
Obsah
2. Programování na úrovni strojového kódu
3. První generace assemblerů a jejich další vývoj
4. Vyplnění sémantické mezery mezi mikroprocesorem a vyššími programovacími jazyky
5. Platforma IBM System/360 a vznik architektury CISC
6. Assemblery pro osmibitové domácí mikropočítače i pro osobní počítače
7. Assemblery pro systém DOS: Turbo Assembler, Microsoft Macro Assembler, a86 a a386
12. Vybrané aplikace naprogramované (kompletně) v assembleru
16. SpeedScript (klasická verze)
17. Textový editor e (pro DOS)
18. Textový editor e3 (pro Linux)
19. Legendární textový editor WordStar
1. Sedmdesátiny assemblerů
„Assembler is human-readable machine code.“
Po dvojici článků o třicátých narozeninách Turbo Pascalu 5.5 a šedesátém výročí vzniku programovacího jazyka COBOL se dnes ponoříme ještě o celou jednu dekádu zpět do minulosti, konkrétně do přelomu čtyřicátých a padesátých let minulého století. Letos totiž uplynulo celých sedmdesát let od vzniku nástroje, který dnes nazýváme assembler. Současně se jedná o pojmenování skupiny nízkoúrovňových programovacích jazyků, které leží na hranici mezi strojovým kódem na jedné straně a vyššími programovacími jazyky na straně druhé (tyto jazyky se též nazývají jazyky symbolických adres nebo jazyky symbolických instrukcí). A vzhledem k tomu, že jsou assemblery velmi těsně spjaty s určitým typem mikroprocesorů a navíc i používaným operačním systémem, nedošlo nikdy (a s velkou pravděpodobností ani nikdy nedojde) k unifikaci těchto nástrojů, popř. ke vzniku dodržovaných standardů.

Obrázek 1: Sálový počítač IBM-702, který byl určený pro hromadné zpracování dat. Tento počítač začal být vyráběn již v roce 1953. Programy pro IBM-702 se zpočátku psaly klasicky na papír a posléze se ručně překládaly bez použití programových prostředků.

Obrázek 2: Sálový počítač IBM-704 určený pro vědeckotechnické výpočty. Tento počítač byl vyráběn od roku 1954. Pro tento počítač vznikly dva důležité vysokoúrovňové jazyky – Fortran a LISP. Ovšem v kontextu dnešního článku je důležitější SAP assembler neboli Symbolic Assembly Program.
Ukázka části programu napsaného v assembleru 16bitových mikroprocesorů kompatibilních s Intel 8086 a operační systém DOS (s grafickou kartou VGA):
;-----------------------------------------------------------------------------
org 0x100
section .text
Start:
;------ Graficky rezim 320x200x256 -------
mov ax, 0x13
int 0x10
;------ Inicializace palety -------
xor ax, ax
mov di, paleta
mov cx, 256
push di ; adresa pocatku palety
push cx ; pocet barev
SetPaletteLoop:
stosb ; red component
stosb ; green component
stosb ; blue component
inc ax
loop SetPaletteLoop
;------ Nastaveni palety -------
mov ax, 0x1012
pop cx ; pocet barev
pop dx ; adresa pocatku palety
xor bx, bx
int 0x10
mov bx, 6 ; offset pri pristupu do pole
;------ Nastaveni castic -------
mov cx, ParticleCount
mov si, particles
2. Programování na úrovni strojového kódu
V některých oblastech, zejména před rozšířením vyšších programovacích jazyků se programy do počítače zadávaly přímo ve strojovém kódu. Týkalo se to například mainframů vybavených řídicím panelem, do kterého bylo nutné „naťukat“ minimálně krátkou rutinu nazývanou boot loader, která sloužila pro načtení zbytku operačního systému (či přímo spouštené aplikace) z nějaké formy externí paměti, například z páskové jednotky, z děrného pásku atd. Dodnes kolují historky o operátorech, kteří byli schopni příslušné boot loadery zadat zcela zpaměti.

Obrázek 3: Hlavní moduly počítače MESM včetně jeho řídicího (operátorského) panelu.
Samotný boot loader byl vytvořen ve strojovém kódu, ovšem pochopitelně ho bylo možné (ručně) napsat v assembleru a (taktéž ručně) přeložit instrukci po instrukci do strojového kódu, což je u programu o délce maximálně několika stovek bajtů sice pracné, ale stále ještě proveditelné. Později ovšem jak nutnost ručního zadávání boot loaderů a nutnosti ručního překladu do strojového kódu zcela pominula a již na začátku šedesátých let minulého století se většinou jednalo o polozapomenuté umění.

Obrázek 4: Někteří programátoři dokázali i v primitivním monitoru (program umožňující modifikaci paměti) naprogramovat rozsáhlé aplikace, a to včetně her. V takovém případě se pro ruční převod assembleru do strojového kódu používaly takovéto tabulky (i když osobně znám člověka, který si dokázal zapamatovat kódy všech strojových instrukcí i jejich variant).
Původně bylo programování ve strojovém kódu vynuceno omezenými technickými prostředky, ovšem v určitých situacích se ruční překlad programu napsaného (na papíře) v assembleru do strojového kódu prováděl i na výkonnějších mikropočítačích, u nichž byly k dispozici lepší programové prostředky (jak assembler, tak i vyšší programovací jazyky). Strojové podprogramy (subrutiny) totiž bylo možné volat i z vyšších programovacích jazyků, typicky z BASICu. V tomto případě ovšem bylo nutné strojový program reprezentovat daty (hodnotami jednotlivých bajtů) a právě zde se mnohdy programátoři nevyhnuli ručnímu překladu, což je ukázáno na následujícím obrázku.

Obrázek 5: Ruční překlad programu napsaného v assembleru (levá horní část tohoto skenu) na jednotlivé bajty, které jsou zapsány ve formě dat v BASICovém programu (pravá dolní část skenu).
Program typu „Hello world!“ pro MS DOS určený pro Turbo Assembler:
ideal
model tiny ;pametovy model CS=DS=SS mensi nez 64kB
p286 ;povoleny instrukce procesoru 286+
;-----------------------------------------------------------------------------
dataseg ;zacatek data-segmentu
message db "Hello world!$"
;-----------------------------------------------------------------------------
codeseg ;zacatek code-segmentu
org 0100h ;zacatek kodu pro programy typu COM
start:
;------ Tisk retezce na obrazovku
mov dx, offset message
mov ah, 9
int 21h
;------ Vyprazdnit buffer klavesnice a cekat na klavesu
xor ax, ax
int 16h
;------ Ukonceni procesu
retn
end start
3. První generace assemblerů a jejich další vývoj
Vývoj assemblerů je poměrně úzce spjatý s prvními počítači (tehdy většinou mainframy), které používaly pro uložení programů nějakou formu zapisovatelné či dokonce přepisovatelné paměti. Dobrým příkladem může být počítač EDSAC neboli Electronic Delay Storage Automatic Calculator. Pro tento počítač byl v roce 1949, tedy před sedmdesáti lety, vytvořen velmi jednoduchý assembler, v němž byly mnemotechnické zkratky instrukcí zkráceny na jediný znak. Tento koncept byl později rozšířen, takže se v pozdějších assemblerech setkáme s mnemotechnickými zkratkami instrukcí se dvěma, třemi, čtyřmi či proměnným počtem znaků. Ovšem poměrně často se i u pozdějších assemblerů setkáme s třípísmennými zkratkami; například u assemblerů pro mikroprocesory Intel 8080, Intel 8086, MOS 6502 atd.

Obrázek 6: Telefonní volič pocházející zhruba z doby vzniku hry OXO.
Ovšem vraťme se zpátky k prvním nástrojům, které dnes nazýváme assemblery. V roce 1955 vznikl pro počítače řady IBM 650 systém SOAP neboli celým jménem Symbolic Optimal Assembly Program (ať již slovo „optimal“ mělo znamenat cokoli). Autorem tohoto systému, kde se již objevuje slovo assembler, byl Stan Poley. Právě v této době, tj. zhruba v polovině padesátých let minulého století, se assemblery rozšířily i na prakticky všechny ostatní typy mainframů vyráběných osmi nejvýznamnějšími společnostmi v této oblasti (kterým se přezdívalo „IBM a sedm trpaslíků“). Mezi tyto společnosti patřily firmy Borroughs, UNIVAC, NCR, Control Data Corporation (CDC), Honeywell, RCA a General Electric (GE).

Obrázek 7: Bubnová paměť je předchůdcem dnešních pevných disků. Na rozdíl od nich se pro každou stopu využívala samostatná sada čtecích a zápisových hlav, což zjednodušilo konstrukci paměti (nemusel se implementovat mechanismus pro vystavení hlav) a umožnilo paralelní zápis/čtení ze všech stop současně. Kvůli poměrně malému množství stop však byla kapacita bubnové paměti malá.
Původní assemblery prováděly pouze základní činnost – překlad mnemotechnických kódů instrukcí do strojového kódu. Takový překlad bylo možné provést v jednom průchodu, což mj. znamenalo, že zdrojový kód mohl být uložen na děrných štítcích nebo děrných páskách a výsledek opět mohl být zaznamenán na stejná datová média. Spotřeba paměti pro překlad (v angličtině se používá assembly neboli sestavení) byla v tomto případě minimální a nebyla ani závislá na objemu zdrojového kódu. Ovšem současně byly tyto assemblery dosti omezené, například neumožňovaly použití návěstí (label) u cílů skoků. Tento nedostatek byl odstraněn u další generace assemblerů podporujících takzvané symbolické adresy. Proto se někdy assemblery nazývaly jazyk symbolických adres – JSA.
Těmto programům, jejichž možnosti se postupně vylepšovaly (například do nich přibyla podpora textových maker, řízení víceprůchodového překladu, vytváření výstupních sestav s překládanými symboly, později i skutečné linkování s knihovnami atd.), se začalo obecně říkat assemblery a jazyku pro symbolický zápis programů pak jazyk symbolických instrukcí či jazyk symbolických adres – assembly language (někdy též zkráceně nazývaný assembler, takže toto slovo má vlastně dodnes oba dva významy). Jednalo se o svým způsobem převratnou myšlenku: sám počítač byl použit pro tvorbu programů, čímž odpadla namáhavá práce s tužkou a papírem.
Dalším důležitým mílníkem byl assembler pro IBM 709, který se nazýval FAP neboli FORTRAN Assembly Program. Jednalo se o vylepšenou verzi projektu SCAT (SHARE Compiler-Assembler-Translator). Později byl FAP rozšířen o možnosti zápisu maker, což bylo velké vylepšení.
Posléze se pochopitelně zjistilo, že i programování přímo v assembleru je většinou zbytečně pracné a zdlouhavé, takže se na mainframech začaly používat různé vyšší programovací jazyky, zejména FORTRAN a COBOL. Použití vyšších programovacích jazyků bylo umožněno relativně vysokým výpočetním výkonem mainframů i (opět relativně) velkou kapacitou operační paměti; naopak se díky vyšším programovacím jazykům mohly aplikace přenášet na různé typy počítačů, což je nesporná výhoda.

Obrázek 8: Feritová paměť, která nahradila složitou a drahou paměť vytvořenou pomocí katodových (Williamsových) trubic. Předností feritové paměti je poměrně dlouhá doba udržení zapsané informace, takže obsah paměti většinou úspěšně přestál i pád systému – nebylo zapotřebí implementovat core-dump :-)
Zapomenout nesmíme ani na počítač GE-635 a makroassembler GEMAP, protože právě s využitím tohoto prostředku vznikla první verze UNIXu. Vývoj tohoto operačního systému začal na PDP-7, ovšem hardwarové možnosti tohoto počítače byly velmi omezené, například kapacita operační paměti dosahovala pouze 8192 osmnáctibitových slov, tj. osmnácti kilobajtů. Z tohoto důvodu byl originální UNIX (který ovšem toto jméno ještě neměl) naprogramován v assembleru počítače PDP-7, přičemž je zajímavé, že vlastní vývoj byl prováděn na jiném (výkonnějším a taktéž mnohem dražším) počítači: již zmíněném 36bitovém GE-635 s využitím makroassembleru GEMAP. Po vytvoření objektového kódu tímto assemblerem se (stále ještě na počítači GE-635) zapsalo přeložené jádro i další pomocné programy na děrnou pásku, která se následně vložila do čtecího zařízení na počítači PDP-7, odkud se systém „nabootoval“ patřičným příkazem zadaným z řídicího panelu.
4. Vyplnění sémantické mezery mezi mikroprocesorem a vyššími programovacími jazyky
V roce 1962 se firma IBM rozhodla navrhnout do značné míry univerzální architekturu počítačů, která by pokrývala jak nároky jednodušších úloh (pro které stačily méně výkonné a tím pádem i levnější počítače), tak i nároky mnohem větší. Předností této architektury mělo být to, že systém „rostl“ současně s rostoucími požadavky zákazníka bez nutnosti měnit programové vybavení. Výsledkem těchto snah firmy IBM byla platforma nazvaná System/360, resp. zkráceně S/360. Pro tuto platformu byla vytvořena poměrně rozsáhlá a složitá instrukční sada (ISA), která mimo běžné binární aritmetiky obsahovala i instrukce pro práci s textem, různé numerické formáty dat známé například z kalkulaček, ale i podporu BCD aritmetiky, která se dodnes používá například při výpočtech s měnou. V té době totiž vládlo přesvědčení, že bohatší instrukční sada ulehčí práci překladačům z vyšších programovacích jazyků, vyplní takzvanou sémantickou mezeru mezi assemblerem a vyššími programovacími jazyky atd.

Obrázek 9: Jeden z prvních modelů počítače série System/360.
5. Platforma IBM System/360 a vznik architektury CISC
Procesorové jednotky počítačů System/360 zpracovávaly poměrně složité instrukce, protože se jednalo o klasickou architekturu CISC (v té době se věřilo, že komplexní instrukční sada pomůže programátorům překonat již zmíněnou „sémantickou propast“ mezi strojovým kódem, popř. assemblerem a vyššími programovacími jazyky). Aby i jednodušší modely série System/360 mohly zpracovávat všechny instrukce, používaly jejich procesory mikrokód, pomocí něhož se složitější instrukce rozdělily na sérii jednodušších mikroinstrukcí (ty měly zcela jiný formát, protože se jimi přímo ovládaly jednotlivé bloky v procesoru – ALU, registry, interní sběrnice atd.). Jednalo se o 32bitovou architekturu se šestnácti 32bitovými registry označovanými jmény R0 až R15 a čtyřmi 64bitovými registry určenými pro práci s hodnotami uloženými ve formátu pohyblivé řádové čárky. Kromě pracovních registrů procesor obsahoval i PSW (processor status word), v němž byl uložen i čítač instrukcí PC, příznak práce v superuživatelském režimu atd.

Obrázek 10: Úvodní stránka manuálu k assembleru počítačů System/360.
Program typu „Hello world!“ mohl být v assembleru počítačů IBM System/360 zapsán takto (zdroj: https://try-mts.com/system-360-assembly-language-introduction/):
HELLO START 0 PROGRAM AT RELATIVE ADDRESS 0
USING HELLO,12 R12 WILL CONTAIN PROGRAM ADDR
LR 12,15 LOAD R12 WITH ABSOLUTE ADDR
L 3,RUNS R3 COUNTS DOWN NUMBER OF RUNS
LOOP SPRINT 'Hello, world!' PRINT THE MESSAGE
S 3,DECR DECREMENT R3
BP LOOP IF R3 POSITIVE, LOOP AGAIN
SYSTEM EXIT PROGRAM
RUNS DC F'5' NUMBER OF RUNS TO MAKE
DECR DC F'1' DECREMENT FOR LOOP
END HELLO END OF CODE
6. Assemblery pro osmibitové domácí mikropočítače
Oživení zájmu o programování v assembleru přinesl vznik minipočítačů (například známé řady PDP) a na konci sedmdesátých let minulého století pak zcela nového fenoménu, který nakonec přepsal celé dějiny výpočetní techniky – domácích osmibitových mikropočítačů.
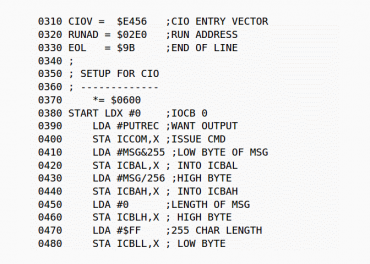
Obrázek 11: Takto vypadá úryvek programu napsaný v assembleru mikroprocesoru MOS 6502.
Mikropočítače bývaly vybaveny pamětí ROM s interpretrem BASICu, ovšem pro profesionální vývoj byly k dispozici i assemblery, linkery, monitory a debuggery. Prvním typem byly assemblery interaktivní, které uživateli nabízely poměrně komfortní vývojové prostředí, v němž bylo možné zapisovat jednotlivé instrukce, spouštět programy, krokovat je, vypisovat obsahy registrů atd. Výhodou byla nezávislost těchto assemblerů na rychlém externím paměťovém médiu.
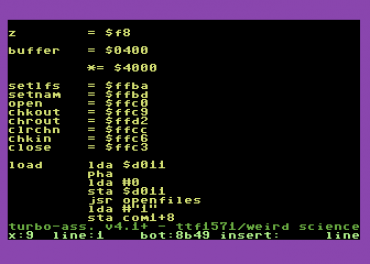
Obrázek 12: Assembler na domácím osmibitovém mikropočítači Commodore C64.
Druhý typ assemblerů je používán dodnes – jedná se vlastně o běžné překladače, kterým se na vstupu předloží zdrojový kód (uložený na kazetě či disketě) a po překladu se výsledný nativní kód taktéž uloží na paměťové médium (odkud ho lze spustit). Tyto assemblery byly mnohdy vybaveny více či méně dokonalým systémem maker (odtud název macroassembler).

Obrázek 13: Obal na kazetu se Zeus Assemblerem určeným pro slavné ZX Spectrum.
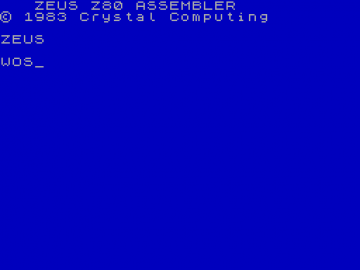
Obrázek 14: Vývojové prostředí Zeus Assembleru.
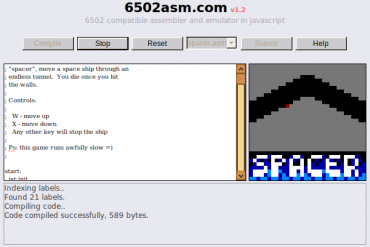
Obrázek 15: Jak se programovalo v assembleru si můžete vyzkoušet na stránce http://6502asm.com. Zde je implementován assembler i emulátor počítače založeného na osmibitovém mikroprocesoru MOS 6502.
Obrázek 16: Úvodní obrazovka Atari Macro Assembleru.
Obrázek 17: Vývojové prostředí Atari Macro Assembleru.

Obrázek 18: Vývojové prostředí Atari Macro Assembleru (výpis obsahu pracovních registrů mikroprocesoru).

Obrázek 19: Celoobrazovkové uživatelské rozhraní monitoru pro mikropočítače Apple II.
Assemblery byly mezi programátory poměrně populární i na mnohem výkonnějších osobních mikropočítačích Amiga a Atari ST, a to i díky tomu, že instrukční kód mikroprocesorů Motorola 68000 byl do značné míry ortogonální, obsahoval relativně velké množství registrů (univerzální datové registry D0 až D7 a adresové registry A0 až A7) a navíc bylo možné používat i takové adresovací režimy, které korespondovaly s konstrukcemi používanými ve vyšších programovacích jazycích (přístupy k prvkům polí, přístup k lokálním proměnným umístěných v zásobníkovém rámci, autoinkrementace adresy atd.). Podívejme se na jednoduchý příklad rutiny (originál najdete zde), která sečte všechny prvky (16bitové integery – načítá se vždy jen 16bitové slovo) v poli. V tomto příkladu se používá autoinkrementace adresy při adresování prvků polí a taktéž instrukce DBRA provádí dvě činnosti – snížení hodnoty registru o jedničku a skok v případě, že je výsledek nenulový:
moveq #0, d0 ; potřebujeme vynulovat horních 16 bitů d0
moveq #0, d1 ; mezivýsledek
loop:
move.w (a0)+, d0 ; horních 16 bitů d0 je pořád nastaveno na 0
add.l d0, d1
dbra d2, loop ; d2 je použit jako počitadlo
Pokud by nebyly k dispozici adresovací režimy s autoinkrementací a instrukce pro snížení operandu a podmíněný skok, musel by být celý program delší a současně ještě více nízkoúrovňový.
7. Assemblery pro systém DOS: Turbo Assembler, Microsoft Macro Assembler, a86 a a386
Nyní se ve stručnosti seznámíme s nejznámějšími assemblery určenými pro operační systém DOS. V první řadě se jednalo o Turbo Assembler (TASM) vydaný společností Borland, s níž jsme se již seznámili v souvislosti s Turbo Pascalem. Turbo Assembler podporoval dva způsoby zápisu programů (vzájemně nekompatibilních) a byl poměrně široce rozšířen, mj. i díky snadné instalaci (postačovalo mít nainstalován samotný assembler tasm.exe a linker tlink.exe). První verze Turbo Assembleru podporovaly pouze reálný režim mikroprocesorů Intel 8086, další verze pak i chráněný režim.
Konkurentem Turbo Assembleru byl Microsoft Macro Assembler známý mj. i pod zkratkou MASM. I tento assembler, který vznikl již v roce 1981, byl původně určen pouze pro šestnáctibitový reálný režim mikroprocesorů, později však došlo k jeho rozšíření pro chráněný režim (286 i 386). Dnes dokonce existuje ML64 určený pro 64bitové architektury x86–64. Jméno tohoto assembleru naznačuje, že jsou podporována makra, ta však byla k dispozici i uživatelům konkurenčního TASMu.
Zajímavou koncepci nalezneme u dvojice aplikací a86 a a386. Jedná se o pravděpodobně nejrychlejší assemblery pro DOS, které navíc dokážou případná chybová hlášení assembleru přímo vložit do zdrojových kódů a patřičně je označit. Při dalším průchodu se tato hlášení automaticky smažou. Jedná se o poměrně elegantní způsob řešení, zejména při překladu dlouhých programů (musíme si totiž uvědomit, že systém DOS neměl dobře vyřešenou podporu scrollingu v terminálu, takže zápis chyb přímo do zdrojového kódu umožnil, aby si programátor chyby dohledal s využitím možností samotného textového editoru).
Část zdrojového kódu dále zmíněného textového editoru e určeného pro sestavení Turbo Assemblerem:
Start: mov ax, cs mov [ProgramSegment], ax ;Store current segment for EXEC function add ax, ((PROGLENGTH + ENDFBUFFER) SHR 4) + 1 mov [heapStart], ax ;Compute start of free memory in paragraphs mov [heapPtr], ax mov sp, OFFSET STACKTOP mov si, 80h ;Make pointer to command tail mov cl, [si] ;Get filename length sub ch, ch mov [fName?], cl ;Save a copy mov al, ' ' ;Skip leading blanks @@L1: inc si cmp al, [si] loope @@L1 inc cx mov di, OFFSET fName ;Move command tail to FName rep movsb sub al, al ;Make ASCIIZ string stosb mov ax, 2523h ;Redirect Ctrl C handler mov dx, OFFSET Cancel int 21h mov [byte OtherFName], 0 ;Prevent Alt Shift O crash without prev. file mov ah, 0Fh ;Set defaults for color or mono adapter int 10h
8. Vývojové prostředí ASM lab
Dále se musíme zmínit o aplikaci pojmenované ASM Lab. Jak již název tohoto IDE napovídá, jednalo se o nástroj určený pro programátory, kteří pracovali s assemblerem mikroprocesorů řady Intel x86. Úkolem Asm Labu bylo zpříjemnit tvorbu programů v assembleru a navíc vývojářům nabídnout různé doplňkové nástroje, například kalkulátor pro převod mezi různými číselnými soustavami, obligátní ASCII tabulku atd. Asm Lab bylo založeno na knihovně TurboVision, takže vlastně není překvapivé, že se jeho vzhled podobal dalším aplikacím s textovým uživatelským rozhraním, včetně již popsaných integrovaných vývojových prostředí společnosti Borland. Editor, který používal mnoho zkratek kompatibilních s produkty Borlandu, byl propojen s dalšími moduly ASM Labu, takže uživatelé mohli například jednoduše přecházet mezi různými procedurami atd. Na klávesové zkratky byl napojen taktéž vlastní assembler (zde je míněn nástroj určený pro překlad do strojového kódu, nikoli jazyk).
Obrázek 20: Úvodní obrazovka integrovaného vývojového prostředí ASM Lab.
Velmi důležitou součástí ASM Labu byla nápověda, která obsahovala mj. i podrobný popis všech instrukcí mikroprocesorů řady Intel x86. U každé instrukce byla popsána její funkce, dostupné adresovací režimy, počet bajtů nutných pro uložení instrukce (a samozřejmě i operandů) do operační paměti a taktéž počet cyklů nutných pro provedení instrukce u různých variant mikroprocesorů.
Obrázek 21: Programátorský editor integrovaný do ASM Labu.
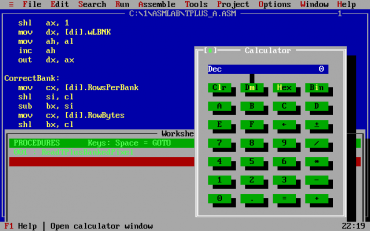
Obrázek 22: Přímo z ASM Labu je možné spustit i programátorskou kalkulačku.
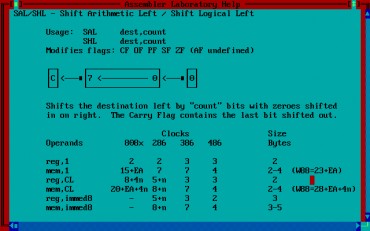
Obrázek 23: Podrobná nápověda k instrukci SAL (SHL).
9. Assemblery v Linuxu
V této kapitole budeme pod termínem „assembler“ chápat programový nástroj určený pro transformaci zdrojového kódu naprogramovaného v jazyku symbolických adres do strojového kódu (což je původní význam tohoto slova). Pro Linux vzniklo hned několik takových nástrojů, přičemž některé nástroje jsou komerční a jiné patří mezi open source. Z nekomerčních nástrojů, které nás samozřejmě na serveru https://www.root.cz zajímají především, se jedná o známý GNU Assembler, dále pak o nástroj nazvaný Netwide assembler (NASM), nástroj Yasm Modular Assembler či až překvapivě výkonný vasm. NASM a Yasm jsou pro první krůčky v assembleru velmi dobře použitelné, neboť mají dobře zpracovaný mechanismus reakce na chyby, dají se v nich psát čitelné programy atd. Určitý problém nastává v případě, kdy je nutné vyvíjet aplikace určené pro jinou architekturu, než je 32bitová architektura i386 či dnes již převažující architektura x86_64, a to z toho důvodu, že ani Netwide assembler ani Yasm nedokážou pracovat s odlišnou instrukční sadou. Naproti tomu GNU Assembler tímto problémem ani zdaleka netrpí, takže se v následujících kapitolách budeme zabývat jak nástrojem NASM, tak i GNU Assemblerem.
Bližší informace o jednotlivých assemblerech pro Linux zmíněných v předchozím odstavci lze najít na jejich domovských stránkách, popř. v porovnávací tabulce:
- yasm
https://yasm.tortall.net/ - vasm
http://sun.hasenbraten.de/vasm/ - FASM
https://en.wikipedia.org/wiki/FASM - NASM
https://www.nasm.us/ - GNU Binutils (včetně GNU assembleru)
https://www.gnu.org/software/binutils/ - Open Watcom Assembler
http://www.openwatcom.com/ - Porovnání assemblerů pro platformu x86–64
https://en.wikipedia.org/wiki/Comparison_of_assemblers#x86–64_assemblers
10. GNU Assembler
GNU Assembler (gas) je součástí skupiny nástrojů nazvaných GNU Binutils. Jedná se o nástroje určené pro vytváření a správu binárních souborů obsahujících takzvaný „objektový kód“, dále nástrojů určených pro práci s knihovnami strojových funkcí i pro profilování. Mezi GNU Binutils patří vedle GNU Assembleru i linker ld, profiler gprof, správce archivů strojových funkcí ar, nástroj pro odstranění symbolů z objektových a spustitelných souborů strip a několik pomocných utilit typu nm, objdump, size a strings. GNU Assembler je možné použít buď pro překlad uživatelem vytvořených zdrojových kódů nebo pro zpracování kódů vygenerovaných překladači vyšších programovacích jazyků (GCC atd.). Zajímavé je, že všechny moderní verze GNU Assembleru podporují jak původní AT&T syntaxi, tak i (podle mě mnohem čitelnější) syntaxi používanou společností Intel.
Podívejme se nyní na to, jak může vypadat kostra velmi jednoduché aplikace naprogramované v GNU Assembleru pro procesory řady i386 či x86_64. Celý zdrojový kód je rozdělen na řádky, přičemž na jednotlivých řádcích mohou být komentáře, deklarace různých konstant a symbolů (sys_exit=1), speciální direktivy (.section), návěští/labels (_start) a samozřejmě i samotný kód reprezentovaný mnemotechnickými názvy instrukcí a jejich operandů. Důležitý je symbol _start, protože ten je používán i linkerem a specifikuje vstupní bod do programu:
# Linux kernel system call table
sys_exit=1
#-----------------------------------------------------------------------------
.section .data
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
movl $sys_exit,%eax # cislo sycallu pro funkci "exit"
movl $0,%ebx # exit code = 0
int $0x80 # volani Linuxoveho kernelu
Povšimněte si rozdělení do sekcí – sekce pojmenované .data a .bss jsou prázdné, samotný kód je umístěn do sekce pojmenované .text, což může být matoucí, protože ve výsledném binárním souboru tato sekce taktéž obsahuje binární data (instrukce). Instrukce jsou v programu pouze tři a slouží pro naplnění pracovních registrů eax a ebx (funkce číslo 1, návratová hodnota 0) a zavolání syscallu. Používáme zde původní AT&T syntaxi GNU Assembleru, proto se do instrukce movl operandy zapisují v pořadí zdroj,cíl.
Překlad (assemblerem) a následné slinkování do spustitelného souboru se provede následovně:
as template.s -o template.o ld -s template.o
Další příklad kostry aplikace napsané v GNU Assembleru, tentokrát určené pro Linux a pro mikroprocesory s 32bitovou architekturou ARM (nikoli AArch64):
# Linux kernel system call table
sys_exit=1
#-----------------------------------------------------------------------------
.section .data
#-----------------------------------------------------------------------------
.section .bss
#-----------------------------------------------------------------------------
.section .text
.global _start @ tento symbol ma byt dostupny i z linkeru
_start:
mov r7,$sys_exit @ cislo sycallu pro funkci "exit"
mov r0,#0 @ exit code = 0
svc 0 @ volani Linuxoveho kernelu
Překlad a slinkování se provede těmito dvěma příkazy:
as arm_32.s -o arm_32.o ld -s arm_32.o
Výsledkem by měl být binární soubor o délce pouhých 311 bajtů:
0000000: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............ 0000010: 02 00 28 00 01 00 00 00 54 80 00 00 34 00 00 00 ..(.....T...4... 0000020: 98 00 00 00 00 02 00 05 34 00 20 00 01 00 28 00 ........4. ...(. 0000030: 04 00 03 00 01 00 00 00 00 00 00 00 00 80 00 00 ................ 0000040: 00 80 00 00 60 00 00 00 60 00 00 00 05 00 00 00 ....`...`....... 0000050: 00 80 00 00 01 70 a0 e3 00 00 a0 e3 00 00 00 ef .....p.......... 0000060: 41 13 00 00 00 61 65 61 62 69 00 01 09 00 00 00 A....aeabi...... 0000070: 06 01 08 01 00 2e 73 68 73 74 72 74 61 62 00 2e ......shstrtab.. 0000080: 74 65 78 74 00 2e 41 52 4d 2e 61 74 74 72 69 62 text..ARM.attrib 0000090: 75 74 65 73 00 00 00 00 00 00 00 00 00 00 00 00 utes............ 00000a0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 00000b0: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 00000c0: 0b 00 00 00 01 00 00 00 06 00 00 00 54 80 00 00 ............T... 00000d0: 54 00 00 00 0c 00 00 00 00 00 00 00 00 00 00 00 T............... 00000e0: 04 00 00 00 00 00 00 00 11 00 00 00 03 00 00 70 ...............p 00000f0: 00 00 00 00 00 00 00 00 60 00 00 00 14 00 00 00 ........`....... 0000100: 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 ................ 0000110: 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 ................ 0000120: 74 00 00 00 21 00 00 00 00 00 00 00 00 00 00 00 t...!........... 0000130: 01 00 00 00 00 00 00 00 ........
Pokud vás zajímá interní struktura tohoto souboru, opět pomůže nástroj objdump:
objdump -f -d -t -h a.out
a.out: file format elf32-littlearm
architecture: armv4, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00008054
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000000c 00008054 00008054 00000054 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .ARM.attributes 00000014 00000000 00000000 00000060 2**0
CONTENTS, READONLY
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00008054 <.text>:
8054: e3a07001 mov r7, #1
8058: e3a00000 mov r0, #0
805c: ef000000 svc 0x00000000
11. Netwide Assembler (NASM)
Netwide Assembler (NASM) vznikl v době, kdy začali na operační systém Linux přecházet programátoři znající a používající operační systémy DOS a (16/32bit) Windows. Tito programátoři byli většinou dobře seznámeni s možnostmi assemblerů, které se na těchto platformách používaly nejčastěji – Turbo Assembleru (TASM) společnosti Borland i Microsoft Macro Assembleru (MASM) a tak jim možnosti GNU Assembleru (který má své kořeny na odlišných architekturách) příliš nevyhovovaly. Výsledkem snah o vytvoření nástroje podobnému TASMu či MASMu byl právě projekt pojmenovaný NASM, který podporuje stejný způsob zápisu operandů instrukcí a navíc ještě zjednodušuje zápis těch instrukcí, u nichž je jeden operand tvořen nepřímou adresou. NASM byl následován projektem Yasm (fork+přepis), ovšem základní vlastnosti a především pak vazba na platformu i386 a x86_64 zůstaly zachovány (to mj. znamená, že například na Raspberry Pi možnosti těchto dvou nástrojů plně nevyužijeme, což je určitě škoda, protože zrovna tento mikropočítač se poměrně dobře hodí pro výuku assembleru).
Příklad kostry aplikace určené pro překlad Netwide assemblerem, opět naprogramované pro operační systém Linux:
; Linux kernel system call table
sys_exit equ 1
;-----------------------------------------------------------------------------
section .data
;-----------------------------------------------------------------------------
section .bss
;-----------------------------------------------------------------------------
section .text
global _start ; tento symbol ma byt dostupny i linkeru
_start:
mov eax,sys_exit ; cislo sycallu pro funkci "exit"
mov ebx,0 ; exit code = 0
int 80h ; volani Linuxoveho kernelu
Překlad se provede příkazem:
nasm -felf32 template.asm ld -s template.o
popř. pro 64bitový systém příkazem:
nasm -felf64 template.asm ld -s template.o
12. Vybrané aplikace naprogramované (kompletně) v assembleru
Assembler se dnes stále používá, zejména na menších mikrořadičích, včetně čtyřbitových mikrořadičů, s nimiž jsme se již na stránkách Rootu seznámili [Vznik mikrořadičů: čtyřbitový čip TMS 1000] [Vznik mikrořadičů: čtyřbitový MCU Atmel MARC4] [Čtyřbitové mikrořadiče řady Epson S1C60]. Ovšem pochopitelně dnes převážná část kódu vzniká ve vyšších programovacích jazycích. V minulosti tomu tak nebylo, a to z pochopitelných důvodů – relativně nízký výpočetní výkon i malá kapacita operačních pamětí nutily vývojáře k tomu, aby své aplikace optimalizovali, protože jinak by nebyly reálně použitelné. Týkalo se to nejenom počítačových her, kde je důraz na optimalizace velký i dnes, ale i „běžných“ desktopových aplikací – textových editorů, tabulkových editorů, grafických programů atd. V dalších kapitolách se ve stručnosti s některými známějšími aplikacemi naprogramovanými v assembleru seznámíme. Mnohdy se jednalo o přelomové aplikace patřící do kategorie killer app – tedy aplikace, kvůli nimž samotným si mnozí uživatelé pořizovali počítač.

Obrázek 24: Typickým segmentem trhu pro čtyřbitový mikrořadič TMS 1000 (programovaný čistě v assembleru) jsou kapesní kalkulačky, ať již s displeji založenými na LED, LCD či VFD.
13. VisiCalc
Důležitým mezníkem pro využití počítačů v kancelářích se stal tabulkový procesor VisiCalc. Jednalo se o první interaktivní aplikaci typu „tabulkový procesor“ (spreadsheet), která v době svého vzniku bezesporu patřila mezi takzvané „killer app“, tj. mezi programy, jenž samy o sobě některé uživatele přesvědčily k tomu, aby si pořídili osobní mikropočítač (a to se bavíme o začátku osmdesátých let minulého století, kdy byly mikropočítače velmi drahé) [1]. VisiCalc byl portován na mnoho typů mikropočítačů, mj. i na slavné počítače Apple II, na počítače kompatibilní s IBM PC atd. Oproti jiným nástrojům určeným pro zpracování dat měl VisiCalc obrovskou výhodu – byl interaktivní a používal paradigma, kterému mnoho uživatelů velmi dobře rozumělo (data byla uložena v dvourozměrných tabulkách, ovšem bez nutnosti přesné specifikace jejich struktury, navíc bylo umožněno jednotlivé buňky adresovat). Původní verze VisiCalcu byla kompletně naprogramována v assembleru osmibitových mikroprocesorů MOS 6502 a byla tedy dostupná na většině počítačů založených na tomto čipu (Apple II, Atari, …).

Obrázek 25: Tabulkový kalkulátor VisiCalc spuštěný v DOSu.
VisiCalc byl natolik úspěšný, že jeho vydavatel, společnost Personal Software později přejmenovaná na VisiCorp, měla z prodeje VisiCalcu na svoji dobu takřka neuvěřitelné zisky, které se snažila použít pro vývoj dalších softwarových produktů. Jednalo se například o program VisiPlot (kreslení grafů) nebo o relativně jednoduchý textový procesor VisiWord. V roce 1981 se vývojáři VisiCorpu zamýšleli nad tím, jak zlepšit interoperabilitu svých jednotlivých produktů, což by mohlo ve svém důsledku zvýšit jejich oblibu a tím pádem i prodejnost. Došli k tomu, že by bylo vhodné provést tři poměrně zásadní změny: vytvořit jednotné datové struktury, aby spolu programy mohly jednoduše komunikovat (dříve se data musela například exportovat z VisiCalcu a následně importovat do VisiPlotu), umožnit rychlejší přepínání mezi jednotlivými programy bez nutnosti jeden program ukončit a nastartovat druhý a taktéž sjednotit ovládání programů takovým způsobem, aby se uživatelé nemuseli učit rozdílné klávesové zkratky, jiné názvy položek v menu atd.
14. Lotus 1–2–3
Později byl tabulkový procesor VisiCalc překonán programy, které uživatelům nabízely lepší uživatelské prostředí, popř. více funkcí či větší výkonnost. Mezi tyto aplikace patřilo především QuattroPro a taktéž slavný Lotus 1–2–3. Ten byl původně celý naprogramován v makro assembleru, což se týkalo i verze 2.0. Až verze 3.0 byla kompletně přepsána do programovacího jazyka C, což na jednu stranu vedlo ke sjednocení na všech podporovaných platformách, na stranu druhou si přepis vyžádal více než roční zpoždění této verze (to bylo poměrně kritické, protože Lotusu začal silně konkurovat Microsoft).

Obrázek 26: Slavný tabulkový kalkulátor Lotus 1–2–3.
15. Volkov Commander
Jedním z nejúspěšnějších programů, jejichž uživatelské rozhraní i nabízené funkce byly odvozeny od původního Norton Commanderu, byl program Volkov Commander z roku 1992, jehož autorem je Vsevolod Volkov z Ukrajiny. Jako mnoho dalších aplikací pocházejících z postsovětských zemí, je i Volkov Commander ukázkou perfektní znalosti práce s assemblerem – celý program včetně prohlížeče a editoru se nachází v jediném spustitelném souboru typu COM (bez relokačních tabulek atd.), jehož délka nepřesáhla (až do verze 4.0) pouhých 64 kB. Ve Volkov Commanderu měl prakticky každý dialog svoji lokální historii, bylo podporováno rozdělení souborů na více částí při kopiích na disketu (velmi užitečná pomůcka) a ve verzi 5.0 alfa (4.99.xxx) byla přidána například i podpora pro dlouhá jména souborů (LFN), ovšem pouze v případě, že se Volkov Commander spouštěl z Windows, které tuto podporu nabízely. Navíc se mohla při kopírování souborů využívat veškerá dostupná paměť, což kopírování urychlovalo, například při zápisu na diskety nebo práci s CD-ROM.

Obrázek 27: Textové uživatelské prostředí Volkov Commanderu je prakticky k nerozeznání podobné prostředí původního Norton Commanderu.

Obrázek 28: Nápověda k Volkov Commanderu 4.0 s hypertextovými odkazy je taktéž podobná nápovědě k Norton Commanderu.
16. SpeedScript (klasická verze)
Na domácích osmibitových mikropočítačích vybavených mikroprocesorem MOS 6502 (nebo jeho variantou MOS 6510) byl velmi populárním textovým procesorem program nazvaný SpeedScript, který byl naprogramován Charlesem Brannonem. První verze SpeedScriptu byla pod jménem Scriptor publikována časopisem Compute! již v roce 1983 ve formě zdrojového kódu v assembleru (uživatelé si program museli sami opsat do počítače a případně nahrát na kazety/diskety). O rok později pak stejný autor vydal nový program již nazvaný SpeedScript, který byl původně určený pro mikropočítače Commodore VIC-20 a Commodore C64, později však došlo k portaci i na osmibitové mikropočítače Atari a Apple II; SpeedScript se i díky tomu stal vůbec nejpopulárnějším programem publikovaným v časopise Compute!. Nejrozšířenější mezi uživateli byla verze 3 a 3.2 (1985, 1987).

Obrázek 29: Obal s paměťovým médiem nebo návodem ke SpeedScriptu.
Textový procesor SpeedScript se vyznačoval minimalisticky pojatým uživatelským rozhraním (stavový řádek kombinovaný s příkazovým řádkem), poměrně sofistikovanou sadou příkazů, existencí operace undo (podobně implementované jako v Emacsu, tj. přes „kill buffer“), operacemi prováděnými na úrovni slov, vět či odstavců (jako v editoru Vi) atd. Mimochodem, zdrojový kód SpeedScriptu 3.0 je dostupný například zde.

Obrázek 30: Klávesové zkratky SpeedScriptu ve verzi pro počítače Apple II.
Zajímavé je zjistit, proč například operace pro smazání textu uměly smazat slovo, větu či odstavec nebo proč existovala operace na vložení 256 mezer – SpeedScript se totiž musel vyrovnat s tím, že běžel na relativně pomalých počítačích a (pravděpodobně) neimplementoval gap buffer, což znamenalo, že operace smazání či vložení jednoho znaku byla dosti pomalá, zejména u delších textů.

Obrázek 31: Klávesové zkratky SpeedScriptu ve verzi pro počítače Commodore VIC-20.
Obrázek 32: Klávesové zkratky SpeedScriptu ve variantě pro počítače Atari.

Obrázek 33: SpeedScript pro Atari: úvodní obrazovka původního programu (jeho binární obraz má velikost 8330 bajtů).
Textový procesor SpeedScript se dočkal i dalších variant. Zajímavá je například verze určená pro osmibitový mikropočítač Commodore C128, který se od původního slavného Commodore C64 odlišoval jak dvojnásobnou kapacitou operační paměti (128kB oproti 64kB), tak zejména podporou horizontálního rozlišení 640 pixelů, což umožnilo na jednom řádku zobrazit 80 poměrně dobře čitelných znaků, samozřejmě za předpokladu, že je použit odpovídající monitor. SpeedScript byl pro tento nový grafický režim upraven a vydán pod názvem SpeedScript 128. Pořád se však jednalo o aplikaci naprogramovanou v assembleru mikroprocesoru MOS 6502.

Obrázek 34: SpeedScript pro Commodore C128 používá 80 znaků na řádek.
Další varianta SpeedScriptu je zcela odlišná. Jedná se o aplikaci určenou pro počítače IBM PC s DOSem, přičemž tato varianta textového procesoru byla přepsána do Pascalu a nemá tak s původním zdrojovým kódem prakticky nic společného (jen klávesové zkratky a logiku ovládání) a kvůli přepsání do vyššího programovacího jazyka pro nás ani není v kontextu dnešního článku zajímavá. Ovšem na IBM PC měl SpeedScript dosti velkou konkurenci a nebyl na této platformě tak oblíbený, jako na osmibitových mikropočítačích.

Obrázek 35: SpeedScript pro IBM PC (DOS).

Obrázek 36: SpeedScript pro IBM PC (DOS).
17. Textový editor e (pro DOS)
Další textový editor napsaný v assembleru, s nímž se dnes seznámíme, se jmenuje jednoduše E, ovšem je známý spíše pod názvem E.COM, což je název odvozený od jména spustitelného souboru s tímto editorem. Editor E, jehož autorem je David Nye, je kompletně naprogramován v assembleru (šestnáctibitový reálný režim procesorů Intel řady 80×86). Velikost tohoto textového editoru je přibližně šest kilobajtů, což mj. znamená, že každý screenshot zobrazený pod tímto odstavcem je větší, než samotný editor. I přes malou velikost nabízí tento program velmi zajímavé možnosti – samozřejmě práci s bloky, ale i možnost spouštění externích programů po zadání klávesových zkratek, formátování odstavců, nastavení režimu automatického odsazení apod. Výjimečné jsou klávesové zkratky Ctrl+Home a Ctrl+End, kterými lze nastavit levý a pravý okraj odstavců (na základě aktuální pozice kurzoru), což vlastně znamená, že E.COM lze použít i jako jednoduchý textový procesor. Mezi nevýhody patří především fakt, že řádky delší než 80 znaků jsou automaticky a bez varování uříznuty na velikost pouze oněch 80 znaků. I přesto se však jedná o velmi zajímavý minimalisticky pojatý program, který je možné díky dostupnosti jeho zdrojového kódu dále upravovat a rozšiřovat (což nakonec udělal i autor tohoto článku, v sadě malých patchů).

Obrázek 37: Editace zdrojového souboru v editoru E. Tento zdrojový soubor je pro ilustraci otevřen i v dalších editorech popisovaných v navazujících kapitolách.

Obrázek 38: Integrovaná obrazovka s nápovědou k editoru E.

Obrázek 39: Tento editor podporuje i práci s vizuálními bloky.

Obrázek 40: Editor E.COM po malých úpravách provedených autorem tohoto článku. Nejviditelnější je změna atributů textu (modré pozadí, světlemodrý text) a taktéž podpora pro textové režimy 80×28, 80×43 a 80×50.
18. Textový editor e3 (pro Linux)
Další aplikací naprogramovanou mj. i v assembleru, je textový editor, který se jmenuje e3. Již samotné pojmenování tohoto editoru naznačuje, že se jeho autor Albrecht Kleine snažil o vytvoření minimalistického nástroje, což se skutečně (alespoň podle mého názoru) povedlo. Textový editor e3 je totiž naprogramován v assembleru mikroprocesorů řady x86. Zdrojový kód původní verze e3 je uložen v jediném souboru s přibližně 6500 řádky optimalizovaného assembleru určeného pro překlad do 32bitového režimu (použít lze například známý assembler NASM). Pro 64bitový režim existuje jednoduchý skript, který zdrojový kód e3 jednoduše transformuje (odlišná jména registrů apod.). Kromě toho existuje i šestnáctibitová verze editoru e3 určená pro systém DOS či pro šestnáctibitové (real mode) zavaděče a různé utility. Současně existuje i varianta e3 přepsaná do programovacího jazyka C, aby bylo možné tento nepochybně zajímavý editor používat například na počítačích vybavených mikroprocesory ARM či MIPS. My se však v dalším textu budeme zabývat pouze originální 32bitovou a 64bitovou variantou e3 naprogramovanou v assembleru.

Obrázek 41: Spuštění editoru e3 v režimu emulace klávesových zkratek WordStaru.
Binární obraz e3 je v porovnání s ostatními moderními textovými editory velmi malý – podle použitého režimu (32bit/64bit) je spustitelný soubor /usr/bin/e3 velký přibližně 13 či 17 kB a žádné další soubory nejsou pro práci s e3 zapotřebí. Textový editor e3 přitom nabízí uživatelům poměrně velké množství funkcí. Asi nejzajímavější je existence několika režimů práce editoru – ten totiž dokáže napodobit editor WordStar (spuštěno přes link e3ws), Emacs (spuštěno přes link e3em), Vi/Vim (spuštěno přes link e3vi) Pico/Nano (spuštěno přes link e3pi) či NEdit (Nirvana Editor) (spuštěno přes e3ne). Režimy je možné dokonce přepínat i za běhu editoru a součástí je i obrazovka s klávesovými zkratkami (to vše je samozřejmě uloženo ve zmíněných 13 či 17 kB). e3 nabízí dokonce i funkci „undo“, obsahuje kalkulačku (dokáže spočítat i složitý aritmetický výraz zapsaný v textu!) a – což je v našich podmínkách velmi důležité – podporuje plnohodnotný osmibitový vstup znaků. Režim kompatibility s editorem vi je překvapivě dobrý, ovšem například uživatele Vimu některé neexistující příkazy a režimy budou pravděpodobně mrzet (nejvíc asi absence plnohodnotného vizuálního režimu).

Obrázek 42: Obrazovka s nápovědou je dostupná za všech okolností a přitom je vždy indikováno, jakou klávesovou zkratkou se nápověda zobrazí.
Vzhledem ke zcela minimální velikosti tohoto textového editoru asi nepřekvapí, že některé vlastnosti nejsou implementovány. Týká se to zejména podpory pro zarovnávání textu a automatického odřádkování i přerovnání odstavců, což je však funkce užitečná jen v některých případech, nikoli například při úpravách konfiguračních souborů či zdrojových kódů. Taktéž chybí podpora pro využití regulárních výrazů při hledání a nahrazování. To je však vyřešeno elegantním způsobem – funkcí pro poslání vybraného textu do filtru sed, což (znalým) uživatelům otevírá široké možnosti použití. e3 se pravděpodobně nestane jediným textovým editorem, který by byl vhodný pro všechny příležitosti, ovšem ukazuje, že i velmi krátký program dokáže být překvapivě mocný a přitom rychlý a současně nenáročný na systémové zdroje.

Obrázek 43: Editace zdrojového kódu napsaného v programovacím jazyce C v editoru e3.
19. Legendární textový editor WordStar
„I actually have two computers. I have a computer I browse the Internet with and I get my email on, and I do my taxes on. And then I have my writing computer, which is a DOS machine, not connected to the Internet. I use WordStar 4.0 as my word processing system.“
George R. R. Martin, autor Písně ledu a ohně
Od konce sedmdesátých let až do zhruba první poloviny osmdesátých let minulého století byl nejznámějším a současně i nejprodávanějším komerčním textovým procesorem slavný WordStar. Historie tohoto – některými autory dodnes používaného – textového procesoru, který je například Johnem C. Dvorakem považován za jednu z nejlepších aplikací, která kdy byla vytvořena, sahá až do roku 1977, tj. vlastně do období předcházející boomu domácích osmibitových mikropočítačů. V tomto roce si totiž Seymour Rubinstein (jeden ze zaměstnanců firmy IMSAI) pročetl studii společnosti Datapro, která se zabývala specializovanými systémy s textovými procesory, a rozhodl se, že založí čistě softwarovou společnost orientovanou převážně na tento segment trhu. O rok později – konkrétně v roce 1978 – založil Rubinstein firmu nazvanou MicroPro a přesvědčil svého bývalého kolegu Johna Robbinse Barnabyho, aby se k nově založené firmě připojil a vyvíjel pro ni aplikace. Barnaby byl excelentní programátor orientovaný na vývoj v assembleru (v čem jiném v té době? :-) a o několik let později se stal jedním z nejznámějších programátorů celé éry vzestupu fenoménu zvaného „mikropočítač“.

Obrázek 44: Dobová reklama na textový editor WordStar (první část).
Prvním větším úkolem, kterým byl Barnaby pověřen, bylo naprogramování dvojice programů – relativně jednoduchého textového editoru nazvaného zpočátku WordMaster a dále pak programu SuperSort. Oba programy byly určeny pro operační systém CP/M pro osmibitové mikroprocesory Intel 8080 a Zilog Z80. Barnaby pracoval na vývoji obou programů současně (!), přičemž pro vytvoření WordMasteru použil svůj dřívější textový editor nazvaný NED (New EDitor, screenshot bohužel nemám k dispozici), psaný – jak bylo Barnabyho zvykem – v assembleru mikroprocesoru Intel 8080. WordMaster se jakožto komerční aplikace prodával poměrně dobře, ovšem uživatelé začali požadovat nové funkce, především podporu pro tisk a taktéž podporu pro (polo)automatické formátování a zalamování textu – ostatně právě tyto dvě funkce tvořily určitou hranici mezi textovými editory a textovými procesory. John Barnaby se tedy s velkým nasazením pustil do dalšího úkolu – vytvoření plnohodnotného textového procesoru s podporou tisku, aktivních okrajů textu a taktéž podporou pro automatický word wrapping (přeskládání slov v odstavci při jeho editaci, což umí i později naprogramované editory D-Text a TextWriter).

Obrázek 45: Dobová reklama na textový editor WordStar (druhá část).
20. Hrdina používající assembler: 137 000 řádků v assembleru aneb projekt s odhadovanou pracností 42 člověkoroků napsaný za deset měsíců
Naprogramování textového procesoru nazvaného WordStar trvalo deset měsíců a nakonec bylo z původního kódu WordMasteru použito pouze necelých 10%, což mi na program napsaný v assembleru přijde překvapivě velké číslo. Johnu Barnabymu se podařil heroický a možná dodnes nepřekonaný výkon – za oněch deset měsíců napsal 137 tisíc řádků kvalitního a současně i otestovaného programového kódu v assembleru. Seymour Rubinstein a jeho přátelé ze společnosti IBM později vypočítali, že se jednalo o práci v rozsahu 42 člověkoroků! V roce 1979 byl zahájen prodej první komerční verze WordStaru, jehož cena byla 495 dolarů za samotný program a 40 dolarů za manuál (éra záměrně snižovaných cen SW přišla až později). Jednalo se o velmi úspěšný produkt – jen za rok 1979 prodej přesáhl 500 000 dolarů, v roce 1980 již 1,8 milionu dolarů a v roce 1981 dokonce 5,2 milionu dolarů. Největší obrat měla tato firma v roce 1984 – celých 70 milionů dolarů – což z ní činilo největší softwarovou firmu na světě! A to díky projektu naprogramovanému v „pouhém“ assembleru! Druhá verze WordStaru (taktéž vydaná pro CP/M) měla zabudovanou ochranu proti kopírování, což se však odrazilo na menší oblibě. V dalších verzích byla tato ochrana zrušena.
U Johna Barnabyho, který pracoval velmi intenzivně mnoho hodin denně sedm dnů v týdnu, se však na konci roku 1979 začal projevoval syndrom vyhoření. Z tohoto důvodu zažádal o čtyřměsíční volno, které mu Rubinstein skutečně dal, ostatně pravděpodobně mu ani nic jiného nezbývalo. Avšak ani na počátku roku 1980 Barnaby ještě nebyl připraven pokračovat v práci a nakonec firmu MicroPro opustil. Jako každý správný hrdina se však John Barnaby ještě jednou ukázal na scéně a to ve druhé polovině roku 1980. Firma Epson totiž zkonstruovala malý počítač PX-8 se zabudovaným monochromatickým LCD. Společnost Epson si přála, aby v tomto počítači byla v paměti ROM uložena upravená verze WordStaru schopná pracovat s pouhými 48 kB RAM, což znamenalo přepsat část původního zdrojového kódu (psaného v assembleru, jak již víme z předchozího textu).
Tehdejší programátoři, kteří ve firmě MicroPro pracovali, odhadli, že jim bude konverze WordStaru na PX-8 trvat šest měsíců. Rubinstein na to odpověděl, že se přece jedná o pouhopouhou konverzi, která musí být na základě požadavků firmy Epson hotová za čtyři měsíce. Po dlouhých diskuzích nakonec Rubinstein znovu (a naposledy) přemluvil Barnabyho, aby portaci provedl samostatně. John Barnaby si řekl o 100 dolarů na hodinu a nakonec se mu podařilo portaci dodělat za pouhé dva týdny! (další týden si vyžádalo odladění a otestování).

Obrázek 46: Počítač PX-8 se zabudovaným monochromatickým LCD a WordStarem.
V roce 1981 byl WordStar vydán pro operační systém CP/M-86, tj. pro mikropočítače postavené na mikroprocesorech Intel 80×86. Říká se, že programátoři firmy MicroPro nebyli schopni (nebo neměli dosti času) na pochopení původního optimalizovaného zdrojového kódu Johna Barnabyho, takže velkou část kódu prostě přepsali z instrukcí osmibitového mikroprocesoru Intel 8080 na instrukce šestnáctibitového mikroprocesoru Intel 8086 (výsledek – ještě první verze WordStaru pro DOS dokázala pracovat jen s 64 kB RAM). I to je možná důvod, proč se o tři roky později společnost MicroPro rozhodla, že celý textový procesor přepíše znovu, tentokrát v programovacím jazyce C, ale to již poněkud předbíháme. Nicméně na konci roku 1981 byl WordStar bezpochyby nejslavnějším textovým procesorem provozovaným prakticky na všech počítačích s osmibitovým operačním systémem CP/M i s jeho šestnáctibitovou variantou CP/M-86.

Vzhledem k tomu, že WordStar byl úspěšně portován na operační systém CP/M-86, bylo jen otázkou času, kdy se firma MicroPro pokusí o vydání verze určené pro operační systém MS-DOS, čímž by se WordStaru otevřela cesta na potenciálně velmi rozsáhlý trh s programy pro počítače IBM PC. Již v dubnu 1982 se dalšímu hackerovi z firmy MicroPro – Jimu Foxovi – podařilo za jedinou noc upravit verzi WordStaru pro CP/M-86 takovým způsobem, že tento textový procesor mohl být spuštěn v MS-DOSu. Jednalo se prozatím o technologické demo, které Jim Fox ukázal další ráno Rubinsteinovi, ovšem plnohodnotná portace byla provedena až skupinou irských programátorů, kteří pro vývoj používali vývojový systém firmy Intel, jenž pracoval s operačním systémem ISIS II a pro ukládání dat používal osmipalcové diskety (nikoli pevný disk). Vytvořené spustitelné soubory s WordStarem byly následně přeneseny na IBM PC s využitím sériového portu.

Obrázek 47: Další dobová reklama na textový procesor WordStar v podstatě ani moc nepřeháněla :-).
Zdroj: www.old-computers.com
21. Odkazy na Internetu
- George R. R. Martin writes with a DOS word processor
http://www.cnet.com/news/george-r-r-martin-writes-with-a-dos-word-processor/#! - Assembly Language: Still Relevant Today
http://wilsonminesco.com/AssyDefense/ - Programovani v assembleru na OS Linux
http://www.cs.vsb.cz/grygarek/asm/asmlinux.html - TIOBE Index for September 2019
https://www.tiobe.com/tiobe-index/ - Assembly language on TIOBE Index
https://www.tiobe.com/tiobe-index/assembly-language/ - Why Assembly Language Programming? (Why Learning Assembly Language Is Still a Good Idea)
https://wdc65×x.com/markets/education/why-assembly-language-programming/ - Low Fat Computing
http://www.ultratechnology.com/lowfat.htm - Assembly Language
https://www.cleverism.com/skills-and-tools/assembly-language/ - Why do we need assembly language?
https://cs.stackexchange.com/questions/13287/why-do-we-need-assembly-language - Assembly language (Wikipedia)
https://en.wikipedia.org/wiki/Assembly_language#Historical_perspective - Assembly languages
https://curlie.org/Computers/Programming/Languages/Assembly/ - vasm
http://sun.hasenbraten.de/vasm/ - A86/A386 assembler and D86/D386 debugger
http://eji.com/a86/ - FASM
https://en.wikipedia.org/wiki/FASM - NASM
https://www.nasm.us/ - High Level Assembly (home page)
http://plantation-productions.com/Webster/ - High Level Assembly (Wikipedia)
https://en.wikipedia.org/wiki/High_Level_Assembly - A86/A386 Features
http://eji.com/a86/features.htm#FeaturesA86 - Sphinx C–
http://c–sphinx.narod.ru/indexe.htm - OPEN SPHiNX C– Compiler
https://sourceforge.net/projects/c--/ - The Art of Assembly Language
http://www.plantation-productions.com/Webster/www.artofasm.com/Windows/HTML/AoATOC.html - SpeedScript 3.2 for the Commodore 64
http://www.atarimagazines.com/compute/gazette/198705-speedscript.html - SpeedScript source code
http://www.atariarchives.org/speedscript/ch3.php - SpeedScript 3.0: All Machine Language Word Processor For the Atari
http://www.atariarchives.org/speedscript/ch1.php - Textové editory pro mainframy
http://texteditors.org/cgi-bin/wiki.pl?MainframeEditorFamily - Text editor (Wikipedia)
https://en.wikipedia.org/wiki/Text_editor - Line editor (Wikipedia)
https://en.wikipedia.org/wiki/Line_editor - Opravdoví programátoři nepoužívají Pascal
http://www.logix.cz/michal/humornik/Pojidaci.Kolacu.xp - Programovani v assembleru na OS Linux
http://www.cs.vsb.cz/grygarek/asm/asmlinux.html - Is it worthwhile to learn x86 assembly language today?
https://www.quora.com/Is-it-worthwhile-to-learn-x86-assembly-language-today?share=1 - Assembly language today
http://beust.com/weblog/2004/06/23/assembly-language-today/ - Assembler: Význam assembleru dnes
http://www.builder.cz/rubriky/assembler/vyznam-assembleru-dnes-155960cz - Assembler pod Linuxem
http://phoenix.inf.upol.cz/linux/prog/asm.html - AT&T Syntax versus Intel Syntax
https://www.sourceware.org/binutils/docs-2.12/as.info/i386-Syntax.html - Linux Assembly website
http://asm.sourceforge.net/ - Using Assembly Language in Linux
http://asm.sourceforge.net/articles/linasm.html - Borland Turbo Assembler
https://web.archive.org/web/20101023185143/http://info.borland.com/borlandcpp/cppcomp/tasmfact.html - Microsoft Macro Assembler Reference
https://docs.microsoft.com/en-us/cpp/assembler/masm/microsoft-macro-assembler-reference?view=vs-2019 - Tesla PMI-80
http://osmi.tarbik.com/cssr/pmi80.html - PMI-80
http://en.wikipedia.org/wiki/PMI-80 - PMI-80
http://www.old-computers.com/museum/computer.asp?st=1&c=1016 - IBM System 360/370 Compiler and Historical Documentation
http://www.edelweb.fr/Simula/ - IBM 700/7000 series
http://en.wikipedia.org/wiki/IBM700/7000_series - IBM System/360
http://en.wikipedia.org/wiki/IBM_System/360 - IBM System/370
http://en.wikipedia.org/wiki/IBM_System/370 - Mainframe family tree and chronology
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_FT1.html - 704 Data Processing System
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP704.html - 705 Data Processing System
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_PP705.html - The IBM 704
http://www.columbia.edu/acis/history/704.html - IBM Mainframe album
http://www-03.ibm.com/ibm/history/exhibits/mainframe/mainframe_album.html - ASM-One Macro Assembler
http://en.wikipedia.org/wiki/ASM-One_Macro_Assembler - ASM-One pages
http://www.theflamearrows.info/documents/asmone.html - Základní informace o ASM-One
http://www.theflamearrows.info/documents/asminfo.html



































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU