
Obsah
1. Úpravy Emacsu a tvorba nových modulů s využitím Emacs Lispu
2. LISP aneb jazyk, který nám nepřinesl AI
3. Rozdíly mezi různými dialekty programovacího jazyka LISP
4. Je Emacs Lisp funkcionálním jazykem?
5. Základní nastavení Emacsu při zkoušení možností Emacs LISPu
6. Scratch buffer ve funkci REPLu
7. Spouštění příkladů naprogramovaných v Elispu z příkazového řádku
8. Základní datové typy Elispu
9. Prázdný seznam a rekurzivní datové struktury založené na seznamech
10. Tečka-dvojice: základ pro tvorbu složitějších datových struktur
11. Základní funkce pro konstrukci seznamů a pro přístup k prvkům seznamů
13. Funkce s nepovinnými parametry
16. Výpočet faktoriálu realizovaný funkcí vyššího řádu
17. Repositář s demonstračními příklady
1. Úpravy Emacsu a tvorba nových modulů s využitím Emacs Lispu
Textový editor Emacs si získal podporu mezi uživateli mj. i proto, že je široce konfigurovatelný a navíc pro něj vzniklo téměř nepřeberné množství různých modulů (minimálně několik tisíc), přičemž některé moduly dělají z původně textového editoru webový prohlížeč, kalendář, mailového klienta, integrované vývojové prostředí s rozhraním pro debugger atd. Je to umožněno díky tomu, že se samotný Emacs (velmi zjednodušeně řečeno) skládá ze tří částí: základního „engine“ naprogramovaného v céčku, který se stará o ovládání displeje, použití klávesnice, myši, operační paměti atd., dále pak z virtuálního stroje programovacího jazyka Emacs Lisp a konečně ze skriptů psaných právě v Emacs Lispu, které základní engine využívají a realizují tak všechny uživatelsky viditelné funkce. A právě Emacs Lispem (Elispem), resp. přesněji řečeno základy, na nichž je tento jazyk postaven, se budeme zabývat v dnešním článku.
2. LISP aneb jazyk, který nám nepřinesl AI
Syntaxe jazyka LISP je již po 50 let zdrojem inspirace pro autory vtipů
Historie programovacího jazyka LISP je velmi dlouhá, neboť se jedná o jeden z nejstarších vyšších programovacích jazyků vůbec. Autorem teoretického návrhu tohoto jazyka je John McCarthy, který se již v roce 1956 připojil k týmu, jehož úkolem bylo navrhnout algebraický programovací jazyk umožňující mj. zpracování seznamů, jenž by byl vhodný pro vývoj systémů umělé inteligence – AI. McCarthy navrhl, že by se fakta o okolním světě (která může AI při své činnosti použít) mohla reprezentovat formou vět ve vhodně strukturovaném formálním jazyce. Posléze se ukázalo, že je výhodné reprezentovat jednotlivé věty formou seznamů. McCarthy myšlenku jazyka vhodného pro AI rozpracoval dále – odklonil se například od infixové notace zápisu algebraických výrazů, protože naprogramování některých manipulací s těmito výrazy (derivace, integrace, zjednodušení výrazů, logická dedukce) bylo zbytečně složité.

Obrázek 1: Na tomto grafu evoluce programovacích jazyků můžeme vidět některé programovací jazyky, které jsme si již popsali v seriálu o vývoji počítačů a mikropočítačů.
Následně McCarthy ve svých teoretických pracích (vznikajících v průběhu let 1957 a 1958) ukázal, že je možné pomocí několika poměrně jednoduchých operací (a notací pro zápis funkcí) vytvořit programovací jazyk, který je Turingovsky kompletní (tj. jeho výpočetní mocnost je ekvivalentní Turingovu stroji), ale zápis algoritmů v tomto jazyce je mnohem jednodušší než zápis pravidel pro Turingův stroj. Tento jazyk, jenž byl z velké části založen na Lambda kalkulu, obsahoval možnost vytváření rekurzivních funkcí (což byl významný rozdíl například oproti tehdejší verzi FORTRANU), funkce jako argumenty jiných funkcí, podmíněné výrazy (jedna z variant speciální formy), funkce pro manipulaci se seznamy a v neposlední řadě také funkci eval.
Na McCarthovu teoretickou práci navázal S. R. Russell, který si uvědomil, že samotná funkce eval, pokud by byla implementována na nějakém počítači, může sloužit jako základ plnohodnotného interpretru jazyka LISP (interpretr LISPu se někdy též označuje zkratkou REPL: Read-Eval-Print-Loop, tj. interpretr ve smyčce načítá jednotlivé výrazy, vyhodnocuje je a následně tiskne jejich výslednou hodnotu). Russell skutečně celou smyčku REPL implementoval – tímto způsobem se zrodila první skutečně použitelná verze LISPu.
3. Rozdíly mezi různými dialekty programovacího jazyka LISP
V průběhu dalších více než pěti desetiletí dosti překotného rozvoje výpočetní techniky i programovacích jazyků vzniklo velmi mnoho dialektů tohoto programovacího jazyka, například MacLISP, InterLISP, ZetaLISP, XLisp, AutoLISP (původně odvozený z XLispu), samozřejmě Emacs LISP nebo slavný Common LISP (více viz odkazy na konci článku). Kromě těchto implementací jazyka LISP, které se od sebe v několika ohledech odlišují (například existencí či neexistencí maker či objektového systému), vznikl v minulosti i nový dialekt tohoto jazyka nazvaný Scheme (původně Schemer), jehož autory jsou Guy L. Steele a Gerald Jay Sussman (Steele později pracoval na specifikaci Javy i programovacího jazyka Fortress). Tento dialekt je implementačně jednodušší a také se ho lze naučit rychleji než mnohé další varianty jazyka LISP.
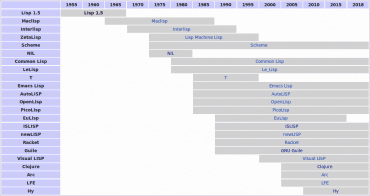
Obrázek 2: Vývoj některých dialektů Lispu.
Zdroj: Wikipedia.
Právě z těchto důvodů se Scheme využívá či využívalo jak při výuce programování, tak i v mnoha open-source projektech, například v dnes popisovaném textovém editoru Emacs či v grafickém editoru GIMP jako jeden z podporovaných skriptovacích jazyků. Richard Stallman si dokonce přál, aby se Scheme stalo standardním skriptovacím jazykem většiny GNU aplikací, což je idea, která se – především po vzniku dalších vysokoúrovňových programovacích jazyků (Perl, Python, TCL) – nakonec neuskutečnila (i když vedla k tzv. Tcl war).
Musíme si však uvědomit, že samotný LISP je nutné chápat jako spíše koncept, než konkrétní programovací jazyk. Proto můžeme pod pojmem LISP (psáno též Lisp) najít poměrně velké množství programovacích jazyků, které sice mají podobný základ, ovšem konkrétní implementace jsou značně rozdílné. Do rodiny LISPovských jazyků tak dnes patří i dosti odlišné Clojure a výše zmíněné implementace jazyka Scheme. Dnes patří mezi nejpopulárnější implementace LISPovského jazyka především Common Lisp, dále pochopitelně Emacs Lisp, ovšem nesmíme zapomenout na již zmíněné Clojure a taktéž Racket neboli původním názvem PLT Scheme popř. na GNU Guile (implementace Scheme, která měla být původně určena jako základní rozšiřující jazyk v GNU projektu, viz zmínka o RMS).
Velmi pěkně jsou základní společné vlastnosti a rozdíly mezi těmito jazyky shrnuty na stránce Common Lisp, Racket, Clojure, Emacs Lisp.

Obrázek 3: SICP – jedna z nejznámějších knížek (nejenom) o LISPovských jazycích.
4. Je Emacs Lisp funkcionálním jazykem?
Někteří potenciální uživatelé Emacsu mohou mít z použití Emacs Lispu určité obavy, především z toho důvodu, že tento jazyk považují za čistě funkcionální. Pravděpodobně to souvisí s tím, že když je nějaký dialekt LISPu nebo Scheme vysvětlován na vysokých školách, skutečně je naprostá většina algoritmů řešena funkcionálně, tj. (velmi zjednodušeně řečeno) bez použití proměnných, procedur s vedlejšími efekty (používají se jen čisté funkce) a programových smyček (ty jsou nahrazeny rekurzí či tail rekurzí). Tento přístup samozřejmě nemusí být vůbec špatný, ale ve skutečnosti je Emacs Lisp společně například s AutoLISPem (i původním XLispem) příkladem dialektu LISPu, v němž je možné psát programy i strukturovaně. Jako příklad si můžeme uvést použití proměnných a funkcí s vedlejším efektem:
(setq i 10) (cl-loop repeat i do (print "Hello world!"))
Následuje programová smyčka a opět použití proměnné (dokonce globální proměnné):
(setq i 10) (while (> i 0) (print i) (setq i (- i 1)))
Jednoduchá modifikace předchozího příkladu, v němž hodnota počitadla roste a používá se zde funkce nazvaná 1+ (v Lispu je možné pro názvy funkcí používat větší množství znaků, než v jiných jazycích, navíc můžete vidět, že i na začátku identifikátoru může být číslice):
(setq i 0) (while (< i 10) (print i) (setq i (1+ i)))
Na druhou stranu nám samozřejmě nikdo nebrání použít funkci s rekurzí:
(defun factorial (n)
(if (<= n 1)
1
(* n (factorial (- n 1)))))
(print (factorial 10))
Nebo faktoriál naprogramovaný s využitím funkce vyššího řádu apply:
(defun factorial (n) (apply '* (number-sequence 1 n)))
5. Základní nastavení Emacsu při zkoušení možností Emacs LISPu
Je Matrix napsaný v LISPu nebo Perlu?
V této kapitole si ukážeme některé možnosti nastavení Emacsu ve chvíli, kdy si budeme chtít vyzkoušet základní schopnosti Emacs LISPu. První možnost spočívá v otevření (a následném pojmenování) nového bufferu. Ve druhém kroku tento buffer přepneme do režimu práce s LISPem. Při použití Evil režimu je to snadné, protože se pomocí dvojtečky přepneme do stavu zadávání příkazů:
:switch-to-buffer [jméno nového bufferu] :lisp-mode
Podobně budeme postupovat ve chvíli, kdy Evil režim není povolen. Bude se jen lišit klávesová zkratka, namísto dvojtečky se stiskne M-x:
M-x switch-to-buffer [jméno nového bufferu] M-x lisp-mode
Druhá možnost, kterou osobně při testování preferuji, je založena na použití bufferu *scratch*, který je automaticky otevřen při nastartování Emacsu a při jeho ukončení je ve výchozím nastavení jeho obsah zahozen.
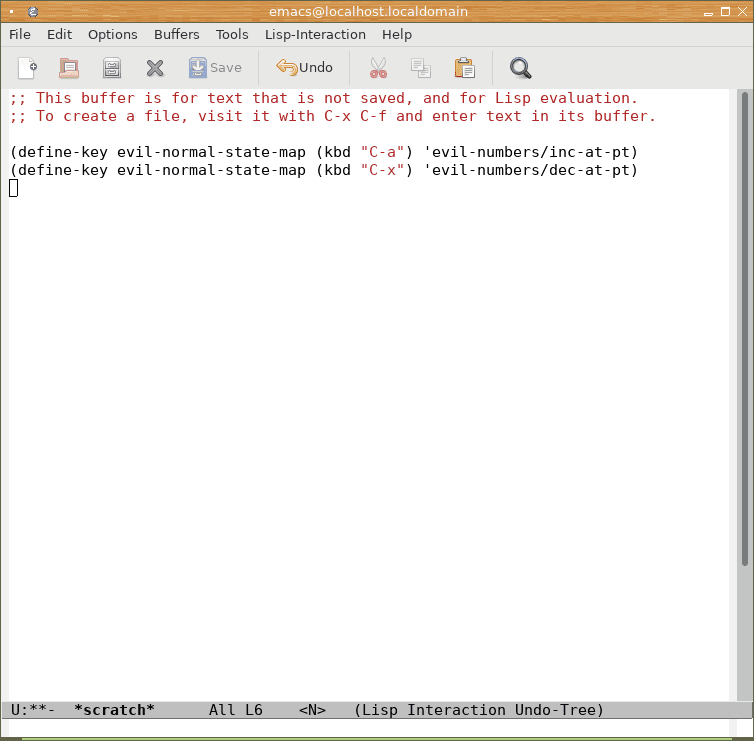
Obrázek 4: Použití scratch bufferu při zkoumání možností Emacs Lispu.
V případě použití scratch bufferu je vhodné si poněkud změnit nastavení Emacsu (klidně přímo v tomto bufferu!). První vhodné nastavení:
(setq evil-move-beyond-eol t)
Při tomto nastavení je možné v normálním stavu přesunout textový kurzor ZA poslední znak na řádku. Toto nastavení velmi úzce souvisí s klávesovou zkratkou C-j sloužící k vyhodnocení tzv. LISPovské formy (výrazu) a vložení výsledku vyhodnocení přímo do bufferu na pozici kurzoru. Vhodnější je, aby se před vyhodnocením textový kurzor nejprve přesunul na konec řádku, protože v opačném případě by byl výsledek vložen přímo do definice formy/výrazu.
Nové mapování klávesové zkratky C-j pro Evil režim může vypadat následovně (stále používám Evil mode):
(define-key evil-normal-state-map "\C-j"
(lambda ()
(interactive)
(move-end-of-line nil)
(eval-print-last-sexp)))
Nezapomeňte na další užitečné klávesové zkratky:
| Zkratka | Význam |
|---|---|
| C-h f | zobrazí popis/dokumentaci vybrané funkce |
| C-h v | zobrazí popis/dokumentaci vybrané proměnné |
| C-M-i | doplnění jména identifikátoru nebo symbolu |
| C-M-q | automatické zarovnání kódu |
6. Scratch buffer ve funkci REPLu
Pokud si chcete ze scratch bufferu udělat obdobu klasické interaktivní smyčky REPL (s historií a plnou možností editace všech dříve zadaných příkazů), můžete si namísto výše zmíněné klávesy C-j přemapovat přímo klávesu Enter (bez dalších modifikátorů) takovým způsobem, aby se při jejím stisku v normálním režimu kurzor posunul na konec řádku a následně se provedlo vyhodnocení výrazu, který je na řádku napsán. Od předchozího nastavení se následující definice odlišuje pouze zavoláním funkce kbd, které se předá název klávesy:
(define-key evil-normal-state-map (kbd "<RET>")
(lambda ()
(interactive)
(move-end-of-line nil)
(eval-print-last-sexp)))
Nastavení je samozřejmě možné uložit do souboru .emacs umístěného v domovském adresáři uživatele. V mém případě vypadá zhruba následovně (neuvádím ovšem ty části, které nejsou z hlediska dnešního článku relevantní):
(setq evil-move-beyond-eol t)
(require 'evil)
(require 'evil-numbers)
(evil-mode 1)
(define-key evil-normal-state-map (kbd "C-a") 'evil-numbers/inc-at-pt)
(define-key evil-normal-state-map (kbd "C-x") 'evil-numbers/dec-at-pt)
(define-key evil-normal-state-map (kbd "<RET>")
(lambda ()
(interactive)
(move-end-of-line nil)
(eval-print-last-sexp)))
Otestování možností takto nastaveného REPLu je možné provést jednoduše – viz následující sekvence screenshotů:
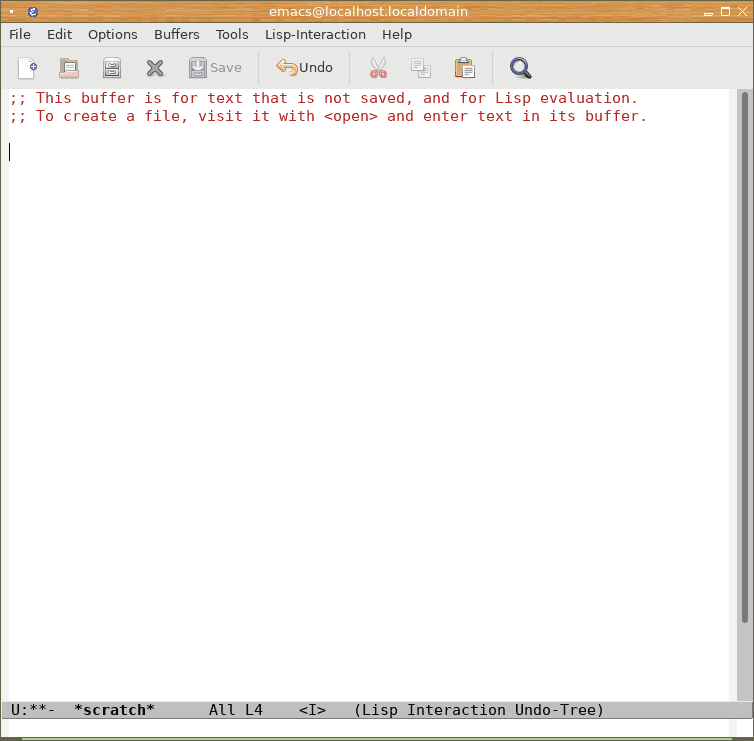
Obrázek 5: Po spuštění Emacsu obsahuje scratch buffer pouze úvodní zprávy (ty začínají středníkem, takže se z hlediska jazyka LISP jedná o komentáře). Povšimněte si, že je zapnutý režim Lisp-Interaction.
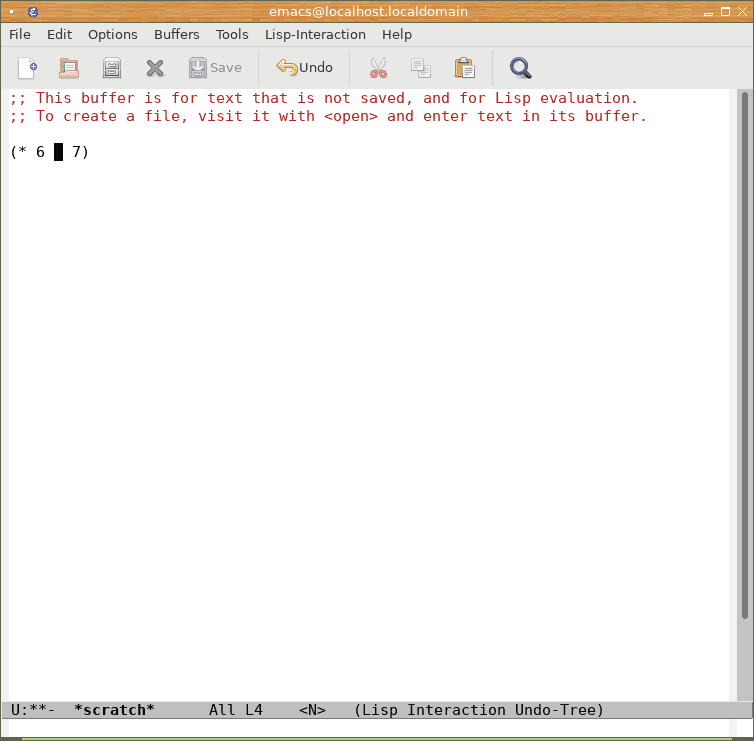
Obrázek 6: Zápis takzvané LISPovské formy, přepnutí do normálního stavu (režim zadávání příkazů) klávesou Esc. Povšimněte si, že se kurzor nachází uprostřed formy a nikoli za jejím koncem.
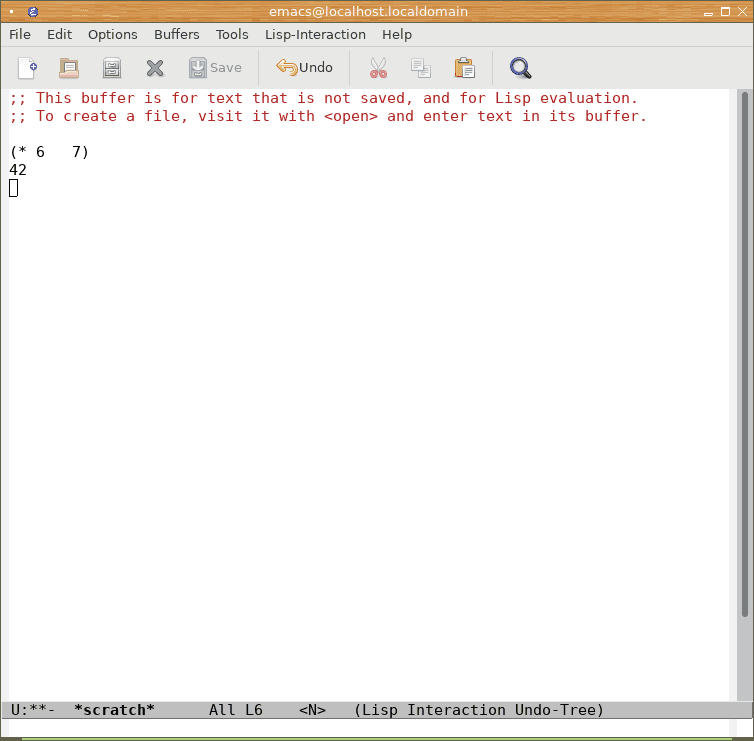
Obrázek 7: Po stisku klávesy Enter se forma vyhodnotí a výsledek vyhodnocení se zapíše na následující řádek.
7. Spouštění příkladů naprogramovaných v Elispu z příkazového řádku
Některé příklady, které si ukážeme v navazujících kapitolách, většinou obsahují pouze několik LISPovských forem, jejichž výsledná hodnota se (po vyhodnocení) vypisuje funkcí print. Takové velmi jednoduché skripty, které vlastně žádným způsobem neinteragují s interními strukturami Emacsu (buffery, minibuffery, okna, kurzory, značky, výběry), je možné spustit v režimu interpretru. Emacs se v tomto případě spustí následujícím způsobem:
emacs --script priklad1.el
Po dokončení skriptu se Emacs automaticky ukončí (přičemž se ovšem vůbec nezobrazí jeho grafické či textové uživatelské rozhraní, takže se skutečně Emacs chová jako „obyčejný“ interpret programovacího jazyka Elisp).
8. Základní datové typy Elispu
Základními datovými typy, se kterými se pracuje v klasických (řekněme ortodoxních) dialektech programovacího jazyka LISP, jsou takzvané atomy a seznamy. Atomy jsou z hlediska tohoto programovacího jazyka základními objekty, které není možné dále dělit, ale je je možné ukládat do seznamů (většinou jsou atomy navíc neměnitelné – immutable). Atomy mohou být několika typů: jedná se především o symboly (například ABC), čísla (42, 3.1415 atd. – některé interpretry jazyka LISP rozlišují celá čísla, čísla reálná, čísla komplexní a někdy též zlomky, tj. čísla racionální), řetězce („pokus“, „velmi dlouhý řetězec“), vestavěné funkce atd.
V reálných programech se atomy ukládají do seznamů, přičemž pro označení začátku a konce seznamu se používají běžné kulaté závorky – levá závorka samozřejmě označuje začátek seznamu a pravá závorka jeho konec. Prvky neboli elementy seznamu jsou od sebe odděleny alespoň jednou mezerou nebo koncem řádku, což mj. znamená, že seznam může být rozepsán na více řádcích (to je velmi důležité ve chvíli, kdy se pomocí seznamů reprezentují funkce, které mohou být rozepsány na mnoho řádků).
V Elispu je nabídka datových typů nepatrně rozšířena. Stále zde existuje rozlišení mezi atomy a ostatními (strukturovanými) typy. Mezi atomy patří zejména:
- Celá čísla (integer)
- Reálná čísla (float)
- Symboly (symbol), začínají apostrofem
- Řetězce (string), začínají a končí uvozovkami
Všechny atomy se vyhodnocují samy na sebe (vyhodnocením je myšlen „výpočet“ výsledné hodnoty). Můžeme si to velmi snadno vyzkoušet ve scratch bufferu (viz kapitolu číslo 6):
42 42 1e10 10000000000.0 1e-3 0.001 3.14 3.14 'nějaký-symbol nějaký-symbol "řetězec" "řetězec"
Mezi strukturované typy, v nichž mohou být uloženy atomy či další strukturované typy (rekurzivně), řadíme například:
- Seznamy složené z tečka-dvojic (zde pojmenované cons, důvod bude vysvětlen v dalším textu)
- Vektory (vector)
- Hešovací tabulky (hash-table)
Nesmíme ovšem zapomenout ani na další datové typy, především na funkce (function) a typy související s vlastním textovým editorem (buffer, marker, frame atd.). Základní práci s funkcemi si ukážeme dnes, ovšem datové typy, které úzce souvisí s „enginem“ textového editoru Emacs budou popsány až v navazujícím článku.
9. Prázdný seznam a rekurzivní datové struktury založené na seznamech
Zvláštním a v mnoha ohledech důležitým typem seznamu je prázdný seznam, který neobsahuje žádné prvky (elementy) a proto je zapisován buď levou závorkou, za níž ihned následuje závorka pravá (mezi závorkami se tedy nenachází žádný atom ani další seznam, mohou se zde nacházet pouze mezery nebo konce řádků), nebo lze pro jeho zápis alternativně použít symbol nil, který je ekvivalentní prázdnému seznamu (současně se tímto symbolem označuje logická hodnota nepravda, tj. prázdný seznam se v logických výrazech vyhodnocuje na hodnotu false).
V Elispu je prázdný seznam zapisovaný stylem '() skutečně chápán jako symbol nil, o čemž se můžeme snadno přesvědčit:
(type-of nil) symbol (type-of '()) symbol (type-of '(1)) cons (type-of '(1 2 3)) cons
Seznam může jako své prvky (elementy) obsahovat jak atomy, tak i další vnořené seznamy, což znamená, že se jedná o rekurzivní datovou strukturu, pomocí níž je možné popsat i mnohé další složitější datové struktury, například n-dimenzionální pole, stromy, hierarchické mřížky atd. Pod tímto odstavcem je uvedeno několik příkladů seznamů akceptovaných interpretrem jazyka Elisp. Povšimněte si především důsledného vyvážení pravých a levých závorek, především v případě, že seznam obsahuje jako své prvky/elementy další podseznamy:
; komentáře jsou uvozené znakem středník, jak je to demonstrováno na tomto programovém řádku ; prázdný seznam, viz předchozí text () ; prázdný seznam - alternativní zápis pomocí symbolu nil nil ; seznam obsahující čtyři atomy (konkrétně se jedná o trojici symbolů a jedno číslo) (SEZNAM OBSAHUJICI 4 ATOMY) ; seznam obsahující trojici čísel (42 3.14159 6502) ; dvouprvkový seznam obsahující dva podseznamy, z nichž každý obsahuje dva atomy ((A B) (C D)) ; dvouprvkový seznam obsahující dva prázdné podseznamy (() ()) ; jednoprvkový seznam obsahující taktéž jednoprvkový podseznam obsahující prázdný podseznam :-) ((())) ; tříprvkový seznam obsahující jeden symbol a dvě čísla (+ 1 2) ; tříprvkový seznam obsahující jeden symbol a dvojici podseznamů (* (+ 1 2) (- 1 2))
Poslední dva seznamy mají v Elispu zvláštní význam, protože jejich první element představuje symbol reprezentující primitivní (základní) funkci. Programovací jazyk LISP by tento seznam zpracoval tak, že by funkci zavolal s tím, že jí jako parametry předá všechny další prvky seznamu (případné podseznamy se nejdříve rekurzivně vyhodnotí naprosto stejným způsobem – ostatně toto vyhodnocování je základ celého REPLu).
10. Tečka-dvojice: základ pro tvorbu složitějších datových struktur
V předchozí kapitole jsme si řekli, že programovací jazyk LISP je založen na zpracování seznamů. Jak jsou však seznamy uloženy v operační paměti počítače a jak s nimi interpretry tohoto jazyka pracují? Základní interní strukturou, která je však přímo dostupná i programátorům aplikací v jazyce LISP, je takzvaná tečka-dvojice (dotted-pair). Tuto strukturu si můžeme představit jako dvojici ukazatelů, přičemž každý z těchto ukazatelů může obsahovat adresu atomu, adresu další tečka-dvojice nebo speciální hodnotu nil odpovídající v céčku hodnotě NULL či v Javě hodnotě null, tj. jedná se o speciální hodnotu, která interpretru říká, že daný ukazatel neobsahuje žádný odkaz.
Tečka-dvojici lze v LISPovských programech zapisovat formou dvojice výrazů (takzvaných S-výrazů zmíněných v úvodních kapitolách) oddělených tečkou, které jsou uzavřeny do kulatých závorek (i když je pravda, že se s tečka-dvojicemi v reálných programech příliš často nesetkáme, především z důvodu nepřehledného zápisu s velkým množstvím závorek):
(1.2) (1.nil) (A.(B.C)) (A.(B.nil)) ((A.B).C) ((A.B).(C.D)) (ABC.DEF) ((ABC.(DEF.UVW)).XYZ)
Pro přístup k informaci (atomu či další tečka dvojici), na kterou odkazuje první ukazatel tečka dvojice, se používá primitivní funkce car, a pro přístup k informaci, na níž se odkazuje druhý ukazatel, lze použít funkci cdr (pozor na to, že Elisp rozlišuje mezi malými a velkými písmeny, na rozdíl od některých dalších dialektů LISPu).
Pomocí tečka-dvojic je možné vytvořit klasický seznam následujícím způsobem: první ukazatel každé n-té tečka-dvojice odkazuje na n-tý prvek seznamu (například atom), druhý ukazatel se odkazuje na další (n plus první) tečka-dvojici. Speciálním případem je poslední tečka-dvojice, jejíž druhý ukazatel obsahuje výše uvedenou speciální hodnotu nil. Z následujícího příkladu (obsahujícího ekvivalentní datové struktury) je patrné, že použití syntaxe pro zápis seznamů je přehlednější a současně i mnohem kratší než explicitní zápis tečka-dvojic; ovšem právě znalost vnitřní reprezentace seznamů pomocí tečka-dvojic nám umožňuje pochopit, jak pracují některé základní funkce, včetně již zmíněných funkcí car a cdr:
; seznam zapsaný pomocí tečka-dvojic (1.(2.(3.(4.(5.nil))))) ; běžný způsob zápisu seznamu (1 2 3 4 5)
; interní struktura seznamu v paměti ; . ; / \ ; 1 . ; / \ ; 2 . ; / \ ; 3 . ; / \ ; 4 . ; / \ ; 5 nil
Poznamenejme, že další struktury vytvořené pomocí rekurzivně zanořených tečka-dvojic není možné převést na běžné seznamy. Například jednoduchý binární strom se třemi úrovněmi a čtyřmi listy lze reprezentovat buď pomocí tečka-dvojic (v paměti se vytvoří skutečná obdoba binárního stromu), popř. je možné tuto datovou strukturu „simulovat“ pomocí seznamů (ovšem v tomto případě bude paměťová náročnost nepatrně vyšší kvůli nutnosti ukončení všech podseznamů tečka dvojicí obsahující ve svém druhém ukazateli hodnotu nil):
; binární strom se třemi úrovněmi a čtyřmi listy vytvořený pomocí tečka dvojic ((A.B).(C.D)) ; interní podoba této struktury v operační paměti: ; . ; / \ ; . . ; / \ / \ ; A B C D ; binární strom vytvořený pomocí LISPovských seznamů ((A B) (C D)) ; interní podoba této struktury v operační paměti: ; . ; / \ ; / \ ; / \ ; / \ ; . . ; / \ / \ ; A . . nil ; / \ / \ ; B nil C . ; / \ ; D nil
11. Základní funkce pro konstrukci seznamů a pro přístup k prvkům seznamů
Jednou ze základních funkcí, která se objevila už v původním návrhu LISPu, je funkce nazvaná cons. Této funkci se předají dvě hodnoty (atomy či strukturované hodnoty) a výsledkem bude tečka dvojice:
(print (cons 1 2)) (1 . 2) (print (cons 1 (cons 2 3))) (1 2 . 3) (print '((1 . 2) . (3 . 4))) ((1 . 2) 3 . 4)
Vhodnou volbou argumentů funkce cons lze vytvořit seznam (viz předchozí kapitolu):
; this is proper list (print (cons 1 (cons 2 (cons 3 nil)))) (1 2 3) ; this is proper list (print (cons 1 (cons 2 (cons 3 ())))) (1 2 3)
Výše dva uvedené příklady sice skutečně vedou k vytvoření seznamu, ovšem jejich zápis je velmi dlouhý a zbytečně pracný. Seznamy lze zkonstruovat i jinak, a to konkrétně funkcí list, která všechny své parametry (libovolný počet) vloží do nového seznamu:
(print (list 1 2 3 4)) (1 2 3 4)
Seznam můžeme přiřadit k proměnné, například k proměnné a:
; create list and assign it to symbol ; (=variable) (setq a '(1 2 3 4))
Dále máme k dispozici funkce car a cdr vracející první prvek resp. všechny prvky kromě prvního. Existují i další variace, například funkce cadr odpovídající (car (cdr …)) či cddr odpovídající (cdr (cdr …)):
; get the first item (print (car a)) 1 ; get the rest of a list (print (cdr a)) (2 3 4) ; combination of car+cdr (print (cadr a)) 2 ; combination of cdr+cdr (print (cddr a)) (3 4)
12. Definice vlastních funkcí
Podobně jako u každého dialektu programovacího jazyka LISP, i v případě Elispu se program skládá především z funkcí. Ty mohou být anonymní (nepojmenované) či naopak pojmenované. Nejprve se zabývejme pojmenovanými funkcemi, protože ty se chovají prakticky stejně, jako běžné funkce v jiných programovacích jazycích. Pojmenované funkce se definují pomocí defun (zkratka od „define function“), za nímž následuje jméno funkce. Každá funkce může mít libovolný počet parametrů, jejichž jména se uvádí v seznamu za pojmenováním funkce. Poslední částí formy defun je tělo funkce, přičemž po zavolání funkce se vyhodnocená forma vrátí jako její výsledek (nikde se tedy nezapisuje slovo „return“ ani nic podobného):
; one-liner function (defun add (x y) (+ x y))
Přehlednější je však zápis definice funkce na více řádků. První řádek obsahuje jméno, druhý pojmenované parametry, další řádky pak tělo funkce:
; function written on more lines (defun mul (x y) (* x y)) ; function written on more lines (defun div (x y) (/ x y))
Zavolání funkce je jednoduché – používá se stále ten samý formát seznamu, na jehož prvním místě je jméno funkce a za ním následují parametry:
; test functions (print (add 1 2)) (print (mul 6 7)) (print (div 10 3))
13. Funkce s nepovinnými parametry
V Elispu se můžeme setkat s velkým množstvím funkcí, které mají nepovinné parametry. Tyto parametry jsou od parametrů povinných odděleny pomocí klauzule &optional. Příkladem může být funkce pro součet dvou nebo tří číselných hodnot (samozřejmě se jedná o dosti umělý příklad):
(defun add3
(x y &optional z)
(if z
(+ x y z)
(+ x y)))
Funkci si můžeme vyzkoušet:
(add3 1 2 3) 6 (add3 1 2) 3 (add3 1) Wrong number of arguments: (lambda (x y &optional z) (if z (+ x y z) (+ x y))), 1
V posledním příkladu je ukázáno, že první dva parametry jsou skutečně povinné.
14. Funkce vyššího řádu
Funkce jsou plnoprávnými datovými typy, takže je lze přiřadit do proměnné atd. V Elispu pouze nastává jeden problém, protože interně jsou ke každému symbolu (například ke jménu funkce) přiřazeny čtyři komponenty (nazývané cells):
- Jméno symbolu tak, jak je zobrazeno uživateli
- Hodnota (pokud se symbol používá jako proměnná)
- Funkce
- Seznam vlastností (property list) popsaný příště
Proto je nutné rozlišovat mezi hodnotou a funkcí. Jsou možné dvě řešení:
(defun add (x y) (+ x y)) (setq soucet 'add) (funcall soucet 10 20)
Druhé řešení pracuje přímo s funkcí, ovšem namísto setq používá fset:
(fset 'soucet2 'add) (soucet2 100 200)
Toto je hlavní rozdíl mezi Elispem a mnoha ostatními dialekty Lispu a bude vám možná zpočátku způsobovat problémy.
Elisp sice není, na rozdíl od Haskellu a částečně i Clojure, čistě funkcionální jazyk, nicméně i zde hrají při vývoji aplikací velkou roli funkce vyššího řádu, tj. funkce, které jako své parametry akceptují jiné funkce popř. dokonce vrací (nové) funkce jako svoji návratovou hodnotu. Mezi dvě základní funkce vyššího řádu, které nalezneme prakticky ve všech dialektech programovacího jazyka Lisp, patří funkce nazvané mapcar a taktéž apply. Funkce mapcar jako svůj první parametr akceptuje jinou funkci (s jedním parametrem) a druhým parametrem musí být seznam. mapcar postupně aplikuje předanou funkci na jednotlivé prvky seznamu a vytváří tak seznam nový (modifikovaný). Podívejme se na jednoduchý příklad – aplikace funkce pro zvýšení hodnoty o jedničku na seznam:
; regular function (defun inc (x) (+ x 1)) ; use inc in higher order function (print (mapcar 'inc '(1 2 3))) (2 3 4)
Funkce apply se chová poněkud odlišně – aplikuje totiž nějakou funkci (svůj první parametr) na předaný seznam. Typický „školní“ příklad s binární funkcí + (tj. funkcí se dvěma parametry) může vypadat následovně:
; use + in higher order function (print (apply '+ '(1 2 3 4))) 10
Podobně je tomu například u funkce *:
; use * in higher order function (print (apply '* (number-sequence 1 6))) 720
Poslední zajímavou funkcí je cl-reduce, která postupně zpracovává prvky předaného seznamu a pomocí akumulátoru tvoří výslednou hodnotu:
(require 'cl-lib) (defun add (x y) (+ x y)) ; use add in higher order function reduce (print (cl-reduce 'add '(1 2 3 4)))
15. Anonymní funkce
Kromě pojmenovaných funkcí, které jsme si již představili v předchozích kapitolách, je možné v Elispu použít i funkce anonymní, tj. funkce, které nejsou navázány na žádné jméno. Pro tento účel se používá lambda výraz, podobně jako v každém ortodoxním Lispu (kromě PicoLispu). Podívejme se na typický příklad – budeme chtít ze vstupního seznamu vytvořit výstupní seznam s hodnotami o jedničku zvýšenými. Pro něco tak jednoduchého asi nemá smysl si vytvářet novou pojmenovanou funkci, ale použijeme přímo funkci anonymní:
; anonymous function used in higher order function (print (mapcar (lambda (x) (+ x 1) ) '(1 2 3 4))) 10
Zajímá vás řada n2?:
; anonymous function used in higher order function (print (mapcar (lambda (x) (* x x)) (number-sequence 1 10)) ) (1 4 9 16 25 36 49 64 81 100)
16. Výpočet faktoriálu realizovaný funkcí vyššího řádu
Funkce vyššího řádu lze použít i pro přepis výpočtu faktoriálu. Ten lze přepsat s využitím funkce apply a taktéž generátoru sekvence čísel number-sequence (ten zhruba odpovídá Pythonovskému range, ovšem generuje se i poslední mezní hodnota):
; higher order function in other (regular) function (defun factorial (n) (apply '* (number-sequence 1 n)))
Otestování je snadné:
(print (factorial 10))
Samozřejmě si můžeme vypsat sekvenci faktoriálu pro vstupní hodnoty n=1, n=2 atd.:
; anonymous function used in higher order function (print (mapcar 'factorial (number-sequence 0 10))) (1 1 2 6 24 120 720 5040 40320 362880 3628800)
Nebo celý výpočet napsat na jediný řádek s využitím dvou funkcí vyššího řádu a jedné anonymní funkce:
; anonymous function used in higher order function (print (mapcar (lambda (n) (apply '* (number-sequence 1 n) )) (number-sequence 1 10)) ) (1 2 6 24 120 720 5040 40320 362880 3628800)
17. Repositář s demonstračními příklady
Zdrojové kódy většiny dnes popsaných demonstračních příkladů byly uloženy do Git repositáře dostupného na adrese https://github.com/tisnik/elisp-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem stále velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:

Všechny příklady se mohou spouštět z příkazové řádky následujícím způsobem:
emacs --script priklad1.el
18. Guile Emacs
Pro zajímavost se v dnešním článku musíme zmínit o projektu nazvaném Guile Emacs. Název tohoto projektu může být poněkud matoucí, protože se ve skutečnosti nejedná o snahu nahradit Emacs Lisp jazykem Scheme (resp. jeho konkrétní implementací pojmenovanou GNU Guile), ale o zajištění, aby byly zdrojové kódy napsané v Elispu překládány stejným způsobem (podobným překladačem), jako je tomu v případě Guile. Výsledkem by měl být rychlejší běh jak samotného Emacsu, tak i jeho modulů, což může být zajímavé pro rozsáhlejší moduly typu org-mode, webového prohlížeče atd. Navíc se díky použití překladače Guile otevírá možnost rozšíření možností samotného Elispu o vlastnosti podporované v Guile. Dále by mělo být možné psát moduly buď v Elispu nebo přímo v Guile (které je sice taktéž založeno na LISPovském dialektu, ale jedná se o matematicky čistější implementaci, což některým programátorům může vyhovovat). Bližší informace o tomto projektu je možné nalézt na EmacsWiki, konkrétně na stránce https://www.emacswiki.org/emacs/GuileEmacs.
19. Literatura
- McCarthy
„Recursive functions of symbolic expressions and their computation by machine, part I“
1960 - Guy L. Steele
„History of Scheme“
2006, Sun Microsystems Laboratories - Kolář J., Muller K.:
„Speciální programovací jazyky“
Praha 1981 - „AutoLISP Release 9, Programmer's reference“
Autodesk Ltd., October 1987 - „AutoLISP Release 10, Programmer's reference“
Autodesk Ltd., September 1988 - McCarthy, John; Abrahams, Paul W.; Edwards, Daniel J.; Hart, Timothy P.; Levin, Michael I.
„LISP 1.5 Programmer's Manual“
MIT Press. ISBN 0 262 130 1 1 4 - Carl Hewitt; Peter Bishop and Richard Steiger
„A Universal Modular Actor Formalism for Artificial Intelligence“
1973 - Feiman, J.
„The Gartner Programming Language Survey (October 2001)“
Gartner Advisory - Harold Abelson, Gerald Jay Sussman, Julie Sussman:
Structure and Interpretation of Computer Programs
MIT Press. 1985, 1996 (a možná vyšel i další přetisk) - Paul Graham:
On Lisp
Prentice Hall, 1993
Dostupné online na stránce http://www.paulgraham.com/onlisptext.html
20. Odkazy na Internetu
- Evil (Emacs Wiki)
https://www.emacswiki.org/emacs/Evil - Evil (na GitHubu)
https://github.com/emacs-evil/evil - Evil (na stránkách repositáře MELPA)
https://melpa.org/#/evil - Evil Mode: How I Switched From VIM to Emacs
https://blog.jakuba.net/2014/06/23/evil-mode-how-to-switch-from-vim-to-emacs.html - GNU Emacs (home page)
https://www.gnu.org/software/emacs/ - GNU Emacs (texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?GnuEmacs - An Introduction To Using GDB Under Emacs
http://tedlab.mit.edu/~dr/gdbintro.html - An Introduction to Programming in Emacs Lisp
https://www.gnu.org/software/emacs/manual/html_node/eintr/index.html - 27.6 Running Debuggers Under Emacs
https://www.gnu.org/software/emacs/manual/html_node/emacs/Debuggers.html - GdbMode
http://www.emacswiki.org/emacs/GdbMode - Emacs (Wikipedia)
https://en.wikipedia.org/wiki/Emacs - Emacs timeline
http://www.jwz.org/doc/emacs-timeline.html - Emacs Text Editors Family
http://texteditors.org/cgi-bin/wiki.pl?EmacsFamily - Vrapper aneb spojení možností Vimu a Eclipse
https://mojefedora.cz/vrapper-aneb-spojeni-moznosti-vimu-a-eclipse/ - Vrapper aneb spojení možností Vimu a Eclipse (část 2: vyhledávání a nahrazování textu)
https://mojefedora.cz/vrapper-aneb-spojeni-moznosti-vimu-a-eclipse-cast-2-vyhledavani-a-nahrazovani-textu/ - Emacs/Evil-mode – A basic reference to using evil mode in Emacs
http://www.aakarshnair.com/posts/emacs-evil-mode-cheatsheet - From Vim to Emacs+Evil chaotic migration guide
https://juanjoalvarez.net/es/detail/2014/sep/19/vim-emacsevil-chaotic-migration-guide/ - Introduction to evil-mode {video)
https://www.youtube.com/watch?v=PeVQwYUxYEg - EINE (Emacs Wiki)
http://www.emacswiki.org/emacs/EINE - EINE (Texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?EINE - ZWEI (Emacs Wiki)
http://www.emacswiki.org/emacs/ZWEI - ZWEI (Texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?ZWEI - Zmacs (Wikipedia)
https://en.wikipedia.org/wiki/Zmacs - Zmacs (Texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?Zmacs - TecoEmacs (Emacs Wiki)
http://www.emacswiki.org/emacs/TecoEmacs - Micro Emacs
http://www.emacswiki.org/emacs/MicroEmacs - Micro Emacs (Wikipedia)
https://en.wikipedia.org/wiki/MicroEMACS - EmacsHistory
http://www.emacswiki.org/emacs/EmacsHistory - Seznam editorů s ovládáním podobným Emacsu či kompatibilních s příkazy Emacsu
http://www.finseth.com/emacs.html - evil-numbers
https://github.com/cofi/evil-numbers - Debuggery a jejich nadstavby v Linuxu (1.část)
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu/ - Debuggery a jejich nadstavby v Linuxu (2.část)
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-2-cast/ - Debuggery a jejich nadstavby v Linuxu (3): Nemiver
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-3-nemiver/ - Debuggery a jejich nadstavby v Linuxu (4): KDbg
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-4-kdbg/ - Debuggery a jejich nadstavby v Linuxu (5): ladění aplikací v editorech Emacs a Vim
https://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-5-ladeni-aplikaci-v-editorech-emacs-a-vim/ - Org mode
https://orgmode.org/ - The Org Manual
https://orgmode.org/manual/index.html - Kakoune (modální textový editor)
http://kakoune.org/ - Vim-style keybinding in Emacs/Evil-mode
https://gist.github.com/troyp/6b4c9e1c8670200c04c16036805773d8 - Emacs – jak začít
http://www.abclinuxu.cz/clanky/navody/emacs-jak-zacit - Programovací jazyk LISP a LISP machines
https://www.root.cz/clanky/programovaci-jazyk-lisp-a-lisp-machines/ - Evil-surround
https://github.com/emacs-evil/evil-surround - Spacemacs
http://spacemacs.org/ - Lisp: Common Lisp, Racket, Clojure, Emacs Lisp
http://hyperpolyglot.org/lisp - Common Lisp, Scheme, Clojure, And Elisp Compared
http://irreal.org/blog/?p=725 - Does Elisp Suck?
http://irreal.org/blog/?p=675 - Emacs pro mírně pokročilé (9): Elisp
https://www.root.cz/clanky/emacs-elisp/ - If I want to learn lisp, are emacs and elisp a good choice?
https://www.reddit.com/r/emacs/comments/2m141y/if_i_want_to_learn_lisp_are_emacs_and_elisp_a/ - Clojure(Script) Interactive Development Environment that Rocks!
https://github.com/clojure-emacs/cider - An Introduction to Emacs Lisp
https://harryrschwartz.com/2014/04/08/an-introduction-to-emacs-lisp.html - Emergency Elisp
http://steve-yegge.blogspot.com/2008/01/emergency-elisp.html - Racket
https://racket-lang.org/ - The Racket Manifesto
http://felleisen.org/matthias/manifesto/ - MIT replaces Scheme with Python
https://www.johndcook.com/blog/2009/03/26/mit-replaces-scheme-with-python/ - Adventures in Advanced Symbolic Programming
http://groups.csail.mit.edu/mac/users/gjs/6.945/ - Why MIT Switched from Scheme to Python (2009)
https://news.ycombinator.com/item?id=14167453 - Starodávná stránka XLispu
http://www.xlisp.org/ - AutoLISP
https://en.wikipedia.org/wiki/AutoLISP - Seriál PicoLisp: minimalistický a výkonný interpret Lispu
https://www.root.cz/serialy/picolisp-minimalisticky-a-vykonny-interpret-lispu/ - Common Lisp
https://common-lisp.net/ - Getting Going with Common Lisp
https://cliki.net/Getting%20Started - Online Tutorial (Common Lisp)
https://cliki.net/online%20tutorial - Guile Emacs
https://www.emacswiki.org/emacs/GuileEmacs - Guile Emacs History
https://www.emacswiki.org/emacs/GuileEmacsHistory - Guile is a programming language
https://www.gnu.org/software/guile/ - MIT Scheme
http://groups.csail.mit.edu/mac/projects/scheme/ - SIOD: Scheme in One Defun
http://people.delphiforums.com/gjc//siod.html - CommonLispForEmacs
https://www.emacswiki.org/emacs/CommonLispForEmacs - Elisp: print, princ, prin1, format, message
http://ergoemacs.org/emacs/elisp_printing.html




































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}
{kind=link}