
Obsah
1. Význam písmene „R“ ve jménu RPython
2. Automatické odvozování typů proměnných, argumentů i návratových hodnot funkcí
3. (Ne)podpora speciálních metod v RPythonu
4. Podporované a nepodporované operace při zpracování seznamů
5. Záporné indexy a použití kroku při výběru podseznamů
6. Práce s n-ticemi v RPythonu
7. Nejednoznačnost při volání metody potenciálně různých tříd
8. Nejednoznačnost při volání metod s různým počtem argumentů
9. Použití aserce pro zamezení některých chyb při překladu
10. Alternativní přístup k překladu Pythonu do nativního kódu: projekt Cython
13. Ukázka překladu Pythonu do spustitelného (nativního) programu
14. Program pro vytvoření skriptu určeného pro překlad Pythonovského programu do nativního kódu
15. Soubor Makefile pro překlad a slinkování programu typu „Hello world!“
16. Benchmark pro výpočet Mandelbrotovy množiny – překlad originálního kódu Cythonem
17. Přidání informace o datových typech argumentů funkce i lokálních proměnných
18. Výsledky benchmarků a možnosti dalšího vylepšení
19. Repositář s demonstračními příklady
1. Význam písmene „R“ ve jménu RPython
V úvodním článku o projektu RPython jsme se seznámili se základními postupy, na nichž je tento projekt založen. Připomeňme si ve stručnosti, že RPython je určen pro překlad programů napsaných v podmnožině programovacího jazyka Python do nativního kódu, ať již se jedná o přímo spustitelný kód či o dynamicky linkovanou knihovnu (.so, .dll). Samotný projekt RPython byl vyvinut primárně pro autory interpretrů a překladačů dalších programovacích jazyků (využit je například v projektu Pixie) a autoři RPythonu nepředpokládají, že by byl masivně využíván mimo tuto dosti úzce vymezenou oblast (samozřejmě to však nezakazují). Pokud se přesto rozhodnete RPython využít ve svém projektu, například pro urychlení některých výpočtů, je nutné se již dopředu připravit na tři potenciální problémy:
- Počáteční písmeno v názvu „RPython“ znamená „restricted“, což se týká jak omezení, která nám klade vlastní jazyk, tak i omezení dostupných knihoven. Pokud se však skutečně překládají výpočty či simulace, nemusí být tato vlastnost RPythonu příliš omezující.
- Některá chybová hlášení RPythonu jsou poněkud kryptická a pro jejich vyluštění je dobré vědět, jakým způsobem vlastně RPython provádí překlad. Právě z tohoto důvodu si v navazujících kapitolách význam některých chybových hlášení popíšeme podrobněji.
- Čas překladu je v porovnání s dále zmíněným Cythonem významně delší. Na mém obstarožním notebooku s procesorem i5 (4×M 540 @ 2.53GHz) trvá překlad i jednoduchého programu typu „Hello world!“ prakticky přesně 25 sekund, což při vývoji může být otravné. Na druhou stranu je většina chyb vedoucích k zastavení překladu detekována již na samotném začátku celého procesu (v Cythonu je překlad explicitně rozdělen na transformaci do C a spuštění překladače s linkerem).
Vraťme se nyní k tématu, kterým jsme se již částečně začali zabývat minule. Jedná se o typový systém RPythonu. RPython totiž kvůli překladu do nativního kódu potřebuje znát typ proměnných, argumentů funkcí i návratových hodnot funkcí. Navíc tuto znalost musí rozšířit z oblasti přiřazení hodnoty do proměnné (zde je typ ve všech případech zřejmý) i do všech dalších částí programu. Původní varianty RPythonu neumožnily po prvním přiřazení hodnoty do proměnné měnit její typ, ovšem současné varianty to umožňují (za předpokladu, že se dodrží podmínky popsané později), což je ostatně patrné i z dnešního prvního příkladu. Povšimněte si, že se v tomto příkladu jedné lokální proměnné postupně přiřazují hodnoty různých typů:
def entry_point(argv):
x = "one"
print x
x = 2
print x
x = None
print x
x = True
print x
x = range(10)
print x[1]
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Tento program by měl jít bez problémů přeložit i spustit.
2. Nejčastější chyba při analýze kódu: UnionError
Při pohledu na předchozí demonstrační příklad by se mohlo zdát, že RPython dokáže typ hodnoty určit vlastně kdykoli a kdekoli. Ve skutečnosti tomu tak není, což si ukážeme na třech zdánlivě totožných příkladech, přičemž první dva příklady jsou přeložitelné, zatímco třetí příklad vypíše při pokusu o překlad chybové hlášení.
V prvním příkladu je pomocná funkce f volána dvakrát, a to s argumentem param vždy nastaveným na hodnotu False. V tomto případě překladač při analýze CFG vlastně nikdy neprojde první větví ve funkci f a překlad (včetně analýzy celého „flow“) proběhne v pořádku:
def f(param):
if param:
return 42
else:
return "foobar"
def entry_point(argv):
z = f(False)
print z
w = f(False)
print w
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Druhá varianta příkladu je prakticky totožná s variantou předchozí, ovšem až na ten detail, že funkce f je vždy volána s argumentem param nastaveným na True a tudíž se řízení programu nikdy nedostane do větve else. I tento příklad bude možné bez problémů přeložit a spustit:
def f(param):
if param:
return 42
else:
return "foobar"
def entry_point(argv):
z = f(True)
print z
w = f(True)
print w
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Konečně se dostáváme k poslední variantě, ve které se (v runtime) volá funkce f opět dvakrát, tentokrát však s odlišnou hodnotou parametru:
def f(param):
if param:
return 42
else:
return "foobar"
def entry_point(argv):
z = f(True)
print z
w = f(False)
print w
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
V klasickém Pythonu to v žádném případě není nijak problematické chování – funkce prostě při prvním volání vrátí hodnotu 42 a při volání druhém hodnotu „foobar“. Ovšem překladač RPythonu je v tomto ohledu striktnější a vypíše chybu při překladu. Ta může vypadat poněkud krypticky, ovšem důležité je hlášení „UnionError“ a také přesné určení místa, kde k chybě došlo:
[translation:ERROR] UnionError:
Offending annotations:
SomeInteger(const=42, knowntype=int, nonneg=True, unsigned=False)
SomeString(const='foobar', no_nul=True)
In <FunctionGraph of (rpython_types_6:1)f at 0x7f60791ea890>:
<return block>
Processing block:
block@3[param_0] is a <class 'rpython.flowspace.flowcontext.SpamBlock'>
in (rpython_types_6:1)f
containing the following operations:
v2 = bool(param_0)
--end--
3. (Ne)podpora speciálních metod v RPythonu
Další omezení RPythonu, o němž je dobré vědět, spočívá v tom, že některé speciální metody nejsou v kódu (při svém volání) podporovány. Ze všech speciálních metod podporovaných Pythonem podporuje RPython pouze __init__ (pochopitelně), __del__ a kde to má význam, tak i __len__, __getitem__, __setitem__, __getslice__, __setslice__ a konečně __iter__. Samozřejmě si můžete vytvořit implementace všech speciálních metod, ovšem problém nastane při jejich nepřímém volání. Opět si ukažme příklad, v němž jsou deklarovány a následně i použity speciální metody __add__ a __str__:
class Foo:
def __init__(self, value):
self._value = value
def __add__(self, other):
return Foo(self._value + other._value)
def __str__(self):
return str(self._value)
def entry_point(argv):
f1 = Foo(1)
f2 = Foo(2)
f3 = f1 + f2
print(f1)
print(f2)
print(f3)
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Při překladu nastane tato chyba s kryptickým chybovým hlášením:
[translation:ERROR] AnnotatorError:
Blocked block -- operation cannot succeed
f3_0 = add(f1_0, f2_0)
In <FunctionGraph of (plus_operator:13)entry_point at 0x7fddd3897910>:
Happened at file plus_operator.py line 17
f1 = Foo(1)
f2 = Foo(2)
==> f3 = f1 + f2
print(f1)
print(f2)
print(f3)
Known variable annotations:
f1_0 = SomeInstance(can_be_None=False, classdef=plus_operator.Foo)
f2_0 = SomeInstance(can_be_None=False, classdef=plus_operator.Foo)
Úprava je prozatím jediná možná – volat nepodporované speciální metody explicitně, což je použito v dalším příkladu:
class Foo:
def __init__(self, value):
self._value = value
def __add__(self, other):
return Foo(self._value + other._value)
def __str__(self):
return str(self._value)
def entry_point(argv):
f1 = Foo(1)
f2 = Foo(2)
f3 = f1.__add__(f2)
print(f1.__str__())
print(f2.__str__())
print(f3.__str__())
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Tento příklad již bude možné korektně přeložit i spustit.
4. Podporované a nepodporované operace při zpracování seznamů
Seznamy jakožto jedny ze základních datových typů Pythonu jsou v RPythonu samozřejmě podporovány, ale opět s několika omezeními. První omezení spočívá v tom, že seznamy musí být homogenní, tj. všechny jejich prvky musí být stejného typu (popř. mohou být nastaveny na None). V dalším příkladu není tato podmínka splněna a proto příklad nepůjde přeložit:
def entry_point(argv):
l1 = [1, 2, 3, 4]
l2 = ['a', 'b', 'c', 'd']
l3 = [1, 'a']
print l1
print l2
print l3
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Při pokusu o překlad opět dostaneme hlášení o chybě typu UnionError:
[translation:ERROR] UnionError:
Offending annotations:
SomeInteger(const=1, knowntype=int, nonneg=True, unsigned=False)
SomeChar(const='a', no_nul=True)
l3_0 = newlist((1), ('a'))
In <FunctionGraph of (rpython_list:1)entry_point at 0x7f795b6c0750>:
Happened at file rpython_list.py line 4
l1 = [1, 2, 3, 4]
l2 = ['a', 'b', 'c', 'd']
==> l3 = [1, 'a']
print l1
print l2
print l3
Navíc ještě RPython vypíše doplňující informace o právě zpracovávaném bloku programu:
Known variable annotations:
Processing block:
block@12[argv_0] is a <class 'rpython.flowspace.flowcontext.SpamBlock'>
in (rpython_list:1)entry_point
containing the following operations:
l1_0 = newlist((1), (2), (3), (4))
l2_0 = newlist(('a'), ('b'), ('c'), ('d'))
l3_0 = newlist((1), ('a'))
v0 = str(l1_0)
v1 = simple_call((function rpython_print_item), v0)
v2 = simple_call((function rpython_print_newline))
v3 = str(l2_0)
v4 = simple_call((function rpython_print_item), v3)
v5 = simple_call((function rpython_print_newline))
v6 = str(l3_0)
v7 = simple_call((function rpython_print_item), v6)
v8 = simple_call((function rpython_print_newline))
5. Záporné indexy a použití kroku při výběru podseznamů
Při výběru prvků ze seznamu je možné používat jak kladné, tak i záporné indexy podle toho, zda potřebujeme prvky vybírat od začátku či od konce seznamu. Omezení však existuje při výběru podseznamů s použitím operátoru [od:do]. V tomto případě není možné použít krok (je vždy nastaven na jedničku) a navíc jediný podporovaný záporný index (pro indexování od konce seznamu) může mít hodnotu pouze –1; další hodnoty nejsou povoleny. To například znamená, že tento demonstrační příklad opět nepůjde přeložit, i když se jedná o korektní kód v Pythonu. RPython ovšem (v současné verzi) nemůže odvodit tvar výsledného kódu:
def entry_point(argv):
t = ["a", "b", "c", "d"]
for i in range(len(t)):
print i, t[:-1-i]
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Chybové hlášení v tomto případě opět obsahuje smysluplnou zprávu:
[translation:ERROR] AnnotatorError:
slicing: not proven to have non-negative stop
v1 = getslice(t_0, (None), v0)
In <FunctionGraph of (rpython_list_slicing:1)entry_point at 0x7fa669592910>:
Happened at file rpython_list_slicing.py line 5
==> print i, t[:-1-i]
Known variable annotations:
t_0 = SomeList(listdef=<[SomeChar(no_nul=True)]>)
v0 = SomeInteger(knowntype=int, nonneg=False, unsigned=False)
Processing block:
block@46[v2...] is a <class 'rpython.flowspace.flowcontext.SpamBlock'>
in (rpython_list_slicing:1)entry_point
containing the following operations:
v3 = str(i_0)
v4 = simple_call((function rpython_print_item), v3)
v0 = sub((-1), i_0)
v1 = getslice(t_0, (None), v0)
v5 = str(v1)
v6 = simple_call((function rpython_print_item), v5)
v7 = simple_call((function rpython_print_newline))
Pokus o použití kroku odlišného od dvojky:
def entry_point(argv):
t = ["a", "b", "c", "d"]
for i in range(len(t)):
print i, t[1:i:2]
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Chybová zpráva RPythonu:
[translation:ERROR] AnnotatorError:
Cannot use extended slicing in rpython
v0 = newslice((1), i_0, (2))
In <FunctionGraph of (rpython_list_slicing_2:1)entry_point at 0x7f49a8a428d0>:
Happened at file rpython_list_slicing_2.py line 5
==> print i, t[1:i:2]
Known variable annotations:
i_0 = SomeInteger(knowntype=int, nonneg=True, unsigned=False)
Processing block:
block@46[v1...] is a <class 'rpython.flowspace.flowcontext.SpamBlock'>
in (rpython_list_slicing_2:1)entry_point
containing the following operations:
v2 = str(i_0)
v3 = simple_call((function rpython_print_item), v2)
v0 = newslice((1), i_0, (2))
v4 = getitem(t_0, v0)
v5 = str(v4)
v6 = simple_call((function rpython_print_item), v5)
v7 = simple_call((function rpython_print_newline))
--end--
6. Práce s n-ticemi v RPythonu
N-tice jsou v RPythonu sice taktéž podporovány, ale existuje zde jedno poměrně zásadní omezení – indexy použité pro výběr prvků n-tic musí být konstantní již v době překladu (compile time). To například znamená, že následující demonstrační příklad nebude korektně přeložen:
def entry_point(argv):
t = ("a", "b", "c", "d")
for i in range(len(t)):
print i, t[i]
return 0
def target(driver, args):
print "*** target ***"
return entry_point, None
Zkrácená chyba při překladu nyní obsahuje jednoznačnou zprávu:
[translation:ERROR] TyperError: non-constant tuple index
.. (rpython_tuple:1)entry_point
.. block@34[v13...] with 1 exits
.. v14 = getitem((('a', 'b', 'c', 'd')), i_0)
Jedno z řešení spočívá v převodu n-tice na seznam (ostatně použití nekonstantních indexů při práci s n-ticemi může znamenat, že se tento datový typ nepoužívá v původním významu a že se spíše trošku zneužívá toho, že n-tice jsou neměnitelné).
7. Nejednoznačnost při volání metody potenciálně různých tříd
Dalším problémem, na který můžeme narazit při snaze o překlad běžných zdrojových kódů napsaných v Pythonu, je nejednoznačnost při volání metod. Python totiž řeší, kterou metodu (jakého objektu) volat až v čase běhu programu, takže následující kód je z hlediska klasického Pythonu bezproblémový, protože metoda foo může patřit ve chvíli jejího volání k instanci třídy ClassX nebo k instanci třídy ClassY, což je z pohledu tohoto dynamicky typovaného jazyka v pořádku:
class ClassX:
def foo(self):
print("ClassX.foo")
class ClassY:
def foo(self):
print("ClassY.foo")
def entry_point(argv):
obj = ClassX() if len(argv) == 3 else ClassY()
obj.foo()
return 0
def target(driver, args):
return entry_point, None
Z pohledu RPythonu se však jedná o chybnou jazykovou konstrukci:
[translation:ERROR] UnionError:
RPython cannot unify instances with no common base class
Offending annotations:
SomeInstance(can_be_None=False, classdef=classes1.ClassY)
SomeInstance(can_be_None=False, classdef=classes1.ClassX)
In <FunctionGraph of (classes1:11)entry_point at 0x7f9e866d6810>:
Happened at file classes1.py line 13
obj.foo()
Processing block:
block@21 is a <class 'rpython.flowspace.flowcontext.SpamBlock'>
in (classes1:11)entry_point
containing the following operations:
obj_0 = simple_call((classobj ClassX))
--end--
V tomto konkrétním případě můžeme program snadno opravit tím, že vytvoříme společného předka pro obě třídy ClassX a ClassY:
class SuperClass:
pass
class ClassX(SuperClass):
def foo(self):
print("ClassX.foo")
class ClassY(SuperClass):
def foo(self):
print("ClassY.foo")
def entry_point(argv):
obj = ClassX() if len(argv) == 2 else ClassY()
obj.foo()
return 0
def target(driver, args):
return entry_point, None
Pro úplnost si ukažme, jak předchozí funkci entry_point „vidí“ interpret Pythonu:
14 0 LOAD_GLOBAL 0 (len)
2 LOAD_FAST 0 (argv)
4 CALL_FUNCTION 1
6 LOAD_CONST 1 (2)
8 COMPARE_OP 2 (==)
10 POP_JUMP_IF_FALSE 18
12 LOAD_GLOBAL 1 (ClassX)
14 CALL_FUNCTION 0
16 JUMP_FORWARD 4 (to 22)
>> 18 LOAD_GLOBAL 2 (ClassY)
20 CALL_FUNCTION 0
>> 22 STORE_FAST 1 (obj)
15 24 LOAD_FAST 1 (obj)
26 LOAD_ATTR 3 (foo)
28 CALL_FUNCTION 0
30 POP_TOP
16 32 LOAD_CONST 2 (0)
34 RETURN_VALUE
Varianta se společným předkem:
17 0 LOAD_GLOBAL 0 (len)
2 LOAD_FAST 0 (argv)
4 CALL_FUNCTION 1
6 LOAD_CONST 1 (2)
8 COMPARE_OP 2 (==)
10 POP_JUMP_IF_FALSE 18
12 LOAD_GLOBAL 1 (ClassX)
14 CALL_FUNCTION 0
16 JUMP_FORWARD 4 (to 22)
>> 18 LOAD_GLOBAL 2 (ClassY)
20 CALL_FUNCTION 0
>> 22 STORE_FAST 1 (obj)
18 24 LOAD_FAST 1 (obj)
26 LOAD_ATTR 3 (foo)
28 CALL_FUNCTION 0
30 POP_TOP
19 32 LOAD_CONST 2 (0)
34 RETURN_VALUE
Vidíme, že všechny další informace musí interpret skutečně získat z konkrétních objektů v čase běhu programu.
8. Nejednoznačnost při volání metod s různým počtem argumentů
Na podobný problém můžeme narazit ve chvíli, kdy sice máme dvě třídy se společným předkem, ovšem každá třída obsahuje stejně pojmenovanou metodu s rozdílným počtem argumentů. I následující program může být (za určitých podmínek dodržených při jeho spuštění) zcela správným Pythonovským skriptem:
class SuperClass:
pass
class ClassX(SuperClass):
def foo(self):
print("ClassX.foo")
class ClassY(SuperClass):
def foo(self, dummy):
print("ClassY.foo")
def entry_point(argv):
obj = ClassX() if len(argv) == 2 else ClassY()
obj.foo()
return 0
def target(driver, args):
return entry_point, None
Jak již pravděpodobně předpokládáte, bude RPython hlásit při pokusu o překlad chyby, protože při analýze CFG bude brát v potaz jen volání metody ClassY.foo() a nikoli ClassX.foo(), což je poněkud matoucí:
[translation:ERROR] AnnotatorError:
signature mismatch: foo() takes exactly 2 arguments (1 given)
Occurred processing the following simple_call:
<MethodDesc 'foo' of <ClassDef 'classes3.ClassX'> bound to <ClassDef 'classes3.ClassX'> {}> returning
<MethodDesc 'foo' of <ClassDef 'classes3.ClassY'> bound to <ClassDef 'classes3.ClassY'> {}> returning
v1 = simple_call(v0)
In <FunctionGraph of (classes3:14)entry_point at 0x7f8f2736e890>:
Happened at file classes3.py line 16
==> obj.foo()
Known variable annotations:
v0 = SomePBC(can_be_None=False, descriptions={...2...}, knowntype=instancemethod, subset_of=None)
Processing block:
block@39[obj_0] is a <class 'rpython.flowspace.flowcontext.SpamBlock'>
in (classes3:14)entry_point
containing the following operations:
v0 = getattr(obj_0, ('foo'))
v1 = simple_call(v0)
v2 = str(v1)
v3 = simple_call((function rpython_print_item), v2)
v4 = simple_call((function rpython_print_newline))
--end--
9. Použití aserce pro zamezení některých chyb při překladu
Předchozí příklad je možné poněkud překvapivě snadno upravit: po vytvoření instance třídy ClassX nebo ClassY (ani my ani RPython nemůže vědět které) použijeme aserci, která RPython ujistí o tom, kterou instanci bude v kódu očekávat:
assert isinstance(obj, ClassX)
Myšlenka je celkem jednoduchá – před tímto řádkem mohla být v proměnné obj uložena reference na instanci třídy ClassX nebo ClassY (což RPython zjistí z CFG), ovšem za tímto řádkem to na 100% bude instance třídy ClassX, neboť jakákoli jiná hodnota by způsobila vyhození výjimky. To znamená, že následující kód již půjde přeložit:
class SuperClass:
pass
class ClassX(SuperClass):
def foo(self):
print("ClassX.foo")
class ClassY(SuperClass):
def foo(self, dummy):
print("ClassY.foo")
def entry_point(argv):
obj = ClassX() if len(argv) == 2 else ClassY()
assert isinstance(obj, ClassX)
obj.foo()
return 0
def target(driver, args):
return entry_point, None
10. Alternativní přístup k překladu Pythonu do nativního kódu: projekt Cython
Krátký seriál o RPythonu sice ještě neskončil, ovšem ve chvíli, kdy již známe princip práce RPythonu a jeho omezení (resp. omezení použitého jazyka) bude zajímavé si porovnat možnosti tohoto nástroje s dalšími překladači, které dokážou transformovat zdrojový kód Pythonu (popř. jeho podmnožinu nebo naopak nadmnožinu) do nativního kódu, ať již ve formě spustitelného souboru nebo sdílené knihovny. Jedním z nejznámějších a pravděpodobně i nejpoužívanějších projektů, které se zaměřují na překlad Pythonu, patří nástroj nazvaný Cython (pozor: neplést s podobně pojmenovaným CPythonem, což je ovšem označení klasického interpretru Pythonu, které se většinou používá ve chvíli, kdy je v nějakém kontextu zapotřebí rozlišit CPython od Jythonu a také Iron Pythonu). Dnes si popíšeme základní vlastnosti Cythonu a také si ukážeme výsledky benchmarku, o němž jsme se zmínili minule, který bude upraven pro Cython.

Obrázek 1: Logo Cythonu.
11. Princip práce Cythonu
Tento překladač pracuje poněkud odlišným způsobem než RPython. Zatímco se totiž RPython snaží odvozovat datové typy proměnných, argumentů i návratových hodnot funkcí na základě analýzy grafu (CFG), používá Cython přímý překlad Pythonu do programovacího jazyka C. Ve chvíli, kdy Cython nezná datový typ funkce/proměnné/argumentu, použije PyObject *, tedy ukazatel na datovou strukturu reprezentující v Pythonu libovolnou hodnotu. V dalším kódu je samozřejmě nutné z tohoto objektu získat skutečnou hodnotu. I takto vlastně velmi primitivně provedený překlad dokáže programový kód zrychlit, což ostatně uvidíme i ve výsledku benchmarků. Cython jde ale ještě dále, protože rozšiřuje jazyk Python o další klíčová slova, především pak o slovo cdef. Toto klíčové slovo je možné použít pro přesnou specifikaci typu proměnné či argumentu, a to způsobem, který plně vychází z programovacího jazyka C. Tato typová informace samozřejmě umožňuje provedení dalších optimalizací ve výsledném kódu (opět uvidíme na výsledcích benchmarku).
12. Instalace Cythonu
Samotná instalace Cythonu je velmi jednoduchá, ovšem aby bylo možné skutečně překládat Python do nativního kódu, je po instalaci nutné zajistit, aby byl v systému nainstalován překladač céčka (GCC, LLVM atd.) a taktéž vývojářské verze knihoven CPythonu (libpython2.7.so, libpython3.6m.so atd.). Začněme tedy nejdříve instalací Cythonu. Pro tento účel použijeme oblíbený nástroj pip. Samotná instalace je většinou záležitostí několika sekund:
$ pip3 install --user cython
Collecting cython
Cache entry deserialization failed, entry ignored
Downloading https://files.pythonhosted.org/packages/6f/79/d8e2cd00bea8156a995fb284ce7b6677c49eccd2d318f73e201a9ce560dc/Cython-0.28.3-cp36-cp36m-manylinux1_x86_64.whl (3.4MB)
100% |████████████████████████████████| 3.4MB 443kB/s
Installing collected packages: cython
Successfully installed cython-0.28.3
You are using pip version 9.0.1, however version 10.0.1 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
Po instalaci si můžeme ověřit, že je Cython dostupný:
$ cython --version Cython version 0.28.3
Taktéž je vhodné ověřit existenci nástroje cythonize, o němž se dále taktéž zmíníme:
$ cythonize --help
Usage: cythonize [options] [sources and packages]+
Options:
-h, --help show this help message and exit
-X NAME=VALUE,..., --directive=NAME=VALUE,...
set a compiler directive
-s NAME=VALUE, --option=NAME=VALUE
set a cythonize option
-3 use Python 3 syntax mode by default
-a, --annotate generate annotated HTML page for source files
-x PATTERN, --exclude=PATTERN
exclude certain file patterns from the compilation
-b, --build build extension modules using distutils
-i, --inplace build extension modules in place using distutils
(implies -b)
-j N, --parallel=N run builds in N parallel jobs (default: 12)
-f, --force force recompilation
-q, --quiet be less verbose during compilation
--lenient increase Python compatibility by ignoring some compile
time errors
-k, --keep-going compile as much as possible, ignore compilation
failures
Dále si pro jistotu ověřte existenci překladače céčka a linkeru:
$ gcc --version gcc (Ubuntu 4.8.4-2ubuntu1~14.04.4) 4.8.4 Copyright (C) 2013 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $ ld --version GNU ld (GNU Binutils for Ubuntu) 2.24 Copyright 2013 Free Software Foundation, Inc. This program is free software; you may redistribute it under the terms of the GNU General Public License version 3 or (at your option) a later version. This program has absolutely no warranty.
13. Ukázka překladu Pythonu do spustitelného (nativního) programu
Při popisu Cythonu začneme s tím nejjednodušším příkladem – s klasickým „Hello world!“. Ten se v Pythonu pochopitelně zapíše následovně:
print("Hello world!")
Překlad se provádí ve třech krocích, přičemž my si pro jednoduchost dva poslední kroky spojíme:
- Transformace zdrojového kódu Pythonu do ANSI C. Pro tento účel se používá nástroj cython, kterému můžeme volbou –embed říct, že má vytvořit soubor s funkcí main (tedy že nebudeme chtít překládat sdílenou knihovnu).
- Překlad zdrojového kódu z ANSI C do objektového souboru. Pro jednoduchost použijeme všudypřítomné gcc, ale samozřejmě lze použít i další překladače.
- Slinkování objektového souboru s potřebnými knihovnami a s vytvořením spustitelné aplikace. Buď se přímo zavolá linkerld, nebo se tento bod spojí s bodem předchozím (linker se tudíž zavolá implicitně z gcc).
Na mém konkrétním počítači s Fedorou 27 bude překlad proveden těmito dvěma kroky:
cython --embed hello_world.py gcc -O9 -I /usr/include/python3.6m/ -L/usr/lib64 -lpython3.6m hello_world.c -o hello_world
Především druhý krok nemusí být vašem systému fungovat, protože se budou lišit cesty k hlavičkovým souborům i k potřebným knihovnám. Jak tento nedostatek odstranit si ukážeme v navazující kapitole.
14. Program pro vytvoření skriptu určeného pro překlad Pythonovského programu do nativního kódu
Při volání překladače a linkeru je nutné specifikovat cesty ke hlavičkovým souborům Pythonu a taktéž cesty k vývojářským (sdíleným) knihovnám Pythonu. Tyto cesty se mohou na různých systémech lišit; navíc je nutné počítat s tím, že někteří vývojáři budou překlad a linkování provádět vůči Pythonu 2.x a jiní vůči Pythonu 3.x. Aby nebylo nutné složitě všechna nastavení zjišťovat pro každou novou konfiguraci, je možné použít následující (prozatím velmi jednoduchý) nástroj, kterému se předá jméno výsledné aplikace (přesněji řečeno jméno spustitelného souboru s aplikací). Nástroj následně na standardní výstup vypíše obsah shell skriptu připravený pro překlad aplikace na konkrétním počítači a s konkrétním Pythonem (záleží tedy, zda tento skript spustíte přes python2 make_build_script nebo python3 make_build_script:
# vim: set fileencoding=utf-8
from distutils import sysconfig
from sys import argv, exit
CC = "gcc"
CC_OPT = "-O9"
INCLUDE_DIR = sysconfig.get_python_inc()
LIBRARY_DIR = sysconfig.get_config_var('LIBDIR')
PYTHON_LIB = sysconfig.get_config_var('LIBRARY')[3:-2]
SYSTEM_LIBS = sysconfig.get_config_var('SYSLIBS')
if __name__ == "__main__":
if len(argv) <= 1:
print("usage: python make_build_script program_name > script.sh")
exit(1)
progname = argv[1]
print("# very simple variant of the build script tied to specific Python version and an CPU architecture\n") # noqa
print("rm -f {progname}.c".format(progname=progname))
print("rm -f {progname}\n".format(progname=progname))
print("cython --embed {progname}.py\n".format(progname=progname))
print("{cc} {cc_opt} -I {include_dir} -L{library_dir} -l{python_lib} {system_libs} {progname}.c -o {progname}".format( # noqa
cc=CC, cc_opt=CC_OPT, include_dir=INCLUDE_DIR, library_dir=LIBRARY_DIR,
python_lib=PYTHON_LIB, system_libs=SYSTEM_LIBS, progname=progname))
Ze zdrojového kódu je patrné, že se všechny potřebné informace mohou zjistit s využitím modulu distutils.sysconfig.
Výsledek vygenerovaný při spuštění nástroje Pythonem 2 na Linux Mintu (jméno aplikace je „hello_world“):
# very simple variant of the build script tied to specific Python version and an CPU architecture rm -f hello_world.c rm -f hello_world cython --embed hello_world.py gcc -O9 -I /usr/include/python2.7 -L/usr/lib -lpython2.7 -lm hello_world.c -o hello_world
Výsledek při spuštění nástroje Pythonem 2 na Fedoře 27:
# very simple variant of the build script tied to specific Python version and an CPU architecture rm -f hello_world.c rm -f hello_world cython --embed hello_world.py gcc -O9 -I /usr/include/python2.7 -L/usr/lib64 -lpython2.7 -lm hello_world.c -o hello_world
Výsledek při spuštění nástroje Pythonem 3 na postarším Linux Mintu s Pythonem 3.4:
# very simple variant of the build script tied to specific Python version and an CPU architecture rm -f hello_world.c rm -f hello_world cython --embed hello_world.py gcc -O9 -I /usr/include/python3.4m -L/usr/lib -lpython3.4m -lm hello_world.c -o hello_world
Výsledek při spuštění nástroje Pythonem 3 na Fedoře 27 s Pythonem 3.6:
# very simple variant of the build script tied to specific Python version and an CPU architecture rm -f hello_world.c rm -f hello_world cython --embed hello_world.py gcc -O9 -I /usr/include/python3.6m -L/usr/lib64 -lpython3.6m -lm hello_world.c -o hello_world
15. Soubor Makefile pro překlad a slinkování programu typu „Hello world!“
Na základě znalostí získaných z předchozí kapitoly dokonce můžeme vytvořit Makefile určený pro překlad našeho jednoduchého demonstračního příkladu hello_world. Tento Makefile vznikl zjednodušením příkladu, který naleznete na adrese https://github.com/cython/cython/blob/master/Demos/embed/Makefile:
PYTHON=python3
COMPILER=gcc
LINKER=gcc
# GCCOPTIONS=-O9 -ffast-math
CCOPTIONS=-O9
INCLUDE_DIR:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_python_inc())")
LIBRARY_DIR:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_config_var('LIBDIR'))")
PYTHON_LIB:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_config_var('LIBRARY')[3:-2])")
SYSLIBS:=$(shell $(PYTHON) -c "import distutils.sysconfig; print(distutils.sysconfig.get_config_var('SYSLIBS'))")
all: hello_world
hello_world: hello_world.o
$(LINKER) -o $@ $^ -L$(LIBRARY_DIR) -l$(PYTHON_LIB) $(SYSLIBS)
hello_world.o: hello_world.c
$(COMPILER) $(CCOPTIONS) -I$(INCLUDE_DIR) -c $<
hello_world.c: hello_world.py
cython --embed $<
clean:
rm -f hello_world
rm -f hello_world.c
rm -f hello_world.o
Použití Makefile je snadné:
$ cd hello_world $ make
16. Benchmark pro výpočet Mandelbrotovy množiny – překlad originálního kódu Cythonem
Jak jsme si slíbili v perexu článku, pokusíme se porovnat RPython s Cythonem s využitím jednoduchého benchmarku, který měří rychlost výpočtu obrázků Mandelbrotovy množiny. První verze příkladu bude vytvořena v čistém Pythonu, který přeložíme Cythonem a GCC do nativního kódu. Výsledek pravděpodobně nebude nijak rychlý, protože jsme Cythonu neposkytli žádné informace o typech proměnných či parametrů (tzv. type hints). Zdrojový kód vypadá takto:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
import palette_mandmap
from sys import argv, exit
def calc_mandelbrot(width, height, maxiter, palette):
print("P3")
print("{w} {h}".format(w=width, h=height))
print("255")
cy = -1.5
for y in range(0, height):
cx = -2.0
for x in range(0, width):
zx = 0.0
zy = 0.0
i = 0
while i < maxiter:
zx2 = zx * zx
zy2 = zy * zy
if zx2 + zy2 > 4.0:
break
zy = 2.0 * zx * zy + cy
zx = zx2 - zy2 + cx
i += 1
r = palette[i][0]
g = palette[i][1]
b = palette[i][2]
print("{r} {g} {b}".format(r=r, g=g, b=b))
cx += 3.0/width
cy += 3.0/height
if __name__ == "__main__":
if len(argv) < 4:
print("usage: python mandelbrot width height maxiter")
exit(1)
width = int(argv[1])
height = int(argv[2])
maxiter = int(argv[3])
calc_mandelbrot(width, height, maxiter, palette_mandmap.palette)
Pro úplnost je zde uveden i listing modulu s barvovou paletou. Zde se vlastně žádný kód nenachází, pouze n-tice obsahující 256 trojic, tj. dalších n-tic:
# taken from Fractint
palette = (
(255, 255, 255), (224, 224, 224), (216, 216, 216), (208, 208, 208),
(200, 200, 200), (192, 192, 192), (184, 184, 184), (176, 176, 176),
(168, 168, 168), (160, 160, 160), (152, 152, 152), (144, 144, 144),
(136, 136, 136), (128, 128, 128), (120, 120, 120), (112, 112, 112),
(104, 104, 104), (96, 96, 96), (88, 88, 88), (80, 80, 80),
(72, 72, 72), (64, 64, 64), (56, 56, 56), (48, 48, 56),
(40, 40, 56), (32, 32, 56), (24, 24, 56), (16, 16, 56),
(8, 8, 56), (000, 000, 60), (000, 000, 64), (000, 000, 72),
(000, 000, 80), (000, 000, 88), (000, 000, 96), (000, 000, 104),
(000, 000, 108), (000, 000, 116), (000, 000, 124), (000, 000, 132),
(000, 000, 140), (000, 000, 148), (000, 000, 156), (000, 000, 160),
(000, 000, 168), (000, 000, 176), (000, 000, 184), (000, 000, 192),
(000, 000, 200), (000, 000, 204), (000, 000, 212), (000, 000, 220),
(000, 000, 228), (000, 000, 236), (000, 000, 244), (000, 000, 252),
(000, 4, 252), (4, 12, 252), (8, 20, 252), (12, 28, 252),
(16, 36, 252), (20, 44, 252), (20, 52, 252), (24, 60, 252),
(28, 68, 252), (32, 76, 252), (36, 84, 252), (40, 92, 252),
(40, 100, 252), (44, 108, 252), (48, 116, 252), (52, 120, 252),
(56, 128, 252), (60, 136, 252), (60, 144, 252), (64, 152, 252),
(68, 160, 252), (72, 168, 252), (76, 176, 252), (80, 184, 252),
(80, 192, 252), (84, 200, 252), (88, 208, 252), (92, 216, 252),
(96, 224, 252), (100, 232, 252), (100, 228, 248), (96, 224, 244),
(92, 216, 240), (88, 212, 236), (88, 204, 232), (84, 200, 228),
(80, 192, 220), (76, 188, 216), (76, 180, 212), (72, 176, 208),
(68, 168, 204), (64, 164, 200), (64, 156, 196), (60, 152, 188),
(56, 144, 184), (52, 140, 180), (52, 132, 176), (48, 128, 172),
(44, 120, 168), (40, 116, 160), (40, 108, 156), (36, 104, 152),
(32, 96, 148), (28, 92, 144), (28, 84, 140), (24, 80, 136),
(20, 72, 128), (16, 68, 124), (16, 60, 120), (12, 56, 116),
(8, 48, 112), (4, 44, 108), (000, 36, 100), (4, 36, 104),
(12, 40, 108), (16, 44, 116), (24, 48, 120), (28, 52, 128),
(36, 56, 132), (40, 60, 140), (48, 64, 144), (52, 64, 148),
(60, 68, 156), (64, 72, 160), (72, 76, 168), (76, 80, 172),
(84, 84, 180), (88, 88, 184), (96, 92, 192), (104, 100, 192),
(112, 112, 196), (124, 120, 200), (132, 132, 204), (144, 140, 208),
(152, 152, 212), (164, 160, 216), (172, 172, 220), (180, 180, 224),
(192, 192, 228), (200, 200, 232), (212, 212, 236), (220, 220, 240),
(232, 232, 244), (240, 240, 248), (252, 252, 252), (252, 240, 244),
(252, 224, 232), (252, 208, 224), (252, 192, 212), (252, 176, 204),
(252, 160, 192), (252, 144, 184), (252, 128, 172), (252, 112, 164),
(252, 96, 152), (252, 80, 144), (252, 64, 132), (252, 48, 124),
(252, 32, 112), (252, 16, 104), (252, 000, 92), (236, 000, 88),
(228, 000, 88), (216, 4, 84), (204, 4, 80), (192, 8, 76),
(180, 8, 76), (168, 12, 72), (156, 16, 68), (144, 16, 64),
(132, 20, 60), (124, 20, 60), (112, 24, 56), (100, 24, 52),
(88, 28, 48), (76, 32, 44), (64, 32, 44), (52, 36, 40),
(40, 36, 36), (28, 40, 32), (16, 44, 28), (20, 52, 32),
(24, 60, 36), (28, 68, 44), (32, 76, 48), (36, 88, 56),
(40, 96, 60), (44, 104, 64), (48, 112, 72), (52, 120, 76),
(56, 132, 84), (48, 136, 84), (40, 144, 80), (52, 148, 88),
(68, 156, 100), (80, 164, 112), (96, 168, 124), (108, 176, 136),
(124, 184, 144), (136, 192, 156), (152, 196, 168), (164, 204, 180),
(180, 212, 192), (192, 220, 200), (208, 224, 212), (220, 232, 224),
(236, 240, 236), (252, 248, 248), (252, 252, 252), (252, 252, 240),
(252, 252, 228), (252, 252, 216), (248, 248, 204), (248, 248, 192),
(248, 248, 180), (248, 248, 164), (244, 244, 152), (244, 244, 140),
(244, 244, 128), (244, 244, 116), (240, 240, 104), (240, 240, 92),
(240, 240, 76), (240, 240, 64), (236, 236, 52), (236, 236, 40),
(236, 236, 28), (236, 236, 16), (232, 232, 0), (232, 232, 12),
(232, 232, 28), (232, 232, 40), (236, 236, 56), (236, 236, 68),
(236, 236, 84), (236, 236, 96), (240, 240, 112), (240, 240, 124),
(240, 240, 140), (244, 244, 152), (244, 244, 168), (244, 244, 180),
(244, 244, 196), (248, 248, 208), (248, 248, 224), (248, 248, 236),
(252, 252, 252), (248, 248, 248), (240, 240, 240), (232, 232, 232))
Makefile pro překlad zdrojového kódu do nativní aplikace bude vypadat následovně. Povšimněte si použití optimalizací při překladu:
PYTHON=python3
COMPILER=gcc
LINKER=gcc
# GCCOPTIONS=-O9 -ffast-math
CCOPTIONS=-O9
INCLUDE_DIR:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_python_inc())")
LIBRARY_DIR:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_config_var('LIBDIR'))")
PYTHON_LIB:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_config_var('LIBRARY')[3:-2])")
SYSLIBS:=$(shell $(PYTHON) -c "from distutils import sysconfig; print(sysconfig.get_config_var('SYSLIBS'))")
all: mandelbrot_cython
mandelbrot_cython: mandelbrot_cython.o
$(LINKER) -o $@ $^ -L$(LIBRARY_DIR) -l$(PYTHON_LIB) $(SYSLIBS)
mandelbrot_cython.o: mandelbrot_cython.c
$(COMPILER) $(CCOPTIONS) -I$(INCLUDE_DIR) -c $<
mandelbrot_cython.c: mandelbrot_cython.py
cython --embed $<
clean:
rm -f mandelbrot_cython
rm -f mandelbrot_cython.c
rm -f mandelbrot_cython.o
17. Přidání informace o datových typech argumentů funkce i lokálních proměnných
Pro vylepšení výsledného strojového kódu vytvořeného Cythonem je nutné tomuto překladači pomoci a předat mu informace o typech proměnných a parametrů funkcí. K tomuto účelu se používá klíčové slovo cdef, které může nahradit def. Například hlavičku funkce pro výpočet Mandelbrotovy množiny můžeme upravit z:
def calc_mandelbrot(width, height, maxiter, palette):
...
...
...
do následujícího formátu, v němž specifikujeme (prozatím) typ třech parametrů:
cdef calc_mandelbrot(int width, int height, int maxiter, palette):
...
...
...
Podobně můžeme na začátku těla této funkce deklarovat typy všech lokálních proměnných (vlastně se jedná o předdeklaraci):
cdef double zx
cdef double zy
cdef double zx2
cdef double zy2
cdef double cx
cdef double cy
cdef int r
cdef int g
cdef int b
cdef int i
Výsledek sice stále není dokonalý (bude méně výkonný než čistý céčkový kód), ale interní smyčky již budou optimalizovány:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
import palette_mandmap
from sys import argv, exit
cdef calc_mandelbrot(int width, int height, int maxiter, palette):
cdef double zx
cdef double zy
cdef double zx2
cdef double zy2
cdef double cx
cdef double cy
cdef int r
cdef int g
cdef int b
cdef int i
print("P3")
print("{w} {h}".format(w=width, h=height))
print("255")
cy = -1.5
for y in range(0, height):
cx = -2.0
for x in range(0, width):
zx = 0.0
zy = 0.0
i = 0
while i < maxiter:
zx2 = zx * zx
zy2 = zy * zy
if zx2 + zy2 > 4.0:
break
zy = 2.0 * zx * zy + cy
zx = zx2 - zy2 + cx
i += 1
r = palette[i][0]
g = palette[i][1]
b = palette[i][2]
print("{r} {g} {b}".format(r=r, g=g, b=b))
cx += 3.0/width
cy += 3.0/height
if __name__ == "__main__":
if len(argv) < 4:
print("usage: python mandelbrot width height maxiter")
exit(1)
width = int(argv[1])
height = int(argv[2])
maxiter = int(argv[3])
calc_mandelbrot(width, height, maxiter, palette_mandmap.palette)
18. Výsledky benchmarků a možnosti dalšího vylepšení
Konečně se dostáváme k pravděpodobně nejzajímavější části celé druhé části dnešního článku věnované Cythonu. Porovnáme si totiž výsledky benchmarků výpočtu Mandelbrotovy množiny, které jsme si popsali minule, s novými benchmarky. První nový benchmark bude měřit dobu výpočtu původního pythonovského kódu přeloženého Cythonem do nativní aplikace. Ovšem v původním kódu nebyly obsaženy žádné informace o typech proměnných a parametrů, takže Cython při překladu musel používat datový typ PyObject * a nikoli přímo nativní datové typy podporované mikroprocesorem. Naproti tomu poslední benchmark byl proveden nativním kódem přeloženým ze souboru mandelbrot_cython.pyx, do kterého byly informace o typech přidány. Sice ne na všechna potřebná místa, ovšem vnitřní programová smyčka by měla být plně pokryta a tedy přeložena podobným způsobem, jako zdrojový kód naprogramovaný přímo v ANSI C. Nejprve se podívejme na všechny výsledky:
| Rozlišení | CPython 2 | CPython 3 | Jython | RPython | ANSI C | Cython | Cython (typy) |
|---|---|---|---|---|---|---|---|
| 16×16 | 0,01 | 0,03 | 2,25 | 0,00 | 0,00 | 0,03 | 0,03 |
| 24×24 | 0,01 | 0,03 | 1,87 | 0,00 | 0,00 | 0,02 | 0,02 |
| 32×32 | 0,02 | 0,03 | 1,95 | 0,00 | 0,00 | 0,03 | 0,02 |
| 48×48 | 0,03 | 0,04 | 2,14 | 0,00 | 0,00 | 0,03 | 0,02 |
| 64×64 | 0,05 | 0,06 | 2,02 | 0,00 | 0,00 | 0,04 | 0,03 |
| 96×96 | 0,09 | 0,10 | 2,17 | 0,01 | 0,00 | 0,06 | 0,03 |
| 128×128 | 0,16 | 0,16 | 2,52 | 0,02 | 0,00 | 0,10 | 0,04 |
| 192×192 | 0,34 | 0,34 | 2,73 | 0,05 | 0,01 | 0,20 | 0,05 |
| 256×256 | 0,57 | 0,59 | 2,79 | 0,07 | 0,02 | 0,34 | 0,08 |
| 384×384 | 1,27 | 1,34 | 3,93 | 0,16 | 0,04 | 0,74 | 0,16 |
| 512×512 | 2,26 | 2,34 | 5,48 | 0,29 | 0,07 | 1,32 | 0,27 |
| 768×768 | 5,08 | 5,52 | 9,41 | 0,65 | 0,16 | 2,89 | 0,60 |
| 1024×1024 | 9,32 | 9,69 | 13,70 | 1,17 | 0,29 | 5,17 | 1,03 |
| 1536×1536 | 24,48 | 21,99 | 28,50 | 2,61 | 0,67 | 11,63 | 2,28 |
| 2048×2048 | 36,27 | 36,70 | 54,22 | 4,62 | 1,19 | 21,39 | 4,15 |
| 3072×3072 | 84,82 | 83,41 | 104,16 | 10,53 | 2,68 | 46,42 | 10,14 |
| 4096×4096 | 150,31 | 152,21 | 203,18 | 18,64 | 4,75 | 88,67 | 16,42 |
Všechny výsledky si můžeme vynést do grafu, který však nebude příliš přehledný, neboť doba výpočtu v CPythonu a Jythonu výrazně mění vertikální měřítko :-):
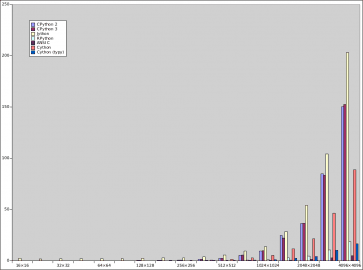
Obrázek 2: Porovnání doby výpočtu Mandelbrotovy množiny všemi sedmi variantami: CPython 2, CPython 3, Jython, RPython, ANSI C, Cython bez type hintů a konečně Cython s type hinty.
Přehlednější je druhý graf, ve kterém je na vertikální ose použito logaritmické měřítko:
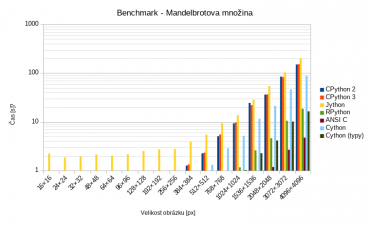
Obrázek 3: Porovnání doby výpočtu Mandelbrotovy množiny všemi sedmi variantami: CPython 2, CPython 3, Jython, RPython, ANSI C, Cython bez type hintů a konečně Cython s type hinty. Vertikální osa používá logaritmické měřítko pro větší přehlednost.
V posledním grafu jsou vyneseny časy výpočtu provedené pouze kódem přeloženým RPythonem, ANSI C, Cythonem bez type hintů a konečně Cythonem s type hinty:

Obrázek 4: Porovnání doby výpočtu Mandelbrotovy množiny RPythonem, Cythonem (bez i s type hinty) a variantou naprogramovanou přímo v ANSI C.
Vidíme, že kód vygenerovaný Cythonem je srovnatelně rychlý s RPythonem za předpokladu, že poskytneme typové informace pomocí cdef. Při pouhém překladu původního Pythonovského kódu nejsou výsledky tak oslnivé, ovšem stále jsou pochopitelně lepší, než při použití interpretrů. Nativní kód psaný v ANSI C je stále rychlejší, ovšem zdaleka jsme prozatím nevyužili všechny možnosti Cythonu. S těmito možnostmi se seznámíme příště.

18. Repositář s demonstračními příklady
Všechny demonstrační příklady, které jsme si v dnešním článku ukázali, naleznete na adrese https://github.com/tisnik/rpython-examples. Následují odkazy na jednotlivé příklady (pro jejich spuštění je nutné mít nainstalován RPython a jeho závislosti, především tedy překladač céčka):
Následuje tabulka s příklady, které souvisejí s Cythonem:
| # | Příklad | Adresa |
|---|---|---|
| 1 | hello_world | https://github.com/tisnik/rpython-examples/blob/master/examples/ |
| 2 | make_build_script | https://github.com/tisnik/rpython-examples/blob/master/cython/make_build_script/make_build_script.py |
| 3 | mandelbrot/cython-v1 | https://github.com/tisnik/rpython-examples/tree/master/benchmarks/mandelbrot/cython-v1 |
| 4 | mandelbrot/cython-v1 | https://github.com/tisnik/rpython-examples/tree/master/benchmarks/mandelbrot/cython-v2 |
20. Odkazy na Internetu
- The Magic of RPython
https://refi64.com/posts/the-magic-of-rpython.html - RPython: Frequently Asked Questions
http://rpython.readthedocs.io/en/latest/faq.html - RPython’s documentation
http://rpython.readthedocs.io/en/latest/index.html - RPython (Wikipedia)
https://en.wikipedia.org/wiki/PyPy#RPython - Getting Started with RPython
http://rpython.readthedocs.io/en/latest/getting-started.html - PyPy (home page)
https://pypy.org/ - PyPy (dokumentace)
http://doc.pypy.org/en/latest/ - Cython (home page)
http://cython.org/ - Cython (wiki)
https://github.com/cython/cython/wiki - Cython (Wikipedia)
https://en.wikipedia.org/wiki/Cython - Cython (GitHub)
https://github.com/cython/cython - Localized Type Inference of Atomic Types in Python (2005)
http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.90.3231 - Numba
http://numba.pydata.org/ - Tutorial: Writing an Interpreter with PyPy, Part 1
https://morepypy.blogspot.com/2011/04/tutorial-writing-interpreter-with-pypy.html - List of numerical analysis software
https://en.wikipedia.org/wiki/List_of_numerical_analysis_software - Pixie: lehký skriptovací jazyk s „kouzelnými“ schopnostmi
https://www.root.cz/clanky/pixie-lehky-skriptovaci-jazyk-s-kouzelnymi-schopnostmi/ - Programovací jazyk Pixie: funkce ze základní knihovny a použití FFI
https://www.root.cz/clanky/programovaci-jazyk-pixie-funkce-ze-zakladni-knihovny-a-pouziti-ffi/ - The future can be written in RPython now (článek z roku 2010)
http://blog.christianperone.com/2010/05/the-future-can-be-written-in-rpython-now/ - PyPy is the Future of Python (článek z roku 2010)
https://alexgaynor.net/2010/may/15/pypy-future-python/ - Portal:Python programming
https://en.wikipedia.org/wiki/Portal:Python_programming - Python Implementations: Compilers
https://wiki.python.org/moin/PythonImplementations#Compilers - RPython Frontend and C Wrapper Generator
http://www.codeforge.com/article/383293 - PyPy’s Approach to Virtual Machine Construction
https://bitbucket.org/pypy/extradoc/raw/tip/talk/dls2006/pypy-vm-construction.pdf - Tutorial: Writing an Interpreter with PyPy, Part 1
https://morepypy.blogspot.com/2011/04/tutorial-writing-interpreter-with-pypy.html - EmbeddingCython
https://github.com/cython/cython/wiki/EmbeddingCython - The Basics of Cython
http://docs.cython.org/en/latest/src/tutorial/cython_tutorial.html


































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU