Obsah
1. Využití knihovny Pygments (nejenom) pro obarvení zdrojových kódů
2. Princip činnosti knihovny Pygments
3. Lexémy a tokeny (tokenizace)
4. Příklad tokenizace jednoduchého kódu napsaného v Pythonu
5. Základní příklad použití: převod zdrojového textu do HTML
6. Převod zdrojového textu do HTML a LaTeXu s volitelnou tvorbou uceleného dokumentu
7. Výstup na terminál (16 barev, 256 barev, true color)
8. Export obarveného kódu do grafických formátů: rastrové obrázky a vektorové kresby
9. Výpis jednotlivých lexikálních tokenů analyzovaného zdrojového kódu
10. Praktické použití: obarvení zdrojových kódů na terminálu, výstup do SVG atd.
11. Specifikace vlastního stylu (barev) při obarvování zdrojových kódů
12. Nastavení filtru pro zpracování výstupu z lexeru
13. Dostupné standardní filtry
16. Změna velikosti písmen v klíčových slovech
17. Jednoduchý lexer založený na rozpoznávání klíčových slov a regulárních výrazů
18. Repositář s demonstračními příklady
1. Využití knihovny Pygments (nejenom) pro obarvení zdrojových kódů
V dnešním článku se seznámíme se základními způsoby použití knihovny Pygments. Tato knihovna je určena pro zvýraznění syntaxe prakticky libovolného programovacího či značkovacího jazyka. Současná verze knihovny Pygments podporuje přibližně 300 jazyků, popř. různých dialektů. Výstupní formáty jsou volitelné a již při základní instalaci dostane programátor k dispozici například výstup do HTML, LaTeXu, RTF, různých rastrových formátů, vektorového formátu SVG a v neposlední řadě taktéž výstup na terminál/konzoli podporující minimálně 16barev (volitelně i 256 barev či true color výstup). Ovšem největší síla této knihovny spočívá v tom, že je poměrně snadné do ní přidat podporu pro další jazyk, vytvořit si vlastní výstupní formát a dokonce naprogramovat takzvané filtry, které dokážou ovlivňovat výsledek práce „obarvovače“.
Dnešní článek bude rozdělen do tří částí. V první části začínající pátou kapitolou si ukážeme použití různých výstupních formátů, do kterých je možné vyexportovat zdrojový kód se zvýrazněním syntaxe. Jedná se například o klasické HTML, LaTeX, výstup na terminál/konzoli s použitím escape znaků, export do rastrového obrázku, vektorového výkresu ve formátu SVG apod. Část druhá bude prozatím pouze informativní a řekneme si v ní základní informace o filtrech sloužících pro modifikaci takzvaných tokenů (ty představují meziformát mezi vstupním textem a formátovaným výstupem). V závěrečné části si na prozatím velmi jednoduchém příkladu ukážeme způsob vytvoření vlastního lexeru, ať již se bude jednat o relativně složitý lexer určený pro nový programovací jazyk či o jednoduchý lexer sloužící pouze pro rozpoznávání klíčových slov v konfiguračních souborech.
2. Princip činnosti knihovny Pygments
Při zpracování a obarvování zdrojových kódů používá knihovna Pygments několik typů tříd, jejichž instance postupně provádí jednotlivé dílčí kroky. Díky rozdělení celého zpracování do několika konfigurovatelných kroků je zajištěna velká flexibilita knihovny a možnost jejího snadného rozšiřování o další podporované jazyky, výstupní formáty, speciální filtry atd. Celý průběh zpracování vypadá následovně:
- Na začátku zpracování se nachází takzvaný lexer, který postupně načítá jednotlivé znaky ze vstupního řetězce (resp. souboru) a vytváří z nich lexikální tokeny. Pro každý podporovaný jazyk se používá jiný lexer a samozřejmě je možné v případě potřeby si napsat lexer vlastní.
- Výstup z lexeru může procházet libovolným počtem filtrů sloužících pro odstranění nebo (častěji) modifikaci jednotlivých tokenů; ať již jejich typů či přímo textu, který tvoří hodnotu tokenu. Díky existenci filtrů je například možné nechat si zvýraznit vybrané bílé znaky, slova se speciálním významem v komentářích (TODO:, FIX:) apod.
- Za filtry se nachází formátovač (formatter), který postupně načítá jednotlivé tokeny a převádí je do výstupního formátu. K dispozici je několik formátovačů zajišťujících například tisk na terminál, výstup do HTML, LaTeXu, RTF, SVG apod. S některými formátovači se seznámíme a opět platí – v případě potřeby je možné si naprogramovat formátovač vlastní.
3. Lexémy a tokeny (tokenizace)
První část zpracování zdrojových textů je nejzajímavější a implementačně i nejsložitější. Lexer totiž musí v sekvenci znaků tvořících zdrojový text najít takzvané lexémy, tj. skupiny (sousedních) znaků odpovídajících nějakému vzorku (použít lze gramatiku, regulární výraz či ad-hoc testy). Z lexémů se posléze tvoří již zmíněné lexikální tokeny, což je – poněkud zjednodušeně řečeno – dvojice obsahující typ tokenu (někdy se namísto „typ“ používá označení „jméno“) a řetězec ze vstupního zdrojového souboru. Převodu zdrojového textu na sekvenci tokenů se někdy říká tokenizace. Účelem tokenizace může být:
- Transformace zdrojového textu do podoby, která může být dále zpracovávána dalším modulem překladače (syntaktická analýza). V takovém případě se však některé tokeny mohou zahazovat; příkladem mohou být komentáře, tokeny představující bílé znaky apod. Spojením lexeru a modulu pro syntaktickou analýzu vznikne parser (jeho typickým výsledkem je AST).
- Transformace zdrojového kódu pro účely zvýraznění syntaxe v editorech či prohlížečích. V tomto případě se žádné tokeny nezahazují, což je případ knihovny Pygments.
| Příkaz | Kód tokenu | Příkaz | Kód tokenu | Příkaz | Kód tokenu | Příkaz | Kód tokenu |
|---|---|---|---|---|---|---|---|
| REM | 00 | NEXT | 09 | CLR | 18 | NOTE | 27 |
| DATA | 01 | GOTO | 10 | DEG | 19 | POINT | 28 |
| INPUT | 02 | GO TO | 11 | DIM | 20 | XIO | 29 |
| COLOR | 03 | GOSUB | 12 | END | 21 | ON | 30 |
| LIST | 04 | TRAP | 13 | NEW | 22 | POKE | 31 |
| ENTER | 05 | BYE | 14 | OPEN | 23 | 32 | |
| LET | 06 | CONT | 15 | LOAD | 24 | RAD | 33 |
| IF | 07 | COM | 16 | SAVE | 25 | READ | 34 |
| FOR | 08 | CLOSE | 17 | STATUS | 26 | RESTORE | 35 |
…atd…
4. Příklad tokenizace jednoduchého kódu napsaného v Pythonu
Podívejme se nyní na příklad tokenizace velmi jednoduchého a krátkého kódu, který je naprogramován v Pythonu:
for i in range(1, 11):
print("Hello world!")
Výsledkem tokenizace je následující sekvence tokenů, tj. dvojic typ+hodnota (řetězec):
| Typ tokenu | Řetězec |
|---|---|
| Token.Keyword | ‚for‘ |
| Token.Text | ' ' |
| Token.Name | ‚i‘ |
| Token.Text | ' ' |
| Token.Operator.Word | ‚in‘ |
| Token.Text | ' ' |
| Token.Name.Builtin | ‚range‘ |
| Token.Punctuation | ‚(‘ |
| Token.Literal.Number.Integer | ‚1‘ |
| Token.Punctuation | ‚,‘ |
| Token.Text | ' ' |
| Token.Literal.Number.Integer | ‚11‘ |
| Token.Punctuation | ‚)‘ |
| Token.Punctuation | ‚:‘ |
| Token.Text | ‚\n‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚print‘ |
| Token.Punctuation | ‚(‘ |
| Token.Literal.String.Double | ‚"‘ |
| Token.Literal.String.Double | ‚Hello world!‘ |
| Token.Literal.String.Double | ‚"‘ |
| Token.Punctuation | ‚)‘ |
| Token.Text | ‚\n‘ |
range(1, "FDA") for while with i
except for for i else
print("Hello world!")
Výsledek tokenizace:
| Typ tokenu | Řetězec |
|---|---|
| Token.Name.Builtin | ‚range‘ |
| Token.Punctuation | ‚(‘ |
| Token.Literal.Number.Integer | ‚1‘ |
| Token.Punctuation | ‚,‘ |
| Token.Text | ' ' |
| Token.Literal.String.Double | ‚"‘ |
| Token.Literal.String.Double | ‚FDA‘ |
| Token.Literal.String.Double | ‚"‘ |
| Token.Punctuation | ‚)‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚for‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚while‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚with‘ |
| Token.Text | ' ' |
| Token.Name | ‚i‘ |
| Token.Text | ‚\n‘ |
| Token.Keyword | ‚except‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚for‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚for‘ |
| Token.Text | ' ' |
| Token.Name | ‚i‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚else‘ |
| Token.Text | ‚\n‘ |
| Token.Text | ' ' |
| Token.Keyword | ‚print‘ |
| Token.Punctuation | ‚(‘ |
| Token.Literal.String.Double | ‚"‘ |
| Token.Literal.String.Double | ‚Hello world!‘ |
| Token.Literal.String.Double | ‚"‘ |
| Token.Punctuation | ‚)‘ |
| Token.Text | ‚\n‘ |
5. Základní příklad použití: převod zdrojového textu do HTML a LaTeXu s obarvením syntaxe
Konkrétním způsobem implementace vlastního lexeru, filtrů a formátovačů se budeme zabývat v dalším textu, ovšem na začátek si ukažme základní příklad použití knihovny Pygments. První příklad slouží k převodu zdrojového kódu z Pythonu do HTML, samozřejmě s obarvením syntaxe. Převáděný zdrojový kód jsme si již ukazovali výše:
for i in range(1, 11):
print("Hello world!")
Při převodu je nutné použít dvě třídy – lexer pro Python (třída PythonLexer) a formátovač pro HTML výstup (knihovna HtmlFormatter). Prozatím nepoužijeme žádné filtry, takže převod bude triviální a provedeme ho funkcí highlight, které se předá zdrojový kód, použitý lexer a použitý formátovač:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import HtmlFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), HtmlFormatter()))
Výsledkem bude fragment HTML stránky:

Obrázek 1: Výsledný fragment HTML stránky vytvořený předchozím příkladem.
6. Převod zdrojového textu do HTML a LaTeXu s volitelnou tvorbou uceleného dokumentu
Získat je možné i úplnou HTML stránku, tj. ucelený dokument s hlavičkou, patičkou atd. K tomuto účelu se používá volitelný parametr full nastavený na hodnotu True a předaný formátovači:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import HtmlFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), HtmlFormatter(full=True)))

Obrázek 2: Úplná podoba vytvořené HTML stránky zobrazené v prohlížeči.
Podobným způsobem můžeme převést zdrojový kód do LaTeXu, a to implicitně ve zkrácené podobě (bez nových příkazů a maker) určené pro vložení do většího dokumentu:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import LatexFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), LatexFormatter()))

Obrázek 3: Výsledek konverze zdrojového kódu do LaTeXu.
Alternativně můžeme vytvořit i samostatný (standalone) dokument, který by měl být bez dalších změn zpracovatelný LaTeXem popř. samozřejmě i pdfLaTeXem:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import LatexFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), LatexFormatter(full=True)))

Obrázek 4: Výsledek konverze zdrojového kódu do plnohodnotného dokumentu zpracovatelného LaTeXem (zde je konkrétně ukázána hlavička s několika TeXovskými makry).
7. Výstup na terminál (16 barev, 256 barev, true color)
Užitečný může být i přímý výstup obarveného zdrojového kódu na terminál/konzoli. V tomto případě příslušný formátovač vygeneruje escape sekvence (řídicí znaky), které instruují terminál, jakým způsobem má změnit styl písma. Na začátku každého řádku je obarvení obnoveno, což je důležité ve chvíli, kdy je zapotřebí výstup rozdělit na jednotlivé stránky. V současné verzi knihovny Pygments existují tři formátovače určené pro vytváření escape sekvencí pro terminál:
| Formátovač | Význam |
|---|---|
| TerminalFormatter | určený pro výstup na běžné emulátory s 16 barvami |
| Terminal256Formatter | určené pro terminály umožňující zobrazení 256 barev (Xterm apod.) |
| TerminalTrueColorFormatter | určené pro terminály umožňující výběr z 16 milionů barev (true color) |
U formátovače TerminalFormatter lze volit barvu pozadí (světlá/tmavá) a popř. i zapnout číslování řádků. Obě možnosti jsou ukázány v dalším demonstračním příkladu:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import TerminalFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), TerminalFormatter()))
print("-----------------------")
print(highlight(code, PythonLexer(), TerminalFormatter(linenos=True)))
print("-----------------------")
print(highlight(code, PythonLexer(), TerminalFormatter(bg="light")))
print("-----------------------")
print(highlight(code, PythonLexer(), TerminalFormatter(bg="dark")))

Obrázek 5: Výsledek obarvení zdrojového kódu na terminálu s 16 barvami. Barva pozadí je nastavena na černou.
Další příklad ukazuje použití terminálu, který rozpoznává 256 barev:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import Terminal256Formatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), Terminal256Formatter()))

Obrázek 6: Výsledek obarvení zdrojového kódu na terminálu rozpoznávajícího minimálně 256 barev. Barva pozadí je opět nastavena na černou.
Třetí příklad je podobný příkladu předchozímu, ovšem předpokládá terminál s pravými barvami:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import TerminalTrueColorFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), TerminalTrueColorFormatter()))

Obrázek 7: Výsledek obarvení zdrojového kódu na terminálu pracujícího s pravými barvami (true color).

Obrázek 8: Test, zda terminál podporuje 256 barev.
8. Export obarveného kódu do grafických formátů: rastrové obrázky a vektorové kresby
V knihovně Pygments nalezneme i formátovače, jejichž výstupem jsou rastrové obrázky popř. vektorové kresby. Jedná se o následující formátovače:
| Formátovač | Význam |
|---|---|
| ImageFormatter | výstup do zvoleného rastrového formátu (ve výchozím nastavení PNG) |
| JpgImageFormatter | výstup do rastrového formátu JPEG |
| BmpImageFormatter | výstup do rastrového formátu BMP |
| GifImageFormatter | výstup do rastrového formátu GIF |
| SvgFormatter | výstup do vektorového formátu SVG |
Ukažme si výstup do SVG s využitím formátovače nazvaného příznačně SvgFormatter:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import SvgFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), SvgFormatter()))
Výsledný SVG soubor: 1.svg.
Většinou je nutné přidat do vektorového výkresu světlé pozadí, což je ukázáno na ručně upraveném souboru 2.svg.

Obrázek 9: Zobrazení SVG v prohlížečce vektorových výkresů.

Obrázek 10: Díky lineárním transformacím je možné text rotovat beze ztráty kvality.
9. Výpis jednotlivých lexikálních tokenů analyzovaného zdrojového kódu
Zajímavý je formátovač nazvaný RawTokenFormatter. Ten slouží pro výpis typů a současně i hodnot tokenů. Formát výstupu je následující:
"Typtokenu\t'hodnota tokenu'\n Typtokenu\t'hodnota tokenu'\n Typtokenu\t'hodnota tokenu'\n"
V dalším příkladu výsledek vytvořený tímto formátovačem zpracujeme zpět na dvojice typ_tokenu+hodnota_tokenu, které ve zformátované podobě vytiskneme na standardní výstup. Pro rozdělení původního řetězce dobře poslouží metoda String.split():
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import RawTokenFormatter
code = """
for i in range(1, 11):
print("Hello world!")
"""
tokens = highlight(code, PythonLexer(), RawTokenFormatter())
tokens = tokens.decode()
for token in tokens.split("\n"):
foobar = token.split("\t")
if len(foobar) == 2:
print("{token:30} {value}".format(token=foobar[0], value=foobar[1]))
Výsledek pro náš jednoduchý vstupní zdrojový kód by měl vypadat následovně:
Token.Keyword 'for'
Token.Text ' '
Token.Name 'i'
Token.Text ' '
Token.Operator.Word 'in'
Token.Text ' '
Token.Name.Builtin 'range'
Token.Punctuation '('
Token.Literal.Number.Integer '1'
Token.Punctuation ','
Token.Text ' '
Token.Literal.Number.Integer '11'
Token.Punctuation ')'
Token.Punctuation ':'
Token.Text '\n'
Token.Text ' '
Token.Keyword 'print'
Token.Punctuation '('
Token.Literal.String.Double '"'
Token.Literal.String.Double 'Hello world!'
Token.Literal.String.Double '"'
Token.Punctuation ')'
Token.Text '\n'
Jak jsme si již řekli v úvodních kapitolách, neprovádí lexer žádnou kontrolu na syntaxi ani na sémantiku zápisu, takže můžeme tokenizovat i po všech stránkách neplatný kód:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import RawTokenFormatter
code = """
range(1, "FDA") for while with i
except for for i else
print("Hello world!")
"""
tokens = highlight(code, PythonLexer(), RawTokenFormatter())
tokens = tokens.decode()
for token in tokens.split("\n"):
foobar = token.split("\t")
if len(foobar) == 2:
print("{token:30} {value}".format(token=foobar[0], value=foobar[1]))
S výsledkem:
Token.Name.Builtin 'range'
Token.Punctuation '('
Token.Literal.Number.Integer '1'
Token.Punctuation ','
Token.Text ' '
Token.Literal.String.Double '"'
Token.Literal.String.Double 'FDA'
Token.Literal.String.Double '"'
Token.Punctuation ')'
Token.Text ' '
Token.Keyword 'for'
Token.Text ' '
Token.Keyword 'while'
Token.Text ' '
Token.Keyword 'with'
Token.Text ' '
Token.Name 'i'
Token.Text '\n'
Token.Keyword 'except'
Token.Text ' '
Token.Keyword 'for'
Token.Text ' '
Token.Keyword 'for'
Token.Text ' '
Token.Name 'i'
Token.Text ' '
Token.Keyword 'else'
Token.Text '\n'
Token.Text ' '
Token.Keyword 'print'
Token.Punctuation '('
Token.Literal.String.Double '"'
Token.Literal.String.Double 'Hello world!'
Token.Literal.String.Double '"'
Token.Punctuation ')'
Token.Text '\n'
10. Praktické použití: obarvení zdrojových kódů na terminálu, výstup do SVG atd.
V této kapitole si pro zajímavost uvedeme zdrojové kódy dvou skriptů, které je možné použít v praxi. Prvnímu skriptu je nutné na příkazové řádce předat jméno vstupního souboru (psaného v Pythonu). Výsledkem bude obarvený zdrojový kód vypsaný přímo na terminál. Skript bude možné použít na jakémkoli terminálu s podporou minimálně šestnácti barev:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
from sys import argv, exit
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import TerminalFormatter
if len(argv) <= 1:
print("Usage: pygments11_highlight_source.py FILENAME")
exit(1)
with open(argv[1], 'r') as fin:
code = fin.read()
print(highlight(code, PythonLexer(), TerminalFormatter()))
Druhý skript slouží k převodu zdrojového kódu do formátu SVG, který lze využít například pro tvorbu badgí apod.:
#!/usr/bin/env python
# vim: set fileencoding=utf-8
from sys import argv, exit
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import SvgFormatter
if len(argv) <= 1:
print("Usage: pygments12_source2svg.py FILENAME > DRAWING.svg")
exit(1)
with open(argv[1], 'r') as fin:
code = fin.read()
print(highlight(code, PythonLexer(), SvgFormatter()))
11. Specifikace vlastního stylu (barev) při obarvování zdrojových kódů
Zejména při tisku obarveného zdrojového kódu na terminál může být užitečné změnit barvu jednotlivých typů tokenů. I to je samozřejmě možné v knihovně Pygments zařídit a to relativně jednoduše. K tomuto účelu se používá třída Style, on níž je možné si odvodit novou třídu s uživatelsky definovaným stylem. V případě použití terminálu, který podporuje 256 barev, lze do stylů zapsat barvy ve formátu #rgb, podobně, jako je tomu v HTML a CSS. Kromě toho je možné specifikovat i styl zobrazení textu (tučný, podtržený, kurzíva). Styly se nastavují pro jednotlivé typy tokenů (je tedy nutné importovat příslušné třídy):
class NewStyle(Style):
default_style = ""
styles = {
Comment: 'italic #888',
Keyword: 'underline #f00',
Name.Builtin: 'bold #ff0',
String: '#0f0 bg:#232'
}
Nová třída se styly se použije snadno – styl se předá formátovači v nepovinném parametru style:
print(highlight(code, PythonLexer(), Terminal256Formatter(style=NewStyle)))
Podívejme se nyní na úplný zdrojový kód tohoto příkladu:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import Terminal256Formatter
from pygments.style import Style
from pygments.token import Keyword, Name, Comment, String, Error, \
Number, Operator, Generic
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), Terminal256Formatter()))
print("-----------------------")
class NewStyle(Style):
default_style = ""
styles = {
Comment: 'italic #888',
Keyword: 'underline #f00',
Name.Builtin: 'bold #ff0',
String: '#0f0 bg:#232'
}
print(highlight(code, PythonLexer(), Terminal256Formatter(style=NewStyle)))

Obrázek 11: Změna stylu zobrazení při použití terminálu s možností práce s 256 barvami.
Druhý příklad je velmi podobný, ovšem při specifikaci stylů jsou použity názvy standardních barev platné i pro původní 16barevné terminály. Povšimněte si, že každá barva opět začíná znakem #:
class NewStyle(Style):
default_style = ""
styles = {
Comment: 'italic #ansidarkgray',
Keyword: 'underline #ansired',
Name.Builtin: 'bold #ansiyellow',
String: '#ansilightgray'
}
Mapování mezi názvem barvy a jejím konkrétním kódem si zajistí knihovna Pygments automaticky na základě tohoto slovníku:
_ansimap = {
# dark
'#ansiblack': '000000',
'#ansidarkred': '7f0000',
'#ansidarkgreen': '007f00',
'#ansibrown': '7f7fe0',
'#ansidarkblue': '00007f',
'#ansipurple': '7f007f',
'#ansiteal': '007f7f',
'#ansilightgray': 'e5e5e5',
# normal
'#ansidarkgray': '555555',
'#ansired': 'ff0000',
'#ansigreen': '00ff00',
'#ansiyellow': 'ffff00',
'#ansiblue': '0000ff',
'#ansifuchsia': 'ff00ff',
'#ansiturquoise': '00ffff',
'#ansiwhite': 'ffffff',
}
Podívejme se nyní na úplný zdrojový kód příkladu:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import Terminal256Formatter
from pygments.style import Style
from pygments.token import Keyword, Name, Comment, String, Error, \
Number, Operator, Generic
code = """
for i in range(1, 11):
print("Hello world!")
"""
print(highlight(code, PythonLexer(), Terminal256Formatter()))
print("-----------------------")
class NewStyle(Style):
default_style = ""
styles = {
Comment: 'italic #ansidarkgray',
Keyword: 'underline #ansired',
Name.Builtin: 'bold #ansiyellow',
String: '#ansilightgray'
}
print(highlight(code, PythonLexer(), Terminal256Formatter(style=NewStyle)))

Obrázek 12: Změna stylu zobrazení při použití terminálu s možností práce se šestnácti barvami.
12. Nastavení filtru pro zpracování výstupu z lexeru
Při popisu činnosti knihovny Pygments, který byl uveden ve druhé kapitole jsme se krátce zmínili o takzvaných filtrech. Ty mohou být v případě potřeby zařazeny mezi lexer a formátovač. Vstupem do filtrů je sekvence tokenů, výstupem taktéž (obecně odlišná) sekvence tokenů; samotný filtr je přitom implementován formou generátoru. Ve filtrech je možné s tokeny různě manipulovat, především pak provádět následující operace:
- Odstraňovat tokeny ze vstupní sekvence
- Přidávat nové tokeny do výstupní sekvence
- Měnit typ tokenů, například z klíčového slova na operátor apod.
- Měnit samotný text (hodnotu) tokenu
Tyto operace je samozřejmě možné kombinovat, takže se například setkáme s filtry, které jeden původní token rozdělí na několik nových tokenů. Příkladem může být filtr, který v běžném komentáři nalezne zvolená slova (TODO, BUG apod.) a ty barevně zvýrazní. Technicky to znamená rozdělit původní token typu Comment na tři nové tokeny typu Comment, Keyword a znovu Comment.
13. Dostupné standardní filtry
Popišme si nyní některé standardní filtry, které jsou již implementovány a v případě potřeby použity přímo v knihovně Pygments. Jedná se o následující sadu filtrů, které je samozřejmě možné různým způsobem kombinovat:
| Filtr | Stručný popis |
|---|---|
| NameHighlightFilter | zvýraznění vybraných slov stejným způsobem (barvou, stylem), jako jména funkcí |
| CodeTagFilter | zvýraznění vybraných slov v komentářích (TODO atd.) |
| KeywordCaseFilter | změna velikosti písmen klíčových slov |
| VisibleWhitespaceFilter | zvýraznění bílých znaků nalezených ve zdrojovém kódu |
V navazujících kapitolách si ukážeme, jakým způsobem se tyto filtry mohou využít.
14. Obarvení vybraných slov
První standardní filtr, s nímž se dnes seznámíme, je filtr nazvaný NameHighlightFilter. Tento filtr slouží ke zvýraznění vybraných slov ve výsledném (naformátovaném) dokumentu, přičemž styl formátování těchto slov odpovídá jménům funkcí (používá se pro ně stejný typ tokenu). Díky existenci tohoto filtru je možné rozšířit možnosti již existujícího lexeru, například přidat nové pseudoklíčové slovo do syntaxe Pythonu. Ostatně přesně tento příklad si nyní ukážeme. Použijeme v něm filtr NameHighlightFilter pro přidání dvou pseudoklíčových slov xor a goto (velmi užitečné :-) do obarvovače zdrojových kódů naprogramovaných v Pythonu:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import TerminalFormatter
from pygments.filters import NameHighlightFilter
code = """
for i in range(1, 11):
print("Hello world!")
if x and y:
print("yes")
if x or y:
print("dunno")
if x xor y:
print("different")
goto 10
"""
print(highlight(code, PythonLexer(), TerminalFormatter()))
print("-----------------------")
lexer = PythonLexer()
# pridani filtru
lexer.add_filter(NameHighlightFilter(
names=['xor', 'goto']
))
print(highlight(code, lexer, TerminalFormatter()))
Příklad použití tohoto typu filtru:

Obrázek 13: Ukázka použití filtru, který dokáže rozpoznat nová slova.
15. Zvýraznění bílých znaků
Druhý standardní filtr, který může být užitečný, se jmenuje VisibleWhitespaceFilter a slouží ke zvýraznění vybraných bílých znaků. Opět tento filtr použijeme pro kód naprogramovaný v Pythonu, a to z toho důvodu, že právě v tomto jazyku může dojít ke změně sémantiky algoritmu ve chvíli, kdy se mixují mezery a tabulační značky:
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import TerminalFormatter
from pygments.filters import VisibleWhitespaceFilter
code = """
for i in range(1, 11):
\tprint("Hello world!")
if x and y:
print("yes")
if x or y:
\tprint("dunno")
"""
print(highlight(code, PythonLexer(), TerminalFormatter()))
print("-----------------------")
lexer = PythonLexer()
lexer.add_filter(VisibleWhitespaceFilter(tabs=True))
print(highlight(code, lexer, TerminalFormatter()))
Příklad použití tohoto typu filtru:

Obrázek 14: Ukázka použití filtru, který dokáže rozpoznat nová bílé znaky (povšimněte si zvýraznění tabů pomocí znaků »).
16. Změna velikosti písmen v klíčových slovech
Třetí standardní filtr, který se jmenuje KeywordCaseFilter, se používá pro změnu velikosti písmen klíčových slov. U některých jazyků nemá větší význam, protože velikost písmen je pevně specifikovaná normou jazyka (C, Java, Python atd.), ale například u Pascalu je možné tento filtr použít pro zobrazení všech zdrojových kódů stejným stylem i ve chvíli, kdy programátoři různým způsobem míchají velká a malá písmena. V dalším příkladu je zdrojový kód napsaný právě v Pascalu vykreslen čtyřmi různými způsoby:
- Bez úpravy velikosti písmen
- Klíčová slova jsou vypsána verzálkami
- Klíčová slova jsou vypsána mínuskami
- Klíčová slova mají první písmeno verzálkou a další mínuskou
from pygments import highlight
from pygments.lexers.pascal import DelphiLexer
from pygments.formatters import TerminalFormatter
from pygments.filters import KeywordCaseFilter
code = """
procedure change(s:string);
begin
s[10]:='a';
end;
const
c:packed array [0..1000] of char = 'staticky retezec';
var
s1:string[10];
s2:string;
i:integer;
begin
s1:='hello';
writeln('"', s1, '"');
s1:=s1+' world';
writeln('"', s1, '"');
for i:=0 to 1000 do begin
s2:=s2+'*';
end;
change(s2);
writeln(s2);
end.
"""
print(highlight(code, DelphiLexer(), TerminalFormatter()))
input()
print("-----------------------")
lexer = DelphiLexer()
lexer.add_filter(KeywordCaseFilter(case='lower'))
print(highlight(code, lexer, TerminalFormatter()))
input()
print("-----------------------")
lexer = DelphiLexer()
lexer.add_filter(KeywordCaseFilter(case='upper'))
print(highlight(code, lexer, TerminalFormatter()))
input()
print("-----------------------")
lexer = DelphiLexer()
lexer.add_filter(KeywordCaseFilter(case='capitalize'))
print(highlight(code, lexer, TerminalFormatter()))
Příklad použití tohoto typu filtru:
 <
<
Obrázek 15: Klíčová slova jsou vytištěna malými písmeny.
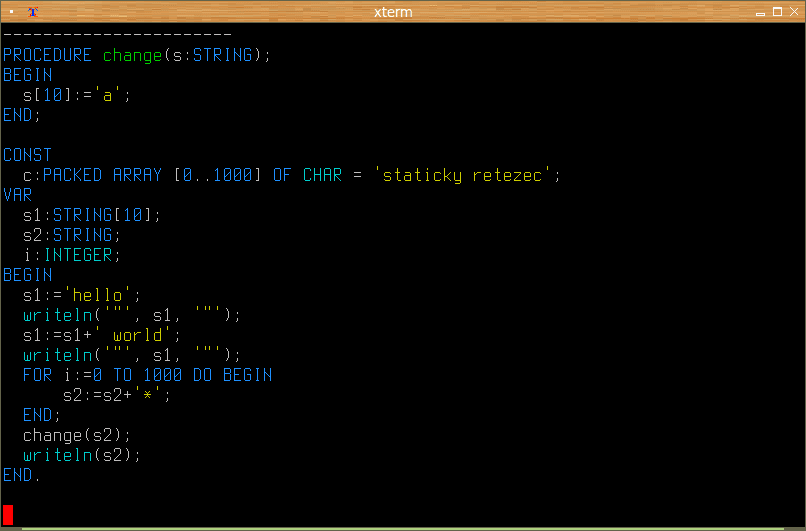
Obrázek 16: Klíčová slova jsou vytištěna velkými písmeny.

Obrázek 17: Klíčová slova jsou kapitalizována.
17. Jednoduchý lexer založený na rozpoznávání klíčových slov a regulárních výrazů
Náš první lexer je velmi jednoduchý, protože bude sloužit pro rozpoznání několika klíčových slov. Bude se jednat o třídu nazvanou FooLangLexer, která bude odvozena od třídy RegexLexer, což je lexer založený na rozpoznávání textu s využitím regulárních výrazů. Náš lexer bude v první řadě rozpoznávat čtyři klíčová slova for, while, begin a end (regulární výrazy jsou tedy triviální) a pokud bude dané slovo rozpoznáno, zobrazí se stylem odpovídajícím kategorii „Keyword“ (což je standardně zelená barva). Dále bude rozpoznáno jméno funkce print a klíčové slovo goto bude považováno za chybu. Jiný text se zobrazí stylem odpovídajícím kategorii „Generic.Normal“ (což je standardně barva červená):
class FooLangLexer(RegexLexer):
name = 'foolang'
aliases = ['foolang']
filenames = ['*.foolang']
tokens = {
'root': [
(r'\ *print', Name.Function),
(r'for', Keyword),
(r'while', Keyword),
(r'goto', Generic.Error),
(r'begin', Keyword),
(r'end', Keyword),
(r'.+', Generic.Normal),
]
}
Náš lexer bude do obarvovače zařazen následovně:
print(highlight(code, FooLangLexer(), TerminalFormatter()))
S výsledkem:

Obrázek 18: Velmi jednoduchý lexer v akci.

Pro úplnost si samozřejmě ukážeme úplný zdrojový kód tohoto příkladu:
from pygments import highlight
from pygments.lexer import RegexLexer
from pygments.token import *
from pygments.formatters import TerminalFormatter
from pygments.filters import NameHighlightFilter
class FooLangLexer(RegexLexer):
name = 'foolang'
aliases = ['foolang']
filenames = ['*.foolang']
tokens = {
'root': [
(r'\ *print', Name.Function),
(r'for', Keyword),
(r'while', Keyword),
(r'goto', Generic.Error),
(r'begin', Keyword),
(r'end', Keyword),
(r'.+', Generic.Normal),
]
}
code = """
for i in range(1, 11)
begin
print("Hello world!")
end
while i < 10
begin
inc i
print(i)
end
goto 10
"""
print(highlight(code, FooLangLexer(), TerminalFormatter()))
18. Repositář s demonstračními příklady
Všechny dnes popisované demonstrační příklady byly uloženy do Git repositáře, který je dostupný na adrese https://github.com/tisnik/presentations. Příklady si můžete v případě potřeby stáhnout i jednotlivě bez nutnosti klonovat celý (dnes již poměrně rozsáhlý) repositář:
19. Odkazy na Internetu
- Pygments – Python syntax highlighter
http://pygments.org/ - Pygments (dokumentace)
http://pygments.org/docs/ - Write your own lexer
http://pygments.org/docs/lexerdevelopment/ - Jazyky podporované knihovnou Pygments
http://pygments.org/languages/ - Pygments FAQ
http://pygments.org/faq/ - Pygments 2.2.0 (na PyPi)
https://pypi.org/project/Pygments/ - Syntax highlighting
https://en.wikipedia.org/wiki/Syntax_highlighting - Lexical analysis
https://en.wikipedia.org/wiki/Lexical_analysis - Lexical grammar
https://en.wikipedia.org/wiki/Lexical_grammar - Compiler Construction/Lexical analysis
https://en.wikibooks.org/wiki/Compiler_Construction/Lexical_analysis - Compiler Design – Lexical Analysis
https://www.tutorialspoint.com/compiler_design/compiler_design_lexical_analysis.htm - Lexical Analysis – An Intro
https://www.scribd.com/document/383765692/Lexical-Analysis - prompt_toolkit 2.0.3 na PyPi
https://pypi.org/project/prompt_toolkit/ - python-prompt-toolkit na GitHubu
https://github.com/jonathanslenders/python-prompt-toolkit - Comparing Python Command-Line Parsing Libraries – Argparse, Docopt, and Click
https://realpython.com/comparing-python-command-line-parsing-libraries-argparse-docopt-click/ - Rosetta Code
http://rosettacode.org/wiki/Rosetta_Code - Mandelbrot set: Sinclair ZX81 BASIC
http://rosettacode.org/wiki/Mandelbrot_set#Sinclair_ZX81_BASIC - Lexikální analýza (Wikipedia)
https://cs.wikipedia.org/wiki/Lexik%C3%A1ln%C3%AD_anal%C3%BDza - Quex, a lexical analyzer generator
http://quex.sourceforge.net/ - ATARI BASIC – tokenizace
https://www.atariarchives.org/dere/chapt10.php - BASIC token
https://www.c64-wiki.com/wiki/BASIC_token


































{kind=link}
{kind=link}