
Obsah
1. Úpravy Emacsu s Emacs Lisp: dokončení popisu Emacs Lispu
3. Operace nad sekvencemi: predikát, kopie, získání prvku a délky sekvence
5. Další funkce určené pro práci s vektory
6. Základní funkce pro práci s poli
9. Základní vlastnosti řetězců
12. Nahrazení části řetězce jiným obsahem
14. Konstruktor hešovacích tabulek
15. Funkce pro práci s hešovacími tabulkami, řešení kolize klíčů
17. Asociativní seznamy a seznamy vlastností
18. Repositář s demonstračními příklady
1. Úpravy Emacsu s Emacs Lisp: dokončení popisu Emacs Lispu
Na předchozí čtyři články, v nichž jsme se seznámili jak se základy programovacího jazyka Emacs Lisp [1] [2], tak i s užitečným makrem cl-loop a s knihovnou Dash, dnes navážeme. Popíšeme si totiž všechny další strukturované datové typy, s nimiž se v tomto programovacím jazyce můžeme setkat. Jedná se zejména o vektory a taktéž o řetězce, které mají hodně společného. S řetězci samozřejmě souvisí funkce pro vyhledání podle regulárního výrazu či náhrada na základě regulárního výrazu. Nesmíme ovšem zapomenout ani na velmi užitečné hešovací tabulky, asociativní seznamy a seznamy vlastností.
2. Sekvence – seznamy a pole
V Emacs Lispu se setkáme s pojmem „sekvence“. Jedná se o obecnější označení seznamů (list) a polí (array), přičemž seznamy již známe a víme, že jsou plnohodnotným LISPovským datovým typem (navíc díky homoikonicitě je samotný program reprezentován seznamem). Pole ovšem není konkrétním datovým typem, ale označením pro skupinu dalších typů, konkrétně vektorů (vector), řetězců (string) a speciálních typů, mezi něž patří především bool-vector a char-table. Vztahy mezi obecnými typy a typy konkrétními je naznačen na následujícím obrázku:
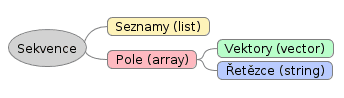
Obrázek 1: Hierarchie sekvenčních datových typů v Emacs Lispu. Ve skutečnosti existují čtyři konkrétní implementace polí, protože k vektorům a řetězcům je možné přidat i poněkud speciální typy bool-vector a char-table zmíněné v předchozím textu.
V následující tabulce jsou vypsány některé společné vlastnosti ale i obecně platné rozdíly mezi seznamy a poli (vektory, řetězci):
| Vlastnost | Seznamy | Vektory | Řetězce |
|---|---|---|---|
| typ struktury | heterogenní | heterogenní | je homogenní |
| přístup k prvku přes index | O(n), lineární | O(1), konstantní | O(1), konstantní |
| index prvního prvku | 0 | 0 | 0 |
| přidání prvku na začátek struktury | lze | nelze | nelze |
| odebrání prvního prvku ze struktury | lze | nelze | nelze |
| konstruktor | '(prvek prvek prvek} | [prvek prvek prvek] | „řetězec“ |
| velikost při konstrukci | nemusí být známá | musí být známá | musí být známá |
3. Operace nad sekvencemi: predikát, kopie, získání prvku a délky sekvence
Pro práci se všemi typy sekvencí (seznam, vektor, řetězec, …) existuje čtveřice obecných funkcí. Především se jedná o test, zda je nějaká hodnota libovolnou sekvencí, dále o funkci pro zjištění délky sekvence, přístup k n-tému prvku přes jeho index a konečně o funkci vytvářející kopii sekvence stejného typu:
| Funkce | Stručný popis |
|---|---|
| sequencep | predikát vracející t pouze tehdy, pokud je mu předána libovolná sekvence |
| length | výpočet délky sekvence (funkce může být relativně pomalá pro seznamy) |
| elt | vrátí n-tý prvek v sekvenci, pokud má samozřejmě sekvence alespoň n prvků (indexuje se od nuly) |
| copy-sequence | kopie sekvence, ovšem nikoli hluboká kopie (ozřejmíme si později) |
Nejprve si vytvořme tři sekvence, každou jiného typu – seznam, vektor, řetězec:
(setq l1 '(1 2 3 4 5)) (setq v1 [1 2 3 4 5]) (setq s1 "Hello")
Dále si vytvoříme tři prázdné sekvence:
(setq l2 '()) (setq v2 []) (setq s2 "")
Nyní můžeme predikátem sequencep snadno zjistit, že všech šest proměnných referencuje nějakou sekvenci:
(print (sequencep l1)) (print (sequencep v1)) (print (sequencep s1)) (print (sequencep l2)) (print (sequencep v2)) (print (sequencep s2))
Výsledek:
t t t t t t
Zjištění délky sekvencí funkcí length:
(print (length l1)) (print (length v1)) (print (length s1)) (print (length l2)) (print (length v2)) (print (length s2))
Výsledek:
5 5 5 0 0 0
Přístup ke třetímu, popř. ke 101 prvku (ten neexistuje):
(print (elt l1 2)) (print (elt v1 2)) (print (elt s1 2)) (print (elt l2 100)) (print (elt v2 100)) (print (elt s2 100))
S výsledky (povšimněte si, že prázdný seznam je zpracován speciálním způsobem, protože je roven nil):
3 3 108 nil Args out of range: [], 100
A konečně můžeme získat kopie sekvencí s využitím funkce copy-sequence:
(setq l1 '(1 2 3 4 5)) (setq v1 [1 2 3 4 5]) (setq s1 "Hello") (setq l2 (copy-sequence l1)) (setq v2 (copy-sequence v1)) (setq s2 (copy-sequence s1)) (print (sequencep l1)) (print (sequencep v1)) (print (sequencep s1)) (print (sequencep l2)) (print (sequencep v2)) (print (sequencep s2)) (print "-----------------------------------------") (print l1) (print v1) (print s1) (print l2) (print v2) (print s2)
Výsledky:
t t t t t t "-----------------------------------------" (1 2 3 4 5) [1 2 3 4 5] "Hello" (1 2 3 4 5) [1 2 3 4 5] "Hello"
4. Konstruktory vektorů
V této kapitole se nejprve zmíníme o základních vlastnostech takzvaných vektorů:
- Vektory obsahují uspořádanou sekvenci hodnot. Tato sekvence zachovává pořadí prvků určené uživatelem (na rozdíl od množin atd.)
- Prvky vektorů mohou být libovolného a od sebe odlišného typu, tj. jedná se o heterogenní datovou strukturu (na rozdíl od polí v některých jiných programovacích jazycích).
- Hodnotu prvku lze za určitých okolností měnit, vektor tedy není striktně neměnitelný (immutable).
- Prvky však nelze ani přidávat ani ubírat, takže tvar vektoru (shape) je zachován. Touto vlastností se vektory přibližují klasickým polím z jiných programovacích jazyků.
Konstrukci vektoru lze provést buď zápisem [prvek prvek prvek], nebo je možné použít jednu z funkcí pojmenovaných vector a make-vector:
| Funkce | Stručný popis funkce |
|---|---|
| vector | vytvoří vektor z předaných prvků |
| make-vector | vytvoří vektor opakováním zadaného prvku |
Podívejme se nyní na příklad, v němž je vytvořeno sedm vektorů, včetně vektoru prázdného a vektoru nehomogenního (s různými typy prvků):
(setq v1 [1 2 3 4 5]) (setq v2 []) (setq v3 (vector)) (setq v4 (vector 1 2 3 4 5)) (setq v5 (vector '1 :2 "3" '(4 5) [6 7])) (setq v6 (make-vector 10 "foo")) (setq v7 (make-vector 0 "foo"))
Výpis hodnot všech vektorů zajistí funkce print:
(print v1) (print v2) (print v3) (print v4) (print v5) (print v6) (print v7)
Výsledky:
[1 2 3 4 5] [] [] [1 2 3 4 5] [1 :2 "3" (4 5) [6 7]] ["foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo"] []
5. Další funkce určené pro práci s vektory
Mezi další funkce určené pro zpracování vektorů patří především tato čtveřice:
| Funkce | Stručný popis funkce |
|---|---|
| vectorp | test (predikát), zda je hodnota vektorem |
| vconcat | všechny prvky předaných sekvencí se transformují do vektoru |
| length | výpočet délky vektoru (již vlastně známe) |
| append | konverze vektoru na seznam s případným připojením prvku |
Všechny tyto funkce budou ukázány v následujících příkladech.
Vytvoříme tři sekvence, ovšem jen jedna sekvence bude vektorem:
(setq s1 '(1 2 3 4)) (setq v1 [1 2 3 4]) (setq n1 42) (setq str1 "Hello")
Použití predikátu vectorp:
(print (vectorp s1)) (print (vectorp v1)) (print (vectorp n1)) (print (vectorp str1))
Výsledky:
nil t nil nil
Vytvoření různých vektorů konstruktorem vector.
(setq v3 (vector)) (setq v4 (vector 1 2 3 4)) (setq v5 (vector '1 :2 "3" '(4 5) [6 7]))
Opětovné použití predikátu vectorp:
(print (vectorp v3)) (print (vectorp v4)) (print (vectorp v5))
Výsledky:
t t t
Použití funkce vconcat (povšimněte si různé struktury prvků):
(setq v1 (vconcat '(A B C) '(D E F))) (setq v2 (vconcat [A B C] '(D E F))) (setq v3 (vconcat '() [])) (setq v4 (vconcat [[1 2] [3 4]])) (setq v5 (vconcat '() [[1 2] [3 4]])) (print v1) (print v2) (print v3) (print v4) (print v5)
Výsledky (na nejvyšší úrovni byly původní struktury „zploštěny“):
[A B C D E F] [A B C D E F] [] [[1 2] [3 4]] [[1 2] [3 4]]
Převod různých vektorů na seznamy pomocí funkce append:
(setq v1 [1 2 3 4 5]) (setq v2 []) (setq v3 (vector)) (setq v4 (vector 1 2 3 4 5)) (setq v5 (vector '1 :2 "3" '(4 5) [6 7])) (setq v6 (make-vector 10 "foo")) (setq v7 (make-vector 0 "foo")) (print (append v1 nil)) (print (append v2 nil)) (print (append v3 nil)) (print (append v4 nil)) (print (append v5 nil)) (print (append v6 nil)) (print (append v7 nil))
Výsledky jsou nyní předvídatelné:
(1 2 3 4 5)
nil
nil
(1 2 3 4 5)
(1 :2 "3" (4 5) [6 7])
("foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo")
nil
6. Základní funkce pro práci s poli
Dalšími funkcemi, s nimiž se seznámíme, jsou funkce použitelné pro práci s poli, tj. především s vektory a s řetězci. Nejedná se tedy o funkce tak specializované, jako funkce popsané v předchozí kapitole, na druhou stranu ovšem nejsou tak obecné, jako funkce pro práci s libovolnou sekvencí:
| Funkce | Stručný popis funkce |
|---|---|
| arrayp | test (predikát), zda je hodnot nějakým polem |
| aref | získání reference na i-tý prvek v poli (indexace) |
| aset | zápis do i-tého prvku v poli |
| fillarray | vyplnění celého pole prvky se shodnou hodnotou |
Všechny čtyři výše popsané funkce si samozřejmě opět otestujeme:
(setq s1 '(1 2 3 4)) (setq v1 [1 2 3 4]) (setq n1 42) (setq str1 "Hello") ; otestování predikátu arrayp (print (arrayp s1)) (print (arrayp v1)) (print (arrayp n1)) (print (arrayp str1)) (print "-----------------------------------------") ; predikát pro vektory (setq v3 (vector)) (setq v4 (vector 1 2 3 4)) (setq v5 (vector '1 :2 "3" '(4 5) [6 7])) (print (arrayp v3)) (print (arrayp v4)) (print (arrayp v5))
Výsledky jsou předvídatelné:
nil t nil t "-----------------------------------------" t t t
Otestování funkce fillarray aplikované na vektor čísel a řetězec:
(setq v1 [1 2 3 4]) (setq str1 "Hello") (print v1) (print str1) (print "-----------------------------------------") (fillarray v1 0) (fillarray str1 ?*) (print v1) (print str1)
Výsledky:
[1 2 3 4] "Hello" "-----------------------------------------" [0 0 0 0] "*****"
7. Čtení a zápis prvků polí
Pro čtení prvků z pole se používá funkce aref, pro zápis (modifikaci) pole pak funkce aset. Těmto funkcím se nejdříve předá pole a posléze index prvku. Funkci aset samozřejmě ještě modifikovaná hodnota:
(setq v1 [1 2 3 4]) (setq str1 "Hello") (print v1) (print str1) (print "-----------------------------------------") (aset v1 1 99) (aset str1 0 ?*) (aset str1 4 ?!) (print v1) (print str1) (print "-----------------------------------------") (print(aref v1 0)) (print(aref str1 0)) (print(aref str1 1))
Výsledky:
[1 2 3 4] "Hello" "-----------------------------------------" [1 99 3 4] "*ell!" "-----------------------------------------" 1 42 101
8. Kopie seznamů a polí
S kopií seznamů a polí jsme se ve skutečnosti už seznámili, protože pro tento účel je možné použít univerzální funkci nazvanou copy-sequence. Ve chvíli, kdy jsou kopírované sekvence jednoúrovňové, nebývá s použitím této funkce spojen prakticky žádný problém:
(setq v1 [1 2 3 4 5]) (setq s1 "Hello") (setq v2 (copy-sequence v1)) (setq s2 (copy-sequence s1)) (print v1) (print s1) (print v2) (print s2)
Výsledky:
[1 2 3 4 5] "Hello" [1 2 3 4 5] "Hello"
V případě, že změníme prvek v původní sekvenci, nebude tato změna v kopiích nijak reflektována:
(aset v1 0 99) (aset s1 0 ??) (print v1) (print s1) (print v2) (print s2)
Výsledky:
[99 2 3 4 5] "?ello" [1 2 3 4 5] "Hello"
Zajímavější situace ovšem nastane, pokud je vstupní sekvence složitější o obsahuje například další vektory nebo řetězce:
(setq x [1 2 [3 4] [5 6]]) (setq y (copy-sequence x)) (print x) (print y)
Výsledky prozatím odpovídají předpokladům:
[1 2 [3 4] [5 6]] [1 2 [3 4] [5 6]]
Ovšem ve chvíli, kdy přes aref získáme referenci na vnořený seznam/řetězec a změníme ho pomocí aset, ukáže se, že původní i zkopírovaná sekvence obsahuje reference na shodné hodnoty:
(aset (aref x 2) 0 -1) (aset (aref x 2) 1 -1) (print x) (print y)
Z výsledků je patrné, že se „nenápadně“ změnila o hodnota sekvence y:
[1 2 [-1 -1] [5 6]] [1 2 [-1 -1] [5 6]]
9. Základní vlastnosti řetězců
Dalším typem pole jsou klasické řetězce. Interně se řetězce chovají prakticky stejně jako vektory celočíselných hodnot, což znamená, že vektory a řetězce mají velmi mnoho společných vlastností zmíněných ve čtvrté kapitole. Řetězce lze samozřejmě zkonstruovat s využitím řetězcového literálu popř. pomocí funkce string, které se předají buď jednotlivé znaky (zapisuje se před nimi prefix „?“) nebo celočíselné kódy jednotlivých znaků:
(setq s1 "Hello") (setq s2 (make-string 10 ?*)) (setq s3 (string ?a ?b ?c)) (setq s4 (string 64 65 32 95 96 32)) (print s1) (print s2) (print s3) (print s4)
Výsledky:
"Hello" "**********" "abc" "@A _` "
Užitečná je funkce concat vracející nový řetězec vytvořený spojením libovolného množství vstupních řetězců:
(print (concat s1 s2 s3 s4)) "Hello**********abc@A _` "
Nesmíme zapomenout ani na další velmi užitečnou funkci pojmenovanou substring. Jak již název této funkce napovídá, lze s ní vytvořit podřetězec zadáním indexu prvního a posledního znaku v řetězci zdrojovém. První znak v řetězci má index roven 0, podobně jako první prvek v seznamu nebo ve vektoru. Index může být kladný (počítá se od začátku řetězce) nebo záporný (počítá se od konce řetězce). Druhý index může mít hodnotu nil znamenající konec řetězce, popř. nemusí být uveden vůbec:
(setq s1 "Hello world") (print s1) (print (substring s1 6 11)) (print (substring s1 0 -6)) (print (substring s1 6 nil)) (print (substring s1 -5 nil)) (print (substring s1 -5)) ; kopie retezce, podobne copy-sequence (print (substring s1 0))
S výsledky:
"Hello world" "world" "Hello" "world" "world" "world" "Hello world"
10. Kódy znaků v Emacsu
V Emacsu je možné znaky reprezentovat buď hodnotami od 0 do 255 (unibyte) nebo hodnotami od 0 do 4194303 (0×3FFFFF), které dokážou reprezentovat libovolný ASCII znak či Unicode znak (multibyte). Posledních 128 hodnot má pak speciální význam, protože reprezentují osmibitové hodnoty s horním bitem nastaveným na jedničku (to je ovšem skutečně specialita, kterou se nyní nemusíme zabývat). Pokud se řetězce konstruují pomocí string, můžeme této funkci předat kódy znaků:
(setq s1 (string 64 65 32 95 96 32)) (print s1) "@A _` "
Popř. lze použít hexadecimální čísla (s poněkud neobvyklým zápisem):
(setq s2 (string #x40 #x41 #x20 #x60 #x20)) (print s2) "@A ` "
Vzhledem k dobré podpoře Unicode si samozřejmě můžeme vytvořit řetězec se znaky alfabety nebo použít kódy dalších znaků a paznaků:
(setq s2 (string #x03b1 #x03b2 #x03c9)) (print s2) "αβω"
11. Regulární výrazy
Emacs Lisp jakožto skriptovací jazyk, na němž je postaven plnohodnotný textový editor, samozřejmě podporuje i práci s regulárními výrazy. Základem je funkce nazvaná string-match, která se snaží nalézt ve vstupním řetězci první výskyt sekvence znaků, které odpovídají regulárnímu výrazu. Podporovány jsou jak základní operátory pro opakování tzv. atomů (?, +, *), tak i například kolekce znaků ([0–9]) a třídy znaků ([[:digit:]]). Podívejme se na jednoduchý příklad:
(setq s1 "Hello world 123456") (print s1) (print (string-match ".+" s1)) (print (string-match "xyz" s1)) (print (string-match "[0-9]+" s1)) (print (string-match "[[:digit:]]+" s1)) (print (string-match "[[:blank:]]" s1)) (print (string-match "[^A-Za-z]+" s1)) (print (string-match "[^A-Za-z ]+" s1))
Z výsledků je patrné, že tato funkce vrací index prvního výskytu popř. hodnotu nil v případě, že regulárnímu výrazu neodpovídá žádná část zdrojového řetězce:
"Hello world 123456" 0 nil 12 12 5 5 12
12. Nahrazení části řetězce jiným obsahem, rozdělení řetězce
Další užitečnou funkcí, která se při zpracování řetězců poměrně často používá, je funkce nazvaná replace-regexp-in-string. Tato funkce umožňuje ve vstupním řetězci nalézt sekvenci znaků, samozřejmě opět na základě nějakého regulárního výrazu, a následně tuto sekvenci nahradit předaným řetězcem. Vzhledem k tomu, že se obecně změní délka řetězce (což u polí není možné), je ve skutečnosti touto funkcí vrácen řetězec nový.
opět si ukažme jednoduchý příklad:
(setq s1 "Hello world 123456") (print s1) (print (replace-regexp-in-string "[0-9]+" "*" s1)) (print (replace-regexp-in-string "world" "Emacs" s1))
Výsledky:
"Hello world 123456" "Hello world *" "Hello Emacs 123456"
Poslední „řetězcovou“ funkcí, s níž se dnes seznámíme, je funkce split-string určená pro rozdělení řetězce na (několik) částí, a to v místě specifikovaného znaku. Výsledkem je seznam kratších řetězců:
(setq s1 "Hello world 123456") (print (split-string s1))
Výsledek:
("Hello" "world" "123456")
Použít lze i řídicí znaky, například znak pro konec řádku atd.:
(setq s2 "This\nis\nmultiline\nstring") (print s2) (print (split-string s2 "\n"))
Výsledek:
"This
is
multiline
string"
("This" "is" "multiline" "string")
13. Hešovací tabulky
Všechny prozatím popsané datové struktury reprezentovaly buď atomy nebo sekvenční (heterogenní) datové typy, v nichž byly všechny prvky adresovány celočíselným indexem (začínajícím od nuly). V praxi, tj. při psaní modulů pro Emacs, se ovšem velmi často setkáme i s hešovacími tabulkami, v nichž jsou uloženy dvojice klíč-hodnota, přičemž klíč nemusí být celočíselný (může být prakticky jakéhokoli typu podporovaného Emacs Lispem). Oproti ostatním heterogenním strukturovaným datovým typům se hešovací tabulky odlišují taktéž v tom ohledu, že se v nich nezachovává pořadí vložených prvků (to nám však u mnoha operací nemusí vadit a pokud ano, lze někdy použít asociativní seznamy nebo seznamy vlastností). Základní způsoby použití hešovacích tabulek je zmíněno v navazujících kapitolách.
14. Konstruktor hešovacích tabulek
Prázdná hešovací tabulka se vytvoří pomocí funkce pojmenované make-hash-table, které je možné v případě potřeby předat i další parametry popisující chování tzv. hešovací funkce, plánovanou kapacitu (počet prvků) a popř. i pravidla určující, kdy a do jaké míry se má hešovací tabulka zvětšit v případě, že již nestačí její kapacita. Ovšem při základním použití funkce pro vytvoření hešovací tabulky tyto údaje nepotřebujeme:
(setq hash1 (make-hash-table))
Mezi další nepovinné parametry patří například:
| Jméno | Význam |
|---|---|
| :test | funkce pro zjištění ekvivalence klíčů při zápisu/vyhledávání |
| :size | přibližná velikost hešovací tabulky (implicitně 65) |
| :rehash-size | míra zvětšení tabulky při jejím zaplnění |
| :rehash-threshold | desetinné číslo udávající práh, kdy je již tabulka považována za zaplněnou |
Alternativně je možné použít i vytvoření hešovací tabulky zápisem její „textové podoby“, tj. takovým způsobem, jakým se obsah hešovací tabulky vypisuje na standardní výstup funkcí print:
(setq hash2 #s(hash-table size 30 data (key1 val1 key2 val2 key3 val3)))
Samozřejmě si můžete pro větší přehlednost tento zápis rozepsat na více řádků:
(setq hash2
#s(hash-table
size 30
data (
key1 val1
key2 val2
key3 val3)))
15. Funkce pro práci s hešovacími tabulkami, řešení kolize klíčů
Pro práci s hešovacími tabulkami je v Emacs Lispu určeno několik funkcí, které jsou vypsány níže společně s jejich stručným popisem:
| Funkce | Stručný popis funkce |
|---|---|
| make-hash-table | vytvoření hešovací tabulky, již známe z předchozí kapitoly |
| gethash | vyhledání prvku v hešovací tabulce |
| puthash | vložení další dvojice klíč-hodnota do hešovací tabulky |
| remhash | odstranění dvojice klíče-hodnota z hešovací tabulky |
| clrhash | vymazání celého obsahu hešovací tabulky |
| maphash | bude popsána v navazující kapitole |
Při použití klíčů si musíme dát pozor na to, jaká funkce se volá pro zjištění, zda jsou klíče ekvivalentní. V níže uvedeném příkladu se nám stane, že řetězec „klic“ je použit dvakrát, protože výchozí porovnávací funkce nepovažuje dva řetězce se stejným obsahem ale jinou adresou za ekvivalentní:
(setq hash1 (make-hash-table)) (setq hash2 #s(hash-table size 30 data (key1 val1 key2 val2))) (print hash1) (print hash2) (puthash 'klic 'hodnota hash1) (puthash "klic" "hodnota" hash1) (print hash1) (puthash 'klic "jina hodnota" hash1) (print hash1) (puthash "klic" "uplne jina hodnota?" hash1) (print hash1)
Výsledky (shodné klíče jsou zvýrazněny):
#s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data ()) #s(hash-table size 30 test eql rehash-size 1.5 rehash-threshold 0.8 data (key1 val1 key2 300)) #s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data (klic hodnota "klic" "hodnota")) #s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data (klic "jina hodnota" "klic" "hodnota")) #s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data (klic "jina hodnota" "klic" "hodnota" "klic" "uplne jina hodnota?"))
Náprava je snadná – explicitní určení funkce použité pro porovnávání klíčů:
(setq hash3 (make-hash-table :test 'equal)) (puthash 'klic 'hodnota hash3) (puthash "klic" "hodnota" hash3) (print hash3) (puthash 'klic "jina hodnota" hash3) (print hash3) (puthash "klic" "uplne jina hodnota?" hash3)
Nyní je již vše v pořádku a prvek byl přepsán novou hodnotou:
#s(hash-table size 65 test equal rehash-size 1.5 rehash-threshold 0.8 data (klic hodnota "klic" "hodnota")) #s(hash-table size 65 test equal rehash-size 1.5 rehash-threshold 0.8 data (klic "jina hodnota" "klic" "hodnota")) #s(hash-table size 65 test equal rehash-size 1.5 rehash-threshold 0.8 data (klic "jina hodnota" "klic" "uplne jina hodnota?"))
16. Funkce maphash
Další funkcí použitou pro práci s hešovacími tabulkami je funkce nazvaná maphash. Jedná se o funkci vyššího řádu, která mapuje jinou uživatelem definovanou funkci na každou nalezenou dvojici klíč-hodnota. Funkce maphash kupodivu nevrací žádný výsledek, tj. ani výsledek mapování uživatelské funkce. Celé chování tedy závisí na vedlejších efektech:
(defun print-key-value (key value) (print (format "%s %d" (reverse key) (* 2 value)))) (setq hash1 (make-hash-table)) (print hash1) (puthash "one" 1 hash1) (puthash "two" 2 hash1) (puthash "three" 3 hash1) (puthash "four" 4 hash1) (print hash1) (maphash 'print-key-value hash1) (print hash1)
Podívejme se na výsledky předchozího skriptu.
Původní prázdná tabulka a naplněná tabulka:
#s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data ())
#s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data ("one" 1 "two" 2 "three" 3 "four" 4))
Výsledek aplikace funkce print-key-value:
"eno 2" "owt 4" "eerht 6" "ruof 8"
Původní tabulka nebyla funkcí maphash nijak dotčena:
#s(hash-table size 65 test eql rehash-size 1.5 rehash-threshold 0.8 data ("one" 1 "two" 2 "three" 3 "four" 4))
17. Asociativní seznamy a seznamy vlastností
Poslední dva strukturované datové typy, s nimiž se v dnešním článku seznámíme, jsou asociativní seznamy (alisp) a seznamy vlastností (property list). Asociativní seznamy jsou tvořeny sekvencí tečka dvojic, přičemž první hodnotu v tečka dvojici můžeme považovat za klíč (nemusí být unikátní):
(setq numbers '((one . 1) (two . 2) (three . 3)))
Pro nalezení tečka dvojice slouží funkce assoc a assq (při porovnávání klíče používá funkce eq, takže nebude pracovat korektně pro řetězce!):
(print (assoc 'one numbers)) (print (car (assoc 'one numbers))) (print (cdr (assoc 'one numbers))) (print (assoc 'two numbers)) (print (car (assoc 'two numbers))) (print (cdr (assoc 'two numbers))) (print (assq 'two numbers)) (print (car (assq 'two numbers))) (print (cdr (assq 'two numbers))) (print (assoc 'zero numbers))
Výsledky vyhledání:
(one . 1) one 1 (two . 2) two 2 (two . 2) two 2 nil
Vyhledávat lze i podle hodnoty, tj. na základě druhého prvku v tečka dvojicích:
(print (rassoc 1 numbers)) (print (car (rassoc 1 numbers))) (print (cdr (rassoc 1 numbers)))
Výsledky:
(one . 1) one 1
Hodnoty v tečka dvojicích mohou být jakékoli, lze tedy použít i běžná čísla:
(setq rnumbers '((1 . one) (2 . two) (3 . three))) (print (assoc 1 rnumbers)) (print (car (assoc 1 rnumbers))) (print (cdr (assoc 1 rnumbers))) (print (assoc 2 rnumbers)) (print (car (assoc 2 rnumbers))) (print (cdr (assoc 2 rnumbers))) (print (assoc 0 rnumbers)) (print (rassoc 'two rnumbers)) (print (car (rassoc 'two rnumbers))) (print (cdr (rassoc 'two rnumbers)))
Výsledky:
(1 . one) 1 one (2 . two) 2 two nil (2 . two) 2 two
Setkat se můžeme i s takzvanými seznamy vlastností (property list). Jedná se o běžné seznamy se sudým počtem prvků, přičemž sudý prvek je jméno vlastnosti a prvek lichý hodnota vlastnosti (indexuje se od 0). Pro přečtení vlastnosti slouží funkce plist-get, pro otestování, zda vlastnost vůbec existuje, pak funkce plist-member (tato druhá funkce existuje pro jednoznačné rozhodnutí o existenci vlastnosti, i když je její hodnota nil):

(setq numbers '(one 1 two 2 three 3)) (print (plist-get numbers 'zero)) (print (plist-get numbers 'one)) (print (plist-get numbers 'two)) (print (plist-member numbers 'zero)) (print (plist-member numbers 'one)) (print (plist-member numbers 'two)) (print "---------------------------------") (setq numbers (plist-put numbers 'zero 0)) (print (plist-get numbers 'zero))
Výsledky:
nil 1 2 nil (one 1 two 2 three 3) (two 2 three 3) "---------------------------------" 0
18. Repositář s demonstračními příklady
Zdrojové kódy většiny dnes popsaných demonstračních příkladů byly uloženy do Git repositáře dostupného na adrese https://github.com/tisnik/elisp-examples (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem stále velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:
$ emacs -script jméno_skriptu.el
19. Literatura
- McCarthy
„Recursive functions of symbolic expressions and their computation by machine, part I“
1960 - Guy L. Steele
„History of Scheme“
2006, Sun Microsystems Laboratories - Kolář J., Muller K.:
„Speciální programovací jazyky“
Praha 1981 - „AutoLISP Release 9, Programmer's reference“
Autodesk Ltd., October 1987 - „AutoLISP Release 10, Programmer's reference“
Autodesk Ltd., September 1988 - McCarthy, John; Abrahams, Paul W.; Edwards, Daniel J.; Hart, Timothy P.; Levin, Michael I.
„LISP 1.5 Programmer's Manual“
MIT Press. ISBN 0 262 130 1 1 4 - Carl Hewitt; Peter Bishop and Richard Steiger
„A Universal Modular Actor Formalism for Artificial Intelligence“
1973 - Feiman, J.
„The Gartner Programming Language Survey (October 2001)“
Gartner Advisory - Harold Abelson, Gerald Jay Sussman, Julie Sussman:
Structure and Interpretation of Computer Programs
MIT Press. 1985, 1996 (a možná vyšel i další přetisk) - Paul Graham:
On Lisp
Prentice Hall, 1993
Dostupné online na stránce http://www.paulgraham.com/onlisptext.html - David S. Touretzky
Common LISP: A Gentle Introduction to Symbolic Computation (Dover Books on Engineering)
- Peter Norvig
Paradigms of Artificial Intelligence Programming: Case Studies in Common Lisp - Patrick Winston, Berthold Horn
Lisp (3rd Edition)
ISBN-13: 978–0201083194, ISBN-10: 0201083191 - Matthias Felleisen, David Van Horn, Dr. Conrad Barski
Realm of Racket: Learn to Program, One Game at a Time!
ISBN-13: 978–1593274917, ISBN-10: 1593274912
20. Odkazy na Internetu
- Elisp: Sequence: List, Array
http://ergoemacs.org/emacs/elisp_list_vs_vector.html - Elisp: Property List
http://ergoemacs.org/emacs/elisp_property_list.html - Elisp: Hash Table
http://ergoemacs.org/emacs/elisp_hash_table.html - Elisp: Association List
http://ergoemacs.org/emacs/elisp_association_list.html - The mapcar Function (An Introduction to Programming in Emacs Lisp)
https://www.gnu.org/software/emacs/manual/html_node/eintr/mapcar.html - Anaphoric macro
https://en.wikipedia.org/wiki/Anaphoric_macro - Some Common Lisp Loop Macro Examples
https://www.youtube.com/watch?v=3yl8o6r_omw - A Guided Tour of Emacs
https://www.gnu.org/software/emacs/tour/ - The Roots of Lisp
http://www.paulgraham.com/rootsoflisp.html - Evil (Emacs Wiki)
https://www.emacswiki.org/emacs/Evil - Evil (na GitHubu)
https://github.com/emacs-evil/evil - Evil (na stránkách repositáře MELPA)
https://melpa.org/#/evil - Evil Mode: How I Switched From VIM to Emacs
https://blog.jakuba.net/2014/06/23/evil-mode-how-to-switch-from-vim-to-emacs.html - GNU Emacs (home page)
https://www.gnu.org/software/emacs/ - GNU Emacs (texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?GnuEmacs - An Introduction To Using GDB Under Emacs
http://tedlab.mit.edu/~dr/gdbintro.html - An Introduction to Programming in Emacs Lisp
https://www.gnu.org/software/emacs/manual/html_node/eintr/index.html - 27.6 Running Debuggers Under Emacs
https://www.gnu.org/software/emacs/manual/html_node/emacs/Debuggers.html - GdbMode
http://www.emacswiki.org/emacs/GdbMode - Emacs (Wikipedia)
https://en.wikipedia.org/wiki/Emacs - Emacs timeline
http://www.jwz.org/doc/emacs-timeline.html - Emacs Text Editors Family
http://texteditors.org/cgi-bin/wiki.pl?EmacsFamily - Vrapper aneb spojení možností Vimu a Eclipse
https://mojefedora.cz/vrapper-aneb-spojeni-moznosti-vimu-a-eclipse/ - Vrapper aneb spojení možností Vimu a Eclipse (část 2: vyhledávání a nahrazování textu)
https://mojefedora.cz/vrapper-aneb-spojeni-moznosti-vimu-a-eclipse-cast-2-vyhledavani-a-nahrazovani-textu/ - Emacs/Evil-mode – A basic reference to using evil mode in Emacs
http://www.aakarshnair.com/posts/emacs-evil-mode-cheatsheet - From Vim to Emacs+Evil chaotic migration guide
https://juanjoalvarez.net/es/detail/2014/sep/19/vim-emacsevil-chaotic-migration-guide/ - Introduction to evil-mode {video)
https://www.youtube.com/watch?v=PeVQwYUxYEg - EINE (Emacs Wiki)
http://www.emacswiki.org/emacs/EINE - EINE (Texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?EINE - ZWEI (Emacs Wiki)
http://www.emacswiki.org/emacs/ZWEI - ZWEI (Texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?ZWEI - Zmacs (Wikipedia)
https://en.wikipedia.org/wiki/Zmacs - Zmacs (Texteditors.org)
http://texteditors.org/cgi-bin/wiki.pl?Zmacs - TecoEmacs (Emacs Wiki)
http://www.emacswiki.org/emacs/TecoEmacs - Micro Emacs
http://www.emacswiki.org/emacs/MicroEmacs - Micro Emacs (Wikipedia)
https://en.wikipedia.org/wiki/MicroEMACS - EmacsHistory
http://www.emacswiki.org/emacs/EmacsHistory - Seznam editorů s ovládáním podobným Emacsu či kompatibilních s příkazy Emacsu
http://www.finseth.com/emacs.html - evil-numbers
https://github.com/cofi/evil-numbers - Debuggery a jejich nadstavby v Linuxu (1.část)
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu/ - Debuggery a jejich nadstavby v Linuxu (2.část)
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-2-cast/ - Debuggery a jejich nadstavby v Linuxu (3): Nemiver
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-3-nemiver/ - Debuggery a jejich nadstavby v Linuxu (4): KDbg
http://fedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-4-kdbg/ - Debuggery a jejich nadstavby v Linuxu (5): ladění aplikací v editorech Emacs a Vim
https://mojefedora.cz/debuggery-a-jejich-nadstavby-v-linuxu-5-ladeni-aplikaci-v-editorech-emacs-a-vim/ - Org mode
https://orgmode.org/ - The Org Manual
https://orgmode.org/manual/index.html - Kakoune (modální textový editor)
http://kakoune.org/ - Vim-style keybinding in Emacs/Evil-mode
https://gist.github.com/troyp/6b4c9e1c8670200c04c16036805773d8 - Emacs – jak začít
http://www.abclinuxu.cz/clanky/navody/emacs-jak-zacit - Programovací jazyk LISP a LISP machines
https://www.root.cz/clanky/programovaci-jazyk-lisp-a-lisp-machines/ - Evil-surround
https://github.com/emacs-evil/evil-surround - Spacemacs
http://spacemacs.org/ - Lisp: Common Lisp, Racket, Clojure, Emacs Lisp
http://hyperpolyglot.org/lisp - Common Lisp, Scheme, Clojure, And Elisp Compared
http://irreal.org/blog/?p=725 - Does Elisp Suck?
http://irreal.org/blog/?p=675 - Emacs pro mírně pokročilé (9): Elisp
https://www.root.cz/clanky/emacs-elisp/ - If I want to learn lisp, are emacs and elisp a good choice?
https://www.reddit.com/r/emacs/comments/2m141y/if_i_want_to_learn_lisp_are_emacs_and_elisp_a/ - Clojure(Script) Interactive Development Environment that Rocks!
https://github.com/clojure-emacs/cider - An Introduction to Emacs Lisp
https://harryrschwartz.com/2014/04/08/an-introduction-to-emacs-lisp.html - Emergency Elisp
http://steve-yegge.blogspot.com/2008/01/emergency-elisp.html - Racket
https://racket-lang.org/ - The Racket Manifesto
http://felleisen.org/matthias/manifesto/ - MIT replaces Scheme with Python
https://www.johndcook.com/blog/2009/03/26/mit-replaces-scheme-with-python/ - Adventures in Advanced Symbolic Programming
http://groups.csail.mit.edu/mac/users/gjs/6.945/ - Why MIT Switched from Scheme to Python (2009)
https://news.ycombinator.com/item?id=14167453 - Starodávná stránka XLispu
http://www.xlisp.org/ - AutoLISP
https://en.wikipedia.org/wiki/AutoLISP - Seriál PicoLisp: minimalistický a výkonný interpret Lispu
https://www.root.cz/serialy/picolisp-minimalisticky-a-vykonny-interpret-lispu/ - Common Lisp
https://common-lisp.net/ - Getting Going with Common Lisp
https://cliki.net/Getting%20Started - Online Tutorial (Common Lisp)
https://cliki.net/online%20tutorial - Guile Emacs
https://www.emacswiki.org/emacs/GuileEmacs - Guile Emacs History
https://www.emacswiki.org/emacs/GuileEmacsHistory - Guile is a programming language
https://www.gnu.org/software/guile/ - MIT Scheme
http://groups.csail.mit.edu/mac/projects/scheme/ - SIOD: Scheme in One Defun
http://people.delphiforums.com/gjc//siod.html - CommonLispForEmacs
https://www.emacswiki.org/emacs/CommonLispForEmacs - Elisp: print, princ, prin1, format, message
http://ergoemacs.org/emacs/elisp_printing.html - Special Forms in Lisp
http://www.nhplace.com/kent/Papers/Special-Forms.html - Basic Building Blocks in LISP
https://www.tutorialspoint.com/lisp/lisp_basic_syntax.htm - Introduction to LISP – University of Pittsburgh
https://people.cs.pitt.edu/~milos/courses/cs2740/Lectures/LispTutorial.pdf - Why don't people use LISP
https://forums.freebsd.org/threads/why-dont-people-use-lisp.24572/ - Structured program theorem
https://en.wikipedia.org/wiki/Structured_program_theorem - Clojure: API Documentation
https://clojure.org/api/api - Tutorial for the Common Lisp Loop Macro
http://www.ai.sri.com/pkarp/loop.html - Common Lisp's Loop Macro Examples for Beginners
http://www.unixuser.org/~euske/doc/cl/loop.html - A modern list api for Emacs. No 'cl required.
https://github.com/magnars/dash.el - The LOOP Facility
http://www.lispworks.com/documentation/HyperSpec/Body/06_a.htm



































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU