
Obsah
1. Vznik mikrořadičů: dokončení popisu čtyřbitového čipu Atmel MARC4
2. Nastavení příznaku branch na základě vypočtené podmínky
3. Operace s příznakovými bity
4. Přesuny dat mezi registry X, Y, SP a RP
6. Základní podpora pro počítané programové smyčky
10. Vznik a vývoj programovacího jazyka Forth
11. Forth: programovací jazyk, vývojové prostředí či operační systém?
12. Abstraktní dvouzásobníkový procesor
13. Základy programování ve Forthu: zásobník operandů
15. Podmínky a programové smyčky
1. Vznik mikrořadičů: dokončení popisu čtyřbitového čipu Atmel MARC4
V předchozím článku jsme se seznámili s architekturou poměrně zajímavých čtyřbitových mikrořadičů Atmel MARC4. Připomeňme si, že tyto mikrořadiče jsou založeny na zásobníkové architektuře, v níž je dvojice zásobníků (zásobník návratových adres a zásobník operandů) doplněna o čtveřici registrů X, Y, SP a RP s adresami do paměti dat. Zjednodušené schéma tohoto čipu můžeme vidět na prvním obrázku:
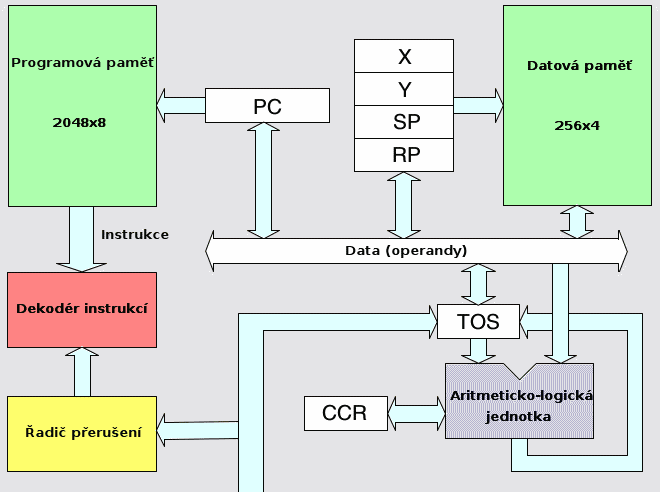
Obrázek 1: Zjednodušené schéma čtyřbitových mikrořadičů MARC4.
V instrukčním souboru nalezneme celkem osmdesát instrukcí, které je možné rozdělit do několika skupin. Prvních šest skupin jsme si již popsali minule, dalších sedm skupin instrukcí bude popsáno v navazujících kapitolách:
| Skupina instrukcí | Počet instrukcí ve skupině |
|---|---|
| Aritmetické instrukce | 7 |
| Logické instrukce | 4 |
| Rotace a posuny | 4 |
| Skoky a volání podprogramů | 5 |
| Operace se zásobníky | 10 |
| Načtení konstanty | 1 |
| Podmínky, nastavení příznaku branch | 6 |
| Operace s příznakovými bity | 4 |
| Přesuny dat mezi registry X, Y, SP a RP | 12 |
| Operace typu load & store | 16 |
| Základní podpora pro počítané programové smyčky | 3 |
| Vstupy a výstupy | 2 |
| Ostatní instrukce | 6 |
| Celkem: | 80 |
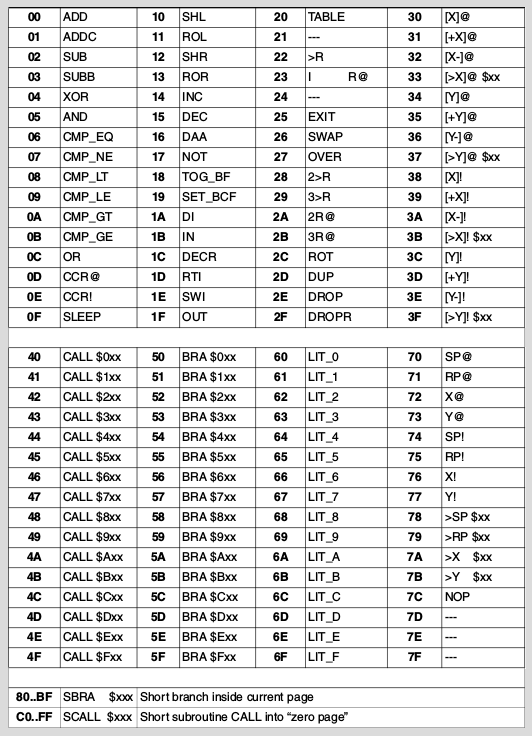
Obrázek 2: Obsazení všech 256 osmibitových kombinací instrukcemi (zdroj: Atmel).
2. Nastavení příznaku branch na základě vypočtené podmínky
Následující skupina šesti instrukcí porovná dva operandy ležící na zásobníku operandů a následně nastaví příznakový bit branch na základě porovnání těchto operandů. Posléze je operand ležící na vrcholu zásobníku (tedy na TOS) odstraněn, což je praktické, neboť se většinou provádí porovnání s konstantou:
| Instrukce | Význam |
|---|---|
| CMP_EQ | nastav B=1 za podmínky, že n1 = n2 |
| CMP_NE | nastav B=1 za podmínky, že n1 ≠ n2 |
| CMP_LT | nastav B=1 za podmínky, že n1 < n2 |
| CMP_LE | nastav B=1 za podmínky, že n1 ≤ n2 |
| CMP_GT | nastav B=1 za podmínky, že n1 > n2 |
| CMP_GE | nastav B=1 za podmínky, že n1 ≥ n2 |
Poznámka: to, že se nastavuje příznak branch a nikoli carry, je velmi praktické, neboť branch se používá u podmíněných skoků:
| Instrukce | Význam |
|---|---|
| BRA | podmíněný skok při splnění branch==1 (dlouhá varianta s 12bitovou adresou) |
| SBRA | podmíněný skok při splnění branch==1 (krátká varianta se šestibitovou adresou) |
3. Operace s příznakovými bity
Další čtyři instrukce slouží k manipulaci s příznakovými bity. Připomeňme si, že existují pouze dva příznakové bity nazvané carry a branch, které jsou uložené ve čtyřbitovém registru nazvaném CCR (další dva bity jsou neobsazené). To mj. znamená, že je možné registr CCR uložit na zásobník operandů nebo ho naopak ze zásobníku obnovit:
| Instrukce | Význam |
|---|---|
| CCR@ | uložení příznakových bitů na vrchol zásobníku operandů (TOS) |
| CCR! | obnovení příznakových bitů ze zásobníku operandů (z TOS) |
| SET_BCF | nastavení příznakových bitů carry i branch na jedničku |
| TOG_BF | negace příznakového bitu branch |
4. Přesuny dat mezi registry X, Y, SP a RP
Minule jsme si řekli, že mezi registry viditelné programátorům patří i čtveřice osmibitových registrů s uloženou adresou. Dva z těchto registrů RP a SP obsahují adresu vrcholu zásobníku návratových nebo vrcholu zásobníku operandů, další dva registry X a Y pak například adresu v poli atd. – tyto dva registry jsou využívané programátory:
| Registr | Šířka | Význam |
|---|---|---|
| RP | 8 bitů | ukazuje na vrchol zásobníku návratových adres, který je umístěný v RAM |
| SP | 8 bitů | ukazuje na druhý prvek uložený na zásobníku operandů, který je umístěný v RAM |
| X | 8 bitů | obecný (index) registr použitý při adresování |
| Y | 8 bitů | obecný (index) registr použitý při adresování |
Pro načtení hodnoty do těchto registrů popř. naopak pro uložení obsahu registrů slouží následujících dvanáct instrukcí. Prvních osm instrukcí načítá a ukládá obsah registrů na zásobník operandů, což znamená, že se vždycky bude pracovat se dvěma prvky (registry mají šířku osm bitů, zatímco prvky na zásobníku mají šířku jen čtyři bity):
| Instrukce | Význam |
|---|---|
| SP@ | na zásobník operandů se uloží obsah registru SP (do dvou prvků), SP se zvýší o 2 |
| RP@ | na zásobník operandů se uloží obsah registru RP (do dvou prvků) |
| X@ | na zásobník operandů se uloží obsah registru X (do dvou prvků) |
| Y@ | na zásobník operandů se uloží obsah registru Y (do dvou prvků) |
| SP! | dva prvky ze zásobníku operandů se použijí pro zápis nové hodnoty do SP |
| RP! | dva prvky ze zásobníku operandů se použijí pro zápis nové hodnoty do RP |
| X! | dva prvky ze zásobníku operandů se použijí pro zápis nové hodnoty do X |
| Y! | dva prvky ze zásobníku operandů se použijí pro zápis nové hodnoty do Y |
| >SP konstanta | konstanta (bajt) se zapíše do registru SP |
| >RP konstanta | konstanta (bajt) se zapíše do registru RP |
| >X konstanta | konstanta (bajt) se zapíše do registru X |
| >Y konstanta | konstanta (bajt) se zapíše do registru Y |
5. Operace typu load & store
Poměrně rozsáhlá skupina instrukcí slouží pro načtení či uložení dat na vrchol zásobníku operandů (TOS). Při adresování operandů se používají adresovací registry X a Y, jejichž obsah (adresa) může být instrukcí modifikována, neboť jsou podporovány pre-inkrementy a post-dekrementy adresy. Díky tomu lze velmi efektivním způsobem procházet poli, a to mnohem efektivnějším způsobem, než je tomu i u některých výkonnějších osmibitových mikrořadičů:
| Instrukce | Význam |
|---|---|
| [X]@ | z RAM na adrese uložené v registru X se načtou data a uloží na TOS |
| [Y]@ | z RAM na adrese uložené v registru Y se načtou data a uloží na TOS |
| [+X]@ | nejprve se zvýší obsah registru X a posléze se provede instrukce [X]@ |
| [+Y]@ | nejprve se zvýší obsah registru Y a posléze se provede instrukce [Y]@ |
| [X–]@ | nejprve se provede instrukce [X]@ a poté se sníží obsah registru X |
| [Y–]@ | nejprve se provede instrukce [Y]@ a poté se sníží obsah registru Y |
| [>X]@ konstanta | provede se instrukce [X]@ a poté se do registru X načte nová konstanta |
| [>Y]@ konstanta | provede se instrukce [Y]@ a poté se do registru Y načte nová konstanta |
| [X]! | obsah TOS se uloží do RAM na adresu uloženou v registru X |
| [Y]! | obsah TOS se uloží do RAM na adresu uloženou v registru Y |
| [+X]! | nejprve se zvýší obsah registru X a posléze se provede instrukce [X]! |
| [+Y]! | nejprve se zvýší obsah registru Y a posléze se provede instrukce [Y]! |
| [X–]! | nejprve se provede instrukce [X]! a poté se sníží obsah registru X |
| [Y–]! | nejprve se provede instrukce [Y]! a poté se sníží obsah registru Y |
| [>X]! konstanta | nejprve se provede instrukce [X]! a poté se do registru X načte nová konstanta |
| [>Y]! konstanta | nejprve se provede instrukce [Y]! a poté se do registru Y načte nová konstanta |
6. Základní podpora pro počítané programové smyčky
Při implementaci počítaných programových smyček se většinou počitadlo smyčky ukládá na zásobník návratových adres. To s sebou přináší několik výhod, například uvolnění zásobníku operandů pro výpočty, uvolnění registrů X a Y pro indexování prvků v polích atd. Aby nebylo nutné při přepočtu hodnoty počitadla neustále přesunovat hodnotu ze zásobníku návratových adres na zásobník operandů a zpět, byla do instrukčního souboru čipů MARC4 přidána instrukce DECR, která počitadlo sníží přímo na zásobníku návratových adres a současně nastaví příznak branch podle toho, zda se dosáhlo nuly či nikoli. Následně je možné použít podmíněný skok používající právě tento příznak:
| Instrukce | Význam |
|---|---|
| >R | přesun hodnoty z TOS zásobníku operandů na zásobník návratových adres s rozšířením na 12 bitů |
| R@ | opak předchozí instrukce |
| I | alias předchozí instrukce |
| DECR | snížení indexu (počitadla) uloženého na vrcholu zásobníku návratových adres, nastavení příznaku branch |
7. Vstupy a výstupy
Tato kapitola bude velmi krátká, protože v instrukčním souboru čipů MARC4 najdeme pouze dvě instrukce určené pro ovládání vstupních a výstupních pinů. Tyto instrukce vždy pracují se čtyřmi piny a proto se mohou přečtené hodnoty či naopak hodnoty, na něž se mají piny nastavit, přenášet z vrcholu zásobníku operandů (TOS):
| Instrukce | Význam |
|---|---|
| IN | čtyři bity přečtené z I/O portu jsou zapsány na vrchol zásobníku operandů |
| OUT | opačná instrukce, zápis čtyř bitů z TOS zásobníku operandů na I/O port |
8. Ostatní instrukce
Na závěr se krátce zmiňme o instrukcích, které nespadají do žádné výše uvedené kategorie:
| Instrukce | Význam |
|---|---|
| NOP | pravděpodobně není nutné zdlouhavě popisovat :-) |
| DI | zákaz všech přerušení |
| RTI | návrat z rutiny přerušení |
| SWI | vyvolání softwarového přerušení |
| SLEEP | přechod MCU do režimu spánku |
| TABLE | načtení osmibitové konstanty z paměti ROM a uložení na TOS |
9. Programování čipů MARC4
Pro čipy MARC4 je možné vytvářet programy buď v assembleru nebo v programovacím jazyce Forth, konkrétně v jeho variantě nazvané qFORTH. Tento dialekt Forthu podporuje všechny základní řídicí konstrukce, tedy BEGIN .. AGAIN, BEGIN .. UNTIL, CASE .. ENDCASE, DO .. LOOP, IF .. THEN, IF .. ELSE .. THEN, BEGIN .. WHILE .. REPEAT (setkáme se s nimi v patnácté kapitole). Kromě toho podporuje práci se čtyřbitovými a osmibitovými operandy, přičemž při použití osmibitových operandů je generován poměrně neefektivní kód (což je ovšem vzhledem k interní architektuře čipu pochopitelné). Kromě toho podporuje qFORTH i direktivy preprocesoru, které se vzdáleně podobají direktivám známým z céčka:
$IFDEF MUX4–LCD $INCLUDE LCD–MUX4.SCR $ELSE $INCLUDE LCD–MUX3.SCR $ENDIF
Většina implementací Forthu sice umožňuje interaktivní tvorbu programu i jeho interaktivní ladění, ovšem v případě qFORTHu je tomu jinak, protože se jedná o překladač. Tato vlastnost je opět pochopitelná, zvláště když si uvědomíme, jak malá je kapacita paměti RAM. Překlad je poměrně přímočarý a to díky chytře zvolené instrukční sadě čipů MARC4. Pro qFORTH je dodáváno vývojové prostředí, které je s velkou pravděpodobností vytvořeno v TurboVision a vypadá tedy podobně, jako například známé IDE společnosti Borland (TurboPascal, Turbo C, Borland C++ atd.).
Poznámka: vzhledem k minimálním kapacitám RAM i ROM, instrukční sadě, možnostem adresování a ostatně i čtyřbitové šířce ALU nemá pro tyto čipy použití jazyka typu C vlastně žádný velký praktický význam.
10. Vznik a vývoj programovacího jazyka Forth
Vývoj programovacího jazyka Forth probíhal velmi zajímavě. Nikdy se totiž nejednalo o čistě „akademický produkt“, který by měl reprezentovat nějakou nosnou revoluční myšlenku (a tím méně o jazyk určený pro výuku programování), ale o programovací jazyk, který vytvořil v podstatě jeden člověk pro svoji osobní potřebu tak, aby přesně splňoval jeho pracovní požadavky. Tento programátor se jmenuje Charles „Chuck“ Moore a dodnes patří mezi zajímavé a současně velmi rozporuplné osobnosti, které se podílely na rozvoji výpočetní techniky, zejména vestavěných (embedded) řídících systémů a systémů běžících v reálném čase. Moore byl prý překvapen, když zjistil, že systém, který vyvinul pro své potřeby, používají i další lidé, kterým v jejich práci vyhovuje více než v té době komerčně prosazovaný Fortran).
Do značně heterogenního prostředí počítačů a operačních systémů sedmdesátých let přišel Moore se svým jazykem (či lépe řečeno celou vývojovou platformou) Forth. Vývojové prostředí Forthu obsahovalo interaktivní editor, interpret jazyka Forth a univerzální vazbu na assembler upravený na právě provozovaný systém. Toto prostředí umožňovalo spouštět souběžně více procesů a současně mohlo v systému nezávisle pracovat až 64 uživatelů, a to i na platformách, jejichž operační systém nebyl multiuživatelský a dokonce ani multitaskový.
Ve skutečnosti Forth (resp. jeho vývojové prostředí, tyto dva pojmy však většinou splývají) nepotřeboval pro své spuštění žádný operační systém, pracoval totiž přímo s periferními zařízeními – z toho také vyplývá skutečnost, že se zdrojové kódy vytvářených aplikací neukládaly tak jako dnes do textových souborů, ale byly v předkompilované či přímo přeložené podobě uloženy v blocích pevné délky (takzvaných obrazovkách), které se podle potřeby nahrávaly do operační paměti počítače. Tyto programové bloky u mnoha systémů odpovídaly velikosti bloků na disku (typická velikost je 512 B a 1 kB), což značně urychlovalo práci s disky, protože se nemusely provádět složité přepočty adres na bloky. Na druhou stranu se nejedná o příliš efektivní způsob uložení a ani násilné rozdělování programů na obrazovky nemusí všem programátorům vyhovovat (zejména v současnosti).
11. Forth: programovací jazyk, vývojové prostředí či operační systém?
Chuck Moore začal vytvářet programovací jazyk Forth docela nevinně – zpočátku se jednalo pouze o jakási makra, která používal při programování aplikací z oblasti astronomie (jednalo se o poměrně složité astronomické výpočty a řízení radioteleskopů). Tato makra se postupným vývojem proměnila v translátor vyšších operací do jazyka symbolických adres (assembleru) a v dalších letech pak do plnohodnotného i když dosti neobvyklého interaktivního programovacího jazyka s vlastním vývojovým prostředím.
Jedná se přitom o jazyk interpretovaný, i když jiným způsobem, než je dnes zvykem, a současně plně a oboustranně interaktivní. Z tohoto důvodu se v něm aplikace vyvíjí a především testují velmi jednoduše, zejména v porovnání s jazyky kompilovanými, jako jsou dnes často používané programovací jazyky C, C++, (polomrtvý) Pascal, C# a v podstatě i Java. Všechny vyjmenované kompilované jazyky potřebují pro vývoj programů mnoho podpůrných prostředků (editor, překladač, linker, debugger), které však mezi sebou nejsou (a ani nemohou být) příliš propojeny – proto je v nich ladění programů poměrně těžkopádné, vyžaduje knihovny s debug symboly atd.
Ve Forthu jsou všechny tyto prostředky sloučeny, ale to v žádném případě neznamená, že by vznikl mnohasetkilobajtový moloch. Naopak, celé vývojové prostředí Forthu zabírá jednotky, maximálně desítky kilobytů. Vývojové prostředí Forthu je totiž účelně vytvořeno tak, že obsahuje jen nejnutnější součásti (ostatně Chuck Moore zapřísáhlý minimalista, což je patrné i při pohledu na design čipů, které navrhl).
Výpočetní výkon počítačů v té době nebyl příliš vysoký, k čemuž se dále přidávala poměrně vysoká cena za jednotku strojového času. Programátoři byli nuceni vytvářet programy co nejrychlejší a s co nejmenšími nároky na kapacitu operační paměti (v té době se to vyplatilo, v dnešním světě je v mnoha případech jednodušší programovat resp. „bastlit“ co nejrychleji a ušetřené prostředky investovat do nového hardwaru). Časově kritické úseky aplikací se tedy neustále tvořily v assembleru, k čemuž byl Forth dokonale připraven, neboť existovalo jednoduché programátorské i aplikační rozhraní pro přístup k assembleru.
Také fakt, že Forth využíval vlastní blokový souborový systém (v dnešních OS se kromě toho používá „proudový“ souborový systém, i když nejmenší adresovatelná jednotka na disku je právě jeden blok), v některých aplikacích značně urychlil práci se soubory. Týká se to zejména databázových aplikací a aplikací pro zpracování obrazu.
12. Abstraktní dvouzásobníkový procesor
Programovací jazyk Forth byl určen zejména pro implementaci na takzvaných zásobníkových procesorech, přesněji řečeno na procesorech s minimálně dvěma zásobníky – zásobníkem operandů (operand stack nebo pouze stack) a zásobníkem návratových adres (return stack). Tyto procesory se od dnes nejpoužívanějších registrových procesorů liší především způsobem provádění aritmetických a logických operací. Prosím povšimněte si, že právě tyto dva zásobníky najdeme na čtyřbitových mikrořadičích MARC4. To však zdaleka není všechno – většina instrukcí MARC4 přímo odpovídá slovům (příkazům) programovacího jazyka Forth, což ostatně uvidíme v navazujících třech kapitolách.
Poznámka: „pravé“ zásobníkové procesory mají zásobníky uloženy ve specializovaných blocích paměti, zatímco u MARC4 jsou součástí operační (datové) paměti. U takto malých čipů to má svůj význam, u větších procesorů se naopak vyžadoval větší výpočetní výkon a tudíž i paralelní přístup k zásobníkům.
13. Základy programování ve Forthu: zásobník operandů
Forth je mezi programátory znám především jako jazyk, ve kterém se aritmetické a logické výrazy zapisují pomocí RPN – Reverse Polish Notation (obrácené polské notace) označované také jako postfixová notace. Při tomto způsobu zápisu se nejdříve uvádějí operandy a teprve poté operace, která se s těmito operandy může provádět.
Už na základní škole se však každý člověk učí takzvanou infixovou notaci zápisu, ve které se operátory píšou mezi operandy. Vzhledem k prioritě operátorů je však nutné v infixové notaci používat závorky. Rozdíl mezi následujícími dvěma výrazy uvedenými v infixové notaci je snad zřejmý:
a+b*c (a+b)*c
Při použití postfixové notace nejsou závorky zapotřebí, protože se priorita operací vyjadřuje přímo posloupností operátorů. Výše uvedené výrazy lze tedy do postfixové notace přepsat následovně:
a b c * + nebo též b c * a + a b + c * nebo též c a b + *
Všimněte si, že u výrazů napsaných na levé straně se oproti infixové notaci nemění pořadí operátorů.
Pomocí postfixové notace je možné zapisovat všechny operace i funkce, dokonce ani nezáleží na počtu operandů (stírá se rozdíl mezi unárními. binárními, ternárními apod. operacemi). Ve skutečnosti není v postfixové notaci prakticky žádný rozdíl mezi operacemi a funkcemi, takže pro ně není nutné zavádět nějaká zvláštní syntaktická pravidla.
Důsledkem výše uvedených skutečností je fakt, že znaky běžně používané pro operátory je možné použít pro jiné účely, podobně jako například v jazyce Lisp nebo Scheme (což jsou mimochodem jazyky používající prefixovou notaci).
Aritmetické operace se ve Forthu zapisují přesně podle infixové notace s tou podmínkou, že jednotlivé operátory od sebe musí být odděleny mezerou, znakem tabelátoru či znakem pro konec řádku. Příklad zápisu některých aritmetických operací a jejich kombinací:
10 20 + 10 20 * 10 20 - 10 20 + 30 * 5 4 3 2 1 * / + -
Význam výše uvedených operací ve Forthu je následující: samotný zápis čísla znamená, že se toto číslo uloží do zásobníku. Zápis operátoru způsobí, že se operandy vyberou ze zásobníku, provede se s nimi operace a výsledek se uloží zpět na zásobník. Vzhledem k tomu, že všechny zmíněné operace jsou binární, vyberou se ze zásobníku dvě hodnoty a zpět se zapíše pouze jediná hodnota, tj. počet položek na zásobníku se o jednu sníží.
S operandy umístěnými na zásobníku operandů lze provádět některé operace, jejichž názvy přitom odpovídají názvům instrukcí mikrořadiče MARC4 (což samozřejmě není náhoda, ale záměr):
Prohození dvou operandů:
1 2 swap
Duplikace (kopie) operandu na TOS:
1 dup
Opak předchozí operace – odstranění operandu z TOS:
1 2 drop
Slovo over se podobá výše popsanému slovu dup, tj. provádí se kopie hodnoty uložené v zásobníku. V tomto případě se však jedná o hodnotu uloženou pod vrcholem zásobníku, nikoli o hodnotu uloženou přímo na vrcholu zásobníku:
1 2 over
Slovo rot manipuluje hned se třemi položkami uloženými na zásobníku. Jak již název tohoto slova napovídá, provádí se rotace položek, a to tak, že datová položka na třetí nejvyšší pozici v zásobníku operandů je vyjmuta a uložena na jeho vrchol:
1 2 3 rot
14. Vytváření nových slov
Forth místo funkcí, operací a řídicích struktur používá pouze slova. Slova se zadávají z klávesnice nebo ze vstupního souboru a jsou určena svým jménem. Jméno je ve Forthu libovolný řetězec znaků, který je oddělen (ukončen) mezerou nebo v novějších verzích libovolným „bílým znakem“. Každé volání funkce je ve forthovském programu nahrazeno jejím jménem bez dalších znaků (závorek apod.), protože veškeré parametry funkce i její návratová hodnota jsou uloženy na zásobníku:
Příkladem slova může být například mocnina. Toto slovo vezme ze zásobníku hodnotu a na zásobník vrátí její druhou mocninu. Slovo může vypadat následovně:
: mocnina dup * ;
Nejdříve se tedy provede duplikace hodnoty na vrcholu zásobníku. Poté se obě (shodné) hodnoty ze zásobníku vyjmou, vynásobí a na zásobník se uloží výsledek operace násobení. Použití tohoto slova je opět velmi jednoduché:
2 mocnina
Poznámka: závěrečný středník na konci slova se překládá do instrukce EXIT.
15. Podmínky a programové smyčky
Nedílnou součástí všech imperativních programovacích jazyků je i jazyková konstrukce pro podmínky. Forth se k této problematice staví poněkud odlišným způsobem: pro zápis podmínek používá tři slova, nejedná se tedy o speciální jazykovou konstrukci, ale o mimořádně flexibilní mechanismus, který umožňuje přidávat i další „strukturované“ konstrukce bez zásahu do překladače:
logický_výraz
if
příkazy_1_větve
else
příkazy_2_větve
then
Interně se provede překlad do vyhodnocení podmínky (na zásobníku), if a else se přeloží jako podmíněný skok a then slouží jako návěští pro konec bloku if.
Jedním ze základních typů cyklů ve Forthu je smyčka typu do-loop. Jedná se o počítanou smyčku, která zhruba odpovídá smyčce for z Pascalu, Fortranu či Basicu:
10 1 do loop
Pro tvorbu prvního typu nepočítaných smyček, kdy se podmínka pro ukončení smyčky testuje ještě před první iterací, se používají slova begin, while a repeat. Způsob jejich použití ilustruje následující kód:

begin
podmínka
while
tělo smyčky
repeat
Další formou nepočítané smyčky je smyčka, při které se test provádí až na konci. Tato smyčka se konstruuje pomocí slov begin a until. Způsob použití je následující:
: gcd
begin
swap over mod
dup 0=
until
drop
. cr
;
V některých případech se hodí testovat podmínku na ukončení smyčky uvnitř jejího těla, tj. nikoli přísně na začátku a na konci. Pro tento typ problémů je možné použít nekonečné smyčky, které se tvoří pomocí slov begin a again. Způsob použití tohoto typu smyček je jednoduchý:
begin
tělo smyčky
again
16. Odkazy na Internetu
- Zero-power Microcontrollers for Low-power and High-temperature Applications
http://en.wikichip.org/w/images/1/17/Atmel_MARC4_brochure.pdf - MARC4 Micro-Controller (Wikipedia)
https://en.wikipedia.org/wiki/MARC4_Micro-Controller - MARC4 – Atmel
https://en.wikichip.org/wiki/atmel/marc4 - MARC 4bit Microcontrollers Programmer's Guide
https://en.wikichip.org/w/images/4/44/MARC4_4-bit_Microcontrollers_Programmer%27s_Guide.pdf - MARC4 User's Guide qFORTH Compiler
https://en.wikichip.org/w/images/2/25/MARC4_User%27s_Guide_qFORTH_Compiler.pdf - Programovací jazyk Forth a zásobníkové procesory
http://www.root.cz/clanky/programovaci-jazyk-forth-a-zasobnikove-procesory/ - Seriál Programovací jazyk Forth
http://www.root.cz/serialy/programovaci-jazyk-forth/ - Programovací jazyk Factor
http://www.root.cz/clanky/programovaci-jazyk-factor/ - Grafický metaformát PostScript
http://www.root.cz/clanky/graficky-metaformat-postscript/ - PMOS
https://en.wikipedia.org/wiki/PMOS_logic - NMOS
https://en.wikipedia.org/wiki/NMOS_logic - CMOS
https://en.wikipedia.org/wiki/CMOS - Vacuum Fluorescent Display
https://en.wikipedia.org/wiki/Vacuum_fluorescent_display - Computer History Museum: TMS 1000 4-Bit microcontroller
http://www.computerhistory.org/collections/catalog/102711697 - Texas Instruments TMS1000 microcontroller family
http://www.cpu-world.com/CPUs/TMS1000/ - Invention History of Microcontroller
http://www.circuitstoday.com/microcontroller-invention-history - TMS1000 Series – TI
https://en.wikichip.org/wiki/ti/tms1000 - TMX1795 – TI
https://en.wikichip.org/wiki/ti/tmx1795 - Milton Bradley Microvision (U.S.) (1979, LCD, 9 Volt (1 or 2), Model# 4952)
http://www.handheldmuseum.com/MB/uVUS.htm - 8051 Microcontroller
http://www.circuitstoday.com/8051-microcontroller - 4-bit (computer architectures)
https://en.wikipedia.org/wiki/4-bit - TMS 1000 Data Manual
http://blog.kevtris.org/blogfiles/TMS_1000_Data_Manual.pdf - Considerations for 4-bit processing
http://www.embeddedinsights.com/channels/2010/12/10/considerations-for-4-bit-processing/ - Are you, or would you consider, using a 4-bit microcontroller?
http://www.embeddedinsights.com/channels/2010/11/24/are-you-or-would-you-consider-using-a-4-bit-microcontroller/ - MARC4 Micro-Controller
https://en.wikipedia.org/wiki/MARC4_Micro-Controller - The Texas Instruments TMX 1795: the (almost) first, forgotten microprocessor
http://www.righto.com/2015/05/the-texas-instruments-tmx-1795-first.html - O2 Homepage
http://www.the-nextlevel.com/odyssey2/ - Magnavox Odyssey2 (1978), Philips Videopac G7000 / C52 (1979)
http://www.mess.org/sysinfo:odyssey2 - The Video Game Critic's Odyssey 2 Reviews
http://videogamecritic.net/odd.htm - Computer Closet Collection: Magnavox Odyssey2
http://www.computercloset.org/MagnavoxOdyssey2.htm - PHILIPS Videopac C52
http://old-computers.com/museum/computer.asp?c=1060 - O2 Tech. Manual V.1.1 (PDF dokument)
http://www.atarihq.com/danb/files/o2doc.pdf - Magnavox Odyssey2
http://www.game-machines.com/consoles/odyssey2.php - Magnavox Odyssey2 (Wikipedia EN)
http://en.wikipedia.org/wiki/Odyssey2 - Magnavox Odyssey2 Games (Wikipedia EN)
http://en.wikipedia.org/wiki/List_of_Videopac_games




































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU