
Obsah
1. Rozsáhlý svět značkovacích jazyků
2. Stručná historie značkovacích jazyků
4. Následovníci roffu – troff a nroff
6. Preprocesory pro troff a preprocesory preprocesorů
7. Rodina značkovacích jazyků založená na TeXu
10. Postmoderní značkovací jazyky – cesta ke zjednodušení a minimalismu
16. Značkovací jazyky vs. řídicí kódy
1. Rozsáhlý svět značkovacích jazyků
V dnešním článku se seznámíme s takzvanými značkovacími jazyky (markup language). V současnosti se jedná o dosti rozsáhlou skupinu jazyků, které se od sebe mnohdy velmi výrazným způsobem odlišují, a to jak vyjadřovacími schopnostmi, tak například tím, jakým způsobem (a zda vůbec) je formálně popsána jejich syntaxe a sémantika, popř. zda definované značky umožňují specifikaci významu textu či „pouze“ způsobu jeho výsledné reprezentace (na obrazovce či vytištěné stránce) po vysázení. V závěru článku se ve stručnosti zmíníme o základních rozdílech mezi značkovacími jazyky určenými mj. i pro přímé použití lidmi a řídicími kódy vkládanými do některých souborových formátů používaných (zejména staršími) textovými editory a procesory. V obou případech se dnes zaměříme zejména na ty značkovací jazyky, popř. formáty, s řídicími kódy určenými primárně pro zápis strukturovaných textových dokumentů.
Původně byly značkovací jazyky skutečně používány především pro vkládání různých formátovacích nebo sémantických značek do víceméně lineárních textů, ovšem později došlo k rozšíření použití specializovaných značkovacích jazyků i do dalších oblastí. Například se jedná o jazyky určené pro popis uživatelských rozhraní, vektorových kreseb (SVG, DOT), služeb (typicky webových služeb), výtahu obsahu (RSS, Atom, JSON Feed), vizualizaci diagramů (PlantUML) atd. V některých případech se již nejedná o klasické značkovací jazyky, ale o doménově specifické jazyky se složitější syntaxí a sémantikou. Dobrým příkladem může být například jazyk a současně i souborový formát používaný známým raytracerem POV-Ray (poslední varianty jazyka POV-Raye podporují makra, tvorbu programových smyček atd.).
2. Stručná historie značkovacích jazyků
Myšlenka použít nějaké značky vkládané do textu uloženého v počítači není nijak nová, ostatně nějaká forma značek se používala již u běžného psaného písma (poznámky, opravy chyb, speciální značky pro tiskaře a v neposlední řadě i běžné školní diktáty poškrtané červenou propiskou učitelem :-). Již v roce 1967 byla tato myšlenka konkrétně popsána Williamem W. Tunnicliffem (což je v této oblasti důležité jméno) a v roce 1970 realizována v systému pojmenovaném GenCode neboli generic coding. Právě v tomto systému se objevil důležitý prvek používaný (a taktéž porušovaný) dodnes – oddělení obsahu od prezentace. William Tunnicliffe následně vedl i výbor, který později vytvořil jazyk SGML, ke kterému se ještě vrátíme.
Mezitím byl Charlesem Goldfarbem v roce 1969 vytvořen jazyk IBM GML neboli IBM Generalized Markup Language. Opět se jedná o jednoho z předchůdců rodiny SGML/HTML, o čemž se ostatně můžete relativně snadno přesvědčit pohledem na kód psaný v GML:
:h1.Chapter 1: Introduction :p.GML supported hierarchical containers, such as :ol. :li.Ordered lists (like this one), :li.Unordered lists, and :li.Definition lists :eol. as well as simple structures. :p.Markup minimization (later generalized and formalized in SGML), allowed the end-tags to be omitted for the "h1" and "p" elements.
Pojďme dále. V roce 1980 dokončil Brian Reid svoji disertační práci o značkovacích jazycích a vytvořil taktéž jazyk nazvaný Scribe. Zde použil nejenom oddělení obsahu od formy (formátování, sazby), ale dokonce i myšlenku oddělení vlastního stylu do k tomu určených sekcí. Jedná se tedy o prakticky dalšího přímého předchůdce SGML a HTML (systém byl převzat výborem pro SGML) a nepřímo taktéž LaTeXu.
Paralelně s tímto úsilím o jediný (a ve výsledku i nesnadno pochopitelný) standard SGML ovšem probíhal vývoj nástroje roff popsaného v navazující kapitole a samozřejmě i TeXu s vlastním jazykem určeným pro popis struktury dokumentů a současně i pro deklaraci vlastních nových příkazů a maker.
Do IT historie zapadá i značkovací jazyk určený pro popis dokumentů s hypertextovými odkazy, jehož první teoretický popis vznikl v roce 1989. Z této základní myšlenky se postupně vyvinula první varianta jazyka HTML, jehož první verze obsahovala pouze tyto značky. Schválně se na odkazovaný seznam značek podívejte a porovnejte si ho s moderním HTML.
3. Nástroj roff
Prvním nástrojem založeným na značkovacím jazyku, s nímž se v tomto článku setkáme, je nástroj nazvaný roff. Pokud vám připadá jméno této utility přinejmenším podivné, nejste sami. Jedná se totiž o jméno odvozené od ještě staršího programu nazvaného runoff, který byl společně s dalším nástrojem typset používán na Multicsu, což je předchůdce Unixu (předchůdce ve smyslu, že se u Multicsu ukázalo, jak operační systém nemá vypadat). Zatímco program typset byl editor, zajišťoval program runoff formátování, stránkování atd. A právě tuto funkci „formátovače“ na Unixu převzal program roff. Jen pro zajímavost se podívejme, jak vlastně vypadaly zdrojové kódy určené pro formátování programem runoff:
When you're ready to order, call us at our toll free number: .BR .CENTER 1-800-555-xxxx .BR Your order will be processed within two working days and shipped
Po naformátování vypadal výsledný dokument na obrazovce terminálu, popř. po vytištění, následovně:
When you're ready to order, call us at our toll free number:
1-800-555-xxxx
Your order will be processed within two working days and shipped
Vidíme tedy, že runoff dokázal porozumět značkám pro konce odstavce, značce pro vycentrování řádku atd.
Vraťme se však k utilitě roff. V době vzniku Unixu se jednalo o jednu z nejdůležitějších aplikací, která byla provozována na úplně prvním počítači zakoupeném speciálně pro provozování tohoto operačního systému. A důvodem pro koupi tohoto (tehdy pochopitelně velmi drahého) stroje byla – sazba textů resp. obecněji systém pro zpracování textů. Roff se používal mj. i pro vytváření manuálových stránek pro Unixy verze 1 až 3. Ostatně i samotný roff stále má svoji manuálovou stránku – https://linux.die.net/man/7/roff.
4. Následovníci roffu – troff a nroff
V dnešních Unixech i na Linuxu se většinou setkáme s nějakou formou následovníka původní utility roff. Prvním z těchto programů je utilita nazvaná troff, což je jméno vzniklé ze sousloví typesetter roff. A je to jméno velmi příhodné, protože se v případě troffu skutečně jedná o program určený pro počítačovou sazbu, a to nejenom na terminály či tiskárny s pevnými šířkami znaků. Při použití troffu je možné specifikovat písma (fonty), okraje, umístění poznámek, styly odstavců atd.
Nástroj troff se používal (a možná ještě v některých případech používá) pro sazbu knih. Jejich pravděpodobně neúplný seznam je dostupný na adrese https://troff.org/pubs.html.
Podívejme se nyní na poměrně složitý dokument obsahující mnoho značek specifikujících vzhled dokumentu. Povšimněte si, že tyto značky začínají tečkou a jsou dvojpísmenné (takže se jejich mnemotechnické zkratky mnohdy pamatují poměrně špatně):
.nf .ll 5.0i .pl 8.0i .in 2.5i 101 Main Street Morristown, NJ 07960 15 March, 1997 .in 0 .sp 1i Dear Sir, .fi .ti 0.5i I just wanted to drop you a note to thank you for spending the time to give me a tour of your facilities. I found the experience both educational and enjoyable. I hope that we can work together to produce a product we can sell. .pn 4 I am sending a copy of our proposal on the next page. I look forward to hearing from you. .sp 2 .in 2.5i Yours, .sp 0.5i Joe Smith, President Any Corp. .bp .in 0 We propose to build our widget tools with your widget makers.
Sazbu můžeme provést na běžný terminál s neproporcionálním písmem. Výsledek bude vypadat následovně:
<beginning of page> 101 Main Street Morristown, NJ 07960 15 March, 1997 Dear Sir, I just wanted to drop you a note to thank you for spending the time to give me a tour of your facilities. I found the experience both educational and enjoyable. I hope that we can work together to produce a product we can sell. I am sending a copy of our pro posal on the next page. I look forward to hearing from you. Yours, Joe Smith, President Any Corp. <beginning of page> We propose to build our widget tools with your widget makers.
Nová GNU varianta troffu se jmenuje groff a kromě jiného dokáže vygenerovat výstup do PostScriptu, který lze snadno převést do PDF:

Obrázek 1: Sazba do PDF provedená groffem společně s ps2pdf.
Kromě nástroje troff (resp. jeho varianty groff) se velmi často setkáme s nástrojem nroff, který je určen pro sazbu na zařízení s fonty s pevnou šířkou (neproporcionální písma), tj. například na terminály. nroff byl původně naprogramován v assembleru (autorem této varianty je Joe Ossanna), později byl přepsán do programovacího jazyka C. Typické použití nroffu spočívá v zobrazování manuálových stránek – viz též navazující kapitolu.
GNU verze se troffu jmenuje, jak již ostatně víme, groff a na Linuxu se setkáme právě s touto variantou. Ostatně i nroff je implementován v rámci groffu (jako skript spouštějící groff).
„Can you imagine anyone rewriting troff from scratch, in what ended up as about 60,000 lines of C++? Wow, I am impressed. If it were not for James' freely available reimplementation, troff would be dead by now.“
5. Makra pro troff
Systém troff obsahuje i sadu příkazů, které se zde nazývají makra (macros). Tato makra se spouští na začátku zpracování dokumentu a umožňují nastavit prakticky všechny parametry sazby, tj. hlavičky stránek, patičky, styl zápisu poznámek, zarovnání atd. Kromě toho definují i nové specializované příkazy, které jsou mnohdy sémantické (pro danou oblast použití). Mezi podporovaná makra patří zejména:
| Jméno makra | stručný popis |
|---|---|
| man | manuálové stránky |
| mdoc | sémanticky anotované manuálové stránky |
| me | vědecké články |
| mm | memoranda |
| ms | knihy a technická dokumentace |
| rfc | psaní RFC |
| present | prezentace |
Následuje příklad zápisu dokumentu, který tvoří zdroj pro sazbu manuálové stránky Vimu:
.TH VIM 1 "2006 Apr 11" .SH NAME vim \- Vi IMproved, a programmers text editor .SH SYNOPSIS .br .B vim [options] [file ..] .br .B vim [options] \- .br .B vim [options] \-t tag .br .B vim [options] \-q [errorfile] .PP .br .B ex .br ... ... ... .SH SEE ALSO vimtutor(1) .SH AUTHOR Most of .B Vim was made by Bram Moolenaar, with a lot of help from others. See ":help credits" in .B Vim. .br .B Vim is based on Stevie, worked on by: Tim Thompson, Tony Andrews and G.R. (Fred) Walter. Although hardly any of the original code remains. .SH BUGS Probably. See ":help todo" for a list of known problems. .PP Note that a number of things that may be regarded as bugs by some, are in fact caused by a too-faithful reproduction of Vi's behaviour. And if you think other things are bugs "because Vi does it differently", you should take a closer look at the vi_diff.txt file (or type :help vi_diff.txt when in Vim). Also have a look at the 'compatible' and 'cpoptions' options.
Příklad výstupu (sazby) na obrazovku:
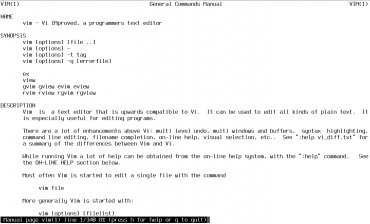
Obrázek 2: Sazba manuálové stránky přímo na obrazovku terminálu.
$ man -t vim | ps2pdf - vim.pdf

Obrázek 3: Sazba manuálové stránky do PDF.
6. Preprocesory pro troff a preprocesory preprocesorů
Pro systém troff vzniklo i poměrně velké množství různých preprocesorů, tedy nástrojů, které získají vstupní data, nějakým způsobem je zpracují a výsledkem jsou data ve formátu zpracovatelném právě troffem. Tato architektura velmi dobře zapadá do konceptu Unixu, tedy do způsobu tvorby rozsáhlejších aplikací z menších částí propojených s využitím rour (pipes). Dokonce je možné říci, že právě ekosystém vyvinutý okolo systému troff poprvé prakticky ukázal možnosti a výhody Unixu.
Mezi známé (a mnohdy doposud používané) preprocesory patří:
| Jméno | Způsob použití |
|---|---|
| eqn | matematické vzorce |
| tbl | tabulky |
| refer | citace |
| pic | základní kreslící funkce (viz dále) |
| ideal | deklarativní specifikace grafiky |
| grn | tvorba obrázků kreslením základních grafických elementů |
Podívejme se například na obsah, který má být zpracovatelný preprocesorem pic:
.PS
# Draw a demonstration up left arrow with grid box overlay
define gridarrow
{
move right 0.1
[
{arrow up left $1;}
box wid 0.5 ht 0.5 dotted with .nw at last arrow .end;
for i = 2 to ($1 / 0.5) do
{
box wid 0.5 ht 0.5 dotted with .sw at last box .se;
}
move down from last arrow .center;
[
if ( $1 == boxht ) \
then { "\fBline up left\fP" } \
else { sprintf("\fBarrow up left %g\fP", $1) };
]
]
move right 0.1 from last [] .e;
}
gridarrow(0.5);
gridarrow(1);
gridarrow(1.5);
gridarrow(2);
undef gridarrow
.PE
Výsledkem může být (zkráceno):
.if !dPS .ds PS .if !dPE .ds PE .lf 1 - .lf 1 .PS 0.750i 5.800i .\" 0 -0.375 5.8 0.375 .\" 0.000i 0.750i 5.800i 0.000i .nr 00 \n(.u .nf .nr 0x 1 ... ... ... \h'5.200i'\v'0.150i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.200i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.250i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.300i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.350i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.400i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.450i'\D'l 0.000i 0.000i' .sp -1 \h'5.200i'\v'0.500i'\D'l 0.000i 0.000i' .sp -1 .lf 25 \h'4.700i-(\w'\fBarrow up left 2\fP'u/2u)'\v'0.750i-(0v/2u)+0v+0.22m'\fBarrow up left 2\fP .sp -1 .sp 0.750i+1 .if \n(00 .fi .br .nr 0x 0 .lf 27 .PE .lf 28
To však není zdaleka vše, protože myšlenku propojení více nástrojů pomocí rour lze ještě dále rozšířit. Pokud existuje například preprocesor pic, jenž umožňuje práci se základními kreslícími funkcemi, je zajisté možné vytvořit další pre-preprocesor, který zajistí tvorbu grafů, diagramů, histogramů, vizualizaci datových struktur aj. Výsledkem práce tohoto preprocesoru by byla data kompatibilní s preprocesorem pic, jenž by posléze mohl vytvořit data použitelná přímo utilitou troff. A takové preprocesory skutečně vznikly, například:
| grap | grafy, diagramy a histogramy |
| chem | molekulární struktury |
| dformat | datové struktury |
7. Rodina značkovacích jazyků založená na TeXu
Samostatnou kapitolou (v tomto článku to platí doslova) je systém TeX a nad ním postavené nadstavby (LaTeX atd.). První verze TeXu byla jeho autorem Donaldem Knuthem vydána již v roce 1978. Jedná se o systém určený pro počítačovou sazbu textů a v tomto článku se o něm zmiňujeme především z toho důvodu, že vstupem pro sazbu jsou textové dokumenty obsahující jak samotný text, který má být vysázen, tak i příkazy (řekněme značky) ovlivňující sazbu. Tyto dokumenty většinou využívají soubor maker nazvaných PlainTeX, existují ovšem i komplikovanější nadstavby nad samotným TeXem, které mj. přidávají i sémantické značky (tj. označení textu podle jeho významu, ne podle toho, jakým způsobem se má vysázet). Nejznámější nadstavbou tohoto typu je LaTeX, dnes ve verzi LaTeX 2ε, ovšem oblibu si postupně získává i novější ConTeXt a XeTeX.
Podívejme se nyní, jak může vypadat (zde neúplný) dokument, který má být zpracovaný LaTeXem a následně vysázený samotným TeXem. V tomto dokumentu jsou dva běžné odstavce, vzorec, seznam a několik vzorců vložených přímo do textu (odstavce):
Při aproximaci exponenciální funkce a s~požadavkem na průchod funkce nulou,
lze s~výhodou použít polynomů. Přesnější aproximaci lze provést polynomem
šestého stupně. Jeho nevýhodou jsou poměrně složité výpočty, které se mohou
projevit například při vykreslování implicitních ploch sníženou rychlostí
vykreslování. Tvar tohoto polynomu je následující:
\begin{equation}
D_i(r_i)=-\frac{4}{9}\frac{r_i^6}{R_i^6}+\frac{17}{9}\frac{r_i^4}{R_i^4}-\frac{22}{9}\frac{r_i^2}{R_i^2}+1
\label{impl_0}
\end{equation}
kde:
\begin{itemize}
\item $R_i$ je poloměr prvku kostry
\item $r_i$ je vzdálenost vyšetřovaného bodu v~prostoru od středu prvku kostry
\item $D_i(r_i)$ je výsledná intenzita v~daném bodě
\end{itemize}
Tato funkce je pro $r_i \geq R_i$ nulová. Při výpočtu nemusíme vyšetřovat
všechny body v~prostoru, ale pouze ty, které leží ve~vzdálenosti menší než
$R_i$. Mezi další výhodné vlastnosti této funkce patří to, že má pro $r_i=0$ a
$r_i=R_i$ nulové derivace a že je symetrická pro hodnotu $r=\frac{R_i}{2}$
(viz též obrázek \ref{obr_funkce_polynom_6}).
Výsledek po vysázení, převodu do PDF a rasterizaci v PDF prohlížeči může vypadat následovně (veškeré chyby typu „poskakujícího písma“ má na svědomí prohlížeč PDF, nikoli samotný TeX, který sází písmena na samotné hranici optické přesnosti):

Obrázek 4: Část stránky vysázené programem TeX.
8. SGML, XML a DocBook
O jazyku SGML neboli Standard Generalized Markup Language jsme se krátce zmínili v úvodních kapitolách. Ve skutečnosti se jedná o značkovací metajazyk, tj. o jazyk určený pro definici dalších značkovacích jazyků, které jsou jeho podmnožinou a sdílí s ním společné vlastnosti (zejména syntaxi zápisu s využitím pojmenovaných elementů a značek zapisovaných se špičatými závorkami). Součástí SGML je i metajazyk pro popis elementů a atributů – jedná se o známý DTD (Document Type Description). SGML je bezkontextový jazyk (viz Chomského hierarchie), což mj. znamená, že se jednotlivé značky mohou vzájemně vnořovat, ale nikoli překrývat (samotný termín context je ovšem v SGML používán v jiném významu – je to text, jenž je uložen do nějaké značky). V důsledku se můžeme na dokument založený na nějaké podmnožině SGML dívat jako na strukturovaný zápis stromové struktury, což se ostatně využívá v DOMu založeném na HTML (což byla jedna z podmnožin SGML).
Následuje příklad (nijak neupraveného) SGML souboru:
<recipe> <title> Haupia (Coconut Pudding) </title> <ingredient-list> <ingredient> 12 ounces coconut milk </ingredient> <ingredient> 4 to 6 tablespoons sugar </ingredient> </ingredient-list> <instruction-list> <step> Pour coconut milk into saucepan. </step> <step> Combine sugar and cornstarch; stir in water and blend well. </step> <step> Stir sugar mixture into coconut milk; cook and stir over low heat until thickened. </step> </instruction-list> </recipe>
Zjednodušenou variantou SGML je XML neboli eXtensible Markup Language. Tento značkovací jazyk se v současnosti používá k mnoha účelům – k tvorbě dokumentů se sémantickými značkami (bez informací o formátování), pro serializaci a deserializaci složitě strukturovaných dat a taktéž pro ukládání konfiguračních informací. Příklad XML reprezentujícího tabulku v tabulkovém procesoru Gnumeric:
<?xml version="1.0" encoding="UTF-8"?>
<gnm:Workbook xmlns:gnm="http://www.gnumeric.org/v10.dtd" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.gnumeric.org/v9.
xsd">
<gnm:Version Epoch="1" Major="12" Minor="9" Full="1.12.9"/>
<gnm:Attributes>
<gnm:Attribute>
<gnm:name>WorkbookView::show_horizontal_scrollbar</gnm:name>
<gnm:value>TRUE</gnm:value>
</gnm:Attribute>
<gnm:Attribute>
<gnm:name>WorkbookView::show_vertical_scrollbar</gnm:name>
<gnm:value>TRUE</gnm:value>
</gnm:Attribute>
<gnm:Attribute>
<gnm:name>WorkbookView::show_notebook_tabs</gnm:name>
<gnm:value>TRUE</gnm:value>
</gnm:Attribute>
<gnm:Attribute>
<gnm:name>WorkbookView::do_auto_completion</gnm:name>
<gnm:value>TRUE</gnm:value>
</gnm:Attribute>
<gnm:Attribute>
<gnm:name>WorkbookView::is_protected</gnm:name>
<gnm:value>FALSE</gnm:value>
</gnm:Attribute>
</gnm:Attributes>
<office:document-meta xmlns:office="urn:oasis:names:tc:opendocument:xmlns:office:1.0" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:dc="http://purl.org/dc
/elements/1.1/" xmlns:meta="urn:oasis:names:tc:opendocument:xmlns:meta:1.0" xmlns:ooo="http://openoffice.org/2004/office" office:version="1.2">
<office:meta>
<meta:creation-date>2020-03-16T18:15:18Z</meta:creation-date>
</office:meta>
</office:document-meta>
<gnm:Calculation ManualRecalc="0" EnableIteration="1" MaxIterations="100" IterationTolerance="0.001" FloatRadix="2" FloatDigits="53"/>
<gnm:SheetNameIndex>
<gnm:SheetName gnm:Cols="256" gnm:Rows="65536">Sheet1</gnm:SheetName>
...
...
...
Dalším příkladem XML je konfigurační soubor hry FreeCol:
<?xml version="1.0" encoding="UTF-8"?><optionGroup id="gameOptions" editable="true">
<optionGroup id="gameOptions.map" editable="true">
<integerOption id="model.option.turnsToSail" value="3" maximumValue="10" minimumValue="1"/>
<integerOption id="model.option.settlementLimitModifier" value="0"/>
...
...
...
<booleanOption id="model.option.fogOfWar" value="true"/>
<booleanOption id="model.option.teleportREF" value="true"/>
<selectOption id="model.option.startingPositions" value="0" localizedLabels="true">
<selectValue value="0" label="model.option.startingPositions.classic"/>
<selectValue value="1" label="model.option.startingPositions.random"/>
<selectValue value="2" label="model.option.startingPositions.historical"/>
</selectOption>
<integerOption id="model.option.initialImmigration" value="15" maximumValue="99" minimumValue="0"/>
<percentageOption id="model.option.peaceProbability" value="90"/>
<integerOption id="model.option.playerImmigrationBonus" value="2" minimumValue="0"/>
<booleanOption id="model.option.equipEuropeanRecruits" value="true"/>
</optionGroup>
Dalším důležitým značkovacím jazykem (odvozeným ze SGML), o němž se v dnešním článku musíme zmínit, je DocBook. Jak již název tohoto jazyka napovídá, je jeho primárním účelem ukládání strukturovaných dokumentů. Všechny DocBookové značky jsou navíc čistě sémantické, tj. označují, o jaký text se jedná a nikoli jakým způsobem má být zobrazen. To je velmi důležité v oblastech, ve kterých se DocBook nasazuje – poloautomatická tvorba manuálů, dokumentace k API (mnohdy taktéž automaticky či poloautomaticky generovaná) atd. Samotné vysázení dokumentu se provádí například transformací pomocí XSL-FO (XSL Formatting Objects) nebo převodem do jiného formátu (včetně HTML). Ovšem právě proto, že DocBook obsahuje čistě sémantické značky, může být jeho použití pro některé autory problematické (celkový počet značek dosahuje několika set). Z tohoto důvodu byl navržen upravený jazyk nazvaný příznačně Simplified DocBook určený převážně pro tvorbu článků (značka „book“ zde vůbec není povolena).
Příklad jednoduchého dokumentu vytvořeného v DocBooku:
<?xml version="1.0" encoding="UTF-8"?>
<book xml:id="simple_book" xmlns="http://docbook.org/ns/docbook" version="5.0">
<title>Very simple book</title>
<chapter xml:id="chapter_1">
<title>Chapter 1</title>
<para>Hello world!</para>
<para>I hope that your day is proceeding <emphasis>splendidly</emphasis>!</para>
</chapter>
<chapter xml:id="chapter_2">
<title>Chapter 2</title>
<para>Hello again, world!</para>
</chapter>
</book>
9. HTML a HTMLBook
Značkovací jazyk HTML v tomto článku zmiňuji jen pro úplnost, protože ho s velkou pravděpodobností zná naprostá většina čtenářů Roota (ostatně jak vypadá poloautomaticky generované HTML zjistíte po stisku klávesové zkratky Ctrl+U). Samotný jazyk HTML prošel několika fázemi, od jednoduchého jazyka se sémantickými značkami přes období, kdy do HTML byly přidávány takové podivnosti, jako značka <font>, <blink> či dokonce <marquee> až po fázi, kdy se HTML používá pro popis sémantiky dokumentu (nebo designu stránky) a se striktně oddělenými styly (první variantou bylo XHTML, dnes se ovšem setkáme spíše s HTML 5, které obsahuje další sémantické značky určené pro popis uživatelského rozhraní).
Zajímavá a poněkud méně známá varianta XHTML (konkrétně XHTML5) se jmenuje HTMLBook, což je HTML upravené (zjednodušené) takovým způsobem, aby bylo vhodné pro sazbu knih. Vychází se přitom z faktu, že struktura knih je prakticky stejná už několik století a pravděpodobně se často měnit nebude. Současně je XML a HTML tak rozšířeným jazykem, že lze předpokládat, že s námi v nějaké podobě vydrží určitě minimálně několik desetiletí; navíc se v HTMLBooku ukládá struktura knihy (sémantické značky) a ne to, jak bude vytištěna či prezentována na budoucích zařízeních (samotné styly jsou oddělené a uložené klasicky do CSS). Proto může HTMLBook sloužit pro ukládání knih tak, aby bylo možné tyto dokumenty zpracovat i po velmi dlouhé době. Popis, resp. přesněji řečeno specifikaci HTMLBooku naleznete na adrese http://oreillymedia.github.io/HTMLBook/.
10. Postmoderní značkovací jazyky – cesta ke zjednodušení a minimalismu
Všechny značkovací jazyky popsané v předchozích kapitolách jsou bezpochyby velmi mocné (z pohledu vyjadřovacích schopností), ovšem mají i několik nevýhod. Především mnohdy vyžadují poměrně značnou počáteční časovou investici nutnou do zaučení (DocBook, TeX, nemluvě o troff) a některé z výše uvedených jazyků vyžadují pro tisk (resp. pro sazbu) i netriviální sadu pomocných nástrojů. Proto vlastně není ani velkým překvapením, že se zejména na začátku tisíciletí – společně s nástupem nové generace aplikací (založených na Webu 2.0, což je ostatně jen obecné označení trendu, ovšem zahrnuje například i fenomén wiki) – objevily i nové značkovací jazyky s mnohdy se značně zjednodušeným způsobem zápisu, který navíc většinou stíral rozdíl mezi běžným plain textem a značkovacím jazykem. Mezi takto navržené značkovací jazyky patří například:
- AsciiDoc
- atx
- BBCode
- Creole
- Crossmark
- Epytext
- Haml
- JsonML
- MakeDoc
- Markdown
- Org
- ode
- POD
- reST
- RD
- Setext
- SiSU
- SPIP
- Xupl
- Texy
- Textile
- txt2tags
- UDO
- nd
- wikitext
11. POD a RD
Zejména ve světě programovacího jazyka Perl se setkáme se soubory označovanými POD neboli Plain Old Documentation. Jedná se o značkovací jazyk používaný pro tvorbu dokumentace právě v ekosystému tohoto programovacího jazyka. Svými schopnostmi se podobá dále zmíněnému Markdownu; ostatně existuje i převodník mezi soubory POD a Markdownem. Jedná se o typický „postmoderní“ značkovací jazyk – text se zapisuje běžným způsobem a značky se vkládají jen tam, kde je to skutečně nutné (na rozdíl od HTML, XML či DocBooku).
Podívejme se nyní na dokument vytvořený právě v PODu. Jedná se o zdrojový kód určený pro zpracování a zkonvertování do podoby manuálové stránky:
=head1 NAME emend - a command-line interface for Emender =head1 SYNOPSIS B<emend> [B<-clsvDT>] [B<-o> I<output_file>] [I<test_file>...] B<emend> B<-h>|B<-V>|B<-L> =head1 DESCRIPTION The B<emend> utility runs tests stored in the local file system and prints a detailed report to standard output. By default, the utility looks for tests in the F<test> directory, but you can specify individual tests on the command line. =head1 OPTIONS =over =item B<-o> I<output_file>, B<--output> I<output_file> Stores a detailed report to the file named I<output_file>. The B<emend> utility deduces the format of the output file form the file extension: currently recognized file extensions are B<.txt> (plain text), B<.html> (HTML), B<.xml> (XML as described in B<emender_xml>(5)), and B<.junit> (JUnit XML output). Note that you can specify the B<-o> option more than once to generate the report in multiple formats.
Úplný zdrojový kód tohoto dokumentu naleznete na adrese https://github.com/emender/emender/blob/master/doc/man/man1/emend.1.pod.
Dalším podobně koncipovaným formátem je RD neboli Ruby Document. Ten může vypadat následovně:
=begin
= NAME
RD sample - A sample RD document
= SYNOPSIS
here.is_a?(Piece::Of::Code)
print <<"END"
This indented block will not be scanned for formatting
codes or directives, and spacing will be preserved.
END
= DESCRIPTION
Here's some normal text. It includes text that is
((*emphasized*)), ((%keyboard%)), (({code}))-formatted,
((|variable part|)), ((:indexed:)), and (('as-is'))((-footnote-)).
== An Example List
* This is a bulleted list.
* Here's another item.
* Nested list item.
== An ordered List
(1) This is the first item
(2) second
* Nested unordered list.
(3) third
(1) Nested ordered list
(2) its second item
=end
Následovníkem RD je RDoc, který se dnes používá pro generování dokumentace ekosystému programovacího jazyka Ruby. Příklad použití naleznete například na adrese https://gist.github.com/hunj/f89cabc10c155f06cc3e.
12. AsciiDoc
Dalším značkovacím jazykem, a to velmi důležitým, je AsciiDoc, jehož první verze vznikla v roce 2002 a jehož autorem je Stuart Rackham. Jedná se o značkovací jazyk, který se podobně jako ostatní postmoderní značkovací jazyky snaží o to, aby byl na prvním místě samotný dokument (text) a případné značky se přidávaly pouze tam, kde je to nutné. Navíc by měl být dokument vytvořený v AsciiDocu čitelný i bez použití konvertorů (asciidoc, a2×, Asciidoctor). AsciiDoc je dnes podporovaný v mnoha textových editorech, které mnohdy nabízí i režim náhledu na editovaný dokument, viz například textový editor Atom. Jeho předností je například podpora pro specifikaci tabulek. AsciiDoc je podporován i nástrojem Atlas, který slouží pro zjednodušení publikace knih ve známém nakladatelství O'Reilly.
Podívejme se nyní na příklad dokumentu vytvořeného v AsciiDocu, konkrétně na dokument z adresy https://raw.githubusercontent.com/asciidoctor/asciidoctor.org/master/docs/asciidoc-writers-guide.adoc:
Open up your favorite text editor and get ready to write some AsciiDoc!
=== Content is king!
include::{includedir}/para.adoc[]
Just like that, *you're writing in AsciiDoc!*
As you can see, it's just like writing an e-mail.
Save the file with a file extension of `.adoc`.
TIP: If you want to find out how to convert the document to HTML, DocBook or PDF, skip ahead to the section on <>.
// Update convert section with new link to guide
==== Wrapped text and hard line breaks
include::{includedir}/para-line-break.adoc[]
=== Admonitions
include::{includedir}/admonition.adoc[tag=intro]
include::{includedir}/admonition.adoc[tag=icon]
An admonition paragraph is rendered in a callout box with the admonition label--or its corresponding icon--in the gutter.
Icons are enabled by setting the `icons` attribute on the document.
// Should icon settings be specified here, in a more detailed section further down, or do we need a styling document?
NOTE: Admonitions can also encapsulate any block content, which we'll cover later.
All words and no emphasis makes the document monotonous.
Let's give our paragraphs some [big]*_emotion_*.
=== Mild punctuation, strong impact
Just as we emphasize certain words and phrases when we speak, we can emphasize them in text by surrounding them with punctuation.
AsciiDoc refers to this markup as _quoted text_.
Vysázenou podobu můžete vidět zde.
Příklad jednoduché tabulky i se specifikací způsobu jejího zobrazení (zarovnání sloupců atd.):
[width="50%",cols=">s,^m,e",frame="topbot",options="header,footer"] |========================== | 2+|Columns 2 and 3 |1 |Item 1 |Item 1 |2 |Item 2 |Item 2 |3 |Item 3 |Item 3 |4 |Item 4 |Item 4 |footer 1|footer 2|footer 3 |==========================
13. reST (reStructuredText)
V roce 2002, tedy ve stejném roce, kdy vznikl AsciiDoc, byl navržen i další podobný značkovací jazyk nazvaný reST neboli reStructuredText, jehož autorem je David Goodger. Jedná se o jazyk částečně postavený na značkovacím jazyku StructuredText používaném v Zope, který ovšem měl několik nepříjemných vlastností, které byly v reST vyřešeny. Dnes se tento značkovací jazyk používá velmi masivně, a to ve světě Pythonu (například pro dokumentaci vlastního jazyka a jeho knihoven), protože ho od roku 2008 podporuje nástroj Sphinx. Důležitou službou je Read the Docs umožňující publikování dokumentace vytvořené právě v reST popř. v Markdownu. Může se jednat jak o několik odstavců, tak i o rozsáhlé knihy.
Další informace o reSTu lze získat na stránkách https://docutils.readthedocs.io/en/sphinx-docs/user/rst/quickstart.html.
Ukázka použití: https://fangohr.github.io/computing/rst/rst.txt a vysázená verze téhož dokumentu na https://fangohr.github.io/computing/rst/rst.html.
14. Markdown a CommonMark
Dva roky po uvedení AsciiDocu a ReStructuredTextu vznikl formát Markdown, který pravděpodobně není nutné čtenářům tohoto serveru dlouze představovat, protože soubory Markdown jsou masivně používány, zejména pro zápis kratší dokumentace, v níž se ještě neprojeví některé nepodporované vlastnosti. Původními autory Markdownu jsou John Gruber a Aaron Swartz. Původně se jednalo o velmi jednoduchý značkovací jazyk umožňující specifikaci nadpisů, seznamů s odrážkami, číslovaných seznamů, odkazů a obrázků, později ovšem došlo k několika rozšířením Markdownu o další vlastnosti, například o zaškrtávací boxy (viz níže) atd. Chybějící textové entity, například tabulky, je nutné dopisovat formou vkládaného HTML, což nemusí být vždy nejlepší řešení. Některé varianty rendererů Markdownu však tabulky podporují:
| Tables | Are | Cool | | ------------- |:-------------:| -----:| | col 3 is | right-aligned | $1600 | | col 2 is | centered | $12 | | zebra stripes | are neat | $1 |

Obrázek 5: Logo značkovacího jazyka Markdown.
Podívejme se nyní na variantu Markdownu používanou na GitHubu. Ta umožňuje specifikovat zaškrtávací políčka:
# Description Please include a summary of the change and which issue is fixed. Please also include relevant motivation and context. List any dependencies that are required for this change. Fixes # (issue) ## Type of change Please delete options that are not relevant. - [ ] Bug fix (non-breaking change which fixes an issue) - [ ] New feature (non-breaking change which adds functionality) - [ ] Breaking change (fix or feature that would cause existing functionality to not work as expected) - [ ] This change requires a documentation update

Obrázek 6: Mnohé moderní textové editory, například Atom, mají interní prohlížeč souborů ve formátu Markdown.

Obrázek 7: Dtto, ovšem s jinou barvovou paletou.
Existuje i formální specifikace Markdownu nazývaná CommonMark, jejímž primárním autorem je John MacFarlane.
15. Texy!
Zapomenout nesmíme ani na značkovací jazyk Texy!, jehož autorem je David Grudl. Texy! se v mnoha ohledech podobá výše popsanému Markdownu (základní struktura) či AsciiDocu (podpora tabulek), navíc jsou ovšem podporovány dvě důležité vlastnosti – stylování s využitím CSS (výstup je prováděn do HTML) a taktéž podpora pro rozdělování dlouhých slov podle konkrétního jazyka. Velmi pěkná je podpora tabulek, protože je možné nejenom zvolit zarovnání sloupců, ale navíc je možné vybrané buňky slučovat a stylovat. Podobnost základního formátu dokumentů je ostatně patrná i z ukázkového příkladu:
Titulek ********** Lorem ipsum Nadpis první úrovně ========== Lorem ipsum Nadpis druhé úrovně ---------------- Lorem ipsum **tučný text** a samozřejmě i *kurzíva* Podporován je i `text s pevnou šířkou znaků`, podobně jako v dalších podobně koncipovaných jazycích. Odkazy vypadají takto: "Root":https://www.root.cz Seznamy s odrážkami ======== * prvek * prvek * prvek - prvek - prvek - prvek Číslované seznamy ================ 1. prvek 1. prvek 1. prvek Programový kód ===============
/--php
x = 0
y = 2
\--
\---
Texy! si můžete vyzkoušet přímo ve webovém textovém editoru dostupném na adrese https://editor.texy.info/:
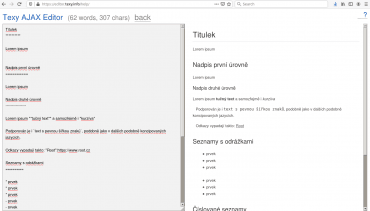
Obrázek 8: Webový editor značkovacího jazyka Texy!.
Taktéž si můžete vyzkoušet konverzi mezi Texy! a Markdownem (nefunguje v případě tabulek):
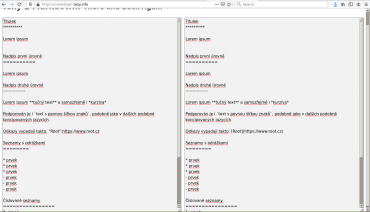
Obrázek 9: Konverze mezi značkovacími jazyky Texy! a Markdown.
16. Značkovací jazyky vs. řídicí kódy
V souvislosti se značkovacími jazyky se musíme zmínit i o vlastně velmi podobném systému. Jedná se o souborové formáty používané některými (vetšinou staršími) textovými editory a procesory. Některé z těchto formátů byly založeny na jednoduché myšlence – do zapisovaného textu se budou vkládat speciální řídicí znaky určující, jak se text bude při sazbě formátovat. Takovým znakem mohl v jednoduchém případě být znak (či dvojice znaků) s významem „zapni sazbu tučného písma“, „měkký konec řádku v rámci odstavce“, „nedělitelná mezera“, „vypni sazbu vysokého písma“ apod. K těmto znakům se postupně přidávaly i složitější řídicí kódy nebo (většinou) jejich sekvence, které například umožňovaly vkládání obrázků či byly určený k takzvanému mail merge, což je systém použitelný například pro tisk obálek, vysvědčení, obchodních dopisů atd. (stejná šablona, odlišný obsah). V navazujících třech kapitolách se ve stručnosti seznámíme se třemi takto koncipovanými formáty.

Obrázek 10: Wang 1220 je jedním z prvních modelů specializovaných zařízení firmy Wang Laboratories určených pro přípravu a editaci textů, jejich ukládání na magnetické pásky (jednotka pro magnetické pásky je umístěná napravo) a dokonce i pro provádění jednoduchého vyplňování formulářů z databáze (mail-merge).
Původní textové procesory byly založeny na vkládání specializovaných značek nebo celých složitých kódů do vytvářeného textu, takže uživatelé (většinou sekretářky pracující ve velkých společnostech v samostatném oddělení vyhrazeném pouze pro práci s dokumenty) ve skutečnosti na obrazovce terminálu neviděli pouze vlastní text, který bude později vytištěn, ale i další znaky, jež byly pro běžné korporátní uživatele spíše matoucí.

Obrázek 11: Na pravé straně klávesnice zařízení Wang 1220 byly umístěny klávesy pro ovládání textového procesoru.
17. WordStar
Od konce sedmdesátých let až do zhruba poloviny osmdesátých let minulého století byl nejznámějším a současně i nejprodávanějším textovým procesorem slavný WordStar. Historie tohoto textového procesoru, který je například Johnem C. Dvorakem považován za jednu z nejlepších aplikací, která kdy byla vytvořena, sahá až do roku 1977. V tomto roce si totiž Seymour Rubinstein (jeden ze zaměstnanců firmy IMSAI) pročetl studii společnosti Datapro, která se zabývala specializovanými systémy s textovými procesory, a rozhodl se, že založí čistě softwarovou společnost orientovanou převážně na tento segment trhu. O rok později – v roce 1978 – založil Rubinstein firmu MicroPro a přesvědčil svého bývalého kolegu Johna Robbinse Barnabyho, aby se k nově založené firmě připojil a vyvíjel pro ni aplikace. Barnaby byl excelentní programátor v assembleru a o několik let později se stal jedním z nejznámějších programátorů celé éry vzestupu mikropočítačů.

Obrázek 12: Instalační diskety WordStaru 4 pro CP/M, který byl vydán v roce 1987. Jednalo se o jeden z posledních komerčních programů pro CP/M.
Zdroj: Wikipedia
Důvodem, proč se o tomto editoru zmiňujeme v dnešním článku, je jeho sada řídicích znaků, která určovala, jakým způsobem se má dokument vytisknout popř. zobrazit na obrazovce v režimu náhledu (Preview). Používaly se zejména jednobajtové kódy ležící mimo oblast tisknutelných znaků, konkrétně kódy 0 až 31 a dále kódy 141 až 160. Viz například http://justsolve.archiveteam.org/wiki/WordStar. To však není vše, protože kromě těchto 34 kódů se do dokumentu zapisovaly i takzvané „tečkové příkazy“ ne nepodobné příkazům výše zmíněné utility troff. I tyto příkazy je možné zobrazit na stránce http://justsolve.archiveteam.org/wiki/WordStar (dole), z níž lze mj. vyčíst i to, jaké formátování mohl WordStar při sazbě provádět (žádné další operace nebyly podporovány).

Obrázek 13: Klávesové zkratky editoru WordStar (a nepřeberného množství jeho nástupců) pro posun textového kurzoru. Základem je čtveřice kláves S, D, E, X umístěná do tvaru „diamantu“. Napravo a nalevo od diamantu jsou umístěny klávesy A a F s podobnou funkcí jako klávesy S a D, ovšem s větším dosahem – namísto posunu o jeden znak se prováděl posun o celé slovo. Zkratka Ctrl+Q navíc význam ještě zesiluje – kurzor se přesouvá na začátek a konec textového řádku, popř. na začátek a konec dokumentu. Tyto zkratky jsou snadno zapamatovatelné a využitelné zejména na klávesnicích, kde je CTRL umístěna nalevo od klávesy A (namísto celkem zbytečné klávesy Caps Lock). Prakticky všechny klávesnice počítačů, kde se WordStar používal, měly CTRL umístěno nalevo od A, teprve u PC AT došlo ke změně.
18. WordPerfect
Řídicí kódy se používaly i ve slavném WordPerfectu. Klíčové vlastnosti svého textového procesoru – použití implicitního vkládacího režimu, automatické reformátování textu při psaní a řízené skrývání či zobrazování řídicích značek (reveal codes) – popsal Alan Ashton ve specifikaci o délce cca padesáti stránek, která byla dokončena již na konci prázdnin roku 1977. Ovšem kromě „pouhé“ specifikace měl již naprogramovány některé nejdůležitější a nejzajímavější algoritmy, především vlastní vkládací režim a podprogramy pro automatické přeformátování textu po každé editační operaci. Přitom se nejedná o zcela primitivní záležitost, protože zejména na pomalejších počítačích bylo nutné provádět různé optimalizace (například při vložení znaku na začátek dokumentu je neefektivní posouvat celým dokumentem v paměti, takže se používají gap buffery atd.).

Obrázek 14: V pozdějších letech byl WordPerfect vydán i pro počítače Apple IIe a Apple IIc, což mimochodem svědčí o velké oblíbenosti těchto osmibitových mikropočítačů mezi uživateli (žijícími převážně v USA).
Z pohledu dnešního článku je nejdůležitější právě skutečnost, že tento textový procesor dokázal na požádání zobrazovat řídicí značky vkládané do textu (funkce reveal codes zmíněná v předchozím odstavci). To naznačuje, jakým způsobem vlastně byly dokumenty interně organizovány – jako sekvence znaků doplněná o řídicí značky (sekvence bajtů), tedy vlastně velmi podobným způsobem, jako je tomu ve značkovacích jazycích (opakem je složitá „objektová“ struktura používaná v moderních textových procesorech). Navíc se díky funkci reveal codes mohla snadno a rychle opravit většina problémů, s nimiž mnozí uživatelé v moderních editorech dennodenně bojují – například pokračování číslování prvků seznamu apod.

Obrázek 15: Textový procesor WordPerfect ve verzi pro DOS, kde byl v průběhu editace využíván standardní textový režim.
19. Text602
Text602 byl v tuzemsku jedničkou na poli aplikací určených pro zpracování textů. Text602 dokonce byl po mnoho let – a v některých úřadech a státních podnicích pravděpodobně dodnes je – považován za standard pro tvorbu textových dokumentů. Interně má Text602 mnoho společného s WordStarem, protože se používá i velmi systém řídicích kódů a „tečkových příkazů“ (zde se používá zavináč namísto tečky), takže se opět jedná o jednu z forem zobecněného značkovacího jazyka.

Obrázek 16: Textový procesor Text602 zobrazený grafickou kartou EGA v rozlišení 640×350 v šestnácti barvách.

Samotný formát textových dokumentů editoru T602 je poměrně jednoduchý, což například usnadňuje převod starších dokumentů do HTML nebo TeXu (konverzní program lze napsat za několik desítek minut). Vlastní text je zapisován přesně v takovém tvaru a kódování, jak byl zapsán uživatelem. Mezi tento text se vkládají řídicí znaky pro změnu typu písma (například znak s ASCII kódem 02 zapíná a vypíná tučné písmo) a taktéž znak nahrazující konec řádku uvnitř odstavce (tento znak je editorem vytvářen při automatickém formátování odstavce). Kromě řídicích znaků se mohou v souboru nacházet i řádky začínající zavináčem, za nímž je zapsána dvojice znaků následovaná mezerou a případnými parametry. Na těchto řádcích jsou uloženy parametry editace, například délka strany (@PL), pozice tabelačních zarážek (@TB), pravý okraj (@RM). Samotný textový editor ignoruje parametry, které nezná, což mj. znamená, že bylo poměrně snadné formát rozšiřovat, což se stalo minimálně jednou s příchodem verze 3.1, která podporovala – i když dosti diskutabilně – styly odstavce.

Obrázek 17: Textový procesor Text602 zobrazený poměrně neznámou kartou MCGA, která v režimu nejvyššího rozlišení 640×480 měla jen jednu bitovou rovinu a tím pádem podporovala pouze současné zobrazení dvou barev.
20. Odkazy na Internetu
- The Text Processor for Typesetters
https://troff.org/ - The history of troff
https://troff.org/history.html - Macro packages (for troff)
https://troff.org/macros.html - Markup language (Wikipedia)
https://en.wikipedia.org/wiki/Markup_language - roff (software)
https://en.wikipedia.org/wiki/Roff_(software) - Troff Resources
http://www.kohala.com/start/troff/troff.html - List of markup languages (Wikipedia)
https://en.wikipedia.org/wiki/List_of_markup_languages - Lightweight markup language
https://en.wikipedia.org/wiki/Lightweight_markup_language - WordPerfect
http://texteditors.org/cgi-bin/wiki.pl?WordPerfect - RSS (Wikipedia)
https://en.wikipedia.org/wiki/RSS - XML RSS
https://www.w3schools.com/XML/xml_rss.asp - Atom (Web standard)
https://en.wikipedia.org/wiki/Atom_(Web_standard) - JSON feed
https://jsonfeed.org/ - Nástroje pro tvorbu grafů a diagramů z příkazové řádky (root.cz)
https://www.root.cz/clanky/nastroje-pro-tvorbu-grafu-a-diagramu-z-prikazove-radky/ - Nástroje pro tvorbu UML diagramů z příkazové řádky (root.cz)
https://www.root.cz/clanky/nastroje-pro-tvorbu-uml-diagramu-z-prikazove-radky/ - Nástroje pro tvorbu UML diagramů z příkazové řádky (II) (root.cz)
https://www.root.cz/clanky/nastroje-pro-tvorbu-uml-diagramu-z-prikazove-radky-ii/ - Making Pictures With GNU PIC
http://floppsie.comp.glam.ac.uk/Glamorgan/gaius/web/pic.html - What is Texy
https://texy.info/en/ - Texy AJAX Editor
https://editor.texy.info/en/try/ - Texy help
https://editor.texy.info/help/ - Texy syntax
https://texy.info/en/syntax - Atlas
https://docs.atlas.oreilly.com/index.html - Atlas – Writing in Markdown
https://docs.atlas.oreilly.com/writing_in_markdown.html - Atlas – Writing in AsciiDoc
https://docs.atlas.oreilly.com/writing_in_asciidoc.html - HTMLBook
https://github.com/oreillymedia/HTMLBook - HTMLBook (Draft)
http://oreillymedia.github.io/HTMLBook/ - HTMLBook schema
https://github.com/oreillymedia/HTMLBook/tree/master/schema - DocBook
https://en.wikipedia.org/wiki/DocBook - An introduction to DocBook, a flexible markup language worth learning
https://opensource.com/article/17/9/docbook - DocBook 5: The Definitive Guide
https://tdg.docbook.org/tdg/5.0/docbook.html - CommonMark
https://commonmark.org/ - XSL Formatting Objects
https://en.wikipedia.org/wiki/XSL_Formatting_Objects - Ruby Document format
https://en.wikipedia.org/wiki/Ruby_Document_format - RDoc – Ruby Documentation System
https://ruby.github.io/rdoc/ - Plain Old Documentation
https://en.wikipedia.org/wiki/Plain_Old_Documentation - CommonMark Spec
https://spec.commonmark.org/ - William W. Tunnicliffe
https://en.wikipedia.org/wiki/William_W._Tunnicliffe - roff(7) – Linux man page
https://linux.die.net/man/7/roff - Basic Formatting with troff/nroff
http://cmd.inp.nsk.su/old/cmd2/manuals/unix/UNIX_Unleashed/ch08.htm - Publications that use troff
https://troff.org/pubs.html - Making Pictures With GNU PIC
http://floppsie.comp.glam.ac.uk/Glamorgan/gaius/web/pic.html - Atom: moderní textový editor
https://www.root.cz/clanky/atom-moderni-textovy-editor/ - A ReStructuredText Primer
https://docutils.readthedocs.io/en/sphinx-docs/user/rst/quickstart.html - reStructuredText Markup Specification
https://docutils.sourceforge.io/docs/ref/rst/restructuredtext.html - Web 2.0
https://en.wikipedia.org/wiki/Web2.0 - Creole (markup)
https://en.wikipedia.org/wiki/Creole_(markup) - AsciiDoc Syntax Quick Reference
https://asciidoctor.org/docs/asciidoc-syntax-quick-reference/ - Basic Syntax
https://www.markdownguide.org/basic-syntax - LaTeX – A document preparation system
https://www.latex-project.org/ - Standard Generalized Markup Language (SGML)
https://www.techopedia.com/definition/1898/standard-generalized-markup-language-sgml - A brief SGML tutorial
https://www.w3.org/TR/WD-html40–970708/intro/sgmltut.html



































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU