Vlákno názorů k článku Specifika instrukční sady mikroprocesorů Intel 8086/8088 (2) od atarist - Ty blokové operace byly v době vzniku fajn,...
-

Ty blokové operace byly v době vzniku fajn, ale jak to dokázaly využít tehdejší překladače. Třeba céčkové nebo Turbo/Borland Pascaly? Myslím tím knihovní funkce (tam asi jo) ale i rozpoznání, že programátor vlastně "matlá" třeba to STOSB nebo co já vím SCASB?
Protože pokud to překladače nevyužívaly, tak by to dost celou platformu táhlo dolů IMHO (ti si Intel zažil s dalšími architekturami, že?)
-
 Pavel TišnovskýZlatý podporovatel
Pavel TišnovskýZlatý podporovatelpřipomenu kód na kopírování obrázku z CS do video RAM. Máme něco jako:
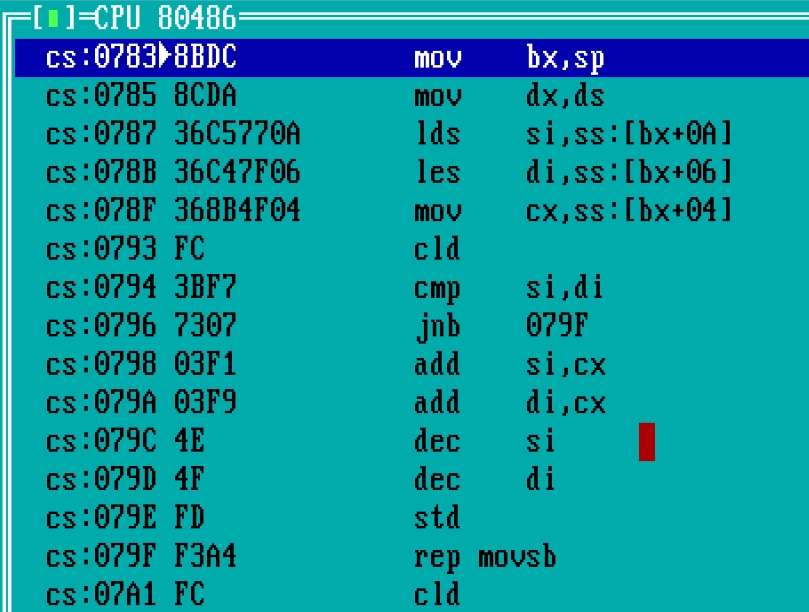
org 0x100 ; zacatek kodu pro programy typu COM (vzdy se zacina na 256) start: gfx_mode 0x13 ; nastaveni rezimu 320x200 s 256 barvami grayscale_palette ; nastaveni palety se stupni sedi mov ax, cs mov ds, ax mov si, image ; nyni DS:SI obsahuje adresu prvniho bajtu v obrazku mov ax, 0xa000 ; video RAM v textovem rezimu mov es, ax xor di, di ; nyni ES:DI obsahuje adresu prvniho pixelu ve video RAM mov cx, 320*200/2 ; pocet zapisovanych bajtu (=pixelu) rep movsw ; prenos celeho obrazku wait_key ; cekani na klavesu exit ; navrat do DOSu ; pridani binarnich dat s rastrovym obrazkem image: incbin "image_320x200.bin"když se do CX hodí nula, nic se nezkopíruje
-
Pavel TišnovskýZlatý podporovatel
re segment: v reálném režimu je to pořád v rámci jednoho segmentu, takže MOVSW atd. má cenu jen pro CX<32768 (resp. mě nenapadá, kdyby bylo vhodnější použít větší CX)
-
Knihovní funkce MOVS / SCAS / LODS / STOS uměly využít dobře, ale Pascal skoro nic neoptimalizoval, překladač to nevyužil vůbec.
Zrovna Borland měl výbornou integraci ASM do Pascalu, stačilo kdekoliv napsat "asm ... end;" a vložit kousek kódu v assembleru nebo i celou funkci mít v asm.
V "C" bylo obdobně asm { ... };
-
Pavel TišnovskýZlatý podporovatel
jo no, co si clovek nenapsal sam v assmebleru, tak mel jen pomerne spatnej vyslednej strojak. Zkusim tady potom pastnout nejaky ukazky toho, co Turbo/Borland C/Pascal generoval (na druhou stranu ty IDE byly hodne dobry na svou dobu).
-
Podobně absurdně se tam pracovalo s FPU. Když jsem si poprvé pořídil koprocesor, chtěl jsem ho vyzkoušet, tak že jsem napsal prográmek, který celkem zobrazoval Juliovu množinu celkem naivním způsobem s počítáním ve floating point. Při přeložení bez/s použitím FPU tam skutečně nějaké zrychlení bylo, ale zdálo se mi, že ne dost velké.
Tak jsem se podíval na výsledný kód a zjistil, že každý výraz se počítá tak, že každá jednotlivá operace nejdřív zkopíruje argumenty do FP registrů, pak vykoná příslušnou intrukci a nakonec si přečte výsledek, bez ohledu na to, jestli ho opravdu potřebuje nebo jestli se jen hned použije pro další instrukci. A že pokud ano, tak ho tam prostě zase nakopíruje zpátky (klidně i do toho samého registru, ze kterého se právě přečetl). Pouhé přepsání vnitřní smyčky do příčetně vypadajícího assembleru program zrychlilo o dva až tři (desítkové) řády.
-
To je vejce a slepice - bylo to jednoduché, bo kompilátor byl úplně tupý a všechno měl v paměti. Takže assembler, aniž by mu rozuměl, nemohl nic rozbít (myšleno aktuální kontext registrů).
Dnešní kryptické zápisy jsou nutné, aby si kompilátor mohl udržet alokace registrů, které ten kousek assembleru nepoužije.
intrinsic jsou dalším krokem, sice s menší kontrolou, ale kompilátoru nechávají ještě větší volnost.
-
Pavel TišnovskýZlatý podporovatel
takze to spis byla vyhoda vice cest v procesoru (to jeste nebylo vice jader)?
protoze parovani asi bylo mozne, ale ze by to tak znevyhodnilo treba REP MOVSD?
(nic proti RISC, spis naopak)
17. 9. 2024, 12:28 editováno autorem komentáře
-
REP MOVS mělo v nejobecnější formě velkou režii pro malé ECX (<128) a pak pro větší ECX (>4096).
S předpokladem DF==0, ECX != 0 a ESI/EDI zarovnáno to šlo realizovat efektivněji.
Na Pentiu se pro memcpy běžně zneužívalo FILD/FISTP. Později pak MMX/SSE/AVX.Posledních 10 let Intel zapracoval a v MSROM má více variant mikrokódu pro REP MOVS i REP STOS.
Za běhu se podle DF, ECX a zarovnanosti ESI/EDI/ECX rozhodne pro nejefektivnější možnost.
Pro DF==1 je REP MOVS pomalejší (používá se pro memmove).Přítomnost "Enhanced REP MOVS/STOS" a "Fast short MOVS" lze zjistit z CPUID.
Jen REPE CMPS a REPNE SCAS zůstává stále bez optimalizací.
-
Nebyl důvod. Ty případy, kdy nelze použít knihovní funkci a zároveň se kód dá efektivně přeložit pomocí řetězcových instrukcí, jsou velice vzácné. To bylo největší zklamání při psaní v assembleru, když člověku došlo, že zrovna tady stosb a scasb použít nemůže, nebo ještě hůř, může, ale s ládováním segmentů a cld to bude delší, nedejbože pomalejší, než normálně.
-
nebyl důvod? co například takový memcpy, kde dopředu vím, že mám zarovnání, že mám správně nastavené segmenty, že se délka je dělitelná 2 nebo 4 atd. Nebo nějakou formu splitu, tedy čtení s "pokračováním", ale zápisem jinam.
a už vůbec asi překladače nedají tabulku rozeskoků, protože to nemá obdobu ve zdrojáku (myslím v DOSu, no možná později Watson něco dával)
-
Ano, nebyl důvod, na memcpy je v Turbo Pascalu procedura Move(). S tím splitem nevím. Ono by asi bylo efektivnější rozepsat split do dvou cyklů za sebou, ale pak by překladač musel kontrolovat, jestli na sebe cykly logicky navazují a nemusí se měnit ds:si a es:di, což by překladač komplikovalo, a to je v rozporu s cílem překládat rychle. Ale řek' bych, že pascalista by to spíš napsal do jednoho cyklu, ve kterém bude podmínka, jestli se ještě čte, nebo už zapisuje jinam.
-
procedura Move() nemuze byt nikdy tak rychla jako to, co si pro dany kontext napisu sam. Duvody byly zmineny: jen ja vim, jestli mam zarovnano, jen ja vim, jestli je ok provadet prenosy pres slova, jen ja vim, jestli jsou ok segmentove registry a DF priznak. Move() to nevi, takze to vsechno nastavi a bude kontrolovat furt dokola.
-
Pavel TišnovskýZlatý podporovatel
tady to mate, jak je implementovany move() v TP:
https://i.iinfo.cz/images/284/td.webp
(Necham na kazdem, jestli si mysli, ze je to skvely kod, nebo jestli to jde naprogramovat mnohem lip pro dany pripad. Ja mam jasno :-)
-
Původní otázka zněla, jestli překladače využívaly blokové operace, když to programátor namatlal. Delší dpověď zní nebylo potřeba, protože obyčejný programátor použil řetězcové funkce, chytrý programátor použil Move() nebo Fillchar() a asemblerista si to napsal sám a optimalizovat smatlaný kód by prodlužovalo překlad, o což nikdo ze tří zmíněných nestál.
Move() nikdy nemůže být tak rychlá jako vlastní kód, pokud zrovna nemusíš nastavovat DS, ES i DF a nebude se přenášet po bajtech. Ale i při letmém pohledu na knihovní funkce zjistíš, že na začátku rutiny, která používá blokové operace, bývá CLD nebo STD a na konci té, kde bylo STD, je poctivě CLD, čili jednoznačně upřednostnili robustnost před rychlostí.
-
Otázky byly dvě: jak to dokázaly využít tehdejší překladače. Myslím tím knihovní funkce (tam asi jo) ale i rozpoznání, že programátor vlastně "matlá" třeba to STOSB nebo co já vím SCASB?
A tedy odpovědi jsou:
1) knihovní funkce trošku ano, ale výsledek tedy není optimální (třeba to Move)
2) běžný kód (smyčka) se přeložila bez těchto operací (protože to Borlandi neuměli nebo nepovažovali za vhodné do toho investovat svoje prostředky)
3) a tedy assembler je vhodný v obou případech, když na tom záleží :-)Ten screenshot je z TD?
-
1. to teda sakra ano, v knihovních funkcích, kde to použít šlo, se to taky použilo. Move() je v TP odjakživa, takže ty suboptimality, o kterých je řeč, jsou způsobené spíš záměrnou blbuvzdorností.
2. Tato část dotazu mi přijde zajímavější. Poznat, že dejme tomu for i:=1 to 99 do a[i]:=i; je realizovatelné pomocí řetězcové instrukce, není úplně triviální a u většiny smyček beztak skončíme závěrem, že je marná snaha ji použít a plýtváme časem a ještě nafoukneme překladač. Z vlastní zkušenosti: stejný program překládal fortran na robotronu 1715 (sorry, že se to vůbec netýká specifik 8086), mnohem dýl než turbopascal, výsledek běžel zhruba stejně dlouho. Čili ta snaha turbopřekládat byla vidět.
3. Bavíme se o tom, jestli řetězcové instrukce využívaly překladače. Ne o tom, jestli je využívali assembleristi. Nevím jak v raných verzích MSC, ale inline assembler byl až v TP4. Do té doby inline($F3/$A4) {rep movsb} -
Pavel TišnovskýZlatý podporovatel
jj ta poznamka 2 je hodne dulezita, protoze se bavime o prekladaci pro pomaloucke 8088 bezici na 4,77 MHz, nebo o nejakem ATcku (286) na rekneme 16 MHz. Taky to melo tech slavnych 640kB RAM (zdravime Vilika), kam se muselo vejit cele IDEcko i prekladac (a mnohdy se prekladalo do pameti). Takze nejaky brutalne optimalizujici prekladac nehrozil. A az ty prisly (WatcomC), tak to chtelo 386 s megabajty pameti (tady mozna trosku kecam a mozna by to slo uskrtit i na 1MB, hmm schvalne vyzkousim).
























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}