
Dotazy zadané do webového vyhledávání prochází komplikovaným předzpracováním, jehož základním cílem je nalézt i stránky, které neobsahují přesně slova zadaná uživatelem. Tradičně se jedná například o expanzi dotazu o synonyma, skloňování a podobně. Velmi užitečným krokem v tomto směru je oprava chyb v dotazu, zejména různé gramatické chyby, překlepy a zkomoleniny, které znemožňují nalezení relevantních výsledků.
Vyhledávání Seznam.cz dotazy opravuje, přičemž z pohledu uživatele mohou nastat dva odlišné scénáře. Rozlišujeme tzv. „jistou opravu”, kdy jsou prezentovány přímo výsledky pro opravený dotaz, a „nejistou opravu”, kdy uživateli nabídneme opravený dotaz, ale zobrazíme výsledky pro dotaz původní. Pokud v takové situaci uživatel usoudí, že oprava je užitečná, získá příslušné výsledky kliknutím na navržený námi upravený dotaz. Rozhodnutí, jestli vydat jistou, nebo nejistou opravu je založené zejména na skóre opravy z našeho modelu a uživatelské zpětné vazbě.

Jistá a nejistá oprava dotazu. Pro dotaz „ramstajn” volíme nejistou opravu a uživateli nabídneme výsledky pro původní dotaz, protože možná hledal tuto častou zkomoleninu. Naopak pro dotaz „ramstein” nabízíme rovnou výsledky pro opravený dotaz, protože se patrně jedná o překlep.
Architektura oprav překlepů
V Seznamu opravujeme chyby v dotazech od roku 2015. Celková architektura je poměrně jednoduchá. Vstupní dotaz se nejprve normalizuje (lowercase, odstranění diakritiky apod.) a následně se pošle do tzv. suggesterů, které jednoduchými metodami vygenerují podobné dotazy. Příklad suggesteru je provedení záměny znaků z častých českých překlepů (y/i, s/z nebo š/3). Takto získaných kandidátů může být velké množství, proto je filtrujeme podle Levenshteinovy vzdálenosti od původního dotazu tak, aby jich pro typický dotaz zůstaly maximálně desítky. Pro každého kandidáta se pro potřeby opravy překlepů počítá přes 200 signálů (features) extrahujících řadu informací. Jsou zde signály týkající se vzdálenosti od původního dotazu, uživatelské zpětné vazby, detekce jmenných entit a další. Strojové učení (dvoufázové rankování pomocí gradient boosted trees) se postará o výběr nejlepší opravy (nebo původního dotazu). Nakonec se opravený dotaz opět obohatí o zahozenou diakritiku.
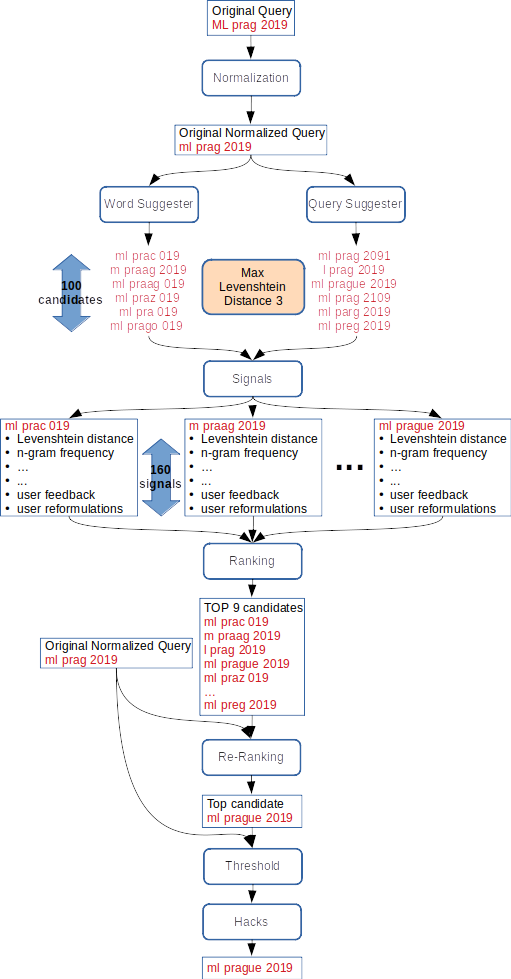
Architektura oprav překlepů. Jak lze vytušit, v této podobě byla prezentována na konferenci Machine Learning Prague 2019.
Uvedený systém oprav překlepů je léty prověřený a z pohledu kvality dostačující. Jeho nevýhodou je nedostatečná rychlost. Aby jednoduché suggestery měly dostatečné pokrytí, musí generovat velké množství kandidátů, což pro delší dotazy trvá dlouho (u nejpomalejších suggesterů desítky až stovky milisekund). Navíc je třeba pro tyto kandidáty napočítat signály a nechat seřadit rankerem. Naším cílem tedy bylo dosavadní systém úprav nahradit, nebo obohatit novým přístupem s hlubším pochopením textu.
Transformery a zpracování jazyka
Strojové učení a zejména hluboké neuronové sítě prochází v posledním desetiletí překotným vývojem. Ve zpracování přirozeného jazyka se osvědčila dnes velmi populární architektura Transformers. V Seznamu jsme v tomto roce spustili hledání pomocí významových vektorů počítaných právě pomocí této architektury, přesněji pomocí odvozeného modelu ELECTRA. Dokonce o tom vyšel článek od mého kolegy Jardy Gratze přímo zde na Root.cz, ve kterém se kromě použití významových vektorů ve Vyhledávání můžete dočíst o řadě detailů učení a nasazení ELECTRA, které v mém článku neuvádím. Protože jsme již měli zkušenost s produkčním nasazením ELECTRA a protože je možné ji použít i k opravám chyb v textu, rozhodli jsme se ji vyzkoušet právě k opravě dotazů ve vyhledávání.
ELECTRA je jednou z úspěšných variant modelu BERT s efektivnějším způsobem učení. V textu budeme psát zejména o ELECTRA, i když většina informací je platná i pro původní model BERT. ELECTRA má bohatou vnitřní strukturu s klíčovou komponentou „Multi-head self attention” v každé vrstvě a desítky až stovky milionů parametrů k trénování podle zvolené varianty, zejména počtu vrstev. Díky tomu má dostatečně velkou kapacitu například na zachycení hlubších jazykových vlastností textu, které dokáže při zpracování textu využít.
Učení modelu ELECTRA probíhá ve dvou fázích. První je předučení nad velkým jazykovým korpusem, kdy se model učí jazyk samotný pomocí doplňování slov do věty. Tato fáze trvá obvykle hodně dlouho, a to týdny až měsíce na jedné nebo více grafických kartách. Jakmile je ale takový jazykový model předučený, je možné ho snadno doučit pro řešení konkrétních problémů, například textovou relevanci nebo opravu dotazů.
Vstupem modelu je sekvence „subword tokenů”, což jsou krátké řetězce pokrývající maximálně jedno slovo. Například text „rammstein koncert” může být rozdělen na tokeny ‚ram‘, ‚##ms‘, ‚##te‘, ‚##in‘, ‚koncert‘ (symbol ## značí subword tokeny uprostřed slova). Všimněte si, že slovo „koncert” má svůj vlastní subword, zatímco „rammstein” je rozdělené na čtyři. Je to způsobené tím, jak se slovník tokenů vytváří. Slovník se učí na jazykovém korpusu, na základě kterého vybere takové subwordy, které jsou (zjednodušeně řečeno) v korpusu nejvíce zastoupené (používá se algoritmus WordPiece). A protože slovo „koncert” je velmi časté české slovo, je ve slovníku zastoupené celé, zatímco „rammstein”, byť jde o populární kapelu, se v českém textu objevuje spíše zřídka (a rovněž jeho prefix „ramm” bude v češtině velmi vzácný). Námi používaný tokenizer naučený na českém jazyce má 30 522 tokenů.
Model doučený na konkrétní úlohu vrací buď jeden výstup pro celou sekvenci tokenů, nebo zvlášť výstup pro každý token, jako v našem přístupu k opravám dotazů.
Příprava dotazů pro učení
Jak už jsem opatrně nastínil, jedním z možných použití ELECTRA je oprava chyb v textu (respektive v dotazech). Tohoto lze docílit výběrem (klasifikací) vhodných transformací jednotlivých vstupních tokenů. Jejich aplikací na tokeny a následným spojením tokenů získáme opravený dotaz. Takto jsme ve stručnosti přistupovali k našemu řešení, které je inspirované článkem GECToR – Grammatical Error Correction: Tag, Not Rewrite.

Ukázka opravy dotazu. Dotaz nejdříve rozdělíme na tokeny, jejichž identifikátory jsou vstupem modelu. Pro každý z tokenů vybereme a následně aplikujeme transformaci. Transformované tokeny spojíme a získáme opravený dotaz.
Pro naučení modelu potřebujeme učící data ve tvaru „Vstupní tokeny” + „Transformace”. Surová učící data máme ve tvaru „Původní dotaz” + „Opravený dotaz”. „Vstupní tokeny” lze z původního dotazu získat pomocí tokenizéru, který máme k dispozici. Ve zbytku této kapitoly popíšu, jak jsme pro tyto tokeny vybírali transformace opravující dotaz. Následující popis je techničtějšího rázu. Čtenáři, které tyto detaily nezajímají, mohou přeskočit k další kapitole.
Pro ilustraci zde detailněji rozeberu příklad opravy z obrázku. Mějme dotaz „ramstein konzert” a jeho tokenizaci [ram, ##ste, ##in, konzer, ##t]. Chtěli bychom opravit první a čtvrtý token na [ramm, ##ste, ##in, koncer, ##t], čemuž odpovídají například transformace [APPEND(m), KEEP, KEEP, REPLACE_CHAR(z, c), KEEP]. Jak ale tyto transformace vybrat? Pokud máme k dispozici zdrojový i cílový token (např. ‚ram‘ → ‚ramm‘), je výběr transformace přímočarý. My ale máme k dispozici opravený dotaz vcelku, proto jej nejdříve rozdělíme s ohledem na podobnost s tokeny z původního dotazu (WordPiece tokenizér k tomuto účelu vhodný není).
Rozumným přístupem může být snaha o maximalizaci počtu transformací KEEP, čehož dosáhneme zahledáním tokenů z původního dotazu v jeho opravené variantě a jeho rozdělením podle těchto tokenů. U tohoto rozdělení navíc vyžadujeme nalezení maximálně jednoho výskytu každého vstupního tokenu a zachování jejich pořadí, k čemuž lze použít vhodnou kombinaci algoritmu Aho-Corasickové a LCS. Získáme výsledek [ram, ##m, ##ste, ##in, koncer, ##t]. Tučně zvýrazněné jsou nalezené tokeny odpovídající transformaci KEEP. Zbývá vyřešit nezarovnané tokeny. Token ‚##m‘ můžeme připojit k jednomu ze sousedních tokenů (třeba vlevo) a ‚koncer‘ přiřadit vstupnímu tokenu ‚konzer‘, čímž získáme již zmíněné rozdělení [ramm, ##ste, ##in, koncer, ##t]. Případné vstupní tokeny bez přiřazeného výstupního můžeme smazat transformací DELETE.
V uvedeném postupu pracujeme s velmi širokým prostorem transformací tokenů, kdy většina vygenerovaných transformací je v učících datech pouze jednou. Aby měl model šanci se naučit správné použití jednotlivých transformací, zredukovali jsme jejich počet na 5000. Po prvním průchodu daty jsme vybrali 5000 nejčastějších transformací a v druhém průchodu volili pouze z nich. Experimentováním s prostorem transformací se nám podařilo dosáhnout s 5000 transformacemi pokrytí 96 % dat.
| transformace tokenu | význam |
|---|---|
| KEEP() | zachovej token |
| PREPEND_SPACE() | přidej mezeru před token |
| DELETE() | smaž token |
| DELETE_SPACE() | smaž předcházející mezeru |
| REPLACE_LAST_CHAR(‘y’) | nahraď poslední znak za ‘y’ |
| REPLACE_CHAR(‘k’, ‘c’) | nahraď výskyty ‘k’ za ‘c’ |
Výběr z nejčetnějších transformací v našem datasetu. Celkem model vybírá z 5000 nejběžnějších transformací.
Učíme model
Pro předučení ELECTRA jsme využili kód zveřejněný s původním článkem. Model jsme předučili s využitím korpusu českých webových stránek a zveřejnili. Pokřtili jsme ho jako Small-E-Czech [smolíček]. Pro doučení jsme využili třídu ElectraForTokenClassification z knihovny „Transformers” (Huggingface Transformers), do které lze předučený model nahrát.
Učící data jsme sestavili z těchto zdrojů:
-
sada ručně opravených dotazů (stovky tisíc příkladů)
-
logované kliknuté opravy z dosavadního řešení (desítky milionů příkladů)
-
slovníky jmenných entit (Zboží.cz, Firmy.cz, Wiki) s uměle zanesenými překlepy
Z těchto dat jsme naučili řadu variant modelů lišících se různými meta parametry (nejdůležitější z nich byl způsob smíchání učících dat) a zjistili, že nejlepší z nich zaostává za jednodušším provozním řešením. Domníváme se, že signály používané pro řazení oprav v původním řešení obsahují mnoho informací, které čistě z textu nelze získat.
Naštěstí jsme od začátku měli plán B, kterým bylo obohacení původního řešení o dotazy vytvořené ELECTRA modelem (nový suggester). ELECTRA nám doposud pro každý dotaz nabízí právě jednu opravu. Protože ale pro každý z tokenů máme k dispozici skóre všech možných transformací, lze z tohoto výstupu vybrat N nejlepších návrhů oprav. Konkrétně se ukázalo, že pomocí ELECTRA suggesteru vracejícího dvacet návrhů lze nahradit všechny dosavadní pomalé suggestery, a získat tak rychlejší řešení, které navíc opravuje o trochu lépe.
Zlepšení kvality a zrychlení
Vyhledávač Seznam.cz opravuje dotazy pomocí jednoduchých heuristik a tradičních metod strojového učení. Řadu těchto naivních (a pomalých) heuristik se podařilo nahradit moderní neuronovou sítí ELECTRA, získat kvalitnější návrhy a celý systém tak o desítky procent zrychlit při zlepšení kvality (přesnost a pokrytí) o jednotky procent.

Klíčem k úspěchu byla dostupnost kvalitních dat k učení, jejich komplexní předzpracování a rovněž pokrok v architekturách hlubokých neuronových sítí pro zpracování textu.
(Autorem obrázků je společnost Seznam.cz)



































