Obsah
1. Sledování správy paměti v Pythonu s využitím nástroje objgraph
2. Proměnné v Pythonu: jména versus hodnoty (objekty)
4. Ukázka zjištění referencí na objekty
5. Automatická správa paměti v Pythonu
6. Správa paměti založená na počítání referencí
7. Sledovací algoritmus a rozdělení objektů do generací
8. Cache pro často používané objekty
10. Prealokace paměti pro prvky seznamů a slovníků
11. Uvolňování paměti při mazání prvků
13. Instalace nástroje objgraph
16. Grafy se zpětným zjištěním referencí
17. Zjištění počtu objektů v paměti (podle jejich typu)
18. Sledování nově vytvořených objektů (podle jejich typu)
19. Repositář s demonstračními příklady
1. Sledování správy paměti v Pythonu s využitím nástroje objgraph
Programovací jazyk Python, podobně jako prakticky všechny další vyšší programovací jazyky, používá automatickou správu paměti, což znamená, že se programátor (většinou!) nemusí starat o uvolňování prostředků (objektů) z operační paměti. V Pythonu se používají dva způsoby detekce již nepotřebných objektů, a to zejména z toho důvodu, že mezi objekty mohou vznikat cyklické závislosti, jenž nejsou jednodušším algoritmem správně vyřešeny a detekovány. V dnešním článku si nejprve ve stručnosti popíšeme, jak se vlastně v Pythonu pracuje s proměnnými a parametry funkcí/metod a následně se zaměříme na popis nástroje nazvaného objgraph, který dokáže zobrazit reference mezi objekty, a to jak v textové podobě, tak i ve formě snadno pochopitelných grafů.
2. Proměnné v Pythonu: jména versus hodnoty (objekty)
Před popisem nástrojů a technik, které je možné využít pro sledování správy paměti v Pythonu je vhodné si připomenout, jakým způsobem se vlastně v tomto programovacím jazyce pracuje s proměnnými, popř. s parametry funkcí a metod.
Začněme velmi stručným popisem práce s proměnnými v jazyku C a v podobně koncipovaných programovacích jazycích, které jsou staticky typované, překládané a navíc nemají automatickou správu paměti (se všemi z toho plynoucími důsledky). V C můžeme deklarovat globální proměnné, proměnné lokální v rámci funkce nebo proměnné lokální v rámci bloku (ve funkci):
int x = 42;
Na základě této informace je proměnná uložena v paměti na místě vybraném překladačem. Konstanty (const int y = 10;) jsou většinou uloženy v kódovém segmentu (ten se ovšem někdy označuje jako „text“). Inicializované statické lokální proměnné (static int z = 6502; a inicializované globální (nekonstantní) proměnné jsou uloženy v datovém segmentu, protože jeho obsah je součástí spustitelného kódu a proměnné jsou tedy automaticky inicializovány na uživatelem specifikovanou hodnotu. Ostatní globální proměnné a statické proměnné, tedy ty, které nejsou inicializovány, jsou uloženy v bss segmentu (block starting symbol), který je po spuštění aplikace alokován a následně vymazán nulami, čímž se zajistí chování odpovídající specifikaci programovacího jazyka C. Zbývají nám lokální (nestatické) proměnné. Ty jsou uloženy na zásobníkovém rámci alokovaném ve chvíli, kdy je zavolána odpovídající funkce. To, do jaké oblasti se proměnná uloží, je informace známá již v době překladu, přičemž překladač taktéž zná typ proměnné, který se v rámci daného bloku nemůže změnit (a v jiném bloku se bude jednat o zcela odlišnou proměnnou). Jediná „dynamika“ spočívá v tom, že lokální (nestatické) proměnné jsou automaticky vytvářeny popř. rušeny při vstupu a výstupu z funkce, kde jsou tyto proměnné deklarovány.
Poslední oblastí paměti je halda neboli heap. V této oblasti je možné explicitně alokovat bloky paměti a získat ukazatel na daný blok paměti. Problém spočívá v tom, že v C je nutné se explicitně postarat i o uvolnění paměti.
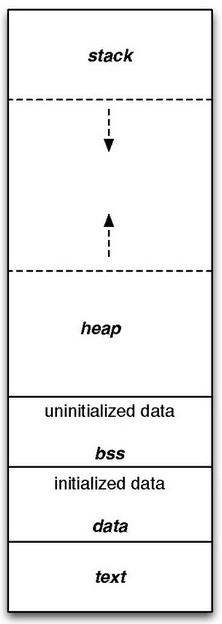
Obrázek 1: Struktura paměti alokované pro běžící program
Zdroj: Wikipedia.
V Pythonu je ovšem situace značně odlišná, což vede některé uživatele k tvrzení, že Python vlastně nemá proměnné (viděno optikou céčkařů). V Pythonu se totiž používá koncept jméno→reference→objekt. Jméno reprezentuje skutečné jméno nějakého objektu uloženého v paměti. Toto jméno je přes referenci svázáno se skutečným objektem, kterým je buď přímo hodnota nebo kontejner odkazující na jiný objekt (tedy mající uloženou referenci). A konečně zde máme bloky v paměti (konkrétně uložené na haldě), kterým se říká objekty. Jedná se o datové struktury, které kromě hodnoty (což je důvod, proč objekt vůbec vznikl) obsahuje i typ hodnoty a dále počet referencí, které na tento objekt odkazují.
Toto je velký a navíc i koncepční rozdíl oproti jazykům typu C, které do paměti ukládají pouze hodnotu. Typ se neukládá, protože ho zná překladač (a to pouze v době překladu) a počet referencí není nutný, protože C nemá automatickou správu paměti.
3. Reference na objekty
Na závěr si shrňme základní vlastnosti jmen a objektů v Pythonu:
- Jména nemají přiřazen typ a v různých místech programu může jedno jméno referencovat hodnoty různých typů
- Interpret zná rozsah platnosti (viditelnosti) jména
- Hodnoty (objekty) nemají rozsah platnosti, mohou být referencovány přes mnoho jmen
- Hodnoty (objekty) mají přiřazen typ, ten je neměnný
- Hodnoty (objekty) mají i čítač referencí
Reference na objekt vzniká přiřazením:
x = 6502
(ve skutečnosti byl v tomto případě vytvořen i příslušný objekt).
Pokud nyní zadáme:
y = x
budou na objekt 6502 uložený v paměti ukazovat dvě reference. Ovšem stále se bude jednat o týž objekt, o čemž se přesvědčíme funkcí id, která v CPythonu vrací adresu objektu:
>>> id(x) 140363521220176 >>> id(y) 140363521220176
Totéž platí pro všechny reference, tedy i reference na kontejnery:
>>> l1=[1,2,3] >>> l2=l1 >>> id(l1) 140363521208840 >>> id(l2) 140363521208840 # změna provedená přes l2 >>> l2[1] = "****" # je pochopitelně viditelná i při použití jména l1 >>> l1 [1, '****', 3]
Ke stejným hodnotám (referencím na objekty v seznamu) jsme přistoupili přes jména l1 a l2.
4. Ukázka zjištění referencí na objekt
Zjištění počtu referencí na objekty můžeme provést přímo z interaktivní smyčky (REPL) programovacího jazyka Python. Komentáře jsou v tomto případě přímo součástí „sezení“:
$ python3 Python 3.6.6 (default, Jul 19 2018, 16:29:00) [GCC 7.3.1 20180303 (Red Hat 7.3.1-5)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> # budeme potřebovat funkci sys.getrefcount >>> import sys >>> # vytvoříme první objekt a navážeme ho na jméno x >>> x = 6502 >>> # zjistíme počet referencí - první referenci vytvořil interpret, druhou my >>> sys.getrefcount(x) 2 >>> # hodnotu navážeme na další jméno >>> y = x >>> # počet referencí se zvýší o jedničku >>> sys.getrefcount(x) 3 >>> # hodnotu navážeme na další jméno >>> z = y >>> # počet referencí se opět zvýší o jedničku >>> sys.getrefcount(x) 4 >>> # jméno z navážeme na jinou hodnotu >>> z = 0 >>> # počet referencí se sníží o jedničku >>> sys.getrefcount(x) 3 >>> # vymažeme jméno, čímž se počet referencí sníží >>> del y >>> # počet referencí se opět sníží o jedničku >>> sys.getrefcount(x) 2 >>> # ukazují obě jména na stejný objekt? >>> id(x) 139646852357712 >>> id(y) 139646852357712 >>> # evidentně ano >>> x is y True
Můžeme si vyzkoušet i další podobně koncipované příklady. Pokud nebudou spouštěny přímo z REPL, bude počet referencí o jedničku vyšší, protože se objekty (hodnoty) vytvoří již v době překladu do bajtkódu:
"""Zobrazení počtu referencí řetězce 'Test!'."""
import sys
# počet referencí na řetězec 'Test!'
print(sys.getrefcount('Test!'))
Výsledek:
3
"""Zobrazení počtu referencí řetězce 'Test!'.""" import sys # nová reference na řetězec x = "Test!" # počet referencí na řetězec 'Test!' print(sys.getrefcount(x))
Výsledek:
4
"""Zobrazení počtu referencí na malé celé číslo.""" import sys # nová reference na malé celé číslo (viz další text s vysvětlením) x = 10 # počet referencí na malé celé číslo print(sys.getrefcount(x))
Výsledek:
22
"""Zobrazení počtu referencí na hodnotu True.""" import sys # nová reference na hodnotu True (viz další text s vysvětlením) x = True # počet referencí na hodnotu True print(sys.getrefcount(x))
Výsledek:
149
"""Reference na seznam.""" import sys x = [] print(sys.getrefcount(x)) print(sys.getrefcount([]))
Výsledek:
2 1
"""Zobrazení počtu referencí na řetězec."""
import sys
# více referencí na řetězec
x = "Test!"
# počet referencí na řetězec 'Test!'
print(sys.getrefcount(x))
# více referencí na řetězec
y = [x, "Test!"]
# nový počet referencí na řetězec 'Test!'
print(sys.getrefcount(x))
del y[1]
# nový počet referencí na řetězec 'Test!'
print(sys.getrefcount(x))
del y[0]
# nový počet referencí na řetězec 'Test!'
print(sys.getrefcount(x))
x = None
# nový počet referencí na řetězec 'Test!'
print(sys.getrefcount("Test!"))
Výsledek:
4 6 5 4 3
"""Zobrazení počtu referencí na řetězec.""" import sys # více referencí na řetězec x = "Test!" print(x) # počet referencí na řetězec 'Test!' print(sys.getrefcount(x)) y = (x, x, x) print(y) # počet referencí na řetězec 'Test!' print(sys.getrefcount(x)) z = (y, y) print(z) # počet referencí na řetězec 'Test!' print(sys.getrefcount(x)) y = None z = None # nový počet referencí na řetězec 'Test!' print(sys.getrefcount(x))
Výsledek:
Test!
4
('Test!', 'Test!', 'Test!')
7
(('Test!', 'Test!', 'Test!'), ('Test!', 'Test!', 'Test!'))
7
4
"""Zobrazení počtu referencí na řetězec."""
import sys
# více referencí na řetězec
x = "Test!"
y = x
z = y
print(sys.getrefcount("foo"))
print(sys.getrefcount("Test!"))
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print(sys.getrefcount(z))
Výsledek:
3 6 6 6 6
"""Zobrazení počtu referencí na řetězec."""
import sys
def foo(ref):
print(sys.getrefcount(ref))
# reference na řetězec
x = "Test!"
print(sys.getrefcount(x))
# předání reference
foo(x)
Výsledek:
4 6
"""Zobrazení počtu referencí na řetězec."""
import sys
def foo(ref):
bar(ref)
def bar(ref):
print(sys.getrefcount(ref))
# reference na řetězec
x = "Test!"
print(sys.getrefcount(x))
# předání reference
foo(x)
Výsledek:
4 8
"""Reference na různé hodnoty."""
import sys
x = "foobar"
y = 0
z = True
w = None
l = []
print(sys.getrefcount("foo"))
print(sys.getrefcount("foobar"))
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print(sys.getrefcount(z))
print(sys.getrefcount(w))
print(sys.getrefcount(l))
print(sys.getrefcount([]))
Výsledek:
3 4 4 509 149 2150 2 1
"""Cyklické reference na různé hodnoty."""
import sys
import pprint
x = {}
y = {}
pprint.pprint(x)
pprint.pprint(y)
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print()
x["1"] = y
pprint.pprint(x)
pprint.pprint(y)
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print()
y["2"] = x
pprint.pprint(x)
pprint.pprint(y)
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print()
del x["1"]
pprint.pprint(x)
pprint.pprint(y)
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print()
del y["2"]
pprint.pprint(x)
pprint.pprint(y)
print(sys.getrefcount(x))
print(sys.getrefcount(y))
print()
Výsledek:
{}
{}
2
2
{'1': {}}
{}
2
3
{'1': {'2': <Recursion on dict with id=140094332450352>}}
{'2': {'1': <Recursion on dict with id=140094332450424>}}
3
3
{}
{'2': {}}
3
2
{}
{}
2
2
5. Automatická správa paměti v Pythonu
V Pythonu jsou objekty z operační paměti odstraňovány automaticky. Abychom činnost správce paměti pochopili, je nutné si znovu uvědomit, že pracujeme se dvěma skupinami struktur – se jmény a s objekty. Přitom již víme, že jménům není přiřazen typ hodnot, ovšem na druhou stranu je známý jejich rozsah platnosti (viditelnosti). Naproti tomu u objektů sice známe jejich typ a velikost, ovšem nikoli rozsah platnosti. Je tomu tak z toho důvodu, že na jeden objekt může existovat (a v naprosté většině případů taktéž existuje) větší počet referencí, takže rozsah platnosti objektu – tedy do jakého okamžiku je ještě objekt nutné držet v operační paměti – není možné zjistit jednoduše odvozením viditelnosti jména.
Tento problém je možné řešit mnoha různými správci paměti. V Pythonu nalezneme dva z nich. První typ správy paměti je založen na takzvaném počítání referencí (reference counting), což je velmi jednoduchý systém, který však má určité nedostatky zmíněné v navazující kapitole. Druhý typ správy paměti je založen na sledovacím (trasovacím) algoritmu, jenž ještě pro zvýšení své efektivity rozděluje objekty (zde myšleno ve smyslu hodnot uložených v paměti) do tří generací. Tento typ správce paměti bude zmíněn v sedmé kapitole.
6. Správa paměti založená na počítání referencí
Víme již, že v Pythonu se používají dva typy správců paměti (resp. uvolňovačů paměti). První z nich je založený na počítání referencí. U každého objektu se kromě vlastní hodnoty a typu ukládá i počet referencí, které na tento objekt ukazují. Ve chvíli, kdy nějaké jméno (typicky lokální proměnné, ovšem může se jednat i o výsledek příkazu del atd.) zanikne, počet referencí se sníží o jedničku. Jakmile dosáhne nuly, je možné objekt ihned uvolnit z paměti – vše je provedeno prakticky okamžitě (ovšem může se tím spustit kaskáda uvolňování, když například zaniká obsah celého seznamu nebo objekt).
Počítání referencí (reference counting) je implementačně značně jednoduchý a nabízí okamžité uvolňování paměti, takže se zdá, že se jedná o ideální způsob správy paměti. Ovšem nesmíme zapomenout i na některé jeho negativní vlastnosti:
- U objektů je nutné uchovávat další atribut, což zvyšuje nároky na obsazení paměti. A počitadlo se ukládá i u hodnot typu celé číslo atd., takže nárůst může být v některých případech obrovský.
- Každé přiřazení v programu modifikuje minimálně jedno počitadlo referencí, někdy i více (a += 1 mění počitadlo u dvou objektů – jedno snižuje a druhé zvyšuje!).
- Buď je nutné počitadlo modifikovat atomicky (náročné), nebo se vzdát možnosti souběžného použití více vláken. Ostatně právě existence reference countingu je jedním z důvodů, proč Python obsahuje a s velkou pravděpodobností i nadále bude obsahovat neslavně známý GIL – Global Interpreter Lock.
- Navíc nelze odstraňovat objekty s cyklickými referencemi. Většinou se nejedná o stav, kdy by objekt referencoval sám sebe, ale spíše se bude jednat o cyklus přes více objektů (zákazník je objekt referencující objekt typu Firma, Firma je objekt se seznamem zákazníků atd.)
Právě z toho důvodu, aby bylo možné detekovat i cyklické reference, obsahuje Python i takzvaný sledovací algoritmus zmíněný v navazující kapitole.
7. Sledovací algoritmus a rozdělení objektů do generací
Python, resp. přesněji řečeno jeho virtuální stroj, obsahuje i podporu pro uvolňování objektů, které se navzájem referencují. Tyto objekty jsou zpracovány takzvaným sledovacím algoritmem, který se u každého objektu pokusí zjistit, zda je dosažitelný přes alespoň jedno jméno s platnou oblastí viditelnosti. Tento algoritmus není spouštěn okamžitě, ale až ve chvíli, kdy je nutné uvolnit část haldy (a dokonce ho lze i zakázat zavoláním gc.disable() – což může být rozumná volba pro často spouštěné, ale jen krátkou dobu používané skripty). Teoreticky tento algoritmus začne v první fázi pracovat se slovníky obsahujícími aktuálně viditelná jména a následně prochází všechny přímo dostupné objekty, objekty referencované z těchto objektů atd. Každý takový objekt je označen příznakem. Ve fázi druhé jsou uvolněny ty objekty, které nejsou tímto příznakem označeny.
Ovšem takto pojatá správa paměti by nebyla příliš efektivní – obě fáze algoritmu by program zastavily na poměrně dlouhou dobu. Namísto toho se počítá s tím (jedná se o ověřený statistický fakt), že velké množství objektů má pouze krátkou životnost a naopak – čím vícekrát objekt „přežije“ zavolání výše popsaného algoritmu, tím větší je pravděpodobnost, že „přežije“ i volání následující. Z tohoto důvodu jsou objekty rozděleny do tří generací – každý (resp. prakticky každý) objekt je nejprve umístěn do první generace a pokud přežije několik běhů algoritmu pro vyčištění paměti, je převeden do generace druhé atd. Algoritmus se díky tomu většinou spouští pouze nad první generací, méně často nad druhou generací atd.
Počet cyklů nutných pro převedení objektu do další generace zjistíme funkcí get_threshold. Počet provedených kolekcí pro jednotlivé generace zjistíme funkcí get_stats:
"""Zjištění základních informací o správci paměti.""" import gc print(gc.get_threshold()) print(gc.get_stats())
Výsledky získané ihned po spuštění:
(700, 10, 10)
[{'collections': 17, 'collected': 92, 'uncollectable': 0},
{'collections': 1, 'collected': 7, 'uncollectable': 0},
{'collections': 0, 'collected': 0, 'uncollectable': 0}]
Spuštění algoritmu si můžete vynutit funkcí gc.collect(), které lze předat i číslo generace (0..2), které se má mark a sweep týkat.
8. Cache pro často používané objekty
Velmi často používané objekty (tedy hodnoty) jsou uloženy do cache. Konkrétně se to týká celočíselných hodnot v rozsahu od -5 do 257, které jsou interně uloženy do pole small_ints. Pokud v programovém kódu bude použito přiřazení takto malého čísla ke jménu, bude použit objekt z tohoto pole (a zvýší se počet jeho referencí):
>>> sys.getrefcount(1) 896 >>> x=1 >>> sys.getrefcount(1) 897 >>> y=x >>> sys.getrefcount(1) 898 >>> x=None >>> y=None >>> sys.getrefcount(1) 896
Objekty referencované na jména x a y jsou skutečně totožné:
>>> x=1 >>> y=1 >>> x is y True >>> id(x) 140520351155200 >>> id(y) 140520351155200
U větších hodnot není tento přístup použit – jsou vytvořeny dva nové objekty:
>>> x=6502 >>> y=6502 >>> x is y False >>> id(x) 139647346708048 >>> id(y) 139647346707792
9. „Interning“ řetězců
Ve skriptech psaných v Pythonu se velmi často používají řetězce, a to například i ve funkci klíčů ve slovnících atd. (je tomu tak z toho důvodu, že Pythonu chybí datový typ symbol). Aby bylo porovnávání řetězců rychlé, lze využít takzvaný „interning“, což znamená, že se řetězce se stejným obsahem uloží do paměti jen jedenkrát. Porovnání řetězce se v tomto případě může provést pouze porovnáním jeho adresy (hodnoty reference) a nikoli pracným porovnáváním znak po znaku. Interning existuje interní a externí.
Interní interning je proveden automaticky:
- U řetězců obsahujících jen jediný znak
- U starších verzí Pythonu (3.7) u vybraných řetězců do délky 20 znaků
- U novějších verzí Pythonu rozhoduje analýza AST a může se jednat o řetězce do délky 4096 znaků
- Jména tříd, proměnných atd. jsou „internována“ vždy
Explicitní interning lze vynutit zavoláním funkce sys.intern. Výsledkem je menší spotřeba paměti, rychlejší přístup k prvkům map atd., ovšem vlastní interning je časově náročná operace, takže se ne vždy musí vyplatit.
Podívejme se na situaci, kdy se interning automaticky neprovede:
import sys
last_letter = "d"
a = "Hello World"
b = "Hello Worl" + last_letter
print("The ID of a: {}".format(id(a)))
print("The ID of b: {}".format(id(b)))
print("a is b? {}".format(a is b))
Po spuštění skriptu uvidíme, že řetězce sice mají stejný obsah, ovšem jedná se o samostatné objekty (s rozdílnými referencemi), nikoli o shodné objekty:
The ID of a: 139719026913008 The ID of b: 139719026946224 a is b? False
Explicitně vynucený interning:
import sys
last_letter = "d"
a = sys.intern("Hello World")
b = sys.intern("Hello Worl" + last_letter)
print("The ID of a: {}".format(id(a)))
print("The ID of b: {}".format(id(b)))
print("a is b? {}".format(a is b))
Nyní existuje v paměti jediný řetězec referencovaný jmény a i b:
The ID of a: 140679980293936 The ID of b: 140679980293936 a is b? True
10. Prealokace paměti pro prvky seznamů a slovníků
Seznamy a slovníky slouží jako kontejnery pro uložení referencí na další objekty. Tyto reference poněkud nepřesně nazýváme prvky, i když skutečné hodnoty prvků nejsou přímo v těchto kontejnerech uloženy. Velmi často se setkáme s tím, že se prvky do seznamů a slovníků přidávají či naopak ubírají. Aby se zmenšil počet realokací paměti (a tím pádem i nutnosti přesunu celého kontejneru), jsou tyto kontejnery vytvořeny tak, aby mohly pojmout několik dalších prvků bez toho, aby bylo nutné při každém přidání realokaci použít. Toto chování si můžeme ověřit na jednoduchém příkladu, v němž začínáme s prázdným seznamem, do kterého postupně přidáváme další prvky:
import sys
l = []
for i in range(31):
print(len(l), sys.getsizeof(l))
l.append(i)
Po spuštění tohoto skriptu můžeme sledovat, jak se velikost paměti alokované pro seznam zvyšuje skokově a pouze ve chvíli, kdy je volná kapacita naplněna:
0 64 1 96 2 96 3 96 4 96 5 128 6 128 7 128 8 128 9 192 10 192 11 192 12 192 13 192 14 192 15 192 16 192 17 264 18 264 19 264 20 264 21 264 22 264 23 264 24 264 25 264 26 344 27 344 28 344 29 344 30 344
11. Uvolňování paměti při mazání prvků
Podobně jako kapacita seznamu skokově roste při přidávání prvků, bude se – opět na základě ověřeného algoritmu – seznam, resp. jeho volná kapacita, zmenšovat ve chvíli, kdy jsou z něho prvky ubírány. Ovšem vždy se počítá s tím, že prvky mohou být v dalším kroku i přidány, takže se udržuje určitá volná kapacita na konci seznamu. I toto chování si můžeme ověřit na demonstračním příkladu:
import sys
l = []
for i in range(31):
l.append(i)
for i in range(31):
print(len(l), sys.getsizeof(l))
del l[-1]
Můžeme vidět, že se při mazání prvků zpočátku udržuje původní kapacita (zhruba až na 1/2 zaplněnosti) a teprve poté dochází k realokaci seznamu v paměti:
31 344 30 344 29 344 28 344 27 344 26 344 25 344 24 344 23 344 22 344 21 344 20 344 19 344 18 344 17 344 16 256 15 256 14 256 13 256 12 256 11 208 10 208 9 208 8 160 7 160 6 160 5 128 4 128 3 112 2 104 1 96
12. Nástroj objgraph
Pro zobrazení vzájemných vztahů mezi jmény, referencemi a objekty lze použít až překvapivě propracovaný nástroj nazvaný příznačně objgraph. Tento nástroj se používá jako běžná knihovna programovacího jazyka Python a umožňuje v jakékoli chvíli získat informace o struktuře haldy (heapu), tj. jaké objekty a jakého typu jsou zde uloženy. Získat lze i další důležité informace, například o tom, které objekty byly vytvořeny v určitém časovém intervalu (mezi voláním dvou funkcí z knihovny) atd. Některé příklady použití objgraphu budou ukázány v navazujících kapitolách.
Nástroj objgraph umí kromě textových informací a tabulek zobrazovat i grafy se zvýrazněním referencí mezi objekty. Pro tento účel je použit balíček nástrojů nazvaný Graphviz. V tomto balíčku nalezneme především utilitu nazvanou dot, která na základě textové definice orientovaného či neorientovaného grafu vytvoří rastrový či vektorový obrázek s grafem, přičemž je možné si zvolit, jaký algoritmus bude použit pro rozmístění uzlů a hran na vytvořeném obrázku. Textová definice grafu používá jednoduchý popisný jazyk, který je v současnosti podporován i několika dalšími nástroji a stává se tak nepsaným standardem pro mnoho programů pracujících s grafovými strukturami. Pro utilitu Graphviz existuje i knihovna určená pro programovací jazyk Python – viz též https://pypi.org/project/graphviz/; tento balíček je používán i nástrojem objgraph.
13. Instalace nástroje objgraph
Samotná instalace nástroje objgraph je stejně snadná, jako instalace jakéhokoli jiného Pythonovského balíčku nabízeného přes Python Package Index. Instalaci můžeme provést pro celý systém:
# pip install objgraph Collecting objgraph Downloading https://files.pythonhosted.org/packages/a9/79/9f47706447b9ba0003c0680da4fed1d502adf410e1d953b4d1a5d3486640/objgraph-3.5.0-py2.py3-none-any.whl Collecting graphviz Downloading https://files.pythonhosted.org/packages/64/72/f4f4205db2a58e7a49e8190c0b49e9669d7ecadf6385b5bcdcf910354a6d/graphviz-0.15-py2.py3-none-any.whl Installing collected packages: graphviz, objgraph Successfully installed graphviz-0.15 objgraph-3.5.0
Nebo pro právě přihlášeného uživatele:
$ pip install objgraph
Ověření, že je balíček skutečně dostupný:
$ python3 Python 3.8.6 (default, Sep 25 2020, 00:00:00) [GCC 10.2.1 20200723 (Red Hat 10.2.1-1)] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import objgraph >>> help(objgraph)
Měla by se zobrazit nápověda:
Help on module objgraph:
NAME
objgraph - Tools for drawing Python object reference graphs with graphviz.
DESCRIPTION
You can find documentation online at https://mg.pov.lt/objgraph/
Copyright (c) 2008-2017 Marius Gedminas <marius@pov.lt> and contributors
Released under the MIT licence.
FUNCTIONS
at(addr)
Return an object at a given memory address.
The reverse of id(obj):
>>> at(id(obj)) is obj
True
Note that this function does not work on objects that are not tracked by
the GC (e.g. ints or strings).
14. Zobrazení grafu referencí
Pravděpodobně nejzajímavější funkcí nástroje objgraph je jeho schopnost zobrazit orientovaný graf s hranami vedoucími od zadaného jména (typicky jména proměnné nebo parametru funkce popř. metody) až po konkrétní hodnoty uložené v paměti (viz též druhou kapitolu):
Help on function show_refs in module objgraph:
show_refs(objs, max_depth=3, extra_ignore=(), filter=None, too_many=10, highlight=None, filename=None, extra_info=None, refcounts=False, shortnames=True, output=None, extra_node_attrs=None)
Generate an object reference graph starting at ``objs``.
The graph will show you what objects are reachable from ``objs``, directly
and indirectly.
``objs`` can be a single object, or it can be a list of objects. If
unsure, wrap the single object in a new list.
``filename`` if specified, can be the name of a .dot or a image
file, whose extension indicates the desired output format; note
that output to a specific format is entirely handled by GraphViz:
if the desired format is not supported, you just get the .dot
file. If ``filename`` and ``output`` is not specified, ``show_refs`` will
try to display the graph inline (if you're using IPython), otherwise it'll
try to produce a .dot file and spawn a viewer (xdot). If xdot is
not available, ``show_refs`` will convert the .dot file to a
.png and print its name.
``output`` if specified, the GraphViz output will be written to this
Podívejme se nyní na několik okomentovaných ukázek použití této užitečné funkce.
Proměnná z je referencí na řetězec, proto se při volání funkce show_refs vyhodnotí (a zobrazí asi něco jiného, než bychom očekávali):
"""Grafické zobrazení referencí.""" import objgraph x = "Foo" y = x z = y # zobrazení referencí vedoucích až na řetězec "Foo" objgraph.show_refs(z, filename='objgraph1.png')

Obrázek 2: Zobrazí se pouze přímo hodnota s řetězcem.
Zobrazit můžeme i objekty, které jsou referencovány ze seznamu:
"""Grafické zobrazení referencí.""" import objgraph x = "Foo" y = [x, "bar"] # zobrazení referencí ze seznamu y objgraph.show_refs(y, filename='objgraph2.png')
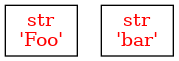
Obrázek 3: Zobrazí se pouze přímo hodnoty s řetězci.
Pokud chceme zobrazit, jaké hodnoty jsou dostupné (referencované) přímo ze seznamu y, musíme tento seznam umístit do složených závorek (předá se tak vlastně reference na seznam):
"""Grafické zobrazení referencí.""" import objgraph x = "Foo" y = [x, "bar"] # zobrazení referencí na dva řetězce uložené v seznamu objgraph.show_refs([y], filename='objgraph3.png')
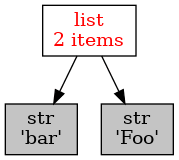
Obrázek 4: Hodnoty referencované ze seznamu y.
Již poněkud složitější hierarchie objektů uložených v operační paměti:
"""Grafické zobrazení referencí."""
import objgraph
x = "Foo"
y = [x, "bar", [x], (x, x), {"x":x}]
# reference u složitějších datových struktur
objgraph.show_refs([x, y], filename='objgraph4.png')
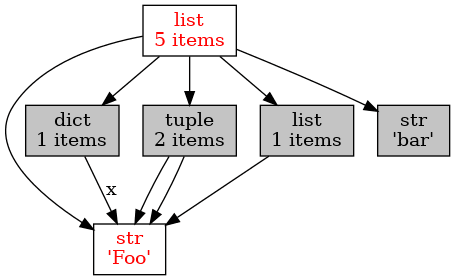
Obrázek 5: Složitější hierarchie hodnot uložených v operační paměti.
15. Cykly v grafu
Největší užitečnost funkce show_refs (vytvářející snadno pochopitelné grafy) se projeví ve chvíli, kdy je vzájemná provázanost mezi proměnnými (jmény) a hodnotami (objekty) složitější, popř. když obsahuje cykly. A dosažení cyklu je snadné – můžeme například použít dvojici slovníků, které na sebe navzájem odkazují:
"""Grafické zobrazení referencí."""
import objgraph
x = {}
y = {}
# prázdné slovníky
objgraph.show_refs([x, y], filename='objgraph5A.png')
x["1"] = y
# jedna reference
objgraph.show_refs([x, y], filename='objgraph5B.png')
y["2"] = x
# cyklická reference
objgraph.show_refs([x, y], filename='objgraph5C.png')
x["a"] = 10
x["b"] = True
x["c"] = False
x["d"] = None
y["a"] = False
y["b"] = True
y["c"] = False
y["d"] = None
# přidání dalších referencí
objgraph.show_refs([x, y], filename='objgraph5D.png')
Význam předchozího programového kódu je pravděpodobně zřejmý, takže se ihned podívejme, jaké grafy postupně vznikly:
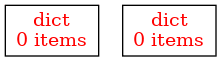
Obrázek 6: Dva prázdné slovníky na začátku skriptu.
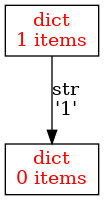
Obrázek 7: Prvek jednoho slovníku obsahuje referenci na druhý slovník.
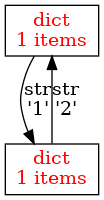
Obrázek 8: Vznik cyklu v grafu.
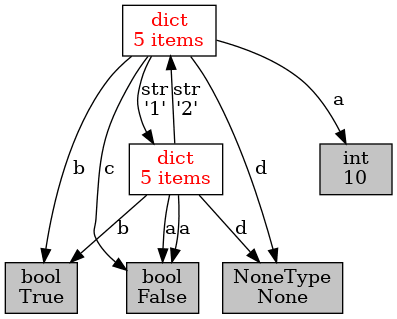
Obrázek 9: Přidáním dalších hodnot nic nemění na tom, že graf obsahuje cyklus (a tedy se musí použít složitější správce paměti).
Vztahy mezi referencemi a hodnotami mohou být i složitější, což je ukázáno na dalším demonstračním příkladu s trojicí slovníků, které se vzájemně referencují:
"""Grafické zobrazení referencí."""
import objgraph
x = {}
y = {}
z = {}
# cyklické reference N:N
x["->x"] = x
x["->y"] = y
x["->z"] = z
y["->x"] = x
y["->y"] = y
y["->z"] = z
z["->x"] = x
z["->y"] = y
z["->z"] = z
# graf s cyklickými referencemi
objgraph.show_refs([x, y, z], filename='objgraph6.png')
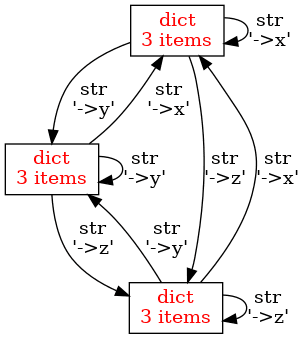
Obrázek 10: Tři slovníky, které se vzájemně referencují.
Prakticky téhož výsledku dosáhneme ve chvíli, kdy se vzájemně referencují objekty, resp. přesněji řečeno, když objekty obsahují atributy s referencemi na jiné objekty:
"""Grafické zobrazení referencí."""
import objgraph
class A():
def __init__(self, other):
self.other = other
# tři objekty, které na sebe navzájem ukazují
x = A(None)
y = A(x)
z = A(y)
x.other=z
# cyklické reference mezi objekty
objgraph.show_refs([x, y, z], filename='objgraph7.png')
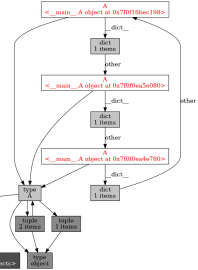
Obrázek 11: Tři objekty, které se vzájemně referencují.
Cyklus může vést i přes větší množství uzlů. V dalším demonstračním příkladu se jedná o šest uzlů:
"""Grafické zobrazení referencí."""
import objgraph
a = {}
b = {}
c = {}
d = {}
e = {}
f = {}
a["next"] = b
b["next"] = c
c["next"] = d
d["next"] = e
e["next"] = f
f["next"] = a
# cyklické reference mezi objekty
objgraph.show_refs([a, b, c, d, e, f], filename='objgraph8.png')
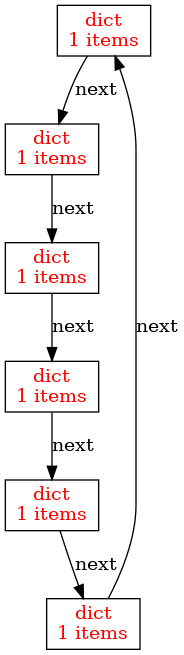
Obrázek 12: Cyklus, který vede přes šest uzlů.
A konečně, čistě jen jako demo, si ukažme reference na hodnoty získané z celého globálního prostoru (jmen, tedy referencí):
"""Grafické zobrazení referencí."""
import objgraph
x = {}
y = {}
# objekty z celého jmenného prostoru
objgraph.show_refs(globals(), filename='objgraph9.png')
S výsledkem:
Obrázek 13: Reference na hodnoty získané z celého globálního prostoru (jmen, tedy referencí).
16. Grafy se zpětným zjištěním referencí
V mnoha případech budeme potřebovat zjistit, jaké reference na daný objekt ukazují. K vizuálnímu zobrazení těchto vztahů (jméno→reference→objekt/hodnota) slouží funkce nazvaná show_backrefs:
Help on function show_backrefs in module objgraph:
show_backrefs(objs, max_depth=3, extra_ignore=(), filter=None, too_many=10, highlight=None, filename=None, extra_info=None, refcounts=False, shortnames=True, output=None, extra_node_attrs=None)
Generate an object reference graph ending at ``objs``.
The graph will show you what objects refer to ``objs``, directly and
indirectly.
``objs`` can be a single object, or it can be a list of objects. If
unsure, wrap the single object in a new list.
``filename`` if specified, can be the name of a .dot or a image
file, whose extension indicates the desired output format; note
that output to a specific format is entirely handled by GraphViz:
if the desired format is not supported, you just get the .dot
file. If ``filename`` and ``output`` are not specified, ``show_backrefs``
will try to display the graph inline (if you're using IPython), otherwise
it'll try to produce a .dot file and spawn a viewer (xdot). If xdot is
not available, ``show_backrefs`` will convert the .dot file to a
.png and print its name.
``output`` if specified, the GraphViz output will be written to this
Ukažme si nyní příklad použití této funkce.
"""Grafické zobrazení referencí.""" import objgraph x = "Foo" y = x z = y # zobrazení referencí na řetězec "Foo" objgraph.show_backrefs(x, filename='objgraph1_backrefs.png')
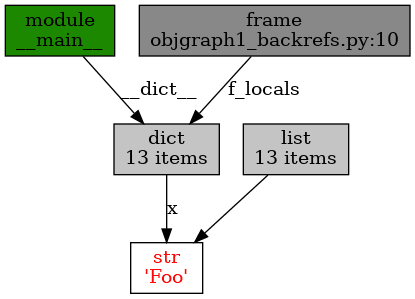
Obrázek 14: Zobrazení referencí na řetězec „Foo“.
"""Grafické zobrazení referencí.""" import objgraph x = "Foo" y = [x, "bar"] objgraph.show_backrefs(y, filename='objgraph2_backrefs.png')
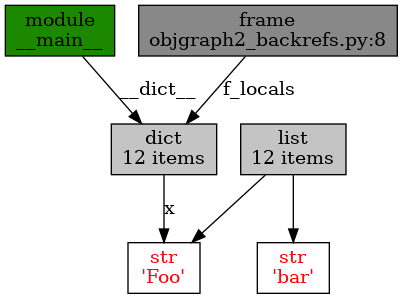
Obrázek 15: Zobrazení referencí na dva objekty referencované ze seznamu y.
"""Grafické zobrazení referencí.""" import objgraph x = "Foo" y = [x, "bar"] objgraph.show_backrefs([y], filename='objgraph3_backrefs.png')
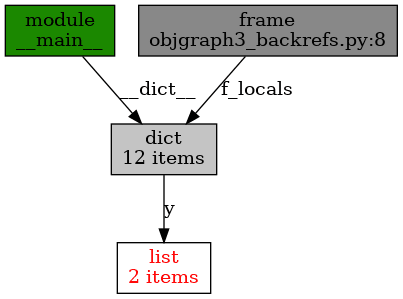
Obrázek 16: Zobrazení referencí na seznam y (nikoli na hodnoty referencované ze seznamu).
"""Grafické zobrazení referencí."""
import objgraph
x = "Foo"
y = [x, "bar", [x], (x, x), {"x":x}]
objgraph.show_backrefs([x, y], filename='objgraph4_backrefs.png')
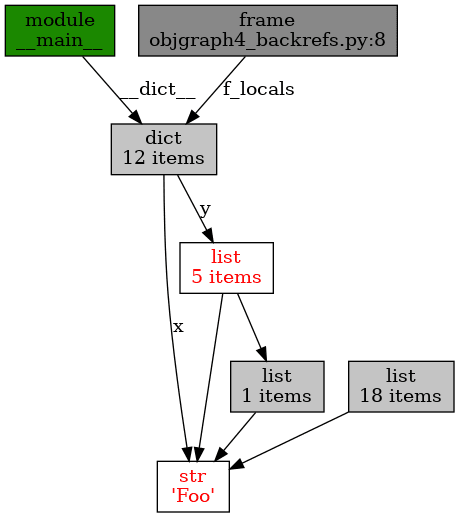
Obrázek 17: Reference na dva objekty – řetězec a seznam (graf není stromem, ovšem prozatím neobsahuje cyklus).
"""Grafické zobrazení referencí."""
import objgraph
x = {}
y = {}
# prázdné slovníky
objgraph.show_backrefs([x, y], filename='objgraph5A_backrefs.png')
x["1"] = y
# jedna reference
objgraph.show_backrefs([x, y], filename='objgraph5B_backrefs.png')
y["2"] = x
# cyklická reference
objgraph.show_backrefs([x, y], filename='objgraph5C_backrefs.png')
x["a"] = 10
x["b"] = True
x["c"] = False
x["d"] = None
y["a"] = False
y["b"] = True
y["c"] = False
y["d"] = None
# přidání dalších referencí
objgraph.show_backrefs([x, y], filename='objgraph5D_backrefs.png')
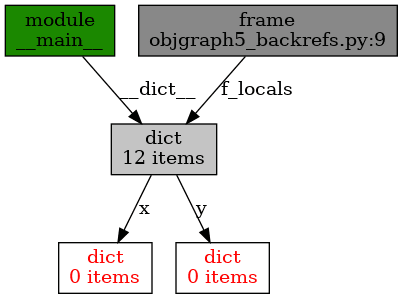
Obrázek 18: Postupná změna cyklu v grafu – prázdné slovníky.
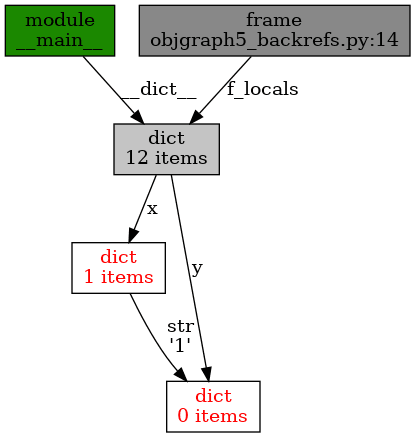
Obrázek 19: Postupná změna cyklu v grafu – první vazba mezi slovníky.
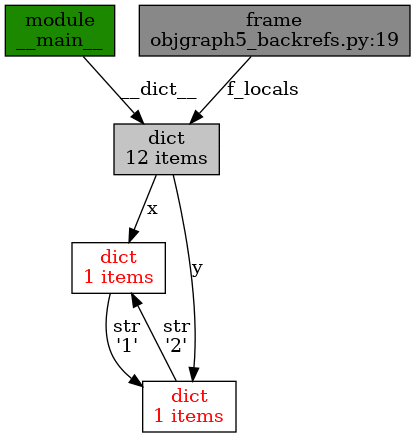
Obrázek 20: Postupná změna cyklu v grafu – druhá vazba mezi slovníky.
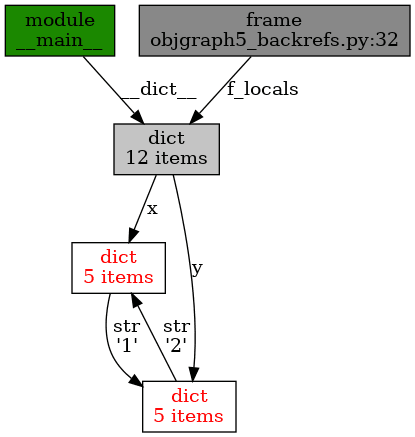
Obrázek 21: Postupná změna cyklu v grafu – přidání dalších hodnot.
"""Grafické zobrazení referencí."""
import objgraph
x = {}
y = {}
z = {}
# cyklické reference N:N
x["->x"] = x
x["->y"] = y
x["->z"] = z
y["->x"] = x
y["->y"] = y
y["->z"] = z
z["->x"] = x
z["->y"] = y
z["->z"] = z
# graf s cyklickými referencemi
objgraph.show_backrefs([x, y, z], filename='objgraph6_backrefs.png')
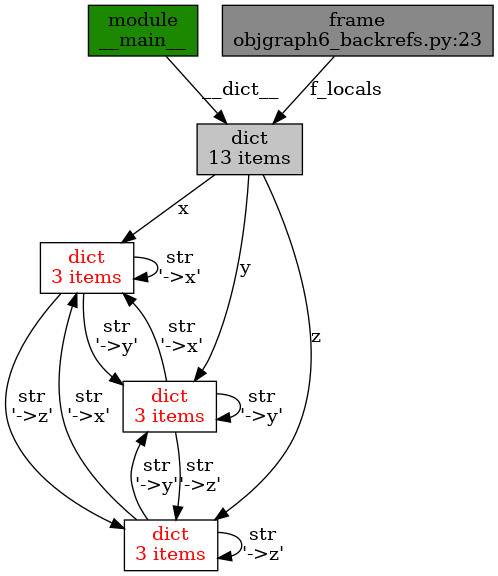
Obrázek 22: Vzájemné vazby mezi trojicí slovníků.
"""Grafické zobrazení referencí."""
import objgraph
class A():
def __init__(self, other):
self.other = other
# tři objekty, které na sebe navzájem ukazují
x = A(None)
y = A(x)
z = A(y)
x.other=z
# cyklické reference mezi objekty
objgraph.show_backrefs([x, y, z], filename='objgraph7_backrefs.png')
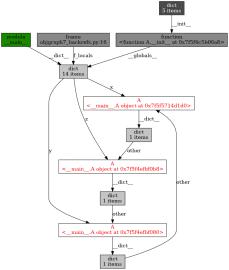
Obrázek 23: Vzájemné vazby mezi trojicí objektů svázaných přes atributy.
"""Grafické zobrazení referencí."""
import objgraph
a = {}
b = {}
c = {}
d = {}
e = {}
f = {}
a["next"] = b
b["next"] = c
c["next"] = d
d["next"] = e
e["next"] = f
f["next"] = a
# cyklické reference mezi objekty
objgraph.show_backrefs([a, b, c, d, e, f], filename='objgraph8_backrefs.png')
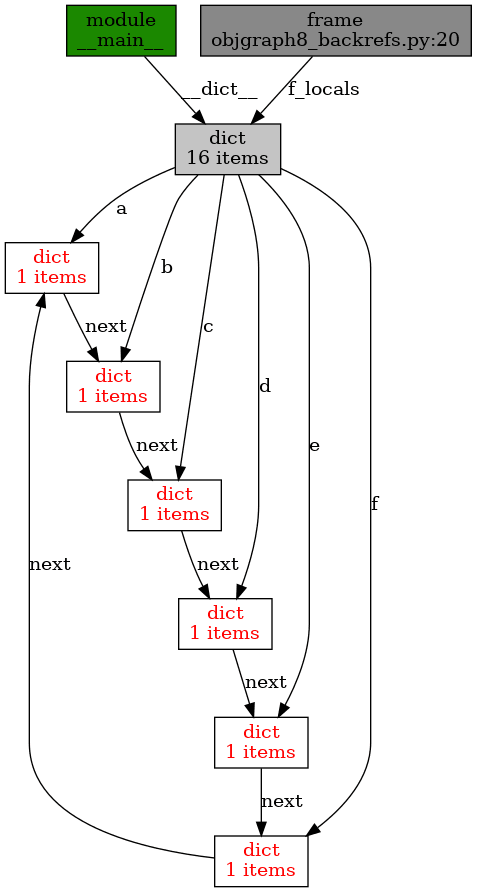
Obrázek 24: Cyklická vazba mezi šesticí slovníků.
17. Zjištění počtu objektů v paměti (podle jejich typu)
Užitečná je i funkce nazvaná show_growth nabízená knihovnou objgraph. Tato funkce zobrazí informace o tom, kolik objektů na haldě vzniklo od předchozího volání této funkce. Objekty jsou agregovány na základě svého typu, což například znamená, že všechny slovníky jsou reprezentovány jedním řádkem ve výsledku. Pokud je tato funkce volána periodicky, umožňuje sledovat, co přesně se na haldě děje:
Help on function show_growth in module objgraph:
show_growth(limit=10, peak_stats=None, shortnames=True, file=None, filter=None)
Show the increase in peak object counts since last call.
if ``peak_stats`` is None, peak object counts will recorded in
func `growth`, and your can record the counts by yourself with set
``peak_stats`` to a dictionary.
The caveats documented in :func:`growth` apply.
Example:
>>> show_growth()
wrapper_descriptor 970 +14
tuple 12282 +10
dict 1922 +7
...
.. versionadded:: 1.5
.. versionchanged:: 1.8
New parameter: ``shortnames``.
Podívejme se nyní na jednoduchý demonstrační příklad, v němž vytváříme nové objekty a mezi těmito operacemi voláme i funkci show_growth:
"""Zjištění počtu objektů v paměti."""
import objgraph
import queue
x = {}
y = {}
objgraph.show_growth()
print()
x["1"] = y
objgraph.show_growth()
print()
y["2"] = x
objgraph.show_growth()
print()
x = Exception()
y = queue.Queue()
z = queue.LifoQueue()
objgraph.show_growth()
print()
První volání vypíše stav na začátku programu a současně si tento stav zapamatuje (čítače počtu jednotlivých typů objektů):
function 2284 +2284 dict 1250 +1250 tuple 1020 +1020 wrapper_descriptor 998 +998 weakref 903 +903 method_descriptor 732 +732 builtin_function_or_method 703 +703 set 461 +461 getset_descriptor 410 +410 list 372 +372
Další volání po zápisu reference do prvního slovníku:
dict 1251 +1 list 373 +1
Třetí volání po zápisu reference do druhého slovníku:
dict 1252 +1
Vytvoření (konstrukce) tří dalších objektů, mj. i typu Exception, Queue a LifoQueue:
builtin_function_or_method 715 +12 deque 8 +7 dict 1258 +6 Condition 7 +6 list 374 +1 Exception 1 +1 Queue 1 +1 LifoQueue 1 +1
18. Sledování nově vytvořených objektů (podle typu)
Poslední funkcí, o níž se dnes zmíníme, je funkce nazvaná get_new_ids. Tato funkce zjistí a zobrazí počet nově vytvořených objektů, opět seskupených podle typu. Při prvním zavolání si funkce zapamatuje počty objektů, takže při dalším volání již dokáže zobrazit relativní přírůstky:
Help on function get_new_ids in module objgraph:
get_new_ids(skip_update=False, limit=10, sortby='deltas', shortnames=None, file=None, _state={})
Find and display new objects allocated since last call.
Shows the increase in object counts since last call to this
function and returns the memory address ids for new objects.
Returns a dictionary mapping object type names to sets of object IDs
that have been created since the last time this function was called.
``skip_update`` (bool): If True, returns the same dictionary that
was returned during the previous call without updating the internal
state or examining the objects currently in memory.
``limit`` (int): The maximum number of rows that you want to print
data for. Use 0 to suppress the printing. Use None to print everything.
``sortby`` (str): This is the column that you want to sort by in
descending order. Possible values are: 'old', 'current', 'new',
'deltas'
``shortnames`` (bool): If True, classes with the same name but
Ukažme si použití této funkce na jednoduchém příkladu:
"""Zjištění konstrukce objektů v paměti."""
import objgraph
x = {}
y = {}
objgraph.get_new_ids()
print()
x["1"] = y
objgraph.get_new_ids()
print()
y["2"] = x
objgraph.get_new_ids()
print()
Při prvním volání se zobrazí tato tabulka – vychází se z toho, že funkce si nezapamatovala předchozí hodnoty:
============================================================================== Type Old_ids Current_ids New_ids Count_Deltas ============================================================================== function 0 2262 +2262 +2262 dict 0 1243 +1243 +1243 tuple 0 1011 +1011 +1011 wrapper_descriptor 0 998 +998 +998 weakref 0 898 +898 +898 method_descriptor 0 732 +732 +732 builtin_function_or_method 0 703 +703 +703 set 0 461 +461 +461 getset_descriptor 0 406 +406 +406 list 0 371 +371 +371 ==============================================================================
Druhé volání ukazuje, že na haldě došlo ke změně:
====================================================================== Type Old_ids Current_ids New_ids Count_Deltas ====================================================================== set 461 797 +336 +336 list 371 372 +1 +1 dict 1243 1244 +1 +1 zipimporter 1 1 +0 +0 wrapper_descriptor 998 998 +0 +0 weakref 898 898 +0 +0 uname_result 1 1 +0 +0 type 296 296 +0 +0 staticmethod 39 39 +0 +0 property 120 120 +0 +0 ======================================================================
Třetí volání:
====================================================================== Type Old_ids Current_ids New_ids Count_Deltas ====================================================================== dict 1244 1245 +1 +1 zipimporter 1 1 +0 +0 wrapper_descriptor 998 998 +0 +0 weakref 898 898 +0 +0 uname_result 1 1 +0 +0 type 296 296 +0 +0 tuple 1010 1010 +0 +0 staticmethod 39 39 +0 +0 set 797 797 +0 +0 property 120 120 +0 +0 ======================================================================
Zajímavější bude zjistit, jak se změní počet objektů alokovaných v rámci jedné funkce – otestujeme tak, jestli se volá správce paměti či nikoli při opuštění funkce:
"""Zjištění konstrukce objektů v paměti."""
import objgraph
import queue
objgraph.get_new_ids()
def foo():
x = Exception()
y = queue.Queue()
z = queue.LifoQueue()
objgraph.get_new_ids()
foo()
objgraph.get_new_ids()
Zobrazení obsahu haldy po spuštění skriptu:
============================================================================== Type Old_ids Current_ids New_ids Count_Deltas ============================================================================== function 0 2284 +2284 +2284 dict 0 1251 +1251 +1251 tuple 0 1020 +1020 +1020 wrapper_descriptor 0 998 +998 +998 weakref 0 903 +903 +903 method_descriptor 0 732 +732 +732 builtin_function_or_method 0 703 +703 +703 set 0 461 +461 +461 getset_descriptor 0 410 +410 +410 list 0 372 +372 +372 ==============================================================================
Zjištění obsahu haldy uvnitř funkce s vytvořenými objekty:

============================================================================== Type Old_ids Current_ids New_ids Count_Deltas ============================================================================== set 461 797 +336 +336 builtin_function_or_method 703 715 +12 +12 dict 1251 1259 +8 +8 deque 1 8 +7 +7 Condition 1 7 +6 +6 list 372 374 +2 +2 function 2284 2285 +1 +1 frame 3 4 +2 +1 Queue 0 1 +1 +1 LifoQueue 0 1 +1 +1 ==============================================================================
A konečně poslední volání po opuštění funkce:
====================================================================== Type Old_ids Current_ids New_ids Count_Deltas ====================================================================== set 797 806 +9 +9 zipimporter 1 1 +0 +0 wrapper_descriptor 998 998 +0 +0 weakref 903 903 +0 +0 uname_result 1 1 +0 +0 type 301 301 +0 +0 tuple 1017 1017 +0 +0 staticmethod 39 39 +0 +0 property 120 120 +0 +0 partial 1 1 +0 +0 ======================================================================
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů určených pro Python 3 a nejnovější stabilní verzi knihovny Objgraph byly uloženy do Git repositáře dostupného na adrese https://github.com/tisnik/most-popular-python-libs. V případě, že nebudete chtít klonovat celý repositář (ten je ovšem stále velmi malý, dnes má velikost zhruba několik desítek kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:
20. Odkazy na Internetu
- objgraph 3.5.0 na PyPi
https://pypi.org/project/objgraph/ - Python Garbage Collection: What It Is and How It Works
https://stackify.com/python-garbage-collection/ - The Garbage Collector
https://pythoninternal.wordpress.com/2014/08/04/the-garbage-collector/ - Nástroje pro tvorbu grafů a diagramů z příkazové řádky
https://www.root.cz/clanky/nastroje-pro-tvorbu-grafu-a-diagramu-z-prikazove-radky/ - Graphviz – Graph Visualization Software
https://www.graphviz.org/ - Manuálová stránka nástroje Graphviz
https://www.root.cz/man/7/graphviz/ - Manuálová stránka nástroje dot
https://www.root.cz/man/1/dot/ - Graphviz na Wikipedii
https://en.wikipedia.org/wiki/Graphviz - Reference counting
https://en.wikipedia.org/wiki/Reference_counting - Tracing garbage collection
https://en.wikipedia.org/wiki/Tracing_garbage_collection - Generational GC (ephemeral GC)
https://en.wikipedia.org/wiki/Tracing_garbage_collection#Generational_GC_(ephemeral_GC) - Graphviz pro Python
https://graphviz.readthedocs.io/en/stable/examples.html - Memory Management in Python
https://www.slideshare.net/VijayKumarBagavathSi/memory-management-in-python - Memory Management In Python The Basics
https://www.slideshare.net/nnja/memory-management-in-python-the-basics - Python execution model
https://docs.python.org/3.8/reference/executionmodel.html - Guide to String Interning in Python
https://stackabuse.com/guide-to-string-interning-in-python/ - Python Names and Values
https://nedbatchelder.com/text/names1.html



































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU