
Obsah
1. SIMD instrukce využívané v moderních mikroprocesorech řady x86 (2.část: SSE)
2. Od MMX přes 3DNow! k instrukčním sadám SSE, SSE2 a SSE4
3. Počty nových instrukcí zaváděných v rámci jednotlivých rozšíření instrukční sady
4. Registry používané technologií SSE
5. Sada registrů použitelná vývojáři pracujícími s procesory podporujícími SSE
7. Aritmetické instrukce pracující se skalárními hodnotami i s vektory
8. Řízení režimu výpočtů s hodnotami reprezentovanými v systému plovoucí řádové čárky
1. SIMD instrukce využívané v moderních mikroprocesorech řady x86 (2.část: SSE)
V předchozí části seriálu o architekturách počítačů jsme si řekli základní informace o rozšíření instrukční sady procesorů x86 nazvané MMX, neboli MultiMedia eXtension, popř. též Matrix Math eXtension. Díky MMX se vlastně poprvé původně skalární (v případě čipů Pentium ve skutečnosti superskalární) procesorová architektura x86 rozšířila o instrukce typu SIMD (Single Instruction, Multiple Data), tj. o instrukce pracujícími s vektory pevné délky a nikoli pouze se skalárními hodnotami. V případě instrukční sady MMX bylo možné pracovat s celočíselnými daty uloženými v registrech o šířce 64 bitů, popř. v operační paměti. Jednalo se buď o vektory obsahující osmici bajtů, čtveřici šestnáctibitových slov, dvojici slov 32bitových či o jedinou 64bitovou skalární hodnotu. Poměrně rychle se ukázalo, že technologie SIMD instrukcí je na platformě x86 nejenom velmi dobře použitelná, ale i to, že se díky jejímu zařazení do původního repertoáru skalárních instrukcí může podařit zvýšit výpočetní rychlost některých algoritmů; samozřejmě za předpokladu, že jsou tyto algoritmy optimalizovány pro použití MMX instrukcí (zde jsme naopak mohli vidět absenci dobré podpory MMX jak v překladačích, tak i knihovnách).
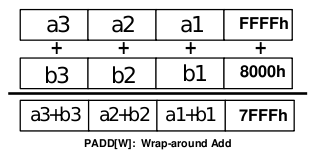
Obrázek 1: Ukázka chování MMX instrukce PADDW, která provádí součet čtveřice šestnáctibitových hodnot s přetečením, což je patrné z posledního sloupce.
(Zdroj: Intel MMXTM Technology Overview, Intel corporation, 1996)
Technologie MMX byla představena firmou Intel v roce 1996 a o rok později se již instrukční sada MMX začala používat v reálných mikroprocesorech. To pro konkurenční společnost AMD samozřejmě představovalo nemalou výzvu, takže již o dva roky později byla k dispozici technologie 3DNow! obsahující kromě podpory MMX taktéž nové SIMD instrukce. V tomto případě se však jednalo o instrukce umožňující manipulaci s dvouprvkovými vektory obsahujícími numerické hodnoty s plovoucí řádovou čárkou odpovídající formátu single/float známé normy IEEE 754 (i když je pravda, že některé režimy práce předepisované touto normou nebyly v 3DNow! použity, k čemuž se ještě v tomto článku vrátíme). Podobně jako v případě MMX, i u technologie 3DNow! se ukázalo, že se jedná o jeden z dobře použitelných způsobů zvýšení reálného výpočetního výkonu mikroprocesorů řady x86, aniž by bylo nutné přecházet na vyšší hodinové frekvence či zvětšovat kapacity vyrovnávacích pamětí (Level 1 Cache, Level 2 Cache).
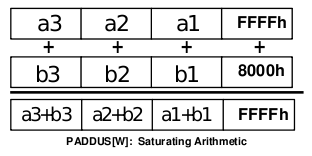
Obrázek 2: MMX instrukce PADDUSW, která sice také provádí součet čtveřice šestnáctibitových hodnot, ovšem součet je proveden se saturací – v případě, že se výsledek součtu již nemůže reprezentovat šestnáctibitovou hodnotou, uloží se namísto výsledku hodnota 0×FFFF, tj. nejvyšší šestnáctibitové celé číslo bez znaménka.
(Zdroj: Intel MMXTM Technology Overview, Intel corporation, 1996)
2. Od MMX přes 3DNow! k instrukčním sadám SSE, SSE2 a SSE4
Po úspěšném a relativně bezproblémovém zavedení rozšíření MMX i 3DNow! do praxe není divu, že obě nejvýznamnější společnosti podnikající v oblasti návrhu a prodeje mikroprocesorů patřících do rodiny x86, tj. firmy Intel a AMD, začaly pro tyto typy mikroprocesorů navrhovat i další rozšiřující instrukční sady s „vektorovými“ instrukcemi typu SIMD. V následující tabulce jsou tyto rozšiřující instrukční sady vypsány, včetně roku vzniku dané technologie i informace o tom, v jakém mikroprocesoru byla ta která technologie zpočátku využita. Některé z níže zmíněných technologií byly použity v mikroprocesorech vyráběných jednou společností (což je především případ 3DNow!), ovšem v současnosti můžeme vidět oboustranné snahy o zavádění rozšíření instrukční sady x86 podle jednotného schématu a navíc tak, aby ho bylo možné používat na mikroprocesorech vyráběných oběma zmíněnými společnostmi. To je poměrně velký rozdíl oproti ad-hoc řešením, s nimiž jsme se setkali v případě MMX i 3DNow! (kde navíc byli výrobci čipů svázaní snahou o zachování zpětné kompatibility s existujícími operačními systémy):
| Název technologie | Společnost | Rok uvedení | Poprvé použito v čipu |
|---|---|---|---|
| MMX | Intel | 1996 | Intel Pentium P5 |
| 3DNow! | AMD | 1998 | AMD K6–2 |
| SSE | Intel | 1999 | Intel Pentium III (mikroarchitektura P6) |
| SSE2 | Intel | 2001 | Intel Pentium 4 (mikroarchitektura NetBurst) |
| SSE3 | Intel | 2004 | Intel Pentium 4 (Prescott) |
| SSSE3 | Intel | 2006 | mikroarchitektura Intel Core |
| SSE4 | Intel+AMD | 2006 | AMD K10 (SSE4a) , mikroarchitektura Intel Core |
| XOP | AMD | 2011? | založeno na SSE5 |
| CVT16 | AMD | 2011? | založeno na SSE5 |
| AVX | Intel+AMD | 2013? | rozšíření SSE registrů na 256 bitů, celkem 32 registrů |

Obrázek 3: Intel Xeon 5600 je zástupcem mikroprocesorů určených pro oblast serverů. Samozřejmě taktéž podporuje SIMD operace: MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2
3. Počty nových instrukcí zaváděných v rámci jednotlivých rozšíření instrukční sady
Pro někoho může být taktéž zajímavá i informace o tom, jak velké změny v instrukční sadě mikroprocesorů byly vlastně při přidávání nových „vektorových“ rozšiřujících instrukčních sad typu SIMD provedeny. To nám ukáže další tabulka. Je pouze nutné dát pozor na to, že počty nových instrukcí zavedených v rámci těchto nových technologií, které jsou vypsány v tabulce pod odstavcem, nemusí přesně souhlasit s počty uváděnými v jiných informačních materiálech. Je tomu tak především z toho důvodu, že se v některých případech rozlišuje i datový typ, s nímž instrukce pracují (například se může jednat o součet vektoru s 32 bitovými hodnotami nebo 64bitovými hodnotami reprezentovanými v obou případech ve formátu s plovoucí řádovou čárkou) a někdy se taková instrukce do celkové sumy započítává pouze jedenkrát. Nicméně údaje vypsané v níže uvedené tabulce by měly být konzistentní, protože se jedná o počty nově přidaných operačních kódů instrukcí (například u dále popsané instrukční sady SSE2 končí instrukce znakem D, S, I či Q podle typu zpracovávaných dat/operandů):
| Název technologie | Počet nových instrukcí |
|---|---|
| MMX | 56 |
| 3DNow! | 21 |
| SSE | 70 |
| SSE2 | 144 |
| SSE3 | 13 |
| SSSE3 | 32 (ve skutečnosti vlastně jen 16 instrukcí, ovšem pro dva datové typy) |
| SSE4 | 54 (z toho 47 v rámci SSE4.1, zbytek v rámci SSE4.2) |

Obrázek 4: Konkurenční mikroprocesor společnosti AMD, který taktéž podporuje různé SIMD instrukce, konkrétně MMX, SSE, SSE2, SSE3 i 3DNow!.
4. Registry používané technologií SSE
Technologie MMX a 3DNow! jsme si již popsali v předchozí části tohoto seriálu, pojďme se tedy podívat na další rozšíření instrukční sady mikroprocesorů rodiny x86, které je dokonce v několika ohledech mnohem důležitější a pro mnoho programátorů taktéž zajímavější. Jedná se o technologii označovanou SSE, což je zkratka znamenající Streaming SIMD Extension. Na SSE se můžeme dívat buď jako na zcela nové rozšíření instrukční sady o SIMD instrukce, nebo jako na určité propojení předností obou předchozích technologií, tj. jak MMX (relativně velký počet prvků uložených ve vektorech, ovšem podpora pouze pro celočíselné operace nad prvky vektorů), tak i 3DNow! (práce s reálnými čísly, ovšem uloženými pouze v dvouprvkových vektorech, z čehož vyplývají menší možnosti paralelizace výpočtů). V případě SSE je navíc umožněna souběžná práce jednotky MMX či FPU. Ve specifikaci SSE jsou popsány jak významy všech nových instrukcí, tak i různé režimy využívané při aritmetických operacích. Specifikace taktéž říká, jaké registry se u nových instrukcí používají.
Nejprve se zaměřme na registry využívané v technologii SSE. U mikroprocesorů implementujících instrukční sadu SSE je využita nová sada registrů pojmenovaných XMM0 až XMM7. Na 64bitové platformě (architektura AMD 64) navíc došlo k přidání dalších osmi registrů se jmény XMM8 až XMM15 využitelných pouze v 64bitovém režimu. Všechny nové registry mají šířku 128 bitů, tj. jsou dvakrát širší, než registry používané v MMX i 3DNow! a čtyřikrát širší, než běžné pracovní registry na platformě x86 (bavíme se o 32bitovém režimu). Do každého registru je možné uložit čtveřici reálných numerických hodnot reprezentovaných v systému plovoucí řádové tečky podle normy IEEE 754, přičemž tato norma je dodržována přesněji, než v případě 3DNow! (různé zaokrouhlovací režimy či práce s denormalizovanými čísly sice mohou vypadat trošku jako černá magie, ovšem například v knihovnách pro numerické výpočty, které musí vždy za specifikovaných okolností dát stejný výsledek, se jedná o velmi důležitou vlastnost). K osmi či šestnácti novým registrům XMM* byl ještě přidán jeden 32bitový registr nazvaný MXCSR, jenž byl určený pro nastavení (řízení) režimů výpočtu.
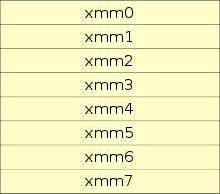
Obrázek 5: Sada nových pracovních registrů přidaných v rámci rozšíření instrukční sady SSE.
5. Sada registrů použitelná vývojáři pracujícími s procesory podporujícími SSE
Díky zavedení rozšíření instrukční sady SSE do praxe začali mít programátoři vytvářející aplikace na 32bitové platformě x86, jejíž začátek se datuje od dnes již spíše historického mikroprocesoru Intel 80386, k dispozici nejenom 64bitové registry (jednotka MMX), ale i registry 128bitové, což je zajisté užitečné. Přitom i přes zavedení rozšířených instrukčních sad MMX/3DNow!/SSE stále zůstávala zachována binární zpětná i dopředná kompatibilita s předchozími typy mikroprocesorů (nejedná se tedy o takovou změnu, jako v případě přechodu 16->32->64 bitů). Zde je myšlena především možnost běhu starších aplikací na novějších mikroprocesorech, protože program přeložený s podporou SSE nebude na procesoru bez této technologie pracovat korektně, i když by pravděpodobně bylo možné SSE emulovat pomocí podprogramů spouštěných při zavolání neplatného operačního kódu (tj. operačního kódu SSE instrukce, která je samozřejmě pro ne-SSE procesor neznámým kódem).
Pro zajímavost se podívejme, jak se společně se zavedením instrukční sady SSE prakticky zdvojnásobila celková kapacita všech využitelných registrů na 32bitové platformě x86 (na 64bitové x86_64 je situace odlišná). V následující tabulce jsou kromě univerzálních pracovních registrů, indexových registrů a bázových registrů vypsány i registry se speciálním významem:
| # | Typ registrů | Počet registrů | Bitová šířka registru | Příklady |
|---|---|---|---|---|
| 1 | Univerzální registry | 4 | 32 bitů | EAX, EBX, ECX, EDX |
| 2 | Indexové registry | 3 | 32 bitů | ESI, EDI, EIP |
| 3 | Bázové registry | 2 | 32 bitů | EBP, ESP |
| 4 | Segmentové registry | 6 | 16 bitů | CS, DS, ES, FS, GS, SS |
| 5 | Příznakový registr | 1 | 32 bitů | EFLAGS (původně 16bitový FLAGS) |
| 6 | Registry pro ladění | 8 | 32 bitů | DR0..DR7 |
| 7 | Řídicí registry | 4 | 32 bitů | CR0, CR2, CR3, CR4 |
| 8 | Další spec. registry | 12? | 32 bitů | TR1…TR12 |
| 9 | Registry MMX/3DNow! | 8 | 64 bitů | shodné s FPU registry st(x), resp. se spodními 64 bity st(x) |
| 10 | Pracovní registry SSE | 8 | 128 bitů | XMM0 .. XMM7 |
| 11 | Řídicí registr SSE | 1 | 32 bitů | MXCSR |
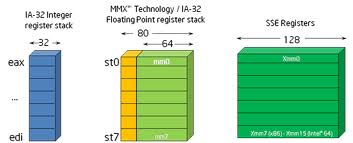
Obrázek 6: Zjednodušený programátorský model architektury x86 v 32bitovém režimu.
6. Nové instrukce SSE
V rámci technologie SSE byla instrukční sada rozšířena o několik typů instrukcí, které většinou pracovaly s již výše zmíněnými registry XMM*, popř. taktéž s operační pamětí nebo s obecnými celočíselnými 32bitovými registry procesorů x86, tj. například s registrem EAX. Všechny instrukce je možné rozdělit do několika kategorií:
| # | Kategorie | Příklad instrukce |
|---|---|---|
| 1 | Přenosy dat | MOVUPS, MOVAPS, MOVHPS, MOVLPS… |
| 2 | Aritmetické operace | ADDPS, SUBPS, MULPS, DIVPS, RCPPS… |
| 3 | Porovnání | CMPEQSS, CMPEQPS, CMPLTSS, CMPNLTSS, … |
| 4 | Logické operace | ANDPS, ANDNPS, ORPS, XORPS |
| 5 | Přenosy mezi prvky vektorů (shuffle) a konverze | SHUFPS, UNPCKHPS, UNPCKLPS |
| 6 | Načtení dat do cache | PREFETCH0, … |
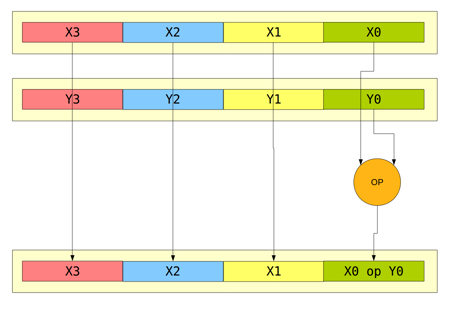
Obrázek 7: Některé instrukce zavedené v rámci SSE pracují pouze s dvojicí skalárních hodnot.
Zajímavá je podpora jak skalárních operací, tak i operací vektorových v instrukční sadě SSE. Příkladem může být například skalární instrukce součtu ADDSS (SS=single scalar), která může mít dvojí podobu:
ADDSS xmm1, xmm2 ; instrukce pracující s dvojicí registrů SSE ADDSS xmm1, mem32 ; instrukce pracující s registrem SSE a paměťovým místem (32 bitů)
Naproti tomu „vektorová“ podoba instrukce součtu ADDPS (PS=parallel scalar) pracuje s čtyřprvkovými vektory a zajímavé je, že operační kód této instrukce je o jeden prefixový bajt kratší, než je tomu u dříve zmíněné instrukce ADDSS (to dává smysl, protože častěji používané vektorové instrukce zaberou v operační paměti menší objem):
ADDPS xmm1, xmm2 ; instrukce pracující s dvojicí registrů SSE ADDPS xmm1, mem128 ; instrukce pracující s registrem SSE a paměťovým místem (128 bitů)
Taktéž stojí za zdůraznění fakt, že se v instrukční sadě SSE nenachází žádné instrukce, v jejichž operačním kódu by se nacházela konstanta. Ta musí být vždy uložena v operační paměti nebo přenesena z obecných registrů.

Obrázek 8: Vektorové operace podporované instrukční sadou SSE.
7. Aritmetické instrukce pracující se skalárními hodnotami i s vektory
Nejdůležitější skupinou SSE instrukcí jsou instrukce pro provádění aritmetických výpočtů. Tyto instrukce, které jsou vypsány v následující tabulce, pracují buď s dvojicí skalárních hodnot typu float/single umístěných v nejnižších 32 bitech 128bitového registru, nebo naopak s dvojicí vektorů, z nichž každý obsahuje čtyři 32bitové hodnoty opět typu float/single:
| # | Instrukce se skalárními operandy | Instrukce pracující s vektory | Význam instrukce |
|---|---|---|---|
| 1 | ADDSS | ADDPS | součet |
| 2 | SUBSS | SUBPS | rozdíl |
| 3 | MULSS | MULPS | součin |
| 4 | DIVSS | DIVPS | podíl |
| 5 | RCPSS | RCPPS | převrácená hodnota |
| 6 | SQRTSS | SQRTPS | druhá odmocnina |
| 7 | RSQRTSS | RSQRTPS | převrácená hodnota z druhé odmocniny |
| 8 | MAXSS | MAXPS | výpočet maxima |
| 9 | MINSS | MINPS | výpočet minima |

Obrázek 9: Formát 32bitových slov obsahujících hodnoty s plovoucí řádovou čárkou podle IEEE 754 (single/float).
8. Řízení režimu výpočtů s hodnotami reprezentovanými v systému plovoucí řádové čárky
Pro mnohé typy algoritmů, především těch z oblasti numerické matematiky, je důležité správné nastavení režimu aritmetické jednotky při provádění všech aritmetických operací, včetně způsobu zaokrouhlování hodnot i práce s denormalizovanými hodnotami, tj. takovými hodnotami, které není možné kvůli chybějícímu rozsahu exponentu normalizovat tak, aby se první bitová jednička nacházela v blízkosti řádové čárky. Tato nastavení aritmetické jednotky jsou snad ještě důležitější v případě použití 32bitového datového typu single/float, kde by ztráta přesnosti posledního bitu mantisy mohla mít velký vliv například na stabilitu numerických výpočtů (pokud by se naopak použil 64bitový datový typ double či 80bitový extended, nebylo by možné využít instrukce SSE, tudíž je vždy nutné zvolit mezi přesností, paměťovými nároky a rychlostí výpočtu).

Zatímco v případě instrukcí 3DNow! byl využíván pouze jediný zaokrouhlovací režim bez možnosti volby (jednalo se buď o zaokrouhlení směrem k nule nebo k nejbližší reprezentovatelné hodnotě v závislosti na typu instrukce), v případě SSE je již situace lepší, protože jsou podporovány čtyři režimy definované v normě IEEE 754: zaokrouhlení směrem k nule, ke kladnému nekonečnu, k zápornému nekonečnu i k nejbližšímu reprezentovatelnému číslu. Volba režimu se provádí přes řídicí registr MXCSR. Při požadavku na vyšší rychlost výpočtů s menší přesností lze dokonce zakázat práci s denormalizovanými čísly, které se automaticky považují za nulové hodnoty. V registru MXCSR lze taktéž zvolit masky příznaků, které mohou být nastaveny při provádění aritmetických operací – dělení nulou, přetečení, podtečení, nevalidní operace, ztráta přesnosti. Právě díky těmto vlastnostem se SSE začalo využívat i v některých tradičních knihovnách obsahujících algoritmy z oblasti numerické matematiky.

Obrázek 10: V 32bitových slovech lze podle normy IEEE 754 reprezentovat jak „běžné“ číselné konstanty, tak i kladnou či zápornou nulu, kladné i záporné nekonečno i NaN (Not a Number), což je pro mnoho operací zcela korektní hodnota.
9. Odkazy na Internetu
- SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - Cray History
http://www.cray.com/About/History.aspx?404;http://www.cray.com:80/about_cray/history.html - Cray Historical Timeline
http://www.cray.com/Assets/PDF/about/CrayTimeline.pdf - Computer Speed Claims 1980 to 1996
http://homepage.virgin.net/roy.longbottom/mips.htm





































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU