Ke změně nemělo vůbec dojít. To jsme odhalili dotazem (SELECT) v čase (tactual). Musíme se vrátit k předchozímu stavu. Změnu, provedenou v čase (tn+3) můžeme zrušit. Záznam nabude předchozí hodnoty z času (tn+2), jak ukazuje pozice (BB).
Stornovat lze všechny provedené změny na záznamu. Postupuje se vždy od nejmladší změny ke změně nejstarší (BC). Tak se můžeme dostat až do výchozí pozice (BD) a záznam zrekonstruovat na původní hodnoty. Rekonstrukce záznamu se nedotkne jiných referencovaných záznamů.
Kontrola integrity
Každé vložení záznamu (INSERT) a každá změna záznamu (UPDATE), případně (DELETE), prochází kontrolou integrity cizích klíčů. Kontroluje se stav záznamu, na který se cizí klíč vkládaného záznamu odkazuje. Tzn., že pokud je referencovaný záznam ve schvalovacím procesu, jeho vypovídající hodnota je téměř nulová. Změna stavu totiž může nebo nemusí projít. Pokud projde, nabude záznam nového stavu. Pokud neprojde, zůstane záznam v původním stavu. To v okamžiku vkládání nového záznamu ještě nevíme. Systémově můžeme nastavit, jaké stavy referencovaného záznamu jsou pro vložení a úpravy akceptovatelné a jaké nikoliv.

Obrázek 11. ukazuje řešení (B), kde existují záznamy (R1 – R9) v různých tabulkách. Každý záznam byl ve své tabulce vytvořen v jiném čase. Barvy označují provedené změny záznamu a dobu platnosti. Červená barva označuje vyřazený záznam. Čas (tm) ukazuje, kdy byl záznam (R9) vytvořen. (NR1) a (NR2) jsou nově vkládané záznamy do tabulky („Table BA“) v čase (tn) a (tn+1). Celé zpracování probíhá právě dnes, v čase (tactual).
Předpokládejme, že oba nově vkládané záznamy (NR1) a (NR2) mají cizí klíče (FK1 – FK9), které se odkazují na záznamy (R1 – R9). Cizí klíče jsou povinné. Musí obsahovat Id referencovaného záznamu.
Vidíme, že záznam (R6) je v čase (tn) vyřazen. Pro záznam (NR1) a jeho cizí klíč (FK6) je v čase (tn) nedostupný. Stejně jako záznam (R9) pro cizí klíč (FK9). (R9) v čase (tn) ještě v databázi neexistoval. Byl vytvořen až v čase (tm). To odporuje podmínkám zmíněným výše.
Implementované kontrolní mechanismy takovou situaci rozpoznají a zakážou vložení nového záznamu (NR1) v čase (tn) pro zadané cizí klíče (FK6) a (FK9). To proto, že se odkazují na nekorektní záznamy (R6) a (R9). Protože se cizí klíč (FK9) záznamu (NR1) odkazuje na záznam (R9), který v čase (tn) neexistoval, nebude možné záznam (NR1) v čase (tn) nikdy uložit.
U druhého nově vkládaného záznamu (NR2) v čase (tn+1) problémy nebudou. Záznam je ukládán v jiném čase. Proto se korektně uloží.
Uvedený pokus o vložení záznamu (NR1) odpovídá následující situaci. Představme si, že vkládaný záznam (NR1) je nějaké zařízení. Jeho cizí klíč (FK9) představuje odkaz na odpovědnou osobu (R9) v tabulce zaměstnanců. Jinak řečeno. Snažíme se zaměstnanci (R9) přiřadit zodpovědnost za zařízení (NR1) v čase (tn). V čase (tn) zaměstnanec ve firmě ještě vůbec nepracoval! Logicky jde o nesmysl.
Zde je popsána pouze modelová situace pro základní vysvětlení problematiky. V reálné aplikaci situace se záznamem (NR1) a cizím klíčem (FK9) na záznam (R9) nenastane. A to proto, že jsou uživateli nabídnuty pouze záznamy, které v čase (tn) již existují. Jiná bude situace s cizím klíčem (FK6) na záznam (R6) – vyřazený záznam. Tato situace nastat může (zobrazení vyřazených záznamů). Kontrolní mechanismy tuto situaci ale spolehlivě zachytí a konflikt ošetří.


Obrázek 12. nám pro porovnání ukazuje předchozí situaci za použití standardního řešení (A). V tomto případě se kolize neřeší. Záznam (NR1) bude v čase (tn) normálně uložen. A to i přes to, že záznam (R9) byl založen později, v čase (tm). Čili jakákoliv integrita dat a časový sled byly bezostyšně ignorovány. A je-li výše uvedený příklad se zaměstnancem logický a pochopitelný, tak proč takové řešení používáme? Jakou vypovídající hodnotu taková data mají?
Závěr
Dnes jsem představil základní principy chování historie dat. Věřím, že názorný výklad za použití obrázků je pro čtenáře lépe pochopitelný. V příští úvaze se chci vrátit k tématu a představit další integrované prvky chování.
































