Názory k článku Specifika instrukční sady mikroprocesorů Intel 8086/8088 (2)
-

Pěkně se ta série rozrůstá. :)
Opět nějaké opravy v textu:
* 3. Instrukce XLAT
Oprava:
Tato instrukce dokáže načíst hodnotu z adresy DS:[BX+AL] a uložit výsledek opět do registru AL.* 4. BCD aritmetika na čipech Intel 8086/8088
Oprava:
V tomto případě osmibitové registry obsahují buď pouze jednu cifru (tj. hodnotu 0–9 z možného rozsahu 0–256)* 7. Instrukce DAS po provedení operace rozdílu
Oprava: příklad používá instrukce "daa" místo "das"* 14. Varianty řetězcových a blokových operací
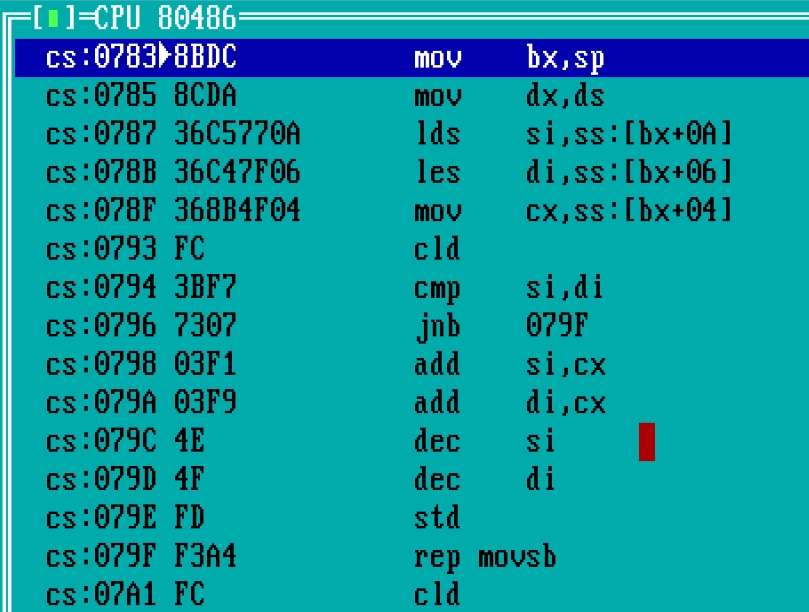
CLD nastaví příznak DF pro určení směru přenosu nahoru
STD nastaví příznak DF pro určení směru přenosu dolůV tabulce všude vypadly hranaté závorky s registry SI/DI, tj. DS:[SI] nebo ES:[DI]
* 15. Zápis několika po sobě jdoucích znaků do řetězce
Oprava:
- 4. Pětkrát zopakujeme instrukci STOSB, která vlastně provede mov ES:[DI], AL + inc DI [tedy DI, ne AL]* 16. Vylepšení předchozího příkladu: opakování instrukce STOSB CX-krát
Vloudila se vrána:
- 5. Spustíme instrukci REP STOSB, která vlastně CX-krák^H^H^H^Hkrát provede mov ES:[DI], AL + inc DI [opět ne AL]* Jako bonus, který z pochopitelných důvodů není uveden v článku, existuje "magická sekvence instrukcí", která z bytu (0-15) v AL vyrobí přímo ASCII kód odpovídající hexadecimální číslici ('0'-'F') v AL bez použití převodní tabulky:
add al,90h
daa
adc al,40h
daaOdvození jak to funguje ponechávám jako cvičení na laskavém čtenáři.
17. 9. 2024, 03:23 editováno autorem komentáře
-
 Pavel TišnovskýZlatý podporovatel
Pavel TišnovskýZlatý podporovatelZdravicko. Co je spatne s tim XLATem a chybejicimi zavorkami v tabulce? IMHO je to napsany dobre. Ostatni jsem opravil a doplnil, diky!
Jinak bonus: kdyby na to nekdo neprisel, proc to funguje, tak jsme to probirali v clancich o programovani ZX Spectra, tam je popsany priznaky v jednotlivych krocich atd. (bohudik ma Speccy taky ASCII, takze je to prenositelny).
-
V článku vidím toto:
"Tato instrukce dokáže načíst hodnotu z adresy DS a uložit výsledek opět do registru AL."DS je segmentový registr a bez offsetu ani netvoří kompletní adresu. Offset je tvořen součtem BX+AL, ale v článku to není. Bez této informace je funkce instrukce XLAT značně nejasná.
Tipuji, že redakční systém "sežral" celé hranaté závorky, protože podobně chybí i v jiných částech článku.
-
Pavel TišnovskýZlatý podporovatel
teď už je to snad ok. Tyjo na to si budu muset dát pozor při dalších článcích, kde se to asi adresama bude jen hemžit :-)
-

V článku je: "Tato instrukce dokáže načíst hodnotu z adresy DS a uložit výsledek opět do registru AL."
Ale ona dělá DS:[(E)BX + unsigned AL] => AL
Tzn. v tom textu není zmíněno nic o adresování pomocí BX a AL pouze o DS a stálo by zato to tam doplnit. Není to tam špatně, jen to tam není úplně přesně ;)
-
Pavel TišnovskýZlatý podporovatel
záhada je vyřešena - ten importér textů nemá rád zápis "něco:[něco]". Musel jsem před a za dvojtečku dát mezery, teď to prošlo.
(všude, i v té tabulce)mea culpa: já se díval na text v RedSysu, tam je to dobře, akorát po renderingu na Rootu už ne
@Petr Krčmář ^^^
-
Pavel TišnovskýZlatý podporovatel
tak snad opraveno. Co mě potěšilo - můj "master" text většinu těch chyb neobsahoval, akorát se prostě špatně importují zápisy "něco:[něco]", prostě zase byl počítač "chytřejší" než člověk :-)
-
Ty blokové operace byly v době vzniku fajn, ale jak to dokázaly využít tehdejší překladače. Třeba céčkové nebo Turbo/Borland Pascaly? Myslím tím knihovní funkce (tam asi jo) ale i rozpoznání, že programátor vlastně "matlá" třeba to STOSB nebo co já vím SCASB?
Protože pokud to překladače nevyužívaly, tak by to dost celou platformu táhlo dolů IMHO (ti si Intel zažil s dalšími architekturami, že?)
-
Pavel TišnovskýZlatý podporovatel
připomenu kód na kopírování obrázku z CS do video RAM. Máme něco jako:
org 0x100 ; zacatek kodu pro programy typu COM (vzdy se zacina na 256) start: gfx_mode 0x13 ; nastaveni rezimu 320x200 s 256 barvami grayscale_palette ; nastaveni palety se stupni sedi mov ax, cs mov ds, ax mov si, image ; nyni DS:SI obsahuje adresu prvniho bajtu v obrazku mov ax, 0xa000 ; video RAM v textovem rezimu mov es, ax xor di, di ; nyni ES:DI obsahuje adresu prvniho pixelu ve video RAM mov cx, 320*200/2 ; pocet zapisovanych bajtu (=pixelu) rep movsw ; prenos celeho obrazku wait_key ; cekani na klavesu exit ; navrat do DOSu ; pridani binarnich dat s rastrovym obrazkem image: incbin "image_320x200.bin"když se do CX hodí nula, nic se nezkopíruje
-
Pavel TišnovskýZlatý podporovatel
re segment: v reálném režimu je to pořád v rámci jednoho segmentu, takže MOVSW atd. má cenu jen pro CX<32768 (resp. mě nenapadá, kdyby bylo vhodnější použít větší CX)
-
Knihovní funkce MOVS / SCAS / LODS / STOS uměly využít dobře, ale Pascal skoro nic neoptimalizoval, překladač to nevyužil vůbec.
Zrovna Borland měl výbornou integraci ASM do Pascalu, stačilo kdekoliv napsat "asm ... end;" a vložit kousek kódu v assembleru nebo i celou funkci mít v asm.
V "C" bylo obdobně asm { ... };
-
Pavel TišnovskýZlatý podporovatel
jo no, co si clovek nenapsal sam v assmebleru, tak mel jen pomerne spatnej vyslednej strojak. Zkusim tady potom pastnout nejaky ukazky toho, co Turbo/Borland C/Pascal generoval (na druhou stranu ty IDE byly hodne dobry na svou dobu).
-
Podobně absurdně se tam pracovalo s FPU. Když jsem si poprvé pořídil koprocesor, chtěl jsem ho vyzkoušet, tak že jsem napsal prográmek, který celkem zobrazoval Juliovu množinu celkem naivním způsobem s počítáním ve floating point. Při přeložení bez/s použitím FPU tam skutečně nějaké zrychlení bylo, ale zdálo se mi, že ne dost velké.
Tak jsem se podíval na výsledný kód a zjistil, že každý výraz se počítá tak, že každá jednotlivá operace nejdřív zkopíruje argumenty do FP registrů, pak vykoná příslušnou intrukci a nakonec si přečte výsledek, bez ohledu na to, jestli ho opravdu potřebuje nebo jestli se jen hned použije pro další instrukci. A že pokud ano, tak ho tam prostě zase nakopíruje zpátky (klidně i do toho samého registru, ze kterého se právě přečetl). Pouhé přepsání vnitřní smyčky do příčetně vypadajícího assembleru program zrychlilo o dva až tři (desítkové) řády.
-
To je vejce a slepice - bylo to jednoduché, bo kompilátor byl úplně tupý a všechno měl v paměti. Takže assembler, aniž by mu rozuměl, nemohl nic rozbít (myšleno aktuální kontext registrů).
Dnešní kryptické zápisy jsou nutné, aby si kompilátor mohl udržet alokace registrů, které ten kousek assembleru nepoužije.
intrinsic jsou dalším krokem, sice s menší kontrolou, ale kompilátoru nechávají ještě větší volnost.
-
Pavel TišnovskýZlatý podporovatel
takze to spis byla vyhoda vice cest v procesoru (to jeste nebylo vice jader)?
protoze parovani asi bylo mozne, ale ze by to tak znevyhodnilo treba REP MOVSD?
(nic proti RISC, spis naopak)
17. 9. 2024, 12:28 editováno autorem komentáře
-
REP MOVS mělo v nejobecnější formě velkou režii pro malé ECX (<128) a pak pro větší ECX (>4096).
S předpokladem DF==0, ECX != 0 a ESI/EDI zarovnáno to šlo realizovat efektivněji.
Na Pentiu se pro memcpy běžně zneužívalo FILD/FISTP. Později pak MMX/SSE/AVX.Posledních 10 let Intel zapracoval a v MSROM má více variant mikrokódu pro REP MOVS i REP STOS.
Za běhu se podle DF, ECX a zarovnanosti ESI/EDI/ECX rozhodne pro nejefektivnější možnost.
Pro DF==1 je REP MOVS pomalejší (používá se pro memmove).Přítomnost "Enhanced REP MOVS/STOS" a "Fast short MOVS" lze zjistit z CPUID.
Jen REPE CMPS a REPNE SCAS zůstává stále bez optimalizací.
-
Nebyl důvod. Ty případy, kdy nelze použít knihovní funkci a zároveň se kód dá efektivně přeložit pomocí řetězcových instrukcí, jsou velice vzácné. To bylo největší zklamání při psaní v assembleru, když člověku došlo, že zrovna tady stosb a scasb použít nemůže, nebo ještě hůř, může, ale s ládováním segmentů a cld to bude delší, nedejbože pomalejší, než normálně.
-
nebyl důvod? co například takový memcpy, kde dopředu vím, že mám zarovnání, že mám správně nastavené segmenty, že se délka je dělitelná 2 nebo 4 atd. Nebo nějakou formu splitu, tedy čtení s "pokračováním", ale zápisem jinam.
a už vůbec asi překladače nedají tabulku rozeskoků, protože to nemá obdobu ve zdrojáku (myslím v DOSu, no možná později Watson něco dával)
-
Ano, nebyl důvod, na memcpy je v Turbo Pascalu procedura Move(). S tím splitem nevím. Ono by asi bylo efektivnější rozepsat split do dvou cyklů za sebou, ale pak by překladač musel kontrolovat, jestli na sebe cykly logicky navazují a nemusí se měnit ds:si a es:di, což by překladač komplikovalo, a to je v rozporu s cílem překládat rychle. Ale řek' bych, že pascalista by to spíš napsal do jednoho cyklu, ve kterém bude podmínka, jestli se ještě čte, nebo už zapisuje jinam.
-
procedura Move() nemuze byt nikdy tak rychla jako to, co si pro dany kontext napisu sam. Duvody byly zmineny: jen ja vim, jestli mam zarovnano, jen ja vim, jestli je ok provadet prenosy pres slova, jen ja vim, jestli jsou ok segmentove registry a DF priznak. Move() to nevi, takze to vsechno nastavi a bude kontrolovat furt dokola.
-
Pavel TišnovskýZlatý podporovatel
tady to mate, jak je implementovany move() v TP:
https://i.iinfo.cz/images/284/td.webp
(Necham na kazdem, jestli si mysli, ze je to skvely kod, nebo jestli to jde naprogramovat mnohem lip pro dany pripad. Ja mam jasno :-)
-
Původní otázka zněla, jestli překladače využívaly blokové operace, když to programátor namatlal. Delší dpověď zní nebylo potřeba, protože obyčejný programátor použil řetězcové funkce, chytrý programátor použil Move() nebo Fillchar() a asemblerista si to napsal sám a optimalizovat smatlaný kód by prodlužovalo překlad, o což nikdo ze tří zmíněných nestál.
Move() nikdy nemůže být tak rychlá jako vlastní kód, pokud zrovna nemusíš nastavovat DS, ES i DF a nebude se přenášet po bajtech. Ale i při letmém pohledu na knihovní funkce zjistíš, že na začátku rutiny, která používá blokové operace, bývá CLD nebo STD a na konci té, kde bylo STD, je poctivě CLD, čili jednoznačně upřednostnili robustnost před rychlostí.
-
Otázky byly dvě: jak to dokázaly využít tehdejší překladače. Myslím tím knihovní funkce (tam asi jo) ale i rozpoznání, že programátor vlastně "matlá" třeba to STOSB nebo co já vím SCASB?
A tedy odpovědi jsou:
1) knihovní funkce trošku ano, ale výsledek tedy není optimální (třeba to Move)
2) běžný kód (smyčka) se přeložila bez těchto operací (protože to Borlandi neuměli nebo nepovažovali za vhodné do toho investovat svoje prostředky)
3) a tedy assembler je vhodný v obou případech, když na tom záleží :-)Ten screenshot je z TD?
-
1. to teda sakra ano, v knihovních funkcích, kde to použít šlo, se to taky použilo. Move() je v TP odjakživa, takže ty suboptimality, o kterých je řeč, jsou způsobené spíš záměrnou blbuvzdorností.
2. Tato část dotazu mi přijde zajímavější. Poznat, že dejme tomu for i:=1 to 99 do a[i]:=i; je realizovatelné pomocí řetězcové instrukce, není úplně triviální a u většiny smyček beztak skončíme závěrem, že je marná snaha ji použít a plýtváme časem a ještě nafoukneme překladač. Z vlastní zkušenosti: stejný program překládal fortran na robotronu 1715 (sorry, že se to vůbec netýká specifik 8086), mnohem dýl než turbopascal, výsledek běžel zhruba stejně dlouho. Čili ta snaha turbopřekládat byla vidět.
3. Bavíme se o tom, jestli řetězcové instrukce využívaly překladače. Ne o tom, jestli je využívali assembleristi. Nevím jak v raných verzích MSC, ale inline assembler byl až v TP4. Do té doby inline($F3/$A4) {rep movsb} -
Pavel TišnovskýZlatý podporovatel
jj ta poznamka 2 je hodne dulezita, protoze se bavime o prekladaci pro pomaloucke 8088 bezici na 4,77 MHz, nebo o nejakem ATcku (286) na rekneme 16 MHz. Taky to melo tech slavnych 640kB RAM (zdravime Vilika), kam se muselo vejit cele IDEcko i prekladac (a mnohdy se prekladalo do pameti). Takze nejaky brutalne optimalizujici prekladac nehrozil. A az ty prisly (WatcomC), tak to chtelo 386 s megabajty pameti (tady mozna trosku kecam a mozna by to slo uskrtit i na 1MB, hmm schvalne vyzkousim).
-
Dodneska mne líbí, jak překladače realizují dělení konstantou pomocí instrukce násobení, protože dělení trvá déle
Třeba dělení deseti se řeší násobením čísla 6554 v 16bit systému
MOV AX,0x78 ;=120
IMUL 0x199A
DX=0x0C ;=12Na 386 se LEA se dala použít na násobení o různé konstanty
LEA AX,[AX+AX*2] - násobení 3x - pro RGB data .
-
Pavel TišnovskýZlatý podporovatel
jj LEA se na 386 (ale ne dřív) stala velmi užitečnou instrukcí (která vlastně byla použitelná na všechno možný, nejenom na loading adresy). Na 8086 ale byly možnosti omezené std.adresováním (jak jsme si ukázali minule).
-
Vymenit deleni za nasobeni neni az tak trivialni jak muze vypadat.
Vetsinou ti podminky umozni to nasobit s dvojnasobnou sirkou.
A na konci to nekdy musis posouvat o par bitu doprava.
Vse kvuli zaokrouhleni.
Nedavno jsem cetl nejaky par let stary clanek, ktery ukazoval, ze ani nejlepsi prekladace nenajdou vzdy nejlepsi reseni. A vysvetloval nejake podminky, za kterych to jde udelat lepe.
Pisi jako hobby projekt prekladac pro Z80 a deleni konstanotou je... PEKLO. Vetsina veci kde se objevi konstanta je tezka, ale deleni je extrem. I modulo je lehci i kdyz jsem dlouho nevedel ze to jde delat bez deleni.
Metod na ktere jsem prisel jak udelat deleni je nekolik a kazda ma svoje podvarianty a ty nikdy nevis, ktery kod pujde nejlepe optimalizovat a bude nakonec nejlepsi.Nasobit 6554? 16x16=32 bit...
To je zbytecne slozite (pokud procesor neumi nasobit).
U deleni 10 me nejlepe vychazi pouzit deleni 5. Protoze delit deseti je to same co "delit"dvema a pak deseti. Nebo naopak. Ale prvni se lepe optimalizuje, protoze mas uz zadarmo nasobek 2. Ktery vyuzijes protoze to prevadis na to nasobeni.
Deleni 5 se dela pres nasobeni 13107, ale drzi se to v 16x16=24 bit protoze se pouziva trik, ze ti staci to nasobit 51.
Osetrit zaokrouhleni.
A pak to vynasobit 257! 51*257=13107
A nasobeni 257 je brnkacka... protoze v ramci toho neustale to drzet na co nejmensim poctu bitu se to dela jako
(N*257)>>8
Takze ti staci hornich 8 bitu dat do spodnich a secist s puvodni hodnotou.A ted si vem ze najit tohle pro kazde cislo je dost prace... a stejne nevis zda to nejde lepe... i kdyz to delas rucne.
dworkin@dw-A15:~/repositories/M4_FORTH$ ./check_word.sh 'PUSH(10) UDIV' ;[32:185] 10 u/ Variant HL/10 = (HL/2)*(65536/5)/65536 = (HL/2)*51*257/65536 ld B, H ; 1:4 10 u/ ld C, L ; 1:4 10 u/ srl B ; 2:8 10 u/ rr C ; 2:8 10 u/ 1x base xor A ; 1:4 10 u/ inc BC ; 1:6 10 u/ +19 rounding constant add HL, BC ; 1:11 10 u/ adc A, A ; 1:4 10 u/ 3x AHL add HL, HL ; 1:11 10 u/ inc HL ; 1:6 10 u/ +8 rounding constant adc A, A ; 1:4 10 u/ 6x AHL add HL, HL ; 1:11 10 u/ adc A, A ; 1:4 10 u/ 12x AHL add HL, HL ; 1:11 10 u/ adc A, A ; 1:4 10 u/ 24x AHL add HL, BC ; 1:11 10 u/ adc A, 0x00 ; 2:7 10 u/ 25x AHL add HL, HL ; 1:11 10 u/ adc A, A ; 1:4 10 u/ 50x AHL add HL, BC ; 1:11 10 u/ adc A, 0x00 ; 2:7 10 u/ 51x AHL with rounding constant 26..35 ld B, A ; 1:4 10 u/ (AHL * 257) >> 16 = (AHL0 + 0AHL) >> 16 = AH.L0 + A.HL = A0 + H.L + A.H ld C, H ; 1:4 10 u/ BC = "A.H" add HL, BC ; 1:11 10 u/ HL = "H.L" + "A.H" ld L, H ; 1:4 10 u/ adc A, 0x00 ; 2:7 10 u/ + carry ld H, A ; 1:4 10 u/ HL/10 = (HL/2)*(65536/5)/65536 = (HL/2)*(1+256)*51 >> 16 ; seconds: 0 ;[32:185]Sorry, Z80 je trosku offtopic. .)
-
Nekde na netu jsem kdysi narazil na Pythoni script, ktery po zadani delitele projel definovany rozsah multiplikativnich konstant a k validnim konstantam vypsal tabulku potrebne bitove sirky multiplikace a posunu. Vicemene to vychazelo z HD ale tusim, ze tam bylo jeste rozsireni z nejakeho paperu (patrne rozsah multiplikantu, pokud nebylo potreba nasobit plny rozsah n-bitoveho registru). Ani to nebylo tak pomale.
Prekladac musi podporovat cely rozsah registru, takze generuje konstantu a posuv v dikci algoritmu z HD. -
Existuje na to třeba knihovna libdivide https://libdivide.com/ popř. stačí to dělení napsat do godbolta https://godbolt.org/z/MqoEW5abf
18. 9. 2024, 21:53 editováno autorem komentáře
-
Pouzivam kdyz zkoumam jak to na Z80 resi nejlepsi soucasny prekladac C. Tedy z88dk.
Ale ten vubec neumi delit konstantou.
Krome nasobku 2 a to jeste jen nejake nasobky dvou.
Konkretne umi delit beznamenkove inline 2, 4, 256 a 512.
Pak dokaze volat funkci pro bitovy posun pro deleni 8,16,32,64,128.
1024 a vyse uz radsi vola obecnou funkci pro deleni.Bojim se psat dal abych nebyl prilis kriticky... muselo to dat spoustu prace a je to zdarma.
Vcera jsem zkousel jak umi kopirovat 16 bitovou hodnotu z jednoho pointeru na druhy pointer.
void copypointer(int *adr1, int *adr2) { *adr2 = *adr1; }._copypointer ld hl,2 ;const call l_gintspsp ; ld hl,6 ;const add hl,sp call l_gint ; call l_gint ; pop de call l_pint rethttps://godbolt.org/z/fdxGKabfr
Kdyz si to projdete vcetne neukazanych pomocnych rutin tak ten kod vypada
._copypointer ld hl,2 ; 3:10 call l_gintspsp ; 3:17 .l_gintspsp add hl,sp ; 1:11 inc hl ; 1:6 inc hl ; 1:6 ld a,(hl) ; 1:7 inc hl ; 1:6 ld h,(hl) ; 1:7 ld l,a ; 1:4 ex (sp),hl ; 1:19 jp (hl) ; 1:4 ld hl,6 ; 3:10 add hl,sp ; 1:11 call l_gint ; 3:17 .l_gint ld a,(hl) ; 1:7 inc hl ; 1:6 ld h,(hl) ; 1:7 ld l,a ; 1:4 ret ; 1:10 call l_gint ; 3:17 .l_gint ld a,(hl) ; 0:7 inc hl ; 0:6 ld h,(hl) ; 0:7 ld l,a ; 0:4 ret ; 0:10 pop de ; 1:10 call l_pint ; 3:17 .l_pint ld a,l ; 1:4 ld (de),a ; 1:7 inc de ; 1:6 ld a,h ; 1:4 ld (de),a ; 1:7 ret ; 1:5 ret ; 1:5 ;[41:285]a rucne to jde napsat jako
ldi ; 2:16 __INFO [DE++] = [HL++], BC-- ldd ; 2:16 __INFO [DE--] = [HL--], BC-- ; seconds: 0 ;[ 4:32]HL a DE nebude zmeneno a BC se zmensi o 2.
Jde to napsat i hure, ale neverim ze kdokoliv by to napsal tak slozite jako neironicky opravdu nejlepsi prekladac C na Z80.
10x delsi kod a 9x pomalejsi.
K tomu ocekavejte ze vam to automaticky pribali ke kodu 4 kb asi pro runtime knihovnu. -
Na tohle tema jsem narazil na celkem citelny clanek i pro nematfyzaky na:
https://jk-jeon.github.io/posts/2023/08/optimal-bounds-integer-division/
kde popisuje postup a vysvetleni jednotlivych vet pomalu a srozumitelne s priklady..
Protoze koukani na https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8258644/table/tbl0010/?report=objectonly je proste pro nekoho chytrejsiho nez jsem ja.
Vlastne pekny clanek na deleni 10 na osmibitech je na
https://homepage.cs.uiowa.edu/~dwjones/bcd/decimal.html
Je tam popsana citelne dalsi zajimava metoda.
Ale je videt ze autor to nepsal pro Z80, ale obecne a vlastne cilil na nejlepsi algoritmus pro C.
Protoze kdyz se nakonec kouknete na to co zplodil, tak zjistite, ze v realu kdyz to budete psat v assembleru tak uplne prvni, primitivni varianta s postupnym prostym odcitani nasobku 10000,1000,100,10 je kratsi a asi i rychlejsi varianta, nez po celem tom usili vytvori on.
Ten kod i postup je inspirativni, ale...
Napriklad zkousi nasobit kratsi konstantou a pak resit korekci +1 z vypocitane chyby, protoze vysledek znovu nasobi 10. To je rychle, staci n*10 = n*2*5 = 2*(2*2*n + n).
Pouziva ale bitove posuny DOPRAVA o konstantu vetsi jak 1.
Naprosto NEPRIJATELNE pro 16 bitu na Z80.
Opakovane nasobeni 8*8=16 bitu atd.
C a assembler je proste jiny svet, na techto starych CICS procesorech.
8086 je o neco vic Pascal/C kompatibilni (predavani parametru pres zasobnik a neustala podpora rekurze at to stoji co to stoji), ale asi to take neni a uz nebude zadna slava, protoze je to davno zapomenuty procesor pro vetsinu modernich prekladacu. -
Jj, vypocty na 8bitech byly peklo. V drevnich dobach jsme se ucili zaklady DSP (zde P = processing) na pripravcich s 8051...
Pred 20 lety jsem presel na ARMy a tam treba na slabych Cortexech s jednocyklovou nasobickou, ale casove drahym delenim konci rychla konverze utoa treba takto:uint8_t * bin2dec(uint32_t u, uint8_t * dest) { uint8_t * d = dest; uint64_t r; if (u < 100UL) { /* 1 & 2 digits */ ECHO2DECDIGCOND(d, u) goto lm0; } else if (u < 1000000UL) { if (u < 10000UL) { /* 3 & 4 digits */ /* (100..9999) * (2^32 / 100) -> 2^32 / 100 = 42,949,672.96 -> 42,949,673 */ r = (uint64_t)u * 42949673UL; u = (uint32_t)(r >> 32U); ECHO2DECDIGCOND(d, u) d += 2UL; goto lm2; } else { /* 5 & 6 digits */ /* 10000..999999 * (2^32 / 10000) -> 2^32 / 10000 = 429,496.7296 -> 429,497 */ r = (uint64_t)u * 429497UL; u = (uint32_t)(r >> 32U); ECHO2DECDIGCOND(d, u) d += 4UL; goto lm4; } } else { if (u < 100000000UL) { /* 7 & 8 digits */ /* 1000000..99999999 * (2^32 / 1000000) -> 2^32 / 1000000 = 4,294.967296 -> 4,294 */ /* The multiplication precision is not sufficient */ /* 1000000..99999999 * (2^(32 + 16) / 1000000) -> 2^(32 + 16) / 1000000 = 281,474,976.710656 -> 281,474,977 */ r = ((uint64_t)u * 281474977UL) >> 16U; u = (uint32_t)(r >> 32U); ECHO2DECDIGCOND(d, u) d += 6UL; goto lm6; } else if (u <= 1160773632UL) { // 9 & 9+1/2 digits /* 100000000..4294967295 * (2^32 / 100000000) -> 2^32 / 100000000 = 42.94967296 -> 43 */ /* The multiplication precision is not sufficient */ /* 100000000..1160872980 * (2^(32 + 25) / 100000000) -> 2^(32 + 25) / 100000000 = 1,441,151,880.75855872 -> 1,441,151,882 ! */ // -> it works up to 1160872980 only! // For immediate comparison -> 1,160,773,632 <-> 0x45300000 11-bit value r = ((uint64_t)u * 1441151882UL) >> 25U; u = (uint32_t)(r >> 32U); ECHO2DECDIGCOND(d, u) goto lm8; } else { /* 10 digits */ /* 100000000..4294967295 * (2^32 / 100000000) -> 2^32 / 100000000 = 42.94967296 -> 43 */ /* The multiplication precision is not sufficient */ /* 100000000..4294967295 * (2^(32 + 25) / 100000000) -> 2^(32 + 25) / 100000000 = 1,441,151,880.75855872 -> 1,441,151,881 */ r = (uint64_t)u * 1441151881UL; u = (uint32_t)(r >> 57U); ECHO2DECDIGCOND(d, u) /* Fix back to 32-bit fraction */ r >>= 25U; goto lm8; } } lm8: r = (r & 0xFFFFFFFFUL) * 100UL; u = (uint32_t)(r >> 32U); ECHO2DECDIG(d - 8UL, u) d += 8UL; lm6: r = (r & 0xFFFFFFFFUL) * 100UL; u = (uint32_t)(r >> 32U); ECHO2DECDIG(d - 6UL, u) lm4: r = (r & 0xFFFFFFFFUL) * 100UL; u = (uint32_t)(r >> 32U); ECHO2DECDIG(d - 4UL, u) lm2: r = (r & 0xFFFFFFFFUL) * 100UL; u = (uint32_t)(r >> 32U); ECHO2DECDIG(d - 2UL, u) lm0: *d = 0U; return d; }To ECHO... makro neni nic jineho nez sahnuti do 200bajtove tabulky dvojic znaku. Cilem bylo zvolit takove multiplikativni konstanty, aby byly potreba 32bitove posuny, tj. zadne, takze to uint64_t je vicemene takova berlicka pro C.
-
Z hlediska instrukční sady mezi 8086 a 8088 není žádný rozdíl, 8088 je jen low end verze s užší datovou sběrnicí. To by bylo jako rozlišovat mezi instrukční sadou 386DX a 386SX, mezi kterými byl v podstatě stejný rozdíl.
8086 se určitě někde i používal, koneckonců 8088 přišel až později. To je otázka spíš pro pamětníky, tipoval bych, že spíš v dražších systémech, protože to vyžadovalo náročnější, a tedy dražší, základní desku. (Což byl ostatně důvod, proč ta 8088 vůbec vznikla.)
-
Pavel TišnovskýZlatý podporovatel
souhlas, 8086 okolo sebe potřeboval dražší čipovou sadu, složitější základní desku a tak.
-
Pavel TišnovskýZlatý podporovatel
je to tak, celý ten business okolo x86 má na svědomí právě 8088 a ne 8086 (https://www.root.cz/clanky/vyvoj-her-a-grafickych-dem-pro-oslavovanou-i-nenavidenou-platformu-pc-prvni-kroky/#k03)
Byl to poměrně dobrý výběr IBM, protože potom dokázali PC postavit nad levnými osmibitovými čipy (PC tehdy nemělo konkurenci ve strojích s 68k, takže to tak nebilo do očí :-)
-
Třeba v SAPI-86 / M3T330 (vyráběla Metra) byl originál i8086 a hned vedle prázdná zelená patice pro koprocesor.
PC XT určené pro průmysl, byla to taková stavebnice.
Backplane v bedně, všechny desky eurokarta 30x20cm s 2x DIN41612 konektorem.Na jedné desce byl procesor se základní pamětí 128kB.
Další deska přídavná paměť 512kB.
CGA deska.
Zvlášť řadič FDD, LPT a konektor pro klávesnici.
Speciální deska byl konvertor na krátkou ISA sběrnici. -
Pavel TišnovskýZlatý podporovatel
Potřebovali tam tu 86 kvůli nějakým 16bitovým IO zařízením? Za SAPI stál pan Starý že? (legenda)
-
K SAPI byly různé I/O desky, třeba s 8x 8255 a 64 libovolně programovatelnými vstupy/výstupy vyvedenými na konektory. Používala se na testování.
Byla k tomu dokonce i "síťovka" na koaxiál.
Na velké eurokarty se vešla spousta IO s nízkou integrací, snadno se pro to vyráběly periferie z tehdy dostupných součástek.
-
Pavel TišnovskýZlatý podporovatel
to jo, ale zrovna ty 8255 jsou osmibitové. ale asi k tomu byl důvod (bylo by zajímavý zjistit rozdíly v ceně 8086 a 8088).
-
Pavel TišnovskýZlatý podporovatel
eh ano byl, mě už neslouží paměť. Ano ano hmm hmm ... o čem jsme to mluvili? :-)





















{kind=link}