
Obsah
1. Užitečné balíčky pro každodenní použití jazyka Go
2. Získání seznamu nainstalovaných balíčků
3. Použití webového prohlížeče pro získání podrobnějších informací o balíčcích
4. Instalace externího balíčku
5. Použití nově nainstalovaného balíčku
6. Funkce pro konverzi řetězců na pravdivostní hodnotu
7. Konverze řetězců na číselné hodnoty
8. Převod popř. naformátování celočíselné hodnoty na řetězec
9. Převod hodnoty s plovoucí čárkou na řetězec
10. Obecné formátování hodnot s jejich uložením do řetězce (Sprintf)
11. Kontejnery implementované ve standardní knihovně
12. Základní operace se seznamy
13. Praktičtější příklad: použití seznamů ve funkci zásobníku pro implementaci RPN
14. Externí knihovna GoDS (Go Data Structures)
15. Datová struktura arraylist, jednosměrně a obousměrně vázané seznamy
16. Implementace zásobníků, přepis a vylepšení příkladu s implementací RPN
17. Množiny, implementace Eratosthenova síta
18. Stromy, struktura Red-Black tree
19. Repositář s demonstračními příklady
1. Užitečné balíčky pro každodenní použití jazyka Go
V předchozích částech tohoto seriálu jsme se zaměřili především na popis samotného jazyka Go a později i na způsob vytváření a použití nových balíčků (packages). Mnoho demonstračních příkladů používalo některé základní balíčky, které jsou součástí instalace samotného jazyka Go a jeho základní sady nástrojů. Jednalo se především o balíčky fmt, math a time (připomeňme si, že je zvykem, aby názvy balíčků byly jednoslovní a aby byly zapisovány malými písmeny). V praxi je ovšem většinou nutné použít i mnohé další balíčky, a to jak balíčky ze standardní knihovny programovacího jazyka Go, tak i externí balíčky, které implementují další funkcionalitu. Dnes se s některými užitečnými a často používanými balíčky seznámíme. Již na úvod je nutné poznamenat, že se (alespoň prozatím) zaměříme na instalaci a správu balíčků s využitím základních nástrojů jazyka Go. Použitím pokročilejších správců balíčků se budeme zabývat v samostatném článku.
2. Získání seznamu nainstalovaných balíčků
Seznam základních balíčků patřících do standardní knihovny jazyka Go nalezneme i s jejich popisem na stránce https://golang.org/pkg/. Povšimněte si, že balíčky jsou rozděleny do několika kategorií, ovšem prakticky vždy se jedná o základní funkcionalitu (práce se sítí, balíčky umožňující vytvoření HTTP serveru, zpracování datových struktur, volání funkcí operačního systému, kryptografické a hešovací funkce, podpora pro práci s několika rastrovými formáty apod.). Nenajdeme zde tedy například knihovny pro tvorbu grafického uživatelského rozhraní, multimediální funkce, či zpracování XML (kromě jednoduchého parseru představovaného balíčkem encoding/xml). V případě, že budete potřebovat získat seznam aktuálně nainstalovaných balíčků na vašem systému, je pro tento účel možné použít prostředky nabízené vlastním jazykem Go a jeho základní sady nástrojů.
Základním příkazem, který můžeme pro tento účel použít, je příkaz go list. Nápovědu k tomuto příkazu získáme následujícím způsobem:
$ go help list usage: go list [-f format] [-json] [-m] [list flags] [build flags] [packages] ... ... ...
Ukažme si nyní několik praktických příkladů. Pro výpis všech balíčků použijte následující příkaz:
$ go list ...
popř. alternativně:
$ go list all
V našem případě (čistá instalace Go + několik testovacích balíčků) by měl výstup vypadat takto – nejdříve se vypíšou balíčky ze standardní knihovny a po nich šest balíčků, které jsme vytvořili minule:
archive/tar archive/zip bufio bytes cmd/addr2line cmd/api cmd/asm ... ... ... hello1 hello2 hello3 hello4 say_hello_1 say_hello_2
U tohoto příkazu je dokonce možné specifikovat formát výstupu a tím i ovlivnit, jaké informace se zobrazí na standardním výstupu. Následující příkaz zobrazí napřed název balíčku (i s cestou) a poté seznam všech dalších balíčků, které jsou explicitně importovány:
$ go list -f "{{.ImportPath}} {{.Imports}}" all
archive/tar [bytes errors fmt io io/ioutil math os os/user path reflect runtime sort strconv strings sync syscall time]
archive/zip [bufio compress/flate encoding/binary errors fmt hash hash/crc32 io io/ioutil os path strings sync time unicode/utf8]
bufio [bytes errors io unicode/utf8]
...
...
...
V případě, že upravíme balíček say_hello takovým způsobem, aby obsahoval:
package main
import "fmt"
func main() {
fmt.Println("Hello world #1!")
}
Projeví se tato změna ihned i ve výpisu balíčků:
$ go list -f "{{.ImportPath}} {{.Imports}}" say_hello_...
say_hello_1 [fmt]
say_hello_2 []
Všechny závislosti (tedy nikoli jen přímo importované balíčky), lze vypsat například takto:
$ go list -f "{{.ImportPath}} {{.Deps}}" say_hello_...
say_hello_1 [errors fmt internal/bytealg internal/cpu internal/poll internal/race internal/syscall/unix internal/testlog io math math/bits os reflect runtime runtime/internal/atomic runtime/internal/sys strconv sync sync/atomic syscall time unicode unicode/utf8 unsafe]
say_hello_2 [internal/bytealg internal/cpu runtime runtime/internal/atomic runtime/internal/sys unsafe]
3. Použití webového prohlížeče pro získání podrobnějších informací o balíčcích
Existuje ještě jedna možnost, jak se dozvědět podrobnější informace o nainstalovaných balíčcích. Můžeme si totiž lokálně spustit webový (HTTP) server, který nám zpřístupní veškerou automaticky generovanou dokumentaci. Samotné spuštění serveru je jednoduché:
$ godoc --http :8080
2019/01/22 21:21:40 ListenAndServe :8080: listen tcp :8080: bind: address already in use
Následně ve webovém prohlížeči otevřete adresu http://localhost:8080/pkg. Pro jednoduchost můžeme zůstat v terminálu a použít Lynx nebo Links:
The Go Programming Language
Go
▽
Documents Packages The Project Help Blog ____________________ (BUTTON)
Packages
Standard library
Third party
Other packages
Sub-repositories
Community
Standard library ▹
Standard library ▾
Name Synopsis
archive
tar Package tar implements access to tar archives.
zip Package zip provides support for reading and writing ZIP archives.
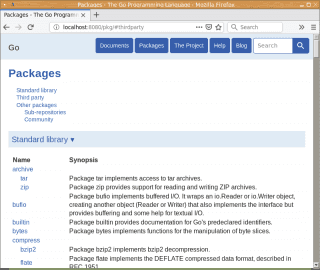
Obrázek 1: Zobrazení automaticky vygenerované stránky se seznamem balíčků.
Na vygenerované stránce nalezneme i seznam balíčků, které jsme vytvořili v rámci předchozího článku. Ovšem jak je patrné, nejsou tyto balíčky rozumně zdokumentovány:
Third party ▾
Name Synopsis
hello1
hello2
hello3
hello4
say_hello_1
say_hello_2
Other packages
Sub-repositories
These packages are part of the Go Project but outside the main Go tree.
They are developed under looser compatibility requirements than the Go
core. Install them with "go get".
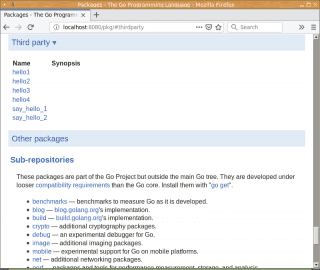
Obrázek 2: Zobrazení balíčků „třetích stran“, což jsou v tomto okamžiku balíčky, které jsme vytvořili v rámci předchozího článku.
4. Instalace a použití externího balíčku
Nyní si ukážeme, jakým způsobem je vlastně možné nainstalovat nějaký externí balíček. Použijeme přitom pouze základní nástroje, které byly nainstalovány společně s překladačem a základními knihovnami programovacího jazyka Go. Balíčky se budou instalovat do adresářové struktury, na níž ukazuje proměnná $GOPATH, což je typicky adresář ~/go. Tento adresář by měl vypadat zhruba následovně:
├── bin
├── pkg
└── src
├── hello1
│ └── hello1.go
├── hello2
│ └── hello1.go
├── hello3
│ └── hello1.go
├── hello4
│ └── hello4.go
├── say_hello_1
│ └── hello.go
└── say_hello_2
└── hello.go
9 directories, 6 files
Vidíme, že se v adresáři – alespoň prozatím – nachází pouze balíčky vytvořené z demonstračních příkladů popsaných v předchozí části tohoto seriálu.
Pokud například budeme potřebovat vypočítat Levenštejnovu vzdálenost dvou řetězců (což se provádí poměrně často například při implementaci uživatelsky přívětivé funkce Search), můžeme pro tento účel použít knihovnu/balíček s názvem levenshtein a s cestou github.com/agext/levenshtein, která je dostupná na GitHubu, konkrétně na adrese https://github.com/agext/levenshtein (součástí plné cesty balíčku je skutečně i „github.com“).
Balíček agext/levenshtein se instaluje velmi snadno, a to příkazem go get, kterému předáme jméno repositáře s balíčkem (ovšem vynechá se protokol!):
$ go get github.com/agext/levenshtein
Pokud chcete vidět, jaké operace se provádí, přidejte přepínač -v:
$ go get -v github.com/agext/levenshtein github.com/agext/levenshtein (download)
Nyní by měla adresářová struktura ~/go (přesněji řečeno adresář, na který ukazuje proměnná prostředí $GOPATH) vypadat zhruba následovně:
.
├── bin
├── pkg
│ └── linux_amd64
│ └── github.com
│ └── agext
│ └── levenshtein.a
└── src
├── github.com
│ └── agext
│ └── levenshtein
│ ├── DCO
│ ├── levenshtein.go
│ ├── levenshtein_test.go
│ ├── LICENSE
│ ├── MAINTAINERS
│ ├── NOTICE
│ ├── params.go
│ ├── params_test.go
│ └── README.md
├── hello1
│ └── hello1.go
├── hello2
│ └── hello1.go
├── hello3
│ └── hello1.go
├── hello4
│ └── hello4.go
├── say_hello_1
│ └── hello.go
└── say_hello_2
└── hello.go
15 directories, 16 files
Povšimněte si, že se balíček nainstaloval jak do podadresáře src (vlastní zdrojové kódy, testy, licence, další dokumentace), tak i do podadresáře pkg (binární knihovna určená pro slinkování s kódem výsledných aplikací). Po instalaci je součástí cesty k balíčku skutečně i prefix github.com, protože zdrojové kódy balíčku leží v podadresáři src/github.com/agext/levenshtein.
Příkaz go list by nyní měl ukázat informace i o nově nainstalované knihovně agext/levenshtein:
$ go list ... ... ... ... github.com/agext/levenshtein ... ... ...
Podobně uvidíme základní informace o balíčku i na dynamicky generovaných stránkách s dokumentací:
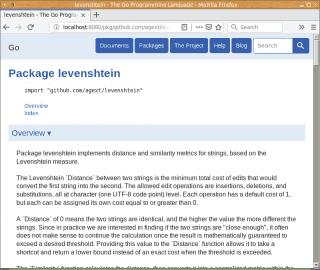
Obrázek 3: Automaticky vygenerované stránky s dokumentací k balíčku github.com/agext/levenshtein.
5. Použití nově nainstalovaného balíčku
Po instalaci balíčku si můžeme zobrazit jeho nápovědu, a to opět přímo na příkazovém řádku:
$ go doc levenshtein
Začátek nápovědy pro celý balíček:
package levenshtein // import "github.com/agext/levenshtein"
Package levenshtein implements distance and similarity metrics for strings,
based on the Levenshtein measure.
The underlying `Calculate` function is also exported, to allow the building
of other derivative metrics, if needed.
func Calculate(str1, str2 []rune, maxCost, insCost, subCost, delCost int) (dist, prefixLen, suffixLen int)
func Distance(str1, str2 string, p *Params) int
func Match(str1, str2 string, p *Params) float64
func Similarity(str1, str2 string, p *Params) float64
type Params struct{ ... }
func NewParams() *Params
Nápovědu si můžeme zobrazit i pro libovolnou exportovanou funkci popř. pro datový typ (exportují se pouze ty objekty, které začínají velkým písmenem):
$ go doc levenshtein.Distance
package levenshtein // import "github.com/agext/levenshtein"
func Distance(str1, str2 string, p *Params) int
Distance returns the Levenshtein distance between str1 and str2, using the
default or provided cost values. Pass nil for the third argument to use the
default cost of 1 for all three operations, with no maximum.
V testovacím příkladu se balíček naimportuje, přičemž při importu musíme použít celou cestu, a to včetně prefixu „github.com“. Po importu můžeme zavolat funkci levenshtein.Distance() a zjistit vzdálenost mezi dvěma řetězci. Posledním parametrem této funkce jsou případné další parametry, jejichž význam si můžete přečíst v nápovědě (my je ovšem nebudeme potřebovat ani nastavovat, takže v posledním parametru předáme pouze nil):
package main
import (
"github.com/agext/levenshtein"
)
func main() {
s1 := "Hello"
s2 := "hello"
println(levenshtein.Distance(s1, s2, nil))
s1 = "Marta"
s2 = "Markéta"
println(levenshtein.Distance(s1, s2, nil))
s1 = " foo"
s2 = "jiný naprosto odlišný text nesouvisející s foo"
println(levenshtein.Distance(s1, s2, nil))
}
Po překladu a spuštění tohoto příkladu by se na standardní výstup měly vypsat tyto tři Levenštejnovy vzdálenosti:
1 2 42
6. Funkce pro konverzi řetězců na pravdivostní hodnotu
Nyní si popíšeme některé často používané funkce, které jsou používány prakticky dennodenně a které nalezneme ve standardní knihovně programovacího jazyka Go. Mnohokrát se setkáme s potřebou konvertovat řetězec obsahující pravdivostní hodnotu zapsanou ve formě textu na skutečnou pravdivostní hodnotu typu bool. K tomuto účelu se používá funkce nazvaná ParseBool, kterou nalezneme v balíčku strconv. Této funkci se předá řetězec a po konverzi se vrátí dvě hodnoty – vlastní pravdivostní hodnota typu bool a hodnota typu error, která může nést informace o případné chybě (jak je zvykem, pokud k chybě nedošlo, vrací se nil). Zbývá doplnit informaci o tom, jak se konkrétně provádí konverze:
| Řetězec | Výsledek |
|---|---|
| „true“ | true, error==nil |
| „True“ | true, error==nil |
| „TRUE“ | true, error==nil |
| „t“ | true, error==nil |
| „T“ | true, error==nil |
| „1“ | true, error==nil |
| „false“ | false, error==nil |
| „False“ | false, error==nil |
| „FALSE“ | false, error==nil |
| „f“ | false, error==nil |
| „F“ | false, error==nil |
| „0“ | false, error==nil |
| jiná hodnota | chyba, error!=nil |
Chování této funkce je tedy snadno pochopitelné, takže si ji odzkoušíme na tomto demonstračním příkladu:
package main
import (
"fmt"
"strconv"
)
func tryToParseBool(s string) {
i, err := strconv.ParseBool(s)
if err == nil {
fmt.Printf("%t\n", i)
} else {
fmt.Printf("%v\n", err)
}
}
func main() {
tryToParseBool("true")
tryToParseBool("True")
tryToParseBool("TRUE")
tryToParseBool("T")
tryToParseBool("t")
tryToParseBool("false")
tryToParseBool("False")
tryToParseBool("FALSE")
tryToParseBool("F")
tryToParseBool("f")
tryToParseBool("Foobar")
tryToParseBool("0")
tryToParseBool("1")
tryToParseBool("no")
tryToParseBool("")
}
Po překladu a spuštění by se na standardním výstupu měly objevit následující řádky s výsledky konverze:
true true true true true false false false false false strconv.ParseBool: parsing "Foobar": invalid syntax false true strconv.ParseBool: parsing "no": invalid syntax strconv.ParseBool: parsing "": invalid syntax
7. Konverze řetězců na číselné hodnoty
Velmi často se v praxi setkáme s nutností získat číselné hodnoty uložené v řetězcích. Může se například jednat o zpracování vstupů z příkazové řádky, zpracování zpráv předaných přes sockety atd. K tomuto účelu nám standardní knihovna programovacího jazyka Go nabízí několik funkcí, které jsou vypsány v tabulce. Až na poslední funkci nalezneme ostatní funkce v balíčku strconv, podobně jako výše popsanou funkci ParseBool:
| Funkce | Stručný popis |
|---|---|
| ParseInt | převod řetězce na celé číslo se znaménkem, je možné specifikovat základ číselné soustavy |
| ParseUint | převod řetězce na celé číslo bez znaménka, opět je možné specifikovat základ číselné soustavy |
| ParseFloat | převod řetězce na číslo s plovoucí řádovou čárkou |
| Atoi | odpovídá funkci ParseInt se základem 10 a bitovou šířkou typu int |
| Scanf | na základě řetězce se specifikací formátu vstupu se snaží ve vstupním řetězci nalézt číselné popř. i další hodnoty |
První funkcí, kterou si popíšeme, je funkce ParseInt sloužící pro převod řetězce na celé číslo se znaménkem, přesněji řečeno na hodnotu typu int64 (nikoli int). Této funkci se předávají tři parametry:
- Samotný řetězec, který se má převést. Pokud řetězec nebude obsahovat pouze číslice, ale i další znaky, vrátí se (ve druhé návratové hodnotě) příslušná chyba.
- Základ číselné soustavy, ve které je číslo v řetězci zapsáno (od 2 do 36, což je dáno omezením na znaky 0–9 a A-Z). Můžeme použít i hodnotu 0; v tomto případě se při konverzi budou rozeznávat čísla v desítkové soustavě, osmičkové soustavě (prefix 0) a v soustavě šestnáctkové (prefix 0×).
- Bitovou šířkou výsledku, protože vrácená hodnota je sice typuint64, ovšem mnohdy ji potřebujeme zkonvertovat například na osmibitové číslo, 32bitové číslo atd.
Tato funkce opět vrací dvě hodnoty – vlastní číslo a informaci o chybě. Pokud se konverze podařila, bude druhá vrácená hodnota obsahovat nil.
Podívejme se nyní na jednoduchý demonstrační příklad s konverzí různých typů řetězců:
package main
import (
"fmt"
"strconv"
)
func tryToParseInteger(s string, base int) {
i, err := strconv.ParseInt(s, base, 32)
if err == nil {
fmt.Printf("%d\n", i)
} else {
fmt.Printf("%v\n", err)
}
}
func main() {
tryToParseInteger("42", 10)
tryToParseInteger("42", 0)
tryToParseInteger("42", 16)
tryToParseInteger("42", 2)
tryToParseInteger("42x", 10)
println()
tryToParseInteger("-42", 10)
tryToParseInteger("-42", 0)
tryToParseInteger("-42", 16)
tryToParseInteger("-42", 2)
tryToParseInteger("-42x", 10)
println()
}
Po spuštění a překladu získáme tyto číselné hodnoty (popř. informace o chybě):
42 42 66 strconv.ParseInt: parsing "42": invalid syntax strconv.ParseInt: parsing "42x": invalid syntax -42 -42 -66 strconv.ParseInt: parsing "-42": invalid syntax strconv.ParseInt: parsing "-42x": invalid syntax
K funkci ParseInt existuje i její alternativa pojmenovaná ParseUint určená pro převod celých čísel bez znaménka, konkrétně se vrací hodnoty typu uint64. Opět se podívejme na jednoduchý demonstrační příklad, ve kterém se tato funkce použije:
package main
import (
"fmt"
"strconv"
)
func tryToParseUnsignedInteger(s string, base int) {
i, err := strconv.ParseUint(s, base, 32)
if err == nil {
fmt.Printf("%d\n", i)
} else {
fmt.Printf("%v\n", err)
}
}
func main() {
tryToParseUnsignedInteger("42", 10)
tryToParseUnsignedInteger("42", 0)
tryToParseUnsignedInteger("42", 16)
tryToParseUnsignedInteger("42", 2)
tryToParseUnsignedInteger("42x", 10)
println()
tryToParseUnsignedInteger("-42", 10)
tryToParseUnsignedInteger("-42", 0)
tryToParseUnsignedInteger("-42", 16)
tryToParseUnsignedInteger("-42", 2)
tryToParseUnsignedInteger("-42x", 10)
println()
}
Výsledky získané po spuštění tohtoo příklad
42 42 66 strconv.ParseUint: parsing "42": invalid syntax strconv.ParseUint: parsing "42x": invalid syntax strconv.ParseUint: parsing "-42": invalid syntax strconv.ParseUint: parsing "-42": invalid syntax strconv.ParseUint: parsing "-42": invalid syntax strconv.ParseUint: parsing "-42": invalid syntax strconv.ParseUint: parsing "-42x": invalid syntax
Třetí funkce určená pro získání celočíselné hodnoty z řetězce se jmenuje Atoi. Její chování se podobá podobně pojmenované céčkovské funkci atoi(3): vstupem je pouze řetězec, protože jak základ číselné soustavy, tak i bitová šířka výsledku jsou pevně nastavené (základ je odvozen od prefixu čísla v řetězci, šířka odpovídá typu int). Funkce je to tedy velmi jednoduchá na použití, což je ostatně patrné i při pohledu na dnešní pátý demonstrační příklad:
package main
import (
"fmt"
"strconv"
)
func tryToParseInteger(s string) {
i, err := strconv.Atoi(s)
if err == nil {
fmt.Printf("%d\n", i)
} else {
fmt.Printf("%v\n", err)
}
}
func main() {
tryToParseInteger("42")
tryToParseInteger("42x")
tryToParseInteger("")
println()
tryToParseInteger("-42")
tryToParseInteger("-42x")
tryToParseInteger("-")
println()
}
Samozřejmě se opět podíváme na výsledky tohoto příkladu:
42 strconv.Atoi: parsing "42x": invalid syntax strconv.Atoi: parsing "": invalid syntax -42 strconv.Atoi: parsing "-42x": invalid syntax strconv.Atoi: parsing "-": invalid syntax
Předposlední funkcí z tabulky uvedené na začátku této kapitoly je funkce ParseFloat, která se snaží v řetězci nalézt textovou reprezentaci číselné hodnoty s desetinnou tečkou popř. s desítkovým exponentem. Prvním parametrem této funkce je vstupní řetězec, druhým parametrem pak určení, zda se má provádět konverze odpovídající typu float32 nebo float64:
package main
import (
"fmt"
"strconv"
)
func tryToParseFloat(s string) {
i, err := strconv.ParseFloat(s, 32)
if err == nil {
fmt.Printf("%f\n", i)
} else {
fmt.Printf("%v\n", err)
}
}
func main() {
tryToParseFloat("42")
tryToParseFloat("42.0")
tryToParseFloat(".5")
tryToParseFloat("0.5")
tryToParseFloat("5e10")
tryToParseFloat(".5e10")
tryToParseFloat(".5e-5")
tryToParseFloat("-.5e-5")
tryToParseFloat("5E10")
tryToParseFloat(".5E10")
tryToParseFloat(".5E-5")
tryToParseFloat("-.5E-5")
}
Po spuštění předchozího příkladu se můžeme přesvědčit, že všechny vstupní řetězce skutečně reprezentují hodnoty odpovídající IEEE 754:
42.000000 42.000000 0.500000 0.500000 49999998976.000000 5000000000.000000 0.000005 -0.000005 49999998976.000000 5000000000.000000 0.000005 -0.000005
8. Převod popř. naformátování celočíselné hodnoty na řetězec
Pro zpětný převod celého čísla na řetězec můžeme v tom nejjednodušším případě (žádné speciální požadavky na výsledné naformátování) použít funkci Itoa, kterou opět nalezneme v balíčku strconv. Použití této funkce je velmi přímočaré, jak je to ostatně patrné i při pohledu na další demonstrační příklad:
package main
import (
. "strconv"
)
func main() {
println(Itoa(42))
println(Itoa(0))
println(Itoa(-1))
}
Výsledkem jsou skutečně řetězce vypsané na standardní výstup (i když nutno říci, že stejně by se vypsaly i přímo celočíselné hodnoty):
42 0 -1
Poněkud více možností nám nabízí funkce FormatInt, taktéž z balíčku strconv. V této funkci můžeme specifikovat základ číselné soustavy použité pro konverzi čísla na řetězec. Podporovány jsou základy od 2 (klasická binární soustava) až po 36, což je opět omezení dané tím, že jednotlivé cifry budou reprezentovány znaky 0–9 a poté a-z. V případě, že budete potřebovat použít velká písmena, postačuje výstup z funkce FormatInt předat do funkce ToUpper z balíčku strings. Opět se podívejme na příklad, který funkci FormatInt použije:
package main
import (
. "strconv"
)
func main() {
value := int64(0xcafebabe)
for base := 2; base < 36; base++ {
println(base, FormatInt(value, base))
}
}
Výsledkem běhu tohoto programu jsou všechny možné reprezentace desítkové hodnoty 3405691582 (neboli 0×cafebabe šestnáctkově):
2 11001010111111101011101010111110 3 22210100102001120021 4 3022333223222332 5 23433324112312 6 1321535442354 7 150252620656 8 31277535276 9 8710361507 10 3405691582 11 1498473547 12 7b06863ba 13 423769627 14 24444d366 15 14decdc07 16 cafebabe 17 851a7gfg 18 5a26a5dg 19 3f781gd7 20 2d45b8j2 21 1ieiebdd 22 180i76ii 23 10032471 24 hjh0inm 25 dnie6d7 26 b0ghb7k 27 8l9b1f7 28 71omia6 29 5l15dnm 30 4k4glmm 31 3ptmepo 32 35ftelu 33 2l0pcr7 34 26whxxg 35 1tti1dr
9. Převod hodnoty s plovoucí čárkou na řetězec
Pro převod hodnot typu float32 nebo float64 na řetězec je možné použít funkci nazvanou FormatFloat. Této funkci se předávají čtyři parametry:
- převáděná hodnota typu float64 (užší float32 je nutné explicitně zkonvertovat)
- specifikace formátu: jeden znak ‚b‘, ‚e‘, ‚E‘, ‚f‘, ‚g‘ nebo ‚G‘
- počet číslic za desetinnou tečkou popř. celkový počet číslic mantisy (ovlivňuje šířku výpisu)
- bitová šířka 32 nebo 64 bitů, řídí případné zaokrouhlení hodnoty před její konverzí na řetězec
Specifikace formátu:
| Znak | Výsledek |
|---|---|
| ‚b‘ | -ddddp±ddd (dvojkový exponent) |
| ‚e‘ | -d.dddde±dd (desítkový exponent) |
| ‚E‘ | -d.ddddE±dd (desítkový exponent) |
| ‚f‘ | -ddd.dddd |
| ‚g‘ | buď ‚e‘ nebo ‚f‘ |
| ‚G‘ | buď ‚E‘ nebo ‚F‘ |
Funkci FormatFloat si samozřejmě opět otestujeme, a to v následujícím demonstračním příkladu:
package main
import (
"math"
. "strconv"
)
func main() {
value := math.Pi
println(FormatFloat(value, 'f', 5, 64))
println(FormatFloat(value, 'f', 10, 64))
println(FormatFloat(value, 'e', 10, 64))
println(FormatFloat(value, 'g', 10, 64))
println(FormatFloat(value, 'b', 10, 64))
println()
value = 1e20
println(FormatFloat(value, 'f', 5, 64))
println(FormatFloat(value, 'f', 10, 64))
println(FormatFloat(value, 'e', 10, 64))
println(FormatFloat(value, 'g', 10, 64))
println(FormatFloat(value, 'b', 10, 64))
println()
value = 0
println(FormatFloat(value, 'f', 5, 64))
println(FormatFloat(value, 'f', 10, 64))
println(FormatFloat(value, 'e', 10, 64))
println(FormatFloat(value, 'g', 10, 64))
println(FormatFloat(value, 'b', 5, 64))
}
Výsledkem budou následující řádky vypsané na standardní výstup:
3.14159 3.1415926536 3.1415926536e+00 3.141592654 7074237752028440p-51 100000000000000000000.00000 100000000000000000000.0000000000 1.0000000000e+20 1e+20 6103515625000000p+14 0.00000 0.0000000000 0.0000000000e+00 0 0p-1074
10. Obecné formátování hodnot s jejich uložením do řetězce (Sprintf)
Již mnohokrát jsme se setkali s funkcí fmt.Printf, která slouží pro naformátování hodnot s určením jejich šířky, zarovnání, umístění znaménka atd. a pro následný výpis těchto hodnot na standardní výstup. Ovšem jakou funkci máme použít ve chvíli, kdy sice potřebujeme hodnoty naformátovat, ale potom je například odeslat na webovou stránku, uložit do souboru atd.? Namísto fmt.Printf se v takovém případě použije funkce fmt.Sprintf, což je možná trošku překvapivé, protože ostatní konverzní funkce nalezneme v balíčku strconv a nikoli fmt. Funkce fmt.Printf a fmt.Sprintf mají podobné vlastnosti a stejná pravidla pro formátovací řetězce, takže si dnes bez větších podrobností pouze ukážeme příklady jejího použití.
Následuje demonstrační příklad ukazující použití funkce Sprintf:
package main
import (
. "fmt"
"math"
)
func main() {
value := 42
s := Sprintf("%10d", value)
println(s)
s = Sprintf("%10.5f", math.Pi)
println(s)
s = Sprintf("%10.9f", math.Pi)
println(s)
a := []int{10, 20, 30}
s = Sprintf("%v", a)
println(s)
}
Po spuštění tohoto příkladu by se měly zobrazit přesně tyto řádky:
42 3.14159 3.141592654 [10 20 30]
11. Kontejnery implementované ve standardní knihovně
Se základními datovými strukturami programovacího jazyka Go jsme se již setkali v předchozích částech tohoto seriálu. Připomeňme si, že Go podporuje jeden typ lineární kolekce (neboli kontejneru) a tím je pole (array) tvořící základ pro řezy (slice). Teoreticky je možné do této skupiny počítat i kanály, které při vhodném použití nahradí frontu (queue), ovšem další typy kolekcí/kontejnerů přímo v programovacím jazyku nenalezneme. Některé alespoň základní typy kontejnerů je však možné najít v základní knihovně jazyka Go. Jedná se o tyto balíčky:
| Balíček | Implementovaná datová struktura/kontejner |
|---|---|
| container/list | obousměrně vázaný seznam |
| container/heap | halda (lze použít například pro implementaci prioritní fronty) |
| container/ring | cyklická fronta |
Do těchto kontejnerů se ukládají prvky typu interface{}, což v programovacím jazyku Go de facto znamená „hodnoty neznámého typu“. Pokud z kontejneru nějakou hodnotu přečteme, musí se většinou explicitně specifikovat, jaký typ prvků očekáváme. K tomuto účelu se v Go používají takzvané typové aserce, které se zapisují následujícím způsobem:
i := x.(T) i, ok := x.(T)
kde se za T doplní konkrétní datový typ, například int nebo string. Ve druhém případě se do nové proměnné ok zapíše pravdivostní hodnota značící, zda se operace provedla či nikoli.
Příklad použití, zde konkrétně ukázaný na příkladu obousměrně vázaného seznamu:
l := list.New() l.PushBack(42) i := l.Front().Value.(int)
12. Základní operace se seznamy
Ukažme si nyní jednoduchý demonstrační příklad, na němž si vysvětlíme základní operace se seznamy. V tomto příkladu se seznam zkonstruuje takto:
l := list.New()
Povšimněte si, že není nutné (a vlastně ani možné) specifikovat typ položek seznamu!
l.PushBack("foo")
l.PushBack("bar")
l.PushBack("baz")
Dále se podívejme na způsob implementace průchodu všemi prvky seznamu. Nejprve získáme ukazatel na první prvek s využitím metody List.Front a následně voláme metodu Element.Next (nikoli List.Next!) tak dlouho, až dojdeme na konec seznamu. Datový typ Element je definován jako struktura obalující hodnotu Value typu interface{}. A hodnotu tohoto typu můžeme snadno vytisknout s využitím fmt.Println:
func printList(l *list.List) {
for e := l.Front(); e != nil; e = e.Next() {
fmt.Println(e.Value)
}
}
Úplný zdrojový kód tohoto příkladu vypadá následovně:
package main
import (
"container/list"
"fmt"
)
func printList(l *list.List) {
for e := l.Front(); e != nil; e = e.Next() {
fmt.Println(e.Value)
}
}
func main() {
l := list.New()
l.PushBack("foo")
l.PushBack("bar")
l.PushBack("baz")
printList(l)
}
Výsledky:
foo bar baz
13. Praktičtější příklad: použití seznamů ve funkci zásobníku pro implementaci RPN
Obousměrně vázané seznamy je možné využít i ve funkci zásobníku. Stačí se pouze rozhodnout, který konec seznamu bude sloužit jako vrchol zásobníku (TOS – Top of Stack). Pokud zvolíme, že TOS bude ležet na konci seznamu, můžeme si vytvořit dvě pomocné funkce pro dvě základní operace se zásobníkem – push a pop. V případě, že zásobník bude obsahovat pouze celá čísla, může implementace obou zmíněných funkcí vypadat následovně.
Implementace operace push
func push(l *list.List, number int) {
l.PushBack(number)
}
Implementace operace pop
func pop(l *list.List) int {
tos := l.Back()
l.Remove(tos)
return tos.Value.(int)
}
Tento zásobník nyní použijeme pro implementaci jednoduchého kalkulátoru, který bude pracovat s výrazy zapsanými v obrácené polské notaci (RPN), kterou jsme se zabývali například v článku Programovací jazyky z vývojářského pekla++. Samotná implementace vyhodnocení RPN výrazů je relativně jednoduchá a spočívá v tom, že na zásobník umisťujeme hodnoty a ve chvíli, kdy se ve výrazu nachází operátor, přečteme ze zásobníku dvě hodnoty, provedeme příslušnou operaci a na zásobník uložíme výsledek:
expression := "1 2 + 2 3 * 8 + *"
terms := strings.Split(expression, " ")
stack := list.New()
for _, term := range terms {
switch term {
case "+":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand1+operand2)
...
...
...
default:
number, err := strconv.Atoi(term)
if err == nil {
push(stack, number)
}
}
Pokud je zapsaný výraz korektní, bude po jeho vyhodnocení na zásobníku uložena jediná hodnota, a to výsledek celého výrazu:
printStack(stack)
Následuje výpis úplného zdrojového kódu tohoto demonstračního příkladu:
package main
import (
"container/list"
"fmt"
"strconv"
"strings"
)
type Stack list.List
func printStack(l *list.List) {
for e := l.Front(); e != nil; e = e.Next() {
fmt.Println(e.Value)
}
}
func push(l *list.List, number int) {
l.PushBack(number)
}
func pop(l *list.List) int {
tos := l.Back()
l.Remove(tos)
return tos.Value.(int)
}
func main() {
expression := "1 2 + 2 3 * 8 + *"
terms := strings.Split(expression, " ")
stack := list.New()
for _, term := range terms {
switch term {
case "+":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand1+operand2)
case "-":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand2-operand1)
case "*":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand1*operand2)
case "/":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand2/operand1)
default:
number, err := strconv.Atoi(term)
if err == nil {
push(stack, number)
}
}
}
printStack(stack)
}
Výsledkem by měla být hodnota 42:
42
Nepatrnou úpravou tohoto programu získáme nástroj, který nejenže daný RPN výraz vypočítá, ale bude v průběhu výpočtu vypisovat i aktuální obsah zásobníku. Úprava spočívá v přidání zvýrazněných řádků:
package main
import (
"container/list"
"fmt"
"strconv"
"strings"
)
type Stack list.List
func printStack(l *list.List) {
for e := l.Front(); e != nil; e = e.Next() {
fmt.Printf("%2d ", e.Value)
}
println()
}
func push(l *list.List, number int) {
l.PushBack(number)
}
func pop(l *list.List) int {
tos := l.Back()
l.Remove(tos)
return tos.Value.(int)
}
func main() {
expression := "1 2 + 2 3 * 8 + *"
terms := strings.Split(expression, " ")
stack := list.New()
for _, term := range terms {
switch term {
case "+":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand1+operand2)
print("+ : ")
printStack(stack)
case "-":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand2-operand1)
print("- : ")
printStack(stack)
case "*":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand1*operand2)
print("* : ")
printStack(stack)
case "/":
operand1 := pop(stack)
operand2 := pop(stack)
push(stack, operand2/operand1)
print("/ : ")
printStack(stack)
default:
number, err := strconv.Atoi(term)
if err == nil {
push(stack, number)
}
fmt.Printf("%-2d: ", number)
printStack(stack)
}
}
print("Result: ")
printStack(stack)
}
Nyní se na standardní výstup vypisuje stav zásobníku při průběžném vyhodnocování výrazu. Opět můžeme vidět, že u korektního výrazu se nakonec na zásobníku objeví jen jediná hodnota:
1 : 1 2 : 1 2 + : 3 2 : 3 2 3 : 3 2 3 * : 3 6 8 : 3 6 8 + : 3 14 * : 42 Result: 42
14. Externí knihovna GoDS (Go Data Structures)
Kontejnery (kolekce) nabízené samotným jazykem Go popř. jeho standardní knihovnou nám v praxi většinou nebudou postačovat, takže bude nutné sáhnout po externí knihovně. Těch existuje větší množství, ovšem pravděpodobně nejúplnější sadu kontejnerů nalezneme v knihovně pojmenované GoDS neboli plným jménem Go Data Structures. Dnes si ukážeme jen základní možnosti nabízené touto knihovnou, podrobnosti budou uvedeny příště.
Tuto knihovnu nainstalujeme příkazem:
$ go get github.com/emirpasic/gods
Knihovna by se ihned poté měla objevit v adresářové struktuře odkazované proměnnou $GOPATH:
. ├── github.com │ ├── agext │ │ └── levenshtein ... ... ... │ └── emirpasic │ └── gods │ ├── containers │ │ ├── containers.go │ │ ├── containers_test.go │ │ ├── enumerable.go │ │ ├── iterator.go │ │ └── serialization.go │ ├── examples │ │ ├── arraylist │ │ │ └── arraylist.go ... ... ... │ └── utils │ ├── comparator.go │ ├── comparator_test.go │ ├── sort.go │ ├── sort_test.go │ ├── utils.go │ └── utils_test.go
Pro jistotu si ještě vypišme všechny balíčky obsahující „gods“:
$ go list ...gods... github.com/emirpasic/gods/containers github.com/emirpasic/gods/examples/arraylist github.com/emirpasic/gods/examples/arraystack ... ... ... github.com/emirpasic/gods/lists github.com/emirpasic/gods/lists/arraylist github.com/emirpasic/gods/lists/doublylinkedlist github.com/emirpasic/gods/lists/singlylinkedlist github.com/emirpasic/gods/maps github.com/emirpasic/gods/maps/hashbidimap github.com/emirpasic/gods/maps/hashmap github.com/emirpasic/gods/maps/linkedhashmap github.com/emirpasic/gods/maps/treebidimap github.com/emirpasic/gods/maps/treemap github.com/emirpasic/gods/sets github.com/emirpasic/gods/sets/hashset github.com/emirpasic/gods/sets/linkedhashset github.com/emirpasic/gods/sets/treeset github.com/emirpasic/gods/stacks github.com/emirpasic/gods/stacks/arraystack github.com/emirpasic/gods/stacks/linkedliststack github.com/emirpasic/gods/trees github.com/emirpasic/gods/trees/avltree github.com/emirpasic/gods/trees/binaryheap github.com/emirpasic/gods/trees/btree github.com/emirpasic/gods/trees/redblacktree github.com/emirpasic/gods/utils
15. Datová struktura arraylist, jednosměrně a obousměrně vázané seznamy
Seznamy popsané rozhraním List existují v knihovně GoDS ve třech implementacích:
- ArrayList: seznam postavený nad polem, které se může realokovat
- SinglyLinkedList: lineárně jednosměrně vázaný seznam
- DoublyLinkedList: obousměrně vázaný seznam
U všech seznamů máme k dispozici iterátor (List.Iterator), který se používá takto:
iterator := list.Iterator()
for iterator.Next() {
index, value := iterator.Index(), iterator.Value()
fmt.Printf("item #%d == %s\n", index, value)
}
Použití seznamů všech tří typů je snadné, pouze nesmíme zapomenout na případnou typovou aserci. Příklad použití operací Add, Remove a Swap:
package main
import (
"fmt"
"github.com/emirpasic/gods/lists/arraylist"
)
func printList(list *arraylist.List) {
iterator := list.Iterator()
for iterator.Next() {
index, value := iterator.Index(), iterator.Value()
fmt.Printf("item #%d == %s\n", index, value)
}
fmt.Println()
}
func main() {
list := arraylist.New()
list.Add("a")
list.Add("c", "b")
printList(list)
list.Swap(0, 1)
list.Swap(1, 2)
printList(list)
list.Remove(2)
printList(list)
list.Remove(1)
printList(list)
}
Výsledek po spuštění příkladu:
item #0 == a item #1 == c item #2 == b item #0 == c item #1 == b item #2 == a item #0 == c item #1 == b item #0 == c
Prakticky stejným způsobem můžeme napsat program používající jednosměrně vázaný seznam:
package main
import (
"fmt"
sll "github.com/emirpasic/gods/lists/singlylinkedlist"
)
func printList(list *sll.List) {
iterator := list.Iterator()
for iterator.Next() {
index, value := iterator.Index(), iterator.Value()
fmt.Printf("item #%d == %s\n", index, value)
}
fmt.Println()
}
func main() {
list := sll.New()
list.Add("a")
list.Add("c", "b")
printList(list)
list.Swap(0, 1)
list.Swap(1, 2)
printList(list)
list.Remove(2)
printList(list)
list.Remove(1)
printList(list)
}
Výsledek činnosti tohoto programu je odlišný:
item #0 == a item #1 == c item #2 == b item #0 == c item #1 == b item #2 == a item #0 == c item #1 == b item #0 == c
16. Implementace zásobníků, přepis a vylepšení příkladu s implementací RPN
První variantu RPN kalkulačky, s níž jsme se seznámili ve třinácté kapitole můžeme snadno přepsat s využitím kontejneru nazvaného arraystack, což je implementace zásobníku realizovaná nad polem (které se v případě potřeby realokuje). Povšimněte si triku u příkazu import, v níž se na arraystack budeme odkazovat přes obecnější alias stack:
package main
import (
"fmt"
stack "github.com/emirpasic/gods/stacks/arraystack"
"strconv"
"strings"
)
func printStack(s *stack.Stack) {
it := s.Iterator()
for it.Next() {
value := it.Value()
fmt.Printf("%3d ", value)
}
println()
}
func main() {
expression := "1 2 + 2 3 * 8 + *"
terms := strings.Split(expression, " ")
stack := stack.New()
for _, term := range terms {
switch term {
case "+":
operand1, _ := stack.Pop()
operand2, _ := stack.Pop()
stack.Push(operand1.(int) + operand2.(int))
print("+ :\t")
printStack(stack)
case "-":
operand1, _ := stack.Pop()
operand2, _ := stack.Pop()
stack.Push(operand2.(int) - operand1.(int))
print("- :\t")
printStack(stack)
case "*":
operand1, _ := stack.Pop()
operand2, _ := stack.Pop()
stack.Push(operand1.(int) * operand2.(int))
print("* :\t")
printStack(stack)
case "/":
operand1, _ := stack.Pop()
operand2, _ := stack.Pop()
stack.Push(operand2.(int) / operand1.(int))
print("/ :\t")
printStack(stack)
default:
number, err := strconv.Atoi(term)
if err == nil {
stack.Push(number)
}
fmt.Printf("%-2d:\t", number)
printStack(stack)
}
}
print("Result: ")
printStack(stack)
}
Při spuštění tohoto příkladu se bude postupně vypisovat obsah zásobníku operandů:
1 : 1 2 : 2 1 + : 3 2 : 2 3 3 : 3 2 3 * : 6 3 8 : 8 6 3 + : 14 3 * : 42 Result: 42
17. Množiny, implementace Eratosthenova síta
Další často používanou datovou strukturou jsou množiny přestavované rozhraním Set. Pro toto rozhraní existují tři implementace:
- HashSet: založeno na hešovacích tabulkách
- TreeSet: založeno na RB-stromech
- LinkedHashSet: zachovává pořadí prvků
Jako příklad praktičtějšího použití množin jsem vybral známý algoritmus pro hledání prvočísel s využitím Eratosthenova síta. Samozřejmě existuje mnoho více či méně optimalizovaných implementací tohoto algoritmu; některé jsou zmíněny na stránce Rosetta Code. My si ukážeme tu nejprimitivnější implementaci spočívající v postupném odstraňování celočíselných násobků prvočísel z množiny, která původně obsahovala všechna celá čísla od 2 do 1000.
Následuje výpis zdrojového kódu tohoto demonstračního příkladu:
package main
import (
"fmt"
"github.com/emirpasic/gods/sets/linkedhashset"
)
const maxPrime = 1000
func printSet(set *linkedhashset.Set) {
iterator := set.Iterator()
for iterator.Next() {
index, value := iterator.Index(), iterator.Value()
fmt.Printf("%3d ", value)
if index%10 == 9 {
fmt.Println()
}
}
fmt.Println()
}
func main() {
primes := linkedhashset.New()
for n := 2; n < maxPrime; n++ {
primes.Add(n)
}
for n := 2; n < maxPrime/2; n++ {
if primes.Contains(n) {
for k := 2 * n; k < maxPrime; k += n {
primes.Remove(k)
}
}
}
printSet(primes)
}
Tento příklad by měl po svém spuštění vypsat všechna prvočísla nalezená v intervalu 0 až 1000:
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619 631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769 773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929 937 941 947 953 967 971 977 983 991 997
18. Stromy, struktura Red-Black tree
Jako malá reklama na další pokračování tohoto seriálu bude sloužit příklad, v němž je použita datová struktura pojmenovaná červeno-černý strom neboli Red-Black Tree, popř. RB-Tree. V příkladu vložíme do stromu několik dvojic klíč-hodnota a pokaždé si necháme vypsat strukturu stromu:

package main
import (
"fmt"
rbt "github.com/emirpasic/gods/trees/redblacktree"
)
func main() {
tree := rbt.NewWithIntComparator()
fmt.Println(tree)
tree.Put(1, "G")
fmt.Println(tree)
tree.Put(2, "a")
tree.Put(3, "b")
fmt.Println(tree)
tree.Put(4, "a")
tree.Put(5, "b")
fmt.Println(tree)
tree.Put(6, "a")
tree.Put(7, "b")
fmt.Println(tree)
tree.Put(8, "a")
tree.Put(9, "b")
fmt.Println(tree)
}
Po spuštění příkladu se bude postupně vykreslovat tvar stromu, přičemž kořen je zde umístěn v levém sloupci (stromy se ovšem v informatice obecně kreslí s kořenem nahoře :-):
RedBlackTree
RedBlackTree
└── 1
RedBlackTree
│ ┌── 3
└── 2
└── 1
RedBlackTree
│ ┌── 5
│ ┌── 4
│ │ └── 3
└── 2
└── 1
RedBlackTree
│ ┌── 7
│ ┌── 6
│ │ └── 5
│ ┌── 4
│ │ └── 3
└── 2
└── 1
RedBlackTree
│ ┌── 9
│ ┌── 8
│ │ └── 7
│ ┌── 6
│ │ └── 5
└── 4
│ ┌── 3
└── 2
└── 1
19. Repositář s demonstračními příklady
Zdrojové kódy všech dnes popsaných demonstračních příkladů byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/go-root (stále na GitHubu :-). V případě, že nebudete chtít klonovat celý repositář (ten je ovšem – alespoň prozatím – velmi malý, dnes má doslova několik kilobajtů), můžete namísto toho použít odkazy na jednotlivé příklady, které naleznete v následující tabulce:
20. Odkazy na Internetu
- Select waits on a group of channels
https://yourbasic.org/golang/select-explained/ - Rob Pike: Simplicity is Complicated (video)
http://www.golang.to/posts/dotgo-2015-rob-pike-simplicity-is-complicated-youtube-16893 - Algorithms to Go
https://yourbasic.org/ - Využití knihovny Pygments (nejenom) pro obarvení zdrojových kódů
https://www.root.cz/clanky/vyuziti-knihovny-pygments-nejenom-pro-obarveni-zdrojovych-kodu/ - Využití knihovny Pygments (nejenom) pro obarvení zdrojových kódů: vlastní filtry a lexery
https://www.root.cz/clanky/vyuziti-knihovny-pygments-nejenom-pro-obarveni-zdrojovych-kodu-vlastni-filtry-a-lexery/ - Go Defer Simplified with Practical Visuals
https://blog.learngoprogramming.com/golang-defer-simplified-77d3b2b817ff - 5 More Gotchas of Defer in Go — Part II
https://blog.learngoprogramming.com/5-gotchas-of-defer-in-go-golang-part-ii-cc550f6ad9aa - The Go Blog: Defer, Panic, and Recover
https://blog.golang.org/defer-panic-and-recover - The defer keyword in Swift 2: try/finally done right
https://www.hackingwithswift.com/new-syntax-swift-2-defer - Swift Defer Statement
https://andybargh.com/swift-defer-statement/ - Modulo operation (Wikipedia)
https://en.wikipedia.org/wiki/Modulo_operation - Node.js vs Golang: Battle of the Next-Gen Languages
https://www.hostingadvice.com/blog/nodejs-vs-golang/ - The Go Programming Language (home page)
https://golang.org/ - GoDoc
https://godoc.org/ - Go (programming language), Wikipedia
https://en.wikipedia.org/wiki/Go_(programming_language) - Go Books (kniha o jazyku Go)
https://github.com/dariubs/GoBooks - The Go Programming Language Specification
https://golang.org/ref/spec - Go: the Good, the Bad and the Ugly
https://bluxte.net/musings/2018/04/10/go-good-bad-ugly/ - Package builtin
https://golang.org/pkg/builtin/ - Package fmt
https://golang.org/pkg/fmt/ - The Little Go Book (další kniha)
https://github.com/dariubs/GoBooks - The Go Programming Language by Brian W. Kernighan, Alan A. A. Donovan
https://www.safaribooksonline.com/library/view/the-go-programming/9780134190570/ebook_split010.html - Learning Go
https://www.miek.nl/go/ - Go Bootcamp
http://www.golangbootcamp.com/ - Programming in Go: Creating Applications for the 21st Century (další kniha o jazyku Go)
http://www.informit.com/store/programming-in-go-creating-applications-for-the-21st-9780321774637 - Introducing Go (Build Reliable, Scalable Programs)
http://shop.oreilly.com/product/0636920046516.do - Learning Go Programming
https://www.packtpub.com/application-development/learning-go-programming - The Go Blog
https://blog.golang.org/ - Getting to Go: The Journey of Go's Garbage Collector
https://blog.golang.org/ismmkeynote - Go (programovací jazyk, Wikipedia)
https://cs.wikipedia.org/wiki/Go_(programovac%C3%AD_jazyk) - Rychle, rychleji až úplně nejrychleji s jazykem Go
https://www.root.cz/clanky/rychle-rychleji-az-uplne-nejrychleji-s-jazykem-go/ - Installing Go on the Raspberry Pi
https://dave.cheney.net/2012/09/25/installing-go-on-the-raspberry-pi - How the Go runtime implements maps efficiently (without generics)
https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics - Niečo málo o Go – Golang (slovensky)
http://golangsk.logdown.com/ - How Many Go Developers Are There?
https://research.swtch.com/gophercount - Most Popular Technologies (Stack Overflow Survery 2018)
https://insights.stackoverflow.com/survey/2018/#most-popular-technologies - Most Popular Technologies (Stack Overflow Survery 2017)
https://insights.stackoverflow.com/survey/2017#technology - JavaScript vs. Golang for IoT: Is Gopher Winning?
https://www.iotforall.com/javascript-vs-golang-iot/ - The Go Programming Language: Release History
https://golang.org/doc/devel/release.html - Go 1.11 Release Notes
https://golang.org/doc/go1.11 - Go 1.10 Release Notes
https://golang.org/doc/go1.10 - Go 1.9 Release Notes (tato verze je stále používána)
https://golang.org/doc/go1.9 - Go 1.8 Release Notes (i tato verze je stále používána)
https://golang.org/doc/go1.8 - Go on Fedora
https://developer.fedoraproject.org/tech/languages/go/go-installation.html - Writing Go programs
https://developer.fedoraproject.org/tech/languages/go/go-programs.html - The GOPATH environment variable
https://tip.golang.org/doc/code.html#GOPATH - Command gofmt
https://tip.golang.org/cmd/gofmt/ - The Go Blog: go fmt your code
https://blog.golang.org/go-fmt-your-code - C? Go? Cgo!
https://blog.golang.org/c-go-cgo - Spaces vs. Tabs: A 20-Year Debate Reignited by Google’s Golang
https://thenewstack.io/spaces-vs-tabs-a-20-year-debate-and-now-this-what-the-hell-is-wrong-with-go/ - 400,000 GitHub repositories, 1 billion files, 14 terabytes of code: Spaces or Tabs?
https://medium.com/@hoffa/400–000-github-repositories-1-billion-files-14-terabytes-of-code-spaces-or-tabs-7cfe0b5dd7fd - Gofmt No Longer Allows Spaces. Tabs Only
https://news.ycombinator.com/item?id=7914523 - Why does Go „go fmt“ uses tabs instead of whitespaces?
https://www.quora.com/Why-does-Go-go-fmt-uses-tabs-instead-of-whitespaces - Interactive: The Top Programming Languages 2018
https://spectrum.ieee.org/static/interactive-the-top-programming-languages-2018 - Go vs. Python
https://www.peterbe.com/plog/govspy - PackageManagementTools
https://github.com/golang/go/wiki/PackageManagementTools - A Tour of Go: Type inference
https://tour.golang.org/basics/14 - Go Slices: usage and internals
https://blog.golang.org/go-slices-usage-and-internals - Go by Example: Slices
https://gobyexample.com/slices - What is the point of slice type in Go?
https://stackoverflow.com/questions/2098874/what-is-the-point-of-slice-type-in-go - The curious case of Golang array and slices
https://medium.com/@hackintoshrao/the-curious-case-of-golang-array-and-slices-2565491d4335 - Introduction to Slices in Golang
https://www.callicoder.com/golang-slices/ - Golang: Understanding ‚null‘ and nil
https://newfivefour.com/golang-null-nil.html - What does nil mean in golang?
https://stackoverflow.com/questions/35983118/what-does-nil-mean-in-golang - nils In Go
https://go101.org/article/nil.html - Go slices are not dynamic arrays
https://appliedgo.net/slices/ - Go-is-no-good (nelze brát doslova)
https://github.com/ksimka/go-is-not-good - Rust vs. Go
https://news.ycombinator.com/item?id=13430108 - Seriál Programovací jazyk Rust
https://www.root.cz/serialy/programovaci-jazyk-rust/ - Modern garbage collection: A look at the Go GC strategy
https://blog.plan99.net/modern-garbage-collection-911ef4f8bd8e - Go GC: Prioritizing low latency and simplicity
https://blog.golang.org/go15gc - Is Golang a good language for embedded systems?
https://www.quora.com/Is-Golang-a-good-language-for-embedded-systems - Running GoLang on an STM32 MCU. A quick tutorial.
https://www.mickmake.com/post/running-golang-on-an-mcu-a-quick-tutorial - Go, Robot, Go! Golang Powered Robotics
https://gobot.io/ - Emgo: Bare metal Go (language for programming embedded systems)
https://github.com/ziutek/emgo - UTF-8 history
https://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt - Less is exponentially more
https://commandcenter.blogspot.com/2012/06/less-is-exponentially-more.html - Should I Rust, or Should I Go
https://codeburst.io/should-i-rust-or-should-i-go-59a298e00ea9 - Setting up and using gccgo
https://golang.org/doc/install/gccgo - Elastic Tabstops
http://nickgravgaard.com/elastic-tabstops/ - Strings, bytes, runes and characters in Go
https://blog.golang.org/strings - Datový typ
https://cs.wikipedia.org/wiki/Datov%C3%BD_typ - Seriál o programovacím jazyku Rust: Základní (primitivní) datové typy
https://www.root.cz/clanky/programovaci-jazyk-rust-nahrada-c-nebo-slepa-cesta/#k09 - Seriál o programovacím jazyku Rust: Vytvoření „řezu“ z pole
https://www.root.cz/clanky/prace-s-poli-v-programovacim-jazyku-rust/#k06 - Seriál o programovacím jazyku Rust: Řezy (slice) vektoru
https://www.root.cz/clanky/prace-s-vektory-v-programovacim-jazyku-rust/#k05 - Printf Format Strings
https://www.cprogramming.com/tutorial/printf-format-strings.html - Java: String.format
https://docs.oracle.com/javase/8/docs/api/java/lang/String.html#format-java.lang.String-java.lang.Object…- - Java: format string syntax
https://docs.oracle.com/javase/8/docs/api/java/util/Formatter.html#syntax - Selectors
https://golang.org/ref/spec#Selectors - Calling Go code from Python code
http://savorywatt.com/2015/09/18/calling-go-code-from-python-code/ - Go Data Structures: Interfaces
https://research.swtch.com/interfaces - How to use interfaces in Go
http://jordanorelli.com/post/32665860244/how-to-use-interfaces-in-go - Interfaces in Go (part I)
https://medium.com/golangspec/interfaces-in-go-part-i-4ae53a97479c - Part 21: Goroutines
https://golangbot.com/goroutines/ - Part 22: Channels
https://golangbot.com/channels/ - [Go] Lightweight eventbus with async compatibility for Go
https://github.com/asaskevich/EventBus - What about Trait support in Golang?
https://www.reddit.com/r/golang/comments/8mfykl/what_about_trait_support_in_golang/ - Don't Get Bitten by Pointer vs Non-Pointer Method Receivers in Golang
https://nathanleclaire.com/blog/2014/08/09/dont-get-bitten-by-pointer-vs-non-pointer-method-receivers-in-golang/ - Control Flow
https://en.wikipedia.org/wiki/Control_flow - Structured programming
https://en.wikipedia.org/wiki/Structured_programming - Control Structures
https://www.golang-book.com/books/intro/5 - Control structures – Go if else statement
http://golangtutorials.blogspot.com/2011/06/control-structures-if-else-statement.html - Control structures – Go switch case statement
http://golangtutorials.blogspot.com/2011/06/control-structures-go-switch-case.html - Control structures – Go for loop, break, continue, range
http://golangtutorials.blogspot.com/2011/06/control-structures-go-for-loop-break.html - Single Function Exit Point
http://wiki.c2.com/?SingleFunctionExitPoint - Entry point
https://en.wikipedia.org/wiki/Entry_point - Why does Go have a GOTO statement?!
https://www.reddit.com/r/golang/comments/kag5q/why_does_go_have_a_goto_statement/ - Effective Go
https://golang.org/doc/effective_go.html - GoClipse: an Eclipse IDE for the Go programming language
http://goclipse.github.io/ - GoClipse Installation
https://github.com/GoClipse/goclipse/blob/latest/documentation/Installation.md#installation




































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU