Názory k článku Specifika instrukční sady mikroprocesorů Intel 8086/8088 (3)
-

repne scasb
Na 486 clocks 7+5*n, * = 5 if n=0
(n = count of bytes, words or dwords)Hledani mezery v retezci...
To me pripomina ze pry existuje jazyk co ma nepocitane retezce... ze pry konci retezce hodnotou nula.
Coz znamena ze v dobe pred internetem kazdy objevoval kolo a resil jak ziskat co nejrychleji delku retezce, pokud s nim chtel delat neco vic nez tisknout.
A pro 486 nekdo vymyslel tohle...lea ecx, [eax - 0x01010101] ; Od kazdeho bajtu odecti 1 * not eax ; invertuj všechny bity v EAX and eax, ecx ; ** test eax, 0x80808080 ; Pokud je výsledek v nejvyšších bitech 1, je v některém bajtu nula jnz found_zero_byte ; Pokud některý bajt obsahuje nulu, jdi na found_zero_byte
* Pokud je nulovych bajtu vic, je zaruceno ze aspon v jednom bude FF.
** Co se stane kdyz odecteme od bajtu 1? Zmeni to nejnizsi jednickovy bit na nulu. A vsechny bity pod nim nastavi na 1.
Co se stane kdyz provedema AND s invertovanymi bity? Horni nulove a jednickove bity se nezmenily, takze kdyz byly nulove jsou jednickove po inverzi a kdyz byly jednickove jsou nulove po inverzi... takze AND je vsechny vynuluje. Ten nejnizsi jednickovy bit po inverzi je nula a stejne po odecteni je taky nula, takze "dvojnasobne" zaruceno ze po AND ziska hodnotu nula. Takze jednickove bity budou jen nejnizsi nulove. Tim je zaruceno ze pokud tam na zacatku bylo neco jineho nez 0 tak nejvyssi bit bude vzdy NULA.Ten kod ma clock 1-2 takty krome skoku na instrukci a prohledava 4 vetsi hodnotu nez 8 bitovy char.
Pokud se to neprovadi nad 10 znakovymi retezci tak je to rychlejsi. -

Tentokrát jen pár oprav:
1. Specifika instrukční sady mikroprocesorů Intel 8086/8088 (3)
CLD nastaví příznak DF pro určení směru přenosu (nahoru)
STD nastaví příznak DF pro určení směru přenosu (dolů)STOSB uložení bajtu z AL do ES : [DI], zvýšení/snížení DI o 1
STOSW uložení slova z AX do ES : [DI], zvýšení/snížení DI o 2MOVSB kombinace LODSB + STOSB v jediné instrukci (nemění AL)
MOVSW kombinace LODSW + STOSW v jediné instrukci (nemění AX)SCASW nalezení slova v AX na adrese DS : [SI] (mění příznaky)
9. Přenos po bajtech, 16bitových slovech nebo 32bitových slovech
Přenos rastrového obrázku (nebo libovolného jiného bloku) po bajtech již velmi dobře známe:
- následuje příklad přenosu po slovech (rep movsw)
Dám se teď od korektur
REP NOP... :o) -
 Pavel TišnovskýZlatý podporovatel
Pavel TišnovskýZlatý podporovateldik tusim vetsina opravena (krome prvnich dvou radku, to tam mam trosku naschval s tim priznakem)
-
Díky za další pootevření tajů 8086 pro mě. Musím říct, že jsem byl trochu v šoku. Ne z těch speciálních instrukcí - dávají smysl a je asi jasné, že budou rychlejší než ručně psané smyčky, proto v té instrukční sadě jsou. Ale v tom porovnání rychlostí mě šokovalo, co je začátek, co je ta základní hodnota, oproti které porovnáváme:
mov al, ds:[si] ; 12+5+2=19
Takže přesun bajtu z indexované adresy do registru AL trvá DEVATENÁCT cyklů? Mně vždycky přišlo, že PC hodně hučí, ale nikdy jsem nevěděl, že to je těmi poštovními holuby, co jim tam lítají... :)
-
Pavel TišnovskýZlatý podporovatel
no 8086 je v tomto šíleně pomalá. Každý výpočet efektivní adresy znamená:
base = 5
BP+DI nebo BX+SI = 7
BP+DI+disp nebo BX+SI+disp = 11
index = 5
BX+DI nebo BP+SI = 8
BX+DI+disp nebo BP+SI+disp = 12
disp = 6Navíc samotná MOV reg, mem je 12 cyklů samo o sobě (+ ten výpočet EA) a navíc segment override je další 2 cykly.
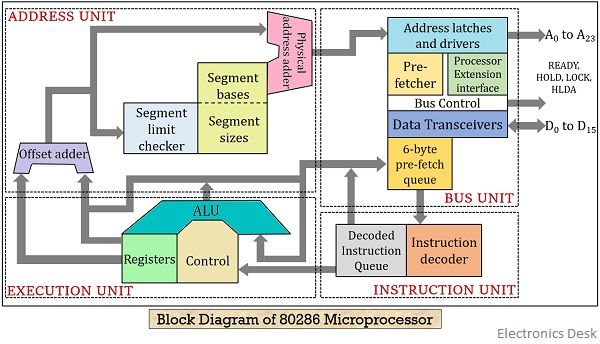
8086 totiž pro výpočet adresy musela používat klasickou ALU, neměla vlastní sčítačku. Kdežto u 286 už to bylo v pohodě, tam byl vlastní offset adder (a navíc ještě lepší dekodér instrukci) https://electronicsdesk.com/wp-content/uploads/2019/06/block-diagram-of-80286-microprocessor.jpg
-
Pavel TišnovskýZlatý podporovatel
jinak jsem se kdysi jako atarista (MOS 6502) jen smutne pousmal, kdyz jsem ty spousty cyklu u 8086 uvidel.
-
Díky moc za odpověď. Jelikož "pocházím" původně také od 8bit Atari, tak jsem se právě zděsil. Čekal jsem to u nějakých komplikovaných instrukcí nebo těch složenin (v jedné instrukci celá smyčka apod.). Obyčejné mov, ještě k tomu do registru... To už pak chápu, proč u M6502 někdo říkal, že vlastně z tohoto úhlu pohledu byla celá nultá stránka paměti 256 registrů.
Musím si někdy zjistit, jak to postupem let optimalizovali v dalších procesorech.
-
Pavel TišnovskýZlatý podporovatel
neni zac.
No optimalizace trvala par let, nez to dotahli, ale nakonec to bylo ok:
8088 186 286 386 486 Pentium 13+EA 9 3 2 1 1
Od 186 (tu jsem nikdy realne nemel v ruce) uz se nemusi pocitat ta efektivni adresa (EA) a nakonec od 486 uz je to pekne v jednom taktu a na Pentiu to snad i paruje
26. 9. 2024, 17:48 editováno autorem komentáře
-
Na novějších procesorech bylo AGU (adress generation unit), několik samostatných jednotek čistě pro výpočet adres, takže výpočet EA byl "zadarmo" paralelně s jinou činností CPU, neblokoval ALU a nepřidával žádný čas navíc.
Přes instrukci LEA jde AGU využít i k jednoduchým výpočtům.
Přístup do paměti taky není zadarmo. Interní L1 cache měla až 486 a L2 cache bývala SRAM v DIL pouzdrech na desce.
-
Pavel TišnovskýZlatý podporovatel
v mym pripade byla L2 cache "prazdnej" cip namisto realne cache. Dal se vytahnout a dokoupit si realnou pamet ;) Proste levna verze 486 ;)
-
Pavel TišnovskýZlatý podporovatel
Jinak takova POPa (od 186) si vezme peknych 56 cyklu.
Ale absolutne nejdelsi je IDIV s mem na 8086, ktera ma 171-190+EA, a to EA muze mit treba ES:[BP+SI+disp], coz je nejakych 14 cyklu navic. Takze klidne cele pres 200 cyklu.
-
Že budou takové instrukce, mě nepřekvapuje. Např. IDIV bych tak i čekal. Co mě šokovalo na tom mov, bylo to, že to není žádná komplikovaná složená instrukce, ale přesně ta samá, co na jiných CPU, konkrétně já to porovnávám samozřejmě s M6502. A to by přitom to měly být naprosto neporovnatelné procesory: zatímco 6502 je 8bitový procesor, a ještě k tomu záměrně vylevněný (vlastně zjednodušená 6800 kvůli ceně), tak 8086 je 16bitový procesor, základ platformy pro profesionálně používaná PC, na kterých poběží Quatro Pro, T602, One Half atp.
-
Nikdy jsem nepochopil tuhle fascinaci ataristu/commodoristu temi pocty taktu.
Kdyz si predstavis ze misto 1 cyklu trva vse 4 cykly, misto 2 cyklu trva 8 cyklu tak se dostanes na uroven Z80.Az na to ze ti diky tomu bezi CPU 4x "rychleji".
Stejne to bylo odvozeny od rychlosti ramky.
Vyhoda je... ze mas jemnejsi krokovani...
Nejaka instrukce ti muze bezet i 7 taktu (ld a,(hl)... misto 8 (muzes si predstavit 2).
Muze ti bezet 10 taktu jako pop hl misto 12 (muzes si predstavit 3).
Muze ti bezet 11 taktu jako push hl misto 12 (muzes si predstavit 3).A prave diky tomu jemnejsimu krokovani ti to v budoucnosti umozni delat ty optimalizace, kde se bude instrukce predzpracovavat ve fronte po castech, takze ti nakonec pobezi ten "1" takt, protoze predchozi 3 takty se provadeli soubezne. A ani se neda tvrdit ze je to neco co by stalo nejak moc kremiku navic... stejne se to musi nekde udelat. Navic mas jen zjisteni minimalni zavislosti.
Fakt je uplne jedno jestli ti bezi CPU na 1Mhz a rozplyvas se ze zvlada instrukci za takt... kdyz mas Hz na cpu schvalne zpomalene aby to tak vyslo.
A nebo ti bezi 3.5Mhz a nejrychlejsi je za 4 takty.Urcite je lepsi mit 486 na 80MHz s pomalym DIV nez na 1MHz a vsechny instrukce trvaji jeden takt (myslena stejna instrukcni sada i s DIV) jen pro ten pocit. Jeden takt jedna instrukce...
-
Na Pentiu MMX bylo výhodné kopírovat po 64bitech použitím FILD/FISTP.
Na 486 bylo FILD/FIST pomalé, konvertovalo int64 na float a zpět.Dnes se na memcpy běžně používá SSE/AVX.
Intel přesvědčuje k návratu na REP MOVS/STOS/CMPS/SCAS a do nových CPU přidal mnoho optimalizací:
Enhanced REP MOVSB / STOSB
Fast Zero Length REP MOVSB
Fast Short REP STOSB
Fast Short REP CMPSB / SCASBDostupnost optimalizací lze zjistit z flagu v CPUID.
-
Pěkný článek.
Zajímalo by mě, jak by se rychlosti REP MOVSx/STOSx změnily, kdyby průchod pamětí nebyl od adresy dělitelné 16, tak, jak to máš, ale od něčeho jako A000h:0003hRychlosti REP MOVSB, MOVSW a MOVSD by se z důvodu nezarovnaného přístupu do paměti srovnaly, nebo mají tato instrukce nějakou optimalizaci?























 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}