Obsah
1. Urychlení výpočtů s využitím SIMD instrukcí
2. Rozšíření instrukční sady SSE2 ve funkci vylepšené SSE
3. Typy dat, s nimž je možné pracovat v instrukční sadě SSE2
4. Nové instrukce přidané do instrukční sady SSE2
5. Aritmetické instrukce v instrukční sadě SSE2
6. Logické a aritmetické posuny
1. Urychlení výpočtů s využitím SIMD instrukcí
V předchozí části seriálu o architekturách počítačů jsme se zabývali popisem postupného (a poměrně rychlého) vývoje instrukcí typu SIMD (Single Instruction Multiple Data), tj. instrukcí pracujících s vektory konstantní délky, na mikroprocesorech kompatibilních s 32bitovou řadou x86. Původní – na platformě x86 historicky první – rozšířená instrukční sada MMX společnosti Intel z roku 1996 byla v roce 1998 doplněna o rozšíření instrukcí pojmenovaných 3DNow!, jejímž autorem je firma AMD. Nové instrukce obsažené v této sadě byly většinou určeny pro provádění výpočtů s numerickými hodnotami s plovoucí řádovou čárkou s jednoduchou přesností, které jsou v programovacích jazycích většinou označovány klíčovým slovem single nebo float. Abychom byli zcela přesní: díky instrukcím obsaženým v sadě 3DNow! bylo možné pracovat s dvouprvkovými vektory s uloženými čísly typu single, protože čísla tohoto typu jsou reprezentována 32bitovými slovy, což znamená, že do původních MMX registrů o šířce 64 bitů bylo možné uložit dvouprvkový vektor a provádět tak základní aritmetické operace (doplněné o výpočet převrácené hodnoty a druhé odmocniny) s dvojicí dvouprvkových vektorů.

Obrázek 1: Typy vektorů, s nimiž pracují instrukce MMX.
Jak instrukce z instrukční sady MMX, tak i instrukce ze sady 3DNow! využívaly osmici registrů určených původně pro použití matematickým koprocesorem (FPU – Floating Point Unit). To znamenalo jak úsporu plochy čipu (nejedná se samozřejmě pouze o klopné obvody realizující jednotlivé bity registrů, ale i o úpravu interních sběrnic atd.), tak i kompatibilitu s tehdy existujícími operačními systémy, protože nenastávaly problémy při přepínání kontextu. I přes určitá omezení, která byla způsobena nutností přepínání mezi funkcí matematického koprocesoru a jednotkami MMX či 3DNow! dokázali vývojáři některé algoritmy optimalizovat takovým způsobem, že nárůst výkonu byl v porovnání s původní „skalární“ implementací až několikanásobný. Na druhém obrázku je pro ilustraci zobrazen graf zvýšení výkonu v algoritmech pro práci s videem i audiem a navíc v algoritmu pro aplikaci konvolučního filtru na rastrové obrázky. V těchto případech se kladně projevily jak možnosti práce s vektory dat, tak i nové instrukce pro provádění aritmetických operací se saturací (MMX), které by se jinak musely řešit pomocí podmíněného skoku.
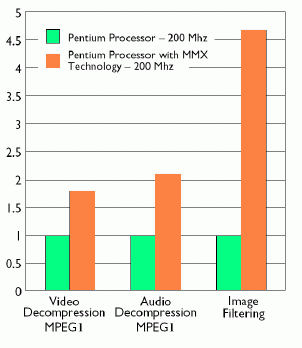
Obrázek 2: Příklad ilustrující, jakým způsobem došlo k urychlení algoritmů pro zpracování video a audio dat i algoritmu pro aplikaci konvolučního filtru díky použití instrukční sady MMX. Na vertikální osu je naneseno relativní zrychlení výpočtu, tj. v posledním případě se běh programu zrychlil 4,5×
2. Rozšíření instrukční sady SSE2 ve funkci vylepšené SSE
Poněkud odlišnou cestou, než tomu bylo u technologií MMX a 3DNow!, se v roce 1999 vydala firma Intel v případě instrukční sady pojmenované SSE (Streaming SIMD Extensions). Díky zavedení této technologie došlo k přidání osmi nových pracovních registrů s – na platformě x86 doposud nevídanou – šířkou 128 bitů. Vzhledem k tomu, že se změnil počet pracovních registrů, bylo nutné některé části systému i aplikací upravit takovým způsobem, aby při přepnutí kontextu nedocházelo ke vzájemnému přepisování těchto registrů (ovšem jen za předpokladu, že operační systém práci s instrukcemi SSE povolil). Rozšiřující instrukční sada SSE obsahovala sedmdesát nových instrukcí orientovaných většinou na práci s vektory obsahujícími čtyři čísla typu single. Jednalo se o výrazné zlepšení oproti možnostem nabízeným konkurenční sadou 3DNow!, protože při práci s reálnými čísly s jednoduchou přesností bylo možné teoreticky dosáhnout až dvojnásobného výpočetního výkonu v porovnání s 3DNow! a čtyřnásobného výkonu oproti práci se skalárním matematickým koprocesorem.
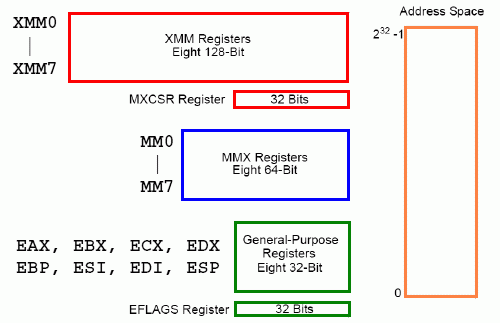
Obrázek 3: Zjednodušený programátorský model mikroprocesoru x86 s podporou MMX a SSE (i SSE2). V rámci MMX došlo k přidání osmice 64bitových registrů sdílených s FPU (modrý rámeček), zatímco v rámci SSE bylo přidáno osm registrů 128bitových a 32bitového řídicího registru MXCSR (dva červené rámečky).
V praxi byla dosažená změna výpočetního výkonu samozřejmě nižší, zejména v případech, kdy bylo nutné data často přenášet mezi operační pamětí a registry mikroprocesoru (obecně platí, že čím více operací se provede s jednou načtenými daty, tím je přírůstek výkonu dosažený díky SSE a 3DNow! vyšší). Ovšem záhy po uvedení instrukční sady SSE se mnozí vývojáři začali ptát, proč se většina instrukcí omezuje pouze na práci s čísly s jednoduchou přesností, když je mnoho aplikací založených na celočíselných datech (osmibitových bajtech, šestnáctibitových slovech, 32bitových slovech atd.), které by tak mohly využívat všech možností nabízených novými 128bitovými registry technologie SSE. Vývojáři pracující především na vývoji algoritmů z oblasti numerické matematiky by naopak uvítali práci s čísly s dvojitou přesností (double) uloženými v 64 bitech (tj. v případě 128bitových registrů by bylo možné do těchto registrů ukládat dvojice čísel s dvojitou přesností). Odpovědí na oba v podstatě protichůdné požadavky byla instrukční sada pojmenovaná jednoduše SSE2 z roku 2001. Tato sada byla zpočátku použita v mikroprocesorech Intel Pentium 4 a Intel Xeon, později se však rozšířila i na procesory firmy AMD (Athlon64, Opteron).
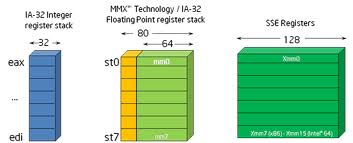
Obrázek 4: Jiný pohled na zjednodušený programátorský model architektury x86 v 32bitovém režimu.
3. Typy dat, s nimž je možné pracovat v instrukční sadě SSE2
Technologie SSE2 přinesla nové instrukce a samozřejmě i podstatné změny v interní struktuře vektorové jednotky, ovšem počet registrů ani jejich bitová šířka se nijak nezměnila. Programátoři používající, ať již přímo či nepřímo, rozšíření instrukční sady SSE2 mohli do osmice 128bitových registrů pojmenovaných XMM* ukládat celkem šest různých typů vektorů. Základ zůstal nezměněn – jednalo se o čtyřprvkové vektory obsahující čísla reprezentovaná ve formátu plovoucí řádové čárky, přičemž každé číslo bylo uloženo v 32 bitech (4×32=128 bitů), což odpovídá typu single/float definovanému v normě IEEE 754. Kromě toho byly v rámci SSE2 ještě zavedeny dvouprvkové vektory obsahující taktéž hodnoty reprezentované ve formátu plovoucí řádové čárky, ovšem tentokrát se jedná o čísla uložená v 64 bitech (2×64=128) odpovídající dvojité přesnosti (double) z normy IEEE 754. Zbývají nám čtyři další podporované datové typy. Jedná se o vektory s celočíselnými prvky: šestnáctiprvkové vektory s osmibitovými hodnotami, osmiprvkové vektory s šestnáctibitovými hodnotami, čtyřprvkové vektory s 32bitovými hodnotami a konečně dvouprvkové vektory s 64bitovými celočíselnými hodnotami.

Obrázek 5: Nové typy vektorů, se kterými je nově možné nativně pracovat na mikroprocesorech podporujících technologii SSE2.
Jak jsme si již řekli v předminulé části tohoto seriálu při popisu rozšíření instrukční sady MMX, je možné vektory obsahující celočíselná data využít pro poměrně velké množství aplikací, zejména pro zpracování zvukového signálu, ale taktéž pro různé operace s rastrovými obrázky (filtrace, některé způsoby komprimace apod.) nebo videem (estimace pohybu použité v MPEG). Na druhé straně spektra datových typů podporovaných funkční jednotkou SSE2 leží vektory obsahující dvojici numerických hodnot typu double, což mj. znamená, že instrukce SSE2 je možné využít i v některých oblastech numerické matematiky, i když je na tomto místě nutné říct, že přímo v SSE2 nejsou podporována čísla s rozšířenou přesností (extended), takže v některých případech může dojít při výpočtech v jednotce SSE2 (a nikoli FPU) ke kumulaci chyb ve výsledku. Nicméně kombinace instrukcí určených pro matematický koprocesor s instrukcemi určenými pro funkční jednotku SSE2 byla možná a v mnoha případech dokonce nutná, protože matematický koprocesor kromě základních aritmetických operací podporuje například i výpočet goniometrických funkcí, logaritmů atd.

Obrázek 6: Formát 32bitových slov obsahujících hodnoty s plovoucí řádovou čárkou podle normy IEEE 754 (single/float) tvoří základ instrukcí 3DNow! i SSE a je samozřejmě podporován i instrukční sadou SSE2.
4. Nové instrukce přidané do instrukční sady SSE2
Zatímco se v rozšiřující instrukční sadě SSE popsané v předcházející části tohoto seriálu nacházelo „pouze“ 70 nových instrukcí, byli tvůrci instrukční sady SSE2 mnohem velkorysejší, protože navrhli a posléze i implementovali hned 144 nových instrukcí, což přibližně odpovídá počtu všech základních instrukcí procesorů x86 (pokud samozřejmě nepočítáme všechny povolené adresní režimy). Tento velký počet nových instrukcí souvisí jak s podporou šesti datových typů popsaných v předchozí kapitole (včetně více než dvaceti konverzních funkcí), tak i s novými režimy přístupu k prvkům uloženým ve vektorech a se zcela novými operacemi, které byly navrženy pro podporu algoritmů pro 3D grafiku a práci s videem. Všechny instrukce, které byly přidány v rozšiřující instrukční sadě SSE2, je možné rozdělit do několika kategorií:
- Aritmetické operace prováděné s celými čísly (včetně součtu a rozdílu se saturací)
- Aritmetické operace prováděné s čísly s plovoucí řádovou čárkou
- Logické operace (některé jsou prováděny pro všech 128 bitů)
- Bitové posuny prvků o různé bitové šířce
- Porovnávací (komparační, relační) operace
- Konverzní funkce
- Konverze prvků uložených ve vektorech (zvýšení či snížení bitové šířky, shuffling apod.)
- Načítání a ukládání dat do operační paměti
- Řízení vyrovnávací paměti (cache)
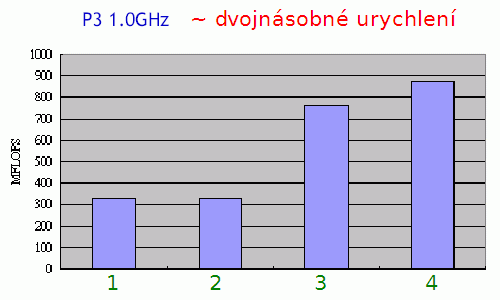
Obrázek 7: Ukázka urychlení operace součtu 1024 číselných prvků reprezentovaných ve formátu s plovoucí řádovou čárkou. Celkem byly použity čtyři algoritmy pro součet:
1 – využití instrukcí FPU
2 – využití instrukcí FPU s rozbalením smyčky
3 – využití vektorových operací SSE/SSE2
4 – využití vektorových operací SSE/SSE2 s rozbalením smyčky
5. Aritmetické instrukce v instrukční sadě SSE2
Podobně jako u rozšiřujících instrukčních sad MMX, 3DNow! a SSE, tvoří i u instrukční sady SSE2 nejpodstatnější část instrukce určené pro provádění aritmetických operací nad vektory prvků různých datových typů. Všechny nové operace implementované v SSE2 jsou vypsány v následující tabulce. Ve třetím sloupci je naznačeno, jaké vektory jsou danou operací zpracovávány, přičemž první číslo znamená počet prvků vektoru, za nímž následuje bitová šířka jednotlivých prvků:
| # | Instrukce | Operace/funkce | Struktura vektoru | Datový typ | Saturace? | Poznámka |
|---|---|---|---|---|---|---|
| 1 | addpd | součet | 2×64bit | double | × | |
| 2 | addsd | součet | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 3 | subpd | rozdíl | 2×64bit | double | × | |
| 4 | subsd | rozdíl | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 5 | mulpd | součin | 2×64bit | double | × | |
| 6 | mulsd | součin | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 7 | divpd | podíl | 2×64bit | double | × | |
| 8 | divsd | podíl | 1×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 9 | paddb | součet | 16×8bit | integer | ne | |
| 10 | paddw | součet | 8×16bit | integer | ne | |
| 11 | paddd | součet | 4×32bit | integer | ne | |
| 12 | paddq | součet | 2×64bit | integer | ne | |
| 13 | paddsb | součet | 16×8bit | integer | ano | |
| 14 | paddsw | součet | 8×16bit | integer | ano | |
| 15 | paddusb | součet | 16×8bit | unsigned | ano | |
| 16 | paddusw | součet | 8×16bit | unsigned | ano | |
| 17 | psubb | rozdíl | 16×8bit | integer | ne | |
| 18 | psubw | rozdíl | 8×16bit | integer | ne | |
| 19 | psubd | rozdíl | 4×32bit | integer | ne | |
| 20 | psubq | rozdíl | 2×64bit | integer | ne | |
| 21 | psubsb | rozdíl | 16×8bit | integer | ano | |
| 22 | psubsw | rozdíl | 8×16bit | integer | ano | |
| 23 | psubusb | rozdíl | 16×8bit | unsigned | ano | |
| 24 | psubusw | rozdíl | 8×16bit | unsigned | ano | |
| 25 | maxpd | maximum | 2×64bit | double | × | |
| 26 | maxsd | maximum | 2×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 27 | minpd | minimum | 2×64bit | double | × | |
| 28 | minsd | minimum | 2×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
| 29 | pmaddwd | součin/add | 8×16bit | integer | × | |
| 30 | pmulhw | součin | 8×16bit | integer | × | vrací vektor horních 16 bitů výsledků |
| 31 | pmullw | součin | 8×16bit | integer | × | vrací vektor dolních 16 bitů výsledků |
| 32 | pmuludq | součin | 4×32bit | integer | × | 64 bitový výsledek pro každý součin |
| 33 | rcpps | převrácená hodnota | 4×32bit | single | × | aproximace |
| 34 | rcpss | převrácená hodnota | 4×32bit | single | × | operace provedena jen s pravým prvkem vektorů |
| 35 | sqrtpd | druhá odmocnina | 2×64bit | double | × | |
| 36 | sqrtsd | druhá odmocnina | 2×64bit | double | × | operace provedena jen s pravým prvkem vektorů |
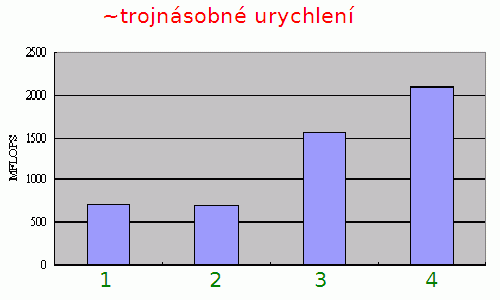
Obrázek 8: Ukázka urychlení operace výpočtu skalárního součinu pro 1024 trojrozměrných vektorů. Prvky vektorů jsou opět reprezentovány ve formátu s plovoucí řádovou čárkou. Celkem byly použity čtyři algoritmy pro součet:
1 – využití instrukcí FPU
2 – využití instrukcí FPU s rozbalením smyčky
3 – využití vektorových operací SSE/SSE2
4 – využití vektorových operací SSE/SSE2 s rozbalením smyčky
Důvod, proč ze došlo k většímu urychlení při použití SSE/SSE2 je jednoduchý: s jednou načtenými daty (vektory) se provádělo větší množství operací, takže se zde v menší míře projevila latence operačních pamětí a další externí vlivy. Sice je možné najít i algoritmy, u nichž je dosaženo ještě většího urychlení výpočtů, ale v praxi je zhruba trojnásobné urychlení (podobně jako na tomto grafu) považováno za velký úspěch.
6. Logické a aritmetické posuny
V instrukční sadě SSE2 můžeme najít i nové logické instrukce a instrukce pro provádění logických či aritmetických posunů. Ve skutečnosti se vlastně jedná o pouhé rozšíření stávajících instrukcí MMX takovým způsobem, aby bylo možné pracovat s novými 128bitovými vektory, popř. s daty uloženými v operační paměti v bloku šestnácti bajtů (16×8=128 bitů). Nejprve si popišme instrukce pro aritmetické a logické posuny. Ty dokážou pracovat s celočíselnými hodnotami o velikosti 16, 32, 64 či 128 bitů, tj. každá část vektoru se posouvá zvlášť (je tedy rozdíl mezi posunem jednoho 128bitového čísla a dvojice 64bitových čísel). Při logických posunech se do nového bitu nasouvá vždy logická nula (nikoli příznak carry), u aritmetických posunů se opakuje hodnota původního nejvyššího bitu, tj. instrukce pracují přesně tak, jak to programátoři očekávají:
| # | Instrukce | Operace/funkce | Struktura vektoru | Datový typ | Poznámka |
|---|---|---|---|---|---|
| 1 | pslldq | logický posun doleva | 1×128bitů | integer | |
| 2 | psllq | logický posun doleva | 2×64bitů | integer | |
| 3 | pslld | logický posun doleva | 4×32bitů | integer | |
| 4 | psllw | logický posun doleva | 8×16bitů | integer | |
| 5 | psrldq | logický posun doprava | 1×128bitů | integer | |
| 6 | psrlq | logický posun doprava | 2×64bitů | integer | |
| 7 | psrld | logický posun doprava | 4×32bitů | integer | |
| 8 | psrlw | logický posun doprava | 8×16bitů | integer | |
| 9 | psrad | aritmetický posun doprava | 4×32bitů | integer | |
| 10 | psraw | aritmetický posun doprava | 8×16bitů | integer |

Obrázek 9: Vektorové operace podporované instrukční sadou SSE a samozřejmě i SSE2.
7. Logické operace
Následuje seznam instrukcí určených pro provádění logických operací nad vektory různé délky. V některých případech (PAND, POR, PXOR) se jedná o rozšíření původních MMX instrukcí takovým způsobem, aby tyto instrukce mohly pracovat se 128bitovými vektory. Dokonce i operační kódy instrukcí zůstávají stejné, ovšem v případě SSE2 je před vlastním instrukčním kódem uveden prefix 0×66, takže jsou instrukce o jeden bajt delší (to ostatně platí i pro aritmetické operace popsané o kapitolu výše):
| # | Instrukce | Operace/funkce | Struktura vektoru | Datový typ | Poznámka |
|---|---|---|---|---|---|
| 1 | pand | and | 1×128 bitů | integer | |
| 2 | pandn | not and | 1×128 bitů | integer | první operand je negován |
| 3 | por | or | 1×128 bitů | integer | |
| 4 | pxor | xor | 1×128 bitů | integer | |
| 5 | andpd | and | 2×64 bitů | double | |
| 6 | orpd | or | 2×64 bitů | double | |
| 7 | xorpd | xor | 2×64 bitů | double | |
| 8 | andnpd | not and | 2×64 bitů | double | první operand je negován |
| 9 | andnps | not and | 4×32 bitů | single | první operand je negován |

Obrázek 10: Intel Xeon 5600 je zástupcem mikroprocesorů určených pro oblast serverů. Samozřejmě taktéž podporuje SIMD operace: MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2
8. Konverzí instrukce
Při implementaci mnoha algoritmů, především pak při zpracování obrazových a zvukových datových toků, se mnohdy programátoři dostanou do situace, kdy potřebují zkonvertovat data do jiného formátu, než v jakém byla původně uložena. Pro tyto účely jsou v instrukční sadě SSE2 k dispozici dvě desítky konverzních instrukcí začínajících prefixem cvt, vypsaných v tabulce pod tímto odstavcem:
| # | Instrukce | Konverze z… | Konverze do… |
|---|---|---|---|
| 1 | cvtdq2pd | 2×32bitový integer | 2×64bitový double |
| 2 | cvtdq2ps | 4×32bitový integer | 4×32bitový single |
| 3 | cvtpd2pi | 2×64bitový double | 2×32bitový integer v MMX registru |
| 4 | cvtpd2dq | 2×64bitový double | 2×32bitový integer ve spodní polovině MMX registru |
| 5 | cvtpd2ps | 2×64bitový double | 2×32bitový single ve spodní polovině MMX registru |
| 6 | cvtpi2pd | 2×32bitový integer | 2×32bitový single ve spodní polovině MMX registru |
| 7 | cvtps2dq | 4×32bitový single | 4×32bitový integer |
| 8 | cvtps2pd | 2×32bitový single | 2×64bitový double |
| 9 | cvtsd2si | 1×64bitový double | 1×32bitový integer v pracovním registru (CPU) |
| 10 | cvttpd2pi | 2×64bitový double | 2×32bitový integer (odseknutí desetinné části) |
| 11 | cvttpd2dq | 2×64bitový double | 2×32bitový integer (odseknutí desetinné části) |
| 12 | cvttps2dq | 4×32bitový single | 4×32bitový integer (odseknutí desetinné části) |
| 13 | cvttps2pi | 2×32bitový single | 2×32bitový integer (odseknutí desetinné části) v MMX registru |
| 14 | cvttsd2si | 1×64bitový double | 1×32bitový integer (odseknutí desetinné části) v pracovním registru |
| 15 | cvttss2si | 1×32bitový single | 1×32bitový integer (odseknutí desetinné části) v pracovním registru |
| 16 | cvtsi2sd | 1×32bitový integer | 1×64bitový double |
| 17 | cvtsi2ss | 1×32bitový integer | 1×32bitový single |
| 18 | cvtsd2ss | 1×64bitový double | 1×32bitový single (horní polovina registru se nemění) |
| 19 | cvtss2sd | 1×32bitový single | 1×64bitový double |
| 20 | cvtss2si | 1×32bitový single | 1×32bitový integer v pracovním registru (CPU) |

Obrázek 11: Univerzální konverzní funkce PSHUF byla v instrukční sadě SSE2 rozšířena tak, aby dokázala pracovat i se 128bitovými registry.

Poznámka: popravdě řečeno by se pro mnoho serverových aplikací hodily ještě instrukce pro konverzi mezi UTF-8 a UCS-4, což je po obvodové stránce poměrně jednoduchá bitová transformace, ovšem obtížně reprezentovatelná v reálně existujících strojových instrukcích.
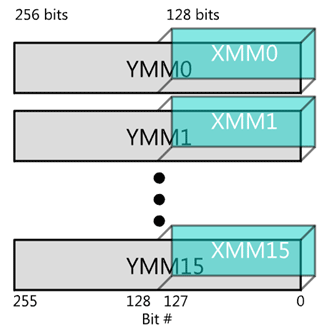
Obrázek 12: V rámci instrukční sady Intel AVX došlo k dalšímu zvýšení bitové šířky „vektorových“ registrů na 256 bitů.
9. Odkazy na Internetu
- Baha Guclu Dundar:
Intel MMX, SSE, SSE2, SSE3/SSSE3/SSE4 Architectures - SSE (Streaming SIMD Extentions)
http://www.songho.ca/misc/sse/sse.html - Timothy A. Chagnon: SSE and SSE2
http://www.cs.drexel.edu/~tc365/mpi-wht/sse.pdf - Intel corporation: Extending the Worldr's Most Popular Processor Architecture
http://download.intel.com/technology/architecture/new-instructions-paper.pdf - SIMD architectures:
http://arstechnica.com/old/content/2000/03/simd.ars/ - Tour of the Black Holes of Computing!: Floating Point
http://www.cs.hmc.edu/~geoff/classes/hmc.cs105…/slides/class02_floats.ppt - 3Dnow! Technology Manual
AMD Inc., 2000 - Intel MMXTM Technology Overview
Intel corporation, 1996 - MultiMedia eXtensions
http://softpixel.com/~cwright/programming/simd/mmx.phpi - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - Cray History
http://www.cray.com/About/History.aspx?404;http://www.cray.com:80/about_cray/history.html - Cray Historical Timeline
http://www.cray.com/Assets/PDF/about/CrayTimeline.pdf - Computer Speed Claims 1980 to 1996
http://homepage.virgin.net/roy.longbottom/mips.htm





































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU