
Obsah
1. Vektorové procesory aneb další pokus o zvýšení výpočetního výkonu počítačů
2. Flynnova klasifikace sekvenčních a paralelních systémů
3. Kategorie SISD: základní způsob implementace skalárních procesorů CISC i RISC
4. Kategorie SIMD: vektorové procesory
6. Vektorové operace jako další způsob dosažení paralelismu v procesorech
7. Využití vektorových operací v minulosti
8. Vektorové instrukce v soudobých typech mikroprocesorů
1. Vektorové procesory aneb další pokus o zvýšení výpočetního výkonu počítačů
„…sequential computers are approaching a fundamental physical limit on their potential power. Such a limit is the speed of light…“
V předchozích částech seriálu o architekturách počítačů jsme se zabývali popisem různých technologií využívaných pro zvýšení výpočetního výkonu mikroprocesorů. Připomeňme si, že z hlediska dosahovaného výpočetního výkonu leží na samém „výkonnostním dně“ klasické mikroprocesory s architekturou CISC, které vykonávají všechny instrukce postupně a dokončení jedné instrukce může v závislosti na jejich složitosti trvat i několik desítek strojových taktů. Předností těchto procesorů může být poměrně velká informační hustota instrukční sady (například i díky tomu, že operandy některých instrukcí jsou zadány implicitně), což mj. znamená, že se procesory tohoto typu po poměrně dlouhou dobu obešly bez nutnosti využití drahých vyrovnávacích pamětí první a druhé úrovně (L1 cache, L2 cache). Klasické procesory s architekturou CISC byly založeny na mikroprogramovém řadiči vybaveném pamětí mikroinstrukcí a teprve později začaly být tyto procesory doplňovány technologiemi získanými z jiných architektur – instrukční pipeline, prediktorem skoků, vektorovými instrukcemi atd.

Obrázek 1: Ukázka časování instrukce ADC (Add with carry) osmibitového mikroprocesoru MOS 6502 s architekturou CISC. V závislosti na zvoleném adresním režimu se liší počty strojových cyklů od dvou do šesti. Liší se samozřejmě i počet bajtů nutných pro zakódování instrukce, protože některé adresní režimy vyžadují zápis absolutní 16bitové adresy a jiné režimy používají jen 8bitový offset, popř. osmibitovou adresu v rámci takzvané nulté stránky (zero page).
Výpočetní výkon mikroprocesorů se podařilo poměrně výrazným způsobem zvýšit u architektury RISC s instrukční pipeline. Provedení jedné instrukce sice stále trvalo větší počet strojových cyklů, ovšem díky rozfázování operací v instrukční pipeline bylo umožněno překrývání většího množství instrukcí, a to bez nutnosti zavádění skutečné paralelizace (která vede k velkému nárůstu složitosti a tím i ceny čipu). Spolu se zavedením mikroprocesorů RISC se skutečně stalo, že reálný i špičkový výpočetní výkon procesorů vzrostl, ale relativně brzy bylo nutné k těmto čipům přidat vyrovnávací paměti (cache), jelikož rychlost procesorů rostla mnohem rychleji, než vybavovací doba pamětí. Tento rozpor mezi rychlostmi obou nejdůležitějších součástí moderních počítačů ostatně trvá dodnes. Pro další zvýšení výpočetního výkonu však bylo nutné použít další technologie, například minule zmíněnou instrukční sadu VLIW, která však – opět – měla velké nároky na rychlost pamětí. Podobně jako u procesorů RISC, i u VLIW bylo pro zmírnění požadavků na rychlost pamětí možné použít Harvardskou architekturu, tj. odděleni paměti programu od paměti dat (programová paměť navíc mohla mít větší šířku datové sběrnice odpovídající šířce instrukčních slov).

Obrázek 2: Ukázka časování některých instrukcí šestnáctibitového mikroprocesoru Intel 8086 s architekturou CISC. I přesto, že se jedná o procesor o generaci starší, než MOS 6502, mají oba zmíněné typy čipů poměrně velké množství společných vlastností.
2. Flynnova klasifikace sekvenčních a paralelních systémů
Před popisem vektorových procesorů je vhodné se zmínit o takzvané Flynnově klasifikaci sekvenčních a paralelních systémů. Jedná se o způsob rozdělení systémů (někdy se jedná o procesory, jindy o celé počítače či výpočetní uzly) v závislosti na tom, zda je tok instrukcí prováděn sekvenčně či paralelně a taktéž na tom, zda je tok dat prováděn sekvenčně či paralelně. Jinými slovy je Flynnova klasifikace založena na rozboru instrukčního a datového paralelismu zkoumaného procesoru/počítače/výpočetního uzlu/cloudu. Sekvenční tok instrukcí se značí zkratkou SI (Single Instruction Stream), paralelní tok instrukcí zkratkou MI (Multiple Instructions Stream). Při rozdělení toků dat se používá zkratka SD (Single Data Stream) pro sekvenční tok dat a zkratka MD (Multiple Data Stream) pro paralelní tok dat. Flynnova klasifikace je sice již poměrně stará (byla prezentována v roce 1966) a hrubá, ovšem stále se s ní můžeme setkat; především s jednou variantou SISD, což jsou právě – když poněkud předběhneme – vektorové procesory.

Obrázek 3: Typický formát instrukcí procesorů s architekturou CISC spadajících do kategorie SISD. U většiny procesorů v kategorii CISC+SISD jsou použity instrukce s mnoha adresními režimy, instrukční slova proměnné délky a s proměnným počtem strojových cyklů nutných pro vykonání operace zakódované v instrukci.
Ve více než padesátileté historii vývoje výpočetní techniky se již objevily všechny čtyři možné kombinace instrukčního a datového paralelismu:
| Zkratka klasifikace | Anglický význam zkratky | Využití systémů s danou klasifikací |
|---|---|---|
| SISD | Single Instruction Stream, Single Data | klasická architektura pro procesory CISC a RISC |
| SIMD | Single Instruction Stream, Multiple Data | vektorové procesory, GPU, procesory s instrukční sadou SSE/MMX… |
| MISD | Multiple Instructions Stream, Single Data Stream | poměrně speciální případy, řídicí počítače raketoplánů (Space Shuttle) |
| MIMD | Multiple Instructions Stream, Multiple Data Stream | Connection Machine, transputery, symetrické multiprocesory |

Obrázek 4: U procesorů s instrukční sadou VLIW může být v jediném instrukčním slově (světle žlutý obdélník) uloženo větší množství operací. Na tomto obrázku je zobrazeno instrukční slovo hypotetického mikroprocesoru obsahujícího jeden modul pro komunikaci s pamětí, jednu ALU, matematický koprocesor a jednotku po provádění skoků. Spojování více operací do jednoho instrukčního slova je náplní práce překladače, přesněji řečeno jeho back endu.
3. Kategorie SISD: základní způsob implementace skalárních procesorů CISC i RISC
Z hlediska Flynnovy klasifikace patří mezi nejjednodušší systémy procesory a počítače ležící v kategorii SISD, která vlastně odpovídá von Neumannově architektuře počítače. Do této kategorie spadají především klasické mikroprocesory s architekturou CISC, ale i procesory RISC. Důvod, proč jsou oba tyto typy procesorů zařazeny do kategorie SISD, je jednoduchý – tyto čipy načítají instrukce z operační paměti sekvenčně a sekvenčně jsou taktéž vykonávány, samozřejmě s určitou výjimkou představovanou instrukční pipeline. Nezávisle na konkrétním typu architektury procesoru jsou čipy patřící do kategorie SISD nejjednodušší jak z hlediska technické implementace a počtu tranzistorů, tak i nároky kladenými na překladač a v neposlední řadě i na programátory (kteří stále hledají vhodné prostředky pro vyjádření algoritmů určených pro paralelní systémy). Z tohoto hlediska se můžeme se systémy SISD stále v praxi setkávat a v mnoha oborech vlastně ani není důvod k přechodu k systémům složitějším a dražším.

Obrázek 5: Schéma systému patřícího do kategorie SISD.
Všechny CISCové mikroprocesory firmy Intel řady 80×86, od ještě z poloviny osmibitového čipu Intel 8088 až po model Intel 80486 (včetně) byly založeny na skalární architektuře SISD, stejně jako velké množství mikrořadičů či digitálních signálových procesorů (DSP – Digital Signal Processor). Nevýhodou systémů SISD ovšem je, že rychlost načítání a tím i zpracování instrukcí je shora omezena a že ani s využitím velmi dlouhé instrukční pipeline se nedá – vcelku logicky – překonat limit jedné zpracované instrukce za jeden takt. Příliš velké množství řezů (slices) pipeline má naopak i své zápory, především při zpracování skoků, návratů z podprogramů či odezvy na přerušení – ve všech těchto případech je nutné vyřešit problém, co se má udělat s instrukcemi, které se nachází v rozpracovaném stavu v pipeline (mohou se buď zahodit nebo naopak dokončit, podle toho, jakým způsobem byl lineární běh programu přerušen).
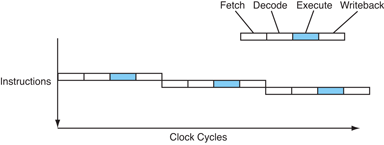
Obrázek 6: Sekvenční zpracování instrukcí, které jsou prováděny v několika fázích.
4. Kategorie SIMD: vektorové procesory
V současnosti se těší značné popularitě procesory patřící do kategorie SIMD, jejíž kořeny ovšem sahají hluboko do minulosti, konkrétně do šedesátých a sedmdesátých let minulého století (tato oblast výpočetní techniky je spojena se Symourem Crayem a jeho superpočítači). Do této kategorie patří ty architektury procesorů, u kterých se pomocí jedné instrukce může zpracovat větší množství dat. Například u rozšířené instrukční sady MMX je možné pomocí jediné instrukce provést součet dvou vektorů číselných hodnot. Může se jednat o osm osmibitových hodnot uložených v jednom vektoru, čtyři šestnáctibitové hodnoty v jednom vektoru atd. Této vlastnosti se dá v mnoha případech využít pro urychlení běhu programů, protože některé algoritmy (ve skutečnosti je těchto algoritmů možná až udivující počet) provádí velké množství stejných operací s rozsáhlým objemem dat – například se může jednat o aplikaci konvolučního filtru na rastrový obrázek, zpracování zvukového signálu, vynásobení matice vektorem, vynásobení dvou matic atd.

Obrázek 7: Schéma systému patřícího do kategorie SIMD.
Mezi přednosti čipů náležejících do kategorie SIMD patří jak relativně kompaktní instrukční sada, tak i paralelní a tím pádem i rychlý běh mnoha algoritmů, ovšem za cenu větších nároků kladených na programátora, popř. na překladač. Stále jen velmi malé množství programovacích jazyků totiž umožňuje explicitně vyjádřit vektorové či maticové operace (například u překladače Fortranu určeného pro superpočítače Cray bylo v manuálu explicitně řečeno, které jazykové konstrukce se budou skutečně provádět ve vektorové – SISD – jednotce). Z tohoto důvodu také není možné většinu SIMD konstrukcí zapsat v konvenčním vyšším programovacím jazyce: musí se použít buď hotová makra, ručně optimalizované knihovní funkce nebo specializované programovací jazyky. Určitou, ale nezanedbatelnou výjimku představují GPU na grafických akcelerátorech, které explicitně pracují s 2D a 3D vektory, přičemž programátor může předem zjistit, které operace budou skutečně provedeny paralelně.

Obrázek 8: Typy vektorů, s nimiž pracují instrukce MMX.
5. Kategorie MISD: prozatím příliš nevyužívaná technologie a MIMD: pravděpodobný směr dalšího vývoje výkonných počítačů
Procesory spadající do kategorie MISD umožňují na jednu sadu dat přečtených z pracovního registru nebo z operační paměti aplikovat větší množství operací zapsaných ve více instrukcích za sebou. Jedná se tedy o zobecněnou instrukční pipeline (ta ovšem ve skutečnosti pracuje na úrovni instrukčních řezů, tedy na nižší úrovni, než je tomu u procesorů z kategorie MISD). Existují případy, kdy je vhodné tuto architekturu použít (například se jedná o některé aplikace pro zpracovávání datových proudů atd.), je jich však méně, než u SIMD. Z tohoto důvodu není MISD u běžných (nespecializovaných) mikroprocesorů příliš rozšířena, i když některé typy zásobníkových procesorů je možné považovat za flexibilněji navrženou architekturu MISD. Mezi známé systémy z této kategorie patří řídicí počítače používané pro řízení raketoplánů v rámci nedávno ukončeného projektu Space Shuttle.

Obrázek 9: Schéma systému patřícího do kategorie MISD.
Zdaleka největší úroveň paralelismu a tím i nejvyšší teoretický výpočetní výkon nabízí systémy spadající do kategorie MIMD. V procesoru nebo procesorovém poli je paralelně zpracováváno větší množství dat a to nezávisle na sobě (většinou asynchronně). V minulosti se tato architektura používala velmi často například u některých typů superpočítačů (zde byly procesory spojeny například sítí s topologií toroidu, hyperkrychle či „tlustého“ binárního stromu), dnes se této úrovně paralelismu dosahuje i na běžných desktopových procesorech s více jádry (i když zde existuje principiální omezení počtu jader). Problémem je, že opravdu masivní paralelismus s několika desítkami, stovkami či tisíci procesory vyžaduje i jiný přístup k programování a použití specializovaných jazyků, například „paralelního“ LISPu s všeříkajícím názvem *Lisp. Pravděpodobně nejzajímavější technologií používající MIMD, jsou slavné stroje Connection Machine, zejména CM-5 vytvořená z RISCových procesorů SPARC (z pohledu CM jsou moderní dvoujádrové až osmijádrové mikroprocesory pouhé hračky, protože v CM bylo možné současně používat až 65536 procesorů :-). Mezi systémy MIMD patří i počítače a akcelerátory využívající takzvané transputery, o nichž se ještě zmíníme.

Obrázek 10: Schéma systému patřícího do kategorie MIMD.
6. Vektorové operace jako další způsob dosažení paralelismu v procesorech
U mikroprocesorů s instrukční sadou VLIW popsaných minule se využívá explicitně vyjádřený paralelismus, kdy je přímo z pozice operací uložených v takzvaných slotech v instrukčním slově zřejmé, s kterými operandy a v kterém modulu (ALU, FPU, jednotce skoků…) se operace skutečně provede. To sice může být pro některé aplikace poměrně výhodné (samozřejmě za předpokladu, že je použit kvalitní překladač), ovšem největší problém instrukční sady VLIW spočívá v tom, že instrukční slova jsou skutečně velmi široká a ne vždy je možné obsadit všechny sloty, z nichž se instrukční slovo skládá. Konstruktéři procesorů tedy hledali další cesty, jak dosáhnout paralelního provádění výpočtů. Kromě již minule a předminule zmíněné technologie superskalárních procesorů, v nichž se o paralelní provádění instrukcí musí snažit samotný hardware a nikoli překladač, se konstruktéři některých typů procesorů vrátili k poměrně staré myšlence – k vektorovým operacím.

Obrázek 11: Transputer firmy INMOS, který byl použit v mnoha systémech z kategorie MIMD.
Princip činnosti vektorových operací je v základní podobě vlastně velmi jednoduchý. Zatímco u skalárních procesorů se každá instrukce provádí s jedním či dvěma operandy (příkladem může být instrukce ADD R1,R2), je vektorová operace prováděna s obsahem vektorových registrů, tj. registrů určených pro uložení a zpracování několika hodnot stejného typu. Příkladem mohou být operace, které lze najít v instrukční sadě SSE2 využívané i v moderních mikroprocesorech řady x86. Tyto operace pracují (v závislosti na použité instrukci) buď s dvojicí 64bitových slov (může se jednat o celá čísla či o hodnoty s plovoucí řádovou čárkou), se čtveřicí 32bitových slov, osmicí slov šestnáctibitových nebo dokonce se šestnácti osmibitovými hodnotami. V praxi to tedy znamená, že například při zpracování obrazu či videa je možné provést současné maskování či změnu hodnoty šestnácti barvových složek RGB, při práci s audio signálem současně zpracovat osm šestnáctibitových vzorků (samplů), vynásobit dvousložkový vektor s FP čísly atd. Navazující instrukční sady SSE3 a SSE4 obsahují další instrukce používané například při digitálním zpracování signálu, výpočtu skalárního součinu atd.

Obrázek 12: Schéma moderního mikroprocesoru (Intel Prescott) s podporou vektorových instrukcí MMX, SSE, SSE2 a SSE3.
7. Využití vektorových operací v minulosti
Vektorové instrukce zpracovávané ve vektorových aritmeticko-logických jednotkách nejsou žádnou technologickou novinkou, která se na světě objevila až společně s instrukčními sadami MMX, SSE či SSE2. Je tomu právě naopak, protože vektorové operace (popř. dokonce operace maticové) začaly být používány již na konci šedesátých let minulého století v některých typech superpočítačů. Použití těchto typů instrukcí v superpočítačích vydrželo až do současnosti, ovšem pravděpodobně nejznámější jsou vektorové výpočetní jednotky použité v superpočítačích Cray, protože již první generace těchto strojů obsahovaly kromě „klasických“ registrů uchovávajících skalární hodnoty i takzvané vektorové registry.

Obrázek 13: Celkový pohled na superpočítač Cray-1 s podporou vektorových operací.
V každé funkční jednotce (jichž mohlo být nainstalováno i několik desítek) bylo použito osm registrů V, přičemž každý registr obsahoval šedesát čtyři 64bitových hodnot, tj. jednalo se o 64složkový vektor. Již z tohoto popisu je zřejmé, že moderní mikroprocesory ve skutečnosti nedosahují takového stupně datového paralelismu, jako 30 let staré konstrukce superpočítačů. Registry první generace superpočítačů Cray:
| Označení | Počet registrů | Šířka | Poznámka |
|---|---|---|---|
| V | 8 | 64×64 bitů | každý registr je ve skutečnosti 64složkovým vektorem |
| T | 64 | 64 bitů | |
| S | 8 | 64 bitů | sada registrů pro běžné skalární operace |
| B | 64 | 32 bitů | |
| A | 8 | 32 bitů | |
| I | 4 | 32×64-bitová slova | též se zpracovávají jako 128×16-bitová slova |

Obrázek 14: Počítač Cray Y-MP.

8. Vektorové instrukce v soudobých typech mikroprocesorů
Jak jsme se již několikrát zmínili v předchozích odstavcích, jsou v soudobých typech mikroprocesorů implementovány i některé vektorové instrukce (popravdě řečeno již celkový počet vektorových instrukcí pravděpodobně překročil počet instrukcí skalárních :-). Pokud prozatím zůstaneme u platformy x86, tak historicky první instrukční sadou (přesněji řečeno doplněním původní instrukční sady) s podporou vektorových operací byla sada instrukcí MMX, s níž přišla firma Intel. Tato sada sice umožňovala provádění vektorových operací, ale měla celou řadu omezení, především nízký počet „vektorových“ registrů, které navíc měly malou bitovou šířku a z toho vycházející nízký počet prvků ve vektorech atd. Nevýhodné taktéž bylo, že se pro instrukce MMX používaly registry určené původně pro práci s matematickým koprocesorem (FPU), takže současné provádění FP operací a MMX operací bylo minimálně složité. Ovšem poměrně brzy po uvedení sady MMX se objevila konkurenční instrukční sada 3Dnow! firmy AMD, která byla následovaná již zmíněnými sadami SSE až SSE5. Podrobnější informace o všech těchto instrukčních sadách si řekneme v navazující části tohoto seriálu.

Obrázek 15: Mikroprocesor AMD K6–2 implementující mj. i instrukční sadu 3Dnow!
9. Odkazy na Internetu
- Great Microprocessors of the Past and Present: Motorola 88000, Late but elegant (mid 1988) . . . .
http://www.unixhub.com/docs/misc/cpu.html#88000 - badabada.org (rozcestník s informacemi čipech Motorola 88000)
http://badabada.org/index.html - Motorola 88000 (Wikipedia)
http://en.wikipedia.org/wiki/Motorola_88000 - Motorola MC88100 (Wikipedia)
http://en.wikipedia.org/wiki/MC88100 - Motorola MC88110 (Wikipedia)
http://en.wikipedia.org/wiki/MC88110 - AMD Am29000 microprocessor family
http://www.cpu-world.com/CPUs/29000/ - AMD 29k (Streamlined Instruction Processor) ID Guide
http://www.cpushack.com/Am29k.html - AMD Am29000 (Wikipedia)
http://en.wikipedia.org/wiki/AMD_Am29000 - AMD K5 („K5“ / „5k86“)
http://www.pcguide.com/ref/cpu/fam/g5K5-c.html - Sixth Generation Processors
http://www.pcguide.com/ref/cpu/fam/g6.htm - Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Philip Koopman: Stack Computers: the new wave
http://www.ece.cmu.edu/~koopman/stack_computers/contents.html - Hewlett Packard PA-8800 RISC (LOSTCIRCUITS)
http://www.lostcircuits.com/mambo//index.php?option=com_content&task=view&id=42&Itemid=42 - PA-RISC 1.1 Architecture and Instruction Set Reference Manual
http://h21007.www2.hp.com/portal/download/files/unprot/parisc/pa1–1/acd.pdf - PA-RISC (Wikipedia)
http://en.wikipedia.org/wiki/PA-RISC - The Great CPU List: Part VI: Hewlett-Packard PA-RISC, a conservative RISC (Oct 1986)
http://jbayko.sasktelwebsite.net/cpu4.html - HP 9000/500 FOCUS
http://www.openpa.net/systems/hp-9000_520.html - HP FOCUS Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/HP_FOCUS - HP 3000 (Wikipedia)
http://en.wikipedia.org/wiki/HP_3000 - The SPARC Architecture Manual Version 8 (manuál v PDF formátu)
http://www.sparc.org/standards/V8.pdf - The SPARC Architecture Manual Version 9 (manuál v PDF formátu)
http://developers.sun.com/solaris/articles/sparcv9.pdf - SPARC Pipelining
http://www.academic.marist.edu/~jzbv/architecture/Projects/S2002/SPARC/pipelining.html - SPARC Instruction
http://www.academic.marist.edu/~jzbv/architecture/Projects/S2002/SPARC/inst_set.html - SPARC Instruction Set
http://www.academic.marist.edu/~jzbv/architecture/Projects/S2002/SPARC/inst_set.html - MIPS Architecture Overview
http://tams-www.informatik.uni-hamburg.de/applets/hades/webdemos/mips.html - MIPS Technologies R3000
http://www.cpu-world.com/CPUs/R3000/ - The MIPS Register Usage Conventions
http://pages.cs.wisc.edu/~cs354–2/beyond354/conventions.html - C.E. Sequin and D.A.Patterson: Design and Implementation of RISC I
http://www.eecs.berkeley.edu/Pubs/TechRpts/1982/CSD-82–106.pdf - Berkeley RISC
http://en.wikipedia.org/wiki/Berkeley_RISC - Great moments in microprocessor history
http://www.ibm.com/developerworks/library/pa-microhist.html - Microprogram-Based Processors
http://research.microsoft.com/en-us/um/people/gbell/Computer_Structures_Principles_and_Examples/csp0167.htm - A Brief History of Microprogramming
http://www.cs.clemson.edu/~mark/uprog.html - What is RISC?
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/whatis/ - RISC vs. CISC
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/risccisc/ - RISC and CISC definitions:
http://www.cpushack.com/CPU/cpuAppendA.html - The Evolution of RISC
http://www.ibm.com/developerworks/library/pa-microhist.html#sidebar1 - SPARC Processor Family Photo
http://thenetworkisthecomputer.com/site/?p=243 - SPARC: Decades of Continuous Technical Innovation
http://blogs.oracle.com/ontherecord/entry/sparc_decades_of_continuous_technical - The SPARC processors
http://www.top500.org/2007_overview_recent_supercomputers/sparc_processors - Maurice V. Wilkes Home Page
http://www.cl.cam.ac.uk/archive/mvw1/ - Papers by M. V. Wilkes (důležitá je především jeho práce číslo 35)
http://www.cl.cam.ac.uk/archive/mvw1/list-of-papers.txt - Microprogram Memory
http://free-books-online.org/computers/advanced-computer-architecture/microprogram-memory/ - First Draft of a report on the EDVAC
http://qss.stanford.edu/~godfrey/vonNeumann/vnedvac.pdf - Introduction to Microcontrollers
http://www.pic24micro.com/cisc_vs_risc.html - Reduced instruction set computing (Wikipedia)
http://en.wikipedia.org/wiki/Reduced_instruction_set_computer - MIPS architecture (Wikipedia)
http://en.wikipedia.org/wiki/MIPS_architecture - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - Classic RISC pipeline (Wikipedia)
http://en.wikipedia.org/wiki/Classic_RISC_pipeline - R2000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R2000_(microprocessor) - R3000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R3000 - R4400 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R4400 - R8000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R8000 - R10000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R10000 - SPARC (Wikipedia)
http://en.wikipedia.org/wiki/Sparc - SPARC Tagged Data – otázka
http://compilers.iecc.com/comparch/article/91–04–079 - SPARC Tagged Data – odpověď #1
http://compilers.iecc.com/comparch/article/91–04–082 - SPARC Tagged Data – odpověď #2
http://compilers.iecc.com/comparch/article/91–04–088 - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - Microcode (Wikipedia)
http://en.wikipedia.org/wiki/Microcode - Microsequencer (Wikipedia)
http://en.wikipedia.org/wiki/Microsequencer - Maurice Wilkes (Wikipedia)
http://en.wikipedia.org/wiki/Maurice_Wilkes - Micro-operation (Wikipedia)
http://en.wikipedia.org/wiki/Micro-operation - b16 stack processor
http://www.jwdt.com/~paysan/b16.html - Color Forth (Chuck Moore home page)
http://www.colorforth.com/ - colorForth Instructions
http://www.colorforth.com/inst.htm - SEAforth 40C18
http://www.intellasys.net/index.php?option=com_content&task=view&id=60&Itemid=75 - Bit slicing
http://en.wikipedia.org/wiki/Bit_slicing - Bitslice DES
http://www.darkside.com.au/bitslice/ - Great Microprocessors of the Past and Present: Part VII: Advanced Micro Devices Am2901, a few bits at a time …
http://www.cpushack.com/CPU/cpu1.html#Sec1Part7 - Cray History
http://www.cray.com/About/History.aspx?404;http://www.cray.com:80/about_cray/history.html - Cray Historical Timeline
http://www.cray.com/Assets/PDF/about/CrayTimeline.pdf - Seymour Cray Biography
http://www.cray.com/Assets/PDF/about/SeymourCray.pdf - Company: Cray Research, Inc. (Computer History)
http://www.computerhistory.org/brochures/companies.php?alpha=a-c&company=com-42b9d5d68b216 - Cray Wiki
http://www.craywiki.com/index.php?title=Main_Page - Seymour Cray
http://www.craywiki.com/index.php?title=Seymour_Cray - Cray (Wikipedia)
http://en.wikipedia.org/wiki/Cray - Cray-1 (Cray Wiki)
http://www.craywiki.com/index.php?title=Cray_1S - Cray-1 (Wikipedia)
http://en.wikipedia.org/wiki/Cray-1 - Cray X-MP (Wikipedia)
http://en.wikipedia.org/wiki/Cray_X-MP - Cray-2 (Wikipedia)
http://en.wikipedia.org/wiki/Cray-2 - What Limits Forecast Accuracy?
http://weather.mailasail.com/Franks-Weather/Forecast-Accuracy-Limitations - Remembering the Cray-1
http://www.theregister.co.uk/2008/01/05/tob_cray1/ - Cray Supercomputer FAQ and other documents
http://www.spikynorman.dsl.pipex.com/CrayWWWStuff/index.html - Cray Research and Cray computers FAQ Part 1
http://www.spikynorman.dsl.pipex.com/CrayWWWStuff/Cfaqp1.html#TOC - Cray Research and Cray computers FAQ Part 2
http://www.spikynorman.dsl.pipex.com/CrayWWWStuff/Cfaqp2.html#TOC1 - Cray Research and Cray computers FAQ Part 3
http://www.spikynorman.dsl.pipex.com/CrayWWWStuff/Cfaqp3.html#TOC1 - Cray Research and Cray computers FAQ Part 4
http://www.spikynorman.dsl.pipex.com/CrayWWWStuff/Cfaqp4.html#TOC1 - Cray Research and Cray computers FAQ Part 5
http://www.spikynorman.dsl.pipex.com/CrayWWWStuff/Cfaqp5.html#TOC1 - The making of a CRAY-3
http://www.cisl.ucar.edu/docs/SCD_Newsletter/News_summer93/04e.cray3.html - Computer Speed Claims 1980 to 1996
http://homepage.virgin.net/roy.longbottom/mips.htm






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU