
Obsah
1. Technologické rozdíly mezi architekturami RISC/CISC a zásobníkovými procesory
2. Instrukční pipeline u zásobníkových procesorů
3. Problémy při použití konvenčních programovacích jazyků na zásobníkových procesorech
4. Neortodoxní zásobníkové mikroprocesory: MuP21 a F21
5. Mikroprocesory MuP21 a F21 versus procesory CISC a RISC
6. Datový zásobník (zásobník operandů), zásobník návratových adres a adresní registr A
7. Instrukční soubor procesoru F21
8. Procesory a procesorová jádra navazující na dvojici MuP21 a F21
1. Technologické rozdíly mezi architekturami RISC/CISC a zásobníkovými procesory
V předcházející části seriálu o architekturách počítačů jsme se seznámili se zásobníkovými mikroprocesory a taktéž jsme si řekli, jaké vlastnosti mají tyto procesory společné či naopak rozdílné při porovnání s procesorovými architekturami RISC a CISC. Z pohledu programátora pracujícího v assembleru spočívá nejpodstatnější rozdíl v tom, že u zásobníkových procesorů jsou všechny operandy umístěny buď v zásobníku operandů (datovém zásobníku), popř. na zásobníku návratových adres, tj. nikoli v pracovních registrech, jak je tomu u architektury RISC či v kombinaci pracovních registrů a operační paměti, jak tomu je u architektury CISC. Ovšem z hlediska složitosti mikroprocesoru (počtu tranzistorů) a taktéž jeho výpočetního výkonu je důležité taktéž interní uspořádání funkčních bloků, z nichž se procesor skládá, samozřejmě včetně instrukční pipeline. Jak již víme z předchozích částí tohoto seriálu, je instrukční pipeline nedílnou součástí mikroprocesorů s architekturou RISC, protože právě díky této technologii je zaručen jejich vysoký výpočetní výkon.

Obrázek 1: 32bitový mikroprocesor AMD 386DX je typickým zástupcem mikroprocesorů s komplexní instrukční sadou – CISC.
Převážná část snahy konstruktérů mikroprocesorů RISC je zaměřena na to, aby byla instrukční pipeline co nejlépe využita. Proto se také objevily prediktory skoků, branch delay sloty, překladače provádějící rozbalování smyček či tvorbu inline funkcí a i vyrovnávací paměti (cache) v podstatě slouží k tomu, aby se nejlépe v každém taktu začala zpracovávat nová instrukce. Připomeňme si, že v instrukční pipeline jsou strojové instrukce rozloženy do jednodušších operací, z nichž každá je vykonána za jeden strojový takt. Tyto jednodušší operace jsou prováděny v samostatně pracujících funkčních modulech, což znamená, že v jeden okamžik může být v ideálním případě rozpracováno tolik instrukcí, kolik „řezů“ má instrukční pipeline. Mikroprocesory postavené na architektuře MIPS využívaly dnes již klasickou „RISCovou“ pipeline s pěti fázemi:
| Zkratka | Celý název | Význam |
|---|---|---|
| IF | Instruction Fetch | načtení instrukčního kódu z operační paměti a současné zvýšení hodnoty čítače instrukcí |
| ID | Instruction Decode | dekódování instrukce a výběr registrů pro provedení operace |
| EX | Execute | vlastní operace provedená většinou v ALU, popř. vyhodnocení podmínky skoku |
| MA | Memory Access | načtení či uložení hodnot do operační paměti |
| WB | Write Back | uložení vypočtené hodnoty nebo hodnoty načtené z operační paměti zpět do vybraného pracovního registru |

Obrázek 2: Mikroprocesor PA RISC firmy Hewlett-Packard, který je zde zobrazen spolu s dalšími podpůrnými obvody a paměťmi cache.
Čistě teoreticky je tedy možné, aby se v mikroprocesoru současně zpracovávalo pět instrukcí (každá v jiné fázi – operaci), jak je to naznačeno na následujícím schématu:
CLK Instrukce: 1. 2. 3. 4. 5. ============================= 01 IF -- -- -- -- 02 ID IF -- -- -- 03 EX ID IF -- -- 04 MA EX ID IF -- 05 WB MA EX ID IF 06 -- WB MA EX ID 07 -- -- WB MA EX 08 -- -- -- WB MA 09 -- -- -- -- WB
U architektury SPARC je struktura instrukční pipeline poněkud odlišná, protože samotná pipeline je sestavena pouze ze čtveřice řezů, v nichž se provádí operace Instruction Fetch (IF), Execute (EX), Memory Access (MA) a Write Back (WB). Díky tomu, že je vynechána operace Instruction Decode, je možné, aby druhá instrukce v pipeline využila výsledky vypočtené v předchozí instrukci (bypass), takže v tomto případě nedojde k vložení zpožďovacích „prázdných“ slotů (delay slotů). Na následujícím schématu je naznačeno, v jakém stavu se nachází čtveřice instrukcí v instrukční pipeline za předpokladu, že procesor nepoužil žádný delay slot:
CLK Instrukce: 1. 2. 3. 4. ========================== 01 IF -- -- -- 02 EX IF -- -- 03 MA EX IF -- 04 WB MA EX IF 05 -- WB MA EX 06 -- -- WB MA 07 -- -- -- WB

Obrázek 3: Struktura moderní varianty multiprocesoru postaveného na čipech PA-RISC.
2. Instrukční pipeline u zásobníkových procesorů
„While Unix/C programmers on RISC processors are unhappy with less than 8M to 16M bytes of memory, and want 128K bytes of cache, Forth programmers are still engaged in heated debate as to whether more than 64K bytes of program space is really needed on stack machines“
U zásobníkových procesorů je však použitá technologie poněkud odlišná od RISCových procesorů, protože zásobníkové procesory mají většinou pouze dvoufázovou instrukční pipeline, tj. současně se provádí pouze dvě instrukce. V první fázi dochází k načtení instrukčního slova a současně se provádí vybraná ALU operace u instrukce předešlé. Fáze dekódování instrukce je přeskočena, protože se u většiny zásobníkových procesorů používá horizontální formát instrukcí a navíc se operandy vždy nachází na prvních dvou položkách zásobníku operandů (popř. se nejedná o ALU operaci, ale například o instrukci přenosu či načtení dat z operační paměti). Na vstupu ALU se většinou nachází dvojice interních registrů, které nahrazují nejvyšší dvě položky zásobníku, tj. ALU má v každém okamžiku k dispozici data pro provedení operace. Navíc se výsledek ALU operace (z předchozí instrukce) ihned zpětnovazební smyčkou zapisuje do jednoho z těchto registrů, což je další rozdíl oproti procesorům RISC a CISC. Ve výsledku tedy pro ALU operace vypadá překrývání instrukcí u zásobníkových procesorů následovně:
CLK Instrukce: 1. 2. 3. 4. ========================== 01 IF -- -- -- 02 EX IF -- -- 03 -- EX IF -- 04 -- -- EX IF 05 -- -- -- EX

Obrázek 4: Struktura zásobníkového mikroprocesoru se zvýrazněnou aritmeticko-logickou jednotkou (modrá barva), shifterem (zelená barva) a dvojicí interních registrů suplujících funkci dvou nejvyšších prvků zásobníku operandů (červená barva).
Na rozdíl od procesorů s architekturou RISC či CISC nedochází u zásobníkových procesorů k hazardům, které se u jiných architektur musí řešit například změnou pořadí instrukcí, vkládáním instrukcí typu NOP, popř. (pro některé případy) vytvořením „zkratky“ mezi jednotlivými fázemi instrukční pipeline. Zatímco u RISC a CISC s pipeline mající větší počet řezů se překladače snaží o to, aby se v po sobě následujících instrukcích nepoužily stejné registry, je u zásobníkových procesorů problém přesně opačný – v ideálním případě se všechny instrukce provádí s operandy umístěnými na vrcholu zásobníku, tj. ve skutečnosti ve dvojici interních registrů připojených na vstup aritmeticko-logické jednotky. Problém při vykonávání jednotlivých operací samozřejmě nastává u instrukcí typu „Load and Store“, řešen je většinou podobným způsobem, jako je tomu u procesorů s architekturou RISC, tj. pozdržením fáze IF následující instrukce (ovšem některé zásobníkové procesory používají oddělenou datovou paměť od paměti programu, tudíž k uvedeným problémům nedochází).
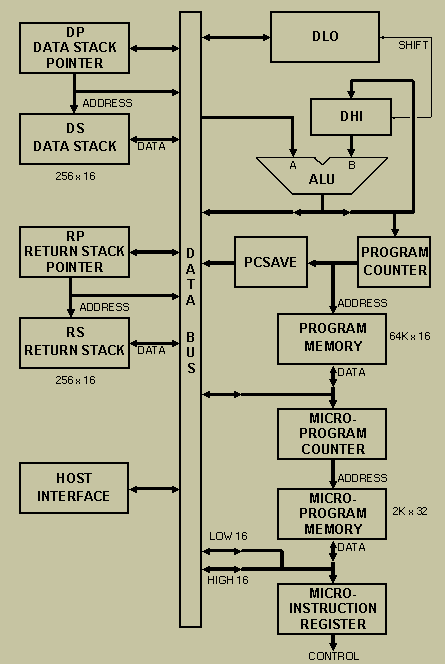
Obrázek 5: Blokové schéma zásobníkového procesoru WISC CPU/16.
Zdroj: P. Koopman – Architecture of the WISC CPU/16
3. Problémy při použití konvenčních programovacích jazyků na zásobníkových procesorech
V minulosti se na příkladu poměrně velkého množství různých procesorových architektur ukázalo, že jednou z podmínek nutných pro úspěch daného procesoru je existence optimalizujících překladačů programovacích jazyků C, C++ a v některých případech (například v segmentu procesorů určených pro superpočítače) taktéž překladače jazyka Fortran. Příkladem „problematických“ procesorů jsou například čipy Intel 860, pro něž kvalitní překladače těchto jazyků vznikaly poměrně pomalu, takže v praxi byl výkon těchto procesorů degradován, protože horší překladače nedokázaly využít všech jejich vlastností. Ovšem právě v této oblasti mají zásobníkové procesory dosti ztíženou pozici, protože pro efektivní překlad aplikací naprogramovaných v jazycích C a C++ je nutné, aby technologie procesorů splňovala několik požadavků. Problém ale nespočívá v překladu zdrojového kódu do mezikódu – to je operace, která je prakticky nezávislá na architektuře procesorů. Komplikace nenajdeme ani v překladu aritmetických a logických výrazů do „zásobníkového“ kódu; spíše naopak, protože jakkoli složitý aritmetický výraz lze převést na RPN (převrácenou polskou notaci), jenž vlastně přímo odpovídá vygenerované sekvenci instrukcí (což je jednodušší, než plánování obsazení pracovních registrů).

Obrázek 6: Mikroprocesor Intel i860.
Nejzávažnější komplikace však spočívá v tom, že se při volání funkcí využívají v programovacích jazycích C a C++ takzvané zásobníkové rámce (stack frames), které i přes použití slova „zásobník“ ve skutečnosti nemají s hardwarovými zásobníky implementovanými u zásobníkových procesorů příliš mnoho společného. Zásobníkové rámce jsou totiž alokovány přímo v operační paměti, což například znamená, že je možné vytvořit ukazatel na lokální proměnnou (vytvořenou v zásobníkovém rámci) a posléze tento ukazatel předat do jiné volané funkce. Navíc se k datům uloženým na zásobníkovém rámci může přistupovat náhodně, což je ostatně logické, protože jsou zde uloženy jak parametry volané funkce, tak i lokální proměnné. Ovšem u čistého zásobníku lze přistupovat pouze k prvkům umístěným na jeho vrcholu, takže ve skutečnosti se při překladu programů z C či C++ musí zásobníkový rámec skutečně vytvářet v operační paměti, což však znamená nutnost použít větší množství instrukcí typu „Load a Store“. To v důsledku vede ke zvětšení a zpomalení výsledného programového kódu. V tomto ohledu tedy poměrně jasně vyhrávají mikroprocesory s architekturou RISC, zejména ty čipy, které jsou vybaveny technologií posuvných registrových oken (register window) – není ostatně divu, že se RISCové procesory s oblibou používají na počítačích s Unixem, který je na céčku založen (nejenom samotné jádro, ale i mnohé aplikace).

Obrázek 7: Subsystém zásobníku operandů (zvýrazněno modrou barvou) a zásobníku návratových adres (zvýrazněno barvou červenou) zásobníkového mikroprocesoru WISC CPU/16.
Zdroj: P. Koopman – Architecture of the WISC CPU/16
4. Neortodoxní zásobníkové mikroprocesory: MuP21 a F21
San Mateo, CA (November, 1994) – Offete Enterprises announces successful production of the high performance, multiprocessor chip MuP21. MuP21 has a 21-bit CPU core, a memory coprocessor, and a video coprocessor, implemented with 1.2 micron CMOS process. It is targeted for applications in video displays, CAD design, communication, video games, and embedded systems.
V předchozí části tohoto seriálu jsme se seznámili se základními vlastnostmi zásobníkového procesoru RTX 2000 vyráběného v minulosti společností Harris. Tento procesor využíval instrukční sadu, která byla odvozena od starších procesorů Novix NC4016 a MISC M17. Jednalo se o instrukce pevné délky šestnáct bitů, které ve svém instrukčním slovu mohly obsahovat kódy většího množství operací, například aritmetické či logické operace následované bitovým posunem a navíc se pomocí jednoho bitu mohlo specifikovat, zda má procesor v průběhu ALU operace paralelně provést návrat z podprogramu/subrutiny (z pohledu programátora se tedy návrat z podprogramu provedl za nula strojových cyklů). Instrukční slova všech tří zmíněných procesorů – Harris RTX 2000, Novix NC4016 i MISC M17 – používala formát velmi podobný formátu, který můžeme nalézt i u mikroprocesorů s architekturou RISC: každé instrukční slovo bylo rozděleno na několik bitových polí, přičemž na základě formátu instrukce (určeného obsahem jednoho bitového pole) procesor rozlišoval například mezi instrukcemi pro provedení ALU operací, instrukcí skoku, instrukcí pro načtení konstanty atd.

Obrázek 8: Formát mikroinstrukčního slova procesoru WISC CPU/16, na němž je patrné rozdělení mikroinstrukce na několik samostatných bloků. Adresa další mikroinstrukce je získána na základě obsahu bitů 23, 24 a 25 (to, že je procesor WISC CPU/16 založen na mikroprogramovém řadiči, vychází z toho, že se jedná o čip sestavený pro studijní účely).
Zdroj: P. Koopman – Architecture of the WISC CPU/16
Po relativně dlouhou dobu cca pěti let se zdálo, že tento formát instrukcí je pro RISCové procesory i zásobníkové procesory ideální, protože zaručuje velkou variabilitu instrukční sady současně se zachováním pevné délky instrukcí, což zjednodušuje implementaci instrukční pipeline i samotného obvodového či mikroprogramového řadiče. Ovšem v první polovině devadesátých let minulého století se objevila poměrně revoluční koncepce nového typu zásobníkového mikroprocesoru, se kterou nepřišel nikdo jiný, než Chuck Moore, vynálezce programovacího jazyka Forth, programátor systému pro poloautomatický návrh VLSI obvodů nazvaný OKAD a současně i známý a hlasitý propagátor principu minimalismu při návrhu hardware i tvorbě software. Nový Moorův mikroprocesor nesl označení MuP21. Na tento mikroprocesor navázal čip M21 a posléze i velmi zajímavý procesor F21. V následujících čtyřech kapitolách si o těchto zajímavých (i když komerčně relativně neúspěšných) mikroprocesorech řekneme podrobnější informace.

Obrázek 9: Formát instrukce procesoru WISC CPU/16 v případě, že se jedná o instrukci aritmetickou, logickou či o instrukci přesunu dat.
Zdroj: P. Koopman – Architecture of the WISC CPU/16
5. Mikroprocesory MuP21 a F21 versus procesory CISC a RISC
Odborná veřejnost se začala o mikroprocesory MuP21 a F21 zajímat, i když tyto čipy nebyly podporovány žádným významným výrobcem mikroprocesorů. Důvodem tohoto zájmu byla především schopnost MuP21/F21 reagovat na přerušení se zpožděním pouze jednoho strojového cyklu, zcela nová instrukční sada a taktéž kvůli tomu, že se skutečně jednalo o minimalisticky navržené mikroprocesory (ostatně při návrhu čipu MuP21 použit Chuck Moore svůj systém OKAD). Konkrétně to znamenalo, že čip MuP21 obsahoval pouze 7000 tranzistorů a jeho následovník F21 měl spolu se všemi koprocesory (paralelním portem, sériovým portem, analogovým převodníkem a dokonce i video výstupem) jen 15000 tranzistorů, ovšem jeho výpočetní rychlost dosahovala až 500 MIPS (ve skutečnosti byla kvůli pomalým pamětem výpočetní rychlost omezena na 333 MIPS či 200 MIPS, v závislosti na použité paměťové technologii). Počty tranzistorů odpovídají spíše osmibitovým mikroprocesorům s architekturou CISC, ovšem ve skutečnosti mají čipy MuP21 i F21 aritmeticko-logickou jednotku se šířkou operandů 20 bitů, což je pro mnohé aplikace dobrý poměr mezi šířkou a paměťovými či výpočetními nároky (16 bitů bývá pro mnohé aplikace málo, celých 32 bitů se mnohdy nevyužívá v plném rozsahu).

Obrázek 10: Formát instrukce procesoru WISC CPU/16 v případě, že se jedná o instrukci skoku do podprogramu (call).
Zdroj: P. Koopman – Architecture of the WISC CPU/16
Pro úplnost je možná vhodné doplnit základní informace o „konkurenčních“ mikroprocesorech s architekturami RISC a CISC (zvláště zajímavé je porovnání procesorů MuP21 a F21 s Itaniem 2 a PA-RISC PCX-L2):
| Mikroprocesor | Architektura | Bitová šířka | Rok prodeje | Počet tranzistorů |
|---|---|---|---|---|
| Intel 4004 | CISC | 4 | 1971 | 2 250 |
| Intel 8008 | CISC | 8 | 1972 | 3 500 |
| MOS Technology 6502 | CISC | 8 | 1975 | 3 510 |
| Motorola 6800 | CISC | 8 | 1974 | 4 100 |
| Intel 8080 | CISC | 8 | 1974 | 4 500 |
| Intel 8086 | CISC | 16 | 1978 | 29 000 |
| Intel 8088 | CISC | 8/16 | 1979 | 29 000 |
| Intel 80186 | CISC | 16 | 1982 | 55 000 |
| Motorola 68000 | CISC | 32 | 1979 | 68 000 |
| Intel 80286 | CISC | 16 | 1982 | 134 000 |
| Intel 80386 | CISC | 32 | 1985 | 275 000 |
| Intel 80486 | CISC | 32 | 1989 | 1 180 000 |
| Pentium | CISC | 32 | 1993 | 3 100 000 |
| Pentium II | CISC | 32 | 1997 | 7 500 000 |
| Pentium II | CISC | 32 | 1998 | 7 500 000 |
| Pentium III | CISC | 32 | 1999 | 9 500 000 |
| Pentium III | CISC | 32 | 2000 | 28 000 000 |
| Pentium 4 | CISC | 32 | 2000 | 42 000 000 |
| Pentium 4 | CISC | 32 | 2002 | 55 000 000 |
| Pentium 4 | CISC | 32 | 2004 | 125 000 000 |
| Pentium 4 | CISC | 32 | 2006 | 188 000 000 |
| Itanium | CISC | 64 | 2001 | 25 000 000 |
| Itanium 2 | CISC | 64 | 2003 | 220 000 000 |
| Itanium 2 | CISC | 64 | 2004 | 592 000 000 |
| Itanium 2 | CISC | 64 | 2006 | 1 720 000 000 |
| Core 2 | CISC | 64 | 2006 | 291 000 000 |
| Core 2 | CISC | 64 | 2008 | 800 000 000 |
| RISC I | RISC | 32 | 1980 | 44 000 |
| RISC II | RISC | 32 | 1981 | 39 000 |
| PA-RISC TS-1 | RISC | 32 | 1986 | 115 000 |
| PA-RISC CS-1 | RISC | 32 | 1987 | 164 000 |
| PA-RISC NS-1 | RISC | 32 | 1987 | 144 000 |
| PA-RISC NS-2 | RISC | 32 | 1989 | 183 000 |
| PA-RISC PCX | RISC | 32 | 1990 | 196 000 |
| PA-RISC PCX-S | RISC | 32 | 1991 | 580 000 |
| PA-RISC PCX-T | RISC | 32 | 1992 | 850 000 |
| PA-RISC PCX-T | RISC | 32 | 1994 | 850 000 |
| PA-RISC PCX-T' | RISC | 32 | 1994 | 1 260 000 |
| PA-RISC PCX-L | RISC | 32 | 1994 | 900 000 |
| PA-RISC PCX-L2 | RISC | 32 | 1996 | 9 200 000 |
| MuP21 | Stack | 20/21 | 1994 | 7 000 |
| F21 | Stack | 20/21 | 1996 | 15 000 |

Obrázek 11: Jedna z mnoha 64bitových variant mikroprocesoru využívajícího instrukční sadu MIPS.
6. Datový zásobník (zásobník operandů), zásobník návratových adres a adresní registr A
Vzhledem k tomu, že procesor MuP21 i jeho následovník F21 byly navrženy takovým způsobem, aby umožňovaly efektivní běh aplikací napsaných v programovacím jazyku Forth (co jiného lze ostatně od Chucka Moora čekat?), jsou oba procesory vybaveny dvojicí zásobníků. První zásobník je určen pro přenos dat a provádění aritmetických výpočtů. Tento zásobník má kapacitu osmnácti položek, z nichž každá má šířku 21 bitů. Celý zásobník je implementován přímo na mikroprocesoru (v jednom čipu), čímž vlastně nahrazuje sadu pracovních registrů, které se používají u mikroprocesorů s architekturami CISC a RISC. Druhý zásobník je určen především na úschovu návratových adres při volání podprogramů/subrutin či při obsluze přerušení. Kromě toho je možné na tento zásobník ukládat i data, ovšem většinou pouze v rámci těla jedné funkce. V tomto zásobníku se taktéž ukládají počitadla smyček. Tento zásobník má kapacitu sedmnácti položek a je – podobně jako zásobník první – umístěn přímo na mikroprocesoru.

Obrázek 12: Bloky, z nichž se skládá procesor F21.
Proč však mají oba zásobníky tak divné kapacity? Osmnáct resp. sedmnáct položek (prvků) jsou ve výpočetní technice poměrně netypické hodnoty. Ve skutečnosti však má datový zásobník kapacitu „pouze“ šestnácti položek (to už je pro programátory zajímavější číslo) a zbývající dvě položky jsou umístěny přímo na vstupu do aritmeticko-logické jednotky, protože u zásobníkového procesoru je již dopředu zřejmé, že se data pro provedení ALU operací budou vždy brát z první položky či prvních dvou položek datového zásobníku (někdy se též nazývá zásobník operandů). Tyto dvě položky se označují písmeny T (Top of Stack) a S (Second Item on Stack). U zásobníku návratových adres je situace podobná – nejvrchnější položka je umístěna ve speciálním registru nazývaném R (Return) a zbývající kapacita zásobníku je rovna opět šestnácti položkám. V instrukční sadě se nenachází žádné instrukce, které by umožňovaly přístup k nižším položkám zásobníků, což mj. znamená, že se zjednodušuje příprava operandů pro všechny možné operace – je jisté, že tyto operandy budou buď načteny z operační paměti, nebo budou přítomny v registrech T, S, R či ve speciálním adresovém registru A.

Obrázek 13: „b16“ je název procesorového jádra inspirovaného čipy MuP21 a F21 (částečně též C18).
Autor: Bernd Paysan
Na samém konci předchozího odstavce jsme se zmínili o speciálním adresovém registru nazvaném jednoduše A. Jedná se o registr, který se v „ortodoxních“ zásobníkových procesorech sice nepoužívá, ovšem Chuck Moore zjistil, že pro efektivní adresování dat uložených v operační paměti je vhodné podobný registr implementovat. Adresový registr A má šířku 21 bitů a v instrukční sadě procesorů MuP21 i F21 se nachází instrukce umožňující načtení či uložení dat (z vrcholu zásobníku operandů) do operační paměti s možnou inkrementací obsahu tohoto registru. To znamená, že například práce s daty uloženými v poli může být velmi jednoduchá a současně i rychlá, protože inkrementace adresního registru A je samozřejmě prováděna paralelně s přístupem k datům umístěným v operační paměti. Kromě toho je v instrukční sadě i několik instrukcí pracujících s adresou uloženou na vrcholu zásobníku návratových adres, tj. ve skutečnosti v interním registru R. V důsledku tak lze například kopírovat data mezi dvojicí polí bez toho, aby se neustále musel měnit ukazatel umístěný v adresním registru A.

Obrázek 14: „b16-small“ je procesorové jádro vzniklé dalším zjednodušením jádra „b16“
Autor: Bernd Paysan
7. Instrukční soubor procesoru F21
Chuck Moore se rozhodl, že šířka instrukčních slov bude u procesorů MuP21 i F21 rovna poněkud neobvyklé hodnotě 20 bitů, přičemž do jednoho dvacetibitového slova bude možné uložit až čtyři instrukce, protože počet bitů na jednu instrukci je roven pouze pěti! Maximální počet instrukcí tak dosahuje na první pohled směšné hodnoty 25=32, instrukcí je však ve skutečnosti ještě o něco méně, protože se zde opět projevil Moorův smysl pro minimalismus (jiný konstruktér procesoru by zajisté všech 32 nabízených kódů vyplnil nějakou instrukcí). Vždy čtveřice pětibitových instrukcí jsou spojeny tak, že vytváří jedno dvacetibitové slovo. To ovšem v důsledku znamená, že vlastní procesor může pracovat na čtyřnásobné frekvenci oproti přístupové době použitých paměťových modulů, protože v každém paměťovém taktu je umožněn přístup ke všem dvaceti bitům! Zde je vidět velká výhoda malého instrukčního souboru, který vede k výrazné redukci počtu bitů na jednu instrukci, protože procesor může pracovat i na poměrně velkých frekvencích bez použití drahých cache pamětí (pokud jsou například použity synchronní paměti s hodinovou frekvencí 100 MHz, může procesor pracovat s hodinovou frekvencí 400 MHz =téměř 400 MIPS bez jakékoli vyrovnávací paměti).
Instrukce lze rozdělit do čtyř skupin: řízení běhu programu, načítání a ukládání hodnot do operační paměti, aritmetické a logické instrukce a konečně operace nad zásobníky.
Instrukce pro řízení běhu programu
V této skupině se nachází jak instrukce pro nepodmíněný skok, tak i dva podmíněné skoky a instrukce pro volání podprogramu/subrutiny a návrat ze subrutiny. U podmíněných skoků se testuje buď nulovost operandu uloženého na vrcholu datového zásobníku, popř. hodnota příznaku přetečení, která je do datového zásobníku ukládána společně s operandem (operand má šířku 20 bitů, prvky na datovém zásobníku mají šířku 21 bitů):
| Kód instrukce | Jméno v assembleru | Význam |
|---|---|---|
| 00 | else | unconditional jump |
| 01 | T=0 | jump if T0–19 zero |
| 02 | call | push P+1 to R, jump |
| 03 | C=0 | jump if T20 zero |
| 04 | ||
| 05 | ||
| 06 | ret | pop P from R |
| 07 |
Instrukce typu Load a Store
U těchto instrukcí je adresa buď uložena na vrcholu zásobníku návratových adres (=interní registr R) nebo v adresním registru A:
| Kód instrukce | Jméno v assembleru | Význam |
|---|---|---|
| 08 | @R+ | fetch, address in R, increment R |
| 09 | @A+ | fetch, address in A, increment A |
| 0A | # | fetch 20-bit in-line literal |
| 0B | @A | fetch, address in A |
| 0C | !R+ | store, address in R, increment R |
| 0D | !A+ | store, address in A, increment A |
| 0E | ||
| 0F | !A | store, address in A |
Aritmetické a logické instrukce
Při provádění aritmetických operací se výpočty aplikují v ALU, která má bitovou šířku 21 bitů. Poslední bit slouží jako CARRY, tj. obsahuje jedničku v případě, že došlo k přetečení kapacity registrů. Toho lze využít například při implementaci vícebitové aritmetiky. I adresy jsou reprezentovány 21 bity, skokové instrukce však mohou měnit pouze nižší bity adresy. Zajímavá jsou především instrukce + a +*. Procesor F21 totiž obsahuje sčítačku s postupným přenosem, která může být sestavena z mnohem menšího množství tranzistorů, než sčítačka se zrychleným přenosem. Na druhou stranu ovšem sčítání trvá delší počet cyklů, což v případě procesoru F21 znamená, že pokud je instrukce sčítání uložena v prvním slotu (5 bitech) instrukčního slova, je součet dokončen spolu s instrukcí v posledním slotu, protože se provede přibližně součet 6 bitů v jednom strojovém cyklu. Programátor či překladač si tedy sám může určit, jaký počet bitů se má skutečně sečíst a podle toho umístit instrukci + a +* do správného slotu.
| Kód instrukce | Jméno v assembleru | Význam |
|---|---|---|
| 10 | com | complement T |
| 11 | 2* | shift T, 0 to T0 |
| 12 | 2/ | shift T, T20 to T19 |
| 13 | +* | add S to T if T0 one |
| 14 | -or | exclusive-or S to T |
| 15 | and | and S to T |
| 16 | ||
| 17 | + | add S to T |

Obrázek 15: Operace násobení s rozbalenou smyčkou zapsaná ve Forthu.
Instrukce pro operace nad zásobníky
Zde pravděpodobně není co dodávat, jedná se o instrukce běžných zásobníkových procesorů doplněných o několik instrukcí pracujících s adresním registrem A:
| Kód instrukce | Jméno v assembleru | Význam |
|---|---|---|
| 18 | pop | pop R, push into T |
| 19 | A@ | push A into T |
| 1A | dup | push T into T |
| 1B | over | push S into T |
| 1C | push | pop T, push into R |
| 1D | A! | pop T into A |
| 1E | nop | nop |
| 1F | drop | pop T |

Obrázek 16: Operace dělení s rozbalenou smyčkou zapsaná ve Forthu.
8. Procesory a procesorová jádra navazující na dvojici MuP21 a F21
Principy využité při návrhu zásobníkových mikroprocesorů MuP21 a F21 byly v následujících letech použity i u dalších typů procesorů a procesorových jader. Jedná se například o procesorové jádro nazvané C18 s 18bitovými sběrnicemi, jehož autorem je opět Chuck Moore. Procesorové jádro C18 je díky svým malým rozměrům (jak fyzickým, tak i počtem tranzistorů) určeno pro použití v multiprocesorech. Příkladem může být čip SEAforth 40C18, který obsahuje celkem čtyřicet(!) jader C18, přičemž každé z těchto jader má k dispozici vlastní paměť RAM i ROM, každou o kapacitě 64 slov. Multiprocesorový čip SEAforth 40C18 lze využít například jako velmi výkonný digitální signálový procesor s relativně malým příkonem, protože každé procesorové jádro C18 má maximální příkon nepřesahující 9 mW a v automatickém režimu spánku dokonce jen 5 µW. Tento čip je určen pro provádění instrukcí tvořících základní slova (funkce) VentureForthu.

Obrázek 17: Multiprocesorový čip SEAforth 40C18.

Druhou oblast, v nichž se uplatnily principy implementované v mikroprocesorech MuP21 a F21, tvoří procesorová jádra „naprogramovaná“ ve VHDL nebo ve Verilogu, tj. jádra využitelná na FPGA. Zde se opět projevuje jedna z předností těchto typů zásobníkových procesorů – velmi malý počet tranzistorů/logických hradel/bloků nutných pro implementaci celého procesoru a tím i možnost syntézy těchto jader i na malých FPGA. Příkladem mohou být procesorová jádra nazvaná b16 a b16-small, která byla navržená ve VHDL Berndem Paysanem (viz též odkazy uvedené v deváté kapitole). Tato jádra, podobně jako je tomu u předchozích procesorů, taktéž používají pětibitové instrukce sdružené do slov o větší bitové šířce, na rozdíl od MuP21 a F21 se však vždy trojice instrukcí spojuje do 16bitového slova, přičemž šestnáctý bit lze využít pro zakódování „dlouhého“ skoku s 15bitovou adresou. Zajímavé je, že už tak velmi jednoduché procesorové jádro b16 bylo nahrazeno ještě jednodušším návrhem b16-small, kde například chybí adresový registr A a druhá položka zásobníku operandů NOS (N) je umístěna v paměti, čímž se celkový počet registrů (a tím pádem i počet klopných obvodů) snížil na hodnotu 3.

Obrázek 18: Instrukční soubor procesorového jádra b16.
9. Odkazy na Internetu
- Great Microprocessors of the Past and Present
http://www.cpushack.com/CPU/cpu1.html - Philip Koopman: Stack Computers: the new wave
http://www.ece.cmu.edu/~koopman/stack_computers/contents.html - Hewlett Packard PA-8800 RISC (LOSTCIRCUITS)
http://www.lostcircuits.com/mambo//index.php?option=com_content&task=view&id=42&Itemid=42 - PA-RISC 1.1 Architecture and Instruction Set Reference Manual
http://h21007.www2.hp.com/portal/download/files/unprot/parisc/pa1–1/acd.pdf - Fotografie mikroprocesorů HP PA (stránka 1)
http://www.chipdb.org/cat-pa-risc-592.htm - Fotografie mikroprocesorů HP PA (stránka 2)
http://www.chipdb.org/cat-pa-risc-592.htm?page=2 - Fotografie mikroprocesorů HP PA (stránka 2)
http://www.chipdb.org/cat-pa-risc-592.htm?page=3 - PA-RISC (Wikipedia)
http://en.wikipedia.org/wiki/PA-RISC - The Great CPU List: Part VI: Hewlett-Packard PA-RISC, a conservative RISC (Oct 1986)
http://jbayko.sasktelwebsite.net/cpu4.html - HP 9000/500 FOCUS
http://www.openpa.net/systems/hp-9000_520.html - HP FOCUS Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/HP_FOCUS - HP 3000 (Wikipedia)
http://en.wikipedia.org/wiki/HP_3000 - The SPARC Architecture Manual Version 8 (manuál v PDF formátu)
http://www.sparc.org/standards/V8.pdf - The SPARC Architecture Manual Version 9 (manuál v PDF formátu)
http://developers.sun.com/solaris/articles/sparcv9.pdf - SPARC Pipelining
http://www.academic.marist.edu/~jzbv/architecture/Projects/S2002/SPARC/pipelining.html - SPARC Instruction
http://www.academic.marist.edu/~jzbv/architecture/Projects/S2002/SPARC/inst_set.html - OpenSPARC
http://www.opensparc.net/ - History of SPARC systems 1987 to 2010
http://www.sparcproductdirectory.com/history.html - Sun-1 (Wikipedia)
http://en.wikipedia.org/wiki/Sun-1 - Sun-2 (Wikipedia)
http://en.wikipedia.org/wiki/Sun-2 - Sun-3 (Wikipedia)
http://en.wikipedia.org/wiki/Sun-3 - Sun386i (Wikipedia)
http://en.wikipedia.org/wiki/Sun386i - Sun 386i/250
http://sites.inka.de/pcde/site/sun386i.html - SPARC Instruction Set
http://www.academic.marist.edu/~jzbv/architecture/Projects/S2002/SPARC/inst_set.html - MIPS Architecture Overview
http://tams-www.informatik.uni-hamburg.de/applets/hades/webdemos/mips.html - MIPS Technologies R3000
http://www.cpu-world.com/CPUs/R3000/ - CPU-collection: IDT R3010 FPU
http://www.cpu-collection.de/?tn=0&l0=co&l1=IDT&l2=R3010+FPU - The MIPS R2000 Instruction Set
http://suraj.lums.edu.pk/~cs423a05/Reference/MIPSCodeTable.pdf - Maska mikroprocesoru RISC 1
http://www.cs.berkeley.edu/~pattrsn/Arch/RISC1.jpg - Maska mikroprocesoru RISC 2
http://www.cs.berkeley.edu/~pattrsn/Arch/RISC2.jpg - The MIPS Register Usage Conventions
http://pages.cs.wisc.edu/~cs354–2/beyond354/conventions.html - C.E. Sequin and D.A.Patterson: Design and Implementation of RISC I
http://www.eecs.berkeley.edu/Pubs/TechRpts/1982/CSD-82–106.pdf - Berkeley RISC
http://en.wikipedia.org/wiki/Berkeley_RISC - Great moments in microprocessor history
http://www.ibm.com/developerworks/library/pa-microhist.html - Microprogram-Based Processors
http://research.microsoft.com/en-us/um/people/gbell/Computer_Structures_Principles_and_Examples/csp0167.htm - A Brief History of Microprogramming
http://www.cs.clemson.edu/~mark/uprog.html - Architecture of the WISC CPU/16
http://www.ece.cmu.edu/~koopman/stack_computers/sec4_2.html - Zásobníkový procesor WISC CPU/16 (Root.CZ)
http://www.root.cz/clanky/programovaci-jazyk-forth-a-zasobnikove-procesory-16/#k03 - Writable instruction set, stack oriented computers: The WISC Concept
http://www.ece.cmu.edu/~koopman/forth/rochester87.pdf - The Great CPU List: Part X: Hitachi 6301 – Small and microcoded (1983)
http://jbayko.sasktelwebsite.net/cpu2.html#Sec2Part10 - What is RISC?
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/whatis/ - RISC vs. CISC
http://www-cs-faculty.stanford.edu/~eroberts/courses/soco/projects/2000–01/risc/risccisc/ - RISC and CISC definitions:
http://www.cpushack.com/CPU/cpuAppendA.html - The Evolution of RISC
http://www.ibm.com/developerworks/library/pa-microhist.html#sidebar1 - SPARC Processor Family Photo
http://thenetworkisthecomputer.com/site/?p=243 - SPARC: Decades of Continuous Technical Innovation
http://blogs.oracle.com/ontherecord/entry/sparc_decades_of_continuous_technical - The SPARC processors
http://www.top500.org/2007_overview_recent_supercomputers/sparc_processors - Maurice V. Wilkes Home Page
http://www.cl.cam.ac.uk/archive/mvw1/ - Papers by M. V. Wilkes (důležitá je především jeho práce číslo 35)
http://www.cl.cam.ac.uk/archive/mvw1/list-of-papers.txt - Microprogram Memory
http://free-books-online.org/computers/advanced-computer-architecture/microprogram-memory/ - First Draft of a report on the EDVAC
http://qss.stanford.edu/~godfrey/vonNeumann/vnedvac.pdf - Introduction to Microcontrollers
http://www.pic24micro.com/cisc_vs_risc.html - Reduced instruction set computing (Wikipedia)
http://en.wikipedia.org/wiki/Reduced_instruction_set_computer - MIPS architecture (Wikipedia)
http://en.wikipedia.org/wiki/MIPS_architecture - Very long instruction word (Wikipedia)
http://en.wikipedia.org/wiki/Very_long_instruction_word - Classic RISC pipeline (Wikipedia)
http://en.wikipedia.org/wiki/Classic_RISC_pipeline - R2000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R2000_(microprocessor) - R3000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R3000 - R4400 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R4400 - R8000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R8000 - R10000 Microprocessor (Wikipedia)
http://en.wikipedia.org/wiki/R10000 - SPARC (Wikipedia)
http://en.wikipedia.org/wiki/Sparc - SPARC Tagged Data – otázka
http://compilers.iecc.com/comparch/article/91–04–079 - SPARC Tagged Data – odpověď #1
http://compilers.iecc.com/comparch/article/91–04–082 - SPARC Tagged Data – odpověď #2
http://compilers.iecc.com/comparch/article/91–04–088 - CPU design (Wikipedia)
http://en.wikipedia.org/wiki/CPU_design - Control unit (Wikipedia)
http://en.wikipedia.org/wiki/Control_unit - Microcode (Wikipedia)
http://en.wikipedia.org/wiki/Microcode - Microsequencer (Wikipedia)
http://en.wikipedia.org/wiki/Microsequencer - Maurice Wilkes (Wikipedia)
http://en.wikipedia.org/wiki/Maurice_Wilkes - Micro-operation (Wikipedia)
http://en.wikipedia.org/wiki/Micro-operation - b16 stack processor
http://www.jwdt.com/~paysan/b16.html - Color Forth (Chuck Moore home page)
http://www.colorforth.com/ - colorForth Instructions
http://www.colorforth.com/inst.htm - SEAforth 40C18
http://www.intellasys.net/index.php?option=com_content&task=view&id=60&Itemid=75






































 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU
{kind=link}
{kind=link}