
Obsah
1. Trasování a ladění nativních aplikací v Linuxu: pokročilejší možnosti nabízené GNU Debuggerem
2. Ladění aplikací naprogramovaných v assembleru
3. Překlad aplikace v assembleru se zachováním ladicích informací
5. Načtení aplikace naprogramované v assembleru do GNU Debuggeru
6. Disassembler v GNU Debuggeru
7. Přepnutí režimu zobrazení instrukcí: syntaxe AT&T versus Intel
8. Nastavení breakpointů a krokování po instrukcích
9. Zobrazení obsahu pracovních registrů
10. Zobrazení obsahu vybrané části operační paměti
11. Formátování zobrazovaných dat
13. Praktický příklad a použití TUI
1. Trasování a ladění nativních aplikací v Linuxu: pokročilejší možnosti nabízené GNU Debuggerem
V předchozí části seriálu o trasování a ladění nativních aplikací jsme se seznámili se základními možnostmi a příkazy nabízenými GNU Debuggerem. Připomeňme si, že se jednalo například o příkaz list (zkráceně l) určený pro zobrazení zvolené části zdrojového kódu laděné aplikace, dále pak o práci s breakpointy (příkaz break, zkráceně b), krokování po jednotlivých řádcích či se vstupem do volané funkce (příkazy next a step) a v neposlední řadě taktéž o příkaz frame sloužící pro zobrazení vybraných zásobníkových rámců. Již s těmito několika příkazy, pokud se doplní o univerzální příkazy print, run a continue, je možné celkem bez větších problémů odladit i rozsáhlejší aplikaci naprogramovanou v nějakém vyšším programovacím jazyce (typicky v Céčku či C++). Ovšem ve chvíli, kdy nemáme k dispozici zdrojový kód (ladění některých ovladačů umístěných v blobech), chybí ladicí informace, popř. je aplikace naprogramovaná v assembleru, je nutné použít i některé další příkazy, s nimiž se seznámíme v dnešním článku.
2. Ladění aplikací naprogramovaných v assembleru
Aby bylo možné si vyzkoušet všechny dále popisované funkce nabízené GNU Debuggerem v praxi, vytvoříme si velmi jednoduchou aplikaci naprogramovanou v assembleru procesorů řady i386 či x86–64. Používat budeme pouze ty pracovní registry, které jsou kompatibilní s 32bitovou architekturou i386, což ostatně platí i pro volání funkcí Linuxového jádra. Aplikace je velmi jednoduchá a skládá se ze tří částí (ty by bylo možné rozepsat do subrutin či vkládaných maker, ovšem nebudeme aplikaci zbytečně komplikovat). V části první se v počítané programové smyčce vytvoří pole znaků od ‚a‘ do ‚z‘ (nejedná se přitom o klasický řetězec, protože pole nemusí být ukončeno znakem \0, to je jen konvence, kterou zde potřebovat nebudeme). V části druhé je výsledné pole vytištěno na standardní výstup s využitím syscallu sys_write. Část třetí pouze aplikaci korektně ukončí, a to opět s využitím syscallu, tentokrát syscallu nazvaného sys_exit. Vzhledem k tomu, že většina(?) programátorů, co pracují s assemblerem na procesorech řady i386 a x86–64, zná a preferuje Intel syntaxi, je celá aplikace napsána právě s využitím této syntaxe (viz zvýrazněná pseudoinstrukce, která syntaxi přepíná):
# asmsyntax=as
# Testovaci program naprogramovany v assembleru GNU as
# - pouzita je "Intel" syntaxe.
#
# Autor: Pavel Tisnovsky
.intel_syntax noprefix
# Linux kernel system call table
sys_exit=1
sys_write=4
#-----------------------------------------------------------------------------
.section .data
#-----------------------------------------------------------------------------
.section .bss
.lcomm buffer, 26 # rezervace bufferu pro vystup
#-----------------------------------------------------------------------------
.section .text
.global _start # tento symbol ma byt dostupny i linkeru
_start:
mov ecx, offset buffer # zapis se bude provadet do tohoto bufferu
mov al, 'a' # kod prvniho zapisovaneho znaku
loop:
mov [ecx], al # zapis znaku do bufferu
inc al # ASCII kod dalsiho znaku
inc ecx # uprava ukazatele do bufferu
cmp al, 'z' # ma se smycka ukoncit?
jna loop # pokud jsme neprekrocili kod 'z', opakovat smycku
mov eax, sys_write # cislo syscallu pro funkci "write"
mov ebx, 1 # standardni vystup
mov ecx, offset buffer # adresa retezce, ktery se ma vytisknout
mov edx, 26 # pocet znaku, ktere se maji vytisknout
int 0x80 # volani Linuxoveho kernelu
mov eax, sys_exit # cislo sycallu pro funkci "exit"
mov ebx, 0 # exit code = 0
int 0x80 # volani Linuxoveho kernelu
3. Překlad aplikace v assembleru se zachováním ladicích informací
Proces vytvoření spustitelného binárního souboru je rozdělen do dvou kroků. V kroku prvním se použije nástroj zvaný assembler (konkrétně GNU Assembler) pro vygenerování objektového kódu. Povšimněte si použití přepínače –gstabs+, který zajistí, že se do objektového kódu vloží i všechny symboly potřebné pro ladění a tudíž i pro GNU Debugger:
as --gstabs+ test.s -o test.o
Tyto symboly sice (mnohdy dosti podstatným způsobem) zvětšují velikost výsledného spustitelného souboru, ovšem na samotný výkon aplikace nemají větší vliv (tato část se ani nemusí načítat do operační paměti):
| Přeloženo | Velikost |
|---|---|
| bez ladicích symbolů | 1071 bajtů |
| s ladicími symboly | 1503 bajtů |
| po strip | 512 bajtů |
Pokud budete chtít později všechny ladicí informace odstranit, může se použít příkaz strip nebo alternativně provést nový překlad, tentokrát bez použití zmíněného přepínače. Po překladu následuje druhá fáze – slinkování. Tato fáze je v naší demonstrační aplikaci velmi jednoduchá, neboť není nutné ani spojit více objektových kódů, ani použít knihovnu (voláme totiž přímo funkce jádra):
ld test.o
Nyní si samozřejmě můžete program vyzkoušet:
./a.out abcdefghijklmnopqrstuvwxyz
4. Tabulka symbolů
Pokud vás zajímá, jak vypadá interní struktura vytvořeného spustitelného souboru a jaké (ladicí i jiné) symboly tento soubor obsahuje, můžete použít následující příkaz, který všechny potřebné informace dokáže získat a zobrazit v čitelné podobě. Nejzajímavější je v tomto okamžiku struktura nazvaná SYMBOL TABLE:
objdump -f -d -t -h a.out
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0x00000000004000b0
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000034 00000000004000b0 00000000004000b0 000000b0 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .bss 00000020 00000000006000e8 00000000006000e8 000000e8 2**3
ALLOC
2 .stab 000000d8 0000000000000000 0000000000000000 000000e4 2**2
CONTENTS, READONLY, DEBUGGING
3 .stabstr 0000001b 0000000000000000 0000000000000000 000001bc 2**0
CONTENTS, READONLY, DEBUGGING
SYMBOL TABLE:
00000000004000b0 l d .text 0000000000000000 .text
00000000006000e8 l d .bss 0000000000000000 .bss
0000000000000000 l d .stab 0000000000000000 .stab
0000000000000000 l d .stabstr 0000000000000000 .stabstr
0000000000000000 l df *ABS* 0000000000000000 test.o
0000000000000001 l *ABS* 0000000000000000 sys_exit
0000000000000004 l *ABS* 0000000000000000 sys_write
00000000006000e8 l O .bss 000000000000001a buffer
00000000004000b7 l .text 0000000000000000 loop
0000000000000000 l df *ABS* 0000000000000000
00000000004000b0 g .text 0000000000000000 _start
00000000006000e4 g .bss 0000000000000000 __bss_start
00000000006000e4 g .bss 0000000000000000 _edata
0000000000600108 g .bss 0000000000000000 _end
Disassembly of section .text:
00000000004000b0 <_start>:
4000b0: b9 e8 00 60 00 mov $0x6000e8,%ecx
4000b5: b0 61 mov $0x61,%al
00000000004000b7 <loop>;
4000b7: 67 88 01 mov %al,(%ecx)
4000ba: fe c0 inc %al
4000bc: ff c1 inc %ecx
4000be: 3c 7a cmp $0x7a,%al
4000c0: 76 f5 jbe 4000b7
4000c2: b8 04 00 00 00 mov $0x4,%eax
4000c7: bb 01 00 00 00 mov $0x1,%ebx
4000cc: b9 e8 00 60 00 mov $0x6000e8,%ecx
4000d1: ba 1a 00 00 00 mov $0x1a,%edx
4000d6: cd 80 int $0x80
4000d8: b8 01 00 00 00 mov $0x1,%eax
4000dd: bb 00 00 00 00 mov $0x0,%ebx
4000e2: cd 80 int $0x80
Při spuštění stejného příkazu, ovšem nad binárním souborem bez ladicích symbolů (po strip), bude výpis vypadat zcela jinak:
objdump -f -d -t -h a.out
a.out: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000102:
EXEC_P, D_PAGED
start address 0x00000000004000b0
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000034 00000000004000b0 00000000004000b0 000000b0 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .bss 00000020 00000000006000e8 00000000006000e8 000000e8 2**3
ALLOC
SYMBOL TABLE:
no symbols
Disassembly of section .text:
00000000004000b0 <.text>:
4000b0: b9 e8 00 60 00 mov $0x6000e8,%ecx
4000b5: b0 61 mov $0x61,%al
4000b7: 67 88 01 mov %al,(%ecx)
4000ba: fe c0 inc %al
4000bc: ff c1 inc %ecx
4000be: 3c 7a cmp $0x7a,%al
4000c0: 76 f5 jbe 0x4000b7
4000c2: b8 04 00 00 00 mov $0x4,%eax
4000c7: bb 01 00 00 00 mov $0x1,%ebx
4000cc: b9 e8 00 60 00 mov $0x6000e8,%ecx
4000d1: ba 1a 00 00 00 mov $0x1a,%edx
4000d6: cd 80 int $0x80
4000d8: b8 01 00 00 00 mov $0x1,%eax
4000dd: bb 00 00 00 00 mov $0x0,%ebx
4000e2: cd 80 int $0x80
Alternativně si můžete zobrazit všechny řetězce, mezi nimiž lze nalézt jak jména jednotlivých sekcí (.text, .bss), tak i návěští (_start, loop) i pojmenované symboly (sys_write, sys_exit):
strings a.out test.s /home/tester/temp/ .symtab .strtab .shstrtab .text .bss .stab .stabstr test.o sys_exit sys_write buffer loop _start __bss_start _edata _end
5. Načtení aplikace naprogramované v assembleru do GNU Debuggeru
Následně se můžeme pokusit o jeho analýzu, krokování a ladění naší testovací aplikace přímo v prostředí GNU Debuggeru, popř. v jeho TUI (textovém uživatelském rozhraní). GNU Debugger spustíme obvyklým způsobem, který již známe z předchozí části tohoto seriálu:
gdb a.out
Důležité je, aby se na posledním řádku úvodní zprávy GNU Debuggeru vypsala informace o tom, že se úspěšně načetly všechny ladicí informace:
GNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1 Copyright (C) 2014 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word"... Reading symbols from a.out...done.
Pokud se pouze zobrazí následující zprávy:
GNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1 Copyright (C) 2014 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word"... Reading symbols from a.out...(no debugging symbols found)...done.
… znamená to, že assembler do objektového kódu nepřidal ladicí symboly, došlo k jejich odstranění při linkování, nebo byl použit příkaz strip, který tyto symboly odstranil kdykoli později. Samozřejmě je možné ladit a krokovat i program bez přidaných ladicích symbolů (někdy je to dokonce nutné), celý postup je však nepatrně složitější, protože se například ztratí informace o všech návěštích (labels), jménech volaných subrutin apod.
6. Disassembler v GNU Debuggeru
Při práci na úrovni jednotlivých instrukcí velmi často využijeme příkaz disassemble, který lze zkrátit například na disas (ještě kratší zápis již nelze použít, neboť by jméno příkazu kolidovalo s příkazem disable). Za příkazem disassemble je možné uvést návěští, například:
(gdb) disassemble _start Dump of assembler code for function _start: 0x00000000004000b0 <+0>: mov $0x6000e8,%ecx 0x00000000004000b5 <+5>: mov $0x61,%al End of assembler dump.
nebo:
(gdb) disassemble loop Dump of assembler code for function loop: 0x00000000004000b7 <+0>: mov %al,(%ecx) 0x00000000004000ba <+3>: inc %al 0x00000000004000bc <+5>: inc %ecx 0x00000000004000be <+7>: cmp $0x7a,%al 0x00000000004000c0 <+9>: jbe 0x4000b7 <loop> 0x00000000004000c2 <+11>: mov $0x4,%eax 0x00000000004000c7 <+16>: mov $0x1,%ebx 0x00000000004000cc <+21>: mov $0x6000e8,%ecx 0x00000000004000d1 <+26>: mov $0x1a,%edx 0x00000000004000d6 <+31>: int $0x80 0x00000000004000d8 <+33>: mov $0x1,%eax 0x00000000004000dd <+38>: mov $0x0,%ebx 0x00000000004000e2 <+43>: int $0x80
Povšimněte si výchozího režimu výpisu. Na začátku každého řádku je adresa, následuje relativní offset od první adresy (z něj lze získat představu o délce instrukce) a poté následuje symbolický kód: mnemotechnické jméno instrukce a její případné operandy. Mimochodem – ona adresa první instrukce 0×00000000004000b0 byla vypsána (a dokonce dvakrát) ve výstupu programu objdump, takže vidíme, že GNU Debugger skutečně „nekecá“:
...
...
...
start address 0x00000000004000b0
...
...
...
0 .text 00000034 00000000004000b0 00000000004000b0 000000b0 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
...
...
...
Samozřejmě je stále možné použít i příkaz list, který známe z předchozí části:
(gdb) list loop 31 32 _start: 33 mov ecx, offset buffer # zapis se bude provadet do tohoto bufferu 34 mov al, 'a' # kod prvniho zapisovaneho znaku 35 loop: 36 mov [ecx], al # zapis znaku do bufferu 37 inc al # ASCII kod dalsiho znaku 38 inc ecx # uprava ukazatele do bufferu 39 cmp al, 'z' # ma se smycka ukoncit? 40 jna loop # pokud jsme neprekrocili kod 'z', opakovat smycku
7. Přepnutí režimu zobrazení instrukcí: syntaxe AT&T versus Intel
Pokud se pečlivěji podíváte na výstup z disassembleru, zjistíte, že operandy instrukcí příliš neodpovídají původnímu zdrojovému kódu:
(gdb) disassemble loop Dump of assembler code for function loop: 0x00000000004000b7 <+0>: mov %al,(%ecx) 0x00000000004000ba <+3>: inc %al 0x00000000004000bc <+5>: inc %ecx 0x00000000004000be <+7>: cmp $0x7a,%al 0x00000000004000c0 <+9>: jbe 0x4000b7 <loop> 0x00000000004000c2 <+11>: mov $0x4,%eax 0x00000000004000c7 <+16>: mov $0x1,%ebx 0x00000000004000cc <+21>: mov $0x6000e8,%ecx 0x00000000004000d1 <+26>: mov $0x1a,%edx 0x00000000004000d6 <+31>: int $0x80 End of assembler dump.
V původním zdrojovém kódu jsme ovšem používali Intel syntaxi:
loop:
mov [ecx], al # zapis znaku do bufferu
inc al # ASCII kod dalsiho znaku
inc ecx # uprava ukazatele do bufferu
cmp al, 'z' # ma se smycka ukoncit?
jna loop # pokud jsme neprekrocili kod 'z', opakovat smycku
mov eax, sys_write # cislo syscallu pro funkci "write"
mov ebx, 1 # standardni vystup
mov ecx, offset buffer # adresa retezce, ktery se ma vytisknout
mov edx, 26 # pocet znaku, ktere se maji vytisknout
int 0x80 # volani Linuxoveho kernelu
Bylo by tedy dobré stejnou syntaxi používat i v GNU Debuggeru. To je skutečně možné, protože každá moderní varianta GNU Debuggeru nabízí následující volbu pro přepnutí režimu disassembleru:
set disassembly-flavor intel
Nyní již výstup disassembleru vypadá lidštěji:
(gdb) disassemble loop Dump of assembler code for function loop: 0x00000000004000b7 <+0>: mov BYTE PTR [ecx],al 0x00000000004000ba <+3>: inc al 0x00000000004000bc <+5>: inc ecx 0x00000000004000be <+7>: cmp al,0x7a 0x00000000004000c0 <+9>: jbe 0x4000b7 <loop> 0x00000000004000c2 <+11>: mov eax,0x4 0x00000000004000c7 <+16>: mov ebx,0x1 0x00000000004000cc <+21>: mov ecx,0x6000e8 0x00000000004000d1 <+26>: mov edx,0x1a 0x00000000004000d6 <+31>: int 0x80 End of assembler dump.
Poznámka: instrukce jbe („jump if below or equal“) je totožná s instrukcí jna („jump if not above“) a disassembler samozřejmě neví, kterou variantu jsme použili v původním zdrojovém kódu.
8. Nastavení breakpointů a krokování po instrukcích
Práce s breakpointy se při ladění aplikací na úrovni strojových instrukcí prakticky vůbec neliší od ladění aplikací naprogramovaných v nějakém vyšším programovacím jazyku. Breakpoint lze nastavit na konkrétní instrukci, návěští (což je pravděpodobně nejpoužívanější způsob), nebo na konkrétní adresu. Následují příklady na nastavení breakpointů:
(gdb) break 1 Breakpoint 2 at 0x4000b0: file test.s, line 1. (gdb) break 10 Note: breakpoint 2 also set at pc 0x4000b0. Breakpoint 3 at 0x4000b0: file test.s, line 10. (gdb) break loop Breakpoint 1 at 0x4000b7: file test.s, line 36.
Seznam všech breakpointů se získá příkazem info break:
(gdb) info break
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000004000b7 test.s:36
breakpoint already hit 4 times
2 breakpoint keep y 0x00000000004000b0 test.s:1
3 breakpoint keep y 0x00000000004000b0 test.s:10
4 breakpoint keep y 0x00000000004000b7 test.s:36
Podívejme se nyní na způsob použití breakpointů. Předpokládejme nastavení jediného breakpointu na návěští loop:
(gdb) clear 1 Deleted breakpoint 5 (gdb) clear 10 Deleted breakpoint 6 (gdb) clear loop Deleted breakpoint 7 (gdb) break loop Breakpoint 8 at 0x4000b7: file test.s, line 36.
Po spuštění programu se jeho běh podle očekávání zastaví na breakpointu, o čemž je vývojář samozřejmě informován:
(gdb) run Starting program: /home/tester/temp/a.out Breakpoint 1, loop () at test.s:36 36 mov [ecx], al # zapis znaku do bufferu
Pro krokování na úrovni jednotlivých instrukcí se používá příkaz nexti, který lze zkrátit na ni:
(gdb) nexti 37 inc al # ASCII kod dalsiho znaku (gdb) ni 38 inc ecx # uprava ukazatele do bufferu (gdb) ni 39 cmp al, 'z' # ma se smycka ukoncit?
Tomuto příkazu je možné zadat i počet provedených instrukcí:
(gdb) nexti 10
Po několika provedeních smyčky (například příkazem c(ontinue)) se můžeme podívat na aktuální stav breakpointů:
(gdb) info break
Num Type Disp Enb Address What
1 breakpoint keep y 0x00000000004000b7 test.s:36
breakpoint already hit 4 times
9. Zobrazení obsahu pracovních registrů
Při ladění a krokování aplikací na úrovni jednotlivých strojových instrukcí se prakticky vždy potřebujeme dozvědět i to, jaké hodnoty jsou uloženy v pracovních registrech. V případě, že chceme znát hodnotu jednoho registru, lze použít univerzální příkaz print, přičemž před jménem registru musí být uveden znak $, aby GNU Debugger věděl, že se neptáme na obsah proměnné:
(gdb) print $al $1 = 100 (gdb) print $ecx $3 = 6291691
Pokud se má hodnota registru vypsat v jiné soustavě, stačí za příkaz print přidat formátovací znak:
(gdb) print/x $ecx $5 = 0x6000eb (gdb) print/t $ecx $7 = 11000000000000011101011 (gdb) print/c $al $10 = 100 'd'
K dispozici jsou tyto formátovací znaky:
o(octal) x(hex) d(decimal) u(unsigned decimal), t(binary) f(float) a(address) c(char)
Všechny pracovní, stavové a řídicí registry se vypisují příkazem info registers. Na architektuře x86–64 vypadá výsledek následovně:
(gdb) info registers rax 0x64 100 rbx 0x0 0 rcx 0x6000eb 6291691 rdx 0x0 0 rsi 0x0 0 rdi 0x0 0 rbp 0x0 0x0 rsp 0x7fffffffe190 0x7fffffffe190 r8 0x0 0 r9 0x0 0 r10 0x0 0 r11 0x0 0 r12 0x0 0 r13 0x0 0 r14 0x0 0 r15 0x0 0 rip 0x4000b7 0x4000b7 <loop> eflags 0x293 [ CF AF SF IF ] cs 0x33 51 ss 0x2b 43 ds 0x0 0 es 0x0 0 fs 0x0 0 gs 0x0 0
Registry matematického koprocesoru se vypíšou příkazem info float, přičemž formát výstupu opět závisí na použité architektuře:
(gdb) info float
R7: Empty 0x00000000000000000000
R6: Empty 0x00000000000000000000
R5: Empty 0x00000000000000000000
R4: Empty 0x00000000000000000000
R3: Empty 0x00000000000000000000
R2: Empty 0x00000000000000000000
R1: Empty 0x00000000000000000000
=>R0: Empty 0x00000000000000000000
Status Word: 0x0000
TOP: 0
Control Word: 0x037f IM DM ZM OM UM PM
PC: Extended Precision (64-bits)
RC: Round to nearest
Tag Word: 0xffff
Instruction Pointer: 0x00:0x00000000
Operand Pointer: 0x00:0x00000000
Opcode: 0x0000
10. Zobrazení obsahu vybrané části operační paměti
Nyní již víme, jak lze zobrazit disassemblovaný kód (sekvenci strojových instrukcí) i obsah pracovních a řídicích registrů, včetně registrů matematického koprocesoru. Stav procesu je ovšem navíc charakterizován i obsahem paměti, která je procesu přidělena. Pro výpis obsahu bloku paměti použijte příkaz x, za nímž může následovat adresa. Pokud víme, že buffer začíná na adrese 0×6000e8, lze si jeho začátek zobrazit příkazem:
(gdb) x 0x6000e8 0x6000e8 <buffer>: 97 'a'
Namísto explicitně zapsané adresy lze použít například i obsah registru. My pro adresování používáme registr ecx a již víme, že před jménem registru musí být zapsán znak dolaru:
(gdb) x $ecx 0x6000eb <buffer+3>: 0x00000000
Při požadavku na výpis delšího bloku se za lomítko zadá počet prvků:
(gdb) x/10 $ecx 0x6000eb <buffer+3>: 0x00000000 0x00000000 0x00000000 0x00000000 0x6000fb <buffer+19>: 0x00000000 0x00000000 0x00000000 0x00000000 0x60010b: 0x00000000 0x00000000
Povšimněte si, jak GNU Debugger inteligentně zjistí, které adresy ještě náleží do bufferu a které už nikoli. Ještě zřejmější to bude při pokusu o výpis paměti, na níž jsou uloženy instrukce tvořící vlastní program:
(gdb) x/50bx _start 0x4000b0 <_start>: 0xb9 0xe8 0x00 0x60 0x00 0xb0 0x61 0x67 0x4000b8 <loop+1>: 0x88 0x01 0xfe 0xc0 0xff 0xc1 0x3c 0x7a 0x4000c0 <loop+9>: 0x76 0xf5 0xb8 0x04 0x00 0x00 0x00 0xbb 0x4000c8 <loop+17>: 0x01 0x00 0x00 0x00 0xb9 0xe8 0x00 0x60 0x4000d0 <loop+25>: 0x00 0xba 0x1a 0x00 0x00 0x00 0xcd 0x80 0x4000d8 <loop+33>: 0xb8 0x01 0x00 0x00 0x00 0xbb 0x00 0x00 0x4000e0 <loop+41>: 0x00 0x00
11. Formátování zobrazovaných dat
Příkaz x kromě počtu prvků akceptuje i počet prvků a formátovací znak. Zobrazme si tedy padesát bajtů začínajících na adrese odpovídající začátku bufferu. Každý bajt bude zobrazen v dekadické podobě:
(gdb) x/50b 0x6000e8 0x6000e8 <buffer>: 97 98 99 0 0 0 0 0 0x6000f0 <buffer+8>: 0 0 0 0 0 0 0 0 0x6000f8 <buffer+16>: 0 0 0 0 0 0 0 0 0x600100 <buffer+24>: 0 0 0 0 0 0 0 0 0x600108: 0 0 0 0 0 0 0 0 0x600110: 0 0 0 0 0 0 0 0 0x600118: 0 0
Přepnutí do režimu hexadecimálního výpisu vypadá takto:
(gdb) x/50bx 0x6000e8 0x6000e8 <buffer>: 0x61 0x62 0x63 0x00 0x00 0x00 0x00 0x00 0x6000f0 <buffer+8>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f8 <buffer+16>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600100 <buffer+24>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600108: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600110: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600118: 0x00 0x00
Kombinace předchozího:
(gdb) x/10xb $ecx-3 0x6000e8 <buffer>: 0x61 0x62 0x63 0x00 0x00 0x00 0x00 0x00 0x6000f0 <buffer+8>: 0x00 0x00
Zajímavý může být režim výpisu „řetězců“, kdy se GNU Debugger pokusí část paměti považovat za céčkovský řetězec. To bude fungovat i pro náš buffer, a to z toho důvodu, že se sekce .bss automaticky nuluje při startu procesu a tudíž vlastně zadarmo získáme znaky pro konec řetězce \0:
(gdb) x/10xs $ecx-3 0x6000e8 <buffer>: "abc" 0x6000ec <buffer+4>: "" 0x6000ed <buffer+5>: "" 0x6000ee <buffer+6>: "" 0x6000ef <buffer+7>: "" 0x6000f0 <buffer+8>: "" 0x6000f1 <buffer+9>: "" 0x6000f2 <buffer+10>: "" 0x6000f3 <buffer+11>: "" 0x6000f4 <buffer+12>: ""
Za příkazem x se tedy za lomítko zadává:
- Počet prvků.
- Formátovací znak o(octal), x(hex), d(decimal), u(unsigned decimal), t(binary), f(float), a(address), i(instruction), c(char), s(string)
- Jak velké jsou prvky: b(byte), h(halfword), w(word), g(8 bajtů)
Velikost prvků se zadává, jen když je to nutné, protože GNU Debugger velikost mnohdy odvodí automaticky podle metadat.
12. Užitečný příkaz display
Při ladění mnohdy potřebujeme neustále sledovat obsah některých registrů či bloku operační paměti. Zadávat neustále příkaz print popř. info registers je samozřejmě těžkopádné a proto přichází na řadu další velmi užitečný příkaz display. Tomu lze zadat výraz, který se vyhodnotí a vypíše po každém provedeném kroku. Podívejme se na příklad krokování smyčky loop, v níž pracujeme s osmibitovým registrem al a 32bitovým registrem ecx:
(gdb) display $al (gdb) display $ecx
Nastavíme breakpoint a spustíme náš testovací program:
(gdb) break loop Breakpoint 1 at 0x4000b7: file test.s, line 36. (gdb) run Starting program: /home/tester/temp/a.out Breakpoint 1, loop () at test.s:36 36 mov [ecx], al # zapis znaku do bufferu 2: $ecx = 6291688 1: $al = 97
Vidíme, že program se zastavil a současně se skutečně vypsaly i obsahy těch registrů, které nás zajímají. Proveďme další iteraci:
(gdb) c Continuing. Breakpoint 1, loop () at test.s:36 36 mov [ecx], al # zapis znaku do bufferu 2: $ecx = 6291689 1: $al = 98
A znovu…
(gdb) c Continuing. Breakpoint 1, loop () at test.s:36 36 mov [ecx], al # zapis znaku do bufferu 2: $ecx = 6291690 1: $al = 99
Přidejme ještě sledování bloku operační paměti, konkrétně našeho bufferu:
(gdb) display/50xb 0x6000e8
3: $ecx = 6291688 2: $al = 97 1: x/50xb 0x6000e8 0x6000e8 <buffer>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f0 <buffer+8>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f8 <buffer+16>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600100 <buffer+24>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600108: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600110: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600118: 0x00 0x00
(gdb) c Continuing. Breakpoint 1, loop () at test.s:37 37 mov [ecx], al # zapis znaku do bufferu 3: $ecx = 6291689 2: $al = 98 1: x/50xb 0x6000e8 0x6000e8 <buffer>: 0x61 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f0 <buffer+8>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f8 <buffer+16>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600100 <buffer+24>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600108: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600110: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600118: 0x00 0x00
(gdb) c Continuing. Breakpoint 1, loop () at test.s:37 37 mov [ecx], al # zapis znaku do bufferu 3: $ecx = 6291690 2: $al = 99 1: x/50xb 0x6000e8 0x6000e8 <buffer>: 0x61 0x62 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f0 <buffer+8>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x6000f8 <buffer+16>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600100 <buffer+24>: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600108: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600110: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x600118: 0x00 0x00
Vidíme, že příkaz display je skutečně užitečný a může GDB přiblížit možnostem celoobrazovkových debuggerů či debuggerů s GUI.
13. Praktický příklad a použití TUI
Pro úplnost se ještě podívejme, jak vypadá použití TUI společně s programy laděnými na úrovni jednotlivých instrukcí. Pravděpodobně nejdůležitější je zde příkaz layout, kterým lze změnit zobrazené informace:
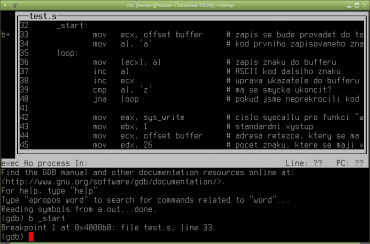
Obrázek 1: Po spuštění gdbtui se v okně zobrazí i původní zdrojový kód.
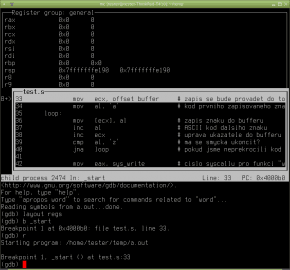
Obrázek 2: Přidali jsme okno s výpisem pracovních registrů příkazem layout regs. Současně se nastavil breakpoint, což je vidět i ze značky B+ se šipkou.

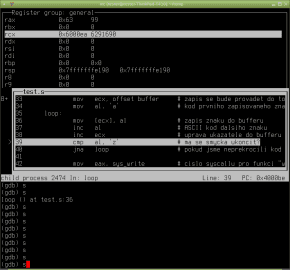
Obrázek 3: Při krokování se zvýrazňuje jak právě zpracovávaná instrukce, tak i ty pracovní registry, jejichž obsah se změnil.
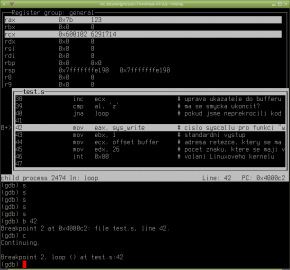
Obrázek 4: Při krokování se zvýrazňuje jak právě zpracovávaná instrukce, tak i ty pracovní registry, jejichž obsah se změnil.
14. Odkazy na Internetu
- Debuggery a jejich nadstavby v Linuxu
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu/ - Debuggery a jejich nadstavby v Linuxu (2. část)
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-2-cast/ - Debuggery a jejich nadstavby v Linuxu (3): Nemiver
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-3-nemiver/ - Debuggery a jejich nadstavby v Linuxu (4): KDbg
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-4-kdbg/ - Debuggery a jejich nadstavby v Linuxu (5): ladění aplikací v editorech Emacs a Vim
http://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-5-ladeni-aplikaci-v-editorech-emacs-a-vim/ - Tracing (software)
https://en.wikipedia.org/wiki/Tracing_%28software%29 - ltrace(1) – Linux man page
http://linux.die.net/man/1/ltrace - ltrace (Wikipedia)
https://en.wikipedia.org/wiki/Ltrace - strace(1) – Linux man page
http://linux.die.net/man/1/strace - strace (stránka projektu na SourceForge)
https://sourceforge.net/projects/strace/ - strace (Wikipedia)
https://en.wikipedia.org/wiki/Strace - SystemTap (stránka projektu)
https://sourceware.org/systemtap/ - SystemTap (Wiki projektu)
https://sourceware.org/systemtap/wiki - SystemTap (Wikipedia)
https://en.wikipedia.org/wiki/SystemTap - Dynamic Tracing with DTrace & SystemTap
http://myaut.github.io/dtrace-stap-book/ - DTrace (Wikipedia)
https://en.wikipedia.org/wiki/DTrace - GDB – Dokumentace
http://sourceware.org/gdb/current/onlinedocs/gdb/ - GDB – Supported Languages
http://sourceware.org/gdb/current/onlinedocs/gdb/Supported-Languages.html#Supported-Languages - GNU Debugger (Wikipedia)
https://en.wikipedia.org/wiki/GNU_Debugger - The LLDB Debugger
http://lldb.llvm.org/ - Debugger (Wikipedia)
https://en.wikipedia.org/wiki/Debugger - 13 Linux Debuggers for C++ Reviewed
http://www.drdobbs.com/testing/13-linux-debuggers-for-c-reviewed/240156817 - Getting started with ltrace: how does it do that?
https://www.ellexus.com/getting-started-with-ltrace-how-does-it-do-that/ - Reverse Engineering Tools in Linux – strings, nm, ltrace, strace, LD_PRELOAD
http://www.thegeekstuff.com/2012/03/reverse-engineering-tools/ - 7 Strace Examples to Debug the Execution of a Program in Linux
http://www.thegeekstuff.com/2011/11/strace-examples/ - Oracle® Solaris 11.3 DTrace (Dynamic Tracing) Guide
http://docs.oracle.com/cd/E53394_01/html/E53395/gkwpo.html#scrolltoc - An Introduction To Using GDB Under Emacs
http://tedlab.mit.edu/~dr/gdbintro.html - GNU Emacs
https://www.gnu.org/software/emacs/emacs.html - The Emacs Editor
https://www.gnu.org/software/emacs/manual/html_node/emacs/index.html - Emacs Lisp
https://www.gnu.org/software/emacs/manual/html_node/elisp/index.html - An Introduction to Programming in Emacs Lisp
https://www.gnu.org/software/emacs/manual/html_node/eintr/index.html - 27.6 Running Debuggers Under Emacs
https://www.gnu.org/software/emacs/manual/html_node/emacs/Debuggers.html - GdbMode
http://www.emacswiki.org/emacs/GdbMode - Emacs (Wikipedia)
https://en.wikipedia.org/wiki/Emacs - Emacs Lisp (Wikipedia)
https://en.wikipedia.org/wiki/Emacs_Lisp - Pyclewn installation notes
http://pyclewn.sourceforge.net/install.html - pip Installation
https://pip.pypa.io/en/latest/installing.html - Clewn
http://clewn.sourceforge.net/ - Clewn installation
http://clewn.sourceforge.net/install.html - Clewn – soubory
http://sourceforge.net/projects/clewn/files/OldFiles/ - KDbg: úvodní stránka
http://www.kdbg.org/ - Nemiver (stránky projektu)
https://wiki.gnome.org/Apps/Nemiver - Basic Assembler Debugging with GDB
http://dbp-consulting.com/tutorials/debugging/basicAsmDebuggingGDB.html - Nemiver FAQ
https://wiki.gnome.org/Apps/Nemiver/FAQ - Nemiver (Wikipedia)
https://en.wikipedia.org/wiki/Nemiver - Data Display Debugger
https://www.gnu.org/software/ddd/ - GDB – Dokumentace
http://sourceware.org/gdb/current/onlinedocs/gdb/ - BASH Debugger
http://bashdb.sourceforge.net/ - The Perl Debugger(s)
http://debugger.perl.org/ - Visual Debugging with DDD
http://www.drdobbs.com/tools/visual-debugging-with-ddd/184404519 - Pydb – Extended Python Debugger
http://bashdb.sourceforge.net/pydb/ - Insight
http://www.sourceware.org/insight/ - Supported Languages (GNU Debugger)
http://sourceware.org/gdb/current/onlinedocs/gdb/Supported-Languages.html#Supported-Languages - GNU Debugger (Wikipedia)
https://en.wikipedia.org/wiki/GNU_Debugger - The LLDB Debugger
http://lldb.llvm.org/ - Debugger (Wikipedia)
https://en.wikipedia.org/wiki/Debugger - 13 Linux Debuggers for C++ Reviewed
http://www.drdobbs.com/testing/13-linux-debuggers-for-c-reviewed/240156817 - Clewn
http://clewn.sourceforge.net/ - Clewn installation
http://clewn.sourceforge.net/install.html - Clewn – soubory ke stažení
http://sourceforge.net/projects/clewn/files/OldFiles/ - Pyclewn installation notes
http://pyclewn.sourceforge.net/install.html - Debugging
http://janus.uclan.ac.uk/pagray/labs/debug.htm






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU